What is “Ryzen”?
“Ryzen” (code-name ZP aka “Zeppelin”) is the latest generation CPU from AMD (2017) replacing the previous “Vishera”/”Bulldozer” designs for desktop and server platforms. An APU version with an integrated (GP)GPU will be launched later (Ryzen2) and likely include a few improvements as well.
This is the “make or break” CPU for AMD and thus greatly improve performance, including much higher IPC (instructions per clock), higher sustained clocks, better Turbo performance and “proper” SMT (simultaneous multi-threading). Thus there are no longer “core modules” but proper “cores with 2 SMT threads” so an “eight-core CPU” really sports 8C/16T and not 4M/8T.
No new chipsets have been introduced – thus Ryzen should work with current 300-series chipsets (e.g. X370, B350, A320) with a BIOS/firmware update – making it a great upgrade.
In this article we test CPU Cache and Memory performance; please see our other articles on:
Hardware Specifications
We are comparing the 2nd-from-the-top Ryzen (1700X) with previous generation competing architectures (i7 Skylake 4C and i7 Haswell-E 6C) with a view to upgrading to a mid-range high performance design. Another article compares the top-of-the-range Ryzen (1800X) with the latest generation competing architectures (i7 Kabylake 4C and i7 Broadwell-E 8C) with a view to upgrading to the top-of-the-range design.
| CPU Specifications | AMD Ryzen 1700X |
Intel 6700K (Skylake) |
Intel 5820K (Haswell-E) | Comments | |
| TLB 4kB pages |
64 full-way
1536 8-way |
64 8-way
1536 6-way |
64 4-way
1024 8-way |
Ryzen has comparatively ‘better’ TLBs than even SKL while the 2-generation older HSW-E is showing its age. | |
| TLB 2MB pages |
64 full-way
1536 2-way |
8 full-way
1536 6-way |
8 full-way
1024 8-way |
Nothing much changes for 2MB pages with Ryzen leading the pack again. | |
| Memory Controller Speed (MHz) | 600-1200 | 800-4000 | 1200-4000 | Ryzen’s memory controller runs at memory clock (MCLK) base rate thus depends on memory installed. Intel’s UNC (uncore) runs between min and max CPU clock thus perhaps faster. | |
| Memory Speed (Mhz) Max |
2400 / 2666 | 2533 / 2400 | 2133 / 2133 | Ryzen supports up to 2666MHz memory but is happier running at 2400; SKL supports only up to 2400 officially but happily runs at 2533MHz; old HSW-E can only do 2133MHz but with 4 memory channels. | |
| Memory Channels / Width |
2 / 128-bit | 2 / 128-bit | 4 / 256-bit | HSW-E leads with 4 memory channels of DDR4 providing massive bandwidth for its cores; however both Ryzen and Skylake can use faster DDR4 memory reducing this problem somewhat. | |
| Memory Timing (clocks) |
14-16-16-32 7-54-18-9 2T | 16-18-18-36 5-54-21-10 2T | 14-15-15-36 4-51-16-3 2T | Despite faster memory Ryzen can run lower timings than HSW-E and SKL reducing its overall latencies. | |
Core Topology and Testing
As discussed in the previous article, cores on Ryzen are grouped in blocks (CCX or compute units) each with its own 8MB L3 cache – but connected via a 256-bit bus running at memory controller clock. This is better than older designs like Intel Core 2 Quad or Pentium D which were effectively 2 CPU dies on the same socket – but not as good as a unified design where all cores are part of the same unit.
Running algorithms that require data to be shared between threads – e.g. producer/consumer – scheduling those threads on the same CCX would ensure lower latencies and higher bandwidth which we will test with presently.
We have thus modified Sandra’s ‘CPU Multi-Core Efficiency Benchmark‘ to report the latencies of each producer/consumer unit combination (e.g. same core, same CCX, different CCX) as well as providing different matching algorithms when selecting the producer/consumer units: best match (lowest latency), worst match (highest latency) thus allowing us to test inter-CCX bandwidth also. We hope users and reviewers alike will find the new features useful!
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (AVX2, AVX, etc.). Ryzen supports all modern instruction sets including AVX2, FMA3 and even more.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and Intel drivers. Turbo / Dynamic Overclocking was enabled on both configurations.
| Native Benchmarks | Ryzen 1700X 8C/16T (MT) 8C/8T (MC) |
i7-6700K 4C/8T (MT) 4C/4T (MC) |
i7-5820K 6C/12T (MT) 6C/6T (MC) |
Comments | |
 |
|||||
 |
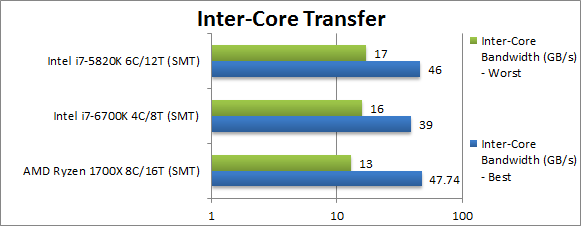
Total Inter-Core Bandwidth – Best (GB/s) | 47.7 [+3%] | 39 | 46 | With 8 cores (and thus 8 pairs) Ryzen’s bandwidth matches the 6-core HSW-E and is 22% higher than SKL thus decent. |
|
Total Inter-Core Bandwidth – Worst (GB/s) | 13 [-23%] | 16 | 17 | In worst-case pairs on Ryzen must go across CCXes while on Intel CPUs they can still use L3 cache to exchange data – thus it ends up about 23% slower than both SKL and HSW-E but it is not catastrophic. |
 |
|||||
|
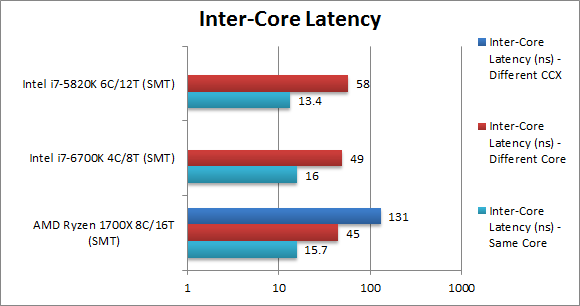
Inter-Unit Latency – Same Core (ns) | 15.7 [-2%] | 16 | 13.4 | Within the same core (sharing L1D/L2) , Ryzen inter-unit is ~15ns comparative with both Intel’s CPUs. |
|
Inter-Unit Latency – Same Compute Unit (ns) | 45 [-8%] | 49 | 58 | Within the same compute unit (sharing L3), the latency is ~45ns a bit lower than either SKL and much lower than HSW-E thus so far so good! |
|
Inter-Unit Latency – Different Compute Unit (ns) | 131 [+3x] | – | – | Going inter-CCX increases the latency by 3 times to about 130ns thus if the threads are not properly scheduled you can end up with far higher latency and far less bandwidth. |
| The multiple CCX design does present some challenges to programmers and threads will have to be carefully scheduled to avoid inter-CCX transfers where possible. As the CCX link runs at UMC speed using faster memory increases link bandwidth and decreases its latency which helps no end. | |||||
 |
|||||
 |
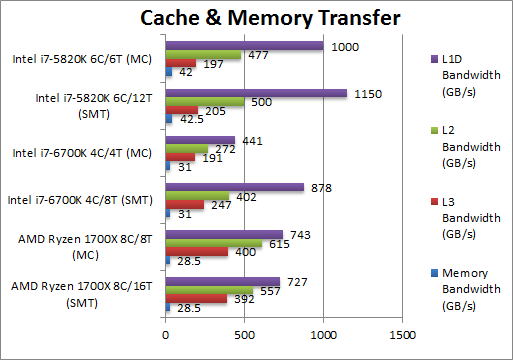
Aggregated L1D Bandwidth (GB/s) | 727 [-17%] | 878 | 1150 | SKL has 512-bit data ports so Ryzen cannot compete with that but it does well against BRW-E. |
|
Aggregated L2 Bandwidth (GB/s) | 557 [+38%] | 402 | 500 | The 8 L2 caches have competitive bandwidth thus overall Ryzen has though BRW-E does well. |
|
Aggregated L3 Bandwidth (GB/s) | 392 [+58%] | 247 | 205 | Even spread over the 2 CCXes the L3 caches have huge aggregated bandwidth – over over SKL. |
|
Aggregated Memory (GB/s) | 28.5 [-8%] | 31 | 42.5 | Running at lower memory speed Ryzen cannot beat SKL nor BRW-E with its 4 memory controllers but has higher comparative efficiency. |
| The 8x L2 caches and 2x L3 caches have much higher aggregated latency than either Intel CPU while the memory controller is also more efficient though it cannot compete with 4-channel BRW-E. But its 8x L1D caches are not “wide enough” to compete with SKL’s widened data ports (again widened in HSW). This may be one reason SIMD performance is not as high with Ryzen and AMD may have to widen them going forward especially when adding AVX512 support. | |||||
 |
|||||
 |
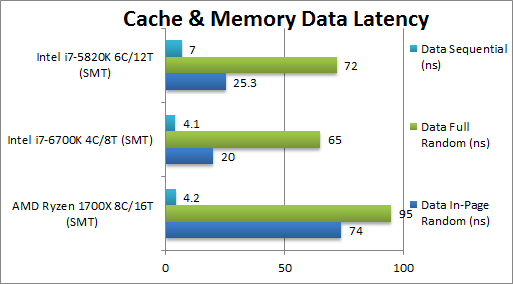
Data In-Page Random Latency (ns) | 74 [+2.9x] (4-17-36) | 20 (4-12-21) | 25.3 (4-12-26) | In-page latency is surprisingly large, almost 3x old SNB-E and ~4x SKL! Ryzen’s TLBs seem slow. L1 and L2 latencies are comparative (4 and 17 clk) but L3 latency is already ~50% higher than HSW and almost 2x SKL. |
|
Data Full Random Latency (ns) | 95 [+31%] (4-17-37) | 65 (4-12-34) | 72 (4-13-52) | Out-of-page latencies are ‘better’ with Ryzen ‘only’ ~30% slower than HSW-E and about 50% slower than SKL. Again L1 is and L2 are fine (4 and 17 clk) and L3 is comparative to SKL (37 vs 34 clk) while old HSW-E trails (52 clk)! |
|
Data Sequential Latency (ns) | 4.2 [+1%] (4-7-7) | 4.1 (4-12-13) | 7 (4-12-13) | Ryzen’s prefetchers are working well with sequential access pattern latency at ~4ns matching SKL and much better than old HSW-E. |
| We finally discover an issue – Ryzen’s memory latencies (in-page) are very high compared to the competition – TLB issue? Fortunately sequential and out-of-page performance is fine so perhaps its memory prefetchers can alleviate the problem somewhat but it is something that will need to be addressed | |||||
 |
|||||
|
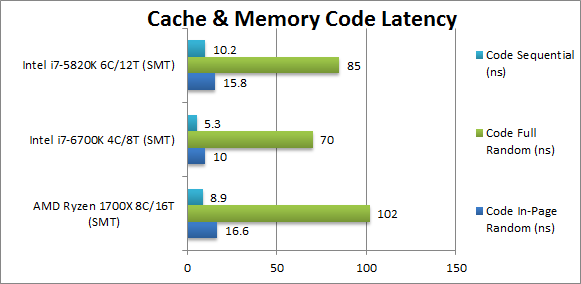
Code In-Page Random Latency (ns) | 16.6 [+5%] (4-9-25) | 10 (4-11-21) | 15.8 (3-20-29) | With code we don’t see the same problem – with in-page latency matching HSW-E, though still about 50% higher than SKL. The twice as large (64kB) L1I cache seems to have the same (4ckl) latency as SKL’s. No issues with L2 nor L3 latencies either. |
|
Code Full Random Latency (ns) | 102 [+20%] (4-13-49) | 70 (4-11-47) | 85 (3-20-58) | Out-of-page latency is a bit higher than both Intel CPUs, ~50% higher than SKL but nothing as bad as we’ve seen with data. |
|
Code Sequential Latency (ns) | 8.9 [-12%] (4-9-18) | 5.3 (4-9-20) | 10.2 (3-8-16) | Ryzen’s prefetchers are working well with sequential access pattern latency at ~9ns comparative to HSW-E but again about ~67% higher than SKL. |
| While code access latencies are higher than the new SKL – they are comparative with the older HSW-E and nowhere near as bad as that we’ve seen with data. Even the twice as large L1I (L1 instruction cache) behaves itself with 4clk latency similar to Intel’s L1I smaller versions. It is thus a mystery with data is affected but not code. | |||||
| Memory Update Transactional (MTPS) | 4.23 [-39%] | 32.4 HLE | 7 | SKL is in a World of its own due to support for HLE/RTM but Ryzen is still about 40% slower than HSW-E with just 6 cores. | |
| Memory Update Record Only (MTPS) | 4.19 [-23%] | 25.4 HLE | 5.47 | With only record updates the difference drops to about 20% but again HLE shows its power for transaction processing. | |
| Without HLE/RTM Ryzen is not going to win against Intel’s latest – but then again HLE/RTM are disabled in all but the very top-end CPUs – not to mention killed in previous HSW and BRW architectures so it is not a big problem. But if future models were to enable it, Intel will have a big problem on its hands… | |||||
Ryzen’s core, memory and cache bandwidths are great, in many cases much higher than its Intel rivals partly due to more cores and more caches (8 vs 6 or 4); overall latencies are also fine for caches and memory – except the crucial ‘in-page random access’ data latencies which are far higher – about 3 times – TLB issues? We’ve been here before with Bulldozer which could not be easily fixed – but if AMD does manage it this time Ryzen’s performance will literally fly!
Still, despite this issue we’ve seen in the previous article that Ryzen’s CPU performance is very strong thus it may not be such a big problem.
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
Ryzen’s memory performance is not the clean-sweep we’ve seen in CPU testing but it is competitive with Intel’s designs, especially the older HSW (and thus BRW) cores while the newer SKL (and thus KBL) cores sporting improved caches and TLBs which are hard for Ryzen to beat. Still it’s nothing to be worried about and perhaps AMD will be able improve things further with microcode/firmware updates if not new steppings and models (e.g. the APU model 10).
Overall we’d still recommend Ryzen over Intel CPUs unless you want absolutely tried and tested design which have already been patched by microcode and firmware/BIOS updates. The platform has a bright future with more CPUs destined to use the AM4 socket while both 1551 (SKL/KBL) and 2011 (HSW-E/BRW-E) platforms due to be replaced again with no future upgrades.
Pingback: AMD Ryzen Review and Benchmarks – CPU – SiSoftware