What is NUMA?
Modern CPUs have had a built-in memory controller for many years now, starting with the K8/Opteron, in order to higher better bandwidth and lower latency. As a result in SMP systems each CPU has their own memory controller and its own system memory that it can access at high speed – while to access other memory it must send requests to the other CPUs. NUMA is a way of describing such systems and allow the operating system and applications to allocate memory on the node they are running on for best performance.
As ThreadRipper is really two (2) Ryzen dies connected internally through InfinityFabric – it is basically a 2-CPU SMP system and thus a 2-node NUMA system.
While it is possible to configure it in UMA (Uniform Memory Access mode) where all memory appears to be unified and interleaved between nodes, for best performance the NUMA mode is recommended when the operating system and applications support it.
While Sandra has always supported NUMA in the standard benchmarks – some of the new benchmarks have not been updated with NUMA support especially since multi-core systems have pretty much killed SMP systems on the desktop – with only expensive severs left to bring SMP / NUMA support.
Note that all the NUMA improvements here would apply to competitor NUMA (e.g. Intel) systems, thus it is not just for ThreadRipper – with EPYC systems likely showing a far higher improvement too.
In this article we test NUMA performance; please see our other articles on:
- AMD Threadripper 1950X Review and Benchmarks – CPU 16-core Performance
- AMD Threadripper 1950X Review and Benchmarks – 4-channel DDR4 Cache & Memory Performance
Native Performance
We are testing native performance using various instruction sets: AVX512, AVX2/FMA3, AVX to determine the gains the new instruction sets bring.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and Intel drivers. Turbo / Dynamic Overclocking was enabled on both configurations.
| Native Benchmarks | NUMA 2-nodes |
UMA single-node |
Comments | |||
 |
||||||
 |
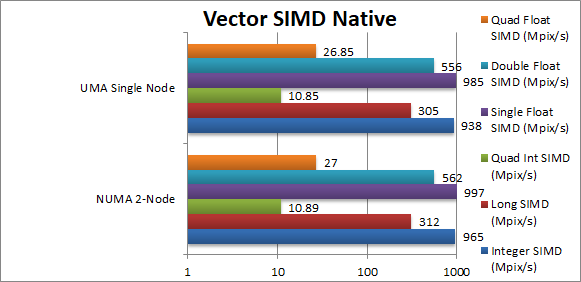
Native Integer (Int32) Multi-Media (Mpix/s) | 965 [+2.8%] | 938 | The ‘lightest’ workload should show some NUMA overhead but we can only manage 3% here. | ||
|
Native Long (Int64) Multi-Media (Mpix/s) | 312 [+2.3%] | 305 | With a 64-bit integer workload the improvement drops to 2%. | ||
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 10.9 [=] | 10.9 | Emulating int128 means far increased compute workload with NUMA overhead insignificant. | ||
|
Native Float/FP32 Multi-Media (Mpix/s) | 997 [+1.2%] | 985 | Again no measured improvement here. | ||
|
Native Double/FP64 Multi-Media (Mpix/s) | 562 [+1%] | 556 | Again no measured improvement here. | ||
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 27 [=] | 26.85 | In this heavy algorithm using FP64 to mantissa extend FP128 we see no improvement. | ||
| Fractals are compute intensive with few memory accesses – mainly to store results – thus we see a maximum of 3% improvement with NUMA support with the rest insignificant. However, this is a simple 2-node system – bigger 4/8-node systems would likely show bigger gains. | ||||||
 |
||||||
 |
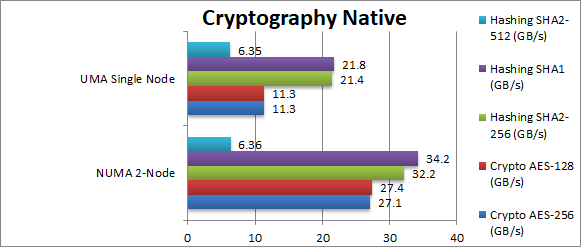
Crypto AES256 (GB/s) | 27.1 [+139%] | 11.3 | AES hardware accelerated is memory bandwidth bound thus NUMA support matters; even in this 2-node system we see a over 2x improvement of 139%! | ||
|
Crypto AES128 (GB/s) | 27.4 [+142%] | 11.3 | Similar to above we see a massive 142% improvement by allocating memory on the right NUMA node. | ||
|
Crypto SHA2-256 (GB/s) | 32.3 [+50%] | 21.4 | SHA is also hardware accelerated but operates on a single input buffer (with a small output hash value buffer) and here out improvement drops to 50%, still very much significant. | ||
|
Crypto SHA1 (GB/s) | 34.2 [+56%] | 21.8 | Similar to above we see an even larger 56% improvement for supporting NUMA. | ||
|
Crypto SHA2-512 (GB/s) | 6.36 [=] | 6.35 | SHA2-256 is not hardware accelerated (AVX2 used) but heavy compute bound thus our improvement drops to nothing. | ||
| Finally in streaming algorithms we see just how much NUMA support matters: even on this 2-note system we see over 2x improvement of 140% when working with 2 buffers (in/out). When using a single buffer our improvement drops to 50% but still very much significant. TR needs NUMA suppport to shine. | ||||||
 |
||||||
 |
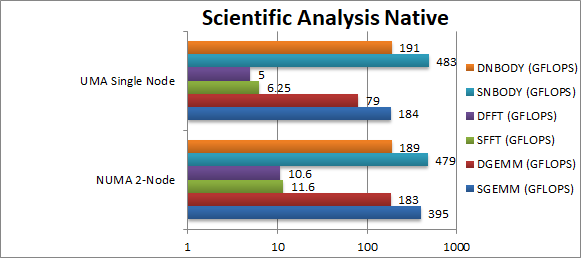
SGEMM (GFLOPS) float/FP32 | 395 [114%] | 184 | As with crypto, GEMM benefits greatly from NUMA support with an incredible 114% improvement by allocating the (3) buffers on the right NUMA nodes. | ||
|
DGEMM (GFLOPS) double/FP64 | 183 [131%] | 79 | Changing to FP64 brings an even more incredible 131%. | ||
|
SFFT (GFLOPS) float/FP32 | 11.6 [86%] | 6.25 | FFT also shows big gains from NUMA support with 86% improvement just by allocating the buffers (2+1 const) on the right nodes. | ||
|
DFFT (GFLOPS) double/FP64 | 10.6 [112%] | 5 | With FP64 again increases | ||
|
SNBODY (GFLOPS) float/FP32 | 479 [=] | 483 | Strangely N-Body does not benefit much from NUMA support with no appreciable improvement. | ||
|
DNBODY (GFLOPS) double/FP64 | 189 [=] | 191 | With FP64 workload nothing much changes. | ||
| As with crypto, buffer heavy algorithms (GEMM, FFT, N-Body) greatly benefit from NUMA support with performance doubling (86-131%) by allocating on the right NUMA nodes; in effect TR needs NUMA in order to perform better than a standard Ryzen! | ||||||
 |
||||||
 |
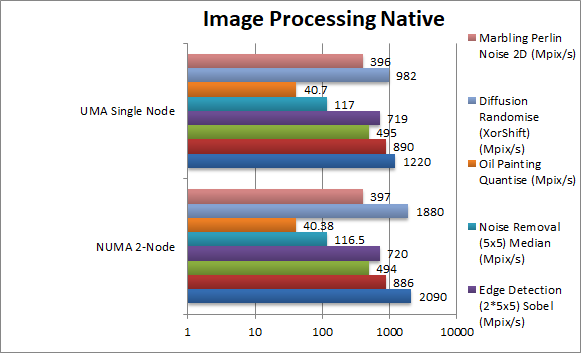
Blur (3×3) Filter (MPix/s) | 2090 [+71%] | 1220 | Least compute brings highest benefit from NUMA support – here it is 71%. | ||
|
Sharpen (5×5) Filter (MPix/s) | 886 [=] | 890 | Same algorithm but more compute brings the improvement to nothing. | ||
|
Motion-Blur (7×7) Filter (MPix/s) | 494 [=] | 495 | Again same algorithm but even more compute again no benefit. | ||
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 720 [=] | 719 | Using two buffers does not seem to show any benefit either. | ||
|
Noise Removal (5×5) Median Filter (MPix/s) | 116 [=] | 117 | Different algorithm keeps with more compute means no benefit either. | ||
|
Oil Painting Quantise Filter (MPix/s) | 40.3 [=] | 40.7 | Using the new scatter/gather in AVX2 does not help matters even with NUMA support. | ||
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 1880 [+90%] | 982 | Here we have a 64-bit integer workload algorithm with many gathers not compute heavy brings 90% improvement. | ||
|
Marbling Perlin Noise 2D Filter (MPix/s) | 397 [=] | 396 | Heavy compute brings down the improvement to nothing. | ||
| As with other SIMD tests, low compute algorithms see 70-90% improvement from NUMA support; heavy compute algorithms bring the improvement down to zero. It all depends whether the overhead of accessing other nodes can be masked by compute; in effect TR seems to perform pretty well. | ||||||
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
It is clear that ThreadRipper needs NUMA support in applications – just like any other SMP system today to shine: we see over 2x improvement in bandwidth-heavy algorithms. However, in compute-heavy algorithms TR is able to mask the overhead pretty well – with NUMA bringing almost no improvement. For non NUMA supporting software the UMA mode should be employed.
Let’s remember we are only testing a 2-node system, here, a 4+ node system is likely to show higher improvements and with EPYC systems stating at 1-socket 4-node we can potentially have common 4-socket 16-node systems that absolutely need NUMA for best performance. We look forward to testing such a system as soon as possible 😉