What is AVX512?
AVX512 (Advanced Vector eXtensions) is the 512-bit SIMD instruction set that follows from previous 256-bit AVX2/FMA/AVX instruction set. Originally introduced by Intel with its “Xeon Phi” GPGPU accelerators, it was next introduced on the HEDT platform with Skylake-X (SKL-X/EX/EP) but until now it was not avaible on the mainstream platforms.
With the 10th “real” generation Core arch(itecture) (IceLake/ICL), we finally see “enhanced” AVX512 on the mobile platform which includes all the original extensions and quite a few new ones.
Original AVX512 extensions as supported by SKL/KBL-X HEDT processors:
- AVX512F – Foundation – most floating-point single/double instructions widened to 512-bit.
- AVX512-DQ – Double-Word & Quad-Word – most 32 and 64-bit integer instructions widened to 512-bit
- AVX512-BW – Byte & Word – most 8-bit and 16-bit integer instructions widened to 512-bit
- AVX512-VL – Vector Length eXtensions – most AVX512 instructions on previous 256-bit and 128-bit SIMD registers
- AVX512-CD* – Conflict Detection – loop vectorisation through predication [only on Xeon/Phi co-processors]
- AVX512-ER* – Exponential & Reciprocal – transcedental operations [only on Xeon/Phi co-processors]
New AVX512 extensions supported by ICL processors:
- AVX512-VNNI** (Vector Neural Network Instructions) [also supported by updated CPL-X HEDT]
- AVX512-VBMI, VBMI2 (Vector Byte Manipulation Instructions)
- AVX512-BITALG (Bit Algorithms)
- AVX512-IFMA (Integer FMA)
- AVX512-VAES (Vector AES) accelerating crypto
- AVX512-GFNI (Galois Field)
- AVX512-GNA (Gaussian Neural Accelerator)
As with anything, simply doubling register widths does not automagically increase performance by 2x as dependencies, memory load/store latencies and even data characteristics limit performance gains; some may require future arch updates or tools to realise their true potential.
SIMD FMA Units: Unlike HEDT/server processors, ICL ULV (and likely desktop) have a single 512-bit FMA unit, not two (2): the execution rate (without dependencies) is thus similar for AVX512 and AVX2/FMA code. However, future versions are likely to increase execution units thus AVX512 code will benefit even more.
In this article we test AVX512 core performance; please see our other articles on:
- Intel Core Gen11 TigerLake ULV (i7-1165G7) Review & Benchmarks – CPU AVX512 Performance
- Intel Core Gen10 IceLake ULV (i7-1065G7) Review & Benchmarks – CPU AVX512 Performance
- AVX512 Improvement for Skylake-X (Core i9-9700X)
Native SIMD Performance
We are testing native SIMD performance using various instruction sets: AVX512, AVX2/FMA3, AVX to determine the gains the new instruction sets bring.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest Intel drivers. Turbo / Dynamic Overclocking was enabled on both configurations.
| Native Benchmarks | ICL ULV AVX512 | ICL ULV AVX2/FMA3 | Comments | |||
 |
||||||
 |
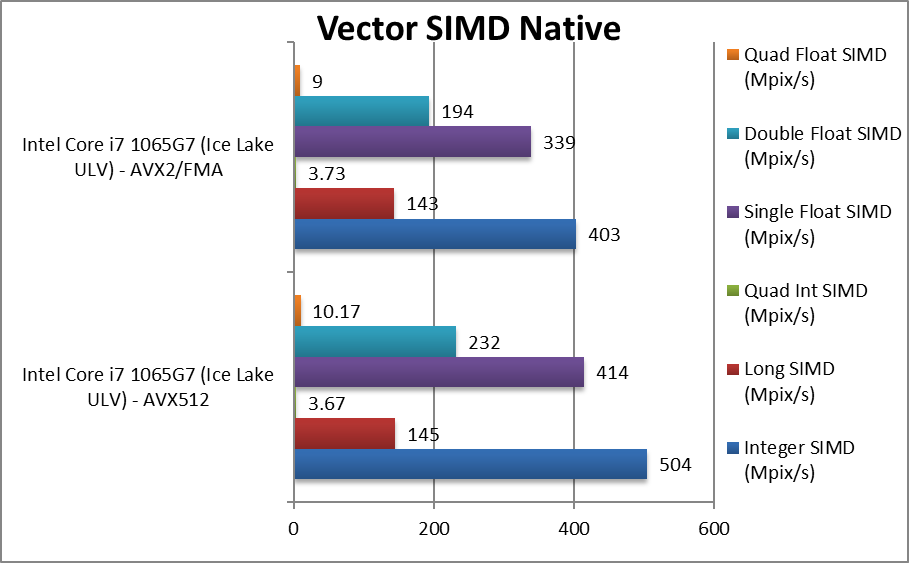
Native Integer (Int32) Multi-Media (Mpix/s) | 504 [+25%] | 403 | For integer workloads we manage25% improvement, not quite the 100% we were hoping but still decent. | ||
|
Native Long (Int64) Multi-Media (Mpix/s) | 145 [+1%] | 143 | With a 64-bit integer workload the improvement reduces to 1%. | ||
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 3.67 | 3.73 [-2%] | – [No SIMD in use here] | ||
|
Native Float/FP32 Multi-Media (Mpix/s) | 414 [+22%] | 339 | In this floating-point test, we see a 22% improvement similar to integer. | ||
|
Native Double/FP64 Multi-Media (Mpix/s) | 232 [+20%] | 194 | Switching to FP64 we see a similar improvement. | ||
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 10.17 [+13%] | 9 | In this heavy algorithm using FP64 to mantissa extend FP128 we see only 13% improvement | ||
| With limited resources, AVX512 cannot bring 100% improvement, but still manages 20-25% improvement over AVX2/FMA which is decent improvement; also consider this is a TDP-constrained ULV platform not desktop/HEDT. | ||||||
 |
||||||
 |
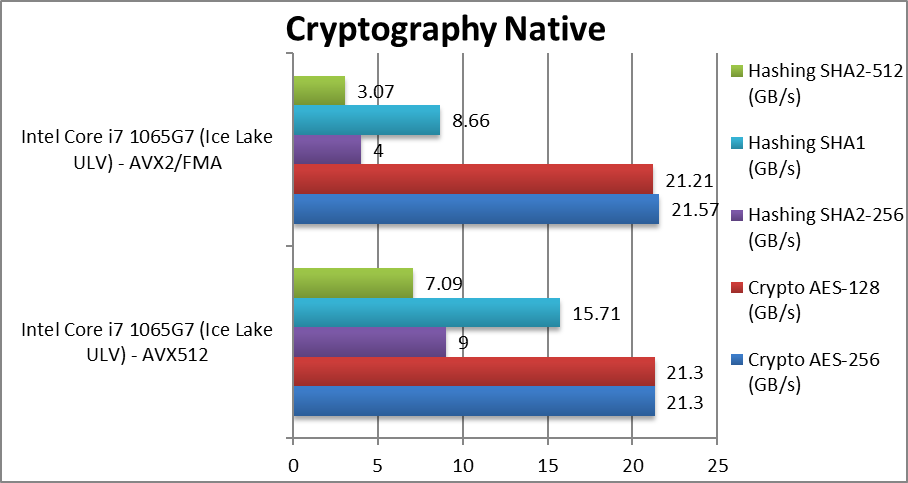
Crypto SHA2-256 (GB/s) | 9 [+2.25x] | 4 | With no data dependency – we get great scaling of over 2x in this integer workload. | ||
|
Crypto SHA1 (GB/s) | 15.71 [+81%] | 8.6 | Here we see only 80% improvement likely due to lack of (more) memory bandwidth – it likely would scale higher. | ||
|
Crypto SHA2-512 (GB/s) | 7.09 [+2.3x] | 3.07 | With 64-bit integer workload we see larger than 2x improvement. | ||
| Thanks to the new crypto-algorithm friendly acceleration instructions of AVX512 and no doubt helped by high-bandwidth LP-DDR4X memory, we see over 2x (twice) improvement over older AVX2. ICL ULV will no doubt be a great choice for low-power network devices (routers/gateways/firewalls) able to pump 100′ Gbe crypto streams. | ||||||
 |
||||||
 |
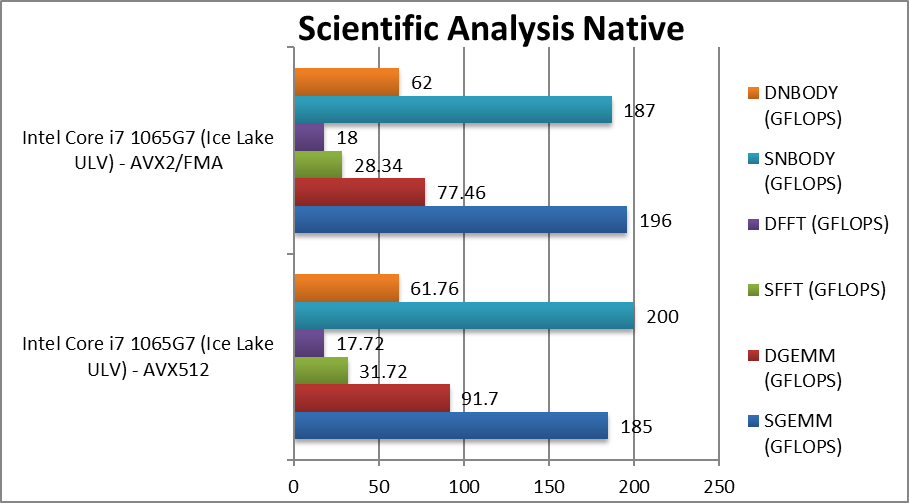
SGEMM (GFLOPS) float/FP32 | 185 [-6%] | 196 | More optimisations seem to be required here for ICL at least. | ||
|
DGEMM (GFLOPS) double/FP64 | 91 [+18%] | 77 | Changing to FP64 brings a 18% improvement. | ||
|
SFFT (GFLOPS) float/FP32 | 31.72 [+12%] | 28.34 | With FFT, we see a modest 12% improvement. | ||
|
DFFT (GFLOPS) double/FP64 | 17.72 [-2%] | 18 | With FP64 we see 2% regression. | ||
|
SNBODY (GFLOPS) float/FP32 | 200 [+7%] | 187 | No help from the compiler here either. | ||
|
DNBODY (GFLOPS) double/FP64 | 61.76 [=] | 62 | With FP64 there is no delta. | ||
| With highly-optimised scientific algorithms, it seems we still have some way to go to extract more performance out of AVX512, though overall we still see a 7-12% improvement even at this time. | ||||||
 |
||||||
 |
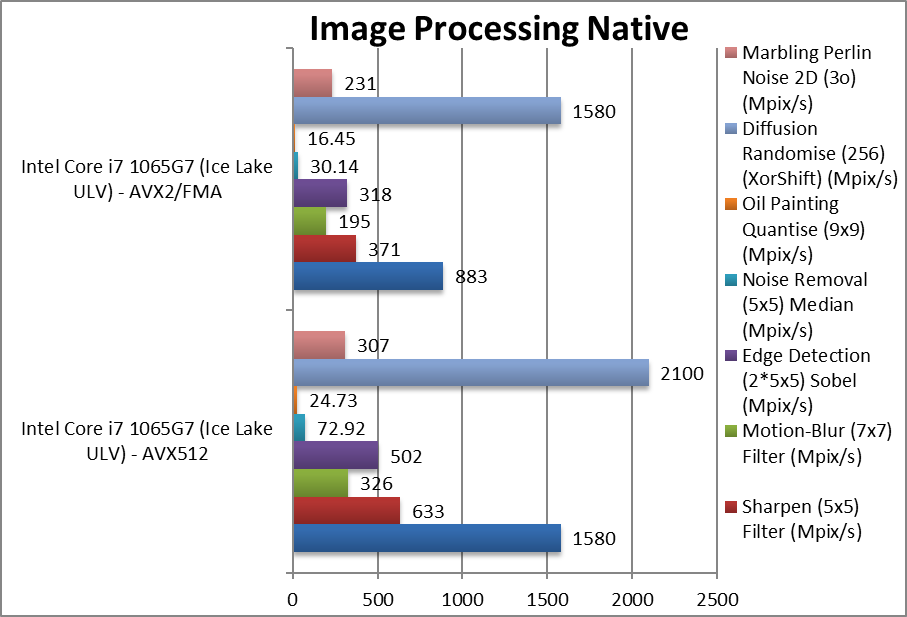
Blur (3×3) Filter (MPix/s) | 1,580 [+79%] | 883 | We start well here with AVX512 80% faster with float FP32 workload. | ||
|
Sharpen (5×5) Filter (MPix/s) | 633 [+71%] | 371 | Same algorithm but more shared data improves by 70%. | ||
|
Motion-Blur (7×7) Filter (MPix/s) | 326 [+67%] | 195 | Again same algorithm but even more data shared now brings the improvement down to 67%. | ||
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 502 [+58%] | 318 | Using two buffers does not change much still 58% improvement. | ||
|
Noise Removal (5×5) Median Filter (MPix/s) | 72.92 [+2.4x] | 30.14 | Different algorithm works better, with AVX512 over 2x faster. | ||
|
Oil Painting Quantise Filter (MPix/s) | 24.73 [+50%] | 16.45 | Using the new scatter/gather in AVX512 still brings 50% better performance. | ||
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 2,100 [+33%] | 1,580 | Here we have a 64-bit integer workload algorithm with many gathers still good 33% improvement. | ||
|
Marbling Perlin Noise 2D Filter (MPix/s) | 307 [+33%] | 231 | Again loads of gathers and similar 33% improvement. | ||
| Image manipulation algorithms working on individual (non-dependent) pixels love AVX512, with 33-140% improvement. The new scatter/gather instructions also simplily memory access code that can benefit from future arch improvements. | ||||||
 |
||||||
 |
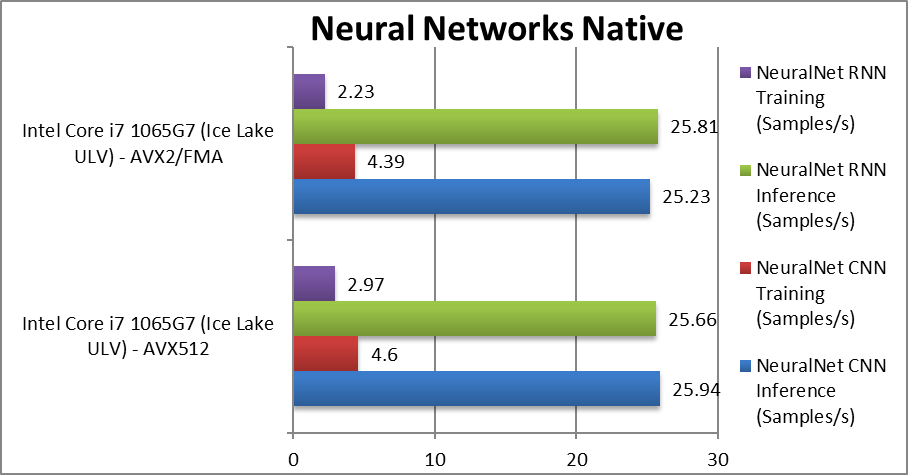
NeuralNet CNN Inference (Samples/s) | 25.94 [+3%] | 25.23 | Inference improves by a mere 3% only despite few dependencies. | ||
|
NeuralNet CNN Training (Samples/s) | 4.6 [+5%] | 4.39 | Traning improves by a slighly better 5% likely due to 512-bit accesses. | ||
|
NeuralNet RNN Inference (Samples/s) | 25.66 [-1%] | 25.81 | RNN interference seems very slighly slower. | ||
|
NeuralNet RNN Training (Samples/s) | 2.97 [+33%] | 2.23 | Finally RNN traning improves by 33%. | ||
| Unlike image manipulation, neural networks don’t seem to benefit as much pretty much the same performance across board. Clearly more optimisation is needed to push performance. | ||||||
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
We never expected a low-power TDP (power)-limited ULV platform to benefit from AVX512 as much as HEDT/server platforms – especially when you consider the lower count of SIMD execution units. Nevertheless, it is clear that ICL (even in ULV form) benefits greatly from AVX512 with 50-100% improvement in many algorithms and no loses.
ICL also introduces many new AVX512 extensions which can even be used to accelrate existing AVX512 code (not just legacy AVX2/FMA), we are likely to see even higher gains in the future as software (and compilers) take advantage of the new extensions. Future CPU architectures are also likely to optimise complex instructions as well as add more SIMD/FMA execution units which will greatly improve AVX512 code performance.
As the data-paths for caches (L1D, L2?) have been widened, 512-bit memory accesses help extract more bandwidth for streaming algorithms (e.g. crypto) while scatter/gather instruction reduce latencies for non-sequential data accesses. Thus the benefit of AVX512 extends to more than just raw compute code.
We are excitedly waiting to see how AVX512-enabled desktop/HEDT ICL performs, not constrained by TDP and adequately cooled…

Intel Ice Lake