What is “CometLake”?
It is one of the 10th generation Core arch (CML) from Intel – the latest revision of the venerable (6th gen!) “Skylake” (SKL) arch; it succeeds the “CofeeLake” 8/9-gen current architectures for desktop devices. The “real” 10th generation Core arch is “IceLake” (ICL) that does bring many changes – but has only released on mobile (ULV) devices so far. It is likely Intel will skip it altogether – on the desktop.
As a result there are no major updates vs. previous “Skylake” (SKL) designs, save increase in core count top end versions and hardware vulnerability mitigations which can still make a big difference:
- Up to 10C/20T (from 8C/10T “CoffeeLake” or 4C/8T “Skylake”/”KabyLake”)
- Increase Turbo ratios, base clocks
- Hyper-Threading (SMT) enabled on all Core SKUs (i9, i7, i5, i3)
- 2-channel DDR4-2933 (up from 2667)
- Thunderbolt 3 integrated
- Hardware fixes/mitigations for vulnerabilities (“Meltdown”, “MDS”, various “Spectre” types)
- New platform based on LGA1200 socket – thus new motherboards (400-series, e.g. Z490, H470, B460, etc.)
- Note 400-series will be compatible with “RocketLake” (RKL), the 14nm version of “IceLake” (ICL) the new generation Core
Unlike CML ULV – we have a modest increase in core count (10C/20T vs. CFL 8C/16T) in the same 125W TDP power envelope – but it is still a big increase vs older designs that have always had 4C/8T. Hyper-Threading is no longer disabled on i7, i5 that – should you wish to keep it enabled – can still provide good performance gains in many applications.
DDR4 official speed support has gone up to 2993Mt/s (46GB/s bandwidth) up from 2667Mt/s which should help feed all those extra cores.
While CFL does mitigate “Meltdown” (CVE-2017-5754 “rogue data cache load”) and reports “not vulnerable” (can be checked with Sandra or similar utility) – due to MDS (to which CFL is vulnerable) recent versions of Windows do consider KVA (“kernel VA shadowing”) required and enable it by default. Thus the relatively large overhead of “Meltdown” mitigation is back. ML does report “not vulnerable” to both “Meltdown” and MDS and thus KVA is not required nor enabled. Hopefully there will be no further vulnerabilities discovered to undo these fixes.
Why review it now?
As “IceLake” (ICL) does not seem to make its public debut on desktop/workstation, “CometLake” (CML) is the latest APU from Intel you can buy today;despite being just a revision of “Skylake” due to increased core counts/Turbo ratios they may still prove worthy competitors not just in cost but also performance.
As per above, the additional hardware fixes/mitigations for vulnerabilities discovered since “Cofeelake” launched – especially “Meltdown” but also “Spectre” variants – the operating system & applications do not need to deploy slower mitigations that can affect performance (especially I/O). For some workloads, this may be worth an upgrade alone!
To compare against the other Gen10 CPU, please see our other articles:
- Intel Core Gen11 TigerLake ULV (i7-1165G7) Review & Benchmarks – CPU AVX512 Performance
- Intel Core Gen10 IceLake ULV (i7-1065G7) Review & Benchmarks – CPU AVX512 Performance
- Benchmarks of JCC Erratum Mitigation – Intel CPUs
Hardware Specifications
We are comparing the top-of-the-range Intel desktop with competing architectures (gen 8, 7, 6) as well as competiors (AMD) with a view to upgrading to a mid-range but high performance design.
| CPU Specifications | Intel i9 10900K 10C/20T (CML) | Intel i9 9900K 8C/16T (CFL) | AMD Ryzen 9 3900X 12C/24T (Zen2) |
AMD Ryzen 7 3700X 8C/16T (Zen2) |
Comments | |
| Cores (CU) / Threads (SP) | 10C / 20T | 8C / 16T | 12C / 24T | 8C / 16T | 25% increase in core count | |
| Speed (Min / Max / Turbo) | 1.6-3.7-5.3GHz | 1.6-3.6-5GHz | 3.8-4.6GHz | 3.6-4.4GHz | CML has modest Turbo increase. | |
| Power (TDP) | 125W | 95W | 105W | 65W | 25% increase in TDP | |
| L1D / L1I Caches | 10x 32kB 8-way /
10x 32kB 8-way |
8x 32kB 8-way /
8x 32kB 8-way |
12x 32kB 8-way /
12x 32kB 8-way |
8x 32kB 8-way /
8x 32kB 8-way |
No L1 changes | |
| L2 Caches | 10x 256kB 8-way | 8x 256kB 16-way | 12x 512kB 16-way inclusive | 8x512kB 16-way inclusive | No L2 changes | |
| L3 Caches | 20MB 16-way | 16MB 16-way | 4x 16MB 16-way (64MB) exclusive | 2x 16MB 16-way (32MB) exclusive | 25% larger L3 | |
| Microcode (Firmware) | MU06A505-C8 | MU069E0C-9E | MU8F71000-21 | MU8F7100-13 | Revisions just keep on coming. | |
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (AVX2, AVX, etc.). “CometLake” (CML) supports all modern instruction sets including AVX2, FMA3 but not AVX512 (like “IceLake”, “Skylake-X”) or SHA HWA (like Atom, Ryzen).
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
| Native Benchmarks | Intel i9 10900K 10C/20T (CML) | Intel i9 9900K 8C/16T (CFL-R) | AMD Ryzen 9 3900X 12C/24T (Zen2) |
AMD Ryzen 7 3700X 8C/16T (Zen2) |
Comments | |
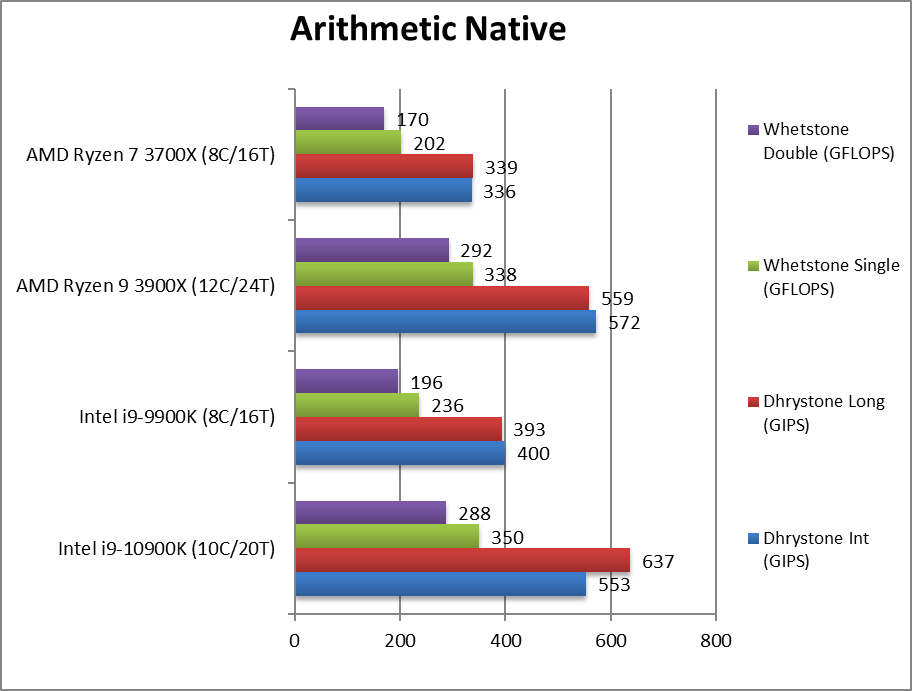 |
||||||
 |
Native Dhrystone Integer (GIPS) | 553 [+38%] | 400 | 572 | 336 | CML starts off 38% faster than CFL with 25% more cores. |
|
Native Dhrystone Long (GIPS) | 537 [+37%] | 393 | 559 | 339 | With a 64-bit integer workload still 37% faster. |
|
Native FP32 (Float) Whetstone (GFLOPS) | 350 [+48%] | 236 | 338 | 202 | With floating-point workload CML is 48% faster! |
|
Native FP64 (Double) Whetstone (GFLOPS) | 288 [+47%] | 196 | 292 | 170 | With FP64 we see a similar 47% improvement. |
| With integer (legacy) workloads, CML is almost 40% faster than CFL – much more than just core increase (+25%). With floating-point we see an ever greater almost 50% improvement! This allows it to get within a whisker of AMD’s 3900X with its 12C. | ||||||
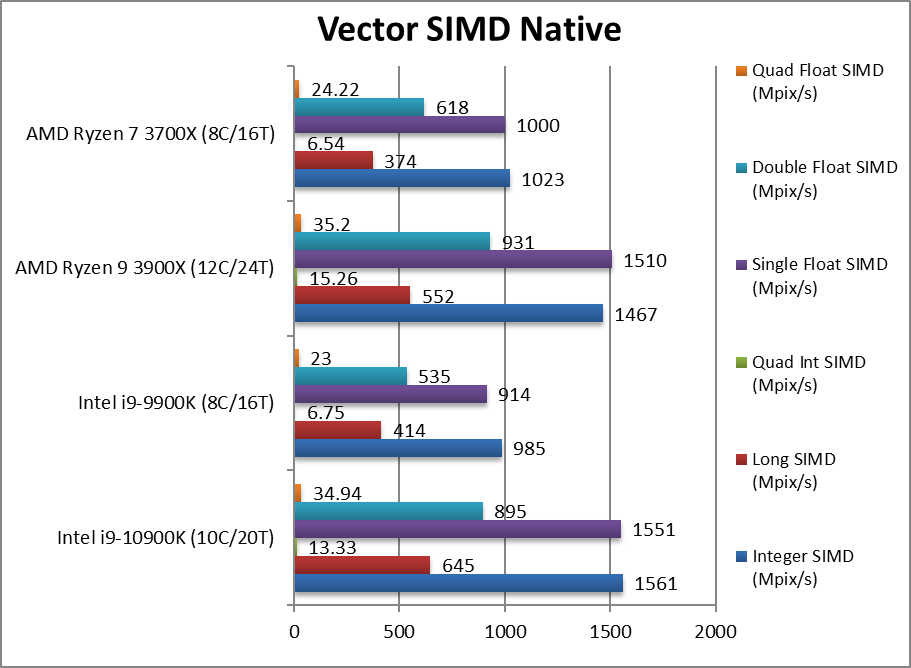 |
||||||
 |
Native Integer (Int32) Multi-Media (Mpix/s) | 1,561 [+58%] | 985 | 1,467 | 1,023 | In this vectorised AVX2 integer test CML is ~60% faster than CFL! |
|
Native Long (Int64) Multi-Media (Mpix/s) | 645 [+56%] | 414 | 552 | 374 | With a 64-bit AVX2 integer workload the difference is similar 56%. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 13.3 [+97%] | 6.75 | 15.26 | 6.54 | This is a tough test using Long integers to emulate Int128 without SIMD but CML is almost 2x faster! |
|
Native Float/FP32 Multi-Media (Mpix/s) | 1,551 [+70%] | 914 | 1,510 | 1,000 | In this floating-point AVX/FMA vectorised test, CML- 70% faster. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 895 [+67%] | 535 | 931 | 618 | Switching to FP64 SIMD code, nothing much changes still 67% faster. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 34.9 [+52%] | 23 | 35.2 | 24.2 | In this heavy algorithm using FP64 to mantissa extend FP128 with AVX2 – we see 52% improvement. |
| With heavily vectorised SIMD workloads CML improves even more over CFL, once even 2x faster, which again allows it to trade blows with 3900X and its 12C. All the mitigations must weigh heavy on CFL as the large improvement is hard to justify otherwise. | ||||||
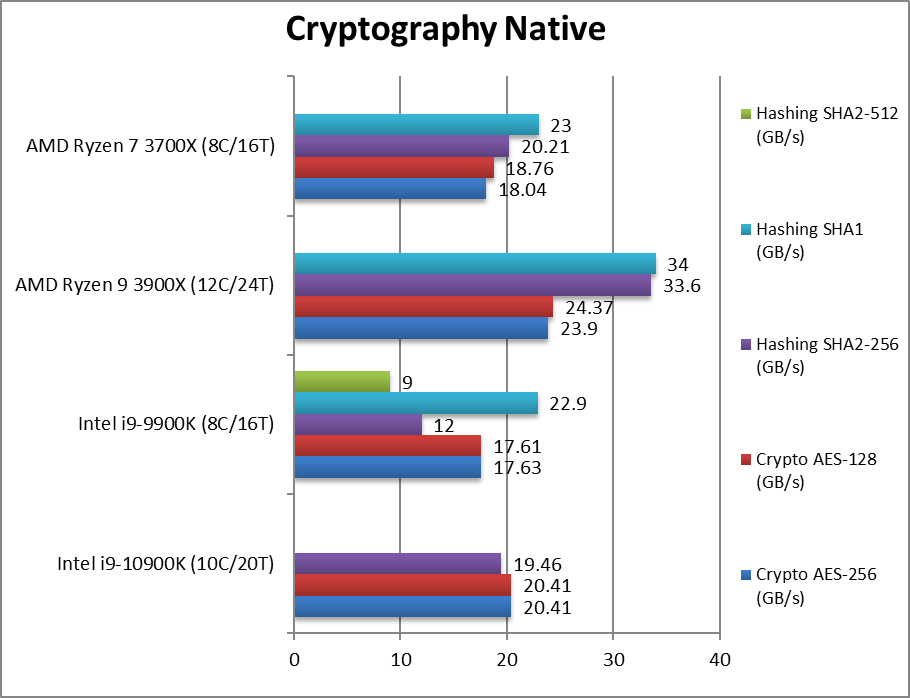 |
||||||
 |
Crypto AES-256 (GB/s) | 20.4 [+16%] | 17.6 | 23.9 | 18.04 | With AES/HWA support all CPUs are memory bandwidth bound. |
|
Crypto AES-128 (GB/s) | 20.4 [+16%] | 17.6 | 24.4 | 18.76 | No change with AES128, CML is 16% faster. |
|
Crypto SHA2-256 (GB/s) | 19.46 [+62%] | 12 | 33.6 | 24.2 | Without SHA/HWA Ryzen beats CML. |
|
Crypto SHA1 (GB/s) | 22.9 | 34 | 23 | Less compute intensive SHA1 allows CML to catch up. | |
|
Crypto SHA2-512 (GB/s) | 9 | SHA2-512 is not accelerated by SHA/HWA CML does better. | |||
| The memory sub-system is crucial here, and CML improves over CFL with faster memory – the extra cores don’t help. But Ryzen is still faster and with SHA/HWA much faster in hashing than even Intel’s AVX2 SIMD units can muster. | ||||||
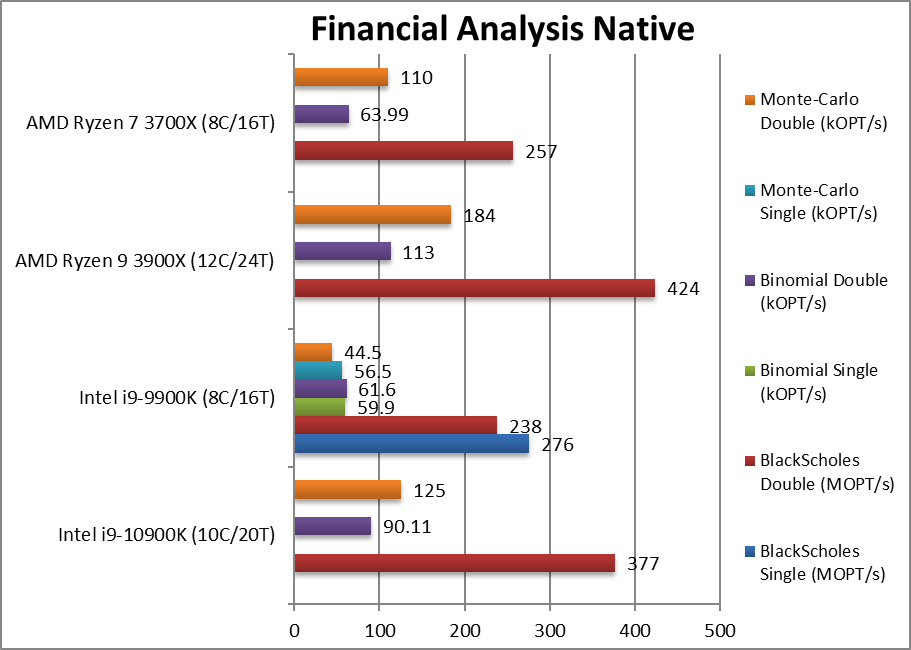 |
||||||
 |
Black-Scholes float/FP32 (MOPT/s) | 276 | With non vectorised CML needs to catch up. | |||
|
Black-Scholes double/FP64 (MOPT/s) | 377 [+58%] | 238 | 424 | 257 | Using FP64 CML is 58% faster but cannot beat Ryzen |
|
Binomial float/FP32 (kOPT/s) | 59.9 | Binomial uses thread shared data thus stresses the cache & memory system. | |||
|
Binomial double/FP64 (kOPT/s) | 90.1 [+46%] | 61.6 | 113 | 64 | With FP64 code CML is 46% faster than CFL. |
|
Monte-Carlo float/FP32 (kOPT/s) | 56.5 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches. | |||
|
Monte-Carlo double/FP64 (kOPT/s) | 125 [+2.8x] | 44.5 | 184 | 110 | Switching to FP64 nothing much changes, CML is 2.8x faster. |
| With non-SIMD financial workloads, CML still improves ~50% over CFL that is a big change; unfortunately AMD’s 3900X is still faster but at least CML remains competitive while CFL was outclassed. ZEN3 will prove a big challenge though. | ||||||
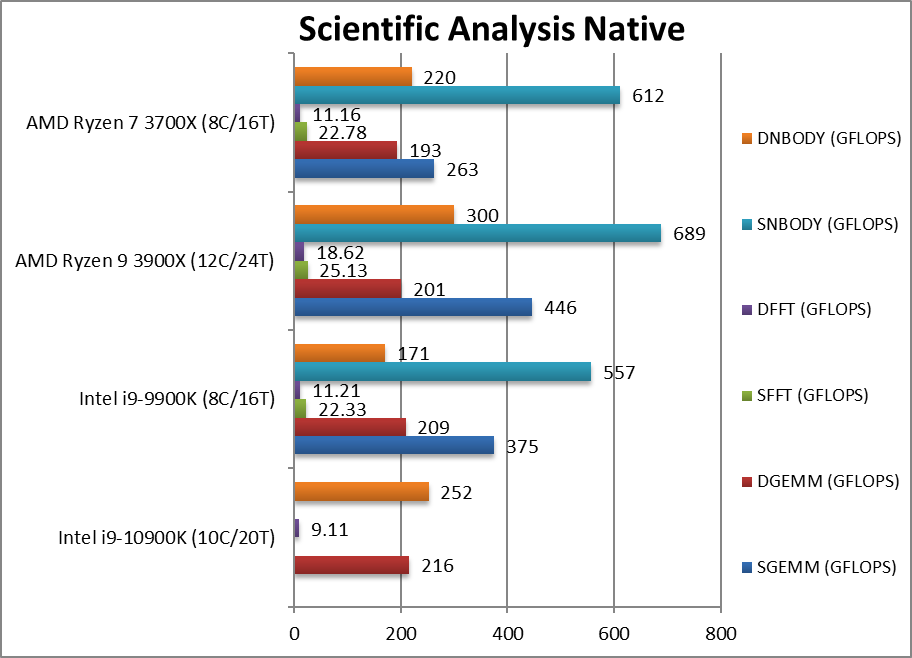 |
||||||
 |
SGEMM (GFLOPS) float/FP32 | 375 | 446 | 263 | In this tough vectorised AVX2/FMA algorithm. | |
|
DGEMM (GFLOPS) double/FP64 | 216 [+3%] | 209 | 201 | 193 | With FP64 vectorised code, CML is just 3% faster. |
|
SFFT (GFLOPS) float/FP32 | 22.33 | 25.13 | 22.78 | FFT is also heavily vectorised (x4 AVX2/FMA) but stresses the memory sub-system more. | |
|
DFFT (GFLOPS) double/FP64 | 9.11 [-19%] | 11.21 | 18.62 | 11.16 | With FP64 code, Ryzen is king. |
|
SNBODY (GFLOPS) float/FP32 | 557 | 689 | 612 | N-Body simulation is vectorised but with more memory accesses. | |
|
DNBODY (GFLOPS) double/FP64 | 252 [+47%] | 171 | 300 | 220 | With FP64 code CML is ~50% faster |
| With highly vectorised SIMD code (scientific workloads) CML improvement is variable but it is there; it is likely that subtle improvements must be made in software for some workloads due to the core-contention for many-threaded cores. However, Ryzen 3900X is always faster. | ||||||
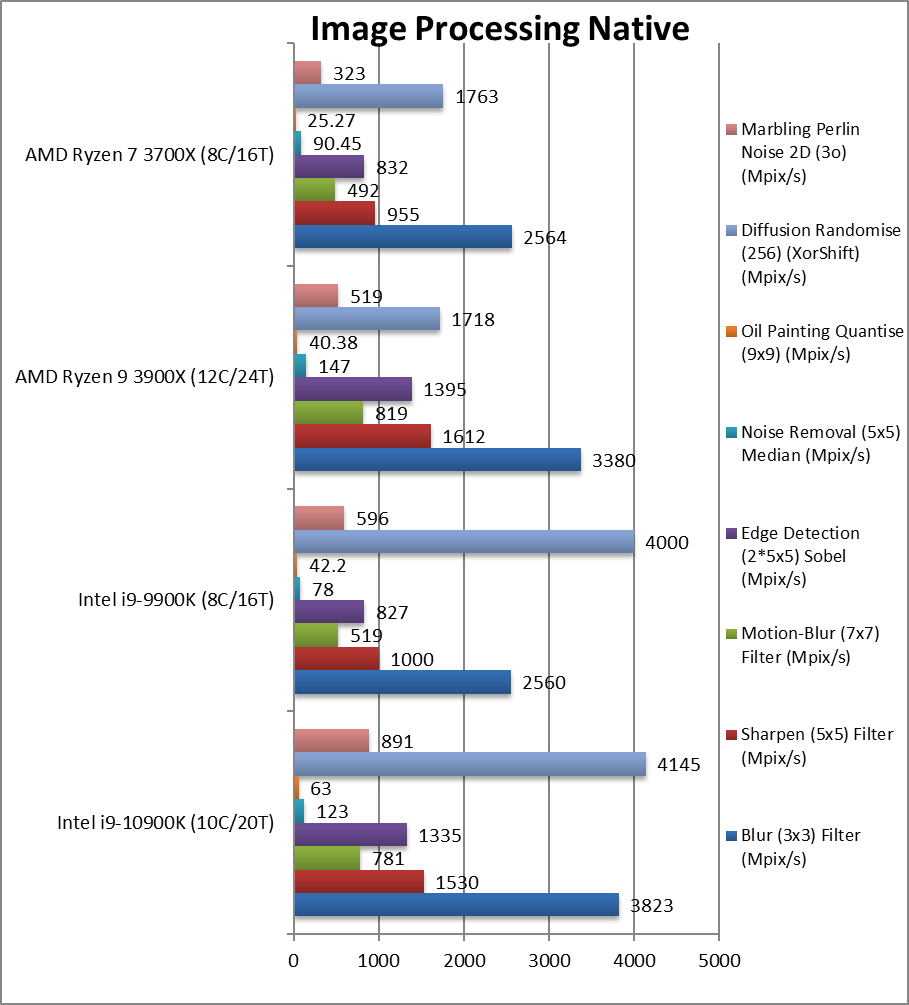 |
||||||
 |
Blur (3×3) Filter (MPix/s) | 3,823 [+49%] | 2,560 | 3,380 | 2,564 | In this vectorised integer AVX2 workload CML is 50% faster. |
|
Sharpen (5×5) Filter (MPix/s) | 1,530 [+53%] | 1,000 | 1,612 | 955 | Same algorithm but more shared data, 53% faster. |
|
Motion-Blur (7×7) Filter (MPix/s) | 781 [+50%] | 519 | 819 | 492 | Again same algorithm but even more data shared still 50% faster. |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 1,335 [+61%] | 827 | 1,395 | 832 | Different algorithm but still AVX2 vectorised workload now 60% faster. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 123 [+58%] | 78 | 147 | 90.45 | Still AVX2 vectorised code but here just 58% faster. |
|
Oil Painting Quantise Filter (MPix/s) | 63 [+49%] | 42.2 | 40.4 | 25.3 | Similar improvement here of about 49%. |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 4,145 [+4%] | 4,000 | 1,718 | 1,763 | With integer AVX2 workload, only 4% improvement. |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 891 [+49%] | 596 | 519 | 323 | In this final test again with integer AVX2 workload CML is 50% faster. |
| Without any new instruction sets (AVX512, SHA/HWA, etc.) support, CML was never going to be a revolution in performance but again we see it beat CFL by ~50% similar to what we’ve seen in other benchmarks. | ||||||
Intel themselves did not claim a big performance improvement – possibly as it makes CFL pretty much obsolete, but with slightly more cores and higher clocks/TDP CML can reach Ryzen 3900X levels of performance which is no mean feat. With ZEN3 looking to launch soon, this is not before time.
SiSoftware Official Ranker Scores
- Intel Core i9-10900K 10-Core/20-Threads
- Intel Core i9-10900 10-Core/20-Threads
- Intel Core i7-10700K 8-Core/16-Threads
Final Thoughts / Conclusions
For some it may be disappointing we do not have brand-new improved “IceLake” (ICL) now rather than a 3-rd revision “Skylake”, but “CometLake” (CML) does seem to improve even over the previous revisions (8/9th gen /”CofeeLake”CFL) due to modest increase in cores, base/Turbo clocks but perhaps also due to hardware-based vunerabilities mitigations which no longer require costly software versions.
Thus, somewhat surprisingly CML is able to trade blows with the 3900X and its 12C/24T that shows the heavily-revised “Skylake” core can still pack a punch against AMD’s latest and greatest. Naturally we would have preferred 12-cores not 10 but that would likely “eat” even further into Intel’s HEDT platform.
While owners of 8/9-th gen won’t be upgrading – it is very rare to recommend changing from one generation to another anyway – owners of older hardware can look forward to over 2x performance increase in most workloads for the same power draw, not to mention the additional features.
On the other hand, the competition (AMD Ryzen 3000 series) has more cores (12C and more) for great cost and performance – and still compatible with the old (with BIOS update) AM4 socket mainboards! With CML needing a new motherboard (LGA1200) and future “IceLake”-based CPUs possibly needing new motherboards again, CML is very much a stop-gap solution.
All in all Intel has managed to squeeze all it can from the old “Skylake” arch that while not revolutionary, still has enough to be competitive with current designs; while it goes out on a high, it is likely the end-of-the-road for this core.
In a word: Qualified Recommendation
Please see our other articles on: