Why test GPGPU performance Intel Core Graphics?
Laptops (and tablets) are still in fashion with desktops largely left to PC game enthusiasts and workstations for big compute workloads; most laptops (and all tablets) make due with integrated graphics with few dedicated graphics options mainly for mobile PC gamers.
As a result integrated graphics on Intel’s mobile platform is what the vast majority of users will experience – thus its importance is not to be underestimated. While in the past integrated graphics options were dire – the introduction of Core v3 (Ivy Bridge) series brought us a GPGPU-capable graphics processor as well an updated internal media transcoder of Core v2 (Sandy Bridge).
With each generation Intel has progressively improved the graphics core, perhaps far more than its CPU cores – and added more variants (GT3) and embedded cache (eDRAM) which greatly increased performance – all within the same power limit.
New Features enabled by the latest 21.45 graphics driver
With Intel graphics drivers supporting just 2 generations of graphics – unlike unified drivers of AMD and nVidia – old graphics quickly become obsolete with few updates; but Windows 10 “free update” forced Intel’s hand somewhat – with its driver (20.40) supporting 3 generations of graphics (Haswell, Broadwell and latest at the time Skylake).
However, the latest 21.45 driver for newly released Kabylake and older Skylake does bring new features that can make a big difference in performance:
- Native FP64 (64-bit aka “double” floating-point support) in OpenCL – thus allowing high precision compute on integrated graphics.
- Native FP16 (16-bit aka “half” floating-point support) in OpenCL, ComputeShader – thus allowing lower precision but faster compute.
- Vulkan graphics interface support – OpenGL’s successor and DirectX 12’s competitor – for faster graphics and compute.
Will these new features make upgrading your laptop to a brand-new KBL laptop more compelling?
In this article we test (GP)GPU graphics unit performance; please see our other articles on:
Hardware Specifications
We are comparing the internal GPUs of the new Intel ULV APUs with the old versions.
| Graphics Unit | Haswell HD4000 | Haswell HD5000 | Broadwell HD6100 | Skylake HD520 | Skylake HD540 | Kabylake HD620 | Comment | |
| Graphics Core | EV7.5 HSW GT2U | EV7.5 HSW GT3U | EV8 BRW GT3U | EV9 SKL GT2U | EV9 SKL GT3eU | EV9.5 KBL GT2U | Despite 4 CPU generations we really have 2 GPU generations. | |
| APU / Processor | Core i5-4210U | Core i7-4650U | Core i7-5557U | Core i7-6500U | Core i5-6260U | Core i3-7100U | The naming convention has changed between generations. | |
| Cores (CU) / Shaders (SP) / Type | 20C / 160SP | 40C / 320SP | 48C / 384SP | 24C / 192SP | 48C / 384SP | 23C / 184SP | BRW increased CUs to 24/48 and i3 misses 1 core. | |
| Speed (Min / Max / Turbo) MHz | 200-1000 | 200-1100 | 300-1100 | 300-1000 | 300-950 | 300-1000 | The turbo clocks have hardly changed between generations. | |
| Power (TDP) W | 15 | 15 | 28 | 15 | 15 | 15 | Except GT3 BRW, all ULVs are 15W rated. | |
| DirectX CS Support | 11.1 | 11.1 | 11.1 | 11.2 / 12.1 | 11.2 / 12.1 | 11.2 / 12.1 | SKL/KBL enjoy v11.2 and 12.1 support. | |
| OpenGL CS Support | 4.3 | 4.3 | 4.3 | 4.4 | 4.4 | 4.4 | SKL/KBL provide v4.4 vs. verision 4.3 for older devices. | |
| OpenCL CS Support | 1.2 | 1.2 | 1.2 | 2.0 | 2.0 | 2.1 | SKL provides v2 support with KBL 2.1 vs 1.2 for older devices. | |
| FP16 / FP64 Support | No / No | No / No | No / No | Yes / Yes | Yes / Yes | Yes / Yes | SKL/KBL support both FP64 and FP16. | |
| Byte / Integer Width | 8 / 32-bit | 8 / 32-bit | 8 / 32-bit | 128 / 128-bit | 128 / 128-bit | 128 / 128-bit | SKL/KBL prefer vectorised integer workloads, 128-bit wide. | |
| Float/ Double Width | 32 / X-bit | 32 / X-bit | 32 / X-bit | 32 / 64-bit | 32 / 64-bit | 32 / 64-bit | Strangely neither arch prefers vectorised floating-point loads – driver bug? | |
| Threads per CU | 512 | 512 | 256 | 256 | 256 | 256 | Strangely BRW and later reduced the threads/CU to 256. | |
GPGPU Performance
We are testing vectorised, crypto (including hash), financial and scientific GPGPU performance of the GPUs in OpenCL, DirectX/OpenGL ComputeShader .
Results Interpretation: Higher values (MPix/s, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest Intel drivers (April 2017). Turbo / Dynamic Overclocking was enabled on all configurations.
| Graphics Processors | HD4000 (EV7.5 HSW-GT2U) | HD5000 (EV7.5 HSW-GT3U) | HD6100 (EV8 BRW-GT3U) | HD520 (EV9 SKL-GT2U) | HD540 (EV9 SKL-GT3eU) | HD620 (EV9.5 KBL-GT2U) | Comments | |
 |
||||||||
 |
Half/Float/FP16 Vectorised OpenCL (Mpix/s) | 288 | 399 | 597 | 875 [+3x] | 1500 | 840 [+2.8x] | If FP16 is enough, KBL and SKL have 2x performance of FP32. |
|
Single/Float/FP32 Vectorised OpenCL (Mpix/s) | 299 | 375 | 614 | 468 [+56%] | 817 | 452 [+50%] | SKL GT3e rules the roost but KBL hardly improves on SKL. |
|
Double/FP64 Vectorised OpenCL (Mpix/s) | 18.54 (eml) | 24.4 (eml) | 38.9 (eml) | 112 [+6x] | 193 | 104 [+5.6x] | SKL GT2 with native Fp64 is almost 4x emulated BRW GT3! |
|
Quad/FP128 Vectorised OpenCL (Mpix/s) | 1.8 (eml) | 2.36 (eml) | 4.4 (eml) | 6.34 (eml) [+3.5x] | 10.92 (eml) | 6.1 (eml) [+3.4x] | Emulating Fp128 though Fp64 is ~2.5x faster than through FP32. |
| As expected native FP16 runs about 2x faster than FP32 and thus provides a huge performance upgrade if precision is sufficient. Native FP64 is about 8x emulated FP64 and even emulated FP128 improves by about 2.5x! Otherwise KBL GT2 matches SKL GT2 and is about 50% faster than HSW GT2 in FP32 and 6x faster in FP64. | ||||||||
 |
||||||||
 |
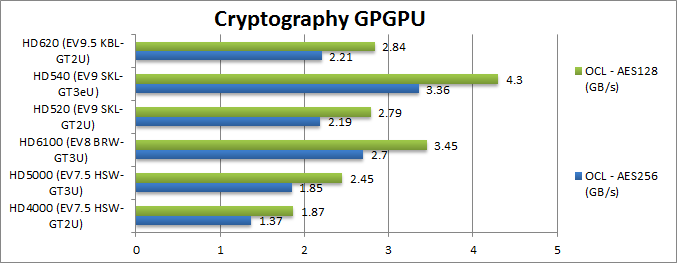
AES256 Crypto OpenCL (MB/s) | 1.37 | 1.85 | 2.7 | 2.19 [+60%] | 3.36 | 2.21 [+60%] | Since BRW integer performance is similar. |
|
AES128 Crypto OpenCL (MB/s) | 1.87 | 2.45 | 3.45 | 2.79 [+50%] | 4.3 | 2.83 [+50%] | Not a lot changes here. |
| SKL/KBL GT2 with integer workloads (with extensive memory accesses) are 50-60% faster than HSW similar to what we saw with floating-point performance. But the changed happened with BRW which improved the most over HSW with SKL and KBL not improving further. | ||||||||
 |
||||||||
|
SHA2-256 (int32) Hash OpenCL (MB/s) | 1.2 | 1.62 | 4.35 | 3 [+2.5x] | 5.12 | 2.92 | In this tough compute test SKL/KBL are 2.5x faster. |
|
SHA1 (int32) Hash OpenCL (MB/s) | 2.86 | 3.93 | 9.82 | 6.7 [+2.34x] | 11.26 | 6.49 | With a lighter algorithm SKL/KBL are still ~2.4x faster. |
|
SHA2-512 (int64) Hash OpenCL (MB/s) | 0.828 | 1.08 | 1.68 | 1.08 [+30%] | 1.85 | 1 | 64-integer performance does not improve much. |
| In pure integer compute tests SKL/KBL greatly improve over HSW being no less than 2.5x faster a huge improvement; but 64-bit integer performance hardly improves (30% faster with 20% more CUs 24 vs 20). Again BRW is where the improvements were added with SKL GT3e hardly improving over BRW GT3. | ||||||||
 |
||||||||
 |
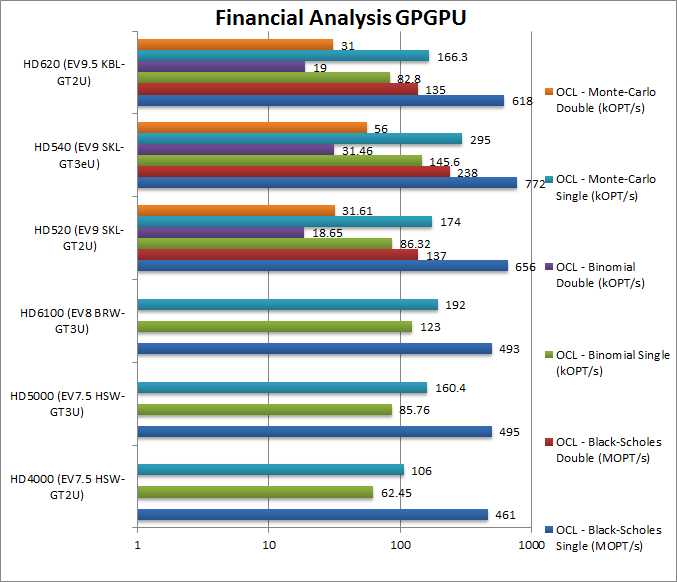
Black-Scholes FP32 OpenCL (MOPT/s) | 461 | 495 | 493 | 656 [+42%] | 772 | 618 [+40%] | Pure FP32 compute SKL/KBL are 40% faster. |
|
Black-Scholes FP64 OpenCL (MOPT/s) | – | – | – | 137 | 238 | 135 | SKL GT3 is 73% faster than GT2 variants |
|
Binomial FP32 OpenCL (kOPT/s) | 62.45 | 85.76 | 123 | 86.32 [+38%] | 145.6 | 82.8 [+35%] | In this tough algorithm SKL/KBL are still amost 40% faster. |
|
Binomial FP64 OpenCL (kOPT/s) | – | – | – | 18.65 | 31.46 | 19 | SKL GT3 is over 65% faster than GT2 KBL. |
|
Monte-Carlo FP32 OpenCL (kOPT/s) | 106 | 160.4 | 192 | 174 [+64%] | 295 | 166.4 [+56%] | M/C is not as tough so here SKL/KBL are 60% faster. |
|
Monte-Carlo FP64 OpenCL (kOPT/s) | – | – | – | 31.61 | 56 | 31 | GT3 SKL manages an 80% improvement over GT2. |
| Intel is pulling our leg here; KBL GPU seems to show no improvement whatsoever over SKL, but both are about 40% faster in FP32 than the much older HSW. GT3 SKL variant shows good gains of 65-80% over the common GT2 and thus is the one to get if available. Obviously the ace card for SKL and KBL is FP64 support. | ||||||||
 |
||||||||
 |
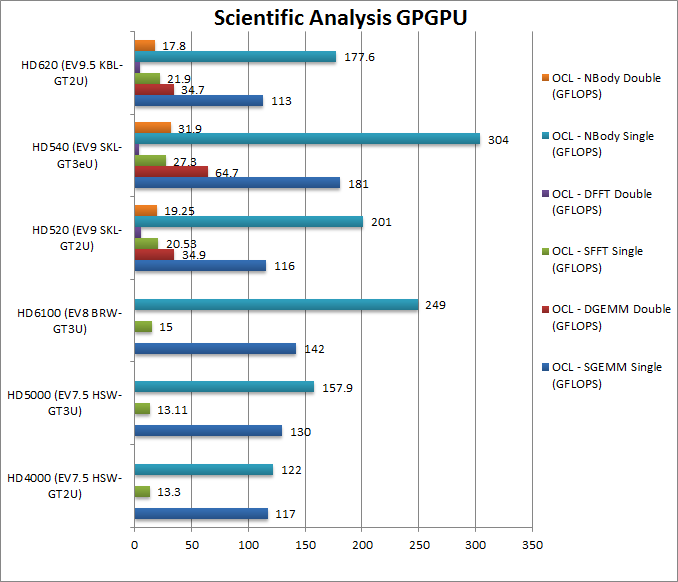
SGEMM FP32 OpenCL (GFLOPS) | 117 | 130 | 142 | 116 [=] | 181 | 113 [=] | SKL/GBL have a problem with this algorithm but GT3 does better? |
|
DGEMM FP64 OpenCL (GFLOPS) | – | – | – | 34.9 | 64.7 | 34.7 | GT3 SKL manages a 86% improvement over GT2. |
|
SFFT FP32 OpenCL (GFLOPS) | 13.3 | 13.1 | 15 | 20.53 [+54%] | 27.3 | 21.9 [+64%] | In a return to form SKL/KBL are 50% faster. |
|
DFFT FP64 OpenCL (GFLOPS) | – | – | – | 5.2 | 4.19 | 4.69 | GT3 stumbles a bit here some optimisations are needed. |
|
N-Body FP32 OpenCL (GFLOPS) | 122 | 157.9 | 249 | 201 [+64%] | 304 | 177.6 [+45%] | Here SKL/KBL are 50% faster overall. |
|
N-Body FP64 OpenCL (GFLOPS) | – | – | – | 19.25 | 31.9 | 17.8 | GT3 manages only a 65% improvement here. |
| Again we see no delta between SKL and KBL – the graphics cores perform the same; again both benefit from FP64 support allowing high precision kernels to run. GT3 SKL variant greatly improves over common GT2 variant – except in one test (DFFT) that seems to be an outlier. | ||||||||
 |
||||||||
 |
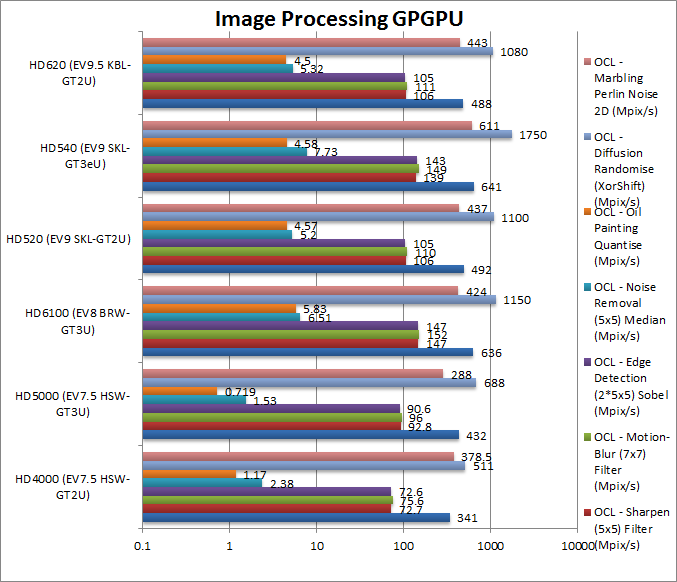
Blur (3×3) Filter OpenCL (MPix/s) | 341 | 432 | 636 | 492 [+44%] | 641 | 488 [+43%] | We see the GT3s trading blows in this integer test, but SKL/KBL are 40% faster than HSW. |
|
Sharpen (5×5) Filter OpenCL (MPix/s) | 72.7 | 92.8 | 147 | 106 [+45%] | 139 | 106 [+45%] | BRW GT3 just wins this with SKL/KBL again 45% faster. |
|
Motion-Blur (7×7) Filter OpenCL (MPix/s) | 75.6 | 96 | 152 | 110 [+45%] | 149 | 111 [+45%] | Another win for BRW and 45% improvent for SKL/KBL. |
|
Edge Detection (2*5×5) Sobel OpenCL (MPix/s) | 72.6 | 90.6 | 147 | 105 [+44%] | 143 | 105 [+44%] | As above in this test. |
|
Noise Removal (5×5) Median OpenCL (MPix/s) | 2.38 | 1.53 | 6.51 | 5.2 [+2.2x] | 7.73 | 5.32 [+2.23x] | SKL’s GT3 manages a win but overall SKl/KBL are over 2x faster than HSW. |
|
Oil Painting Quantise OpenCL (MPix/s) | 1.17 | 0.719 | 5.83 | 4.57 [+3.9x] | 4.58 | 4.5 [+3.84x] | Another win for BRW |
|
Diffusion Randomise OpenCL (MPix/s) | 511 | 688 | 1150 | 1100 [+2.1x] | 1750 | 1080 [+2.05x]_ | SKL/KBL are over 2x faster than HSW. BRW is beat here. |
|
Marbling Perlin Noise 2D OpenCL (MPix/s) | 378.5 | 288 | 424 | 437 [+15%] | 611 | 443 [+17%] | Some wild results here, some optimizations may be needed. |
| In this integer workloads (with texture access) the 28W GT3 of BRW manages a few wins over 15W GT3e of SKL – but compared to old HSW – both SKL and KBL are between 40 and 300% faster. Again we see no delta between SKL and KBL – there does not seem to be any difference at all! | ||||||||
If you have a HSW GT2 then an upgrade to SKL GT2 brings massive improvements as well as FP16 and FP64 native support. But HSW GT3 variant is competitive and BRW GT3 even more so. KBL GT2 shows no improvement over SKL GT2 – so it’s not just the CPU core that is unchanged but the graphics core also – it’s no EV9.5 here more like EV9.1!
For integer workloads BRW is where the big improvement came but for 64-integer that improvement is still to come, if ever. At least all drivers support native int64.
Transcoding Performance
We are testing media (video + audio) transcoding performance for common video algorithms: H.264/MP4, AVC1, M.265/HEVC.
Results Interpretation: Higher values (MPix/s, MB/s, etc.) mean better performance. Lower values (ns, clocks) mean better performance.
Environment: Windows 10 x64, latest Intel drivers (April 2017). Turbo / Dynamic Overclocking was enabled on all configurations.
| Graphics Processors | HD4000 (EV7.5 HSW-GT2U) | HD5000 (EV7.5 HSW-GT3U) | HD6100 (EV8 BRW-GT3U) | HD520 (EV9 SKL-GT2U) | HD540 (EV9 SKL-GT3eU) | HD620 (EV9.5 KBL-GT2U) | Comments | |
| H.264/AVC Decoder/Encoder | QuickSync H264 8-bit only | QuickSync H264 8-bit only | QuickSync H264 8/10-bit | QuickSync H264 8/10-bit | QuickSync H264 8/10-bit | QuickSync H264 8/10-bit | HSW supports 8-bit only so 10-bit (high-colour) are out of luck. | |
| H.265/HEVC Decoder/Encoder | – | – | QuickSync H265 8-bit partial | QuickSync H265 8-bit | QuickSync H265 8-bit | QuickSync H265 8/10-bit | SKL has full/hardware H265/HEVC transcoding but for 8-bit only; Main10 (10-bit profile) requires KBL so finally we see a difference. | |
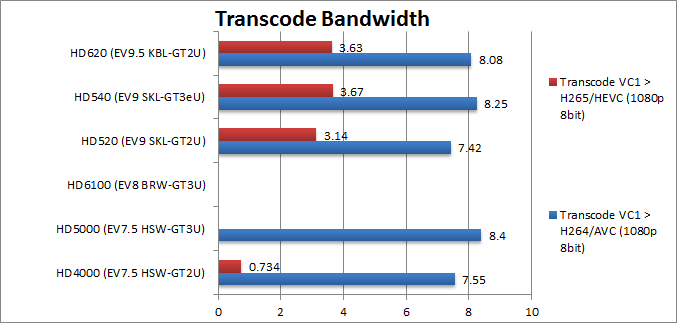 |
||||||||
 |
VC 1 > H264/AVC Transcoding (MB/s) | 7.55 | 8.4 | 7.42 [-2%] | 8.25 | 8.08 [+6%] | With DDR4 KBL is 6% faster. | |
|
VC 1 > H265/HEVC Transcoding (MB/s) | 0.734 | 3.14 [+4.2x] | 3.67 | 3.63 [+5x] | Hardware support makes SKL/KBL 4-5x faster. | ||
If you want HEVC/H.265 then you want SKL including 4k/UHD. But if you plan on using 10-bit/HDR colour then you need KBL – finally an improvement over SKL. As it uses fixed-point hardware the GT3 performs only slightly faster.
Memory Performance
We are testing memory performance of GPUs using OpenCL, DirectX/OpenGL ComputeShader, including transfer (up/down) to/from system memory and latency.
Results Interpretation: Higher values (MPix/s, MB/s, etc.) mean better performance. Lower values (ns, clocks) mean better performance.
Environment: Windows 10 x64, latest Intel drivers (Apr 2017). Turbo / Dynamic Overclocking was enabled on all configurations.
| Graphics Processors | HD4000 (EV7.5 HSW-GT2U) | HD5000 (EV7.5 HSW-GT3U) | HD6100 (EV8 BRW-GT3U) | HD520 (EV9 SKL-GT2U) | HD540 (EV9 SKL-GT3eU) | HD620 (EV9.5 KBL-GT2U) | Comments | |
| Memory Configuration | 8GB DDR3 1.6GHz 128-bit | 8GB DDR3 1.6GHz 128-bit | 16GB DDR3 1.6GHz 128-bit | 8GB DDR3 1.867GHz 128-bit | 16GB DDR4 2.133GHz 128-bit | 16GB DDR4 2.133GHz 128-bit | All use 128-bit memory with SKL/KBL using DDR4. | |
| Constant (kB) / Shared (kB) Memory | 64 / 64 | 64 / 64 | 64 / 64 | 2048 / 64 | 2048 / 64 | 2048 / 64 | Shared memory remains the same; in SKL/KBL constant memory is the same as global. | |
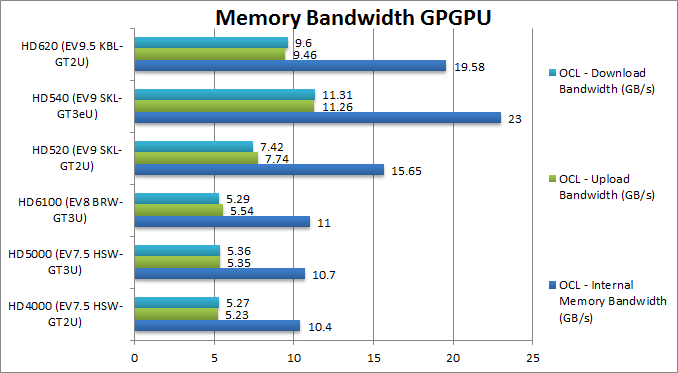 |
||||||||
 |
Internal Memory Bandwidth (GB/s) | 10.4 | 10.7 | 11 | 15.65 | 23 [+2.1x] | 19.6 | DDR4 seems to provide over 2x bandwidth despite low clock. |
|
Upload Bandwidth (GB/s) | 5.23 | 5.35 | 5.54 | 7.74 | 11.23 [+2.1x] | 9.46 | Again over 2x increase in up speed. |
|
Download Bandwidth (GB/s) | 5.27 | 5.36 | 5.29 | 7.42 | 11.31 [+2.1x] | 9.6 | Again over 2x increase in down speed. |
| SKL/KBL + DDR4 provide over 2x increase in internal, up and down memory bandwidth – despite the relatively modern increase in memory speed (2133 vs 1600); with DDR3 1867MHz memory the improvement drops to 1.5x. So if you were to decide DDR3 or DDR4 the choice has been made! | ||||||||
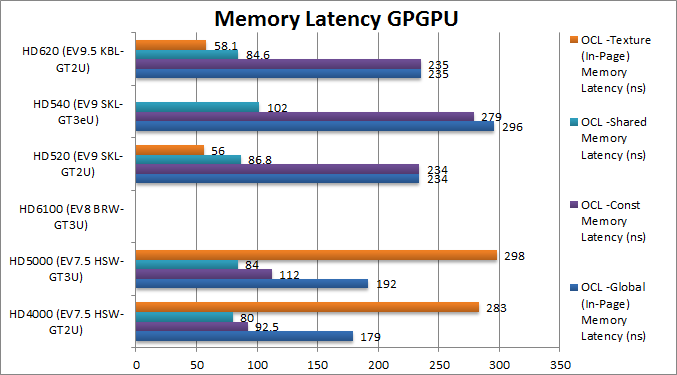 |
||||||||
 |
Global Memory (In-Page Random) Latency (ns) | 179 | 192 | – | 234 [+30%] | 296 | 235 [+30%] | With DDR4 latency has increased by 30% not great. |
|
Constant Memory Latency (ns) | 92.5 | 112 | – | 234 [+2.53x] | 279 | 235 [+2.53x] | Constant memory has effectively been dropped resulting in a disastrous 2.53x higher latencies. |
|
Shared Memory Latency (ns) | 80 | 84 | – | 86.8 [+8%] | 102 | 84.6 [+8%] | Shared memory latency has stayed the same. |
|
Texture Memory (In-Page Random) Latency (ns) | 283 | 298 | – | 56 [1/5x] |
– | 58.1 [1/5x] |
Texture access seems to have markedly improved to be 5x faster. |
| SKL/KBL global memory latencies have increased by 30% with DDR4 – thus wiping out some gains. The “new” constant memory (2GB!) is now really just bog-standard global memory and thus with over 2x increase in latency. Shared memory latency has stayed pretty much the same. Texture memory access is very much faster – 5x faster likely though some driver optimisations. | ||||||||
Again no delta between KBL and SKL; if you want bandwidth (who doesn’t?) DDR4 with modest 2133MHz memory doubles bandwidths – but latencies increase. Constant memory is now the same as global memory and does not seem any faster.
Shader Performance
We are testing shader performance of the GPUs in DirectX and OpenGL as well as memory bandwidth performance.
Results Interpretation: Higher values (MPix/s, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest Intel drivers (Apr 2017). Turbo / Dynamic Overclocking was enabled on all configurations.
| Graphics Processors | HD4000 (EV7.5 HSW-GT2U) | HD5000 (EV7.5 HSW-GT3U) | HD6100 (EV8 BRW-GT3U) | HD520 (EV9 SKL-GT2U) | HD540 (EV9 SKL-GT3eU) | HD620 (EV9.5 KBL-GT2U) | Comments | |
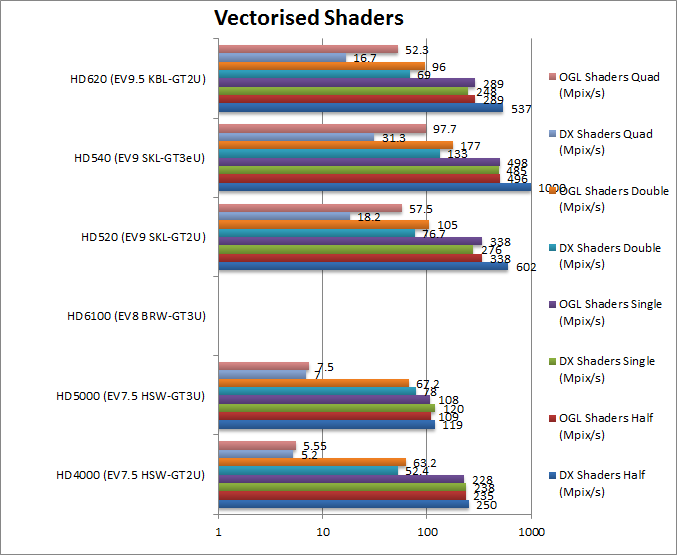 |
||||||||
 |
Half/Float/FP16 Vectorised DirectX (Mpix/s) | 250 | 119 | 602 [+2.4x] | 1000 | 537 [+2.1x] | Fp16 support in DirectX doubles performance. | |
|
Half/Float/FP16 Vectorised OpenGL (Mpix/s) | 235 | 109 | 338 [+43%] | 496 | 289 [+23%] | Fp16 does not yet work in OpenGL. | |
|
Single/Float/FP32 Vectorised DirectX (Mpix/s) | 238 | 120 | 276 [+16%] | 485 | 248 [4%] | We only see a measly 4-16% better performance here. | |
|
Single/Float/FP32 Vectorised OpenGL (Mpix/s) | 228 | 108 | 338 [+48%] | 498 | 289 [+26%] | SKL does better here – it’s 50% faster than HSW. | |
|
Double/FP64 Vectorised DirectX (Mpix/s) | 52.4 | 78 | 76.7 [+46%] | 133 | 69 [+30%] | With FP64 SKL is still 45% faster. | |
|
Double/FP64 Vectorised OpenGL (Mpix/s) | 63.2 | 67.2 | 105 [+60%] | 177 | 96 [+50%] | Similar result here 50-60% faster. | |
|
Quad/FP128 Vectorised DirectX (Mpix/s) | 5.2 | 7 | 18.2 [+3.5x] | 31.3 | 16.7 [+3.2x] | Driver optimisation makes SKL/KBL over 3.5x faster. | |
|
Quad/FP128 Vectorised OpenGL (Mpix/s) | 5.55 | 7.5 | 57.5 [+10x] | 97.7 | 52.3 [+9.4x] | Here we see SKL/KBL over 10x faster! | |
| We see similar results to OpenCL GPGPU here – with FP16 doubling performance in DirectX – but with FP64 already supported in both DirectX and OpenGL even with HSW, KBL and SKL have less of a lead – of around 50%. | ||||||||
 |
||||||||
 |
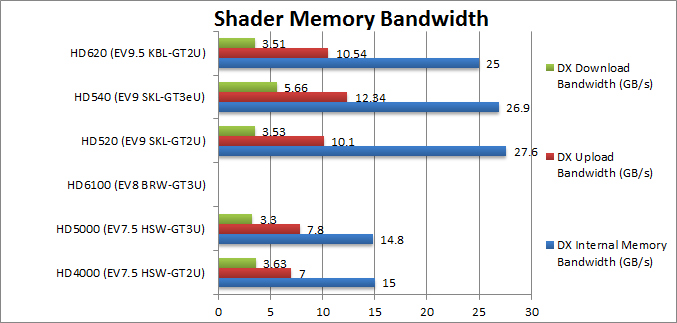
Internal Memory Bandwidth (GB/s) | 15 | 14.8 | 27.6 [+84%] |
26.9 | 25 [+67%] | DDR4 brings almost 50% more bandwidth. | |
|
Upload Bandwidth (GB/s) | 7 | 7.8 | 10.1 [+44%] | 12.34 | 10.54 [+50%] | Upload bandwidth has also increased ~50%. | |
|
Download Bandwidth (GB/s) | 3.63 | 3.3 | 3.53 [-2%] | 5.66 | 3.51 [-3%] | No change in download bandwidth though. | |
Final Thoughts / Conclusions
SKL and KBL with the 21.45 driver yields significant gains in OpenCL making an upgrade from HSW and even BRW quite compelling despite the relatively modern 20.40 driver Intel was forced to provide for Windows 10. The GT3 version provides good gains over the standard GT2 version and should always be selected if available.
Native FP64 support is a huge addition which provides support for high-precision kernels – unheard of for integrated graphics. Native FP16 support provides an additional 2x performance in cases where 16-bit floating-point processing is sufficient.
However KBL’s EV9.5 graphics core shows no improvement at all over SKL’s EV9 core – thus it’s not just the CPU core that has not been changed but the GPU core too! Except for the updated transcoder supporting Main10 HEVC/H.265 (thus HDR / 10-bit+ colour) which is still quite useful for UHD/4K HDR media.
This is very much a surprise – as while the CPU core has not improved markedly since SNB (Core v2), the GPU core has always provided significant improvements – and now we have hit the same road-block. As dedicated GPUs have continued to improve significantly in performance and power efficiency this is quite a surprise. This marks the smallest ever generation to generation – SKL to KBL – ever, effectively KBL is a SKL refresh.
It seems the rumour that Intel may change to ATI/AMD graphics cores may not be such a crazy idea after all!