What is AVX512?
AVX512 is a new SIMD instruction set operating on 512-bit registers that is the natural progression from FMA/AVX (256-bit registers). It was first introduced with Intel’ “Phi” co-processor (Intel’s answer to GPGPUs) and now a version of it is making its way to CPUs themselves.
Why is AVX512 important?
CPU performance has only marginally increased (5-10%) from one generation to the next, with power efficiency being the primary goal; with limited options (cannot increase clocks speeds, must reduce power, hard to improve execution efficiency, etc.) exploiting data level parallelism through SIMD is a relatively simple way to improve performance.
SIMD instructions have long been used to increase performance (since the introduction of MMX with the Pentium in 1997!) and their register width has been increasing steadily from 64-bit (MMX) to 128-bit (SSEx) to 256-bit (AVX/FMA) and now to 512-bit (AVX512) – thus processing more and more data simultaneously.
Unfortunately, software has to be specifically modified to support AVX512 (or at the very least re-compiled) but developers are generally used to this these days after the SSE to AVX transition.
SiSoftware has thus been updating its benchmarks to AVX512, though some need compiler support and will need to wait until Microsoft updates its Visual C++ compiler at some point.
What CPUs will support AVX512?
It was rumoured that the newly released “Skylake” Core consumer CPUs were going to support AVX512 – but they do not. The future “Skylake-E” Xeon “Purley” server/workstation CPUs are supposed to support it.
AVX512 is actually a set of multiple sets – with “Skylake-E” supporting F (foundation) and CD (conflict detection), BW (byte & word), DQ (double-word and quad-word) and VL (vector length extension) – and future “Canonlake-E” supporting IFMA (integer FMA), VBM (vector byte manipulation) and perhaps others.
It is disappointing that AVX512 is not enabled on consumer CPUs (Core) but it will eventually appear in future iterations; gamers/enthusiasts need to buy into the “extreme/Skylake-E” platform and business users getting “Xeon/Skylake-E” in their workstations.
What kind of performance improvement can we expect with AVX512?
The transition from SSE 128-bit to AVX/FMA/AVX2 256-bit has – eventually – resulted in 70-120% improvement, with compute intensive code that seldom access memory yielding the best improvement. Note that AVX executes at lower clock than “normal”/SSE code.
AVX512 not only doubles width (512-bit) but also number of registers (32 vs 16) thus we can hold 4x (four times) more data which may reduce cache/memory accesses by caching more data locally. But AVX512 code will again run at lower clock versus AVX/FMA.
In the next examples we project future gains through AVX512 for common algorithms as implemented in Sandra’s benchmarks and what they might mean to customers.
Can I test AVX512 performance with Sandra?
Yes, with the release of Sandra 2016 SP1 – you can now test AVX512 performance – naturally you need the required CPU. All the low-level benchmarks (below) have been ported to AVX512:
- Multi-Media (Fractal Generation) Benchmark: AVX512 F, BW, DQ supported now
- Cryptography (SHA Hashing) Benchmark: AVX512 BW, DQ supported now
- Memory & Cache Bandwidth Benchmarks: AVX512 F, DQ supported now
The following benchmarks require future compiler support (Microsoft VC++) and have not been released at this time:
- Financial Analysis (Black-Scholes, Binomial, Monte-Carlo): AVX512 F support coming soon
- Scientific Analysis (GEMM, FFT, N-Body): AVX512 F support coming soon
- Image Processing (Blur/Sharpen/Motion-Blur, Sobel, Median): AVX512 BW support coming soon
- .Net Vectorised (Fractal Generation): AVX512 support dependent on RyuJIT numerics libraries that need to be updated by Microsoft. No changes required.
Hardware Stats
We are comparing two released public CPUs with their projected next-gen counterparts supporting AVX512.
| Processor | Intel i7-6700K (Skylake) | Intel i7-77XX? (next-gen) | Intel i7-5820K (Haswell-E) | Intel i7-78XX? (Skylake-E) |
| Cores/Threads | 4C / 8T | 4C / 8T | 6C / 12T | 6C / 12T |
| Clock Speeds (MHz) Min-Max-Turbo | 800-4000-4200 | assumed same | 1200-3300-3600 | assumed same |
| Caches L1/L2/L3 | 4x 32kB, 4x 256kB, 8MB | assumed same | 6x 32kB, 6x 256kB, 15MB | assumed same |
| Power TDP Rating (W) | 91W | assumed same | 140W | assumed same |
| Instruction Set Support | AVX2, FMA3, AVX, etc. | AVX512 + AVX2, FMA3, AVX, etc. | AVX2, FMA3, AVX, etc. | AVX512 + AVX2, FMA3, AVX, etc. |
We do not expect major changes in future AVX512 supporting arch, especially with Skylake-E as Core Skylake is already out and the core specifications are known.
Multi-media (Fractal Generation) Benchmark
| Benchmark | Future Core-i7 (4C/8T AVX512) Projected | Core i7-6700K (4C/8T AVX2/FMA) | Core i7-6700K (4C/8T SSEx) | Future Core i7-E (6C/12T AVX512) Projected | Core i7-5820K (6C/12T AVX2/FMA) | Core i7-5820K (6C/12T SSEx)) | |
 |
|||||||
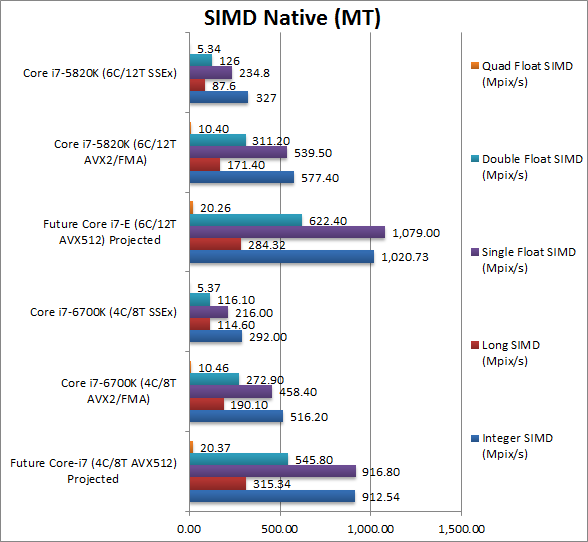
| Integer SIMD (Mpix/s) | 912.5 [+76% over AVX] | 516.2 [+76% over SSE] | 292 | 1020.7 [+76% over AVX] | 577.4 [+76% over SSE] | 327 | |
| We see around 76% improvement from AVX2 vs. SSE, thus we assume we’ll see something similar moving to AVX512 (~80%). | |||||||
| Long SIMD (Mpix/s) | 315.3 [+66% over AVX] | 190.1 [+66% over SSE] | 114.6 | 284.3 [+66% over AVX] | 171.4 [+66% over SSE] | 87.6 | |
| We see around 66% improvement from AVX2 vs. SSE, but due to the new instructions we may see better AVX512 gains. | |||||||
| Single Float SIMD (Mpix/s) | 916.8 [+2x over AVX] | 458.4 [+2.12x over SSE] | 216 | 1079 [+2x over AVX] | 539.5 [+2.12x over SSE] | 234.8 | |
| We saw over 2x improvement from AVX/FMA over SSE so while we may not see such a large improvement with AVX512, we may still get 100%. | |||||||
| Double Float SIMD (Mpix/s) | 545.8 [+2x over AVX] | 272.9 [+2.35x over SSE] | 116.1 | 622.4 [+2x over AVX] | 311.2 [+2.35x over SSE] | 126 | |
| We see even better improvement from AVX to SSE here (2.35x) so hopefully we’ll get 2x moving to AVX512. | |||||||
| Quad Float SIMD (Mpix/s) | 20.3 [+94% over AVX] | 10.5 [+94% over SSE] | 5.4 | 622.4 [+94% over AVX] | 311.2 [+94% over SSE] | 126 | |
| Emulating fp128 is hard work but even then AVX is 94% faster than SSE and thus we’d expect AVX512 to be almost 2x faster still. | |||||||
| Despite some being disappointed by arch-to-arch performance improvement, the Skylake 4C (i7-6700K) already goes toe-to-toe with Haswell-E 6C (i7-5820K), but with AVX512 support Skylake-E 6C/8C is projected to comprehensively outperform it.
AVX512 will also allow Skylake-E to narrow the gap between it and current GPGPUs with multi-CPU Xeon systems able to “do without” GPGPUs – well except perhaps a “Phi” or two? |
|||||||
 |
|||||||
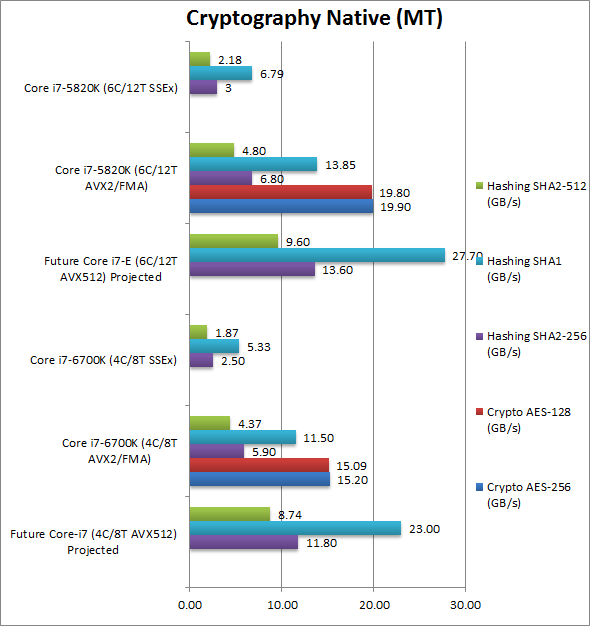
| Hashing SHA2-256 (GB/s) | 11.80 [+2x over AVX] | 5.90 [+2.36x over SSE] | 2.50 | 13.60 [+2x over AVX] | 6.80 [+2.26x over SSE] | 3 | |
| We see a large 2.26-2.36x improvement of AVX2 vs. SSE, thus we expect about 2x increase with AVX512 still. | |||||||
| Hashing SHA1 (GB/s) | 23 [+2x over AVX] | 11.5 [+2.16x over SSE] | 5.33 | 27.70 [+2x over AVX] | 13.85 [+2.04x over SSE] | 6.79 | |
| Even with SHA1 we see a good 2.04-2.16x improvement of AVX2 vs. SSE, thus AVX512 should again double performance though we may be limited by memory bandwidth. | |||||||
| Hashing SHA2-512 (GB/s) | 8.74 [+2x over AVX] | 4.37 [+2.33x over SSE] | 1.87 | 9.60 [+2x over AVX] | 4.80 [+2.20x over SSE] | 2.18 | |
| Switching to 64-bit integer SHA512 we see the best improvement yet of AVX2 vs SSE (2.2-2.33x) with AVX512 likely to improve by 2x yet again. | |||||||
| With hashing we see even better results than even fractal generation, with AVX2 improving over 2x over SSE – and AVX512 will thus improve by at least 100% – if anything it is likely we will hit memory bandwidth limitations. | |||||||
 |
|||||||
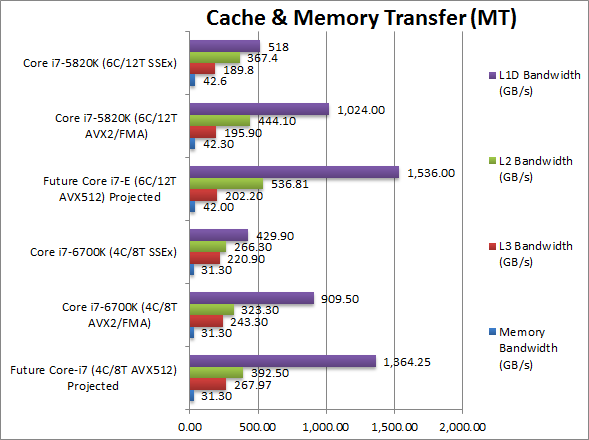
| Memory Bandwidth (GB/s) | ~31.30 | 31.30 [0%] | 31.30 | ~42.00 [0%] | 42.30 [-1%] | 42.6 | |
| Even with DDR4 the memory sub-system hasn’t changed much and despite 512-bit transfers with AVX512 there is really no performance delta in streaming data to/from memory. | |||||||
| L3 Bandwidth (GB/s) | ~267.97 [+10%] | 243.30 [+10%] | 220.90 | ~202.20 [+3%] | 195.90 [+3%] | 189.8 | |
| As we move up the cache hierarchy, the L3 already shows a 10% bandwidth improvement using AVX2/FMA vs. SSE and AVX512 improving performance further. | |||||||
| L2 Bandwidth (GB/s) | ~392.50 [+21%] | 323.30 [+21%] | 266.30 | ~536.81 [+20%] | 444.10 [+20%] | 367.4 | |
| As we expected, L2 bandwidth improves ~20% with AVX2/FMA and likely to improve further. | |||||||
| L1D Bandwidth (GB/s) | ~1,364.25 [+50%] | 909.50 [+2.11x] | 429.90 | ~1,536.00 [+50%] | 1,024.00 [+2x] | 518 | |
| Skylake has widened the data access ports (just like Haswell before it), thus 512-bit AVX512 transfers show the best improvement yet, 40-50%! | |||||||
| AVX512 does help take advantage of the widened data ports in Skylake and future arch, with L1D cache showing the best bandwidth improvement just like Haswell before it (with AVX2).
Memory bandwidth is still limited by DDR4 speeds but faster modules are coming out all the time but this time their clocks are JEDEC ratified. |
|||||||
We will update the article with future (projected) results once more benchmarks are converted to AVX512 – once compiler support is released – but even so far we see excellent performance improvement.
Until then, those of you with access to AVX512 supporting hardware can download Sandra 2016 SP1 and test away!
Pingback: SP1 for SiSoftware Sandra Released! | SiSoftware