What is “Ryzen”?
“Ryzen” (code-name ZP aka “Zeppelin”) is the latest generation CPU from AMD (2017) replacing the previous “Vishera”/”Bulldozer” designs for desktop and server platforms. An APU version with an integrated (GP)GPU will be launched later (Ryzen2) and likely include a few improvements as well.
This is the “make or break” CPU for AMD and thus greatly improve performance, including much higher IPC (instructions per clock), higher sustained clocks, better Turbo performance and “proper” SMT (simultaneous multi-threading). Thus there are no longer “core modules” but proper “cores with 2 SMT threads” so an “eight-core CPU” really sports 8C/16T and not 4M/8T.
No new chipsets have been introduced – thus Ryzen should work with current 300-series chipsets (e.g. X370, B350, A320) with a BIOS/firmware update – making it a great upgrade.
In this article we test CPU core performance; please see our other articles on:
Hardware Specifications
We are comparing the 2nd-from-the-top Ryzen (1700X) with previous generation competing architectures (i7 Skylake 4C and i7 Haswell-E 6C) with a view to upgrading to a mid-range high performance design.
Another article compares the top-of-the-range Ryzen (1800X) with the latest generation competing architectures (i7 Kabylake 4C and i7 Broadwell-E 8C) with a view to upgrading to the top-of-the-range design.
| CPU Specifications | AMD Ryzen 1700X |
Intel 6700K (Skylake) |
Intel 5820K (Haswell-E) | Comments | |
| Cores (CU) / Threads (SP) | 8C / 16T | 4C / 8T | 6C / 12T | Ryzen has the most cores and threads – so it will be down to IPC and clock speeds. But if it’s threads you want Ryzen delivers. | |
| Speed (Min / Max / Turbo) | 2.2-3.4-3.9GHz (22x-34x-39x) | 0.8-4.0-4.2GHz (8x-40x-42x) | 1.2-3.3-4.0GHz (12x-33x-40x) | SKL has the highest rated speed @4GHz but all three have comparative Turbo clocks thus depends on how long they can sustain it. | |
| Power (TDP) | 95W | 91W | 140W | Ryzen has comparative TDP to SKL while HSW-E almost 50% higher. | |
| L1D / L1I Caches | 8x 32kB 8-way / 8x 64kB 8-way | 4x 32kB 8-way / 4x 32kB 8-way | 6x 32kB 8-way / 6x 32kB 2-way | Ryzen instruction cache is 2x the data cache a somewhat strange decision; all caches are 8-way except the HSW-E’s L1I. | |
| L2 Caches | 8x 512kB 8-way | 4x 256kB 8-way | 6x 256kB 8-way | Ryzen L2 is 2x as big as either Intel CPU which should help quite a bit though still 8-way | |
| L3 Caches | 2x 8MB 16-way | 8MB 16-way | 15MB 20-way | With 2x as many cores/threads, Ryzen has 2 8MB caches one for each CCX. | |
Thread Scheduling and Windows
Ryzen’s topology (4 cores in 2 CCXes (compute clusters)) makes it akin to the old Core 2 Quad or Pentium D (2 dies onto 1 socket) effectively a SMP (dual CPU) system on a single socket. Windows has always tended to migrate running threads from unit to unit in order to equalise thermal dissipation though Windows 10/Server 2016 have increased the ‘stickiness’ of threads to units.
As the Windows’ scheduler is inter-twined with the power management system, under ‘Balanced‘ and other power saving profiles – unused cores are ‘parked’ (aka powered down) which affects which cores are available for scheduling. AMD has recommended ‘High Performance‘ profile as well as initially claiming the Windows’ scheduler is not ‘Ryzen-aware’ before retracting the statement.
However, there does seem to be a problem as in Sandra tests when using less than the total 16 threads (e.g. MC test with 8 threads) in tests where Sandra does not hard schedule threads based on its own scheduler (e.g. .Net, Java benchmarks) the scheduling does not appear optimal:
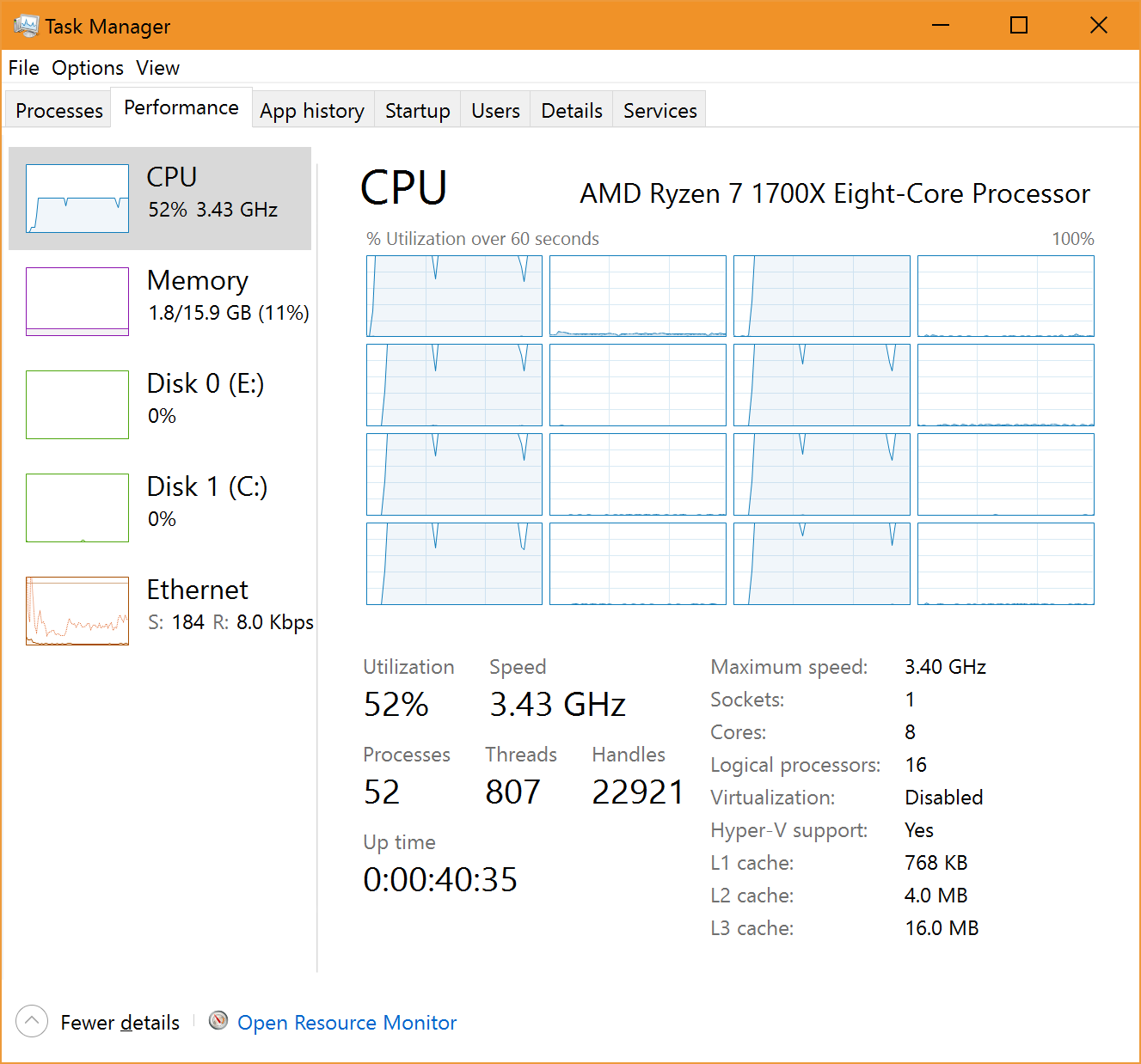 |
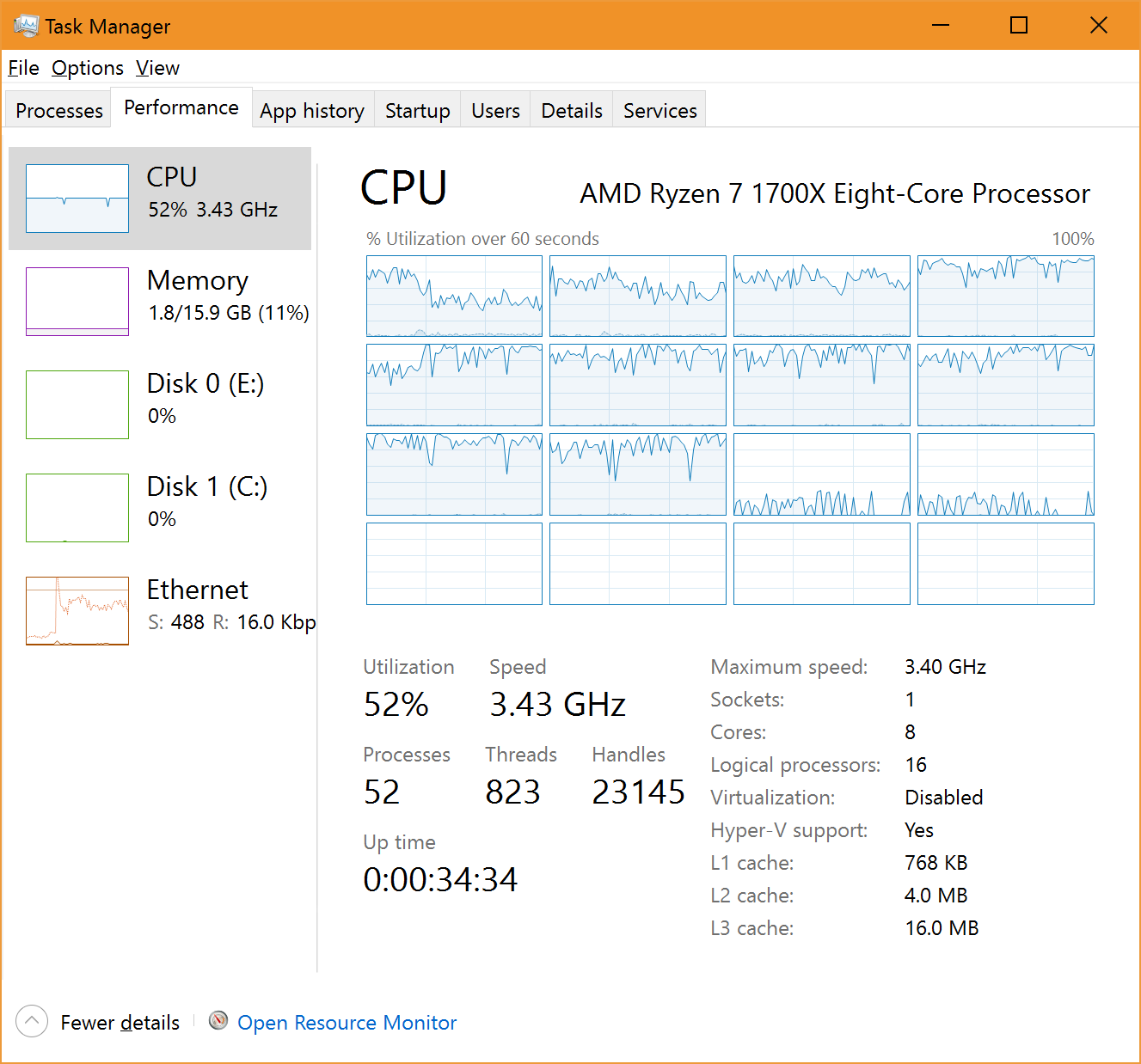 |
| Ryzen Hard Affinity (e.g. Native) | Ryzen No Affinity (e.g. Java/.Net) |
While in the left image we see Sandra at work assigning the 8 threads on the 8 different cores – with 100% utilisation on those units and almost nothing on the other 8 – on the right image we see 10 units (!) used, 4 not used at all but still 50% utilisation.
This does not seem to happen on Intel hardware – even SMP systems – thus it may be something to be adjusted in future Windows versions.
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (AVX2, AVX, etc.). Ryzen supports all modern instruction sets including AVX2, FMA3 and even more like SHA HWA (supported by Intel’s Atom only) but has dropped all AMD’s variations like FMA4 and XOP likely due to low usage.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and Intel drivers. Turbo / Dynamic Overclocking was enabled on both configurations.
| Native Benchmarks | Ryzen 1700X 8C/16T (MT) 8C/8T (MC) |
i7-6700K 4C/8T (MT) 4C/4T (MC) |
i7-5820K 6C/12T (MT) 6C/6T (MC) |
Comments | |
 |
|||||
 |
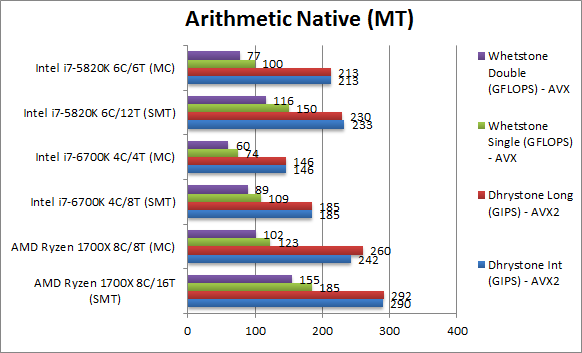
Native Dhrystone Integer (GIPS) | 290 [+24%] | 242 [+13%] AVX2 | 185 | 146 | 233 | 213 | Right off the bat Ryzen beats both Intel CPUs in both MT and MC tests with SMT providing a good gain (hard scheduled of course). |
|
Native Dhrystone Long (GIPS) | 292 [+27%] | 260 [+22%] AVX2 | 185 | 146 | 230 | 213 | With a 64-bit integet workload nothing much changes, Ryzen still beats both in both tests, 27% faster than HSW-E! AMD has ri-sen from the ashes like the Phoenix! |
|
Native FP32 (Float) Whetstone (GFLOPS) | 185 [+23%] | 123 [+23%] AVX/FMA | 109 | 74 | 150 | 100 | Even in this floating-point test, Ryzen beats both again by a similar margin, 23% better than HSW-E. What performance for the money! |
|
Native FP64 (Double) Whetstone (GFLOPS) | 155 [+33%] | 102 [+32%] AVX/FMA | 89 | 60 | 116 | 77 | With FP64 the winning streak continues, with the difference increasing to 33% over HSW-E a huge gain. |
| From integer workloads in Dhyrstone to floating-point workloads in Whestone Ryzen rules the roost blowing both SKL and HSW-E away being between 23-33% faster, with or without SMT. SMT does yield bigger gain than on Intel’s designs also. | |||||
 |
|||||
 |
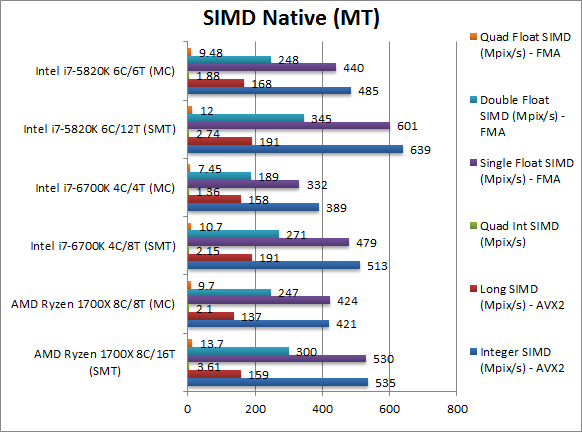
Native Integer (Int32) Multi-Media (Mpix/s) | 535 [-16%] | 421 [-13%] AVX2 | 513 | 389 | 639 | 485 | In this vectorised AVX2 integer test Ryzen just overtakes SKL but cannot beat HSW-E and is just 16% slower; still it is a good result but it shows Intel’s SIMD units are really strong with AMD’s 8 cores matching Intel’s 4 cores. |
|
Native Long (Int64) Multi-Media (Mpix/s) | 159 [-16%] | 137 [-18%] AVX2 | 191 | 158 | 191 | 168 | With a 64-bit AVX2 integer vectorised workload again Ryzen is unable to beat either Intel CPU being slower by a similar margin -16%. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 3.61 [+30%] | 2.1 [+11%] | 2.15 | 1.36 | 2.74 | 1.88 | This is a tough test using Long integers to emulate Int128 without SIMD and here Ryzen comes back on top being 30% faster similar to what we saw in Dhrystone. |
|
Native Float/FP32 Multi-Media (Mpix/s) | 530 [-11%] | 424 [-4%] FMA | 479 | 332 | 601 | 440 | In this floating-point AVX/FMA vectorised test we see again the power of Intel’s SIMD units, with Ryzen being only 11% slower than HSW-E but beating SKL. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 300 [-13%] | 247 [=] FMA | 271 | 189 | 345 | 248 | Switching to FP64 SIMD code, again Ryzen cannot beat HSW-E but does beat SKL which should be sufficient. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 13.7 [+14%] | 9.7 [+2%] FMA | 10.7 | 7.5 | 12 | 9.5 | In this heavy algorithm using FP64 to mantissa extend FP128 but not vectorised – Ryzen manages to beat both CPUs being 14% faster. So AVX2 or FMA code is not a problem. |
| In vectorised AVX2/FMA code we see Ryzen lose for the first time to Intel’s SIMD units but not by a large margin; in non-vectorised code as with Dhrystone and Whetstone Ryzen is again quite a bit faster than either Intel CPUs. Overall Ryzen would be the preferred choice unless number-crunching vectorised code. | |||||
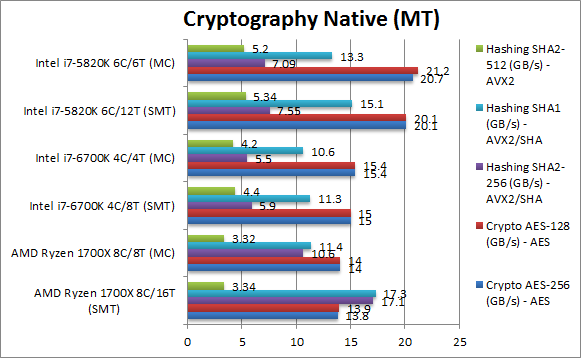 |
|||||
 |
Crypto AES-256 (GB/s) | 13.8 [-31%] | 14 [-32%] AES | 15 | 15.4 | 20 | 20.7 | All three CPUs support AES HWA – thus it is mainly a matter of memory bandwidth – and 2 memory channels is just not enough; with its 4 channels HSW-E is unbeatable for streaming tests. But Ryzen is only marginally slower than its counterpart SKL. |
|
Crypto AES-128 (GB/s) | 13.9 [-31%] | 14 [-33%] AES | 15 | 15.4 | 20.1 | 21.2 | What we saw with AES-256 just repeats with AES-128; Ryzen would need more memory channels to beat HSW-E but at least is marginally slower than SKL. |
|
Crypto SHA2-256 (GB/s) | 17.1 [+2.25x] | 10.6 [+49%] SHA | 5.9 | 5.5 AVX2 | 7.6 | 7.1 AVX2 | Ryzen’s secret weapon is revealed: by supporting SHA HWA it soundly beats both Intel CPUs even running multi-buffer vectorised AVX2 code – it’s 2.2x faster! Surprisingly disabling SMT (MC mode) reduces performance appreciably, not what would be expected. |
|
Crypto SHA1 (GB/s) | 17.3 [+14%] | 11.4 [-14%] SHA | 11.3 | 10.6 AVX2 | 15.1 | 13.3 AVX2 | Ryzen also accelerates the soon-to-be-defunct SHA1 but the AVX2 implementation is much less complex allowing SNB-E to come within a whisker of Ryzen and beat it in MC mode by a similar amount 14%. Still, much better to have SHA HWA than finding multiple buffers to process with AVX2. |
|
Crypto SHA2-512 (GB/s) | 3.34 [-37%] | 3.32 [-36%] AVX2 | 4.4 | 4.2 | 5.34 | 5.2 | SHA2-512 is not accelerated by SHA HWA (version 1) thus Ryzen has to use the same vectorised AVX2 code path where Intel’s SIMD units show their power again. |
| Ryzen’s secret crypto weapon is support for SHA HWA (which Intel only supports on Atom currently) which allows it to beat both Intel’s CPUs. For streaming algorithms like encrypt/decrypt it would probably benefit from more memory channels to feed all those cores. But overall it would still be the overall choice. | |||||
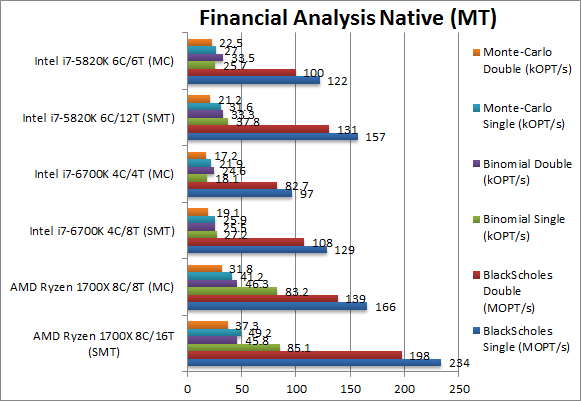 |
|||||
 |
Black-Scholes float/FP32 (MOPT/s) | 234 [+49] | 166 [+36%] | 129 | 97 | 157 | 122 | In this non-vectorised test we see Ryzen shine brightly again beating even SNB-E by 50% an incredible result. The choice for financial analysis? |
|
Black-Scholes double/FP64 (MOPT/s) | 198 [+51%] | 139 [+39%] | 108 | 83 | 131 | 100 | Switching to FP64 code, Ryzen still shines beating SNB-E by 50% again and totally demolishing SKL. So far so great! |
|
Binomial float/FP32 (kOPT/s) | 85.1 [+2.25x] | 83.2 [+3.23x] | 27.2 | 18.1 | 37.8 | 25.7 | Binomial uses thread shared data thus stresses the cache & memory system; we would expect Ryzen to falter here but nothing of the sort – it actually totally beats both Intel CPUs to dust – it’s 2.25 times faster than SNB-E! Even a 12 core SNB-E would not be sufficient. |
|
Binomial double/FP64 (kOPT/s) | 45.8 [+37%] | 46.3 [+38%] | 25.5 | 24.6 | 33.3 | 33.5 | With FP64 code the situation changes somewhat – with Ryzen only 37% faster than SNB-E; but it’s still an appreciable win. Very strange not to see Intel dominating this test. |
|
Monte-Carlo float/FP32 (kOPT/s) | 49.2 [+55%] | 41.2 [+52%] | 25.9 | 21.9 | 31.6 | 27 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches; Ryzen reigns supreme here also being 50% faster than even HSW-E. SKL is left in the dust. |
|
Monte-Carlo double/FP64 (kOPT/s) | 37.3 [+75%] | 31.8 [+41%] | 19.1 | 17.2 | 21.2 | 22.5 | Switching to FP64 Ryzen increases its dominance to 75% over SNB-E and destroying SKL completely. |
| Intel should be worried: across all financial tests, 64-bit or 32-bit floating-point workloads Ryzen reigns supreme beating even 6-core Haswell-E into dust by such a margin that even a 12-core HSW-E may not beat it. For financial workloads there is only one choice: Ryzen!!! Long live the new king! | |||||
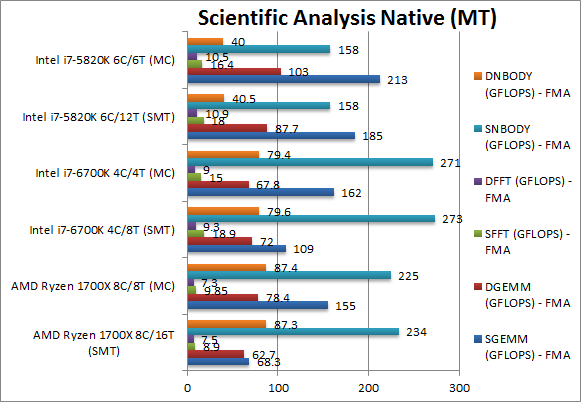 |
|||||
 |
SGEMM (GFLOPS) float/FP32 | 68.3 [-63%] | 155 [-27%] FMA | 109 | 162 | 185 | 213 | In this tough vectorised AVX2/FMA algorithm Ryzen falters and gets soundly beaten by both SKL and HSW-E. Again the powerful SIMD units of Intel’s CPUs allow them to finally beat it as we’ve seen in previous tests. It’s its Achille’s heel. |
|
DGEMM (GFLOPS) double/FP64 | 62.7 [-28%] | 78.4 [-23%] FMA | 72 | 67.8 | 87.7 | 103 | With FP64 vectorised code, the gap reduces with Ryzen just 28% slower than HSW-E and just a bit slower than SKL. Again vectorised SIMD code is problematic. |
|
SFFT (GFLOPS) float/FP32 | 8.9 [-50%] | 9.85 [-39%] FMA | 18.9 | 15 | 18 | 16.4 | FFT is also heavily vectorised (x4 AVX/FMA) but stresses the memory sub-system more; here Ryzen is again much slower than both SKL and HSW-E; for vectorised code it seems it needs 2x more SIMD units to match Intel. |
|
DFFT (GFLOPS) double/FP64 | 7.5 [-31%] | 7.3 [-30%] FMA | 9.3 | 9 | 10.9 | 10.5 | With FP64 code, Ryzen does improve (or Intel gets slower) only 30% slower than HSW-E and 15% slower than SKL. |
|
SNBODY (GFLOPS) float/FP32 | 234 [-15%] | 225 [-16%] FMA | 273 | 271 | 158 | 158 | N-Body simulation is vectorised but many memory accesses to shared data and here SKL seems to do unusually well beating Ryzen in 2nd place but only by 15%. Strangely HSW-E does badly in this test even with 6-cores. |
|
DNBODY (GFLOPS) double/FP64 | 87 [+10%] | 87 FMA | 79 | 79 | 40 | 40 | With FP64 code Ryzen improves beating its SKL rival by 10%; again SNB-E does pretty badly in this test. |
| With highly vectorised SIMD code Ryzen is again the loser but not by a lot; Intel has just one chance – highly vectorised SIMD algorithms that allow the powerful SIMD units to shine. Everything else is dominated by Ryzen. | |||||
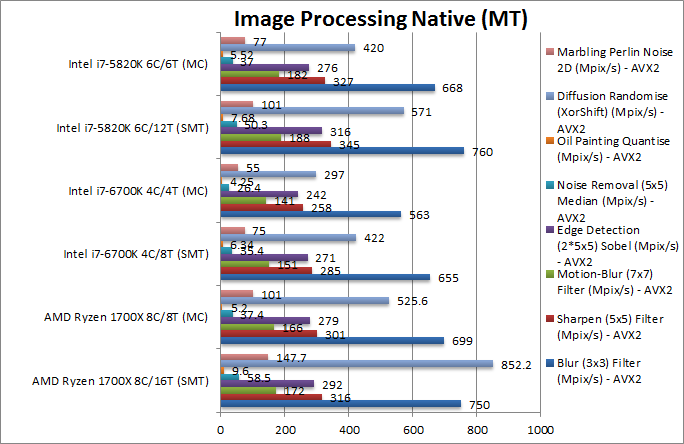 |
|||||
 |
Blur (3×3) Filter (MPix/s) | 750 [-1%] | 699 [+4%] AVX2 | 655 | 563 | 760 | 668 | In this vectorised integer AVX2 workload Ryzen ties with HSW-E, a good result considering we saw it lose in similar algorithms. |
|
Sharpen (5×5) Filter (MPix/s) | 316 [-8%] | 301 AVX2 | 285 | 258 | 345 | 327 | Same algorithm but more shared data used sees Ryzen now 8% slower than SNB-E but still beating SKL. |
|
Motion-Blur (7×7) Filter (MPix/s) | 172 [-8%] | 166 AVX2 | 151 | 141 | 188 | 182 | Again same algorithm but even more data shared does not change anything, Ryzen is again 8% slower. |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 292 [-7%] | 279 AVX2 | 271 | 242 | 316 | 276 | Different algorithm but still AVX2 vectorised workload sees Ryzen still about 7% slower than HSW-E but again still faster than SKL. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 58.5 [+16%] | 37.4 AVX2 | 35.4 | 26.4 | 50.3 | 37 | Still AVX2 vectorised code but here Ryzen manages to beat even SNB-E by 16%. Thus it is not a given it will lose in all such tests, it just depends. |
|
Oil Painting Quantise Filter (MPix/s) | 9.6 [+26%] | 5.2 | 6.3 | 4.2 | 7.6 | 5.5 | This test is not vectorised though it uses SIMD instructions and here Ryzen manages a 26% win even over SNB-E while leaving SKL in the dust. |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 852 [+50%] | 525 | 422 | 297 | 571 | 420 | Again in a non-vectorised test Ryzen just flies: it’s 2x faster than SKL and no less than 50% faster than SNB-E! Intel does not have its way all the time – unless the code is highly vectorised! |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 147 [+47%] | 101 | 75 | 55 | 101 | 77 | In this final non-vectorised test Ryzen really flies, it’s again 2x faster than SKL and almost 50% faster than SNB-E! Intel must be getting desperate for SIMD cectorised versions of algorithms by now… |
With all the modern instruction sets supported (AVX2, FMA, AES and SHA HWA) Ryzen does extremely well beating both Skylake 4C and even Haswell-E 6C in all workloads except highly vectorised SIMD code where the powerful Intel SIMD units can shine. Overall it would still be the choice for most workloads but SIMD number-crunching tasks which are somewhat specialised.
While we’ve not tested memory performance in this article, we see that in streaming tests (e.g. AES, SHA) more memory bandwidth to feed all the 16-threads would not go amiss but the difference may not justify the increased cost as we see with Intel 2011 platform and HSW-E.
Software VM (.Net/Java) Performance
We are testing arithmetic and vectorised performance of software virtual machines (SVM), i.e. Java and .Net. With operating systems – like Windows 10 – favouring SVM applications over “legacy” native, the performance of .Net CLR (and Java JVM) has become far more important.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest Intel drivers. .Net 4.6.x (RyuJit), Java 1.8.x. Turbo / Dynamic Overclocking was enabled on both configurations.
| VM Benchmarks | Ryzen 1700X 8C/16T (MT) 8C/8T (MC) |
i7-6700K 4C/8T (MT) 4C/4T (MC) |
i7-5820K 6C/12T (MT) 6C/6T (MC) |
Comments | ||
 |
||||||
 |
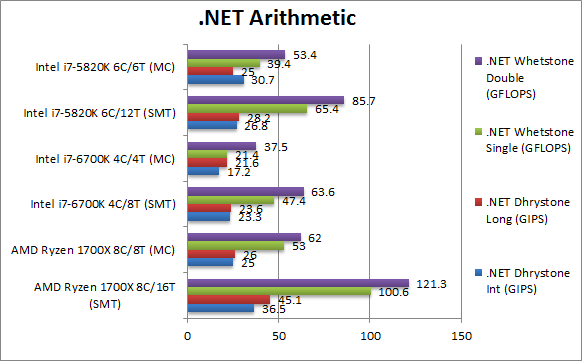
.Net Dhrystone Integer (GIPS) | 36.5 [+18%] | 25 | 23.3 | 17.2 | 30.7 | 26.8 | .Net CLR integer performance starts off very well with a 36% better performance even over HSW-E which admittedly does not do much better over SKL. | |
|
.Net Dhrystone Long (GIPS) | 45.1 [+60%] | 26 | 23.6 | 21.6 | 28.2 | 25 | Ryzen seems to greatly favour 64-bit integer workloads, here it is 60% faster than even HSW-E and over 2x faster than SKL. All CPUs perform better with 64-bit workloads. | |
|
.Net Whetstone float/FP32 (GFLOPS) | 100.6 [+53%] | 53 | 47.4 | 21.4 | 65.4 | 39.4 | Floating-Point CLR performance is pretty spectacular with Ryzen beating HSW-E by over 50% a pretty incredible result. Native or CLR code works just great on Ryzen. | |
|
.Net Whetstone double/FP64 (GFLOPS) | 121.3 [+41%] | 62 | 63.6 | 37.5 | 85.7 | 53.4 | FP64 performance is also great (CLR seems to promote FP32 to FP64 anyway) with Ryzen just over 40% faster than HSW-E. | |
| It’s pretty incredible, for .Net applications Ryzen is king – no point buying Intel’s 2011 platform – buy Ryzen! With more and more applications (apps?) running under the CLR, Ryzen has a bright future. | ||||||
 |
||||||
 |
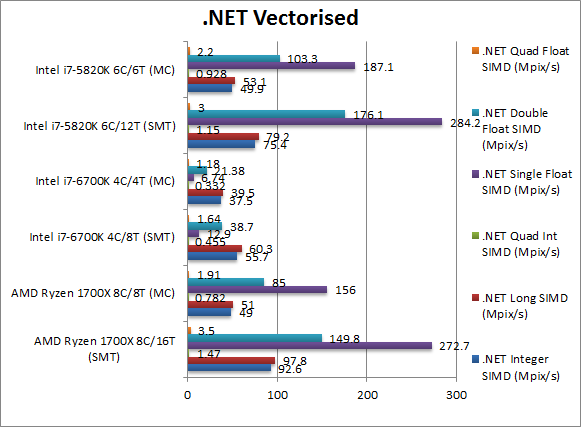
.Net Integer Vectorised/Multi-Media (MPix/s) | 92.6 [+22%] | 49 | 55.7 | 37.5 | 75.4 | 49.9 | Just as we saw with Dhrystone, this integer workload sees a 22% improvement for Ryzen. While RiuJit supports SIMD integer vectors the lack of bitfield instructions make it slower for our code; shame. | |
|
.Net Long Vectorised/Multi-Media (MPix/s) | 97.8 [+23%] | 51 | 60.3 | 39.5 | 79.2 | 53.1 | With 64-bit integer workload we see a similar story – Ryzen is 23% faster than even HSW-E. If only RyuJit SIMD would fix integer workloads too. | |
|
.Net Float/FP32 Vectorised/Multi-Media (MPix/s) | 272.7 [-4%] | 156 AVX | 12.9 | 6.74 | 284.2 | 187.1 | Here we make use of RyuJit’s support for SIMD vectors thus running AVX/FMA code; Intel strikes back through its SIMD units with Ryzen 4% slower than SNB-E. Still Intel usually wins these kinds of tests. | |
|
.Net Double/FP64 Vectorised/Multi-Media (MPix/s) | 149 [-15%] | 85 AVX | 38.7 | 21.38 | 176.1 | 103.3 | Switching to FP64 SIMD vector code – still running AVX/FMA – Ryzen loses again, this time by 15% against SNB-E. | |
| The only tests Intel’s CPUs can win are vectorised ones using RyuJit’s support for SIMD (aka SSE2, AVX/FMA) and thus allowing Intel’s SIMD units to shine; otherwise Ryzen dominates absolutely everything without fail. | ||||||
 |
||||||
 |
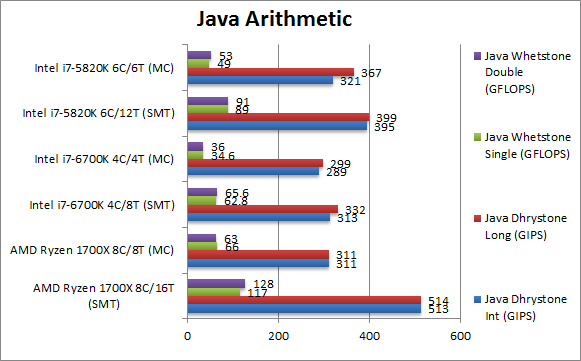
Java Dhrystone Integer (GIPS) | 513 [+29%] | 311 | 313 | 289 | 395 | 321 | We start JVM integer performance with an even bigger gain, Ryzen is ~30% faster than HSW-E and 60% faster than SKL. | |
|
Java Dhrystone Long (GIPS) | 514 [+28%] | 311 | 332 | 299 | 399 | 367 | Nothing much changes with 64-bit integer workload, we have Ryzen 28% faster than HSW-E. | |
|
Java Whetstone float/FP32 (GFLOPS) | 117 [+31%] | 66 | 62.8 | 34.6 | 89 | 49 | With a floating-point workload Ryzen continues its lead over both Intel’s CPUs. Native or CLR or JVM code works just great on Ryzen. | |
|
Java Whetstone double/FP64 (GFLOPS) | 128 [+40%] | 63 | 64.6 | 36 | 91 | 53 | With FP64 workload the gap increases even further to 40% over HSW-E and an incredible 2x over SKL! Ryzen is the JVM king. | |
| Java performance is even more incredible than what we’ve seen in .Net; server people rejoice, if you have Java workloads Ryzen is the CPU for you! 40% better performance than Intel’s 2011 platform for much lower cost? Yes please! | ||||||
 |
||||||
 |
Java Integer Vectorised/Multi-Media (MPix/s) | 99 [+20%] | 52.6 | 59.5 | 36.5 | 82 | 49 | Oracle’s JVM does not yet support native vector to SIMD translation like .Net’s CLR but here Ryzen manages a 20% lead over HSW-E but is almost 2x faster than SKL. | |
|
Java Long Vectorised/Multi-Media (MPix/s) | 93 [+17%] | 51 | 60.6 | 37.7 | 79 | 53 | With 64-bit vectorised workload Ryzen maintains its lead of about 20%. | |
|
Java Float/FP32 Vectorised/Multi-Media (MPix/s) | 86 [+40%] | 42.3 | 40.6 | 22.1 | 61 | 32 | Just as we’ve seen with Whetstone, Ryzen is about 40% faster than HSW-E and over 2x faster than SKL! It does not get a lot better than this.
Intel better hope Oracle will add vector primitives allowing SIMD code to use the power of its CPU’s SIMD units. |
|
|
Java Double/FP64 Vectorised/Multi-Media (MPix/s) | 82 [+30%] | 42 | 40.9 | 22.1 | 63 | 32 | With FP64 workload Ryzen’s lead somewhat unexplicably drops to ‘just’ 30% but remains over 2x faster than SKL. Nothing to grumble about really. | |
| Java’s lack of vectorised primitives to allow the JVM to use SIMD instruction sets (aka SSE2, AVX/FMA) gives Ryzen free reign to dominate all the tests, be they integer or floating-point. It is pretty incredible that neither Intel CPU can come close to its performance. | ||||||
Ryzen absolutely dominates .Net and Java benchmarks with CLR and JVM code running much faster than on Intel’s (ex)-top-of-the-range Haswell-E – thus current and future applications running under CLR (WPF/Metro/UWP/etc.) as well as server JVM workloads run great on Ryzen. For .Net and Java code, Ryzen is the CPU to get!
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
What a return of fortune from AMD! Despite a hurried launch and inevitable issues which will be fixed in time (e.g. Windows scheduler), Ryzen puts a strong performance beating Intel’s previous top-of-the-range Skylake 6700K and Haswell-E 6820K into dust in most tests at a much cheaper price.
Of course there are setbacks, highly vectorised AVX2/FMA code greatly favour Intel’s SIMD units and here Ryzen falls behind a bit; streaming algorithms can overload the 2 memory channels but then again Intel’s mainstream platform has only 2 also. Still if you were replacing a 2011 4-channel platform with Ryzen then very high-speed memory may be required to sustain performance.
It’s dual-CCX design may also affect non-symmetrical workloads where different threads execute different code with thread data-sharing across CCX naturally slower. Clever thread assignment to the ‘right’ CCX should fix those issues but that is down to each application with Windows (or other OSes) may not be able to fix. Considering we have SMP and NUMA systems out there – it is not a new problem but perhaps one not usually seen on normal desktop systems due to the high-cost of SMP/NUMA systems.
All in all Ryzen is a solid CPU which should worry Intel at the high-end, we shall have to see how the lower-end 4-core and even 2-core versions perform.
Pingback: AMD Ryzen Review and Benchmarks – Cache and Memory – SiSoftware
Pingback: SiSoftware Sandra Platinum (2017) Released! – SiSoftware