What is Sandra’s Multi-Media benchmark?
The “multi-media” benchmark in Sandra was introduced way back with Intel’s MMX instruction set (and thus Pentium MMX) to show the difference vectorisation brings to common algorithms, in this case (Mandelbrot) fractal generation. While MMX did not have floating-point support – we can emulate them using integers of various widths (short/16-bit, int/32-bit, long/int64/64-bit, etc.).
The benchmark thus contains various precision tests using both integer and floating point data, currently 6 (single/double/quad-floating point, short/int/long integer) with more to come in the near future (half/FP16 floating-point, etc.). Larger widths provide more precision and thus generate more accurate fractals (images) but are slower to compute (they also take more memory to store).
While the latest instruction sets (AVX(2)/FMA, AVX512) do naturally support floating-point data, integer compute performance is still very much important thus its performance needs to be tested. As quantities become larger (e.g. memory/disk sizes, pointers/address spaces, etc.) we have moved from int/32-bit to long/64-bit processing with even exclusive 64-bit algorithms (e.g. hashing SHA512).
What is the “trouble” with 64-bit integers?
While all native 64-bit processors (e.g. x64, IA64, etc.) support native 64-bit integer operations, these are generally scalar with limited SIMD vectorised support. Multiplication is especially “problematic” as it has the potential to generate numbers up to twice (2x) the number of bits – thus multiplying two 64-bit integers can generate 128-bit integer full result for which there was no (SIMD) support.
Intel has added native full 128-bit multiplication support (MULX) with the BMI2 (Bit Manipulation Instructions Version 2) but that is still scalar (non-SIMD); not even the latest AVX512-DQ instruction set brought support. While we could emulate full 128-bit multiplication using native 32-bit to 64-bit halves multiplication we have chosen to wait for native support. An additional issue (for us) is that we use “signed integers” (i.e. can hold both positive (+ve) and negative (-ve) values) while most multiplication instructions are for “unsigned integers” (thus can hold only positive values) – thus we need to modify the result for our needs which incurs overheads.
Thus the long/64-bit integer benchmark in Sandra remained non-vectorised until the introduction of AVX512-IFMA52.
What is AVX512-IFMA52?
IFMA52 is one of the new extensions of AVX512 introduced with “IceLake” (ICL) that supports native 52-bit fused multiply-add with 104-bit result. As it is 512-bit wide, we can multiply-add eight (8) pairs 64-bit integers in one go every 2 clocks (0.5 throughput, 4 latency on ICL) – especially useful for algorithms like (Mandelbrot) fractals where we can operate on many pixels independently.
As is generates a 104-bit full result, it is (as per name) only a 52-bit integer thus we need to restrict our integers to 52-bits. It also operates on unsigned integers only thus needs to be modified for our signed-integer purpose. Note also that while it is a fused multiply-add, we have chosen to use only the multiply feature here (in this Sandra version 20/20 R9); future versions (of Sandra) may use the full multiply-add feature for even better performance.
Disclaimer
This is an independent article that has not been endorsed or sponsored by any entity (e.g. Intel). All trademarks acknowledged and used for identification only under fair use.
The article contains only public information available elsewhere on the Internet and not provided under NDA or embargoed. At publication time, the products have not been directly tested by SiSoftware and thus the accuracy of the benchmark scores cannot be verified; however, they appear consistent and do not appear to be false/fake.
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (AVX512, AVX2, AVX, etc.).
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
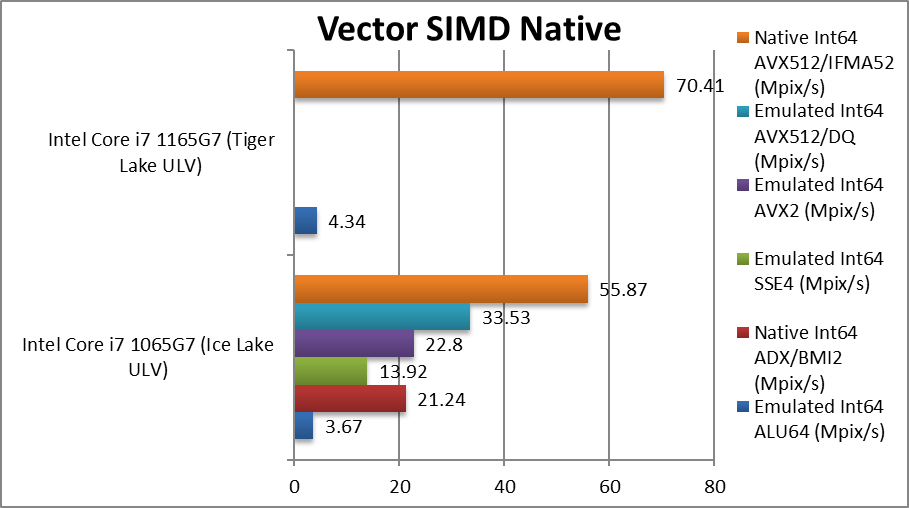
| Native Benchmarks | Intel Core i7 1065G7 4C/8T (IceLake ULV) | Intel Core i7 1165G7 4C/8T (TigerLake ULV) | Comments | |
 |
||||
 |
Emulated Int64 ALU64 (Mpix/s) | 3.67 | 4.34 | While native, scalar int64 processing is pretty slow. |
|
Native Int64 ADX/BMI2 (Mpix/s) | 21.24 [+5.78x] | – | Using BMI2 for 64-bit multiplication increases (scalar) performance by 6x! |
|
Emulated Int64 SSE4 (Mpix/s) | 13.92 [-35%] | – | Using vectorisation though SSE4 (2x wide) is not enough to beat ADX/BMI |
|
Emulated Int64 AVX2 (Mpix/s) | 22.8 [+64%] | – | AVX2 is 4x wide (256-bit) and just about beats scalar ADX/BMI2. |
|
Emulated Int64 AVX512/DQ (Mpix/s) | 33.53 [+47%] | – | 512-bit wide AVX512 is 47% faster than AVX2. |
|
Native Int64 AVX512/IFMA52 (Mpix/s) | 55.87 [+66%] / [+15x over ALU64] | 70.41 [+16x over ALU64] | IFMA52 is 66% faster than normal AVX512 and over 15x faster than scalar ALU. |
| With IFMA52, we finally see a big performance gain though native 64-bit integer multiplication and vectorisation (512-bit wide, thus 8x 64-bit integer pairs), it is over 15x faster on ICL and 16x faster on TGL! In fairness, ADX/BMI2 is only about 1/2 slower and that is scalar – showing how much native instructions help processing. | ||||
Conclusion
AVX512 continues to bring performance improvements by adding more sub-instruction sets like AVX512-IFMA(52) that help 64-bit integer processing. With 64-bit integers taking over most computations due to increased sizes (data, pointers, etc.) this is becoming more and more important and is not before time.
While not a full 128-bit multiplier, 104-bits allow complete 52-bit integer operation which is sufficient for most tasks – today. Perhaps in the future, a IFMA64 will be provided for full 128-bit multiply result integer support.