What is “Ryzen+” ZEN+?
After the very successful launch of the original “Ryzen” (Zen/Zeppelin – “Summit Ridge” on 14nm), AMD has been hard at work optimising and improving the design: “Ryzen+” (code-name “Pinnacle Ridge”) is thus a 12nm die shrink that can also includes APU – with integrated “Vega RX” graphics” – as well as traditional CPU versions.
While new chipsets (AMD 400 series) will also be introduced, the CPUs do work with existing AM4 300-series chipsets (e.g. X370, B350, A320) with a BIOS/firmware update which makes them great upgrades.
Here’s what AMD says it has done for Ryzen+:
- Process technology optimisations (12nm vs 14nm) – lower power but higher frequencies
- Improvements for cache & memory speed & latencies (we shall test that ourselves!)
- Multi-core optimised boost (aka Turbo) algorithm – XFR2 – higher speeds
In this article we test CPU core performance; please see our other articles on:
- AMD Ryzen+ 2700X, 2600 Cache & Memory Performance
- AMD Ryzen Threadripper 3970X, 3960X – CPU Performance
Hardware Specifications
We are comparing the top-of-the-range Ryzen+ (2700X, 2600) with previous generation (1700X) and competing architectures with a view to upgrading to a mid-range high performance design.
| CPU Specifications | AMD Ryzen+ 2700X (Pinnacle Ridge) |
AMD Ryzen+ 2600 (Pinnacle Ridge) |
AMD Ryzen 1700X (Summit Ridge) |
Intel i7-6700K (SkyLake) |
Comments | |
| Cores (CU) / Threads (SP) | 8C / 16T | 6C / 12T | 8C / 16T | 4C / 8T | Ryzen+ like its predecessor has the most cores and threads; it thus be down to IPC and clock speeds for performance improvements. | |
| Speed (Min / Max / Turbo) (GHz) |
2.2-3.7-4.2GHz (22x-37x-42x) [+9% rated, +11% turbo] | 1.55-3.4-3.9GHz (15x-34x-39x) | 2.2-3.3-3.8GHz (22x-34x-38x) | 0.8-4.0-4.2GHz (8x-40x-42x) | Ryzen+ base clock is 9% higher while Turbo/Boost/XFR is 11% higher; we thus expect at least about 10% improvement in CPU benchmarks. | |
| Power (TDP) | 105W | 65W | 95W | 91W | Ryzen+ also increases TDP by 11% (105W vs 95) which may require a bit more cooling especially when overclocking. | |
| L1D / L1I Caches (kB) |
8x 32kB 8-way / 8x 64kB 8-way | 6x 32kB 8-way / 6x 64kB 8-way | 8x 32kB 8-way / 8x 64kB 8-way | 4x 32kB 8-way / 4x 32kB 8-way | Ryzen+ data/instruction caches is unchanged; icache is still 2x as big as Intel’s. | |
| L2 Caches (kB) |
8x 512kB 8-way | 6x 512kB 8-way | 8x 512kB 8-way | 4x 256kB 8-way | Ryzen+ L2 cache is unchanged but we’re told latencies have been improved. 4x bigger than Intel’s. | |
| L3 Caches (MB) |
2x 8MB 16-way | 2x 8MB 16-way | 2x 8MB 16-way | 8MB 16-way | Ryzen+ L3 caches are also unchanged – but again lantencies are meant to have improved. With each CCX having 8MB even the 2600 has 2x as much cache as an i7. | |
| SIMD Units | 128-bit AVX/FMA3/AVX2 | 128-bit AVX/FMA3/AVX2 | 128-bit AVX/FMA3/AVX2 | 256-bit AVX/FMA3/AVX2 | Ryzen+ still uses the 128-bit SIMD units going against the 256-bit SIMD units that all Intel CPUs have had since Sandy Bridge! | |
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (AVX2, AVX, etc.). Ryzen+ supports all modern instruction sets including AVX2, FMA3 and even more like SHA HWA (supported by Intel’s Atom only) but has dropped all AMD’s variations like FMA4 and XOP likely due to low usage.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
| Native Benchmarks | Ryzen+ 2700X 8C/16T (Pinnacle Ridge) |
Ryzen+ 2600 6C/12T (Pinnacle Ridge) |
Ryzen 1700X 8C/16T (Summit Ridge) |
i7-6700K 4C/8T (Skylake) |
Comments | |
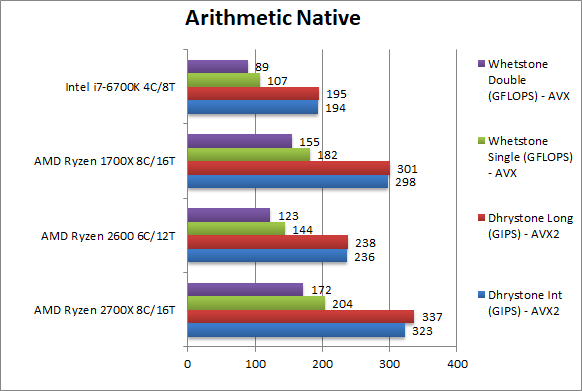 |
||||||
 |
Native Dhrystone Integer (GIPS) | 323 [+8%] | 236 | 298 | 194 | Right off Ryzen+ is 8% faster than Ryzen, let’s hope it does better. Even 2600 beats the i7 easily |
|
Native Dhrystone Long (GIPS) | 337 [+12%] | 238 | 301 | 194 | With a 64-bit integer workload – we finally get into gear, Ryzen+ is 12% faster than its old brother. |
|
Native FP32 (Float) Whetstone (GFLOPS) | 204 [+12%] | 144 | 182 | 107 | Even in this floating-point test, Ryzen+ is again 12% faster. All AMD CPUs beat the i7 into dust. |
|
Native FP64 (Double) Whetstone (GFLOPS) | 172 [+11%] | 123 | 155 | 89 | With FP64 nothing much changes, Ryzen+ is still 11% faster. |
| From integer workloads in Dhrystone to floating-point workloads in Whetstone, Ryzen+ is about 10% faster than Ryzen: this is exactly in line with the speed increase (9-11%) but if you were expecting more you may be a tiny bit disappointed. | ||||||
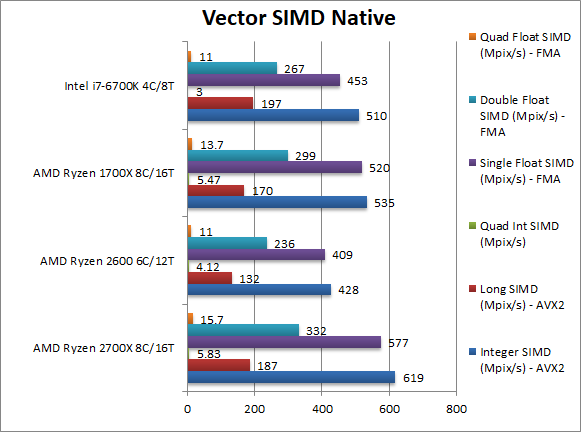 |
||||||
 |
Native Integer (Int32) Multi-Media (Mpix/s) | 619 [+16%] | 428 | 535 | 510 | In this vectorised AVX2 integer test Ryzen+ starts to pull ahead and is 16% faster than Ryzen; perhaps some of the arch improvements benefit SIMD vectorised workloads. |
|
Native Long (Int64) Multi-Media (Mpix/s) | 187 [+10%] | 132 | 170 | 197 | With a 64-bit AVX2 integer vectorised workload, Ryzen+ drops to just 10% but still in line with speed increase. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 5.83 [+7%] | 4.12 | 5.47 | 3 | This is a tough test using Long integers to emulate Int128 without SIMD; here Ryzen+ drops to just 7% faster than Ryzen but still a decent improvement. |
|
Native Float/FP32 Multi-Media (Mpix/s) | 577 [+11%] | 409 | 520 | 453 | In this floating-point AVX/FMA vectorised test, Ryzen+ is the standard 11% faster than Ryzen. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 332 [+11%] | 236 | 299 | 267 | Switching to FP64 SIMD code, again Ryzen+ is just the standard 11% faster than Ryzen. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 15.6 [+15%] | 11 | 13.7 | 11 | In this heavy algorithm using FP64 to mantissa extend FP128 but not vectorised – Ryzen+ manages to pull ahead further and is 15% faster. |
| In vectorised AVX2/FMA code we see a similar story with 10% average improvement (7-15%). It seems the SIMD units are unchanged. In any case the i7 is left in the dust. | ||||||
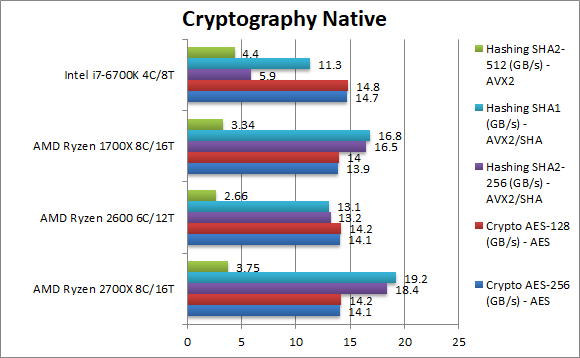 |
||||||
 |
Crypto AES-256 (GB/s) | 14.1 [+1%] | 14.1 | 13.9 | 14.7 | With AES HWA support all CPUs are memory bandwidth bound; as we’re testing Ryzen+ running at the same memory speed/timings there is still a very small improvement of 1%. But its advantage is that the memory controller is rated for 2933Mt/s operation (vs. 2533) thus with faster memory it could run considerably faster. |
|
Crypto AES-128 (GB/s) | 14.2 [+1%] | 14.2 | 14 | 14.8 | What we saw with AES-256 just repeats with AES-128; Ryzen+ is marginally faster but the improvement is there. |
|
Crypto SHA2-256 (GB/s) | 18.4 [+12%] | 13.2 | 16.5 | 5.9 | With SHA HWA Ryzen+ similarly powers through hashing tests leaving Intel in the dust; SHA is still memory bound but with just one (1) buffer it has larger headroom. Thus Ryzen+ can use its speed advantage and be 12% faster – impressive. |
|
Crypto SHA1 (GB/s) | 19.2 [+14%] | 13.1 | 16.8 | 11.3 | Ryzen+ also accelerates the soon-to-be-defunct SHA1 and here it is even faster – 14% faster than Ryzen. |
|
Crypto SHA2-512 (GB/s) | 3.75 [+12%] | 2.66 | 3.34 | 4.4 | SHA2-512 is not accelerated by SHA HWA (version 1) thus Ryzen+ has to use the same vectorised AVX2 code path – it still is 12% faster than Ryzen but still loses to the i7. Those SIMD units are tough to beat. |
| In memory bandwidth bound algorithms, Ryzen+ will have to be used with faster memory (up to 2933Mt/s officially) in order to significantly beat its older Ryzen brother. Otherwise there is only a tiny 1% improvement. | ||||||
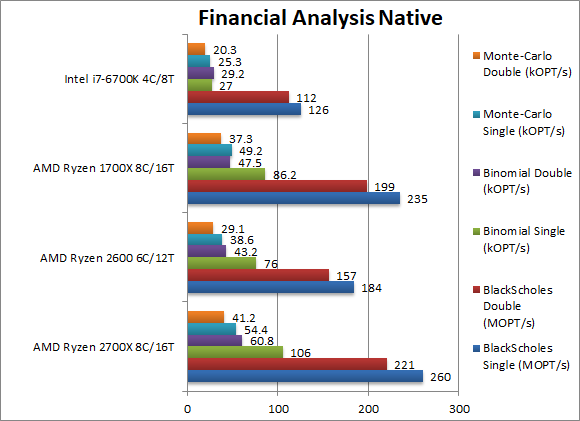 |
||||||
 |
Black-Scholes float/FP32 (MOPT/s) | 260 [+11%] | 184 | 235 | 126 | In this non-vectorised test we see Ryzen+ is the standard 11% faster than Ryzen. |
|
Black-Scholes double/FP64 (MOPT/s) | 221 [+11%] | 157 | 199 | 112 | Switching to FP64 code, nothing changes, Ryzen+ is still 11% faster. |
|
Binomial float/FP32 (kOPT/s) | 106 [+23%] | 76 | 86 | 27 | Binomial uses thread shared data thus stresses the cache & memory system; here the arch(itecture) improvements do show, Ryzen+ 23% faster – 2x more than expected. Not to mention 3x (three times) faster than the i7. |
|
Binomial double/FP64 (kOPT/s) | 60.8 [+28%] | 43.2 | 47.5 | 29.2 | With FP64 code Ryzen+ is now even faster – 28% faster than Ryzen not to mention 2x faster than the i7. Indeed it seems there improvements to the cache and memory system. |
|
Monte-Carlo float/FP32 (kOPT/s) | 54.4 [+11%] | 38.6 | 49.2 | 49.2 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches; Ryzen+ does not seem to be able to reproduce its previous gain and is just the standard 11% faster. |
|
Monte-Carlo double/FP64 (kOPT/s) | 41.2 [+10%] | 29.1 | 37.3 | 20.3 | Switching to FP64 nothing much changes, Ryzen+ is 10% faster. |
| Ryzen dies very well in these algorithms, but Ryzen+ does even better – especially when thread-local data is involved managing 23-28% improvement. For financial workloads Intel does not seem to have a chance anymore – Ryzen is impossible to beat. | ||||||
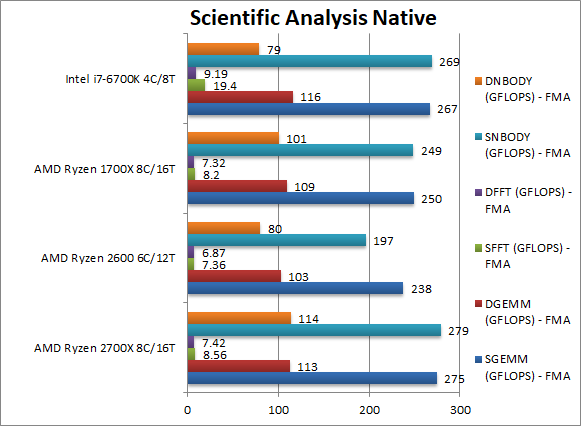 |
||||||
 |
SGEMM (GFLOPS) float/FP32 | 275 [+10%] | 238 | 250 | 267 | In this tough vectorised AVX2/FMA algorithm Ryzen+ is still “just” the 10% faster than older Ryzen – but it finally manages to beat the i7. |
|
DGEMM (GFLOPS) double/FP64 | 113 [+4%] | 103 | 109 | 116 | With FP64 vectorised code, Ryzen+ only manages to be 4% faster. It seems the memory is holding it back thus faster memory would allow it to do much better. |
|
SFFT (GFLOPS) float/FP32 | 8.56 [+4%] | 7.36 | 8.2 | 19.4 | FFT is also heavily vectorised (x4 AVX/FMA) but stresses the memory sub-system more; Ryzen+ is just 4% faster again and is still 1/2x the speed of the i7. Again it seems faster memory would help. |
|
DFFT (GFLOPS) double/FP64 | 7.42 [+1%] | 6.87 | 7.32 | 9.19 | With FP64 code, Ryzen+’s improvement reduces to just 1% over Ryzen and again slower than the i7. |
|
SNBODY (GFLOPS) float/FP32 | 279 [+12%] | 197 | 249 | 269 | N-Body simulation is vectorised but many memory accesses to shared data and Ryzen+ gets back to 12% improvement over Ryzen. This allows it to finally overtake the i7. |
|
DNBODY (GFLOPS) double/FP64 | 114 [+13%] | 80 | 101 | 79 | With FP64 code nothing much changes, Ryzen+ is still 13% faster. |
| With highly vectorised SIMD code Ryzen+ still improves by the standard 10-12% but in memory-heavy code it needs to run at higher memory speed to significantly overtake Ryzen. But it allows it to beat the i7 in more algorithms. | ||||||
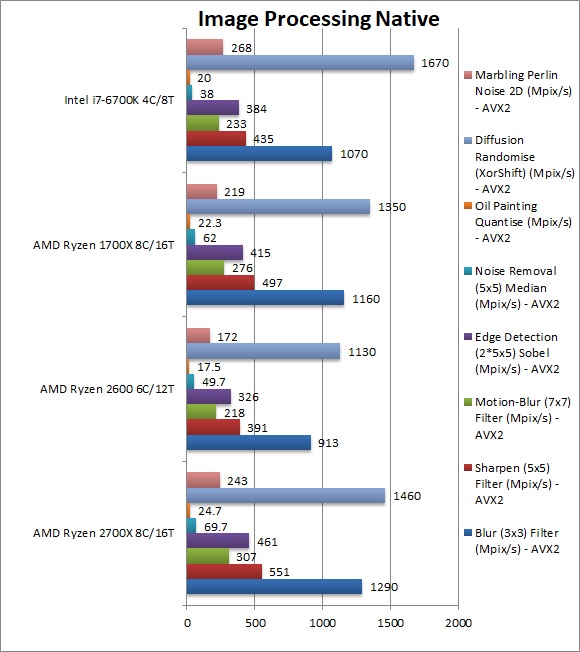 |
||||||
 |
Blur (3×3) Filter (MPix/s) | 1290 [+11%] | 913 | 1160 | 1170 | In this vectorised integer AVX2 workload Ryzen+ is 11% faster allowing it to soundly beat the i7. |
|
Sharpen (5×5) Filter (MPix/s) | 551 [+11%] | 391 | 497 | 435 | Same algorithm but more shared data does not change things for Ryzen+. Only the i7 falls behind. |
|
Motion-Blur (7×7) Filter (MPix/s) | 307 [+11%] | 218 | 276 | 233 | Again same algorithm but even more data shared does not change anything, but now the i7 is so far behind Ryzen+ is 50% faster. Incredible. |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 461 [+11%] | 326 | 415 | 384 | Different algorithm but still AVX2 vectorised workload still changes nothing – Ryzen+ is 11% faster. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 69.7 [+12%] | 49.7 | 62 | 38 | Still AVX2 vectorised code and still nothing changes; the i7 falls even further behind with Ryzen+ 2x (two times) as fast. |
|
Oil Painting Quantise Filter (MPix/s) | 24.7 [+11%] | 17.5 | 22.3 | 20 | Again we see Ryzen+ 11% faster than the older Ryzen and pulling away from the i7. |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 1460 [+8%] | 1130 | 1350 | 1670 | Here Ryzen+ is just 8% faster than Ryzen but strangely it’s not enough to beat the i7. Those SIMD units are way fast. |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 243 [+11%] | 172 | 219 | 268 | In this final test, Ryzen+ returns to being 11% faster and again strangely not enough to beat the i7. |
With all the modern instruction sets supported (AVX2, FMA, AES and SHA HWA) Ryzen+ does extremely well in all workloads – but it generally improves only by the 11% as per clock speed increase, except in some cases which seem to show improvements in the cache and memory system (which we have not tested yet).
Software VM (.Net/Java) Performance
We are testing arithmetic and vectorised performance of software virtual machines (SVM), i.e. Java and .Net. With operating systems – like Windows 10 – favouring SVM applications over “legacy” native, the performance of .Net CLR (and Java JVM) has become far more important.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest drivers. .Net 4.7.x (RyuJit), Java 1.9.x. Turbo / Boost was enabled on all configurations.
| VM Benchmarks | Ryzen+ 2700X 8C/16T Pinnacle Ridge |
Ryzen+ 2600 6C/12T Pinnacle Ridge |
Ryzen 1700X 8C/16T Summit Ridge |
i7-6700K 4C/8T Skylake |
Comments | |
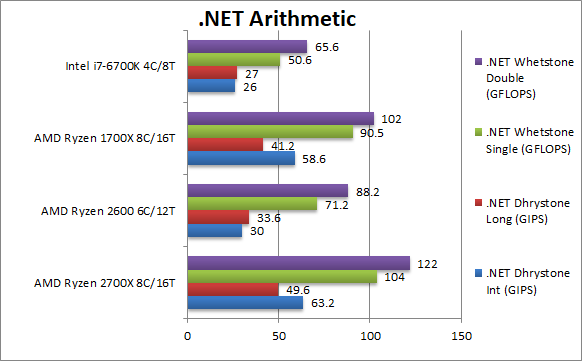 |
||||||
 |
.Net Dhrystone Integer (GIPS) | 63.2 [+8%] | 30 | 58.6 | 26 | .Net CLR integer performance starts off OK with Ryzen+ just 8% faster than Ryzen but now almost 3x (three times) faster than i7. |
|
.Net Dhrystone Long (GIPS) | 49.6 [+20%] | 33.6 | 41.2 | 27 | Ryzen seems to favour 64-bit integer workloads, with Ryzen+ 20% faster a lot higher than expected. |
|
.Net Whetstone float/FP32 (GFLOPS) | 104 [+15%] | 71.2 | 90.5 | 54.3 | Floating-Point CLR performance was pretty spectacular with Ryzen already, but Ryzen+ is 15% than Ryzen still. |
|
.Net Whetstone double/FP64 (GFLOPS) | 122 [+20%] | 88.2 | 102 | 65.6 | FP64 performance is also great (CLR seems to promote FP32 to FP64 anyway) with Ryzen+ even faster by 20%. |
| Ryzen’s performance in .Net was pretty incredible but Ryzen+ is even faster – even faster than expected by mere clock speed increase. There is only one game in town now for .Net applications. | ||||||
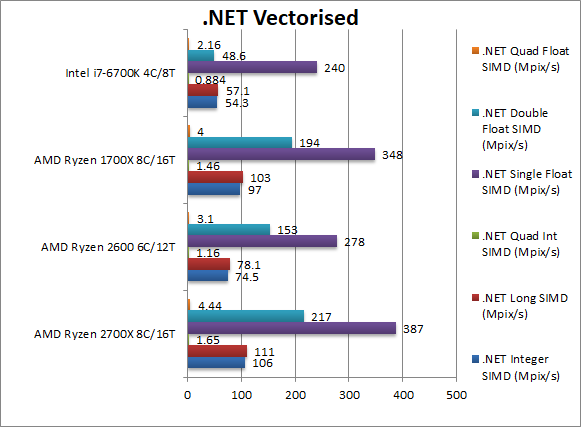 |
||||||
 |
.Net Integer Vectorised/Multi-Media (MPix/s) | 106 [+9%] | 74 | 97 | 54 | Just as we saw with Dhrystone, this integer workload sees a 9% improvement for Ryzen+ which makes it 2x faster than the i7. |
|
.Net Long Vectorised/Multi-Media (MPix/s) | 111 [+8%] | 78 | 103 | 57 | With 64-bit integer workload we see a similar story – Ryzen+ is 8% faster and again 2x faster than the i7. |
|
.Net Float/FP32 Vectorised/Multi-Media (MPix/s) | 387 [+11%] | 278 | 348 | 240 | Here we make use of RyuJit’s support for SIMD vectors thus running AVX/FMA code; Ryzen+ is 11% faster but still almost 2x faster than i7 despite its fast SIMD units |
|
.Net Double/FP64 Vectorised/Multi-Media (MPix/s) | 217 [+12%] | 153 | 194 | 48.6 | Switching to FP64 SIMD vector code – still running AVX/FMA – Ryzen+ is still 12% faster. i7 is truly left in the dust 1/4x the speed. |
| Ryzen+ is the usual 9-12% faster than Ryzen here but it means that even RyuJit’s SIMD support cannot save Intel’s i7 – it would take 2x as many cores (not 50%) to beat Ryzen+. | ||||||
 |
||||||
 |
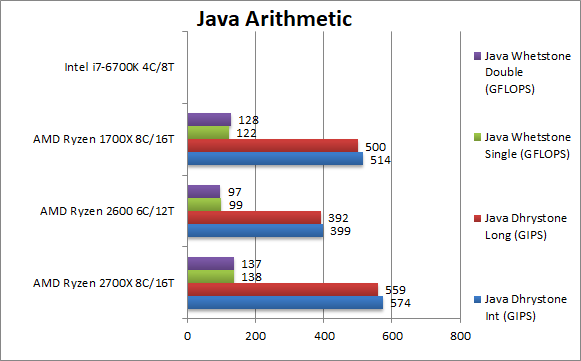
Java Dhrystone Integer (GIPS) | 574 [+12%] | 399 | 514 | We start JVM integer performance with the usual 12% gain over Ryzen. | |
|
Java Dhrystone Long (GIPS) | 559 [+12%] | 392 | 500 | Nothing much changes with 64-bit integer workload, we have Ryzen+ 12% faster. | |
|
Java Whetstone float/FP32 (GFLOPS) | 138 [+13%] | 99 | 122 | With a floating-point workload Ryzen+ performance improvement is 13%. | |
|
Java Whetstone double/FP64 (GFLOPS) | 137 [+7%] | 97 | 128 | With FP64 workload Ryzen+ is just 7% faster but still welcome | |
| Java performance improves by the expected amount 7-13% on Ryzen+ and allows it to completely dominate the i7. | ||||||
 |
||||||
 |
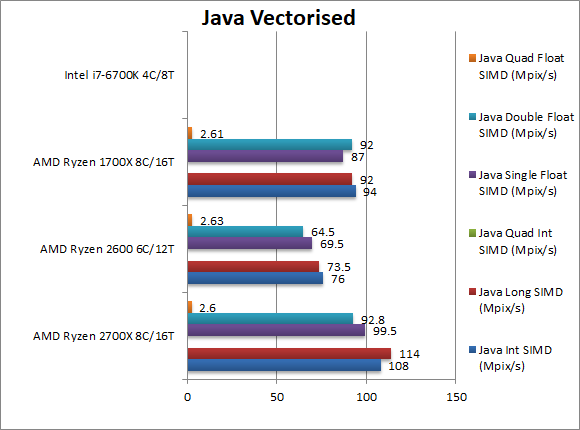
Java Integer Vectorised/Multi-Media (MPix/s) | 108 [+15%] | 76 | 94 | Oracle’s JVM does not yet support native vector to SIMD translation like .Net’s CLR but here Ryzen+ manages a 15% lead over Ryzen. | |
|
Java Long Vectorised/Multi-Media (MPix/s) | 114 [+24%] | 73 | 92 | With 64-bit vectorised workload Ryzen+ (similar to .Net) increases its lead by 24%. | |
|
Java Float/FP32 Vectorised/Multi-Media (MPix/s) | 99 [+14%] | 69 | 87 | Switching to floating-point we return to the usual 14% speed improvement. | |
|
Java Double/FP64 Vectorised/Multi-Media (MPix/s) | 93 [+1%] | 64 | 92 | With FP64 workload Ryzen+’s lead somewhat unexplicably drops to 1%. | |
| Java’s lack of vectorised primitives to allow the JVM to use SIMD instruction sets (aka SSE2, AVX/FMA) gives Ryzen+ free reign to dominate all the tests, be they integer or floating-point. It is pretty incredible that neither Intel CPU can come close to its performance. | ||||||
Ryzen dominated the .Net and Java benchmarks – but now Ryzen+ extends that dominance out-of-reach. It would take a very much improved run-time or Intel CPU to get anywhere close. For .Net and Java code, Ryzen is the CPU to get!
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
Ryzen+ is a worthy update but its speed increase is generally due to its faster clock speed – similar to Intel’s SkyLake > KabyLake (gen 6 to gen 7) transition. But coming at the same price, a “free” performance increase of 10% or so is obviously not to be ignored. Let’s not forget that Ryzen+ can still use all the existing series 300 mainboards – subject to BIOS update.
The process shrink and power optimisations does allow Ryzen+ to run at lower voltages and consume less power – even though TDP has increased at least “on paper”.
Some algorithms do seem to show that the cache and memory system has been improved – but Ryzen+’s advantage is that it can (much) faster memory. Unfortunately at this time DDR4 memory, especially fast versions, are very expensive. Here Intel does (still) have an advantage in that fast DDR4 memory is not required except for bandwidth bound algorithms.
One advantage is that by now operating systems (and applications) have been updated to deal with its dual-CCX design that used to be so much trouble when we benchmarked Ryzen initially. With AMD increasing its market share no high-performance application can afford to ignore AMD CPUs.
We (just) cannot wait to see the new improvements in future AMD designs and especially the ThreadRipper2 update!