What is “Ryzen2” ZEN+ Mobile?
It is the long-awaited Ryzen2 APU mobile “Bristol Ridge” version of the desktop Ryzen 2 with integrated Vega graphics (the latest GPU architecture from AMD) for mobile devices. While on desktop we had the original Ryzen1/ThreadRipper – there was no (at least released) APU version or a mobile version – leaving only the much older designs that were never competitive against Intel’s ULV and H APUs.
After the very successful launch of the original “Ryzen1”, AMD has been hard at work optimising and improving the design in order to hit TDP (15-35W) range for mobile devices. It has also added the brand-new Vega graphics cores to the APU that have been incredibly performant in the desktop space. Note that mobile versions have a single CCX (compute unit) thus do not require operating system kernel patches for best thread scheduling/power optimisation.
Here’s what AMD says it has done for Ryzen2:
- Process technology optimisations (12nm vs 14nm) – lower power but higher frequencies
- Improvements for cache & memory speed & latencies (we shall test that ourselves!)
- Multi-core optimised boost (aka Turbo) algorithm – XFR2 – higher speeds
Why review it now?
With Ryzen3 soon to be released later this year (2019) – with a corresponding Ryzen3 APU mobile – it is good to re-test the platform especially in light of the many BIOS/firmware updates, many video/GPU driver updates and not forgetting the many operating system (Windows) vulnerabilities (“Spectre”) mitigations that have greatly affected performance – sometimes for the good (firmware, drivers, optimisations) sometimes for the bad (mitigations).
In this article we test CPU core performance; please see our other articles on:
- AMD Ryzen 2 Mobile (2500U) Cache & Memory Performance
- AMD Ryzen 2 Mobile (2500U) Vega 8 GP(GPU) Performance
Hardware Specifications
We are comparing the top-of-the-range Ryzen2 mobile (2500U) with competing architectures (Intel gen 6, 7, 8) with a view to upgrading to a mid-range but high performance design.
| CPU Specifications | AMD Ryzen2 2500U Bristol Ridge |
Intel i7 6500U (Skylake ULV) |
Intel i7 7500U (Kabylake ULV) |
Intel i5 8250U (Coffeelake ULV) |
Comments | |
| Cores (CU) / Threads (SP) | 4C / 8T | 2C / 4T | 2C / 4T | 4C / 8T | Ryzen has double the cores of ULV Skylake/Kabylake and only recently Intel has caught up by also doubling cores. | |
| Speed (Min / Max / Turbo) | 1.6-2.0-3.6GHz (16x-20x-36x) | 0.4-2.6-3.1GHz (4x-26x-31x) | 0.4-2.7-3.5GHz (4x-27x-35x) | 0.4-1.6-3.4GHz (4x-16x-34x) | Ryzen2 has higher base and turbo than CFL-U and higher turbo than all Intel competition. | |
| Power (TDP) | 25-35W | 15-25W | 15-25W | 25-35W | Both Ryzen2 and CFL-U have higher TDP at 25W and turbo up to 35W depending on configuration while older devices were mostly 15W with turbo 20-25W. | |
| L1D / L1I Caches | 4x 32kB 8-way / 4x 64kB 4-way | 2x 32kB 8-way / 2x 32kB 8-way | 2x 32kB 8-way / 2x 32kB 8-way | 4x 32kB 8-way / 4x 32kB 8-way | Ryzen2 icache is 2x of Intel with matching dcache. | |
| L2 Caches | 4x 512kB 8-way | 2x 256kB 16-way | 2x 256kB 16-way | 4x 256kB 16-way | Ryzen2 L2 cache is 2x bigger than Intel and thus 4x larger than older SKL/KBL-U. | |
| L3 Caches | 4MB 16-way | 4MB 16-way | 4MB 16-way | 6MB 16-way | Here CFL-U brings 50% bigger L3 cache (6 vs 4MB) which may help some workloads. | |
| Microcode (Firmware) | MU8F1100-0B | MU064E03-C6 | MU068E09-8E | MU068E09-96 | On Intel you can see just how many updates the platforms have had – we’re now at CX versions but even Ryzen2 has had a few. | |
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (AVX2, AVX, etc.). Ryzen supports all modern instruction sets including AVX2, FMA3 and even more like SHA HWA (supported by Intel’s Atom only) but has dropped all AMD’s variations like FMA4 and XOP likely due to low usage.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
| Native Benchmarks | AMD Ryzen2 2500U Bristol Ridge | Intel i7 6500U (Skylake ULV) | Intel i7 7500U (Kabylake ULV) | Intel i5 8250U (Coffeelake ULV) | Comments | |
 |
||||||
 |
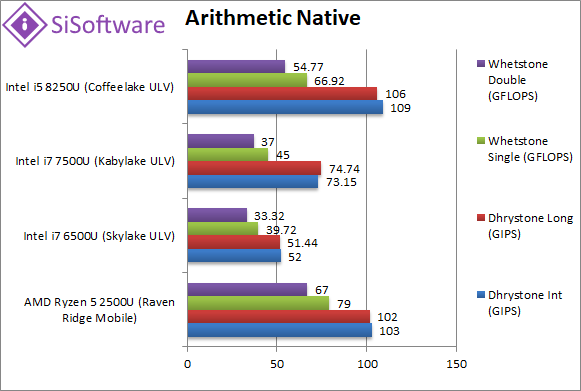
Native Dhrystone Integer (GIPS) | 103 [-6%] | 52 | 73 | 109 | Right off Ryzen2 does not beat CFL-U but is very close, soundly beating the older Intel designs. |
|
Native Dhrystone Long (GIPS) | 102 [-4%] | 51 | 74 | 106 | With a 64-bit integer workload – the difference drops to 4%. |
|
Native FP32 (Float) Whetstone (GFLOPS) | 79 [+18%] | 39 | 45 | 67 | Somewhat surprisingly, Ryzen2 is almost 20% faster than CFL-U here. |
|
Native FP64 (Double) Whetstone (GFLOPS) | 67 [+22%] | 33 | 37 | 55 | With FP64 nothing much changes, with Ryzen2 over 20% faster. |
| You can see why Intel needed to double the cores for ULV: otherwise even top-of-the-line i7 SKL/KBL-U are pounded into dust by Ryzen2. CFL-U does trade blows with it and manages to pull ahead in Dhrystone but Ryzen2 is 20% faster in floating-point. Whatever you choose you can thank AMD for forcing Intel’s hand. | ||||||
 |
||||||
 |
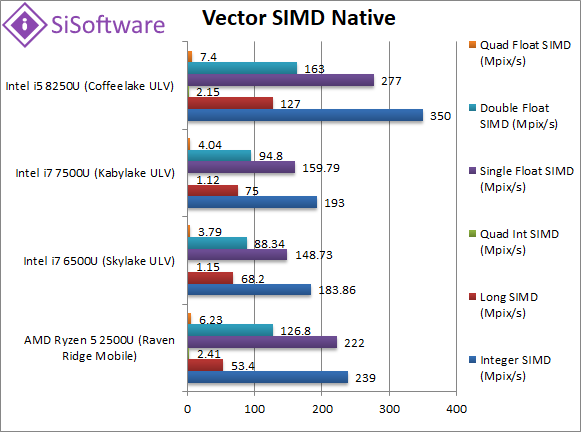
Native Integer (Int32) Multi-Media (Mpix/s) | 239 [-32%] | 183 | 193 | 350 | In this vectorised AVX2 integer test Ryzen2 starts 30% slower than CFL-U but does beat the older designs. |
|
Native Long (Int64) Multi-Media (Mpix/s) | 53.4 [-58%] | 68.2 | 75 | 127 | With a 64-bit AVX2 integer vectorised workload, Ryzen2 is even slower. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 2.41 [+12%] | 1.15 | 1.12 | 2.15 | This is a tough test using Long integers to emulate Int128 without SIMD; here Ryzen2 has its 1st win by 12% over CFL-U. |
|
Native Float/FP32 Multi-Media (Mpix/s) | 222 [-20%] | 149 | 159 | 277 | In this floating-point AVX/FMA vectorised test, Ryzen2 is still slower but only by 20%. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 126 [-22%] | 88.3 | 94.8 | 163 | Switching to FP64 SIMD code, nothing much changes still 20% slower. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 6.23 [-16%] | 3.79 | 4.04 | 7.4 | In this heavy algorithm using FP64 to mantissa extend FP128 with AVX2 – Ryzen2 is less than 20% slower. |
| Just as on desktop, we did not expect AMD’s Ryzen2 mobile to beat 4-core CFL-U (with Intel’s wide SIMD units) and it doesn’t: but it remains very competitive and is just 20% slower. In any case, it soundly beats all older but ex-top-of-the-line i7 SKL/KBL-U thus making them all obsolete at a stroke. | ||||||
 |
||||||
 |
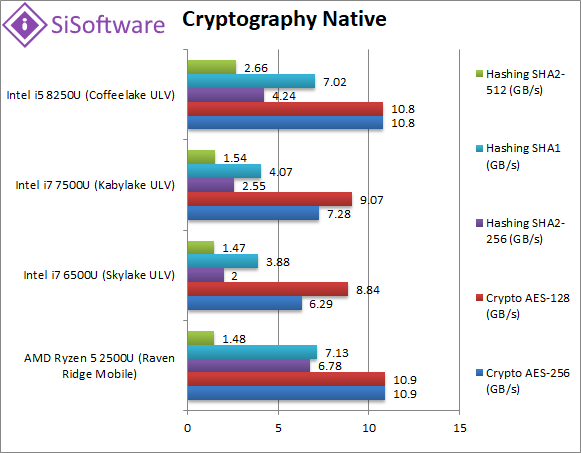
Crypto AES-256 (GB/s) | 10.9 [+1%] | 6.29 | 7.28 | 10.8 | With AES/HWA support all CPUs are memory bandwidth bound – here Ryzen2 ties with CFL-U and soundly beats older versions. |
|
Crypto AES-128 (GB/s) | 10.9 [+1%] | 8.84 | 9.07 | 10.8 | What we saw with AES-256 just repeats with AES-128; Ryzen2 is marginally faster but the improvement is there. |
|
Crypto SHA2-256 (GB/s) | 6.78 [+60%] | 2 | 2.55 | 4.24 | With SHA/HWA Ryzen2 similarly powers through hashing tests leaving Intel in the dust; SHA is still memory bound but Ryzen2 is 60% faster than CFL-U. |
|
Crypto SHA1 (GB/s) | 7.13 [+2%] | 3.88 | 4.07 | 7.02 | Ryzen also accelerates the soon-to-be-defunct SHA1 but CFL-U with AVX2 has caught up. |
|
Crypto SHA2-512 (GB/s) | 1.48 [-44%] | 1.47 | 1.54 | 2.66 | SHA2-512 is not accelerated by SHA/HWA thus Ryzen2 falls behind here. |
| Ryzen2 mobile (like its desktop brother) gets a boost from SHA/HWA but otherwise ties with CFL-U which is helped by its SIMD units. As before older 2-core i7 SKL/KBL-U are left with no hope and cannot even saturate the memory bandwidth. | ||||||
 |
||||||
 |
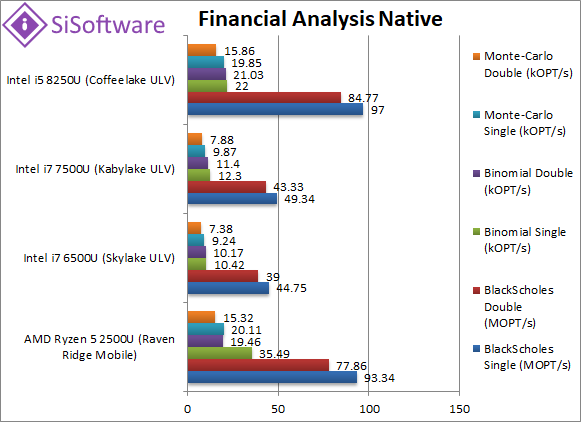
Black-Scholes float/FP32 (MOPT/s) | 93.3 [-4%] | 44.7 | 49.3 | 97 | In this non-vectorised test we see Ryzen2 matches CFL-U. |
|
Black-Scholes double/FP64 (MOPT/s) | 77.8 [-8%] | 39 | 43.3 | 84.7 | Switching to FP64 code, nothing much changes, Ryzen2 is 8% slower. |
|
Binomial float/FP32 (kOPT/s) | 35.5 [+61%] | 10.4 | 12.3 | 22 | Binomial uses thread shared data thus stresses the cache & memory system; here the arch(itecture) improvements do show, Ryzen2 is 60% faster than CFL-U. |
|
Binomial double/FP64 (kOPT/s) | 19.5 [-7%] | 10.1 | 11.4 | 21 | With FP64 code Ryzen2 drops back from its previous win. |
|
Monte-Carlo float/FP32 (kOPT/s) | 20.1 [+1%] | 9.24 | 9.87 | 19.8 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches; Ryzen2 cannot match its previous gain. |
|
Monte-Carlo double/FP64 (kOPT/s) | 15.3 [-3%] | 7.38 | 7.88 | 15.8 | Switching to FP64 nothing much changes, Ryzen2 matches CFL-U. |
| Unlike desktop where Ryzen2 is unstoppable, here we are a more mixed result – with CFL-U able to trade blows with it except one test where Ryzen2 is 60% faster. Otherwise CFL-U does manage to be just a bit faster in the other tests but nothing significant. | ||||||
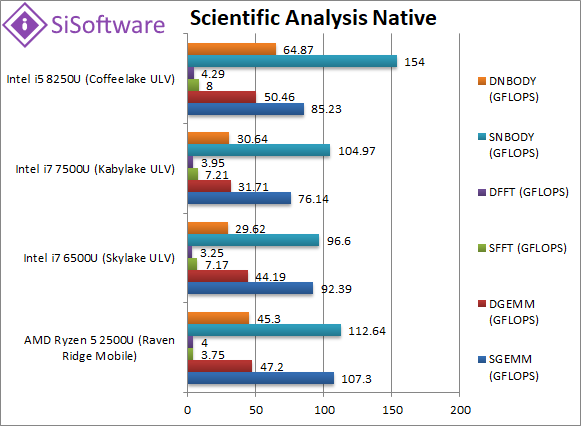 |
||||||
 |
SGEMM (GFLOPS) float/FP32 | 107 [+16%] | 92 | 76 | 85 | In this tough vectorised AVX2/FMA algorithm Ryzen2 manages to be almost 20% faster than CFL-U. |
|
DGEMM (GFLOPS) double/FP64 | 47.2 [-6%] | 44.2 | 31.7 | 50.5 | With FP64 vectorised code, Ryzen2 drops down to 6% slower. |
|
SFFT (GFLOPS) float/FP32 | 3.75 [-53%] | 7.17 | 7.21 | 8 | FFT is also heavily vectorised (x4 AVX2/FMA) but stresses the memory sub-system more; Ryzen2 does not like it much. |
|
DFFT (GFLOPS) double/FP64 | 4 [-7%] | 3.23 | 3.95 | 4.3 | With FP64 code, Ryzen2 does better and is just 7% slower. |
|
SNBODY (GFLOPS) float/FP32 | 112 [-27%] | 96.6 | 104.9 | 154 | N-Body simulation is vectorised but many memory accesses and not a Ryzen2 favourite. |
|
DNBODY (GFLOPS) double/FP64 | 45.3 [-30%] | 29.6 | 30.64 | 64.8 | With FP64 code nothing much changes. |
| With highly vectorised SIMD code Ryzen2 remains competitive but finds some algorithms tougher than others. Just as with desktop Ryzen1/2 it may require SIMD code changes for best performance due to its 128-bit units; Ryzen3 with 256-bit units should fix that. | ||||||
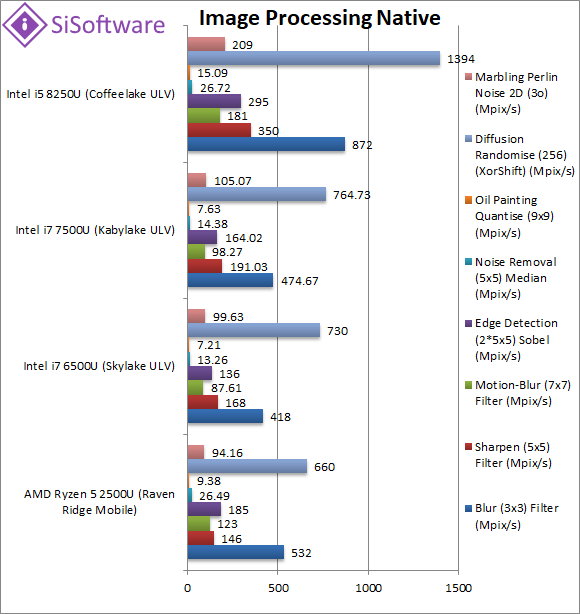 |
||||||
 |
Blur (3×3) Filter (MPix/s) | 532 [-39%] | 418 | 474 | 872 | In this vectorised integer AVX2 workload Ryzen2 is quite a bit slower than CFL-U. |
|
Sharpen (5×5) Filter (MPix/s) | 146 [-58%] | 168 | 191 | 350 | Same algorithm but more shared data makes Ryzen2 even slower, 1/2 CFL-U. |
|
Motion-Blur (7×7) Filter (MPix/s) | 123 [-32%] | 87.6 | 98 | 181 | Again same algorithm but even more data shared reduces the delta to 1/3. |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 185 [-37%] | 136 | 164 | 295 | Different algorithm but still AVX2 vectorised workload still Ryzen2 is ~35% slower. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 26.5 [-1%] | 13.3 | 14.4 | 26.7 | Still AVX2 vectorised code but here Ryzen2 ties with CFL-U. |
|
Oil Painting Quantise Filter (MPix/s) | 9.38 [-38%] | 7.21 | 7.63 | 15.09 | Again we see Ryzen2 fall behind CFL-U. |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 660 [-53%] | 730 | 764 | 1394 | With integer AVX2 workload, Ryzen2 falls behind even SKL/KBL-U. |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 94.1 [-55%] | 99.6 | 105 | 209 | In this final test again with integer AVX2 workload Ryzen2 is 1/2 speed of CFL-U. |
With all the modern instruction sets supported (AVX2, FMA, AES and SHA/HWA) Ryzen2 does extremely well in all workloads – and makes all older i7 SKL/KBL-U designs obsolete and unable to compete. As we said – Intel pretty much had to double the number of cores in CFL-U to stay competitive – and it does – but it is all thanks to AMD.
Even then Ryzen2 does beat CFL-U in non-SIMD tests with the latter being helped tremendously by its wide (256-bit) SIMD units and greatly benefits from AVX2/FMA workloads. But Ryzen3 with double-width SIMD units should be much faster and thus greatly beating Intel designs.
Software VM (.Net/Java) Performance
We are testing arithmetic and vectorised performance of software virtual machines (SVM), i.e. Java and .Net. With operating systems – like Windows 10 – favouring SVM applications over “legacy” native, the performance of .Net CLR (and Java JVM) has become far more important.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest drivers. .Net 4.7.x (RyuJit), Java 1.9.x. Turbo / Boost was enabled on all configurations.
| VM Benchmarks | AMD Ryzen2 2500U Bristol Ridge | Intel i7 6500U (Skylake ULV) | Intel i7 7500U (Kabylake ULV) | Intel i5 8250U (Coffeelake ULV) | Comments | |
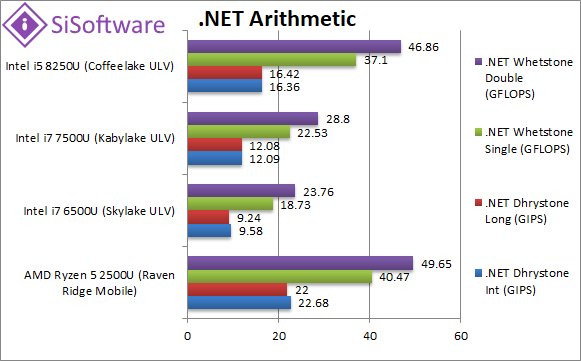 |
||||||
 |
.Net Dhrystone Integer (GIPS) | 22.7 [+39%] | 9.58 | 12.1 | 16.36 | .Net CLR integer starerts great – Ryzen2 is 40% faster than CFL-U. |
|
.Net Dhrystone Long (GIPS) | 22 [+34%] | 9.24 | 12.1 | 16.4 | 64-bit integer workloads also favour Ryzen2, still 35% faster. |
|
.Net Whetstone float/FP32 (GFLOPS) | 40.5 [+9%] | 18.7 | 22.5 | 37.1 | Floating-Point CLR performance is also good but just about 10% faster than CFL-U. |
|
.Net Whetstone double/FP64 (GFLOPS) | 49.6 [+6%] | 23.7 | 28.8 | 46.8 | FP64 performance is also great (CLR seems to promote FP32 to FP64 anyway) with Ryzen2 faster by 6%. |
| .Net CLR performance was always incredible on Ryzen1 and 2 (desktop/workstation) and here is no exception – all Intel designs are left in the dust with even CFL-U soundly beated by anything between 10-40%. | ||||||
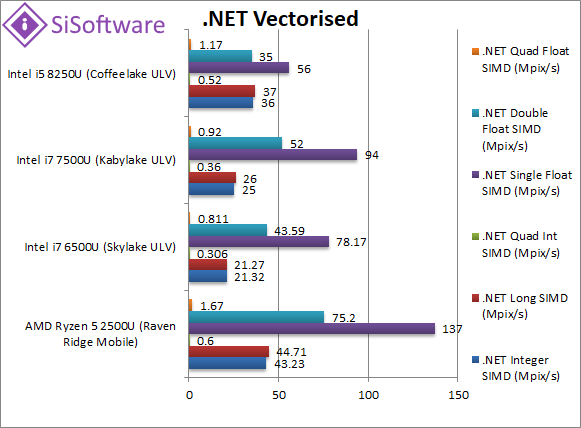 |
||||||
 |
.Net Integer Vectorised/Multi-Media (MPix/s) | 43.23 [+20%] | 21.32 | 25 | 35 | Just as we saw with Dhrystone, this integer workload sees a big 20% improvement for Ryzen2. |
|
.Net Long Vectorised/Multi-Media (MPix/s) | 44.71 [+21%] | 21.27 | 26 | 37 | With 64-bit integer workload we see a similar story – 21% better. |
|
.Net Float/FP32 Vectorised/Multi-Media (MPix/s) | 137 [+46%] | 78.17 | 94 | 56 | Here we make use of RyuJit’s support for SIMD vectors thus running AVX2/FMA code – Ryzen2 does even better here 50% faster than CFL-U. |
|
.Net Double/FP64 Vectorised/Multi-Media (MPix/s) | 75.2 [+45%] | 43.59 | 52 | 35 | Switching to FP64 SIMD vector code – still running AVX2/FMA – we see a similar gain |
| As before Ryzen2 dominates .Net CLR performance – even when using RyuJit’s SIMD instructions we see big gains of 20-45% over CFL-U. | ||||||
 |
||||||
 |
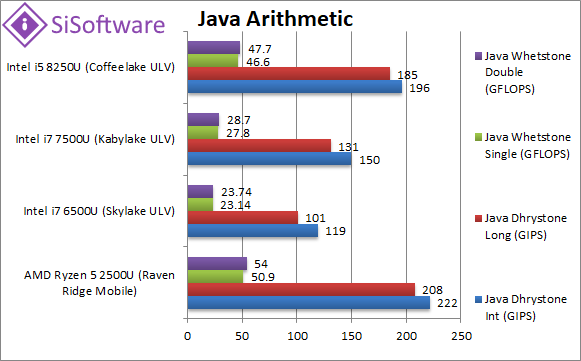
Java Dhrystone Integer (GIPS) | 222 [+13%] | 119 | 150 | 196 | We start JVM integer performance with a 13% lead over CFL-U. |
|
Java Dhrystone Long (GIPS) | 208 [+12%] | 101 | 131 | 185 | Nothing much changes with 64-bit integer workload – Ryzen2 still faster. |
|
Java Whetstone float/FP32 (GFLOPS) | 50.9 [+9%] | 23.13 | 27.8 | 46.6 | With a floating-point workload Ryzen2 performance improvement drops a bit. |
|
Java Whetstone double/FP64 (GFLOPS) | 54 [+13%] | 23.74 | 28.7 | 47.7 | With FP64 workload Ryzen2 gets back to 13% faster. |
| Java JVM performance delta is not as high as .Net but still decent just over 10% over CFL-U similar to what we’ve seen on desktop. | ||||||
 |
||||||
 |
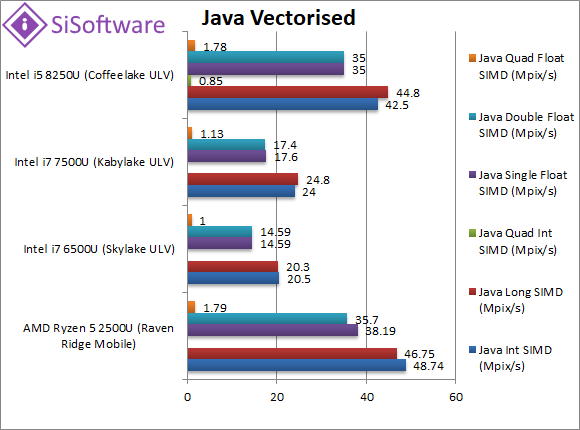
Java Integer Vectorised/Multi-Media (MPix/s) | 48.74 [+15%] | 20.5 | 24 | 42.5 | Oracle’s JVM does not yet support native vector to SIMD translation like .Net’s CLR but Ryzen2 is still 15% faster. |
|
Java Long Vectorised/Multi-Media (MPix/s) | 46.75 [+4%] | 20.3 | 24.8 | 44.8 | With 64-bit vectorised workload Ryzen2’s lead drops to 4%. |
|
Java Float/FP32 Vectorised/Multi-Media (MPix/s) | 38.2 [+9%] | 14.59 | 17.6 | 35 | Switching to floating-point we return to a somewhat expected 9% improvement. |
|
Java Double/FP64 Vectorised/Multi-Media (MPix/s) | 35.7 [+2%] | 14.59 | 17.4 | 35 | With FP64 workload Ryzen2’s lead somewhat unexplicably drops to 2%. |
| Java’s lack of vectorised primitives to allow the JVM to use SIMD instruction sets allow Ryzen2 to do well and overtake CFL-U between 2-15%. | ||||||
Ryzen2 on desktop dominated the .Net and Java benchmarks – and Ryzen2 mobile does not disappoint – it is consistently faster than CFL-U which does not bode well for Intel. If you mainly run .Net and Java apps on your laptop then Ryzen2 is the one to get.
SiSoftware Official Ranker Scores
- AMD Ryzen 7 2700U Radeon Vega Mobile Gfx
- AMD Ryzen 5 2500U Radeon Vega Mobile Gfx
- AMD Ryzen 3 2200U Radeon Vega Mobile Gfx
Final Thoughts / Conclusions
Ryzen2 was a worthy update on the desktop and Ryzen2 mobile does not disappoint; it instantly obsoleted all older Intel designs (SKL/KBL-U) with only the very latest 4-core ULV (CFL/WHL-U) being able to match it. You can see from the results how AMD forced Intel’s hand to double cores in order to stay competitive.
Even then Ryzen2 manages to beat CFL-U in non-SIMD workloads and remains competitive in SIMD AVX2/FMA workloads (only 20% or so slower) while soundly beating SKL/KBL-U with their 2-cores and wide SIMD units. With soon-to-be-released Ryzen3 with wide SIMD units (256-bit as CFL/WHL-U) – Intel will need AVX512 to stay competitive – however it has its own issues which may be problematic in mobile/ULV space.
Both Ryzen2 mobile and CFL/WHL-U have increased TDP (~25W) in order to manage the increased number of cores (instead of 15W with older 2-core designs) and turbo short-term power as much as 35W. This means while larger 14/15″ designs with good cooling are able to extract top performance – smaller 12/13″ designs are forced to use lower cTDP of 15W (20-25W turbo) thus with lower multi-threaded performance.
Also consider than Ryzen2 is not affected by most “Spectre” vulnerabilities and not by “Meltdown” either thus does not need KVA (kernel pages virtualisation) that greatly impacts I/O workloads. Only the very latest Whiskey-Lake ULV (WHL-U gen 8-refresh) has hardware “Meltdown” fixes – thus there is little point buying CFL-U (gen 8 original) and even less point buying older SKL/KBL-U.
In light of the above – Ryzen2 mobile is a compelling choice especially as it comes at a (much) lower price-point: its competition is really only the very latest WHL-U i5/i7 which do not come cheap – with most vendors still selling CFL-U and even KBL-U inventory. The only issue is the small choice of laptops available with it – hopefully the vendors (Dell, HP, etc.) will continue to release more versions especially with Ryzen 3 mobile.
In a word: Highly Recommended!
Please see our other articles on: