What is “Zen4” (Ryzen 7000)?
AMD’s Zen4 (“Raphael”) is the 4rd generation ZEN core – aka the new 7000-series of CPUs from AMD – that brings brand new features like AVX512 ISA (instruction set support), DDR5 and PCIe5. These do require a brand new platform (AM5) almost a decade since the current AM4 platform was launched before even the 1st generation Ryzen. With any luck, it will remain for the next 4 or even more CPU generations, unlike the 2 generation support on competitor (Intel) platform.
Zen4 contains only big/P(erformance) cores and it is not a hybrid design. It remains to be seen if AMD will launch such hybrid (big/LITTLE) products that, in our opinion, are too problematic on desktop platforms for the benefits they bring. Even on mobile platforms where efficiency is a top priority – workloads do not easily lend to a hybrid design despite huge work done on the Windows scheduler for Windows 11. In this regard, a non-hybrid design like Zen4 is very much preferred.
AVX512 is a huge boost for compute performance as we’ve seen on Intel since SKL-X (Skylake-X). There is a reason it exists + all the extensions (IFMA, VNNI, VAES, etc.) and it is not unexpected that even basic usage can bring up to 100% (2x) performance improvement and even higher with specific instructions. While originally CPUs would reduce clocks due to the power generated – this has pretty much been mitigated in modern designs. Even Centaur (before Intel bought them) had AVX512-enabled (LITTLE) cores.
While here AMD has implemented it as 2x 256-bit ops (similar to previous AVX2/FMA3 in Zen1/1+/2 implemented as 2x 128-bit) – we still benefit from 2x more registers + 2x wider registers (4x overall), arguably better instruction specification, optimised extensions (IFMA, VNNI, VAES, etc.) that overall can still build up to a big improvement over old AVX2/FMA3.
- 5nm process (TSMC) for CCX (vs. 7nm on Zen3) for better efficiency and clocks
- 6nm process (TSMC) for I/O hub (vs. 12nm for Zen3) for better memory speeds
- claimed 13% IPC increase vs. Zen3 + clock increase uplift => ~29% total uplift vs. Zen 3
- AVX512 instruction support, with potential 100%+ improvement in optimised workloads
- Executed as 2x 256-bit (not true 512-bit like Intel) but still many benefits over AVX2/FMA3
- Specific AVX512 extensions (IFMA, VNNI, VAES, etc.) can bring well over 100% improvement
- DDR5 support up to 5200Mt/s (official) for much higher memory bandwidth vs. DDR4 Zen3
- Unofficial support for at least 6400Mt/s with XMP3/EXPO profiles
- AMD says 6000Mt/s is the “sweet-spot” for performance/value
- 1MB L2 per core (2x vs. 512kB on Zen3)
- Standard L3 is the same 32MB, V-Cache the same 96MB
- PCIe5 support, up to 24 lanes (2x bandwidth vs. PCIe4)
- Still up to 2 chiplets (at launch) thus up to 2x 8C big/P cores (16C/32T on 7950X)
- Much higher both base and turbo speeds in most variants, e.g. 7950X
- Higher base 4.5GHz of standard CCX (vs. 3.4GHz on 5950X +32% clock uplift)
- Higher base 4.2GHz of V-Cache CCX (vs. 3.4GHz on 5950X +24% clock uplift)
- Higher turbo 5.7GHz (vs. 4.9GHz on 5950X +17% clock uplift)
- TDP has increased to 120W (vs. 105W on 5950X) thus 14% higher
- Turbo (PPT aka PL2) around 160W (vs. 142W on 5950X) thus 14% higher
- Note that other models (e.g. 7700X) have kept the same TDP/Turbo
- Built-in Radeon Graphics (RDNA2) core
- 2CU / 128SP 400-2.2GHz cores for very basic graphics

AMD Zen4-3D (Ryzen 7950X-3D), V-Cache CCX + Standard CCX + I/O
What is the new Zen4-3D V-Cache (Ryzen 7000-3D)?
It is a version of Zen4+ chiplet/CCX with vertically stacked (thus the 3D(imensions) moniker) L3 cache that is 3x larger (thus 96MB). The latency is expected to be slightly higher (+4 clock) and bandwidth also slightly lower (~10% less).
But, unlike Zen3-3D which had a single chiplet/CCX with this large cache – the Zen4-3D models (launched so far) have 2 chiplet/CCX: one with 96MB L3/V-Cache and one with 32MB L3/standard cache. This asymmetric design – that we could call “hybrid” as the chiplet/CCX are different in both size (L3) and speed (clocks).
Similar to Zen3-3D – the clocks (Base) of the cores on the V-Cache CCX (5.25GHz) are lower than the standard CCX (5.7GHz).
To upgrade from standard Zen4 or not?
Except the new L3 3D/V-Cache cache, there are no other major changes:
- Minor stepping update (S2 vs. S0) with no major fixes
- Base and Turbo clocks of standard CCX are the same as original Zen4 (e.g. 7950X)
- Base clocks of V-Cache CCX are lower than original Zen4, thus raw compute power is lower
- AMD provided Windows driver to migrate threads to the “proper” CCX while parking other CCX
- Games scheduled on V-Cache/slow CCX
- Normal workloads scheduled on standard/fast CCX
- This assumes the workload uses 16-threads or less
It all depends on the data set(s) of the workload(s) you are running:
- Data sets that either entirely fit or can be significantly served in the 96MB L3 cache – will see significant uplift
- Inter-core/thread data transfers that can entirely fit in the 3D L3 cache – will see significant uplift
- Streaming workloads or with very large data sets may not show uplift but be slower due to lower base/turbo clocks
- Compute heavy algorithms with small data sets will be slower due to lower base/turbo clocks
Review
In this article we test CPU core performance; please see our other articles on:
- AMD Ryzen 7 7800X-3D (Zen4 V-Cache) Review & Benchmarks – VCache for the Win!
- AMD Ryzen 9 7950X (Zen4 Raphael) Review & Benchmarks – AVX512 Top-End Domination
- AMD Ryzen 7 7700X (Zen4 Raphael) Review & Benchmarks – AVX512 Mainstream Performance
- AMD Ryzen 5 7600X (Zen4 Raphael) Review & Benchmarks – Value AVX512 Performance
Hardware Specifications
We are comparing the top-range Ryzen 9 7000-series (Zen4 3D) with standard Ryzen 9 and competing architectures with a view to upgrading to a top-range, high performance design.
| CPU Specifications | AMD Ryzen 9 7950X-3D 16C/32T (Raphael-3D) |
AMD Ryzen 9 7950X 16C/32T (Raphael) | AMD Ryzen 7 5800X-3D 8C/16T (Vermeer-3D) | Intel Core i9 12900K 8C+8c/24T (ADL, AlderLake) | Comments | |
| Cores (CU) / Threads (SP) | 2M / 16C / 32T | 2M / 16C / 32T | 8C / 16T | 8C+8c / 24T | Core counts remain the same. | |
| Topology | 2 chiplet, 3D/CCX + CCX, each 8 core (16C) + I/O hub | 2 chiplet, 2 CCX, each 8 core (16C) + I/O hub | 1 chiplet, 1 3D/CCX, each 8 core (8C) + I/O hub | Monolithic die | Same topology but asymmetric | |
| Speed (Min / Max / Turbo) (GHz) |
4.2 / 5.25 + 5.7GHz [-7%] | 4.5 / 5.7GHz | 3.4 / 4.5GHz | 3.9 + 2.4 / 5.2GHz + 3.2GHz | Base 7% lower | |
| Power (TDP / Turbo) (W) |
120 / 160W (PPT) [-30%] | 170 / 230W (PPT) | 105 / 135W (PPT) | 125 / 240W (PL2) | TDP 30% lower | |
| L1D / L1I Caches (kB) |
16x 32kB 8-way / 16x 32kB 8-way | 16x 32kB 8-way / 16x 32kB 8-way | 8x 32kB 8-way / 8x 32kB 8-way | 8x 64kB + 8x 32kB / 8x 32kB + 8x 48kB | No changes to L1 | |
| L2 Caches (MB) |
16x 1MB (16MB) 8-way inclusive | 16x 1MB (16MB) 8-way inclusive | 8x 512kB (4MB) 8-way inclusive | 8x 1.25MB + 2x 2MB [14MB] | No changes to L2 | |
| L3 Caches (MB) |
96MB + 32MB (128MB) 16-way exclusive [+2x] |
2x 32MB (64MB) 16-way exclusive | 96MB 16-way exclusive [+3x] | 30MB 16-way | 2x larger L3 | |
| Mitigations for Vulnerabilities | BTI/”Spectre”, SSB/”Spectre v4″ hardware | BTI/”Spectre”, SSB/”Spectre v4″ hardware | BTI/”Spectre”, SSB/”Spectre v4″ hardware | BTI/”Spectre”, SSB/”Spectre v4″ hardware | No new fixes required… yet! | |
| Microcode (MU) |
A60F12-1203 | A60F12-1201 | A20F12-05 | 090672-15 | The latest microcodes have been loaded. | |
| SIMD Units | 2x 256-bit (512-bit total) AVX512+ | 2x 256-bit (512-bit total) AVX512+ | 256-bit AVX/FMA3/AVX2 | 256-bit AVX/FMA3/AVX2 | Same SIMD widths | |
| Price/RRP (USD) |
$699 |
$589 | $449 |
$589 | Same price as non-3D at launch | |
Disclaimer
This is an independent review (critical appraisal) that has not been endorsed nor sponsored by any entity (e.g. AMD, etc.). All trademarks acknowledged and used for identification only under fair use.
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets. Zen4 supports all modern instruction sets including AVX2/FMA3 and crypto SHA HWA but also AVX-512 and extensions (IFMA, VNNI, VAES, etc.)
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 11 x64 (21H2), latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations. All mitigations for vulnerabilities (Meltdown, Spectre, L1TF, MDS, etc.) were enabled as per Windows default where applicable.
| Native Benchmarks | AMD Ryzen 9 7950X-3D 16C/32T (Raphael-3D) | AMD Ryzen 9 7950X 16C/32T (Raphael) | AMD Ryzen 7 5800X-D 8C/16T (Vermeer-3D) | Intel Core i9 12900K 8C+8c/24T (ADL, AlderLake) | Comments | |
 |
||||||
 |
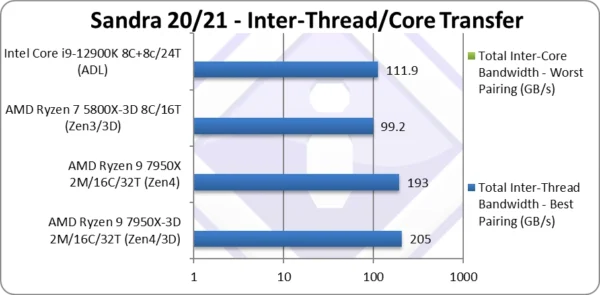
Total Inter-Thread Bandwidth – Best Pairing (GB/s) | 205* [+6%] | 193* | 99.2 | 111.9 | 3D Zen4 has 6% more bandwidth |
| As the 3D/V-Cache L3 is the “star of the show” – we start with the inter-thread benchmark – where we see a +6% overall bandwidth improvement over the original Zen4, as even large data blocks transfers between threads can be fulfilled by the 3D L3 cache and do not need to go through much slower system memory anymore.
This should benefit all algorithms where larger data blocks are processed that cannot fit even in the generous 64MB of the original Zen4 L3 cache. Let’s note that most but the very recent CPUs only had up to 16MB L3 if not much less and 128MB total L3 is huge for desktop processors. Note:* using AVX512 512-bit wide transfers. |
||||||
 |
||||||
|
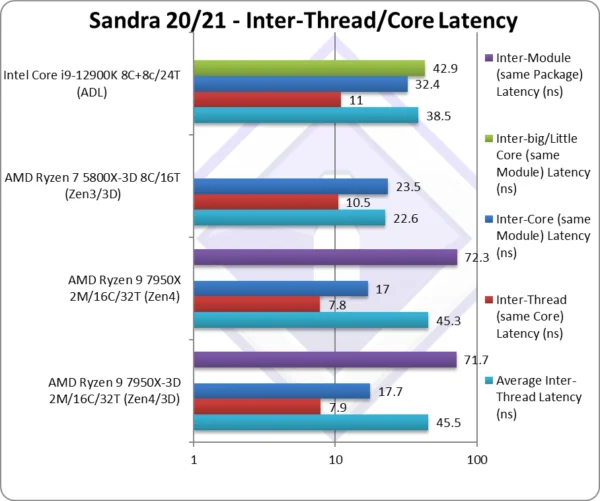
Average Inter-Thread Latency (ns) | 45.5 [=] | 45.3 | 22.6 | 38.5 | Same overall latency |
|
Inter-Thread Latency (Same Core) Latency (ns) | 7.9 [+1%] | 7.8 | 10.5 | 11 | Similar thread latency |
|
Inter-Core Latency (big Core, same Module) Latency (ns) | 17.7 [+4%] | 17 | 23.5 | 32.4 | Finally see 4% higher latency |
|
Inter-Core (Little Core, same Module) Latency (ns) | – | – | – | 42.9 | n/a |
|
Inter-Module Latency (ns) | 71.7 [-1%] | 72.3 | – | – | Similar inter-CCX latency |
| Overall, 3D Zen4 latencies are comparable to standard Zen4; some are higher due to lower (core) clocks on the V-Cache CCX but nothing special. | ||||||
 |
||||||
 |
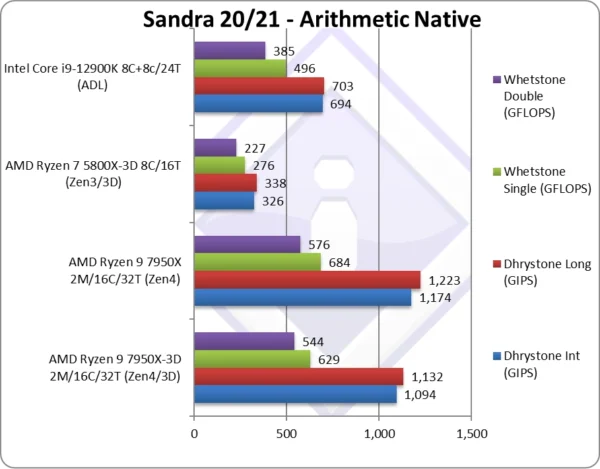
Native Dhrystone Integer (GIPS) | 1,094 [-7%] | 1,174 | 326 | 694 | 3D Zen4 is 7% slower than the standard version. |
|
Native Dhrystone Long (GIPS) | 1,132 [-7%] | 1,223 | 338 | 703 | With a 64-bit integer workload, nothing changes |
|
Native FP32 (Float) Whetstone (GFLOPS) | 629 [-8%] | 684 | 276 | 496 | Floating-point performance is 8% slower |
|
Native FP64 (Double) Whetstone (GFLOPS) | 544 [-6%] | 576 | 227 | 385 | With FP64 we’re down 6%, still beating Intel |
| 3D Zen4 is about 7% slower than normal Zen4 – that is exactly what we’d expect from the lower clocks of the V-Cache CCX in these legacy integer/floating-point benchmarks – that fit entirely in the L1/L2 and won’t take any advantage of the immense new L3 cache.
Against the competition, the situation does not change much, with Zen4 soundly beating ADL. |
||||||
 |
||||||
 |
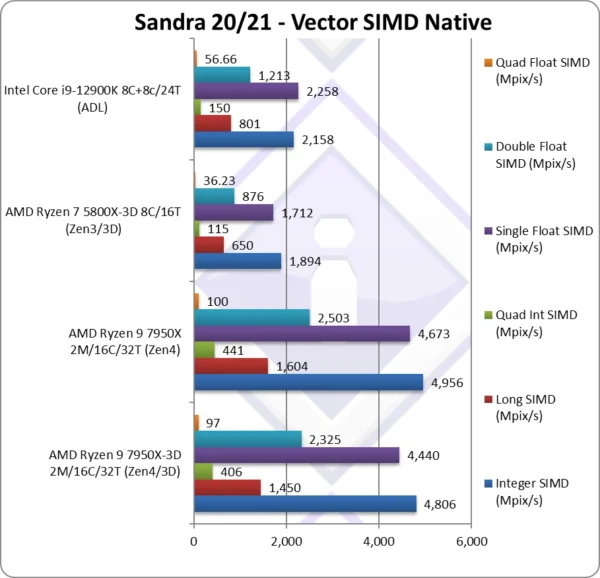
Native Integer (Int32) Multi-Media (Mpix/s) | 4,806* [-3%] | 4,956* | 1,894 | 2,158 | 3D Zen4 is again 3% slower than standard |
|
Native Long (Int64) Multi-Media (Mpix/s) | 1,450* [-10%] | 1,604* | 650 | 801 | With a 64-bit integer workload it’s 10% slower |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 406* [-8%] | 441* | 115 | 150 | This is a tough test using Long integers to emulate Int128 nothing changes. |
|
Native Float/FP32 Multi-Media (Mpix/s) | 4,440* [-5%] | 4,673* | 1,712 | 2,258 | In this floating-point test, we’re 5% slower. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 2,325* [-7%] | 2,503* | 876 | 1,213 | Switching to FP64 code, nothing changes. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 97 [-3%] | 100* | 36.23 | 56.66 | In this heavy algorithm using FP64 to mantissa extend FP128, 3% slower |
| Even in heavy compute SIMD vectorised algorithms we see the same results, 6% slower than standard Zen4 as expected. This is due to the relatively small data set (Mandelbrot fractal bitmap) that already fits in the standard size L3 caches.
If we were to use a much larger data set (e.g. 96-128MB) that would have overwhelmed the smaller caches – but fit in the new 3D V-Cache, we will see a benefit. But the allocated data set for each CCX would need to be proportional to its L3 cache – not an easy feat. Note*: using AVX512 instead of AVX2/FMA. |
||||||
 |
||||||
 |
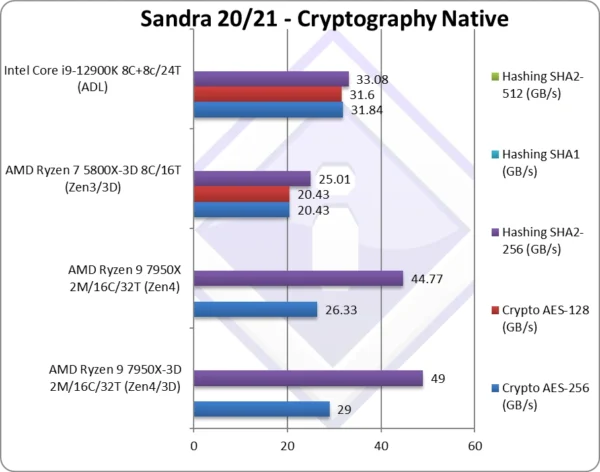
Crypto AES-256 (GB/s) | 29*** [+9%] | 26.33*** | 20.43 | 31.84 | 3D Zen4 sees a 10% improvement over standard |
|
Crypto AES-128 (GB/s) | 20.43 | 31.6 | What we saw with AES-256 just repeats with AES-128. | ||
|
Crypto SHA2-256 (GB/s) | 49* [+9%] | 44.77* | 25.01** | 33.08** | With SHA/HWA it is 9% faster |
|
Crypto SHA1 (GB/s) | The less compute-intensive SHA1 does not change things due to acceleration. | ||||
| While streaming tests (crypto/hashing) are memory bound, 3D Zen4 does finally see an improvement of about 9%.
Again, should our dataset be able to fit entirely in L3 cache(s) or significantly serviced by it – we would see a big improvement over the standard Zen4. But with large dataset (up to 16GB total on 32GB systems) the size of the L3 cache is of little benefit. Again, perhaps allowing configurable size data sets is an idea should these large L3 caches become mainstream. Note***: using VAES 256-bit (AVX2) or 512-bit (AVX512) Note**: using SHA HWA not SIMD (e.g. AVX512, AVX2, AVX, etc.) Note*: using AVX512 not AVX2. |
||||||
 |
||||||
 |
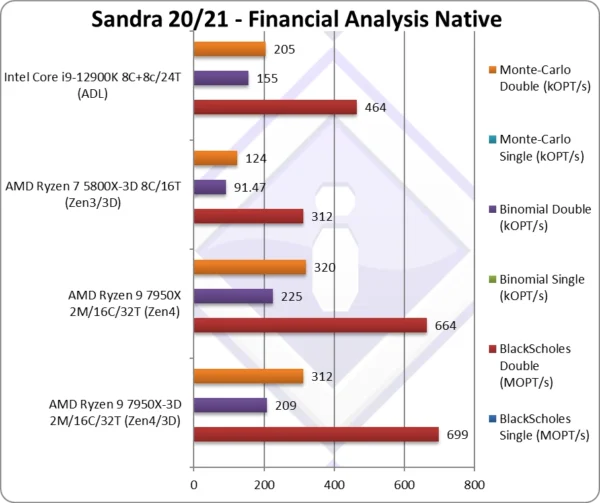
Black-Scholes float/FP32 (MOPT/s) | The standard financial algorithm. | ||||
|
Black-Scholes double/FP64 (MOPT/s) | 699 [+5%] | 664 | 312 | 464 | Switching to FP64 code, 3D Zen4 is 5% faster. |
|
Binomial float/FP32 (kOPT/s) | Binomial uses thread shared data thus stresses the cache & memory system; | ||||
|
Binomial double/FP64 (kOPT/s) | 209 [-7%] | 225 | 91.47 | 155 | With FP64 code 3D Zen4 is 7% slower. |
|
Monte-Carlo float/FP32 (kOPT/s) | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches; | ||||
|
Monte-Carlo double/FP64 (kOPT/s) | 312 [-2%] | 320 | 124 | 205 | No improvement here either. |
| Ryzen always did well on non-SIMD floating-point algorithms and here 3D Zen4 performs as expected, it is about the same performance. Again, we need updated algorithms that can buffer into the L3 cache now that it is so big in order to see improvements. | ||||||
 |
||||||
 |
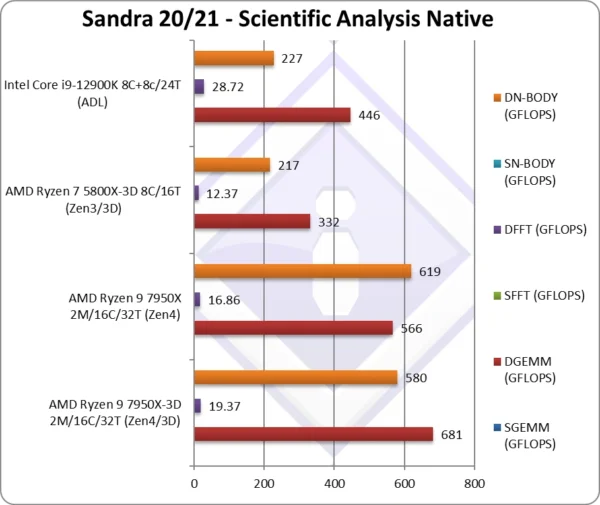
SGEMM (GFLOPS) float/FP32 | In this tough vectorised algorithm that is widely used (e.g. AI/ML). | ||||
|
DGEMM (GFLOPS) double/FP64 | 681* [+20%] | 566* | 332 | 446 | With FP64 3D Zen4 20% faster |
|
SFFT (GFLOPS) float/FP32 | FFT is also heavily vectorised but stresses the memory sub-system more. | ||||
|
DFFT (GFLOPS) double/FP64 | 19.37* [+15%] | 16.86* | 12.37 | 28.72 | With FP64 code, 15% faster |
|
SNBODY (GFLOPS) float/FP32 | N-Body simulation is vectorised but fewer memory accesses. | ||||
|
DNBODY (GFLOPS) double/FP64 | 580* [-6%] | 619* | 217 | 227 | With FP64 precision 3D Zen4 is 6% slower. |
| The main news here is that with a dataset that fits in the 3D L3 cache in GEMM – we see a 20% improvement over standard Zen4. GEMM is already using the L1D caches to buffer the tiles for higher performance – but here we see the huge improvement the L3 cache makes if the whole dataset fits the L3 cache.
Note*: using AVX512 not AVX2/FMA3. |
||||||
 |
||||||
 |
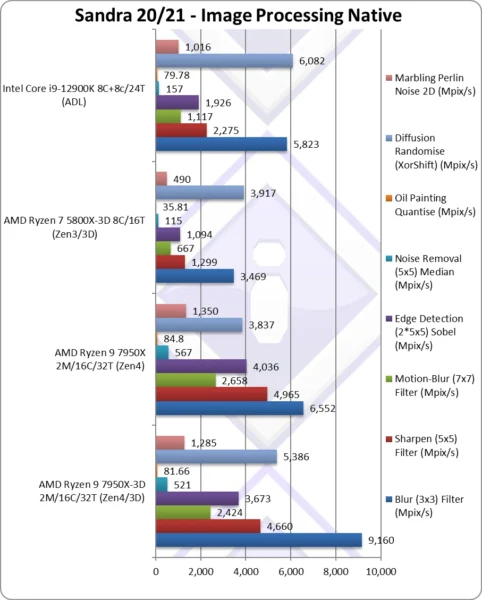
Blur (3×3) Filter (MPix/s) | 9,160* [+40%] | 6,552* | 3,469 | 5,823 | In this vectorised integer workload 3D Zen4 is 40% faster! |
|
Sharpen (5×5) Filter (MPix/s) | 4,660* [-6%] | 4,965* | 1,299 | 2,275 | Same algorithm but more shared data 6% slower |
|
Motion-Blur (7×7) Filter (MPix/s) | 2,424* [-9%] | 2,658* | 667 | 1,117 | Again same algorithm but even more data shared – 9% slower |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 3,673* [-9%] | 4,036* | 1,094 | 1,926 | Different algorithm but still vectorised no change. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 521* [-8%] | 567* | 115 | 157 | Still vectorised code but no change |
|
Oil Painting Quantise Filter (MPix/s) | 81.66* [-4%] | 84.8* | 35.81 | 79.78 | This test has always been tough – 4% slower |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 5,386* [+40%] | 3,837* | 3,917 | 6,082 | With integer workload, we see an unexpected 40% faster |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 1,285* [-5%] | 1,350* | 490 | 1,016 | In this final test we see little change. |
| Again, if the dataset is too small and thus can fit in the normal L3 caches (e.g. 64MB) – you’re not going to see benefit from the much larger 3D V-Cache. Interestingly, we see 2 tests where the improvement is a huge 40%! This is not a fluke, as we’ve seen similar improvement in Zen3-3D vs. standard Zen3.
Note*: using AVX512 not AVX2/FMA3. |
||||||
 |
||||||
 |
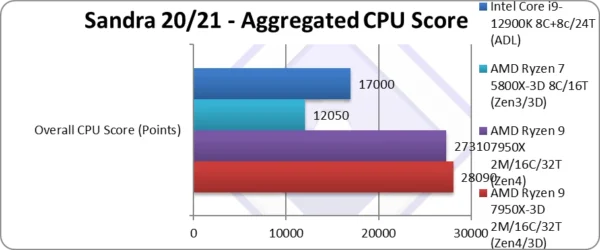
Aggregate Score (Points) | 28,090* [+3%] | 27,310* | 12,050 | 17,000 | Across all benchmarks, 3D Zen4 is 3% faster! |
| Despite being 5-6% slower in most compute benchmarks, the cache-sensitive benchmarks (Inter-Core Transfer, Crypto AES) do manage to bring 3D Zen4 to 3% faster than the normal Zen4 – which is a great result.
Note*: using AVX512 note AVX2/FMA3. |
||||||
 |
||||||
 |
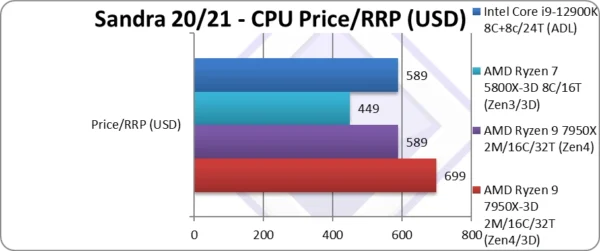
Price/RRP (USD) | $699 [+19%] | $589 | $449 | $589 | Price is 19% higher |
 |
||||||
|
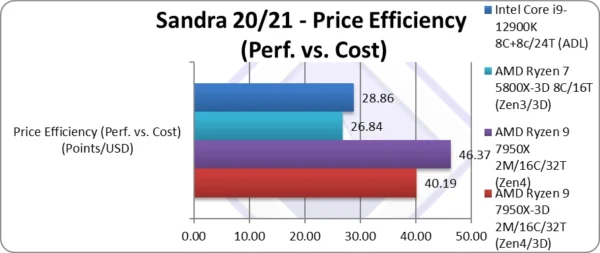
Price Efficiency (Perf. vs. Cost) (Points/USD) | 40.19 [-13%] | 46.37 | 26.84 | 28.86 | Due to price, 13% less efficient |
| As the standard Zen4 has now become cheaper, Zen4-3D comes in at the old price (19% higher), the price efficiency of Zen4-3D ends up 13% lower. If you want “bang-per-buck” the old Zen4 rules and is far beyond the competition. | ||||||
 |
||||||
 |
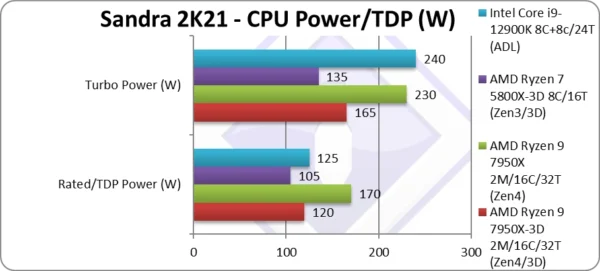
Power/TDP (W) | 120 – 165W (PPT) [-29%] | 170 – 230W (PPT) | 105 – 135W (PPT) | 125 – 240W (PL2) | TDP is almost 30% lower! |
 |
||||||
|
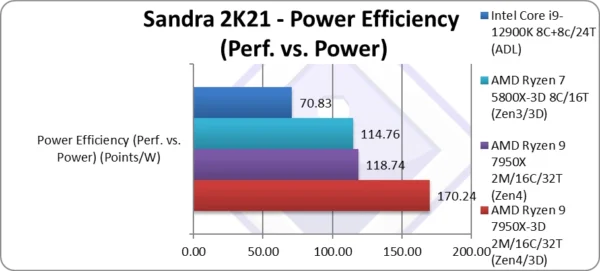
Power Efficiency (Perf. vs. Power) (Points/W) | 170.24 [+43%] | 118.74 | 114.76 | 70.83 | As the TDP is much lower, efficiency is 43% higher! |
| With the much lower TDP (PPT) and modest performance increase, Zen4-3D is an astonishing 43% more power efficient than the normal Zen4 – a big result! Of course, you can always restrict the power of the standard Zen4 to the same and enjoy similar efficiency. | ||||||
SiSoftware Official Ranker Scores
- AMD Ryzen 9 7950X-3D 16-Core/32-Thread
- AMD Ryzen 9 7900X-3D 12-Core/24-Thread
- AMD Ryzen 7 5800X-3D 8-Core/16-Thread
Final Thoughts / Conclusions
Summary: Difficult to recommend over the standard Zen4 (7950X): 7/10
Even with the original 3D V-Cache Zen3 (5800X-3D) – the biggest issue was that the standard Zen3 was too good/performant and the huge L3 cache only made a difference in some workloads (notably games!). The standard 32MB L3 CCX cache is already large enough and fast enough especially considering the competition (Intel). Still, the 3D model had 3x (three times) larger L3 that can be a big asset.
The multi-CCX designs have had even more (but not unified) L3 cache, with the 7950X/7900X sporting 64MB total L3 cache. Thus with just 1x 3D/CCX (with 96MB L3) and a standard CCX (with 32MB L3) – the 7950X-3D/7900X-3D have just 2x (double) L3 not 3x (triple).
This asymmetric CCX design – coupled with lower clocks on the V-Cache CCX – is problematic for optimisation including thread scheduling. AMD’s solution is to effectively “park” one CCX and schedule workload on other CCX depending on workload: e.g. games on V-Cache/slow CCX – normal workloads on fast/standard CCX. This works for workloads up to 8-cores/16 threads (aka single CCX) – but if workload were to take advantage of all the threads/cores (32) then we run into difficulties.
It seems that AMD did not want to “cannibalise” workstation market by releasing a monster CPU with 192MB L3 cache (aka 2x V-Cache CCX) but did not want to lose the sales of higher-end dual-CCX (7950X/7900X) – as the (future) 7800X-3D would be preferred by gamers (as with the 5800X-3D before it). In effect, these hybrid-CCX are supposed to be the “best of both worlds” – as good as 7800X-3D for games but also provide more cores/threads when needed! What’s not to like???
Due lower effective clocks (lower TDP, lower base clocks) – synthetic benchmarks results for Zen4-3D are lower than standard Zen4. Large data-set workloads do show minor improvement but nothing significant. That is not unexpected considering the block sizes are not optimised for different L3 sizes across threads as with hybrid (e.g. Intel ADL/RPL) designs.
Still, the TDP (PPT) restriction does not seem to affect performance, thus in effect Zen4-3D is more efficient than standard Zen4. But you can always restrict TDP of standard Zen4 with minimal performance impact and enjoy better power efficiency…
In the end – it all depends on your workloads: if you game regularly and thus want a 3D/V-Cache Zen4 but also regularly need more cores/threads for other tasks than a (future) 7800X-3D can provide, then these 7950X-3D/7900X-3D could work for you.
Otherwise you’re better off with the standard Zen4 (7950X/7900X), (future) 7800X-3D or even older 5800X-3D depending on what you use most.
Please see the other reviews on other Ryzen variants:
- AMD Ryzen 7 7800X-3D (Zen4 V-Cache) Review & Benchmarks – VCache for the Win!
- AMD Ryzen 9 7950X (Zen4 Raphael) Review & Benchmarks – AVX512 Top-End Domination
- AMD Ryzen 7 7700X (Zen4 Raphael) Review & Benchmarks – AVX512 Mainstream Performance
- AMD Ryzen 5 7600X (Zen4 Raphael) Review & Benchmarks – Value AVX512 Performance
Disclaimer
This is an independent review (critical appraisal) that has not been endorsed nor sponsored by any entity (e.g. AMD, etc.). All trademarks acknowledged and used for identification only under fair use.