What is “Ryzen2” ZEN+ Mobile?
It is the long-awaited Ryzen2 APU mobile “Bristol Ridge” version of the desktop Ryzen 2 with integrated Vega graphics (the latest GPU architecture from AMD) for mobile devices. While on desktop we had the original Ryzen1/ThreadRipper – there was no (at least released) APU version or a mobile version – leaving only the much older designs that were never competitive against Intel’s ULV and H APUs.
After the very successful launch of the original “Ryzen1”, AMD has been hard at work optimising and improving the design in order to hit TDP (15-35W) range for mobile devices. It has also added the brand-new Vega graphics cores to the APU that have been incredibly performant in the desktop space. Note that mobile versions have a single CCX (compute unit) thus do not require operating system kernel patches for best thread scheduling/power optimisation.
Here’s what AMD says it has done for Ryzen2 mobile:
- Process technology optimisations (12nm vs 14nm) – lower power but higher frequencies
- Radeon RX Vega graphics core (DirectX 12.1)
- Optimised boost (aka Turbo) algorithm – sharing between CPU & GPU cores
In this article we test GP(GPU) integrated graphics performance; please see our other articles on:
Hardware Specifications
We are comparing the graphics units of Ryzen2 mobile with competitive APUs with integrated graphics to determine whether they are good enough for modest use, especially for compute (GPGPU) use supporting the CPU.
| GPGPU Specifications | AMD Radeon RX Vega 8 (2500U) |
Intel UHD 630 (7200U) |
Intel HD Iris 520 (6500U) |
Intel HD Iris 540 (6550U) |
Comments | |
| Arch Chipset | GCN1.5 | GT2 / EV9.5 | GT2 / EV9 | GT3 / EV9 | All graphics cores are minor revisions of previous cores with extra functionality. | |
| Cores (CU) / Threads (SP) | 8 / 512 | 24 / 192 | 24 / 192 | 48 / 384 | Vega has the most SPs though only a few but powerful CUs | |
| ROPs / TMUs | 8 / 32 | 8 / 16 | 8 / 16 | 16 / 24 | Vega has less ROPs than GT3 but more TMUs. | |
| Speed (Min-Turbo) | 300-1100 | 300-1000 | 300-1000 | 300-950 | Turbo boost puts Vega in top position power permitting. | |
| Power (TDP) | 25-35W | 15-25W | 15-25W | 15-25W | TDP is about the same for all though both Ryzen2 and CFL-U have somewhat higher TDP (25W). | |
| Constant Memory | 2.7GB | 1.6GB | 1.6GB | 3.2GB | There is no dedicated constant memory thus a large chunk is available to use (GB) unlike a dedicated video card with very fast but small (kB). | |
| Shared (Local) Memory | 32kB | 64kB | 64kB | 64kB | Intel has 2x larger shared/local memory but slow (likely non dedicated) unlike Vega. | |
| Global Memory | 2.7 / 3GB | 1.6 / 3.2GB | 1.6 / 3.2GB | 3.2 / 6.4GB | About 50% of main memory can be used as global memory – thus pretty large workloads can be run. | |
| Memory System | 128-bit DDR4 2400Mt/s | 128-bit DDR3L 1866Mt/s | 128-bit DDR3L 1866Mt/s | 128-bit DDR4 2133MT/s | Ryzen2’s memory controller is rated for faster data rates thus should be able to use faster (laptop) memory. | |
| Memory Bandwidth (GB/s) |
36 | 30 | 30 | 33 | The high data rate of DDR4 can result in higher bandwidth useful for the GPU cores. | |
| L2 Cache | ? | 512kB | 512kB | 1MB | L2 is comparable to Intel units. | |
| FP64/double ratio | Yes, 1/16x | Yes, 1/8x | Yes, 1/8 | Yes, 1/8x | FP64 is supported and at good ratio but lower than Intel’s. | |
| FP16/half ratio |
Yes, 2x | Yes, 2x | Yes, 2x | Yes, 2x | FP16 is also now supported at twice the rate – again unlike gimped dedicated cards. | |
Processing Performance
We are testing both OpenCL performance using the latest SDK / libraries / drivers from both AMD and competition.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest Intel drivers, OpenCL 2.x. Turbo / Boost was enabled on all configurations.
| Processing Benchmarks | Intel UHD 630 (7200U) | Intel HD Iris 520 (6500U) | Intel HD Iris 540 (6550U) | AMD Radeon RX Vega 8 (2500U) | Comments | |
 |
||||||
 |
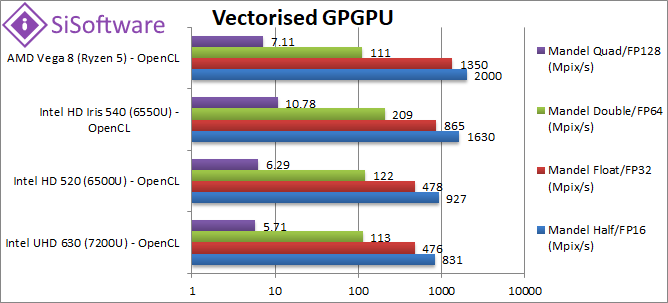
Mandel FP16/Half (Mpix/s) | 831 | 927 | 1630 | 2000 [+23%] | Thanks to FP16 support we see double the performance over FP32 but Vega is only 23% faster than GT3. |
|
Mandel FP32/Single (Mpix/s) | 476 | 478 | 865 | 1350 [+56%] | Vega rules FP32 and is over 50% faster than GT3. |
|
Mandel FP64/Double (Mpix/s) | 113 | 122 | 209 | 111 [-47%] | FP64 lower rate makes Vega 1/2 the speed of GT3 and only matching GT2 units. |
|
Mandel FP128/Quad (Mpix/s) | 5.71 | 6.29 | 10.78 | 7.11 [-34%] | Emulated FP128 precision depends entirely on FP64 performance thus not a lot changes. |
| Vega is over 50% faster than Intel’s top-end Iris/GT3 graphics but only in FP32 precision – while it gains from FP16 Intel scales better reducing the lead to just 25% or so. In FP64 precision though it’s relatively low 1/16x ratio means it only ties with GT2 low-end-models while GT3 is 2x (twice) as fast. Pity. | ||||||
 |
||||||
 |
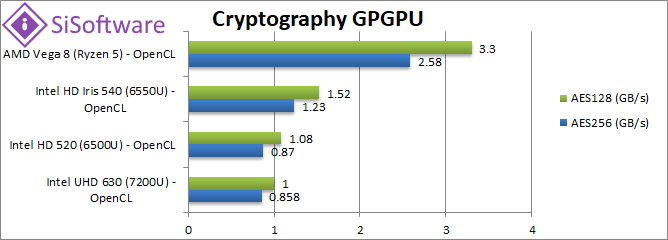
Crypto AES-256 (GB/s) | 0.858 | 0.87 | 1.23 | 2.58 [+2.1x] | No wonder AMD is crypto-king: Vega is over 2x faster than even GT3. |
|
Crypto AES-128 (GB/s) | 1 | 1.08 | 1.52 | 3.3 [+2.17x] | Nothing changes here, Vega is over 2.2x faster. |
 |
||||||
|
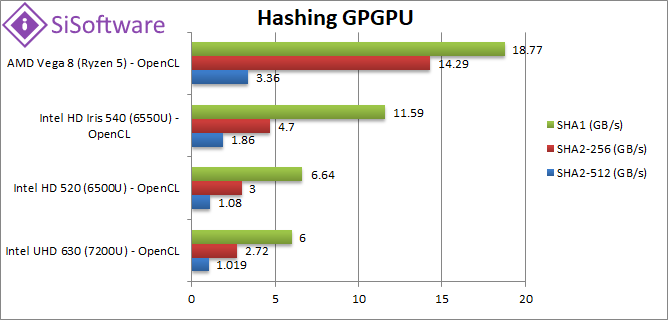
Crypto SHA2-256 (GB/s) | 2.72 | 3 | 4.7 | 14.29 [+3x] | In this heavy integer workload, Vega is now 3x faster no wonder it’s used for crypto mining. |
|
Crypto SHA1 (GB/s) | 6 | 6.64 | 11.59 | 18.77 [+62%] | SHA1 is less compute intensive allowing Intel to catch up but Vega is still over 60% faster. |
|
Crypto SHA2-512 (GB/s) | 1.019 | 1.08 | 1.86 | 3.36 [+81%] | With 64-bit integer workload, Vega does better and is 80% (almost 2x) faster than GT3. |
| Nobody will be using integrated graphics for crypto-mining any time soon, but if you needed to (perhaps using encrypted containers, VMs, etc.) then Vega is your choice – even GT3 is left in the dust despite big improvement over low-end GT2. Intel would need at least 2x more cores to be competitive here. | ||||||
 |
||||||
 |
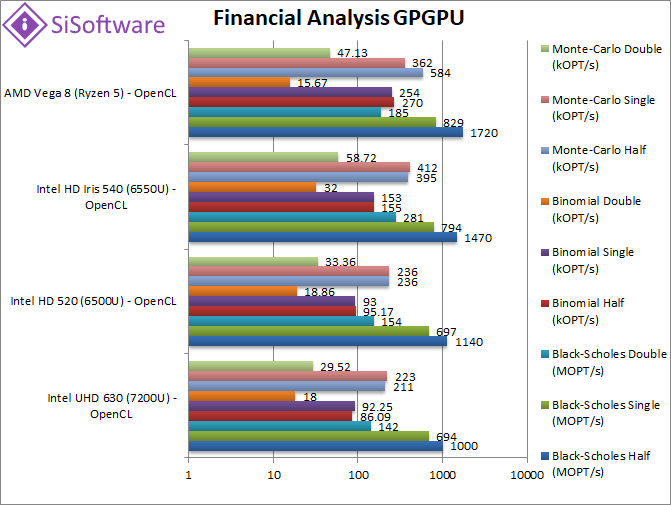
Black-Scholes half/FP16 (MOPT/s) | 1000 | 1140 | 1470 | 1720 [+17%] | If 16-bit precision is sufficient for financial work, Vega is 20% faster than GT3. |
|
Black-Scholes float/FP32 (MOPT/s) | 694 | 697 | 794 | 829 [+4%] | In this relatively simple FP32 financial workload Vega is just 4% faster than GT3. |
|
Black-Scholes double/FP64 (MOPT/s) | 142 | 154 | 281 | 185 [-33%] | Switching to FP64 precision, Vega is 33% slower than GT3. |
|
Binomial half/FP16 (kOPT/s) | 86 | 95 | 155 | 270 [+74%] | Switching to 16-bit precision allows Vega to gain over GT3 and is almost 2x faster. |
|
Binomial float/FP32 (kOPT/s) | 92 | 93 | 153 | 254 [+66%] | Binomial uses thread shared data thus stresses the internal memory sub-system, and here Vega shows its power – it is 66% faster than GT3. |
|
Binomial double/FP64 (kOPT/s) | 18 | 18.86 | 32 | 15.67 [-51%] | With FP64 precision Vega loses again vs. GT3 at 1/2 the speed and just matches GT2 units. |
|
Monte-Carlo half/FP16 (kOPT/s) | 211 | 236 | 395 | 584 [+48%] | With 16-bit precision, Vega dominates again and is almost 50% faster than GT3. |
|
Monte-Carlo float/FP32 (kOPT/s) | 223 | 236 | 412 | 362 [-12%] | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure – but Vega somehow loses against GT3. |
|
Monte-Carlo double/FP64 (kOPT/s) | 29.5 | 33.36 | 58.7 | 47.13 [-20%] | Switching to FP64 precision as expected Vega is slower. |
| Financial algorithms perform well on Vega – at least in FP16 & FP32 precision but FP64 is too “gimped” (1/16x FP32 rate) and thus loses against GT3 despite more powerful cores. | ||||||
 |
||||||
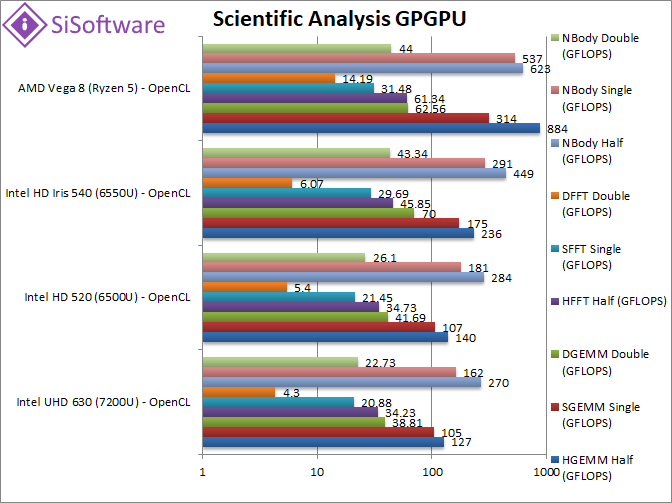
 |
HGEMM (GFLOPS) half/FP16 | 127 | 140 | 236 | 884 [+3.75x] | With 16-bit precision Vega runs away with GEMM and is almost 4x faster than GT3. |
|
SGEMM (GFLOPS) float/FP32 | 105 | 107 | 175 | 214 [+79%] | GEMM makes heavy use of shared/local memory which is likely why Vega is 80% faster than GT3. |
|
DGEMM (GFLOPS) double/FP64 | 38.8 | 41.69 | 70 | 62.6 [-11%] | As expected, due to gimped FP64 rate Vega falls behind GT3 but only by just 11%. |
|
HFFT (GFLOPS) half/FP16 | 34.2 | 34.7 | 45.85 | 61.34 [+34%] | 16-bit precision helps reduce memory bandwidth pressure thus Vega is 34% faster. |
|
SFFT (GFLOPS) float/FP32 | 20.9 | 21.45 | 29.69 | 31.48 [+6%] | FFT is memory access bound but Vega does well to beat GT3. |
|
DFFT (GFLOPS) double/FP64 | 4.3 | 5.4 | 6.07 | 14.19 [+2.34x] | Despite the FP64 rate, Vega manages its memory accesses better beating GT3 by over 2x (two times). |
|
HNBODY (GFLOPS) half/FP16 | 270 | 284 | 449 | 623 [+39%] | 16-bit precision still benefits N-Body and here Vega is 40% faster than GT3. |
|
SNBODY (GFLOPS) float/FP32 | 162 | 181 | 291 | 537 [+85%] | Back to FP32 and Vega has a pretty large 85% lead – almost 2x GT3. |
|
DNBODY (GFLOPS) double/FP64 | 22.73 | 26.1 | 43.34 | 44 [+2%] | With FP64 precision, Vega and GT3 are pretty much tied. |
| Vega performs well on compute heavy scientific algorithms (making heavy use of shared/local memory) and also benefits from half/FP16 to reduce memory bandwidth pressure, but FP64 rate comes back to haunt it where it loses against Intel’s GT3. Pity. | ||||||
 |
||||||
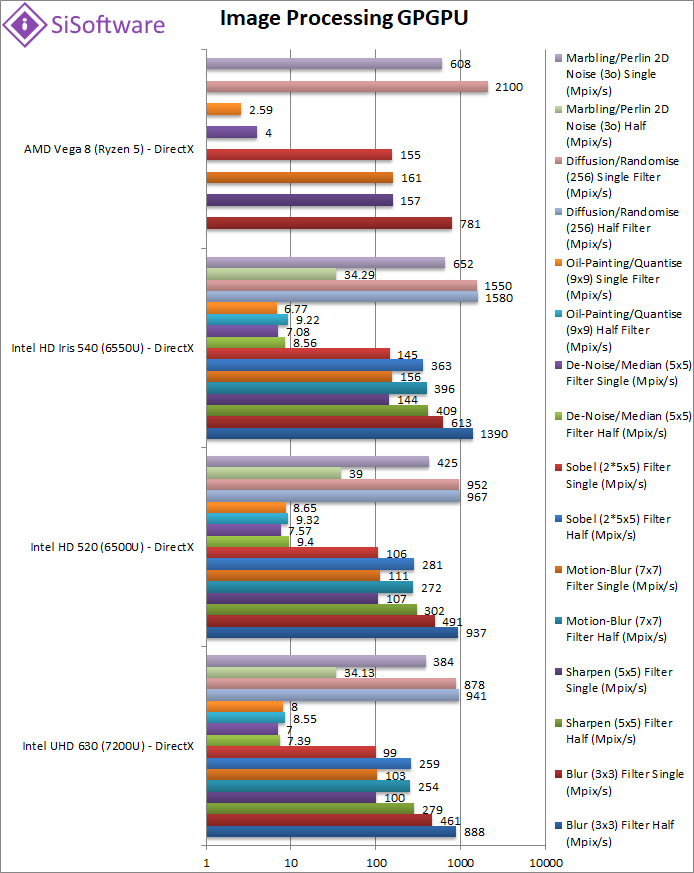
 |
Blur (3×3) Filter half/FP16 (MPix/s) | 888 | 937 | 1390 | 2273 [+64%] | With 16-bit precision Vega doubles its lead to 64% over GT3 despite its gain over FP32. |
|
Blur (3×3) Filter single/FP32 (MPix/s) | 461 | 491 | 613 | 781 [+27%] | In this 3×3 convolution algorithm, Vega does well but only 30% faster than GT3. |
|
Sharpen (5×5) Filter half/FP16 (MPix/s) | 279 | 302 | 409 | 582 [+42%] | Again a huge gain by using FP16, over 40% faster than GT3. |
|
Sharpen (5×5) Filter single/FP32 (MPix/s) | 100 | 107 | 144 | 157 [+9%] | Same algorithm but more shared data reduces the gap to 9%. |
|
Motion Blur (7×7) Filter half/FP16 (MPix/s) | 254 | 272 | 396 | 619 [+56%] | Large gain again by switching to FP16 with 3x performance over FP32. |
|
Motion Blur (7×7) Filter single/FP32 (MPix/s) | 103 | 111 | 156 | 161 [+3%] | With even more shared data the gap falls to just 3%. |
|
Edge Detection (2*5×5) Sobel Filter half/FP16 (MPix/s) | 259 | 281 | 363 | 595 [+64%] | Another huge gain and over 3x improvement over FP32. |
|
Edge Detection (2*5×5) Sobel Filter single/FP32 (MPix/s) | 99 | 106 | 145 | 155 [+7%] | Still convolution but with 2 filters – the gap is similar to 5×5 – Vega is 7% faster. |
|
Noise Removal (5×5) Median Filter half/FP16 (MPix/s) | 7.39 | 9.4 | 8.56 | 7.688 [-18%] | Big gain but not enough to beat GT3 here. |
|
Noise Removal (5×5) Median Filter single/FP32 (MPix/s) | 7 | 7.57 | 7.08 | 4 [-47%] | Vega does not like this algorithm (lots of branching causing divergence) and is 1/2 GT3 speed. |
|
Oil Painting Quantise Filter half/FP16 (MPix/s) | 8.55 | 9.32 | 9.22 | <BSOD> | This test would cause BSOD; we are investigating. |
|
Oil Painting Quantise Filter single/FP32 (MPix/s) | 8 | 8.65 | 6.77 | 2.59 [-70%] | Vega does not like this algorithms either (complex branching) and neither does GT3. |
|
Diffusion Randomise (XorShift) Filter half/FP16 (MPix/s) | 941 | 967 | 1580 | 2091 [+32%] | In order to prevent artifacts most of this test runs in FP32 thus not much gain here. |
|
Diffusion Randomise (XorShift) Filter single/FP32 (MPix/s) | 878 | 952 | 1550 | 2100 [+35%] | This algorithm is 64-bit integer heavy allowing Vega 35% better performance over GT3. |
|
Marbling Perlin Noise 2D Filter half/FP16 (MPix/s) | 341 | 390 | 343 | 1046 [+2.5x] | Switching to FP16 makes a huge difference to Vega which is over 2x faster. |
|
Marbling Perlin Noise 2D Filter single/FP32 (MPix/s) | 384 | 425 | 652 | 608 [-7%] | One of the most complex and largest filters, Vega is a bit slower than GT3 by 7%. |
| For image processing Vega generally performs well in FP32 beating GT3 hands down; but there are a few algorithms that may need to be optimised for it that don’t perform as well as expected. Switching to FP16 though doubles/triples scores – thus Vega may be starved of memory. | ||||||
Memory Performance
We are testing both OpenCL performance using the latest SDK / libraries / drivers from both AMD and competition.
Results Interpretation: Higher values (MB/s, etc.) mean better performance. Lower time values (ns, etc.) mean better performance.
Environment: Windows 10 x64, latest Intel drivers, OpenCL 2.x. Turbo / Boost was enabled on all configurations.
| Memory Benchmarks | Intel UHD 630 (7200U) | Intel HD Iris 520 (6500U) | Intel HD Iris 540 (6550U) | AMD Radeon RX Vega 8 (2500U) | Comments | |
 |
||||||
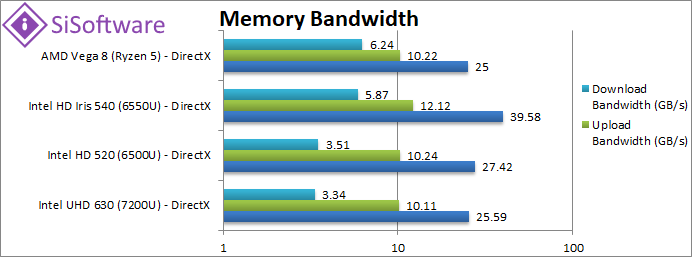
 |
Internal Memory Bandwidth (GB/s) | 12.17 | 21.2 | 24 | 27.32 [+14%] | With higher speed DDR4 memory, Vega has 14% more bandwidth. |
|
Upload Bandwidth (GB/s) | 6 | 10.4 | 11.7 | 4.74 [-60%] | The GPU<>CPU link seems a bit slow here at 1/2 bandwidth of Intel. |
|
Download Bandwidth (GB/s) | 6 | 10.5 | 11.75 | 5 [-57%] | Download bandwidth shows a similar issue, 1/2 bandwidth expected. |
| All designs have to rely on the shared memory controller and Vega performs as expected with good internal bandwidth due to higher speed DDR4 memory. But – transfer up/down speeds are disappointing possibly due to the driver as “zero-copy” mode should be engaged and working on such transfers (APU mode). | ||||||
 |
||||||
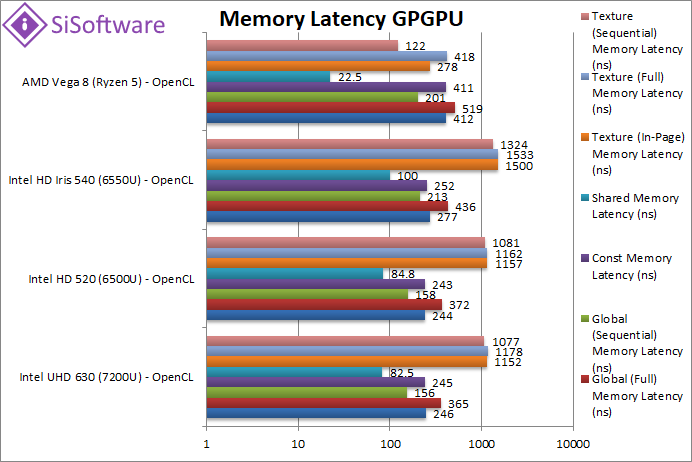
 |
Global (In-Page Random Access) Latency (ns) | 246 | 244 | 288 | 412 [+49%] | Similarly with CPU data latencies, global “in-page/random” (aka “TLB hit”) latencies are a bit high though not by a huge amount. |
|
Global (Full Range Random Access) Latency (ns) | 365 | 372 | 436 | 519 [+19%] | Due to faster memory clock but increased timings “full/random” latencies appear a bit higher. |
|
Global (Sequential Access) Latency (ns) | 156 | 158 | 213 | 201 [-6%] | Sequential access latencies are less than competition by 6%. |
|
Constant Memory (In-Page Random Access) Latency (ns) | 245 | 243 | 252 | 411 [+63%] | None have dedicated constant memory thus we see a similar picture to global memory: somewhat high latencies. |
|
Shared Memory (In-Page Random Access) Latency (ns) | 82 | 84 | 100 | 22.5 [1/5x] | Vega has dedicated shared/local memory and it shows – it’s about 5x faster than Intel’s designs. |
|
Texture (In-Page Random Access) Latency (ns) | 1152 | 1157 | 1500 | 278 [1/5x] | Texture access is also very fast on Vega, with latencies 5x lower (aka 1/5) than Intel’s designs. |
|
Texture (Full Range Random Access) Latency (ns) | 1178 | 1162 | 1533 | 418 [1/3x] | Even full/random accesses are fast, 3x (three times) faster than Intel’s. |
|
Texture (Sequential Access) Latency (ns) | 1077 | 1081 | 1324 | 122 [1/10x] | With sequential access we see a crazy 10x lower latency as if AMD uses prefetchers and Intel does not. |
| As we’ve seen in Ryzen 2’s data latency tests – “in-page/random” latencies are higher than competition but the rest are comparative, with sequential (prefetched) latencies especially small. But dedicated shared/local memory is far faster (5x) and texture accesses are also very fast (3-5x) which should greatly help algorithms making use of them. | ||||||
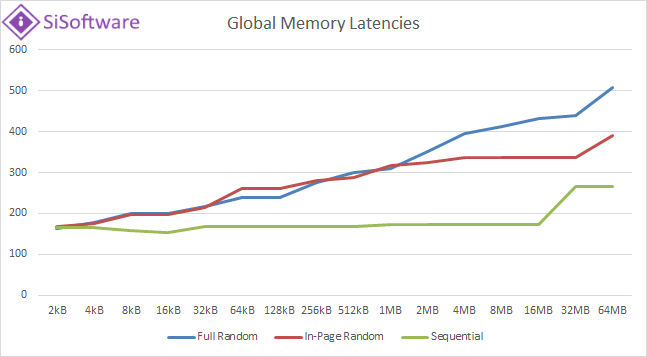 |
||||||
| Plotting the global (or constant) memory latencies together we see that the “in-page/random” access latencies should perhaps peak somewhat lower but still nothing close to what we’ve seen in the (CPU) data memory latencies article. It is not very clear (unlike the texture latencies graph) where the caches are located. | ||||||
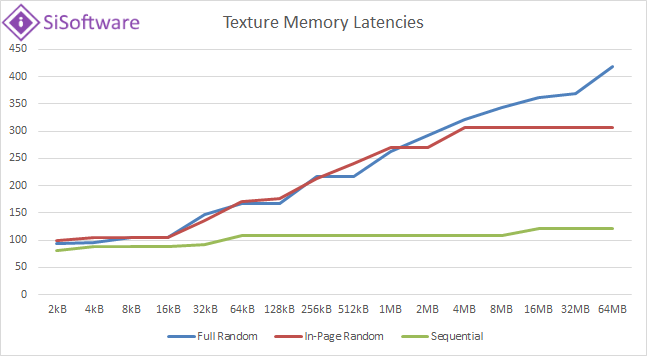 |
||||||
| The texture latencies graph is far clearer where we can see each level’s caches; unlike the global (or constant) latencies we see “in-page/random” latency peak and hold at a somewhat lower level (4MB). | ||||||
SiSoftware Official Ranker Scores
- AMD Ryzen 7 2700U Radeon Vega Mobile Gfx
- AMD Ryzen 5 2500U Radeon Vega Mobile Gfx
- AMD Ryzen 3 2200U Radeon Vega Mobile Gfx
Final Thoughts / Conclusions
Vega mobile, as its desktop big siblings, is undoubtedly powerful and a good upgrade from the older integrated GPU cores; it also supports modern features like half/FP16 compute (which needs vectorisation what the driver reports as “optimised width”) and relishes complex algorithms making use of shared/local memory which is efficient. However Intel’s GT3 EV9.x can get close to it in some workloads and due to better FP64 ratio (1/8x vs 1/16x) even beat it in most FP64 precision tests which is somewhat disappointing.
Luckily for AMD, GT3 variant is very rare and thus Vega has an easy job defeating GT2 in just about all tests; but it shows that should Intel “get serious” and continue to improve integrated graphics (and CPUs) like they used to do before Skylake (SKL/KBL) – AMD might have more serious competition on its hands.
Note that until recently (2019) Ryzen2 mobile APUs were not supported by AMD’s main drivers (“Adrenalin”) and had to rely on pretty old OEM (HP, etc.) drivers that were somewhat problematic especially with Windows 10 changing every 6 months while the drivers were almost 1 year old. Thankfully this has now changed and users (and us) can benefit from updated, stable and performant drivers.
In any case if you want a laptop/ultraportable with just an APU and no dedicated graphics, then Vega is pretty much your only choice which means a Ryzen2 system. That pretty much means it is worthy of a recommendation.
In a word: Highly Recommended
In this article we test GP(GPU) integrated graphics performance; please see our other articles on: