What is “Ryzen+” ZEN+?
After the very successful launch of the original “Ryzen” (Zen/Zeppelin – “Summit Ridge” on 14nm), AMD has been hard at work optimising and improving the design: “Ryzen+” (code-name “Pinnacle Ridge”) is thus a 12nm die shrink that can also includes APU – with integrated “Vega RX” graphics” – as well as traditional CPU versions.
While new chipsets (AMD 400 series) will also be introduced, the CPUs do work with existing AM4 300-series chipsets (e.g. X370, B350, A320) with a BIOS/firmware update which makes them great upgrades.
Here’s what AMD says it has done for Ryzen+:
- Process technology optimisations (12nm vs 14nm) – lower power but higher frequencies
- Improvements for cache & memory speed & latencies (we are testing them in this article!)
- Multi-core optimised boost (aka Turbo) algorithm – XFR2 – higher speeds
In this article we test CPU Cache and Memory performance; please see our other articles on:
Hardware Specifications
We are comparing the top-of-the-range Ryzen+ (2700X, 2600) with previous generation (1700X) and competing architectures with a view to upgrading to a mid-range high performance design.
| CPU Specifications | AMD Ryzen 2700X (Pinnacle Ridge) | AMD Ryzen 2600 (Pinnacle Ridge) |
AMD Ryzen 1700X (Summit Ridge) |
Intel i7-6700K (SkyLake) |
Comments | |
| L1D / L1I Caches (kB) |
8x 32kB 8-way / 8x 64kB 8-way | 6x 32kB 8-way / 6x 64kB 8-way | 8x 32kB 8-way / 8x 64kB 8-way | 4x 32kB 8-way / 4x 32kB 8-way | Ryzen+ data/instruction caches is unchanged; icache is still 2x as big as Intel’s. | |
| L2 Caches (kB) |
8x 512kB 8-way | 6x 512kB 8-way | 8x 512kB 8-way | 4x 256kB 8-way | Ryzen+ L2 cache is unchanged but we’re told latencies have been improved. And 4x bigger than Intel’s! | |
| L3 Caches (MB) |
2x 8MB 16-way | 2x 8MB 16-way | 2x 8MB 16-way | 8MB 16-way | Ryzen+ L3 caches are also unchanged – but again lantencies are meant to have improved. With each CCX having 8MB even the 2600 has 2x as much cache as an i7. | |
| TLB 4kB pages |
64 full-way 1536 8-way | 64 full-way 1536 8-way | 64 full-way 1536 8-way | 64 8-way 1536 6-way | No TLB changes. | |
| TLB 2MB pages |
64 full-way 1536 2-way | 64 full-way 1536 2-way | 64 full-way 1536 2-way | 8 full-way 1536 6-way | No TLB changes, same as 4kB pages. | |
| Memory Controller Speed (MHz) | 600-1200 | 600-1200 | 600-1200 | 1200-4000 | Ryzen’s memory controller runs at memory clock (MCLK) base rate thus depends on memory installed. Intel’s UNC (uncore) runs between min and max CPU clock thus perhaps faster. | |
| Memory Speed Rated/Max (MHz) |
2400 / 2933 | 2400 / 2933 | 2400 / 2666 | 2533 / 2400 | Ryzen+ how supports up to 2933MHz (officially) which should improve its performance quite a bit – unfortunately fast DDR4 is very expensive right now. | |
| Memory Channels / Width |
2 / 128-bit | 2 / 128-bit | 2 / 128-bit | 2 / 128-bit | All have 128-bit total channel width. | |
| Memory Timing (clocks) |
14-16-16-32 7-54-18-9 2T | 14-16-16-32 7-54-18-9 2T | 14-16-16-32 7-54-18-9 2T | 16-18-18-36 5-54-21-10 2T | Memory runs at the same timings on both Ryzen+ and Ryzen but we shall see if measured latencies are different. | |
Core Topology and Testing
As discussed in the previous article, cores on Ryzen are grouped in blocks (CCX or compute units) each with its own 8MB L3 cache – but connected via a 256-bit bus running at memory controller clock. This is better than older designs like Intel Core 2 Quad or Pentium D which were effectively 2 CPU dies on the same socket – but not as good as a unified design where all cores are part of the same unit.
Running algorithms that require data to be shared between threads – e.g. producer/consumer – scheduling those threads on the same CCX would ensure lower latencies and higher bandwidth which we will test with presently.
We have thus modified Sandra’s ‘CPU Multi-Core Efficiency Benchmark‘ to report the latencies of each producer/consumer unit combination (e.g. same core, same CCX, different CCX) as well as providing different matching algorithms when selecting the producer/consumer units: best match (lowest latency), worst match (highest latency) thus allowing us to test inter-CCX bandwidth also. We hope users and reviewers alike will find the new features useful!
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (AVX2, AVX, etc.). Ryzen supports all modern instruction sets including AVX2, FMA3 and even more.
Results Interpretation: Higher rate values (GOPS, MB/s, etc.) mean better performance. Lower latencies (ns, ms, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
| Native Benchmarks | Ryzen+ 2700X 8C/16T (Pinnacle Ridge) |
Ryzen+ 2600 6C/12T (Pinnacle Ridge) |
Ryzen 1700X 8C/16T (Summit Ridge) |
i7-6700K 4C/8T (SkyLake) |
Comments | |
 |
||||||
 |
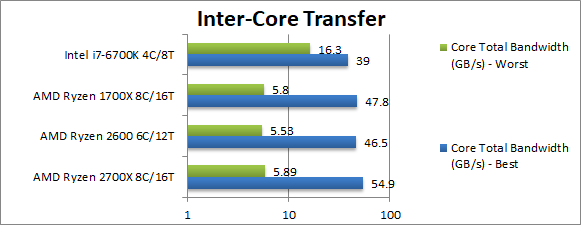
Total Inter-Core Bandwidth – Best (GB/s) | 54.9 [+15%] | 46.5 | 47.8 | 39 | Ryzen+ manages 15% higher bandwidth between its cores, slightly better than just 11% clock increase – signalling some improvements under the hood. |
|
Total Inter-Core Bandwidth – Worst (GB/s) | 5.89 [+2%] | 5.53 | 5.8 | 16.3 | In worst-case pairs on Ryzen must go across CCXes – and with this link running at the same clock (1200MHz) on Ryzen+ we can only manage a 2% increase in bandwidth. This is why faster memory is needed. |
 |
||||||
|
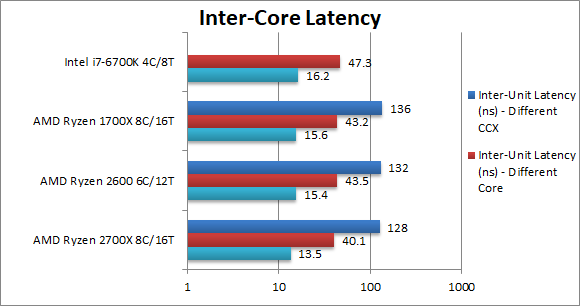
Inter-Unit Latency – Same Core (ns) | 13.5 [-13%] | 15.4 | 15.6 | 16.2 | Within the same core (sharing L1D/L2), Ryzen+ manages a 13% reduction in latency, again better than just clock speed increase. |
|
Inter-Unit Latency – Same Compute Unit (ns) | 40.1 [-7%] | 43.5 | 43.2 | 47.3 | Within the same compute unit (sharing L3), the latency decreased by 7% on Ryzen+ thus L3 seems to have improved also. |
|
Inter-Unit Latency – Different Compute Unit (ns) | 128 [-6%] | 132 | 236 | – | Going inter-CCX we still see a 6% reduction in latency on Ryzen+ – with the CCX link at the same speed – a welcome surprise. |
| The multiple CCX design still presents some challenges to programmers requiring threads to be carefully scheduled – but we see a decent 6-7% reduction in L3/CCX latencies on Ryzen+ even when running at the same clock as Ryzen. | ||||||
 |
||||||
 |
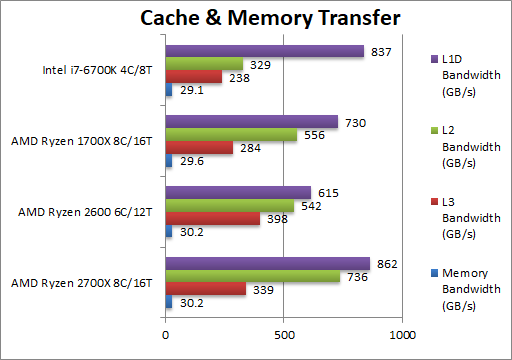
Aggregated L1D Bandwidth (GB/s) | 862 [+18%] | 615 | 730 | 837 | Right off we see a 18% bandwidth increase – almost 2x higher (than the 11% clock increase) – thus some improvements have been made to the cache system. It allows Ryzen+ to finally beat the i7 with its wide L1 data paths (512-bit) though with 2x more caches (8 vs 4). |
|
Aggregated L2 Bandwidth (GB/s) | 736 [+32%] | 542 | 556 | 329 | We see a huge 32% increase in L2 cache bandwidth – almost 3x clock increase (the 11%) suggesting the L2 caches have been improved also. Ryzen+ has thus 2x the L2 bandwidth of i7 though with 2x more caches (8 vs 4). |
|
Aggregated L3 Bandwidth (GB/s) | 339 [+19%] | 398 | 284 | 238 | The bandwidth of the L3 caches has also increased by 19% (2x clock increase) though we see the 6-core 2600 doing better (398 vs 339) likely due to less threads competing for the same L3 caches (12 vs 16). Ryzen+ L3 caches are not just 2x bigger than Intel but also 2x more bandwidth. |
|
Aggregated Memory (GB/s) | 30.2 [+2%] | 30.2 | 29.6 | 29.1 | With the same memory clock, Ryzen+ does still manage a small 2% improvement – signalling memory controller improvements. We also see Ryzen’s memory at 2400Mt/s having better bandwidth than Intel at 2533. |
| We see big improvements on Ryzen+ for all caches L1D/L2/L3 of 20-30% – more than just raw clock increase (11%) – so AMD has indeed made improvements – which to be fair needed to be done. The memory controller is also a bit more efficient (2%) though it can run at higher clocks than tested (2400Mt/s) – hopefully fast DDR4 memory will become more affordable. | ||||||
 |
||||||
 |
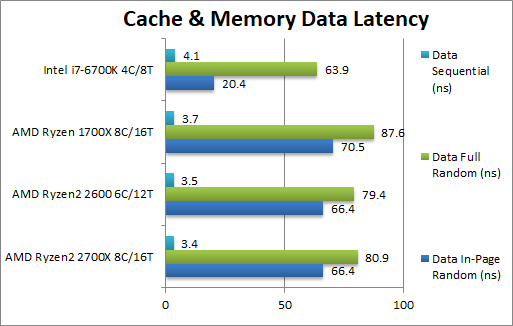
Data In-Page Random Latency (ns) | 66.4 (4-12-31) [-6%] [0][-5][-4] | 66.4 (4-12-31) | 70.5 (4-17-35) | 20.4 (4-12-21) | In-page latency has decreased by a noticeable 6% on Ryzen+ (both 2700X and 2600) – we see 5 clocks reduction for L2 and 4 for L3 a welcome improvement. But still a way to go to catch Intel which has 1/3x (three times less) latency. |
|
Data Full Random Latency (ns) | 80.9 (4-12-32) [-8%] [0][-5][-4] | 79.4 (4-12-32) | 87.6 (4-17-36) | 63.9 (4-12-34) | Out-of-page latencies have also been reduced by 8% on Ryzen+ (same memory) and we see the same 5 and 4 clock reduction for L2 and L3 (on both 2700X and 2600 it’s no fluke). Again these are welcome but still have a way to go to catch Intel. |
|
Data Sequential Latency (ns) | 3.4 (4-6-7) [-8%] [0][-1][0] | 3.5 (4-6-7) | 3.7 (4-7-7) | 4.1 (4-12-13) | Ryzen’s prefetchers are working well with sequential access pattern latency and we see a 8% latency drop for Ryzen+. |
| Ryzen’s issue was high memory latencies (in-page/full random) and Ryzen+ has reduced them all by 6-8%. While it is a good improvement, they are still pretty high compared to Intel’s thus more work needs to be done here. | ||||||
 |
||||||
|
Code In-Page Random Latency (ns) | 14.2 (4-9-24) [-9%] [0][0][0] | 14.6 (4-9-24) | 15.6 (4-9-24) | 10.1 (2-10-21) | Code latencies were not a problem on Ryzen but we still see a welcome reduction of 9% on Ryzen+. (no clocks delta) |
|
Code Full Random Latency (ns) | 88.6 (4-14-49) [-9%] [0][+1][+2] | 89.3 (4-14-49) | 97.4 (4-13-47) | 70.7 (2-11-46) | Out-of-page latency also sees a 9% decrease on Ryzen+ but somewhat surprisingly a 1-2 clock increase. |
|
Code Sequential Latency (ns) | 7.6 (4-12-20) [-8%] [0][+1][+1] | 7.8 (4-12-20) | 8.3 (4-11-19) | 5.0 (2-4-9) | Ryzen’s prefetchers are working well with sequential access pattern latency and we see a 8% reduction on Ryzen+. |
| While code access latencies were not a problem on Ryzen and they also see a 8% improvement on Ryzen+ which is welcome. Note code L1i cache is 2x Intel’s (64kB vs 32). | ||||||
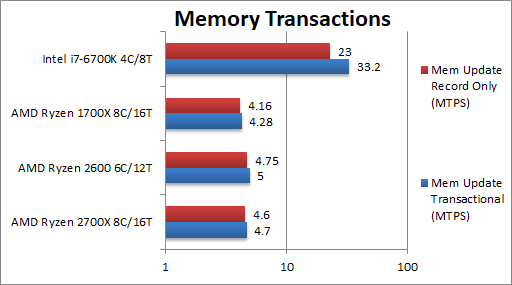 |
||||||
| Memory Update Transactional (MTPS) | 4.7 [+10%] | 5 | 4.28 | 33.2 HLE | Ryzen+ is 10% faster than Ryzen but naturally without HLE support it cannot match the i7. But with Intel disabling HLE on all but top-end CPUs AMD does not have much to worry. | |
| Memory Update Record Only (MTPS) | 4.6 [+11%] | 4.75 | 4.16 | 23 HLE | With only record updates we still see an 11% increase. | |
Ryzen+ brings nice updates – good bandwidth increases to all caches L1D/L2/L3 and also well-needed latency reduction for data (and code) accesses. Yes, there is still work to be done to bring the latencies down further – but it may be just enough to beat Intel to 2nd place for a good while.
At the high-end, ThreadRipper2 will likely benefit most as it’s going against many-core SKL-X AVX512-enabled competitor which is a lot “tougher” than the normal SKL/KBL/CFL consumer versions.
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
As with original Ryzen, the cache and memory system performance is not the clean-sweep we’ve seen in CPU testing – but Ryzen+ does bring welcome improvements in bandwidth and latency – which hopefully will further improve with firmware/BIOS updates (AGESA firmware).
With the potential to use faster DDR4 memory – Ryzen+ can do far better than in this test (e.g. with 2933/3200MHz memory). Unfortunately at this time DDR4 – especially high-end fast versions – memory is hideously expensive which is a bit of a problem. You may be better off using less but fast(er) memory with Ryzen designs.
Ryzen+ is a great update that will not disappoint upgraders and is likely to increase AMD’s market share. AMD is here to stay!