What is “SKL-X”?
“Skylake-X” (E/EP) is the server/workstation/HEDT version of desktop/mobile Skylake CPU – the 6-th gen Core/Xeon replacing the current Haswell/Broadwell-E designs. It naturally does not contain an integrated GPU but what does contain is more cores, more PCIe lanes and more memory channels:
- Server 2S, 4S and 8S (sockets)
- Workstation 1S and 2S
- Up to 28 cores and 56 threads per CPU
- Up to 48 PCIe 3.0 lanes
- Up to 46-bit physical address space and 48-bit virtual address space
- 512-bit SIMD aka AVX512F, AVX512BandW, AVX512DWandQW
While it may seem an “old core”, the 7-th gen Kabylake core is not much more than a stepping update with even the future 8-th gen Coffeelake rumored again to use the very same core. But what it does do is include the much expected 512-bit AVX512 instruction set (ISA) that are are not enabled in the current desktop/mobile parts.
On the desktop – Intel is now using the “i9” moniker for its top parts – in a way a much needed change for its top HEDT platform (socket 2011 now socket 2066) to differentiate from its mainstream one.
In this article we test CPU core performance; please see our other articles on:
Hardware Specifications
We are comparing the top-end desktop Core i9 with current competing architectures from both AMD and Intel as well as its previous version.
| CPU Specifications | Intel i9 7900X (Skylake-X) | AMD Ryzen 1700X | Intel i7 6700K (Skylake) | Intel i7 5820K (Haswell-E) | Comments | |
| Cores (CU) / Threads (SP) | 10C / 20T | 8C / 16T | 4C / 8T | 6C / 12T | SKL-X manages more cores than Ryzen (10 vs 8) which considering their speed may just be too tough to beat. HSW-E topped at 8 cores also. | |
| Speed (Min / Max / Turbo) | 1.2-3.3-4.3GHz (12x-33x-43x) | 2.2-3.4-3.9GHz (22x-34x-39x) | 0.8-4.0-4.2GHz (8x-40x-42x) | 1.2-3.3-4.0GHz (12x-33x-40x) | SKL-X somehow manages higher single-core turbo than even SKL-A (42x v 43x) – but its rated speed is a match for Ryzen and HSW-E. | |
| Power (TDP) | 140W | 95W | 91W | 140W | Ryzen has comparative TDP to SKL while HSW-E and SKL-X are both almost 50% higher | |
| L1D / L1I Caches | 10x 32kB 8-way / 10x 32kB 8-way | 8x 32kB 8-way / 8x 64kB 8-way | 4x 32kB 8-way / 4x 32kB 8-way | 6x 32kB 8-way / 6x 32kB 2-way | Ryzen instruction cache is 2x the data cache a somewhat strange decision; all caches are 8-way except the HSW-E’s L1I. | |
| L2 Caches | 10x 1MB 16-way | 8x 512kB 8-way | 4x 256kB 8-way | 6x 256kB 8-way | Surprise surprise – the new SKL-X’ L2 is 4-times the size of SKL/HSW-E and thus even beating Ryzen. Large datasets should have no problem getting cached. | |
| L3 Caches | 13.75MB 11-way | 2x 8MB 16-way | 8MB 16-way | 15MB 20-way | In a somewhat surprising move, the L3 cache has been reduced pretty drastically and is now smaller than both Ryzen and even the very old HSW-E! | |
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (AVX2, AVX, etc.). Ryzen supports all modern instruction sets including AVX2, FMA3 and even more like SHA HWA (supported by Intel’s Atom only) but has dropped all AMD’s variations like FMA4 and XOP likely due to low usage.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and Intel drivers. Turbo / Dynamic Overclocking was enabled on both configurations.
| Native Benchmarks | i9-7900X (Skylake-X) | Ryzen 1700X | i7-6700K 4C/8T (Skylake) |
i7-5820K (Haswell-E) |
Comments | |
 |
||||||
 |
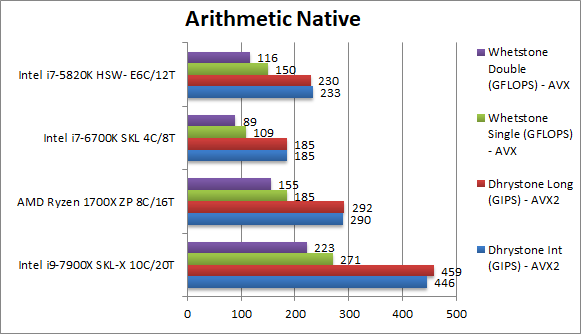
Native Dhrystone Integer (GIPS) | 446 [+54%] AVX2 | 290 AVX2 | 185 AVX2 | 233 AVX2 | Dhrystone does not yet use AVX512 – but no matter SKL-X beats Ryzen by over 50%! |
|
Native Dhrystone Long (GIPS) | 459 [+57%] AVX2 | 292 AVX2 | 185 AVX2 | 230 AVX2 | With a 64-bit integer workload nothing much changes. |
|
Native FP32 (Float) Whetstone (GFLOPS) | 271 [+46%] AVX/FMA | 185 AVX/FMA | 109 AVX/FMA | 150 AVX/FMA | Whetstone does not yet use AVX512 either – but SKL-X is still approx 50% faster! |
|
Native FP64 (Double) Whetstone (GFLOPS) | 223 [+50%] AVX/FMA | 155 AVX/FMA | 89 AVX/FMA | 116 AVX/FMA | With FP64 the winning streak continues. |
| The Empire strikes back – SKL-X beats Ryzen by a sizeable difference (50%) across integer or floating-point workloads even on “legacy” AVX2/FMA instruction set. It will only get faster once AVX512 is enabled. | ||||||
 |
||||||
 |
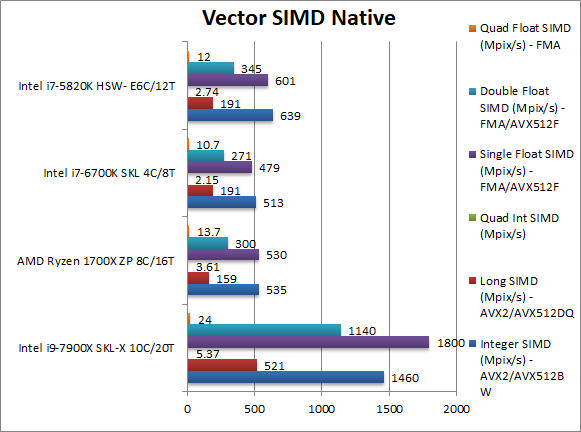
Native Integer (Int32) Multi-Media (Mpix/s) | 1460 [+2.7x] AVX512DQW | 535 AVX2 | 513 AVX2 | 639 AVX2 | For the 1st time we see AVX512 in action and everything is pummeled into dust – almost 3-times faster than Ryzen! |
|
Native Long (Int64) Multi-Media (Mpix/s) | 521 [+3.3x] AVX512DQW | 159 AVX2 | 191 AVX2 | 191 AVX2 | With a 64-bit integer vectorised workload SKL-X is over 3-times faster than Ryzen! |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 5.37 [+48%] | 3.61 | 2.15 | 2.74 | This is a tough test using Long integers to emulate Int128 without SIMD and thus SKL-X returns to “just” 50% faster than Ryzen. |
|
Native Float/FP32 Multi-Media (Mpix/s) | 1800 [+3.4x] AVX512F | 530 FMA | 479 FMA | 601 FMA | In this floating-point vectorised test we see again the power of AVX512 with SKL-X is again over 3-times faster than Ryzen! |
|
Native Double/FP64 Multi-Media (Mpix/s) | 1140 [+3.8x] AVX512F | 300 FMA | 271 FMA | 345 FMA | Switching to FP64 SIMD code SKL-X gets even faster approaching 4-times |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 24 [+84%] AVX512F | 13.7 FMA | 10.7 FMA | 12 FMA | In this heavy algorithm using FP64 to mantissa extend FP128 but not vectorised – SKL-X returns to just 85% faster. |
| Ryzen’s SIMD units were never strong – splitting 256-bit ops into 2 – but with AV512 SKL-X is unstoppable: integer or floating-point we see it over 3-times faster that is a serious improvement in performance. Even against its older HSW-E it is over 2-times faster a significant upgrade. For heavy vectorised SIMD code – as long as it’s updated to AVX512 – there is no other choice. | ||||||
 |
||||||
 |
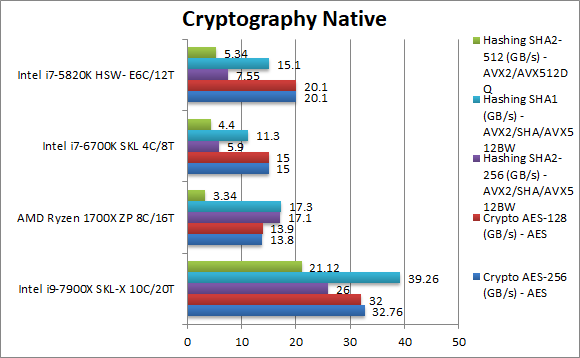
Crypto AES-256 (GB/s) | 32.7 [+2.4x] AES | 13.8 AES | 15 AES | 20 AES | All CPUs support AES HWA – thus it is mainly a matter of memory bandwidth – and with 4 memory channels SKL-X reigns supreme – it’s over 2-times faster. |
|
Crypto AES-128 (GB/s) | 32 [+2.3x] AES | 13.9 AES | 15 AES | 20.1 AES | What we saw with AES-256 just repeats with AES-128; Ryzen would need more memory channels to even HSW-E never mind SKL-X. |
|
Crypto SHA2-256 (GB/s) | 25 [+46%] AVX512DQW | 17.1 SHA | 5.9 AVX2 | 7.6 AVX2 | Even Ryzen’s support for SHA hardware acceleration is not enough as memory bandwidth lets it down with SKL-X “only” 50% faster through AVX512. |
|
Crypto SHA1 (GB/s) | 39.3 [+2.3x] AVX512DQW | 17.3 SHA | 11.3 AVX2 | 15.1 AVX2 | SKL-X only gets faster with the simpler SHA1 and is now over 2-times faster. |
|
Crypto SHA2-512 (GB/s) | 21.1 [+6.3x] AVX512DQW | 3.34 AVX2 | 4.4 AVX2 | 5.34 AVX2 | SHA2-512 is not accelerated by SHA HWA thus Ryzen is forced to use SIMD and loses badly. |
| Memory bandwidth rules here and SKL-X with its 4-channels of ~100GB/s bandwidth reigns supreme (we can only imagine what the 6-channel beast will score) – so Ryzen loses badly. Its ace card – support for SHA HWA is not enough to “save it” as AVX512 allows SKL-X to power through algorithms like a knife through butter. The 64-bit SHA2-512 test is sobbering with SKL-X no less than 6-times faster than Ryzen. | ||||||
 |
||||||
 |
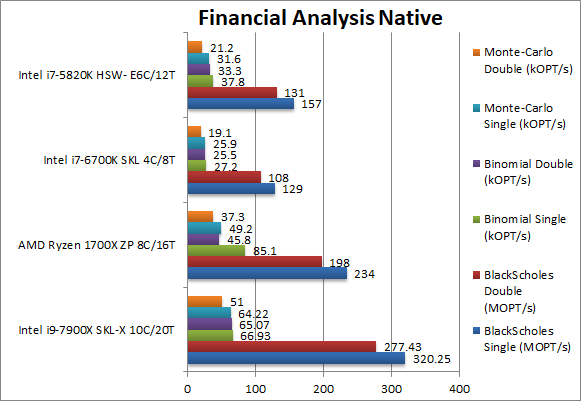
Black-Scholes float/FP32 (MOPT/s) | 320 [+36%] | 234 | 129 | 157 | In this non-vectorised test SKL-X is only 36% faster than Ryzen. SIMD would greaty help it here. |
|
Black-Scholes double/FP64 (MOPT/s) | 277 [+40%] | 198 | 108 | 131 | Switching to FP64 code nothing much changes, SKL-X is just 40% faster. |
|
Binomial float/FP32 (kOPT/s) | 66.9 [-21%] | 85.1 | 27.2 | 37.8 | Binomial uses thread shared data thus stresses the cache & memory system; somehow Ryzen manages to win this. |
|
Binomial double/FP64 (kOPT/s) | 65 [+41%] | 45.8 | 25.5 | 33.3 | With FP64 code the situation gets back to “normal” – with SKL-X again 40% faster than Ryzen. |
|
Monte-Carlo float/FP32 (kOPT/s) | 64 [+30%] | 49.2 | 25.9 | 31.6 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches; SKL-X is just 30% faster here. |
|
Monte-Carlo double/FP64 (kOPT/s) | 51 [+36%] | 37.3 | 19.1 | 21.2 | Switching to FP64 where Ryzen did so well – SKL-X returns to 40% faster. |
| Without the help of its SIMD engine, SKL-X is still 30-40% faster than Ryzen but over 2-times faster than HSW-E showing just how much the core has improved for complex code with lots of shared data (read-only or modifyable). While Ryzen thought it found its “niche” it has been already beaten… | ||||||
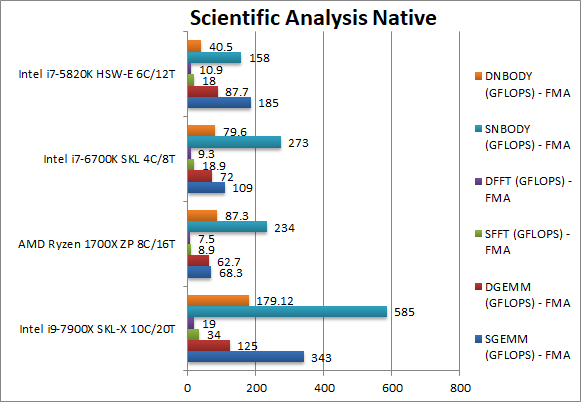 |
||||||
 |
SGEMM (GFLOPS) float/FP32 | 343 [5x] FMA | 68.3 FMA | 109 FMA | 185 FMA | GEMM has not yet been updated for AVX512 but SKL-X is an incredible 5x faster! |
|
DGEMM (GFLOPS) double/FP64 | 124 [+2x] FMA | 62.7 FMA | 72 FMA | 87.7 FMA | Even without AVX512, with FP64 vectorised code, SKL-X still manages 2x faster. |
|
SFFT (GFLOPS) float/FP32 | 34 [+3.8x] FMA | 8.9 FMA | 18.9 FMA | 18 FMA | FFT has also not been updated to AVX512 but SKL-X is still 4x faster than Ryzen! |
|
DFFT (GFLOPS) double/FP64 | 19 [+2.5x] FMA | 7.5 FMA | 9.3 FMA | 10.9 FMA | With FP64 SIMD SKL-X is over 2.5x faster than Ryzen in this tough algorithm with loads of memory accesses. |
|
SNBODY (GFLOPS) float/FP32 | 585 [+2.5x] FMA | 234 FMA | 273 FMA | 158 FMA | NBODY is not yet updated to AVX512 but again SKL-X wins. |
|
DNBODY (GFLOPS) double/FP64 | 179 [+2x] FMA | 87 FMA | 79 FMA | 40 FMA | With FP64 code SKL-X is still 2-times faster than Ryzen. |
| With highly vectorised SIMD code, even without the help of AVX512, SKL-X is over 2.5x faster than Ryzen, but more than that – almost 4-times faster than its older HSW-E brother! | ||||||
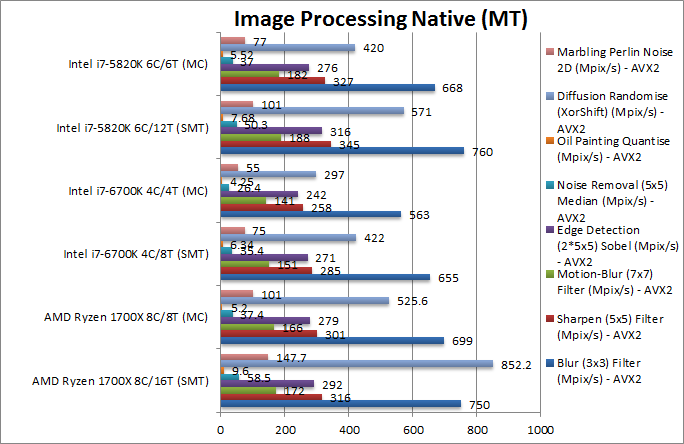 |
||||||
 |
Blur (3×3) Filter (MPix/s) | 1639 [+2.2x] AVX2 | 750 AVX2 | 655 AVX2 | 760 AVX2 | In this vectorised integer AVX2 workload SKL-X is over 2x faster than Ryzen. |
|
Sharpen (5×5) Filter (MPix/s) | 711 [+2.2x] AVX2 | 316 AVX2 | 285 AVX2 | 345 AVX2 | Same algorithm but more shared data does not change anything. |
|
Motion-Blur (7×7) Filter (MPix/s) | 377 [+2.2x] AVX2 | 172 AVX2 | 151 AVX2 | 188 AVX2 | Again same algorithm but even more data shared does not change anything again. |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 609 [+2.1x] AVX2 | 292 AVX2 | 271 AVX2 | 316 AVX2 | Different algorithm but still SKL-X is still 2x faster than Ryzen. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 79.8 [+36%] AVX2 | 58.5 AVX2 | 35.4 AVX2 | 50.3 AVX2 | Still AVX2 vectorised code but here Ryzen does much better, with SKL-X just 36% faster. |
|
Oil Painting Quantise Filter (MPix/s) | 15.7 [+63%] | 9.6 | 6.3 | 7.6 | This test is not vectorised though it uses SIMD instructions and here SKL-X only manages to be 63% faster. |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 1000 [+17%] | 852 | 422 | 571 | Again in a non-vectorised test Ryzen just flies but SKL-X manages to be 20% faster. |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 190 [+29%] | 147 | 75 | 101 | In this final non-vectorised test Ryzen really flies but not enough to beat SKL-X which is 30% faster. |
| As with other SIMD tests, SKL-X remains just over 2-times faster than Ryzen and about as fast over HSW-E. But without SIMD it drops significantly to just 20-60% showing just how good Ryzen performs. | ||||||
When using the new AVX512 instruction set – we see incredible performance with SKL-X about 3x faster than its Ryzen competitor and about 2x faster than the older HSW-E; with the older AVX2/FMA instruction sets supported by all CPUs, it is “only” about 2x faster. When using non-vectorised SIMD code its lead shortens to about 30-60%.
While we’ve not tested memory performance in this article, we see that in streaming tests its 4 DDR4 channels trounce 2-channel CPUs that just cannot feed all their cores. Being able to use much faster DDR4 memory (3200 vs 2133) allows it to also soundly beat its older HSW-E brother.
Software VM (.Net/Java) Performance
We are testing arithmetic and vectorised performance of software virtual machines (SVM), i.e. Java and .Net. With operating systems – like Windows 10 – favouring SVM applications over “legacy” native, the performance of .Net CLR (and Java JVM) has become far more important.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest Intel drivers. .Net 4.7.x (RyuJit), Java 1.8.x. Turbo / Dynamic Overclocking was enabled on both configurations.
| VM Benchmarks | i9-7900X (Skylake-X) | Ryzen 1700X | i7-6700K 4C/8T (Skylake) |
i7-5820K (Haswell-E) |
Comments | |
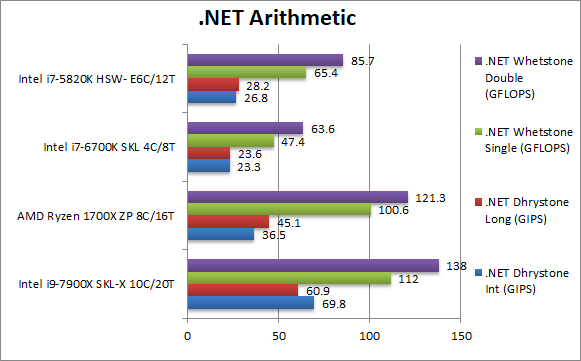 |
||||||
 |
.Net Dhrystone Integer (GIPS) | 69.8 [+1.9x] |
36.5 | 23.3 | 30.7 | While Ryzen used to dominate .Net CLR workloads, now SKL-X is 2x faster than it and naturally older HSW-E. |
|
.Net Dhrystone Long (GIPS) | 60.9 [+35%] | 45.1 | 23.6 | 28.2 | Ryzen seems to do very well here cutting SKL-X’s lead to just 35% – while still being almost 2x faster than HSW-E |
|
.Net Whetstone float/FP32 (GFLOPS) | 112 [+12%] | 100.6 | 47.4 | 65.4 | Floating-Point CLR performance is pretty spectacular with Ryzen and SKL-X only manages 12% faster. |
|
.Net Whetstone double/FP64 (GFLOPS) | 138 [+14%] | 121.3 | 63.6 | 85.7 | FP64 performance is also great (CLR seems to promote FP32 to FP64 anyway) with SKL-X just 14% faster. |
| While Ryzen used to dominate .Net workloads, SKL-X restores the balance in Intel’s favour – though in many tests it is just over 10% faster than Ryzen. The CLR definitely seems to prefer Ryzen. | ||||||
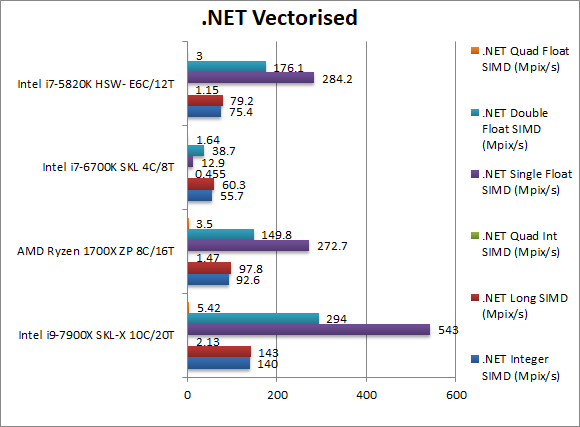 |
||||||
 |
.Net Integer Vectorised/Multi-Media (MPix/s) | 140 [+50%] | 92.6 | 55.7 | 75.4 | Just as we saw with Dhrystone, this integer workload sees a 50% improvement for SKL-X. While RiuJit supports SIMD integer vectors the lack of bitfield instructions make it slower for our code; shame. |
|
.Net Long Vectorised/Multi-Media (MPix/s) | 143 [+47%] | 97.8 | 60.3 | 79.2 | With 64-bit integer workload we see a similar story – SKL-X is about 50% faster. |
|
.Net Float/FP32 Vectorised/Multi-Media (MPix/s) | 543 [+2x] AVX/FMA | 272.7 AVX/FMA | 12.9 | 284.2 AVX/FMA | Here we make use of RyuJit’s support for SIMD vectors thus running AVX/FMA code – SKL-X strikes back to 2x faster than Ryzen. |
|
.Net Double/FP64 Vectorised/Multi-Media (MPix/s) | 294 [+2x] AVX/FMAX | 149 AVX/FMAX | 38.7 | 176.1 AVX/FMA | Switching to FP64 SIMD vector code – still running AVX/FMA – SKL-X is still 2x faster. |
| With RyuJIT’s support for SIMD vector instructions – SKL-X brings its power to bear, being the usual 2-times faster than Ryzen; it does not seem that RyuJIT supports AVX512 yet – something that will make it evern faster. With scalar instructions SKL-X is “only” 50% faster but still about 2x fasster than HSW-E. | ||||||
 |
||||||
 |
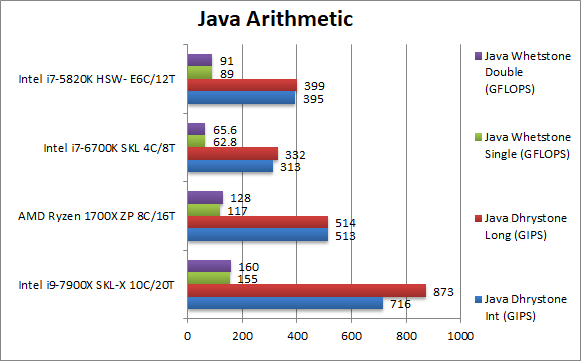
Java Dhrystone Integer (GIPS) | 716 [+39%] | 513 | 313 | 395 | Ryzen puts a strong performance with SKL-X “just” 40% faster. Still it’s almost 2x faster than HSW-E. |
|
Java Dhrystone Long (GIPS) | 873 [+70%] | 514 | 332 | 399 | Somehow SKL-X does better here with 70% faster than Ryzen. |
|
Java Whetstone float/FP32 (GFLOPS) | 155 [+32%] | 117 |
62.8 | 89 | With a floating-point workload Ryzen continues to do well so SKL-X is again “just” 30% faster. |
|
Java Whetstone double/FP64 (GFLOPS) | 160 [+25%] | 128 | 64.6 | 91 | With FP64 workload SKL-X’s lead drops to 25%. |
| With the JVM seemingly favouring Ryzen – and without SIMD – SKL-X is just 25-40% faster than it – but do note it absolutely trounces its older HSW-E brother – being almost 2x faster. So Intel has made big gains but at a cost. | ||||||
 |
||||||
 |
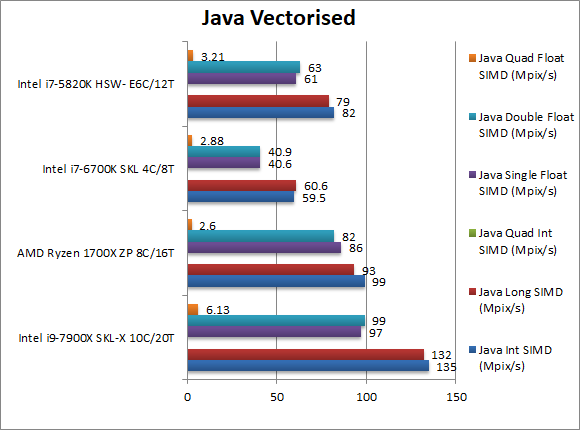
Java Integer Vectorised/Multi-Media (MPix/s) | 135 [+40%] | 99 | 59.5 | 82 | Oracle’s JVM does not yet support SIMD vectors so SKL-X is “just” 40% faster than Ryzen. |
|
Java Long Vectorised/Multi-Media (MPix/s) | 132 [+41%] | 93 | 60.6 | 79 | With 64-bit integers nothing much changes. |
|
Java Float/FP32 Vectorised/Multi-Media (MPix/s) | 97 [+13%] | 86 | 40.6 | 61 | Scary times as SKL-X manages its smallest lead over Ryzen at just over 10%.
Intel better hope Oracle will add vector primitives allowing SIMD code to use the power of its CPU’s SIMD units. |
|
Java Double/FP64 Vectorised/Multi-Media (MPix/s) | 99 [+20%] | 82 | 40.9 | 63 | With FP64 workload SKL-X is lucky to increase its lead to 20%. |
| Java’s lack of vectorised primitives to allow the JVM to use SIMD instruction sets (aka SSE2, AVX/FMA, AVX512) allows the competition to creep up on SKL-X in performance but at far lower cost. This is not a good place for Intel to be in. | ||||||
While Ryzen used to dominate .Net and Java benchmarks – SKL-X restores the balance in Intel’s favour – through both the CLR and JVM do seem to “favour” Ryzen for some reason. If you are running the older HSW-E then you can be sure SKL-X is over 2x faster than it thoughout.
Thus thus current and future applications running under CLR (WPF/Metro/UWP/etc.) as well as server JVM workloads run much better on SKL-X than older Intel designs but also reasonably well on Ryzen – at least if not using SIMD vector extensions when SKL-X’s power comes to the fore.
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
Just when AMD were likely celebrating their fantastic Ryzen, Intel strikes back with a killer – though really expensive CPU. While we’ve not seen major core advances since SandyBridge (SNB and SNB-E) and likely not even see anything new in Coffeelake (CFK) – somehow these improvements add up to quite a lot – with SKL-X soundly beating both Ryzen and its older HSW-E brother.
We finally see AVX512 released and it does not disappoint: SKL-X increases its lead by 50% through it, but note that lower-end CPUs will execute some instructions a lot slower which is unfortunate. Using AVX512 also requires new tools – either compiler which on Windows means the brand-new Visual C++ 2017 or assemblers – and decent amount of work – thus not something most developers will do – at least until the normal desktop/mobile platforms will support it too.
All in all it is a solid upgrade – though costly – but if performance you’re after you can “safely” remain with Intel – you don’t need to join the “rebel camp”. But we’ll need to see what AMD’s Threadripper has in store for us… 😉
Pingback: Intel Core i9 (SKL-X) Review and Benchmarks – Cache & Memory Performance – SiSoftware