What is “Zen4” (Ryzen 7000)?
AMD’s Zen4 (“Raphael”) is the 4rd generation ZEN core – aka the new 7000-series of CPUs from AMD – that brings brand new features like AVX512 ISA (instruction set support), DDR5 and PCIe5. These do require a brand new platform (AM5) almost a decade since the current AM4 platform was launched before even the 1st generation Ryzen. With any luck, it will remain for the next 4 or even more CPU generations, unlike the 2 generation support on competitor (Intel) platform.
Zen4 contains only big/P(erformance) cores and it is not a hybrid design. It remains to be seen if AMD will launch such hybrid (big/LITTLE) products that, in our opinion, are too problematic on desktop platforms for the benefits they bring. Even on mobile platforms where efficiency is a top priority – workloads do not easily lend to a hybrid design despite huge work done on the Windows scheduler for Windows 11. In this regard, a non-hybrid design like Zen4 is very much preferred.
AVX512 is a huge boost for compute performance as we’ve seen on Intel since SKL-X (Skylake-X). There is a reason it exists + all the extensions (IFMA, VNNI, VAES, etc.) and it is not unexpected that even basic usage can bring up to 100% (2x) performance improvement and even higher with specific instructions. While originally CPUs would reduce clocks due to the power generated – this has pretty much been mitigated in modern designs. Even Centaur (before Intel bought them) had AVX512-enabled (LITTLE) cores.
While here AMD has implemented it as 2x 256-bit ops (similar to previous AVX2/FMA3 in Zen1/1+/2 implemented as 2x 128-bit) – we still benefit from 2x more registers + 2x wider registers (4x overall), arguably better instruction specification, optimised extensions (IFMA, VNNI, VAES, etc.) that overall can still build up to a big improvement over old AVX2/FMA3.
- 5nm process (TSMC) for CCX (vs. 7nm on Zen3) for better efficiency and clocks
- 6nm process (TSMC) for I/O hub (vs. 12nm for Zen3) for better memory speeds
- claimed 13% IPC increase vs. Zen3 + clock increase uplift => ~29% total uplift vs. Zen 3
- AVX512 instruction support, with potential 100%+ improvement in optimised workloads
- Executed as 2x 256-bit (not true 512-bit like Intel) but still many benefits over AVX2/FMA3
- Specific AVX512 extensions (IFMA, VNNI, VAES, etc.) can bring well over 100% improvement
- DDR5 support up to 5200Mt/s (official) for much higher memory bandwidth vs. DDR4 Zen3
- Unofficial support for at least 6400Mt/s with XMP3/EXPO profiles
- AMD says 6000Mt/s is the “sweet-spot” for performance/value
- 1MB L2 per core (2x vs. 512kB on Zen3)
- L3 is the same at 32MB – other models will get V-Cache of 96MB
- PCIe5 support, up to 24 lanes (2x bandwidth vs. PCIe4)
- Still up to 2 chiplets (at launch) thus up to 2x 8C big/P cores (16C/32T on 7950X)
- Much higher both base and turbo speeds in most variants, e.g. 7950X
- Higher base 4.5GHz (vs. 3.4GHz on 5950X +32% clock uplift)
- Higher turbo 5.7GHz (vs. 4.9GHz on 5950X +17% clock uplift)
- TDP has been greatly increased to 170W (vs. 105W on 5950X) thus 60% higher! (ouch!)
- Turbo (PPT aka PL2) around 230W (vs. 142W on 5950X) thus 60% higher! (ouch!)
- Note that other models (e.g. 7700X) have kept the same TDP/Turbo
- Built-in Radeon Graphics (RDNA2) core
- 2CU / 128SP 400-2.2GHz cores for very basic graphics

AMD Zen4 (Ryzen 7950X, 7900X) 2x Chiplets + I/O
Review
In this article we test CPU core performance; please see our other articles on:
- AMD Ryzen 7 7800X-3D (Zen4 V-Cache) Review & Benchmarks – VCache for the Win!
- AMD Ryzen 7 7700X (Zen4 Raphael) Review & Benchmarks – AVX512 Mainstream Performance
- AMD Ryzen 5 7600X (Zen4 Raphael) Review & Benchmarks – Value AVX512 Performance
- AMD Ryzen 7 5800X-3D (Zen3 V-Cache) Review & Benchmarks – CPU Performance
Hardware Specifications
We are comparing the top-range Ryzen 7 5000-series (Zen3 8-core) with previous generation Ryzen 7 3000-series (Zen2 8-core) and competing architectures with a view to upgrading to a top-range, high performance design.
| CPU Specifications | AMD Ryzen 9 7950X 16C/32T (Zen4, Raphael) | AMD Ryzen 9 5950X 16C/32T (Zen3, Vermeer) | Intel Core i9 12900K 8C+8c/24T (ADL, AlderLake) |
Intel Core i9 11900K 8C/16T (RKL, RocketLake) |
Comments | |
| Cores (CU) / Threads (SP) | 16C /32T | 16C / 32T | 8C+8c / 24T | 8C/16T | Core counts remain the same. | |
| Topology | 1 chiplet, 2 CCX, each 8 core (16C) + I/O hub | 1 chiplet, 2 CCX, each 8 core (16C) + I/O hub | Monolithic die | Monolithic die | Same topology | |
| Speed (Min / Max / Turbo) (GHz) |
4.5 [+32%] / 5.7GHz [+17%] |
3.4 / 4.9GHz | 3.9 + 2.4 / 5.2Ghz + 3.2Ghz | 3.5 / 5.3GHz | Base is 32% higher, turbo 16% | |
| Power (TDP / Turbo) (W) |
170 / 230W (PPT) [+61%] | 105 / 142W (PPT) | 125 / 241W (PL2) | 125 / 190W (PL2) | TDP is 60% higher but competitive | |
| L1D / L1I Caches (kB) |
16x 32kB 8-way / 16x 32kB 8-way | 16x 32kB 8-way / 16x 32kB 8-way | 8x 64kB + 8x 32kB / 8x 32kB + 8x 48kB | 8x 64kB + 8x 32kB | No changes to L1 | |
| L2 Caches (MB) |
16x 1MB (16MB) 8-way inclusive [+2x] | 16x 512kB (8MB) 8-way inclusive | 8x 1.25MB + 2x 2MB [14MB] | 8x 512MB [4MB] | L2 is 2x larger | |
| L3 Caches (MB) |
2x 32MB (64MB) 16-way exclusive |
2x 32MB (64MB) 16-way exclusive | 30MB 16-way | 16MB 16-way | L3 is the same | |
| Mitigations for Vulnerabilities | BTI/”Spectre”, SSB/”Spectre v4″ hardware | BTI/”Spectre”, SSB/”Spectre v4″ hardware | BTI/”Spectre”, SSB/”Spectre v4″ hardware | BTI/”Spectre”, SSB/”Spectre v4″ software/firmware | No new fixes required… yet! | |
| Microcode (MU) |
A60F12-03 | A20F10-09 | 090672-15 | 06A701-50 | The latest microcodes have been loaded. | |
| SIMD Units | 2x 256-bit (512-bit total) AVX512+ | 256-bit AVX/FMA3/AVX2 | 256-bit AVX/FMA3/AVX2 | 512-bit [1 Unit] AVX512+ | 2x wider SIMD | |
| Price/RRP (USD) |
$699 [-13%] |
$799 | $589 | $539 | Price is even 13% lower | |
Disclaimer
This is an independent review (critical appraisal) that has not been endorsed nor sponsored by any entity (e.g. AMD, etc.). All trademarks acknowledged and used for identification only under fair use.
The review contains only public information and not provided under NDA nor embargoed. At publication time, the products have not been directly tested by SiSoftware but submitted to the public Benchmark Ranker; thus the accuracy of the benchmark scores cannot be verified, however, they appear consistent and pass current validation checks.
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets. Zen4 supports all modern instruction sets including AVX2/FMA3 and crypto SHA HWA but also AVX-512 and extensions (IFMA, VNNI, VAES, etc.)
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 11 x64 (21H2), latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations. All mitigations for vulnerabilities (Meltdown, Spectre, L1TF, MDS, etc.) were enabled as per Windows default where applicable.
| Native Benchmarks | AMD Ryzen 9 7950X 16C/32T (Zen4, Raphael) | AMD Ryzen 9 5950X 16C/32T (Zen3, Vermeer) | Intel Core i9 12900K 8C+8c/24T (ADL, AlderLake) | Intel Core i9 11900K 8C/16T (RKL, RocketLake) | Comments | |
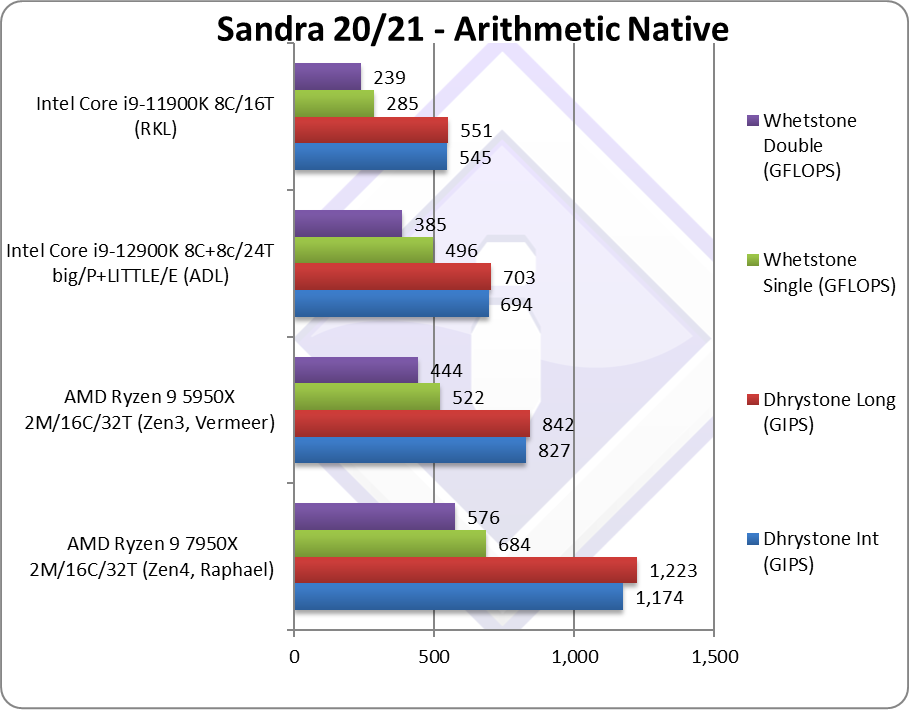 |
||||||
 |
Native Dhrystone Integer (GIPS) | 1,174 [+42%] | 827 | 694 | 545 | Zen4 is 42% faster than Zen3! |
|
Native Dhrystone Long (GIPS) | 1,223 [+45%] | 842 | 703 | 551 | With a 64-bit integer workload, we’re just as fast |
|
Native FP32 (Float) Whetstone (GFLOPS) | 684 [+31%] | 522 | 496 | 285 | Floating-point performance is 31% faster |
|
Native FP64 (Double) Whetstone (GFLOPS) | 576 [+30%] | 444 | 385 | 239 | With FP64 we’re 30% faster |
| Zen4 starts off with some incredible numbers: 42% faster in legacy integer and 30% faster in legacy floating-point – and that is before using any AVX512! The much improved turbo frequencies and ALU/FPU improvements seem to make a big improvement here. All code should benefit from this – no vectorisation necessary nor the use of AVX512 – Zen4 flies with ordinary code.
Intel’s ADL is also left in the dust – RPL (RaptorLake) better bring some impressive improvements to keep it in the game. |
||||||
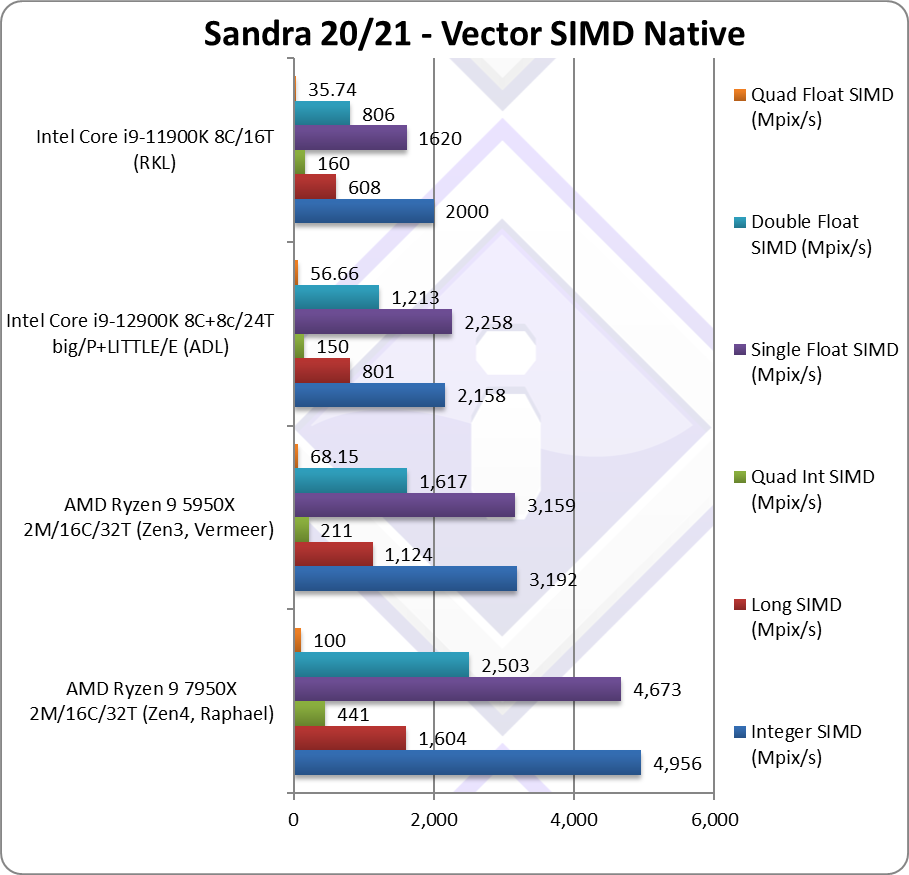 |
||||||
 |
Native Integer (Int32) Multi-Media (Mpix/s) | 4,956* [+55%] | 3,192 | 2,158 | 2,000* | Zen4 with AVX512 is 55% faster than Zen3! |
|
Native Long (Int64) Multi-Media (Mpix/s) | 1,604* [+42%] | 1,124 | 801 | 608* | With a 64-bit integer workload still 42% faster. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 441* [+2.1x] | 211 | 150 | 160* | Using IFMA of AVX512, Zen4 is 2.1x faster than Zen3! |
|
Native Float/FP32 Multi-Media (Mpix/s) | 4,673* [+48%] | 3,159 | 2,258 | 1,620* | In this floating-point test, Zen4 is 48% faster! |
|
Native Double/FP64 Multi-Media (Mpix/s) | 2,503* [+55%] | 1,617 | 1,213 | 806 | Switching to FP64 code, Zen 4 is 55% faster |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 100* [+47%] | 68.15 | 56.66 | 35.74* | Using FP64 to mantissa extend FP128, Zen 4 is 47% faster |
| Even in heavy compute SIMD vectorised algorithms we see the same results, Zen4 with AVX512 demolishes everything in its path – and is overall 60% faster than Zen3 with one test (IFMA/AVX512) over 2.1x faster.
We did expect Zen4 to do well but it is good to see it realised – true to their word, AMD has launched a powerhouse of a CPU that demolishes everything in its path. Both Zen3 and Intel ADL, RKL are left in the dust. Intel seems to have little chance without AVX512 support in ADL/RPL. Note*: using AVX512 instead of AVX2/FMA. |
||||||
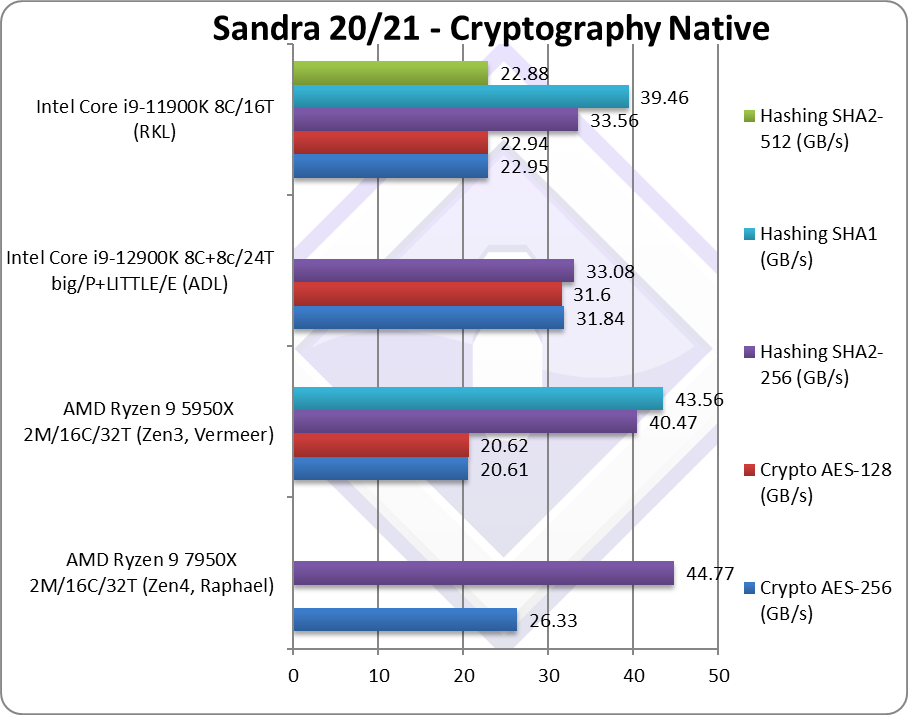 |
||||||
 |
Crypto AES-256 (GB/s) | 26.33*** [+28%] | 20.61*** | 31.84*** | 22.95*** | Zen4 is 28% faster than Zen3 |
|
Crypto AES-128 (GB/s) | 20.62*** | 31.6*** | 22.94*** | What we saw with AES-256 just repeats with AES-128. | |
|
Crypto SHA2-256 (GB/s) | 44.77* [+21%] | 40.47** | 33.08** | 33.56* | With SHA, Zen4 is 11% faster |
|
Crypto SHA1 (GB/s) | 43.56** | 39.46* | The less compute-intensive SHA1 does not change things due to acceleration. | ||
| While streaming tests (crypto/hashing) are memory bound, Zen4 is 30% faster than Zen3 due to DDR5 memory. It would likely be even faster if even faster memory was being used.
AVX512 does help with hashing performance (11% faster than Zen3) – but since all processors have SHA hardware acceleration the improvement is more modest than it would have been otherwise. Still 11% is nothing to be ashamed of and will also improve with memory bandwidth. Note***: using VAES 256-bit (AVX2) or 512-bit (AVX512) Note**: using SHA HWA not SIMD (e.g. AVX512, AVX2, AVX, etc.) Note*: using AVX512 not AVX2. |
||||||
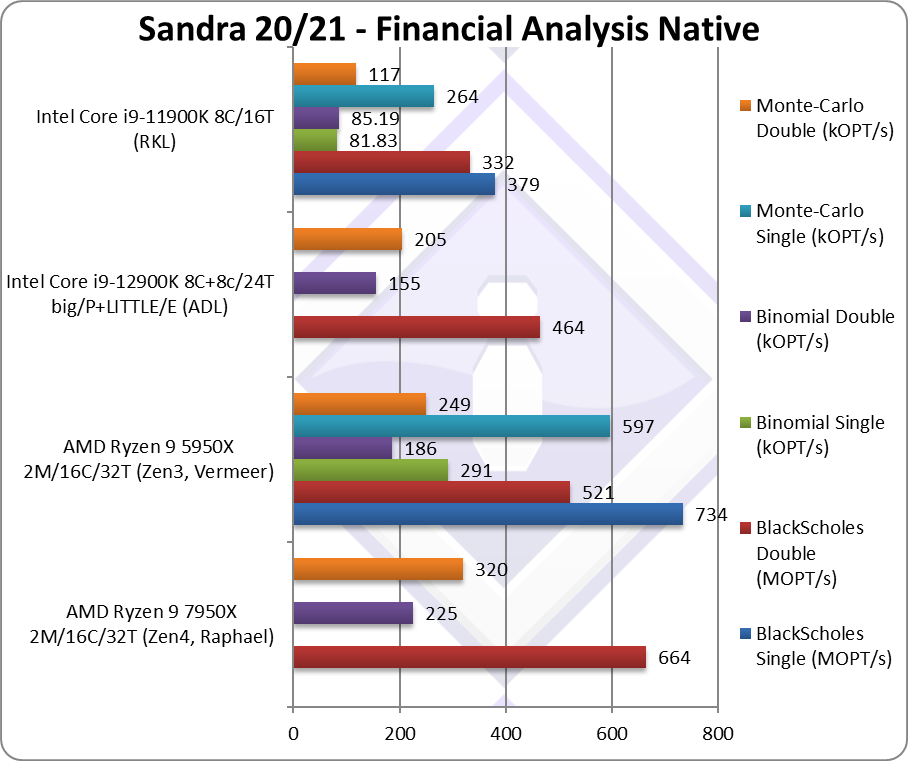 |
||||||
 |
Black-Scholes float/FP32 (MOPT/s) | – | 734 | – | 379 | The standard financial algorithm. |
|
Black-Scholes double/FP64 (MOPT/s) | 664 [+27%] | 521 | 464 | 332 | Switching to FP64 code, Zen4 is 27% faster |
|
Binomial float/FP32 (kOPT/s) | – | 291 | – | 81.83 | Binomial uses thread shared data thus stresses the cache & memory system; |
|
Binomial double/FP64 (kOPT/s) | 225 [+21%] | 186 | 155 | 85.19 | With FP64 code Zen4 is 21% faster. |
|
Monte-Carlo float/FP32 (kOPT/s) | – | 597 | – | 264 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches |
|
Monte-Carlo double/FP64 (kOPT/s) | 320 [+29%] | 249 | 205 | 117 | Here Zen4 is 29% faster |
| Ryzen always did well on non-SIMD floating-point algorithms and as we’ve seen in the legacy benchmarks (Dhrystone/Whetstone) Zen4 does not disappoint – it is 27-88% faster than Zen3 – and there is no SIMD/AVX512 in sight.
Again, it is nice to see Zen4 improving on normal, non-SIMD code, while we expected great things from AVX512 we just did not expect how much better it would perform on ordinary code also. |
||||||
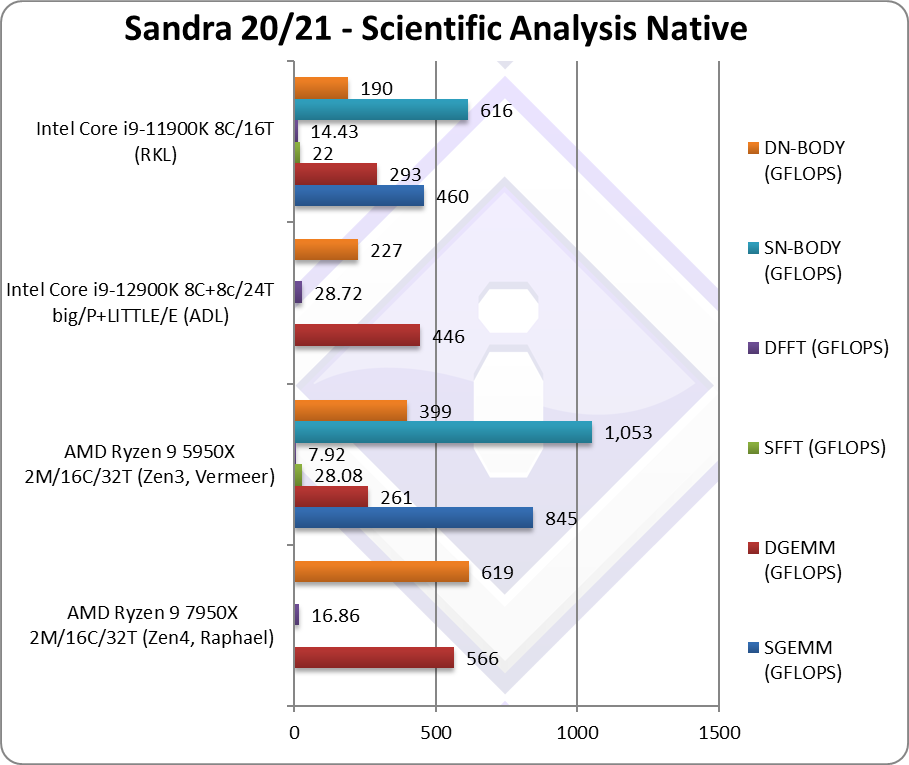 |
||||||
 |
SGEMM (GFLOPS) float/FP32 | – | 845 | – | 460* | In this tough vectorised algorithm that is widely used (e.g. AI/ML). |
|
DGEMM (GFLOPS) double/FP64 | 566* [+2.17x] | 261 | 446 | 293* | With FP64 Zen4 is 2.1x faster |
|
SFFT (GFLOPS) float/FP32 | – | 28.08 | – | 22* | FFT is also heavily vectorised but stresses the memory sub-system more. |
|
DFFT (GFLOPS) double/FP64 | 16.86* [+2.1x] | 7.92 | 28.72 | 14.43* | With FP64 code, Zen4 is memory latency bound |
|
SNBODY (GFLOPS) float/FP32 | – | 1,053 | – | 616* | N-Body simulation is vectorised but fewer memory accesses. |
|
DNBODY (GFLOPS) double/FP64 | 619* [+55%] | 399 | 227 | 190* | With FP64 Zen4 is 55% faster. |
| As we’ve seen in SIMD benchmarks, Zen4 is 50-100% faster than Zen3 on most algorithms that will see it powering through algorithms with little performance problems.
Here, faster DDR5 memory will make a big difference. AMD themselves said that DDR5-6000 memory is the “sweet-spot” and with such speeds Zen4 will perform much better. Note*: using AVX512 not AVX2/FMA3. |
||||||
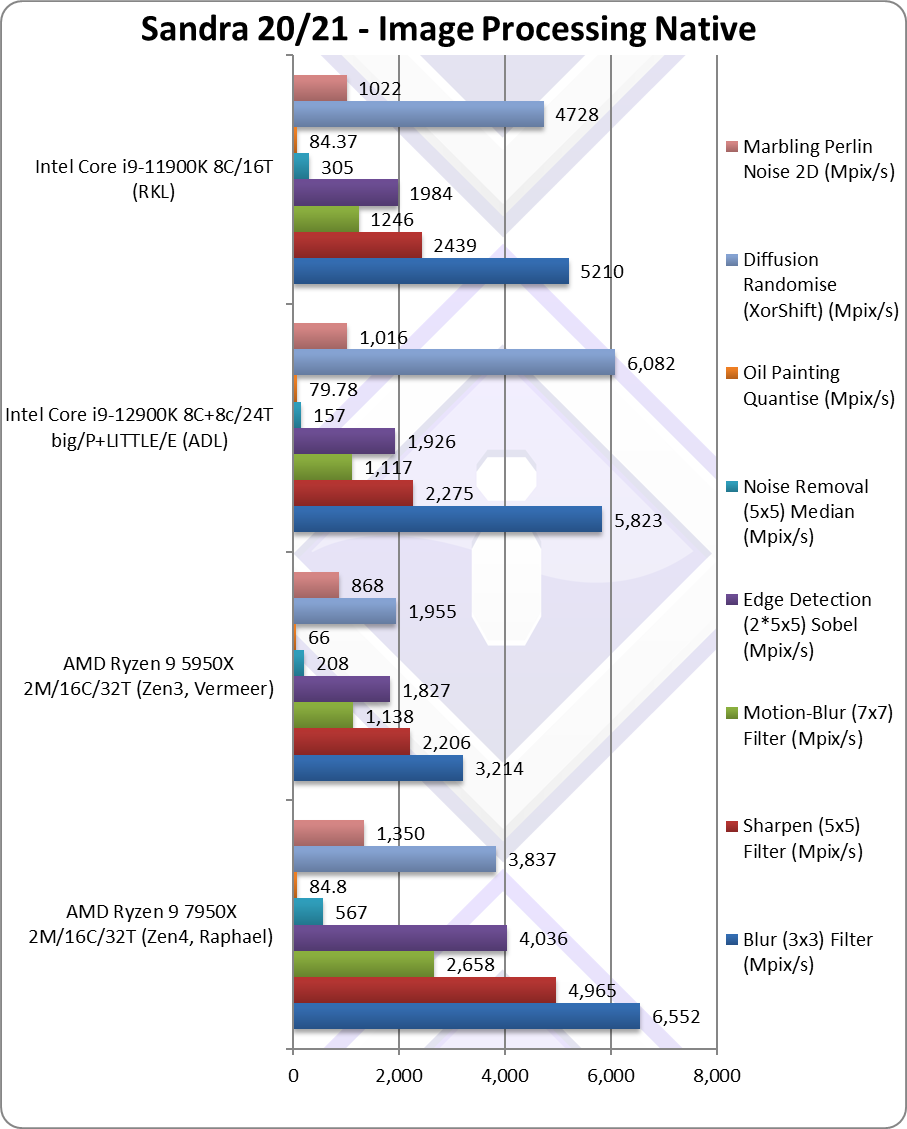 |
||||||
 |
Blur (3×3) Filter (MPix/s) | 6,552* [+2x] | 3,214 | 5,823 | 5,210* | In this vectorised integer Zen4 is 2x faster! |
|
Sharpen (5×5) Filter (MPix/s) | 4,965* [+2.25x] | 2,206 | 2,275 | 2,439* | Same algorithm but more shared data 2.25 faster |
|
Motion-Blur (7×7) Filter (MPix/s) | 2,658* [+2.34x] | 1,138 | 1,117 | 1,246* | Again same algorithm but even more data shared – 2.34x faster! |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 4,036* [+2.2x] | 1,827 | 1,926 | 1,984* | Different algorithm Zen4 is 2.2x faster. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 567* [+2.7x] | 208 | 157 | 305* | Still vectorised code Zen4 i 2.7x faster. |
|
Oil Painting Quantise Filter (MPix/s) | 84.8* [+28%] | 66 | 79.78 | 84.37* | This test has always been tough Zen4 is 28% faster. |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 3,837* [+96%] | 1,955 | 6,082 | 4,728* | With integer workload, Zen4 is 96% faster. |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 1,350* [+56%] | 868 | 1,016 | 1,022* | In this final test we see Zen4 56% faster. |
| AVX512 really loves this benchmark – and here Zen4 is on average 2x faster across the 8 tests, with one test 30% faster and one test 2.7x faster. These are pretty fantastic improvements that ensure Zen4 also beats the Intel ADL competition – though Intel stays competitive in some tests.
With heavy compute vectorised AVX512 code, there is no better CPU to be had at this time. Intel will have to bring AVX512 back pretty quickly if it wants to stay competitive. Note*: using AVX512 not AVX2/FMA3. |
||||||
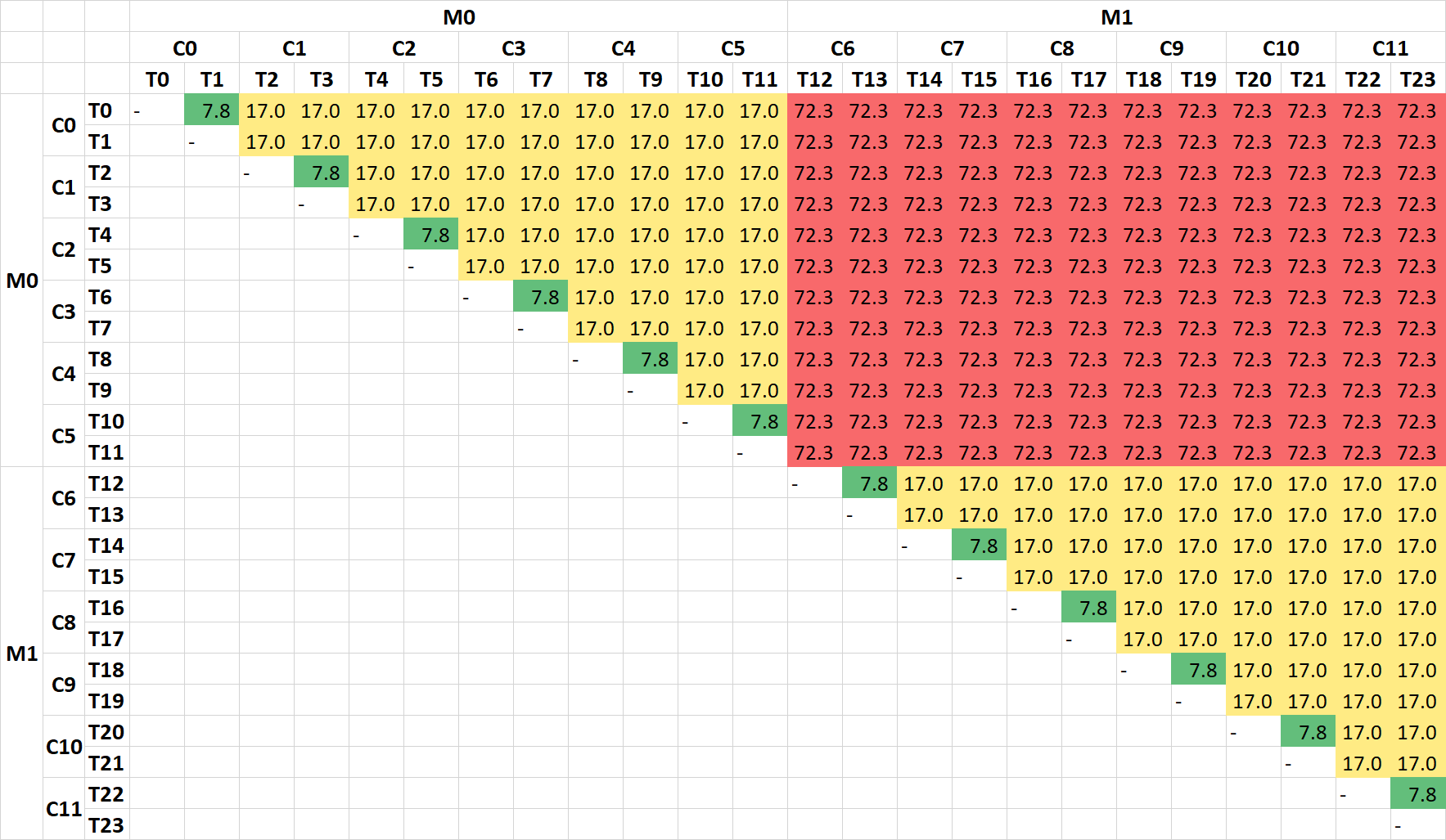 Inter-Thread/Core/CCX Latency Heatmap (ns) – AMD 7900X |
||||||
| The inter-thread/core/module latencies “heat-map” shows how the latencies vary when transferring data off-thread (same L1D), off-core (same L3) or off-module/CCX (through memory). As 7950X has 2x CCX/modules, there are 3 types of latencies.
Judicious thread-pair scheduling is needed to keep latencies low (and conversely bandwidth high when large data is transferred. |
||||||
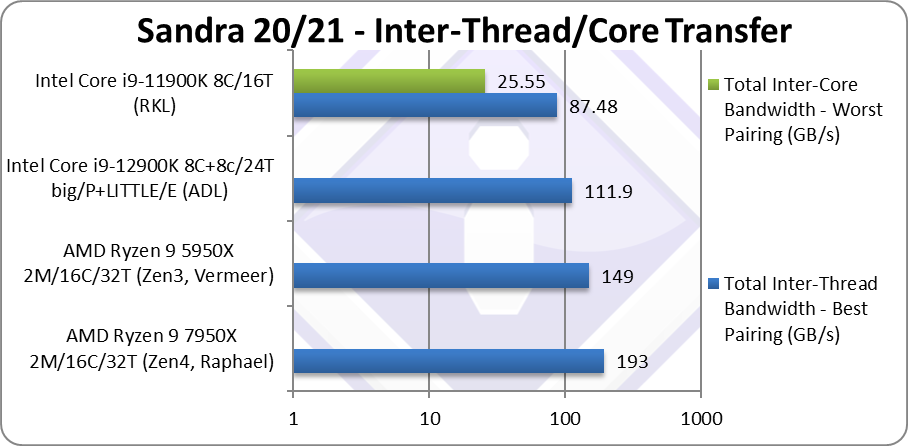 |
||||||
 |
Total Inter-Thread Bandwidth – Best Pairing (GB/s) | 193* [+30%] | 149 | 111 | 87.48* | Zen4 has 30% more bandwidth than Zen3. |
| While L1D and L3 stay the same, AVX512 and the double size L2 (1MB vs. 512kB on Zen3) allow Zen4 30% more bandwidth than Zen3 that is a decent improvement.
The 3D-VCache versions with huge L3 caches are likely to further improve bandwidth by about 10% over this. It remains to be seen if we will see even bigger VCaches. Note:* using AVX512 512-bit wide transfers. |
||||||
 |
||||||
|
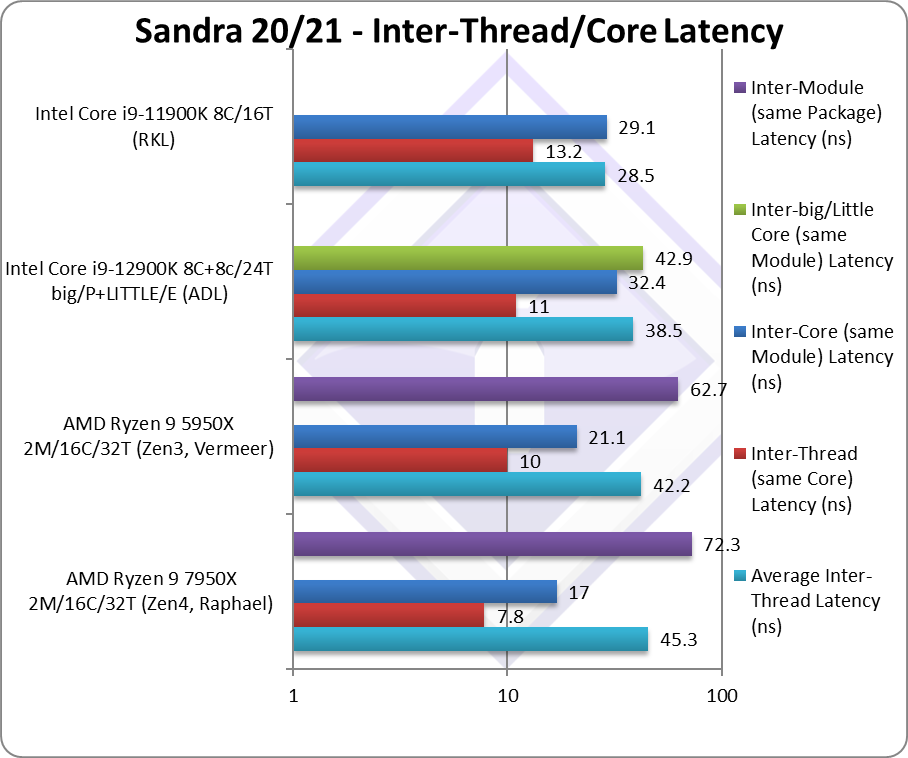
Average Inter-Thread Latency (ns) | 45.3 [+7%] | 42.2 | 38.5 | 28.5 | Overall latencies are up 7% |
|
Inter-Thread Latency (Same Core) Latency (ns) | 7.8 [-22%] | 10 | 11 | 13.2 | Inter-module is 22% faster on Zen4 |
|
Inter-Core Latency (big Core, same Module) Latency (ns) | 17 [-19%] | 21.1 | 32.4 | 29.1 | We see 19% reduced latencies |
|
Inter-Core (Little Core, same Module) Latency (ns) | – | – | 42.9 | – | n/a |
|
Inter-Module/CCX Latency (ns) | 72.3 [+15%] | 62.7 | 68.1 | – | We see increased inter-CCX latency. |
| Running at higher clocks, the inter-thread and inter-core latencies are ~20% less on Zen4 vs. Zen3. We do see an increased in inter-CCX/module latencies of 15% with increases the overall latency by 7%.
This increase in inter-CCX/module is likely due to the inter-CCX link speed that seems to be lower on Zen4 than Zen3. Most likely a configuration issue that can be fixed. |
||||||
 |
||||||
 |
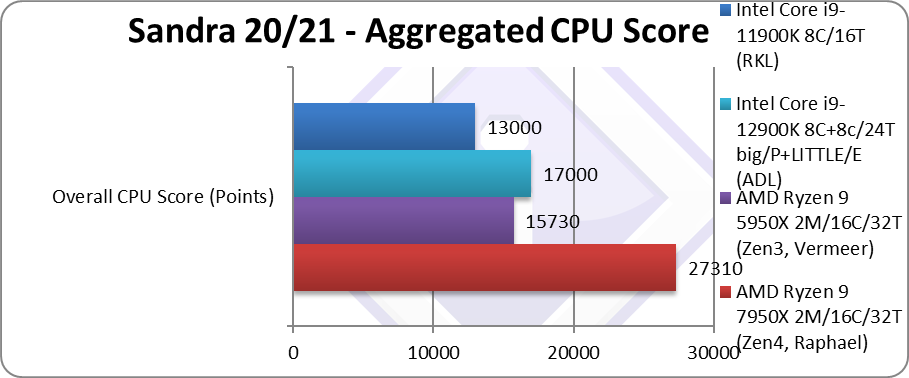
Aggregate Score (Points) | 27,310* [+74%] | 15,730 | 17,000 | 13,000* | Across all benchmarks, Zen4 is 74% faster! |
| Across all the benchmarks – Zen4 ends up an astonishing 74% faster than Zen3 (7950X vs. 5950X) which is a spectacular improvement not seen since the introduction of the original Ryzen (Zen1).
It is not really unexpected, with AVX512 support included (even when executed in 256-bit chunks) brings good performance improvement, maybe not as high as on Intel (with native 512-bit) but still far improved over old AVX2/FMA3 256-bit SIMD. Note*: using AVX512 instead of AVX2/FMA3. |
||||||
 |
||||||
 |
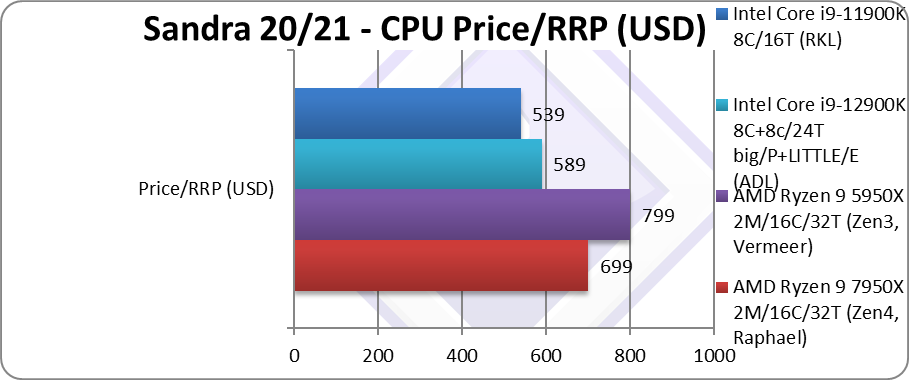
Price/RRP (USD) | $699 [-13%] | $799 | $589 | $539 | Even the price is 13% lower! |
 |
||||||
|
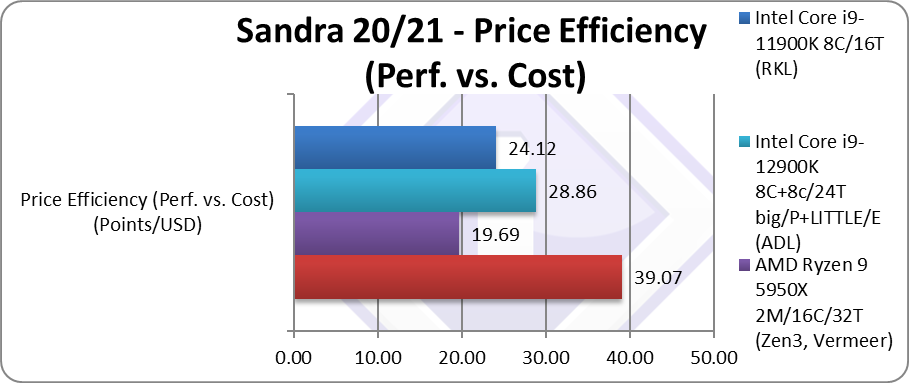
Price Efficiency (Perf. vs. Cost) (Points/USD) | 39.07 [+2x] | 19.69 | 28.86 | 24.12 | Overall 2x more performance for the price |
| As AMD has even reduced the launch price – Zen4 (7950X) ends up 100% more price efficient (aka 2x) than Zen3 (5950X) and about 50% more efficient than Intel’s ADL. There is nothing that has the same “bang-for-buck” performance – Intel would have to reduce prices or greatly improve performance to compete.
Note that Zen3 (5950X) isn’t really very price efficient – while performance is naturally great, the Intel CPUs are far better value for money. |
||||||
 |
||||||
 |
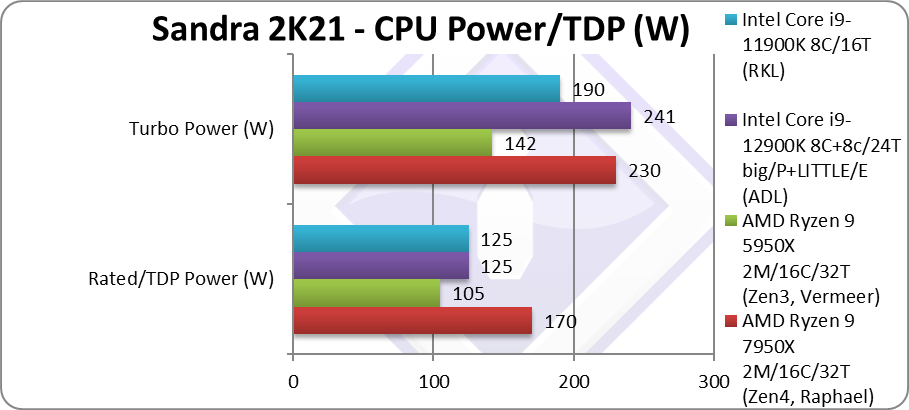
Power/TDP (W) | 170 – 230W [+62%] | 105 – 142W | 125 – 241W | 125 – 190W | TDP has gone up by a large 62%! |
 |
||||||
|
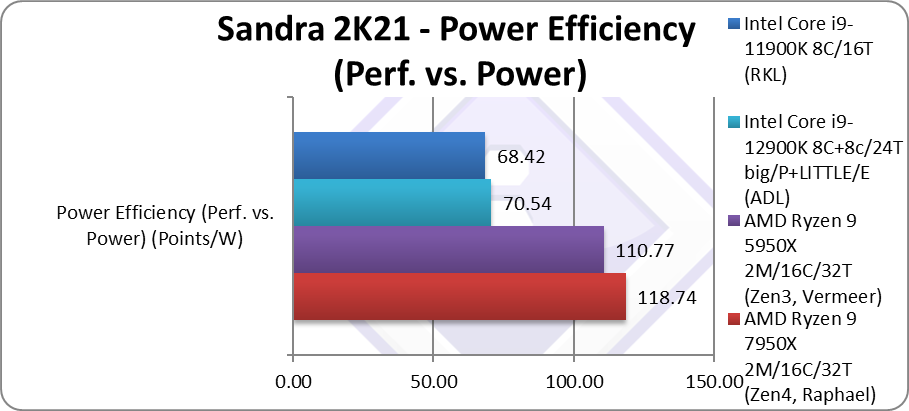
Power Efficiency (Perf. vs. Power) (Points/W) | 118 [+7%] | 110 | 70.54 | 68.42 | Zen4 is still 7% more efficient |
| Unfortunately, the big turbo power increase (230W vs. 142W Zen3) means the power efficiency of Zen4 is just 7% over Zen3. Still it is an improvement and the turbo power is about the same as the Intel ADL competition (241W) and possibly much lower than Intel’s future RPL (~250W).
By disabling/not-using AVX512 it is possible to reduce turbo power and thus make Zen4 more power efficient similar to Intel’s previous AVX512-enabled CPUs. |
||||||
SiSoftware Official Ranker Scores
- AMD Ryzen 9 7950X 16-Core / 32-Thread
- AMD Ryzen 9 7900X 12-Core / 24-Thread
- AMD Ryzen 7 7700X 8-Core / 16-Thread
- AMD Ryzen 5 7600X 6-Core / 12-Thread
Final Thoughts / Conclusions
Summary: A powerhouse of a CPU (AMD Ryzen 7950X): 10/10!
Ever since Ryzen (Zen1) AMD has been hitting winners – with Zen2 (series 2000) and Zen3 (series 5000) bringing decent performance improvements – while still using the same AM4 platform (with BIOS updates). While some features (e.g. PCIe4, USB 3.2, etc.) may not be supported by old mainboards, you could still have gone from a 1st gen Ryzen to series 5000 16C/32T monster on the same platform; thus you’d be going to the very top of desktop performance beating anything the competition (Intel) had released on their latest platform.
AMD had to finally refresh the platform in order to bring new technologies support – DDR5 primarily, but also PCIe5, USB 4.0 – and they could have easily just stuck with that. But, no, AMD has instead brought a pretty revolutionary Zen4 – bringing AVX512 512-bit SIMD support just when Intel has dropped them in their latest hybrid designs (ADL, RPL).
However, both due to increased clocks and core improvements, even legacy code flies – all code is between 30% to 100% (2x) faster (7950X) than Zen3 (5950X) and thus also beats the Intel ADL competition (albeit with just 8 big/P Cores) into dust. The 8 LITTLE/E Atom cores are just not enough, ADL needs more big/P Cores to compete. Even with AVX512 implemented as 2x 256-bit, the new Zen4 instruction support provides sufficient performance improvement.
Price wise, if we’re talking the top end (7950X) this is 13% launch price cheaper – ending up 2x better value than the previous top-of-the-range (5950X) which is great value for money. Intel will have to reduce prices quite drastically to compete at least in the short term.
Our only negative is the greatly increased TDP (170W vs. 105W on Zen3 +60%) – although the turbo power (~240W PPT/PL2) is similar to Intel’s ADL (AlderLake) and likely (from rumours) still less than Intel’s future RPL (RaptorLake). Likely this is what allows Zen4 with 12-16C to perform much better vs. Zen3 that had the same TDP/PPT as the lower end models.
A new AM5 mainboard is required – but hopefully it will last you many more updates than the competition – possibly Zen7 (!) with 64C/128T (!) if things progress in the same manner we’ve seen until now. DDR5 memory has come down somewhat by now and brings much needed memory bandwidth improvements and USB 4.0 is very much needed for (very) high speed external devices. Not to mention PCIe5 support for future NVMe and GP-GPU components.
“Good things come to those who wait” it is said; in this case AMD has definitely delivered!
It did not have to be like this: if Intel had launched a 16-“big/P Core” AVX512-enabled ADL (AlderLake) – would be very competitive with Zen4; alas just 8 big Cores + 8 LITTLE Atom cores without AVX512 are not going to do it. With SIMD/AVX2 code 4 LITTLE/E Atom cores are just about faster than 1 big/P Core thus even 16 of them (as with RPL (RaptorLake)) won’t have enough compute performance to match Zen4 cores.
We will have to see how Intel responds to this – hopefully with more than just more LITTLE/E Atom cores. As consumers, we do need them to be competitive – otherwise we will see greatly increased prices even from the “underdog” as we have seen in the past.
Summary: A powerhouse of a CPU (AMD Ryzen 7950X): 10/10!
Please see the other reviews on the other Zen variants:
- AMD Ryzen 7 7800X-3D (Zen4 V-Cache) Review & Benchmarks – VCache for the Win!
- AMD Ryzen 7 7700X (Zen4 Raphael) Review & Benchmarks – AVX512 Mainstream Performance
- AMD Ryzen 5 7600X (Zen4 Raphael) Review & Benchmarks – Value AVX512 Performance
- AMD Ryzen 7 5800X-3D (Zen3 V-Cache) Review & Benchmarks – CPU Performance
Disclaimer
This is an independent review (critical appraisal) that has not been endorsed nor sponsored by any entity (e.g. AMD, etc.). All trademarks acknowledged and used for identification only under fair use.
The review contains only public information and not provided under NDA nor embargoed. At publication time, the products have not been directly tested by SiSoftware but submitted to the public Benchmark Ranker; thus the accuracy of the benchmark scores cannot be verified, however, they appear consistent and pass current validation checks.