What is “Iris Plus” / “IceLake”?
It is the “proper” 10th generation Core arch (ICL) from Intel – the brand new core to replace the ageing “Skylake” (SKL) arch and its many derivatives; due to delays it actually debuts shortly after the latest update (“CometLake” (CLM)) that is also called 10th generation. Firstly launched for mobile ULV (U/Y) devices, it will also be launched for mainstream (desktop/workstations) soon.
Thus it contains extensive changes to all parts of the SoC: CPU, GPU, memory controller:
- 10nm+ process (lower voltage, performance benefits)
- Gen11 graphics (finally up from Gen9.5 for CometLake/WhiskyLake)
- 64 EUs up to 1.1GHz – up to 1.12 TFLOPS/FP32, 2.25TFLOPS/FP16
- 2-channel LP-DDR4X support up to 3733Mt/s
- No eDRAM cache unfortunately (like CrystallWell and co)
- VBR (Variable Rate Shading) – useful for games
The biggest change GPGPU-wise is the increase in EUs (64 top end) which greatly increases processing power compared to previous generation using few EUs (24 except very rare GT3 version). Most of the features seem to be geared towards gaming not GPGPU – thus one omission is no FP64 support! While mobile platforms are not very likely to use high-precision kernels, Gen9 FP64 performance did exceed CPU AVX2/FMA FP64 performance. FP16 is naturally supported, 2x rate as most current designs.
While there does not seem to be eDRAM (L4) cache at all, thanks to very high-speed LP-DDR4X memory (at 3733Mt/s) the bandwidth has almost doubled (58GB/s) which should greatly help bandwidth-intensive workloads. While L1 does not seem changed, L2 has been increased to 3MB (up from 1MB) which should also help.
We do hope to see more GPGPU-friendly features in upcoming versions now that Intel is taking graphics seriously.
GPGPU (Gen11 G7) Performance Benchmarking
In this article we test GPGPU core performance; please see our other articles on:
- CPU
- Intel Core Gen11 TigerLake ULV (i7-1165G7) Review & Benchmarks – CPU AVX512 Performance
- Benchmarks of JCC Erratum Mitigation – Intel CPUs
- Intel Core Gen10 IceLake ULV (i7-1065G7) Review & Benchmarks – Cache & Memory Performance
- Intel Core Gen10 IceLake ULV (i7-1065G7) Review & Benchmarks – CPU AVX512 Performance
- AVX512 Improvement for Icelake Mobile (i7-1065G7 ULV)
- GPGPU
Hardware Specifications
We are comparing the middle-range Intel integrated GP-GPUs with previous generation, as well as competing architectures with a view to upgrading to a brand-new, high performance, design.
| GPGPU Specifications | Intel UHD 630 (7200U) | Intel Iris HD 540 (6550U) | AMD Vega 8 (Ryzen 5) | Intel Iris Plus (1065G7) | Comments | |
| Arch Chipset | EV9.5 / GT2 | EV9 / GT3 | Vega / GCN1.5 | EV11 / G7 | The first G11 from Intel. | |
| Cores (CU) / Threads (SP) | 24 / 192 | 48 / 384 | 8 / 512 | 64 / 512 | Less powerful CU but same SP as Vega | |
| SIMD per CU / Width | 8 | 8 | 64 | 8 | Same SIMD width | |
| Wave/Warp Size | 32 | 32 | 64 | 32 | Wave size matches nVidia | |
| Speed (Min-Turbo) |
300-1000MHz | 300-950MHz | 300-1100MHz | 400-1100MHz | Turbo maches Vega. | |
| Power (TDP) | 15-25W | 15-25W | 25W | 15-25W | Same TDP | |
| ROP / TMU | 8 / 16 | 16 / 24 | 8 / 32 | 16 / 32 |
ROPs the same but TMU have increased. | |
| Shared Memory |
64kB |
64kB | 32kB | 64kB | Same shared memory but 2x Vega. | |
| Constant Memory |
1.6GB | 3.2GB | 2.7GB | 3.2GB | No dedicated constant memory but large. | |
| Global Memory | 2x DDR4 2133Mt/s | 2x DDR4 2133Mt/s | 2x DDR4 2400Mt/s | 2x LP-DDR4X 3733Mt/s | Fastest memory ever | |
| Memory Bandwidth |
38GB/s | 38GB/s | 42GB/s | 58GB/s | Highest bandwidth ever | |
| L1 Caches | 16kB x 24 | 16kB x 48 | 8x 16kB | 16kB x 64kB | L1 does not appear changed. | |
| L2 Cache | 512kB | 1MB | ? | 3MB | L2 has tripled in size | |
| Maximum Work-group Size |
256×256 | 256×256 | 1024×1024 | 256×256 | Vega supports 4x bigger workgroups | |
| FP64/double ratio |
1/16x | 1/16x | 1/32x | No! | No FP64 support in current drivers! | |
| FP16/half ratio |
2x | 2x | 2x | 2x | Same 2x ratio | |
Processing Performance
We are testing both OpenCL performance using the latest SDK / libraries / drivers from both Intel and competition.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest Intel and AMD drivers. Turbo / Boost was enabled on all configurations.
| Processing Benchmarks | Intel UHD 630 (7200U) | Intel Iris HD 540 (6550U) | AMD Vega 8 (Ryzen 5) | Intel Iris Plus (1065G7) | Comments | |
 |
||||||
 |
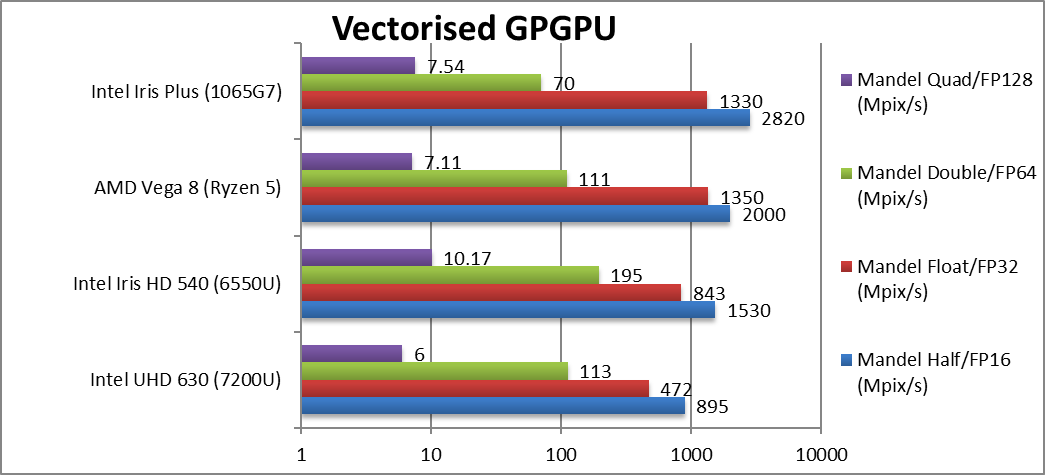
Mandel FP16/Half (Mpix/s) | 895 | 1,530 | 2,000 | 2,820 [+41%] | G7 beats Vega by 40%! Pretty incredible start. |
|
Mandel FP32/Single (Mpix/s) | 472 | 843 | 1,350 | 1,330 [-1%] | Standard FP32 is just a tie. |
|
Mandel FP64/Double (Mpix/s) | 113 | 195 | 111 | 70* | Without native FP64 support G7 craters, but old GT3 beats Vega. |
|
Mandel FP128/Quad (Mpix/s) | 6 | 10.2 | 7.1 | 7.54* | Emulated FP128 is hard on FP64 units and G7 beats Vega again. |
| G7 ties with Mobile Vega in FP32 which in itself is a great achievement but FP16 is much faster. Unfortunately, without native FP64 support – G7 is a lot slower using emulation – but hopefully mobile systems don’t use high-precision kernels.
* Emulated FP64 through FP32. |
||||||
 |
||||||
 |
Crypto AES-256 (GB/s) | 0.88 | 1.14 | 2.58 | 2.6 [+1%] | G7 manages to tie with Vega on this streaming test. |
|
Crypto AES-128 (GB/s) | 1.1 | 1.42 | 3.3 | 3.4 [+2%] | Nothing much changes when changing to 128bit. |
 |
||||||
|
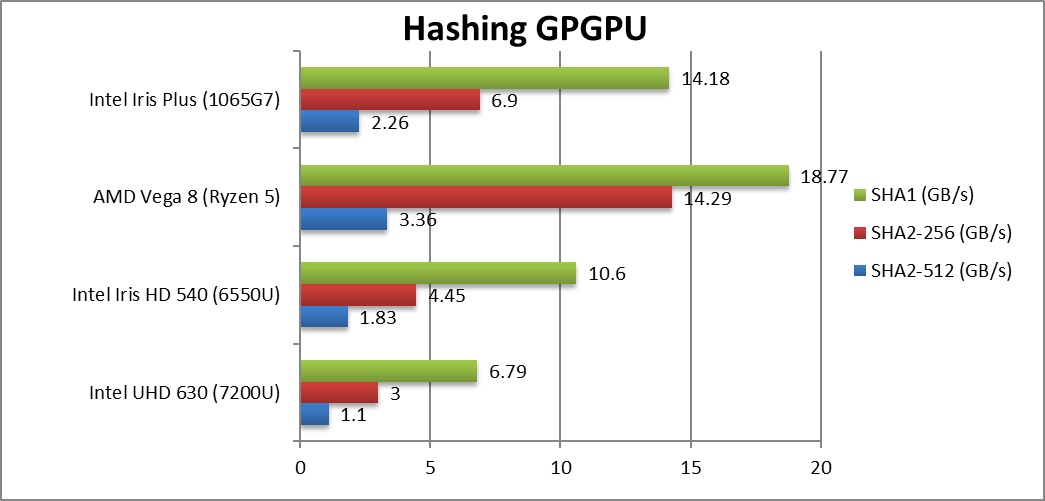
Crypto SHA2-256 (GB/s) | 1.1 | 1.83 | 3.36 | 2.26 [-33%] | Without crypto acceleration G7 cannot match Vega. |
|
Crypto SHA1 (GB/s) | 3 | 4.45 | 14.29 | 6.9 [1/2x] | With 128-bit G7 is 1/2 speed of Vega. |
|
Crypto SHA2-512 (GB/s) | 6.79 | 10.6 | 18.77 | 14.18 [-24%] | 64-bit integer workload is still 25% slower. |
| Thanks to the fast LP-DDR4X memory and its high bandwidth, G7 performance ties with Vega on integer workloads. However, G7 has not crypto acceleration thus Vega is much faster – thus crypto-currency/coin algorithms still favour AMD. | ||||||
 |
||||||
 |
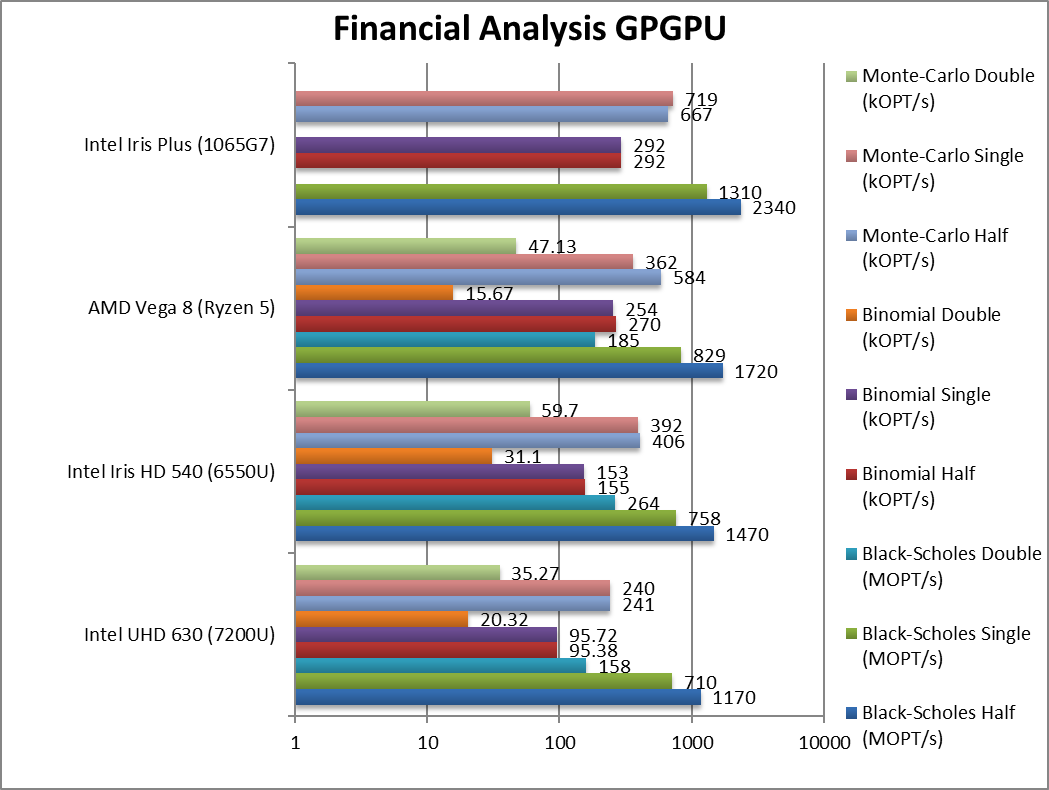
Black-Scholes float/FP16 (MOPT/s) | 1,170 | 1,470 | 1,720 | 2,340 [+36%] | With FP16 we see G7 win again by ~35%. |
|
Black-Scholes float/FP32 (MOPT/s) | 710 | 758 | 829 | 1,310 [+58%] | With FP32 G7 is now even faster – 60% faster than Vega. |
|
Black-Scholes double/FP64 (MOPT/s) | 158 | 264 | 185 | – | No FP64 support. |
|
Binomial float/FP32 (kOPT/s) | 95.7 | 153 | 254 | 292 [+8%] | Binomial uses thread shared data thus stresses the memory system so G7 is just 15% faster. |
|
Binomial double/FP64 (kOPT/s) | 20.32 | 31.1 | 15.67 | – | No FP64 support. |
|
Monte-Carlo float/FP32 (kOPT/s) | 240 | 392 | 362 | 719 [+2x] | Monte-Carlo also uses thread shared data but read-only and here G7 is 2x faster. |
|
Monte-Carlo double/FP64 (kOPT/s) | 35.27 | 59.7 | 47.13 | – | No FP64 support. |
| For financial FP32/FP16 workloads, G7 is between 8% to 100% faster than the Vega – thus for financial workloads it is a great choice. Unfortunately, due to lack of FP64 support – it cannot run high-precision workloads which may be a problem for some algorithms. | ||||||
 |
||||||
 |
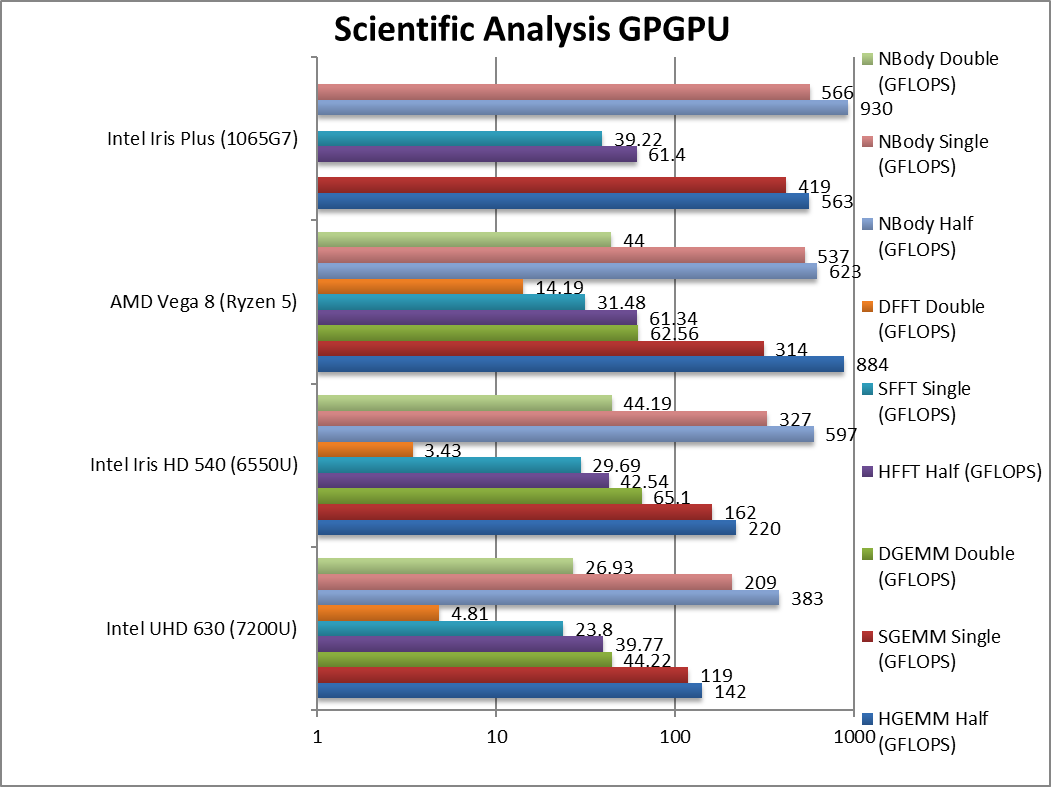
HGEMM (GFLOPS) float/FP16 | 142 | 220 | 884 | 563 [-36%] | G7 cannot beat Vega despite previous FP16 great performance. |
|
SGEMM (GFLOPS) float/FP32 | 119 | 162 | 314 | 419 [+33%] | With FP32, G7 is 33% faster than Vega. |
|
DGEMM (GFLOPS) double/FP64 | 44.2 | 65.1 | 62.5 | – | No FP64 support |
|
HFFT (GFLOPS) float/FP16 | 39.77 | 42.54 | 61.34 | 61.4 [=] | G7 manages to tie with Vega here. |
|
SFFT (GFLOPS) float/FP32 | 23.8 | 29.69 | 31.48 | 39.22 [+25%] | With FP32, G7 is 25% faster. |
|
DFFT (GFLOPS) double/FP64 | 4.81 | 3.43 | 14.19 | – | No FP64 support |
|
HNBODY (GFLOPS) float/FP16 | 383 | 597 | 623 | 930 [+49%] | G7 comes up strong here winning by 50%. |
|
SNBODY (GFLOPS) float/FP32 | 209 | 327 | 537 | 566 [+5%] | With FP32, G7 drops to just 5% faster than Vega. |
|
DNBODY (GFLOPS) double/FP64 | 26.93 | 44.19 | 44 | – | |
| On scientific algorithms, G7 manages to beat Vega between 25-50% with FP32 precision and sometimes with FP16 as well. Again, the lack of FP64 support means all the high-precision kernels cannot be used which for some algorithms may be a problem. | ||||||
 |
||||||
 |
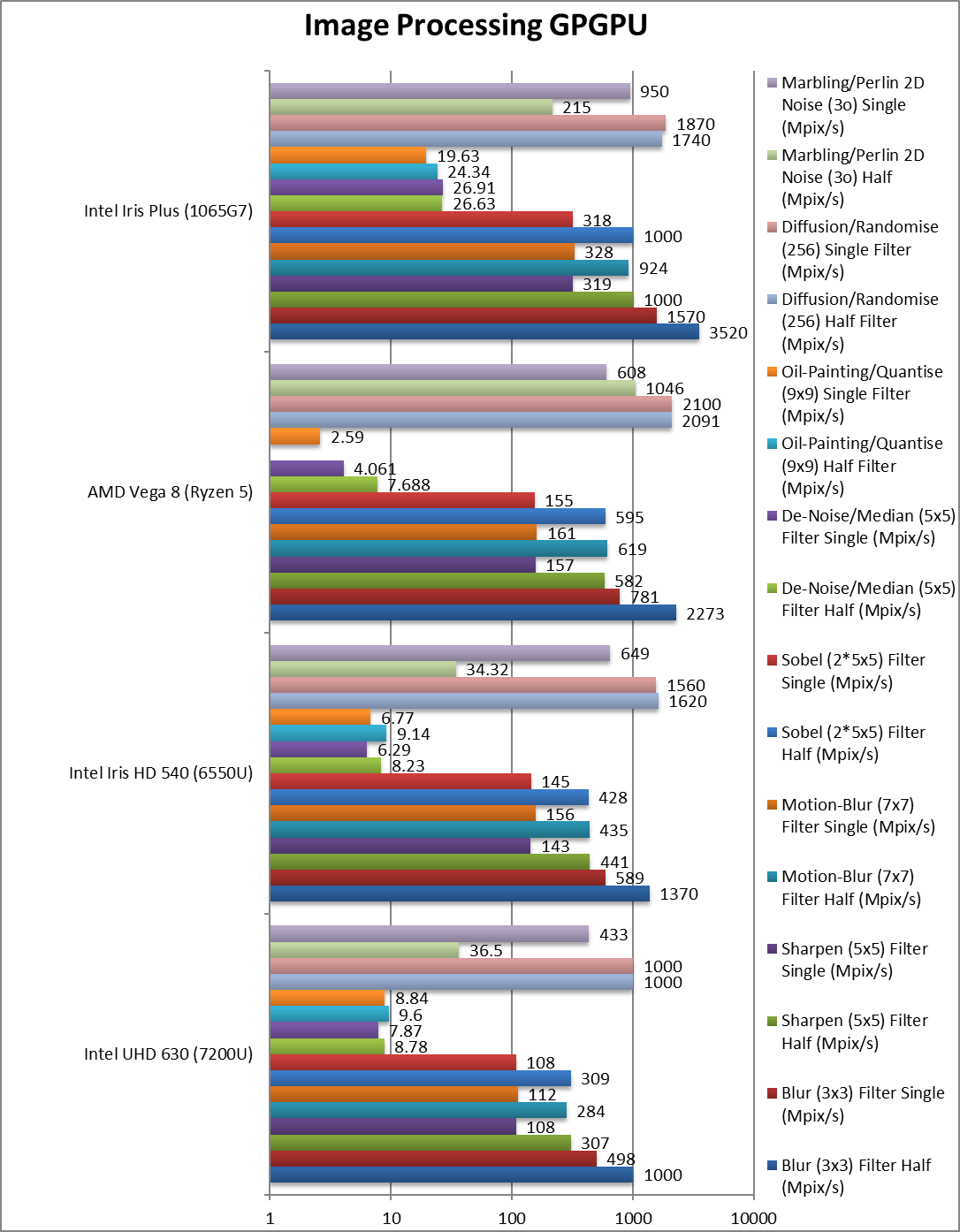
Blur (3×3) Filter single/FP16 (MPix/s) | 1,000 | 1,370 | 2,273 | 3,520 [+55%] | With FP16, G7 is only 50% faster than Vega. |
|
Blur (3×3) Filter single/FP32 (MPix/s) | 498 | 589 | 781 | 1,570 [+2x] | In this 3×3 convolution algorithm, G7 is 2x faster. |
|
Sharpen (5×5) Filter single/FP16 (MPix/s) | 307 | 441 | 382 | 1,000 [+72%] | With FP16, G7 is just 70% faster. |
|
Sharpen (5×5) Filter single/FP32 (MPix/s) | 108 | 143 | 157 | 319 [+2x] | Same algorithm but more shared data, G7 still 2x faster. |
|
Motion Blur (7×7) Filter single/FP16 (MPix/s) | 284 | 435 | 619 | 924 [+49%] | With FP16, G7 is again 50% faster. |
|
Motion Blur (7×7) Filter single/FP32 (MPix/s) | 112 | 156 | 161 | 328 [+2x] | With even more data the gap remains at 2x. |
|
Edge Detection (2*5×5) Sobel Filter single/FP16 (MPix/s) | 309 | 428 | 595 | 1,000 [+68%] | With FP16 precision, G7 is 70% faster than Vega. |
|
Edge Detection (2*5×5) Sobel Filter single/FP32 (MPix/s) | 108 | 145 | 155 | 318 [+2x] | Still convolution but with 2 filters – same 2x difference. |
|
Noise Removal (5×5) Median Filter single/FP16 (MPix/s) | 8.78 | 8.23 | 7.68 | 26.63 [+2.5x] | With FP16, G7 is “just” 2.5x faster than Vega. |
|
Noise Removal (5×5) Median Filter single/FP32 (MPix/s) | 7.87 | 6.29 | 4.06 | 26.9 [+5.6x] | Different algorithm allows G7 to fly at 6x faster. |
|
Oil Painting Quantise Filter single/FP16 (MPix/s) | 9.6 | 9.14 | – | 24.34 | G7 does similarly well with FP16 |
|
Oil Painting Quantise Filter single/FP32 (MPix/s) | 8.84 | 6.77 | 2.59 | 19.63 [+6.6x] | Without major processing, this filter is 6x faster on G7. |
|
Diffusion Randomise (XorShift) Filter single/FP16 (MPix/s) | 1,000 | 1,620 | 2,091 | 1,740 [-17%] | With FP16, G7 is 17% slower than Vega. |
|
Diffusion Randomise (XorShift) Filter single/FP32 (MPix/s) | 1,000 | 1,560 | 2,100 | 1,870 [-11%] | This algorithm is 64-bit integer heavy thus G7 is 10% slower |
|
Marbling Perlin Noise 2D Filter single/FP16 (MPix/s) | 36.5 | 34.32 | 1,046 | 215 [1/5x] | Some issues needed to be worked out here. |
|
Marbling Perlin Noise 2D Filter single/FP32 (MPix/s) | 433 | 649 | 608 | 950 [+56%] | One of the most complex and largest filters, G7 is over 50% faster. |
| For image processing tasks, G7 does very well – it is 2x faster than Vega while dropping to FP16 precision is around 50% faster (with Vega benefiting greatly from the lower precision). All in all a fanstastic result for those using image/video manipulation algorithms. | ||||||
Memory Performance
We are testing both OpenCL performance using the latest SDK / libraries / drivers from Intel and competition.
Results Interpretation: For bandwidth tests (MB/s, etc.) high values mean better performance, for latency tests (ns, etc.) low values mean better performance.
Environment: Windows 10 x64, latest Intel and AMD drivers. Turbo / Boost was enabled on all configurations.
| Memory Benchmarks | Intel UHD 630 (7200U) | Intel Iris HD 540 (6550U) | AMD Vega 8 (Ryzen 5) | Intel Iris Plus (1065G7) | Comments | |
 |
||||||
 |
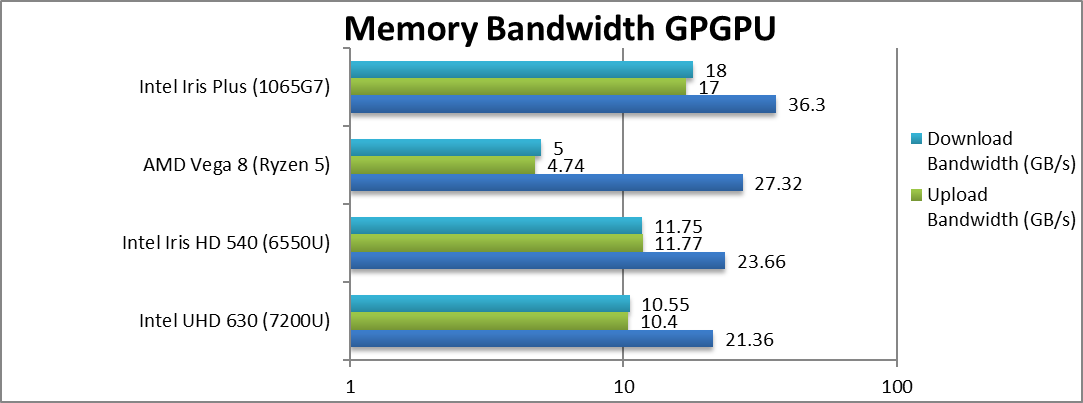
Internal Memory Bandwidth (GB/s) | 21.36 | 23.66 | 27.32 | 36.3 [+33%] | G7 has 33% more bandwidth than Vega. |
|
Upload Bandwidth (GB/s) | 10.4 | 11.77 | 4.74 | 17 [+2.6x] | G7 manages far higher transfers. |
|
Download Bandwidth (GB/s) | 10.55 | 11.75 | 5 | 18 [+2.6x] | Again, same 2.6x delta. |
| Thanks to the fast LP-DDR4X memory, G7 has far more bandwidth than Vega or older GT2/GT3 design; this no doubt helps streaming algorithms as we have seen above. | ||||||
 |
||||||
 |
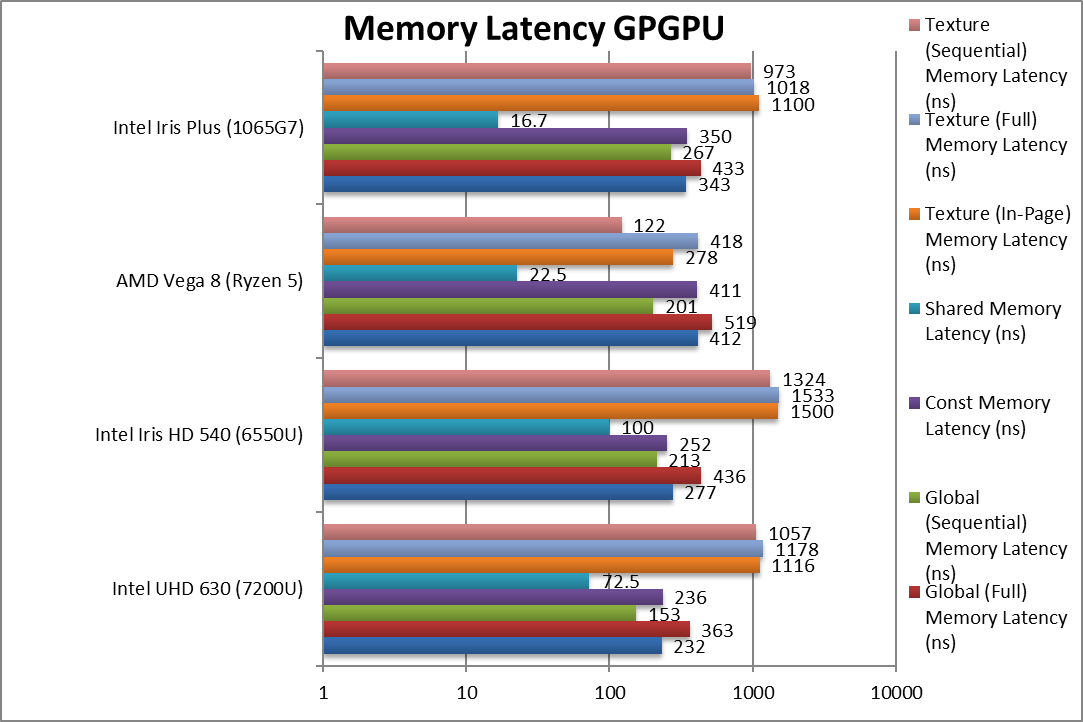
Global (In-Page Random Access) Latency (ns) | 232 | 277 | 412 | 343 [-17%] | Better latency than Vega but not less than old arch. |
|
Global (Full Range Random Access) Latency (ns) | 363 | 436 | 519 | 433 [-17%] | Similar 17% less than Vega. |
|
Global (Sequential Access) Latency (ns) | 153 | 213 | 201 | 267 [+33%] | Vega seems to be a lot faster than G7. |
|
Constant Memory (In-Page Random Access) Latency (ns) | 236 | 252 | 411 | 350 [-15%] | Same latency as global as not dedicated. |
|
Shared Memory (In-Page Random Access) Latency (ns) | 72.5 | 100 | 22.5 | 16.7 [-26%] | G7 has greatly reduced shared memory latency. |
|
Texture (In-Page Random Access) Latency (ns) | 1,116 | 1,500 | 278 | 1,100 [+3x] | Not much improvement over older versions. |
|
Texture (Full Range Random Access) Latency (ns) | 1,178 | 1,533 | 418 | 1,018 [+1.4x] | Similar high latency for G7. |
|
Texture (Sequential Access) Latency (ns) | 1,057 | 1,324 | 122 | 973 [+8x] | Again Vega has much lower latencies. |
| Despite high bandwidth, the latencies are high as LP-DDR4 has higher latencies than standard DDR4 (tens of clocks). Like Vega there is no dedicated constant memory – unlike nVidia. But G7 has greatly reduced shared memory latency to less than Vega which greatly helps algorithms using shared memory. | ||||||
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
It’s great to see Intel taking graphics seriously again; with ICL, you don’t just get a brand-new core but a much updated GPU core too. And it does not disappoint – it trades blows with competition (Vega Mobile) and usually wins while it is close to 2x faster than Gen9/GT3 and 3x faster than Gen9.5/GT2 – a huge improvement.
The lack of native FP64 support is puzzling – but then again it could be reserved for higher-end/workstation versions if supported at all. Intel no doubt is betting on the CPU’s AVX512 SIMD cores for FP64 performance which is considerable. Again, it’s not very likely that mobile (ULV) platforms are going to run high-precision kernels.
The memory bandwidth is also 50% higher but unfortunately latencies are also higher due to LP-DDR4(X) memory; lower-end versions using “standard” DDR4 memory will not see high bandwidth but will see lower latencies – thus it is give and take.
As we’ve said in the other reviews of ICL, if you have been waiting to upgrade from the much older – but still good – SKL/KBL with Gen8/9 GT2 GPU – the Gen11 GPU is a significant upgrade. You will no longer feel “inadequate” compared to competition integrated GPUs. Naturally, you cannot expect discrete GPU levels of performance but for an integrated APU it is more than sufficient.
Overall with CPU and memory improvements, ICL-U is a very compelling proposition that cost permitting should be your top choice for long-term use.
In a word: Highly Recommended!
Please see our other articles on: