What is “Ryzen2” ZEN+ Mobile?
It is the long-awaited Ryzen2 APU mobile “Bristol Ridge” version of the desktop Ryzen 2 with integrated Vega graphics (the latest GPU architecture from AMD) for mobile devices. While on desktop we had the original Ryzen1/ThreadRipper – there was no (at least released) APU version or a mobile version – leaving only the much older designs that were never competitive against Intel’s ULV and H APUs.
After the very successful launch of the original “Ryzen1”, AMD has been hard at work optimising and improving the design in order to hit TDP (15-35W) range for mobile devices. It has also added the brand-new Vega graphics cores to the APU that have been incredibly performant in the desktop space. Note that mobile versions have a single CCX (compute unit) thus do not require operating system kernel patches for best thread scheduling/power optimisation.
Here’s what AMD says it has done for Ryzen2:
- Process technology optimisations (12nm vs 14nm) – lower power but higher frequencies
- Improvements for cache & memory speed & latencies (we shall test that ourselves!)
- Multi-core optimised boost (aka Turbo) algorithm – XFR2 – higher speeds
Why review it now?
With Ryzen3 soon to be released later this year (2019) – with a corresponding Ryzen3 APU mobile – it is good to re-test the platform especially in light of the many BIOS/firmware updates, many video/GPU driver updates and not forgetting the many operating system (Windows) vulnerabilities (“Spectre”) mitigations that have greatly affected performance – sometimes for the good (firmware, drivers, optimisations) sometimes for the bad (mitigations).
In this article we test CPU Cache and Memory performance; please see our other articles on:
Hardware Specifications
We are comparing the top-of-the-range Ryzen2 (2700X, 2600) with previous generation (1700X) and competing architectures with a view to upgrading to a mid-range high performance design.
| CPU Specifications | AMD Ryzen2 2500U Bristol Ridge | Intel i7 6500U (Skylake ULV) | Intel i7 7500U (Kabylake ULV) | Intel i5 8250U (Coffeelake ULV) | Comments | |
| L1D / L1I Caches | 4x 32kB 8-way / 4x 64kB 4-way | 2x 32kB 8-way / 2x 32kB 8-way | 2x 32kB 8-way / 2x 32kB 8-way | 4x 32kB 8-way / 4x 32kB 8-way | Ryzen2 icache is 2x of Intel with matching dcache. | |
| L2 Caches | 4x 512kB 8-way | 2x 256kB 16-way | 2x 256kB 16-way | 4x 256kB 16-way | Ryzen2 L2 cache is 2x bigger than Intel and thus 4x larger than older SKL/KBL-U. | |
| L3 Caches | 4MB 16-way | 4MB 16-way | 4MB 16-way | 6MB 16-way | Here CFL-U brings 50% bigger L3 cache (6 vs 4MB) which may help some workloads. | |
| TLB 4kB pages |
64 full-way / 1536 8-way | 64 8-way / 1536 6-way | 64 8-way / 1536 6-way | 64 8-way / 1536 6-way | No TLB changes. | |
| TLB 2MB pages |
64 full-way / 1536 2-way | 8 full-way / 1536 6-way | 8 full-way / 1536 6-way | 8 full-way / 1536 6-way | No TLB changes, same as 4kB pages. | |
| Memory Controller Speed (MHz) | 600 | 2600 (400-3100) | 2700 (400-3500) | 1600 (400-3400) | Ryzen2’s memory controller runs at memory clock (MCLK) base rate thus depends on memory installed. Intel’s UNC (uncore) runs between min and max CPU clock thus perhaps faster. | |
| Memory Speed (MHz) Max |
1200-2400 (2667) | 1033-1866 (2133) | 1067-2133 (2400) | 1200-2400 (2533) | Ryzen2 now supports up to 2667MHz (officially) which should improve its performance quite a bit – unfortunately fast DDR4 is very expensive right now. | |
| Memory Channels / Width |
2 / 128-bit | 2 / 128-bit | 2 / 128-bit | 2 / 128-bit | All have 128-bit total channel width. | |
| Memory Timing (clocks) |
17-17-17-39 8-56-18-9 1T | 14-17-17-40 10-57-16-11 2T | 15-15-15-36 4-51-17-8 2T | 19-19-19-43 5-63-21-9 2T | Timings naturally depend on memory which for laptops is somewhat limited and quite expensive. | |
| Memory Controller Firmware |
2.1.0 | 3.6.0 | 3.6.4 | Firmware is the same as on desktop devices. | ||
Core Topology and Testing
As discussed in the previous articles (Ryzen1 and Ryzen2 reviews), cores on Ryzen are grouped in blocks (CCX or compute units) each with its own L3 cache – but connected via a 256-bit bus running at memory controller clock. However – unlike desktop/workstations – so far all Ryzen2 mobile designs have a single (1) CCX thus all the issues that “plagued” the desktop/workstation Ryzen designs do note apply here.
However, AMD could have released higher-core mobile designs to go against Intel’s H-line (beefed to 6-core / 12-threads with CFL-H) that would have likely required 2 CCX blocks. At this time (start 2019) considering that Ryzen3 (mobile) will launch soon that seems unlikely to happen…
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (AVX2, AVX, etc.). Ryzen2 mobile supports all modern instruction sets including AVX2, FMA3 and even more.
Results Interpretation: Higher rate values (GOPS, MB/s, etc.) mean better performance. Lower latencies (ns, ms, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
| Native Benchmarks | AMD Ryzen2 2500U Bristol Ridge | Intel i7 6500U (Skylake ULV) | Intel i7 7500U (Kabylake ULV) | Intel i5 8250U (Coffeelake ULV) | Comments | |
 |
||||||
 |
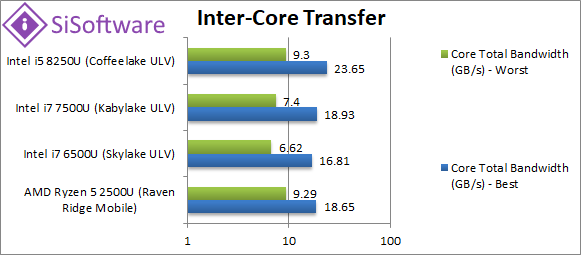
Total Inter-Core Bandwidth – Best (GB/s) | 18.65 [-21%] | 16.81 | 18.93 | 23.65 | Ryzen2 L1D is not as wide as Intel’s designs (512-bit) thus inter-core transfers in L1D are 20% slower. |
|
Total Inter-Core Bandwidth – Worst (GB/s) | 9.29 [=] | 6.62 | 7.4 | 9.3 | Using the unified L3 caches – both Ryzen2 and CFL-U manage the same bandwidths. |
 |
||||||
|
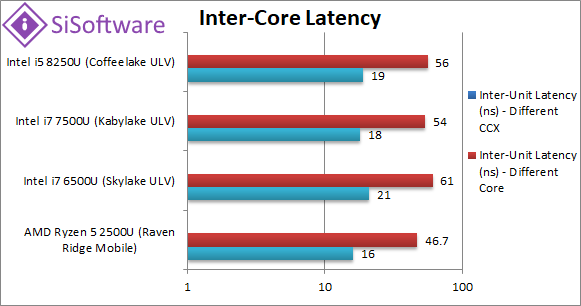
Inter-Unit Latency – Same Core (ns) | 16 [-24%] | 21 | 18 | 19 | Within the same core (share L1D) Ryzen2 has lower latencies by 24% than all Intel CPUs. |
|
Inter-Unit Latency – Same Compute Unit (ns) | 46 [-23%] | 61 | 54 | 56 | Within the same compute unit (shareL3) Ryzen2 again yields 23% lower latencies. |
|
Inter-Unit Latency – Different Compute Unit (ns) | n/a | n/a | n/a | n/a | With a single CCX we have no latency issues. |
| While the L1D cache on Ryzen2 is not as wide as on Intel SKL/KBL/CFL-U to yield the same bandwidth (20% lower), both it and L3 manage lower latencies by a relatively large ~25%. With a single CCX design we have none of the issues seen on the desktop/workstation CPUs. | ||||||
 |
||||||
 |
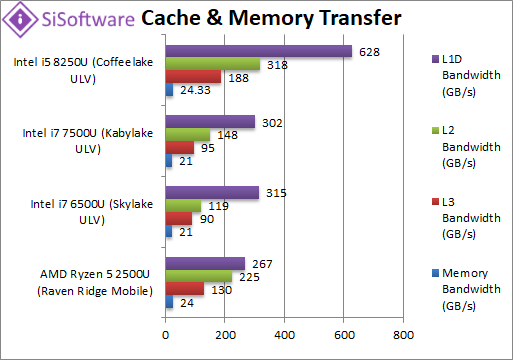
Aggregated L1D Bandwidth (GB/s) | 267 [-67%] | 315 | 302 | 628 | Ryzen2’s L1D is just not wide enough – even 2-core SKL/KBL-U have more bandwidth and CFL-U has almost 3x more. |
|
Aggregated L2 Bandwidth (GB/s) | 225 [-29%] | 119 | 148 | 318 | The 2x larger L2 caches (512 vs 256kB) perform better but still CFL-U manages 30% more bandwidth. |
|
Aggregated L3 Bandwidth (GB/s) | 130 [-31%] | 90 | 95 | 188 | CFL-U not only has 50% bigger L3 (6 vs 4MB) but also somehow manages 30% more bandwidth too while SKL/KBL-U are left in the dust. |
|
Aggregated Memory (GB/s) | 24 [=] |
21 | 21 | 24 | With the same memory clock, Ryzen2 ties with CFL-U which means good bandwidth for the cores. |
| While we saw big improvements on Ryzen2 (desktop) for all caches L1D/L2/L3 – more work needs to be done: in particular the L1D caches are not wide enough compared to Intel’s CPUs – and even L2/L3 need to be wider. Most likely Ryzen3 with native wide 256-bit SIMD (unlike 128-bit as Ryzen1/2) will have twice as wide L1D/L2 that should be sufficient to match Intel.
The memory controller performs well matching CFL-U and is officially rated for higher DDR4 memory – though on laptops the choices are more limited and more expensive. |
||||||
 |
||||||
 |
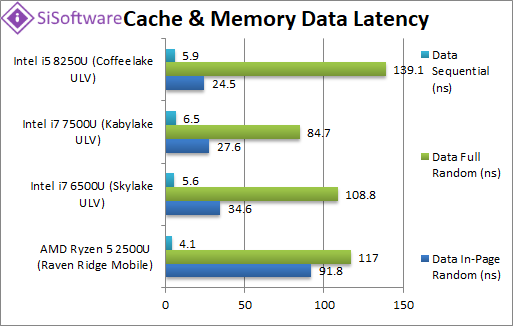
Data In-Page Random Latency (ns) | 91.8 [4-13-32] [+2.75x] | 34.6 [3-10-17] | 27.6 [4-12-22] | 24.5 | As on desktop Ryzen1/2 in-page random latencies are large compared to the competition while L1D/L2 are OK but L3 also somewhat large. |
|
Data Full Random Latency (ns) | 117 [4-13-32] [-16%] | 108 [3-10-27] | 84.7 [4-12-33] | 139 | Out-of-page latencies are not much different which means Ryzen2 is a lot more competitive but still somewhat high. |
|
Data Sequential Latency (ns) | 4.1 [4-6-7] [-31%] |
5.6 [3-10-11] | 6.5 [4-12-13] | 5.9 | Ryzen’s prefetchers are working well with sequential access with lower latencies than Intel |
| Ryzen1/2 desktop issues were high memory latencies (in-page/full random) and nothing much changes here. “In-Page/Random pattern” (TLB hit) latencies are almost 3x higher – actually not much lower compared to “Full/Random pattern” (TBL miss) – which are comparable to Intel’s SKL/KBL/CFL. On the other hand “Sequential pattern” yields lower latencies (30% less) than Intel thus simple access patterns work better than complex/random access patterns. | ||||||
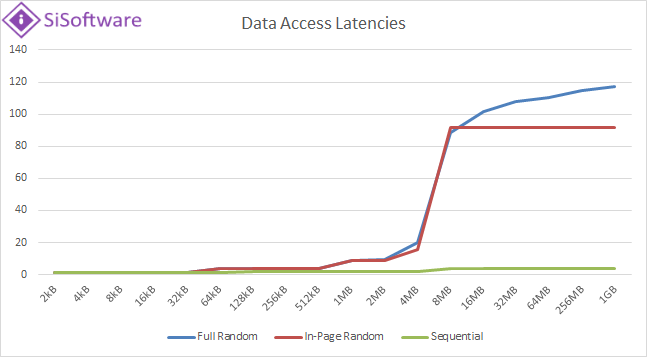 |
||||||
| Looking at the data access latencies’ graph for Ryzen2 mobile – we see the “in-page/random” following the “full/random” latencies all the way to 8MB block where they plateau; we would have expected them to plateau at a lower value. See the “code access latencies” graph below. | ||||||
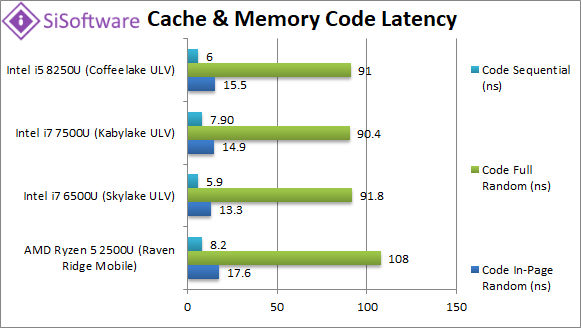 |
||||||
|
Code In-Page Random Latency (ns) | 17.6 [5-9-25] [+14%] | 13.3 [2-9-18] | 14.9 [2-11-21] | 15.5 | Code latencies were not a problem on Ryzen1/2 and they are OK here, 14% higher. |
|
Code Full Random Latency (ns) | 108 [5-15-48] [+19%] | 91.8 [2-10-38] | 90.4 [2-11-45] | 91 | Out-of-page latency is also competitive and just 20% higher. |
|
Code Sequential Latency (ns) | 8.2 [5-13-20] [+37%] | 5.9 [2-4-8] | 7.8 [2-4-9] | 6 | Ryzen’s prefetchers are working well with sequential access pattern latency but not as fast as Intel. |
| Unlike data, code latencies (any pattern) are competitive with Intel though CFL-U does have lower latencies (between 15-20%) but in exchange you get a 2x bigger L1I (64 vs 32kB) which should help complex software. | ||||||
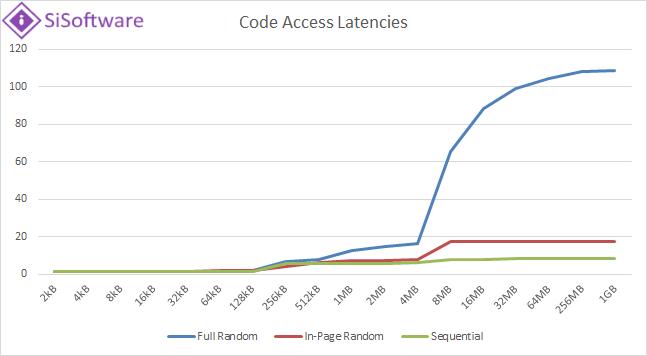 |
||||||
| This graph for code access latencies is what we expected to see for data: “in-page/random” latencies plateau much earlier than “full/random” thus “TLB hit” latencies being much lower than “TLB miss” latencies. | ||||||
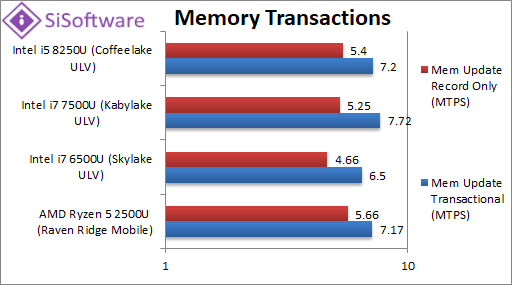 |
||||||
| Memory Update Transactional (MTPS) | 7.17 [-7%] | 6.5 | 7.72 | 7.2 | As none of Intel’s CPUs have HLE enabled Ryzen2 performs really well with just 7% less transactions/second. | |
| Memory Update Record Only (MTPS) | 5.66 [+5%] | 4.66 | 5.25 | 5.4 | With only record updates it manages to be 5% faster. | |
SiSoftware Official Ranker Scores
- AMD Ryzen 7 2700U Radeon Vega Mobile Gfx
- AMD Ryzen 5 2500U Radeon Vega Mobile Gfx
- AMD Ryzen 3 2200U Radeon Vega Mobile Gfx
Final Thoughts / Conclusions
We saw good improvement on Ryzen2 (desktop/workstation) but still not enough to beat Intel and a lot more work is needed both on L1/L2 cache bandwidth/widening and memory latency (“in-page” aka “TBL hit” random access pattern) that cannot be improved with firmware/BIOS updates (AGESA firmware). Ryzen2 mobile does have the potential to use faster DDR4 memory (officially rated 2667MHz) thus could overtake Intel using faster memory – but laptop DDR4 SODIMM choice is limited.
Regardless of these differences – the CPU results we’ve seen are solid thus sufficient to recommend Ryzen2 mobile especially when at a much lower cost than competing designs. Even if you do choose Intel – you will be picking up a better design due to Ryzen2 mobile competition – just compare the SKL/KBL-U and CFL/WHL-U results.
We are looking forward to see what improvements Ryzen3 mobile brings to the mobile platform.
In a word: Recommended – with reservations
In this article we tested CPU Cache and Memory performance; please see our other articles on: