What is big.LITTLE?
ARM’s big.LITTLE arch made big waves on launch way back in 2011; it was heralded as a great way to combine performance with power: a “big” (computationally powerful but power hungry) core was to be coupled with a “LITTLE” (slow but low-power) core – and switched as needed. The way they would be switched has changed as both the SoCs and the OS scheduler managing it all have evolved – but as we shall see not necessarily for the better.
The “poster child” for big.LITTLE has been Samsung’s Exynos family of SoCs as used in their extremely popular range of Galaxy phones and tablets (e.g. S4, S5; Note 3, 4; Tab Pro, S; etc.) so we shall use them to discuss – and benchmark – various big.LITTLE switching techniques.
Clustered Switching (CS)
CS was the first type of switching used that arranged the big cores into a “big cluster” and LITTLE cores into a “LITTLE cluster” – with the whole clusters switched in/out as needed. Exynos 5410 SoC (e.g. in Galaxy S4) thus had 4 Cortex A15 cores in the big cluster and 4 Cortex A7 in the LITTLE cluster – 8 cores in total – but only 4 cores could be used at any one time:
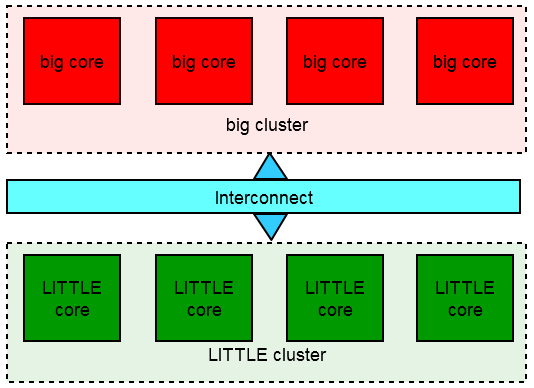
Working out when to switch clusters optimally was difficult – especially with users demanding “no lag” but also good battery time: you want quick ramping of speed on events (fast interaction) but also quick sleep. Do it too conservatively you get “lag”; do it too many times you use too much power.
On single-threaded workloads, 1 high-compute thread would require the whole big cluster to be switched on thus wasting power (theoretically the other 3 cores could have been parked/disabled but the scheduler did not implement this) or run slower on the LITTLE cluster.
But it was “symmetric multi-processing” (SMP) – aka all cores were the same (either all big or all LITTLE), thus making parallel code “easy” with symmetric workloads for each core.
In-Kernel Switching (IKS)
IKS added granularity by arranging each big and LITTLE core in one cluster – with the cores within each cluster switched in/out as needed. Exynos 5420 SoC (e.g. in Note 4) thus had 4 clusters, each made up of one Cortex A15 + one Cortex A7 core – 8 cores in total – but again only 4 cores could be used at any one time:
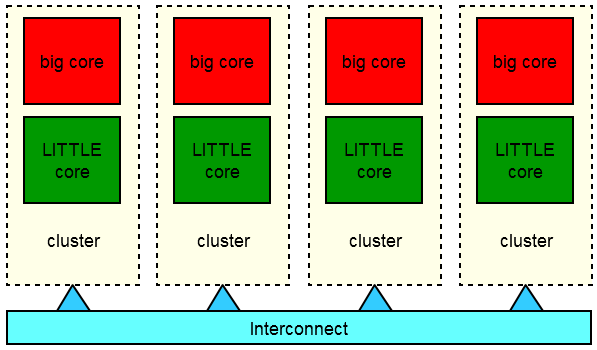
Working out when to switch cores in each cluster was thus easier depending on the compute workload on each cluster – some clusters may have the big core active while others may have the LITTLE core active.
While we no longer had “true SMP” – programmers could still assume it was SMP (aka all cores the same) with the scheduler hopefully switching the same cores within each cluster given symmetrical workload on each cluster.
Heterogeneous Multi-Processing (HMP) aka Global Task Scheduling (GKS)
HMP is really a fancy name for “asymmetric multi-processing” (AMP) where not all the cores are the same and there are no more clusters (at least hardware wise) – all cores are visible. Exynos 5433 (e.g. Note 4) thus has 4 Cortex A57 + 4 Cortex A53 cores – 8 cores in total with all 8 on-line if needed.
It is also possible to have different number of big and LITTLE cores now, e.g. Exynos 5260 had 2 big and 4 LITTLE cores, but normally the count is the same:
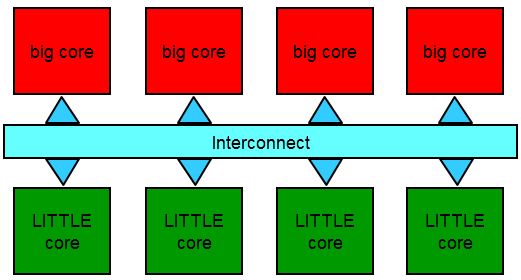
The scheduler can thus allocate high-compute threads on the big cores and low-compute threads on the LITTLE cores or park/disable any core to save power and migrate threads to the other cores. Server OSes have done this for years (both allocating threads on different CPUs/NUMA nodes first for performance or grouping threads on a few CPUs to park/disable the rest to save power).
Unfortunately this pushes some decisions to the app (or algorithm implementation library) programmers: is it better to use all (8 here) threads – or 4 threads? Shall the scheduling be left to the OS or the app/library? It is definitely a headache for programmers and won’t make SoC makers too happy as their latest chip won’t show the performance they were hoping for…
Is it better to use all or just the big cores? Is 4 better than 8?
While in some cultures “8” is a “lucky number” – just witness the proliferation of “octa core” SoCs almost without reason (Apple’s iPhones are still dual-core and slow they are not) – due to HMP we shall see that this is not always the case.
In x86-world, Hyper-Threading created similar issues: some computers/servers had HT disabled as workloads were running faster this way (e.g. games). Early OSes did not distribute threads “optimally” as the scheduler had no knowledge of HT (e.g. 1 core was be assigned 2 theads while the other cores were free) – thus some apps/libraries (like Sandra itself) had to use “hard scheduling” on the “right” cores or use less threads than (maximum) OS threads.
For phones/tablets there is a further issue – SoC power/thermal limits: using all cores may use more power than just the big cores – causing some (or all) cores to be “throttled” and thus run slower.
For parallel algorithms where each thread has the same workload (symmetric or “static work allocator”) using all cores can mean that the big cores will finish first and thus wait for the LITTLE cores to finish – effectively ending up with all LITTLE cores:
If the big cores are 2x or more faster – you were better off just the big cores; even if the big cores are not as fast – using all cores may (as detailed above) hit SoC power/thermal limits causing all cores to run slower than if less cores were used.
Parallel algorithms may thus need to switch to more complex asymmetric (or “dynamic work allocator”) that monitors the performance of each thread (within a time-frame as threads could be migrated to a different core by the scheduler) and assign work accordingly.
Alternatively, implementations may thus have to make decisions based on hardware topology or run quick tests/benchmarks in order to optimise themselves for best performance on the target hardware. Or hope for the best and leave the scheduler to work things out…
Hardware Specifications
Using “hard affinity” aka scheduling threads on specific cores, we have tested the 3 scenarios (only big cores, only LITTLE cores, all cores) on the HMP Exynos 5433 SoC (in the Note 4) across all the benchmarks in Sandra in order optimise each algorithm for best performance.
| SoC Specifications | Samsung Exynos 5433 / All 8 cores | Samsung Exynos 5433 / 4 big cores | Samsung Exynos 5433 / 4 LITTLE cores | Comments | |
| CPU Arch / ARM Arch | 4x Cortex A57 + 4x Cortex A53 | 4x Cortex A57 | 4x Cortex A53 | We shall see how much more powerful the A57 cores are compared to the A53. | |
| Cores (CU) / Threads (SP) | 4C + 4c / 8 threads simultaneously | 4C / 4 threads | 4c / 4 threads | With HMP can have 8 threads active when all cores are in use. Whether we need them remains to be seen. | |
| Core Features | Combined | Pipelined (15 depth), out-of-order, 3-way superscalar, 2-level branch prediction | Pipelined (8 depth), in-order, 2-way superscalar, simple branch prediction | The A57 is “built-for-speed” with a more complex architecture that can be up to 2x faster clock-for-clock. | |
| Speed (Min / Max / Turbo) (MHz) | 400-1900 | 700-1900 [+46%] | 400-1300 | The A57 are not only faster but can also scale up to 46% higher, pushing close to 2GHz. | |
| L1D / L1I Caches (kB) | 2x 4x 32kB | 4x 32kB (2-way set) / 4x 48kB (3-way set) | 4x 32kB (?) | Both cores have the same L1 caches | |
| L2 Caches (MB) | 2x 2MB | 2MB (16-way set) | 2MB (?) | All designs have the same size L2 cache. | |
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (Neon2, Neon, etc.).
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Android 5.x.x, latest updates (May 2015).
| Native Benchmarks | Samsung Exynos 5433 / All 8 cores | Samsung Exynos 5433 / 4 big cores | Samsung Exynos 5433 / 4 LITTLE cores | Comments | |
 |
|||||
 |
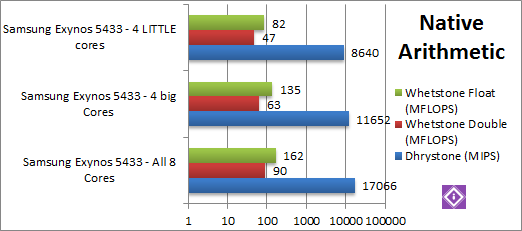
Native Dhrystone (GIPS) | 17.07 [+46% vs 4C] | 11.65 [+34% vs 4c] | 8.64 | Using all cores benefits greatly: they’re even 46% faster than just using the 4 big cores. The big cores are only 34% faster than the LITTLE cores, we were expecting more. |
|
Native FP64 (Double) Whetstone (GFLOPS) | 90 [+42% vs 4C] | 63 [+34% vs 4c] | 47 | We see similar stats in the floating-point test; another win for the 8 cores and small difference in the big/LITTLE performance. |
|
Native FP32 (Float) Whetstone (GFLOPS) | 162 [+20% vs 4C] | 135 [+64% vs 4c] | 82 | With FP32, we see the 8 cores being only 20% faster than just the 4 big cores, with the big cores 64% faster than the LITTLE ones. |
| Using all cores is undoubtedly faster than just big cores – between 20-45% faster. The big cores themselves are 35-65% faster than the LITTLE cores – but that should not be a surprise being clocked 46% faster. Their performance seems limited somewhat. | |||||
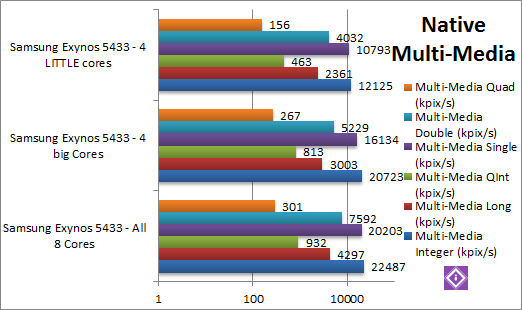 |
|||||
 |
Native Integer (Int32) Multi-Media (Mpix/s) | 22.48 Neon [+8.5% vs 4C] | 20.72 Neon [+71% vs 4c] | 12.12 Neon | SIMD (Neon) code – integer workload – shows the power of the big cores – they are 71% faster than the LITTLE ones! But using all cores is yet 8.5% faster – not a lot but faster. |
|
Native Long (Int64) Multi-Media (Mpix/s) | 4.3 Neon [+43% vs 4C] | 3.0 Neon [+27% vs 4c] | 2.36 Neon | The 64-bit Neon workload is hard on cores, here the big cores are only 27% faster – we would expect a bit better. Thus using all cores is a whopping 43% faster. |
|
Native Quad-Int (Int128) Multi-Media (kpix/s) | 932 [+14% vs 4C] | 813 [+75% vs 4c] | 463 | With normal int64 code, the the big cores are again 75% faster than the LITTLE cores, similar to what we saw in Neon/32 – but using all cores is still 14% faster. So far using all cores is always faster. |
|
Native Float/FP32 Multi-Media (Mpix/s) | 20.2 Neon [+25% vs 4C] | 16.13 Neon [+49% vs 4c] | 10.79 Neon | Switching to floating-point Neon SIMD code, the big cores show their power again – being ~50% faster than the LITTLE cres; but using all cores is 25% faster still! |
|
Native Double/FP64 Multi-Media (Mpix/s) | 7.59 [+45% vs 4C] | 5.22 [+20% vs 4c] | 4.03 | Switching to FP64 VFP code (Neon does support FP64 in ARMv8), the big cores are just 20% faster; thus using all cores is 45% faster still. |
|
Native Quad-Float/FP128 Multi-Media (kpix/s) | 301 [+12% vs 4C] | 267 [+71% vs 4c]] | 156 | In this heavy algorithm using FP64 to mantissa extend FP128, the big cores show their power again – they are 71% faster – but using all cores is 12% faster still. Even with floating-point all cores are still faster. |
| With highly-optimised Neon SIMD code, the big Cortex A57 cores are between 27-75% faster than the LITTLE A53 cores, whether integer or floating-point loads. But using all 8 cores is still faster by as little as 8% up to 45%. Regardless, 8 cores are always faster. | |||||
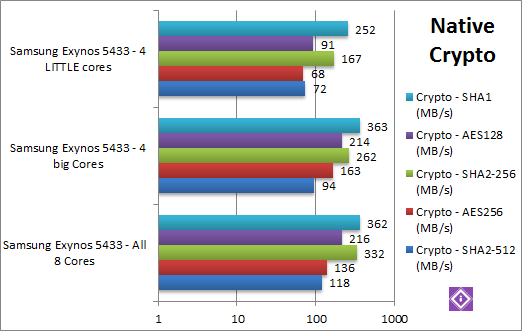 |
|||||
 |
Crypto SHA2-512 (MB/s) | 118 Neon [+25% vs 4C] | 94 Neon [+31% vs 4c] | 72 Neon | Starting with this tough 64-bit Neon SIMD accelerated hashing algorithm, we see big cores 31% faster but all cores 25% faster still. Again, we would expect a little more from the big cores. |
|
Crypto AES-256 (MB/s) | 136 [-17% vs 4C] | 163 [+2.4x vs 4c] | 68 | In this non-SIMD workload, we see the big cores being an incredible 2.4x faster than the LITTLE cores – and finally using all cores is 17% slower than just using the big cores. Naturally all cores support AES HWA but only in ARMv8 mode. In x86 World we saw HT systems supporting AES HWA slower so this is not entirely a surprise. |
|
Crypto SHA2-256 (MB/s) | 332 Neon [+26% vs 4C] | 262 Neon [+57% vs 4c] | 167 Neon | Switching to a 32-bit Neon SIMD, we see the big cores 57% faster (more than clock difference) – but still using all cores is 26% faster. Again, all cores support SHA HWA but only in ARMv8 mode. |
|
Crypto AES-128 (GB/s) | 216 [+1% vs 4C] | 214 [+2.35x vs 4c] | 91 | Less rounds do seem to make a a bit dfference, big cores are again about 2.4x faster than the LITTLE cores but but using all cores is about the same. It seems the LITTLE cores just take bandwidth/power away from the big cores. |
|
Crypto SHA1 (GB/s) | 362 Neon [-1% vs 4C] | 363 Neon [+44% vs 4c] | 252 Neon | SHA1 is the “lightest” compute workload but here the big cores are 44% faster than their LITTLE brothers – and using all cores is 1% slower. |
| In streaming algorithms we finally see the big cores making a difference – they are over 2x (twice) as fast as the LITTLE cores – so using all cores is slower. If AES HWA or SHA HWA were available we’d likely see an even bigger difference. Just as in the x86 World with HT – hardware accelerated streaming algorithms need less threads and more bandwidth – here the little cores just get in the way. Unfortunately the 64-bit OS for the SoC will have to wait… indefinitely… | |||||
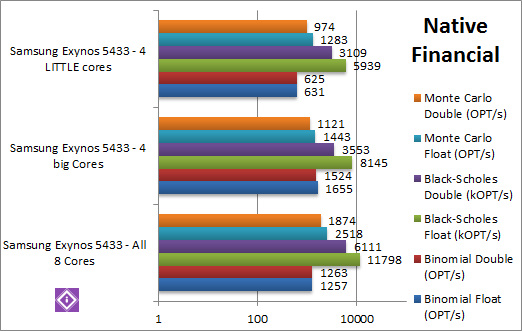 |
|||||
 |
Black-Scholes float/FP32 (MOPT/s) | 11.79 [+45% vs 4C] | 8.15 [+37% vs 4c] | 5.93 | As this algorithm does not use SIMD, the VFP power of the big cores makes only a 37% difference; thus using all cores is 45% faster still. |
|
Black-Scholes double/FP64 (MOPT/s) | 6.11 [+72% vs 4C] | 3.55 [+14% vs 4c] | 3.1 | Switching over to FP64 code, the big cores have a tough time, they’re only 14% faster – while using all cores is a huge 72% faster. |
|
Binomial float/FP32 (kOPT/s) | 1.26 [-25% vs 4C] | 1.66 [+2.62x vs 4c] | 0.63 | Binomial uses thread shared data thus stresses the cache & memory system; here 4 big cores are clearly faster than all 8 by 25%; the big cores themselves are 2.6x times faster than the LITTLE ones. |
|
Binomial double/FP64 (kOPT/s) | 1.26 [-18% vs 4C] | 1.52 [+2.43x vs 4c] | 0.625 | Switching to FP64 code does not change things much, the big cores are 2.4x faster than the LITTLE ones and 18% faster than using all cores. More is not always better it seems. |
|
Monte-Carlo float/FP32 (kOPT/s) | 2.51 [+74% vs 4C] | 1.44 [+13% vs 4c] | 1.28 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches; somehow the big cores don’t work so well here, they are only 13% faster than the LITTLE ones – thus using all cres is 74% faster. More cores make the difference here. |
|
Monte-Carlo double/FP64 (kOPT/s) | 1.87 [+67% vs 4C] | 1.12 [+15% vs 4c] | 0.97 | And finally FP64 code does not make any difference, the big cores are just 15% faster with all cores being a huge 67% faster than them. |
| The financial tests generally favour the 8-core configuration, except the “tough” binomial test where the big cores are between 18-25% faster than using all the cores. Such read/modify/write algorithms cause bottlenecks in the cache/memory system where feeding 8 cores is a lot more difficult than just 4 and it shows. | |||||
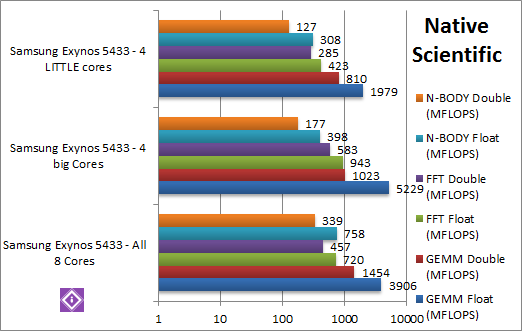 |
|||||
 |
SGEMM (MFLOPS) float/FP32 | 3906 Neon [-25% vs 4C] | 5229 Neon [+2.64x vs 4c] | 1979 Neon | In this complex Neon SIMD workload we would expect the 5433 to lead, and it does but only by 9%. It seems again that memory accesses slow it down and some of the 8 threads may be starving. |
|
DGEMM (MFLOPS) double/FP64 | 1454 [+42% vs 4C] | 1023 [+26% vs 4c] | 810 | Neon does not support FP64 in ARMv7 mode, so the VFPs do all te work: the big ores are now just 26% faster with all the cores being 42% faster still. In ARMv8 mode it is likely the results would mirror the SGEMM ones. |
|
SFFT (GFLOPS) float/FP32 | 720 Neon [-24% vs 4C] | 943 Neon [+2.22x vs 4c] | 423 Neon | FFT also uses SIMD and thus Neon but stresses the memory sub-system more: we see similar results to SGEMM with the big cores being 2.22x faster and using all cores is 24% slower. Again it is likely that the memory sub-system cannot keep up with 8 cores. |
|
DFFT (GFLOPS) double/FP64 | 457 [-22% vs 4C] | 583 [+2.04x vs 4c] | 285 | With FP64 VFP code, we would expect a similar result to DGEMM – but instead we see a re-run of SFFT: big cores are over 2x faster than LITTLE cores with all 8 cores being 22% slower. Using Neon is not likely to change the results based on SFFT. |
|
SNBODY (GFLOPS) float/FP32 | 758 Neon [+90% vs 4C] | 398 Neon [+29% vs 4c] | 308 Neon | N-Body simulation is SIMD heavy and has many memory accesses to shared data, but read-only – so here using all 8 cores is 90% faster than just the 4 big cores that are just 29% faster than LITTLE cores. It is possible some throttling is happening here though. |
|
DNBODY (GFLOPS) double/FP64 | 339 [+91% vs 4C] | 177 [+39% vs 4c] | 127 | With FP64 VFP code we see similar results, using all cores is much faster (91%) but big cores are 39% faster than LITTLE ones. |
| With complex SIMD (Neon) FP32 code we see the power of the 4 big cores – over 2-2.6x faster than the little ones; using all 8 cores is actually slower, with the little cores just sucking bandwidth for nothing. Clearly more is not always better. | |||||
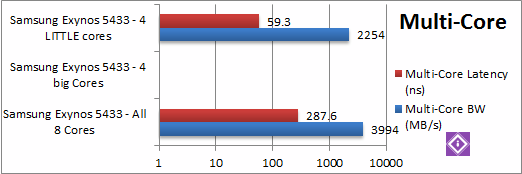 |
|||||
 |
Inter-Core Bandwidth (MB/s) | 3994 (but ~500/core) | 2254 (but ~563/core) | ||
 |
Inter-Core Latency (ns) | 287 | 59 | ||
| The bandwidth per core is similar whether bit or LITTLE – thus all 8 cores have higher total/aggregate bandwidth. However inter-core latency is much higher when all cores are used thus threads that share data should try to run on the same type of core – be tha big or LITTLE. | |||||
Despite the lack of algorithm optimisations – to deal with HMP and thus “asymmetric workload allocation” – it is good to see that using all 8 cores is *generally* faster. In honesty we’re a bit surprised. It seems that the OS scheduler does pretty well all by itself and most workloads should perform pretty well and things can “only get better” 😉
True, heavy SIMD (Neon) workloads allow the big cores to show their power – they are over 2-2.6x faster (more than just clock difference at 46%) – and here using just the big cores is faster between 17-25%. Some of this may be due to the additional stress on the memory sub-system which now has to feed 8 cores not 4, with the bandwidth per core decreasing.
The problem would be bigger in 64-bit ARMv8 mode where FP64 code could finally use SIMD/Neon – while crypto algorithms (AES, SHA) are hardware accelerated and thus bandwidth would count more than compute power. Again this is similar to what we saw in x86 World with HT systems.
However, again just relying on the scheduler to “wake” and migrate the threads on the big cores may be enough – no further scheduler may be needed.
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
Despite our reservations – the Exynos 5433 performs better than expected – with all its 8-cores enabled/used, with the LITTLE Cortex A53 cores punching way above their weight. The big Cortex A57 cores do show their power especially in SIMD Neon code where they are far faster (2-2.6x). Unfortunately in ARMv7 32-bit mode they are a bit hamstrung – unable to use FP64 Neon code as well as crypto (AES, SHA) hardware acceleration – a pity. Here a 64-bit ARMv8 Android version would likely be much faster but does not look like it will happen.
ARM has assumed they don’t need “legacy” ARMv7 code and everybody would just move to ARMv8: thus none of the new instructions are available in ARMv7 mode. Unlike Apple, Android makers don’t seem to rush to adopt an 64-bit Android and while simple Java-only apps would naturally not care – the huge number of apps using native code (though the NDK) just won’t run (similar to other platforms like x86) – making compatibility a nightmare.
Apps/libraries that use dynamic/asynchronous workload allocators are likely to perform even better, but even legacy/simple parallel versions (using static/fixed workload allocators) work just fine.
The proviso is that heavy SIMD/Neon compute algorithms (e.g. Binomial, S/DGEMM, S/DFFT, etc.) use only 4 threads – hopefully migrated by the scheduler to the big cores – and thus perform better. Unfortunately there don’t seem to be APIs to determine whether the CPU is HMP – thus detection is difficult but not impossible. Using “hard affinity” aka scheduling threads on the “right” cores does not seem to be needed – unlike in x86-World where early OSes did not deal with HT properly – it seems the ARM-World has learned a few things.
In the end, whatever the OS – the Cortex A5x cores are performing well and perhaps one day will get the chance to perform even better, but don’t bet on it 😉