What is “XE” / “TigerLake”?
It is 3rd update of the “next generation” Core (gen 11) architecture (TGL/TigerLake) from Intel the one that replaced the ageing “Skylake (SKL)” arch and its many derivatives that are still with us (“CometLake (CML)”, “RocketLake (RKL)”, etc.). It is the optimisation of the “IceLake (ICL)” arch and thus on update 10nm++ again launched for mobile ULV (U/Y) devices and perhaps for other platforms too.
While not a “revolution” like ICL was, it still contains big changes SoC: CPU, GPU, memory controller:
- 10nm++ process (lower voltage, higher performance benefits)
- Gen12 (XE-LP) graphics (up to 96 EU, similar to discrete DG1 graphics)
- DDR5 / LPDDR5 memory controller support (2 controllers, 2 channels each, 5400Mt/s)
- No eDRAM cache unfortunately (like CrystallWell and co)
- New Image Processing Unit (IPU6) up to 4K90 resolution
- New 2x Media Encoders HEVC 4K60-10b 4:4:4 & 8K30-10b 4:2:0
- PCIe 4.0 (up to 32GB/s with x16 lanes)
While ICL has already greatly upgraded the GP-GPU to gen 11 cores (and more than doubled to 64EU for G7), TGL upgrades them yet again to “XE”-LP gen 12 cores now all the way up to 96EUs. While again most features seem to be geared towards gaming and media (with new image processing and media encoders) – there should be a few new instructions for AI – hopefully provided by a OpenCL extension.
Again there is no FP64 support (!) while FP16 is naturally supported at 2x rate as before. BF16 should also be supported by a future driver. Int32, Int16 performance has reportedly doubled with Int8 now supported and DP4A accelerated.
The new memory controller supports DDR5 / LPDDR5 (5400Mt/s) that should – once memory becomes readily available – provide more bandwidth for the EU cores; until then LPDDR4X can clock even faster (4267Mt/s). There is no mention about eDRAM (L4) cache at all.
We do hope to see more GPGPU-friendly features in upcoming versions now that Intel is taking graphics seriously. Perhaps with the forthcoming DG1 discrete graphics
GPGPU (Xe-LP G7) Performance Benchmarking
In this article we test GPGPU core performance; please see our other articles on:
- CPU
- GPGPU
Hardware Specifications
We are comparing the middle-range Intel integrated GP-GPUs with previous generation, as well as competing architectures with a view to upgrading to a brand-new, high performance, design.
| GPGPU Specifications | Intel Iris XE-LP G7 |
Intel XE-LP G1 |
Intel Iris Plus (IceLake) G7 |
AMD Vega 8 (Ryzen5) |
Comments | |
| Arch Chipset | EV12 / G7 | EV12 / G1 | EV11 / G7 | GCN1.5 | The first G12 from Intel. | |
| Cores (CU) / Threads (SP) | 96 / 768 | 32 / 256 | 64 / 512 | 8 / 512 | 50% more cores vs. G11 | |
| SIMD per CU / Width | 8 | 8 | 8 | 64 | Same SIMD width | |
| Wave/Warp Size | 32 | 32 | 16/32 | 64 | Wave size matches nVidia | |
| Speed (Min-Turbo) |
1.2GHz | 1.15GHz | 1.1GHz | 1.1GHz | Turbo speed has slightly increased. | |
| Power (TDP) | 15-35W | 15-35W | 15-35W | 15-35W | Similar power envelope. | |
| ROP / TMU | 24 / 48 | 8 / 16 | 16 / 32 | 8 / 32 | ROPs and TMUs have also increased 50%. | |
| Shared Memory |
64kB |
64kB | 64kB | 32kB | Same shared memory but 2x Vega. | |
| Constant Memory |
3.2GB | 3.2GB | 2.7GB | 3.2GB | No dedicated constant memory but large. | |
| Global Memory | 2x LP-DDR4X 4267Mt/s (LPDDR5 5400Mt/s) | 2x LP-DDR4X 4267Mt/s | 2x LP-DDR4X 3733Mt/s | 2x DDR4-2400 | Can support faster (LP)DDR5 in the future. | |
| Memory Bandwidth |
42GB/s | 42GB/s | 58GB/s | 42GB/s | Highest (possible) bandwidth ever | |
| L1 Caches | 64kB x 6 | 64kB x 2 | 16kB x 8 | 8x 16kB | L1 is much larger. | |
| L3 Cache | 3.8MB | ? | 3MB | ? | L3 has modestly increased. | |
| Maximum Work-group Size |
256×256 | 256×256 | 256×256 | 1024×1024 | Vega supports 4x bigger workgroups. | |
| FP64/double ratio |
No! | No! | No! | Yes, 1/16x | No FP64 support in current drivers! | |
| FP16/half ratio |
2x | 2x | 2x | 2x | Same 2x ratio | |
Disclaimer
This is an independent article that has not been endorsed or sponsored by any entity (e.g. Intel). All trademarks acknowledged and used for identification only under fair use. Errors and omissions excepted (E&OE).
The article contains only public information available elsewhere on the Internet and not provided under NDA or embargoed. At publication time, the products have not been directly tested by SiSoftware and thus the accuracy of the benchmark scores cannot be verified; however, they appear consistent and do not appear to be false/fake.
Processing Performance
We are testing both OpenCL performance using the latest SDK / libraries / drivers from both Intel and competition.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest Intel and AMD drivers. Turbo / Boost was enabled on all configurations.
| Processing Benchmarks | Intel Iris XE-LP G7 96EV |
Intel XE-LP G1 32EV |
Intel Iris Plus (IceLake) G7 64EV |
AMD Vega 8 (Ryzen5) 8CU |
Comments | |
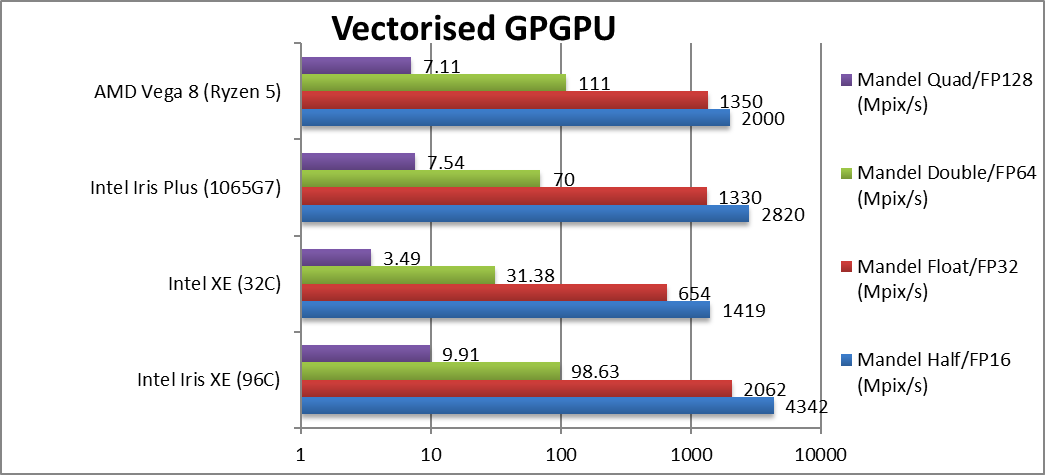 |
||||||
 |
Mandel FP16/Half (Mpix/s) | 4,342 [+54%] | 1,419 | 2,820 | 2,000 | Xe beats EV11 by over 50% using FP16! |
|
Mandel FP32/Single (Mpix/s) | 2,062 [+55%] | 654 | 1,330 | 1,350 | Standard FP32 is just as fast, 55% faster. |
|
Mandel FP64/Double (Mpix/s) | 98.6* [+41%] | 31.3* | 70* | 111 | Without native FP64 support Xe craters like old EV11. |
|
Mandel FP128/Quad (Mpix/s) | 9.91* [+31%] | 3.49* | 7.54* | 7.11 | Emulated FP128 is even harder for Xe. |
| Starting off, we see almost perfect scaling with improvement in EUs, with Xe 50% faster than old EV11. Unfortunately, again without native FP64 support – it cannot match the competition. For FP64 workloads – you’ll have to use the CPU; for ULV that may be OK but for discrete DG1 that is not so great.
* Emulated FP64 through FP32. |
||||||
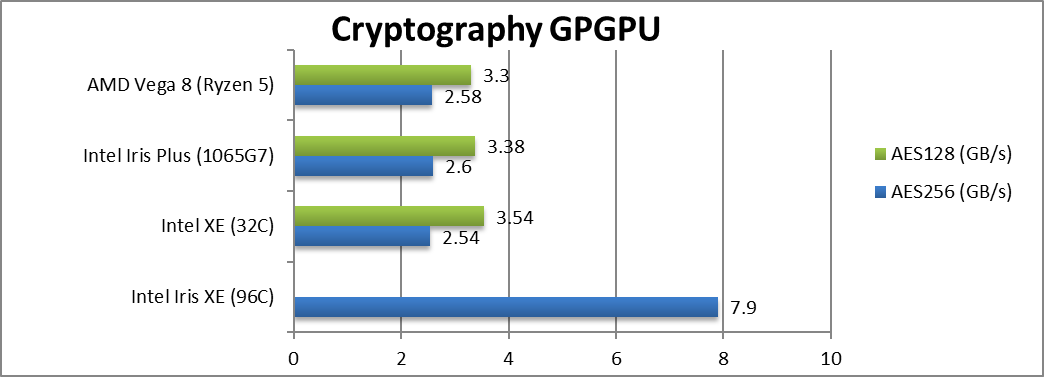 |
||||||
 |
Crypto AES-256 (GB/s) | 7.9 [+3x] | 2.54 | 2.6 | 2.58 | Integer performance is 3x faster than EV11 |
|
Crypto AES-128 (GB/s) | 3.54 | 3.38 | 3.3 | Nothing much changes when changing to 128bit. | |
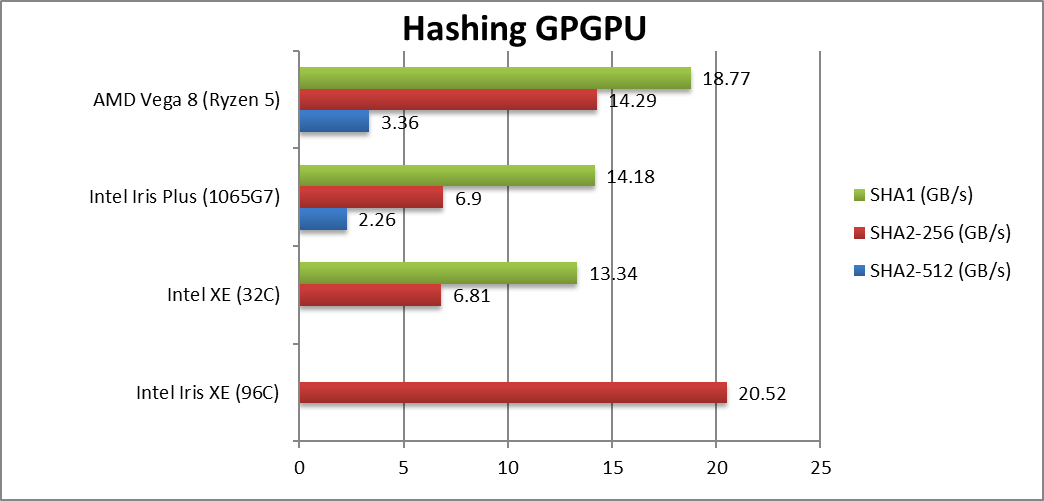 |
||||||
|
Crypto SHA2-256 (GB/s) | 20.52 [+3x] | 6.81 | 6.9 | 14.29 | Xe beats Vega even with its acceleration. |
|
Crypto SHA1 (GB/s) | 13.34 | 14.18 | 18.77 | With 128-bit Xe is even faster. | |
|
Crypto SHA2-512 (GB/s) | 2.26 | 3.36 | 64-bit integer workload is also stellar. | ||
| Despite our sample using slower DDR4 memory vs. LP-DDR4x ICL/EV11, integer performance is 3x faster – a huge upgrade. It even manages to beat AMD’s Vega with its crypto acceleration instructions (media ops). While the crypto currency frenzy has died out (not likely to mine coins on ULV GP-GPUs), the dedicated DG1 may be a serious crypto-craker GPU. | ||||||
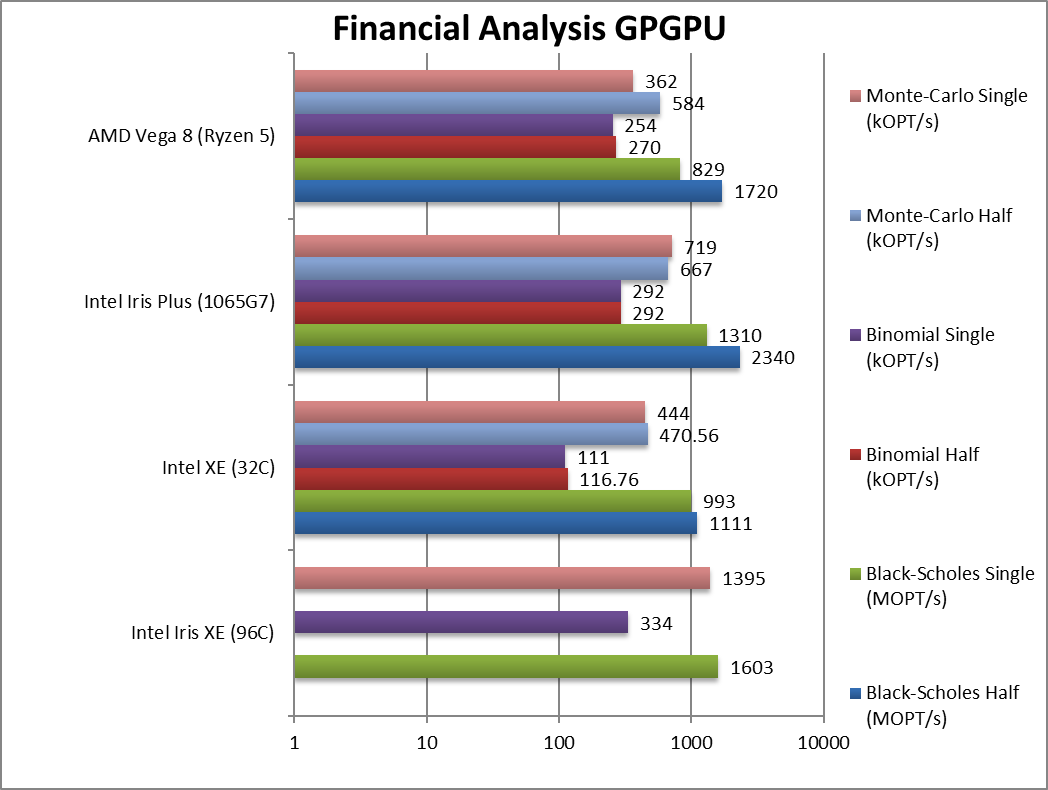 |
||||||
 |
Black-Scholes float/FP16 (MOPT/s) | 1,111 | 2,340 | 1,720 | With FP16 we see G7 win again by ~35%. | |
|
Black-Scholes float/FP32 (MOPT/s) | 1,603 [+22%] | 993 | 1,310 | 829 | With FP32 Xe is 22% faster. |
|
Binomial half/FP16 (kOPT/s) | 116 | 292 | 270 | Binomial uses thread shared data thus stresses the memory system. | |
|
Binomial float/FP32 (kOPT/s) | 334 [+14%] | 111 | 292 | 254 | With FP32, XE is just 15% faster. |
|
Monte-Carlo half/FP16 (kOPT/s) | 470 | 667 | 584 | Monte-Carlo also uses thread shared data but read-only. | |
|
Monte-Carlo float/FP32 (kOPT/s) | 1,385 [+94%] | 444 | 719 | 362 | With FP32 code Xe is 2x faster than EV11. |
| For financial FP32/FP16 workloads, Xe is not always much faster than EV11, with two algorithms just 15-22% faster but one 2x as fast. Again, due to lack of FP64 support – it cannot run high-precision workloads which may be a problem for some algorithms.
This does not bode well for the dedicated DG1 as it would be the only discrete card without native FP64 support unlike competition. However, it is likely (some) FP64 units will be included unless Intel will aim it squarely to gamers (only). |
||||||
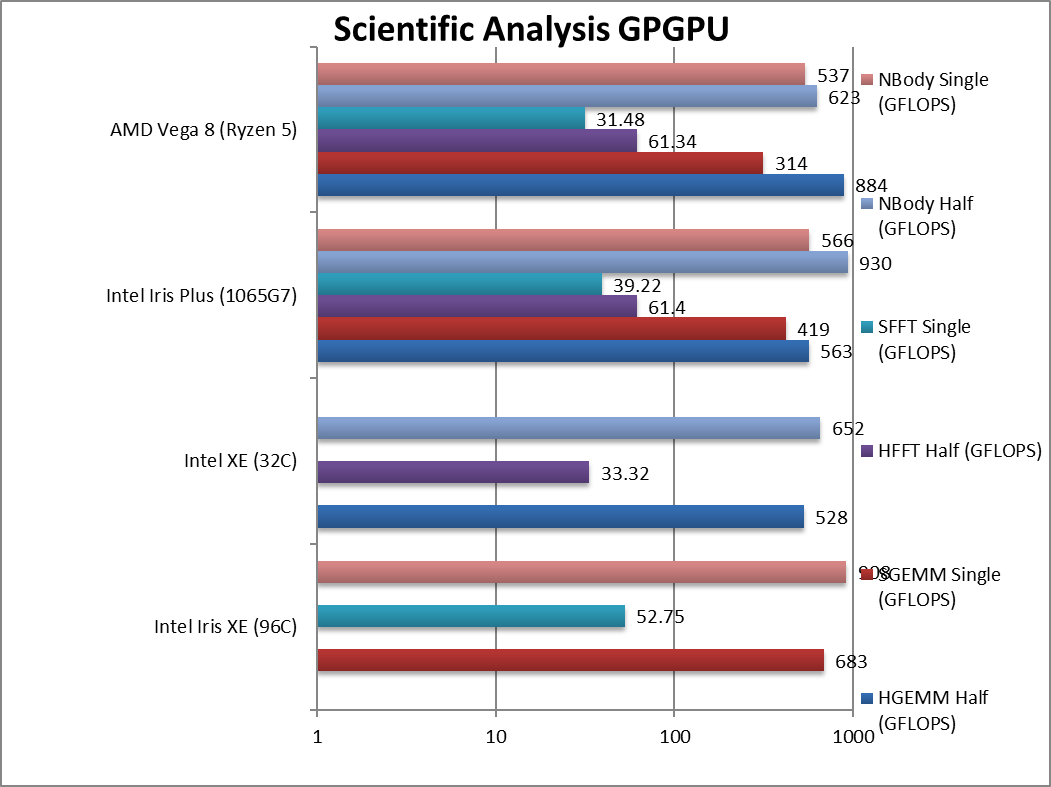 |
||||||
 |
HGEMM (GFLOPS) float/FP16 | 528 | 563 | 884 | Vega still has great performance with FP16. | |
|
SGEMM (GFLOPS) float/FP32 | 683 [+64%] | 419 | 314 | With FP32, Xe is 64% faster than EV11. | |
|
HFFT (GFLOPS) float/FP16 | 33.32 | 61.4 | 61.34 | Vega does very well here also with FP16. | |
|
SFFT (GFLOPS) float/FP32 | 52.7 [+34%] | 39.2 | 31.5 | With FP32, Xe is 34% faster. | |
|
HNBODY (GFLOPS) float/FP16 | 652 | 930 | 623 | All Intel GPUs do well here. | |
|
SNBODY (GFLOPS) float/FP32 | 908 [+60%] | 566 | 537 | With FP32, Xe is 60% faster. | |
| On scientific algorithms, Xe does much better and manages 35-65% better performance than EV11 and generally trouncing Vega on FP32 though not quite on FP16. Shall we mention lack of FP64 again? | ||||||
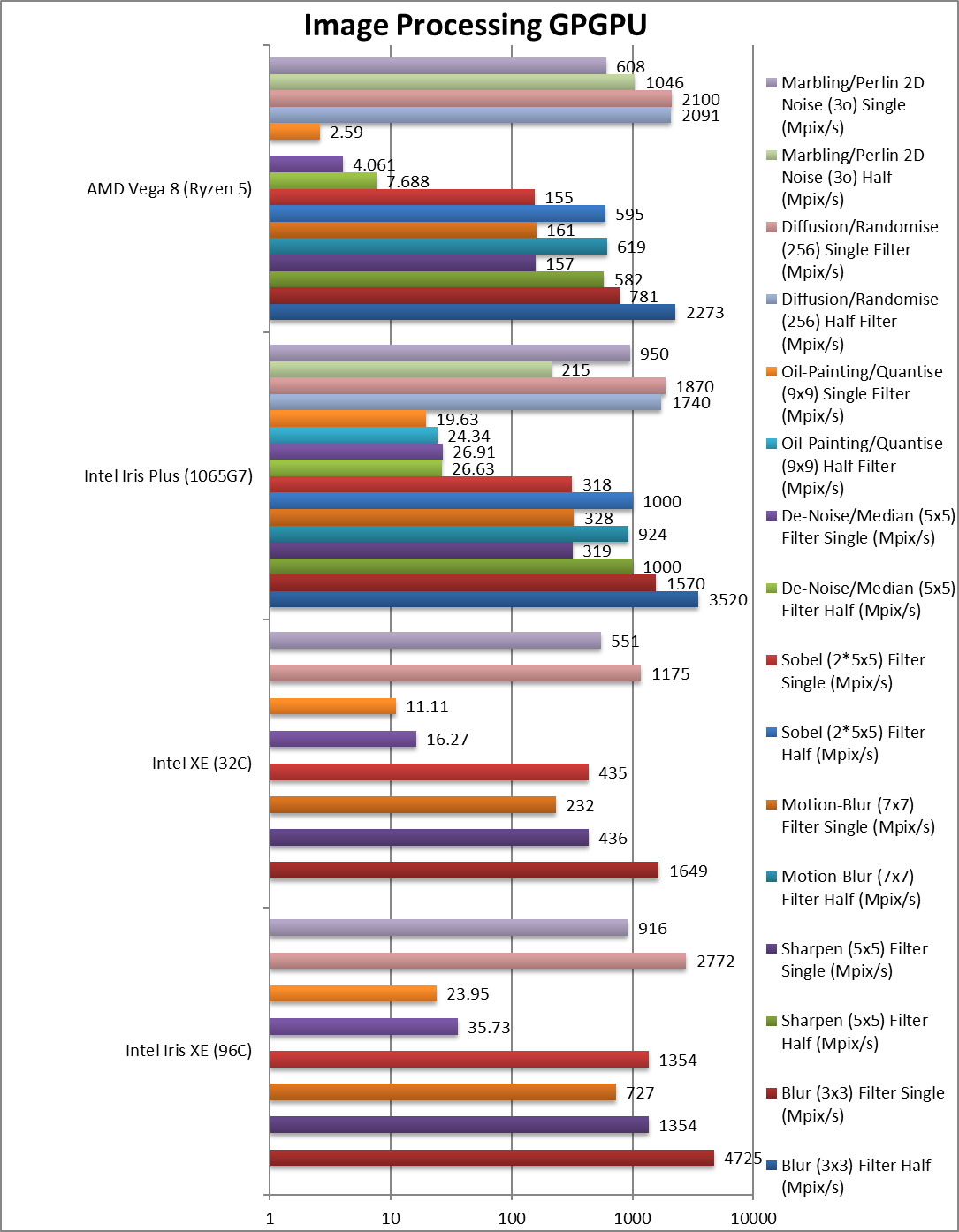 |
||||||
 |
Blur (3×3) Filter single/FP16 (MPix/s) | 3,520 | 2,273 | |||
|
Blur (3×3) Filter single/FP32 (MPix/s) | 4,725 [+3x] | 1,649 | 1.570 | 782 | In this 3×3 convolution algorithm, Xe is 3x faster! |
|
Sharpen (5×5) Filter single/FP16 (MPix/s) | 1,000 | 582 | |||
|
Sharpen (5×5) Filter single/FP32 (MPix/s) | 1,354 [+4.2x] | 436 | 319 | 157 | Same algorithm but more shared data, Xe is 4x faster. |
|
Motion Blur (7×7) Filter single/FP16 (MPix/s) | 924 | 619 | |||
|
Motion Blur (7×7) Filter single/FP32 (MPix/s) | 727 [+2.2x] | 232 | 328 | 161 | With even more data Xe is 2x faster. |
|
Edge Detection (2*5×5) Sobel Filter single/FP16 (MPix/s) | 1,000 | 595 | |||
|
Edge Detection (2*5×5) Sobel Filter single/FP32 (MPix/s) | 1,354 [+4.26x] | 435 | 318 | 155 | Still convolution but with 2 filters – 4.3x faster. |
|
Noise Removal (5×5) Median Filter single/FP16 (MPix/s) | 26.63 | 7.69 | |||
|
Noise Removal (5×5) Median Filter single/FP32 (MPix/s) | 35.73 [+33%] | 16.27 | 26.91 | 4.06 | Different algorithm Xe just 33% faster. |
|
Oil Painting Quantise Filter single/FP16 (MPix/s) | 24.34 | ||||
|
Oil Painting Quantise Filter single/FP32 (MPix/s) | 23.95 [+22%] | 11.11 | 19.63 | 2.59 | Without major processing, Xe is only 22% faster. |
|
Diffusion Randomise (XorShift) Filter single/FP16 (MPix/s) | 1,740 | 2,091 | |||
|
Diffusion Randomise (XorShift) Filter single/FP32 (MPix/s) | 2,772 [+48%] | 1,175 | 1,870 | 2,100 | This algorithm is 64-bit integer heavy thus G7 is 10% slower |
|
Marbling Perlin Noise 2D Filter single/FP16 (MPix/s) | 215 | 1,046 | |||
|
Marbling Perlin Noise 2D Filter single/FP32 (MPix/s) | 916 [-4%] | 551 | 950 | 608 | One of the most complex and largest filters, Xe ties with EV11. |
| For image processing tasks, Xe seems to do best, with up to 4x better performance – likely due to updated compiler and drivers. In any case for such tasks, upgrading to TGL will give you a huge boost. (fortunately no FP64 processing here) | ||||||
Memory Performance
We are testing both OpenCL performance using the latest SDK / libraries / drivers from Intel and competition.
Results Interpretation: For bandwidth tests (MB/s, etc.) high values mean better performance, for latency tests (ns, etc.) low values mean better performance.
Environment: Windows 10 x64, latest Intel and AMD drivers. Turbo / Boost was enabled on all configurations.
| Memory Benchmarks | Intel Iris XE-LP G7 96EV |
Intel XE-LP G1 32EV |
Intel Iris Plus (IceLake) G7 64EV |
AMD Vega 8 (Ryzen5) 8CU |
Comments | |
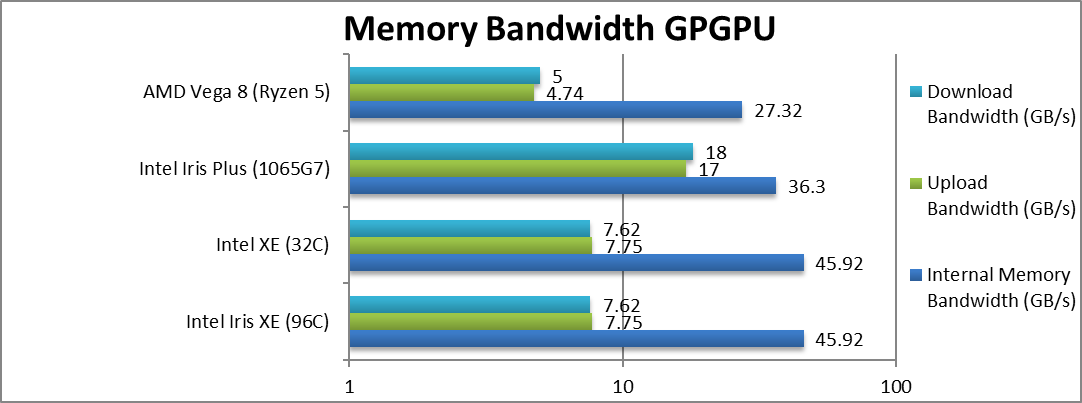 |
||||||
 |
Internal Memory Bandwidth (GB/s) | 44.92 [+27%] | 45.9 | 36.3 | 27.2 | Xe manages to squeeze more bandwidth of DDR4. |
|
Upload Bandwidth (GB/s) | 7.75 [-54%] | 7.7 | 17 | 4.74 | Uploads are 1/2 slower at this time. |
|
Download Bandwidth (GB/s) | 7.6 [-58%] | 7.6 | 185 | Download bandwidth is not much better. | |
| Thanks to the faster LP-DDR4X memory, Xe has even higher bandwidth than EV11; with future DDR5 / LPDDR5 this will increase even higher. At this time, perhaps due to the driver the upload/download bandwidths are 1/2x lower. | ||||||
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
Once again Intel seems to be taking graphics seriously: for the 2nd time in a row we have a major graphics upgrade with Xe with big upgrades in EV cores (count), performance and bandwidth. Overall it seems to be 50% faster than EV11 with lower-end devices benefiting most from the upgrade. While the competition was unassailable – Intel has managed to close the gap and overtake.
However, this is still a core aimed at gamers and it does not provide much for GP-GPU; the improved integer performance is very much welcome – 3-times better (!) but few and specific instructions for AI only. Lack of FP64 makes it unsuitable for high-precision financial and scientific workloads; something that the old EV7-9 cores could do reasonably well (all things considered).
For integrated graphics, this is not a problem – not many people would expect ULV GPU core to run compute-heavy workloads; however, the dedicated DG1 card would really be out-spec’d by the competition, with even old, low-end devices providing more features. However, dedicated DG1 is likely to include (some) FP64 units and/or additional units unlike the low-power (LP ULV) integrated versions.
Getting back to ULV, Xe-LP’s performance completely obsoletes devices (e.g. SKL/KBL/WHL/CML-ULV) using the older EV9x cores – unless you really don’t plan on using them except for “business 2D graphics” or displaying the desktop.
If you have not upgraded to ICL yet, TGL is a far better, compelling, proposition that should be your (current) top choice for long-term use. For ICL owners, there is still a lot to upgrade though not as massive as anything released previously.
In a word: Highly Recommended – 8/10!
Please see our other articles on:
- Intel Iris Plus G7 Gen11 IceLake ULV (i7-1065G7) Review & Benchmarks – GPGPU Performance
- Intel Core Gen10 IceLake ULV (i7-1065G7) Review & Benchmarks – CPU AVX512 Performance
Disclaimer
This is an independent article that has not been endorsed or sponsored by any entity (e.g. Intel). All trademarks acknowledged and used for identification only under fair use. Errors and omissions excepted (E&OE).
The article contains only public information available elsewhere on the Internet and not provided under NDA or embargoed. At publication time, the products have not been directly tested by SiSoftware and thus the accuracy of the benchmark scores cannot be verified; however, they appear consistent and do not appear to be false/fake.