What is the “Processor Inter-Thread Efficiency” Benchmark?
The “processor inter-thread efficiency” benchmark (ex. “multi-core Efficiency“) in SiSoftware Sandra has been specially designed to measure inter-thread/core/module/node/package communication efficiency of modern processors. It has been designed back in the days of the “Intel Pentium-D” (effectively two Pentium 4 in the same package) to show the differences of inter-thread data transfers (both latency and bandwidth) depending on thread (unit) IDs.
Why is the “Inter-Thread” efficiency Important to be measured?
The topology of modern processors is complicated, and now consist of multiple-cores (that each may support 1, 2 or 4 threads) organized in modules (CCX on AMD naming) and further organized in modules, packages/die(s) and finally multiple-sockets in the case of SMP systems.
Unlike, say, server software (e.g. web-servers, file servers, some databases, etc.) that use independent threads working to handle independent requests, most modern software use multiple threads working together on the same workload where they need to share data between them. One of the most common way is “producer-consumer” paradigm where one thread passes processed data, messages, etc. to another thread for further processing – and then stating work on another block of data, message, etc. Asynchronous processing, deferred calls, queuing of messages, etc. also work on this general principle.
Due to processor topology, it is very important for software (or perhaps Operating System scheduler) to assign (aka “affinity“) the pairs of threads on the right physical processor units to facilitate speedy (aka low latency / high bandwidth) data transfers. Incorrect assignment can have a big detrimental effect on performance as not all pairing combinations are as efficient.
How does the benchmark work?
Our implementation also uses the producer-consumer model, with all combinations of thread pairs tested for latency and then bandwidth tested with various sizes of data blocks and chain lengths (number of buffers) between threads. Note that we need synchronization between the producer-consumer threads to signal block ready and this must be as efficient as possible to minimize overheads.
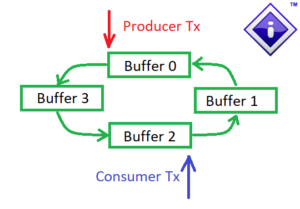
Producer Consumer Pair with 4 Buffers
Thread Pairings: in a (simple) 4 thread system (i.e. U0-U3) we have 6 pair (n!/ (r! * (n-r)!)) combinations:
- U0-U1, U0-U2, U0-U3
- U1-U2, U1-U3
- U2-U3
In a more complex system, like our AMD Ryzen 9 5900X example we have 2 modules/CCX (M0-M1), 12 cores (C0-C11) and 24 threads (T0-T23) and far more thread pairings (276), spanning cores, modules/CCXes and finally package. AMD EPYC processors also have multiple nodes on the same package/socket as well as multiple processors in a SMP system.
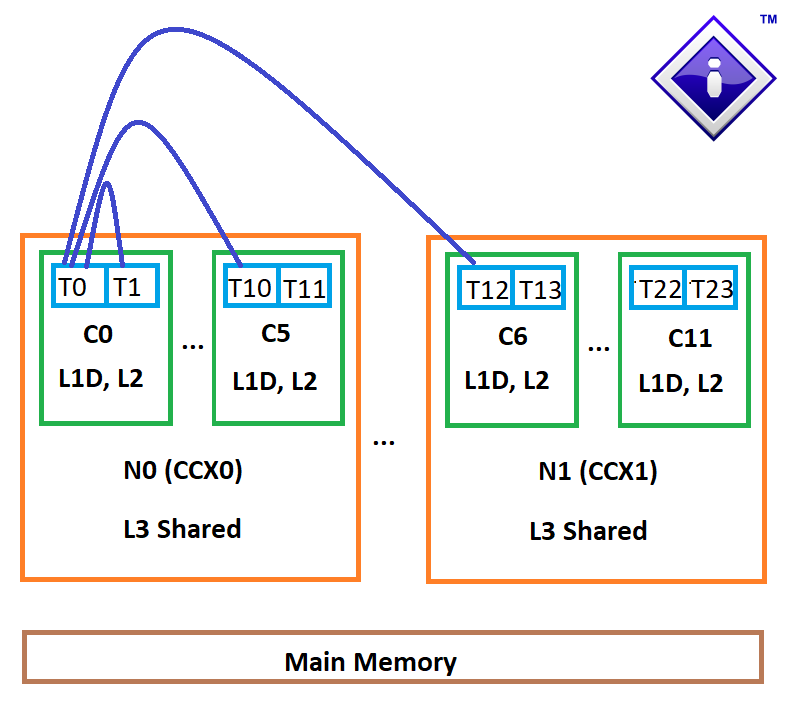
Thread Pair Combinations
For latency we test the smallest data item that can be passed between threads (aka cache line, 64-bytes on x86) and measure the aggregate latency of producer thread write (PTx) and consumer thread read (CTx) in nanoseconds (ns). By analyzing all the combinations we are thus able to select the best pairings based on the lowest latencies that should also result in the highest bandwidths.
To improve efficiency Sandra’s benchmark supports the following features:
- NUMA support: blocks are allocated on the node the (producer) unit/thread belongs to.
- Large Page support: blocks are allocated using 2/4MB large pages rather than normal/small 4kB pages.
- Wide registers support: transfers use the widest registers supported (e.g. SIMD 512-bit AVX512, 256-bit AVX2/AVX, 128-bit SSE2).
- Optimized synchronization: assembler written synchronization primitives (mutex/events) for fastest signalling between cores.
Sandra allows the user to select either:
- Best pairing combination (smallest latencies between pairs)
- Worst pairing combination (highest latencies between pairs)
Sandra measures the bandwidth for various block sizes and chain lengths as these are the most common transfer sizes and lengths:
- 64-bytes (cache line size): 1x, 4x [total 64, 256-byte buffers]
- 256-bytes: 4x [total 1kB buffers]
- 1kB: 4x [total 4kB buffers]
- 4kB (page size): 4x, 16x [total 16, 64kB buffers]
- 64kB: 4x, 16x [total 256k, 1MB buffers]
- 256kB (common L2 size): 8x [total 2MB buffers]
- 1MB: 4x, 16x [total 4, 16MB buffers]
- 8MB (common L3 size): 8x [total 64MB buffers]
Finally, based on the above measurements we can generate the scores for:
- Aggregate Inter-Thread Bandwidth (GB/s): the average of all the tested bandwidth
- Average Inter-Thread Latency (ns): the average of all the tested pair combination latencies
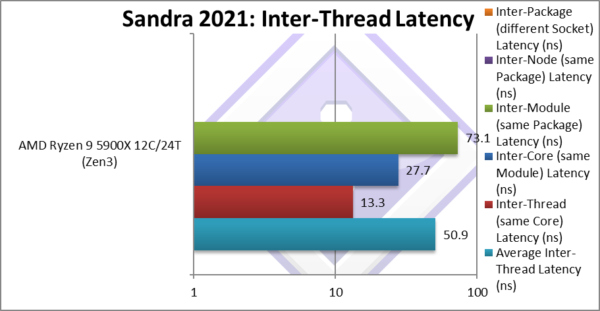
As is aware of processor topology (as its has its own thread scheduler, we can also compute:
- Inter-Thread (same Core) Latency (ns): latency between threads on the same core
- Inter-Core (same Module) Latency (ns): latency between threads on different core but same module/CCX
- Inter-Module (same Package) Latency (ns): latency between threads on different module/CCX but same node/package
- Inter-Node (same Package) Latency (ns): latency between threads on different nodes/dies but same package/socket
- Inter-Package (different Socket) Latency (ns): latency between threads on different packages/sockets on SMP systems
- Inter-big/LITTLE-Core (same Module) Latency (ns): on hybrid processors (i.e. big/LITTLE), latency between threads on different types of cores (so one “big” one “LITTLE) but on the same module/CCX
Naturally only the relevant scores are computed and displayed depending on processor topology: if the system does not have multiple modules/CCX there is no inter-module latency. Similarly for nodes, packages, etc.
Practical Example: AMD Ryzen 9 5900X (2M 12C 24T)
Unlike Intel Core processors with monolithic L3 caches and all cores on the same die/module, AMD Ryzen processors are built around “chiplets” / CCX (core complexes) that we generically call “modules” of 4 (Series 1000-3000) or 8-cores (Series 5000+) with a shared L3 cache (8-32MB). Their topologies thus have 3 hierarchy levels (threads, cores, modules) rather than 2 (threads, cores) and thus require Operating System scheduler modifications to schedule threads in the best fashion.

Sandra thus must test all the combinations between the 24 threads (units) and compile the list of the latencies between them:
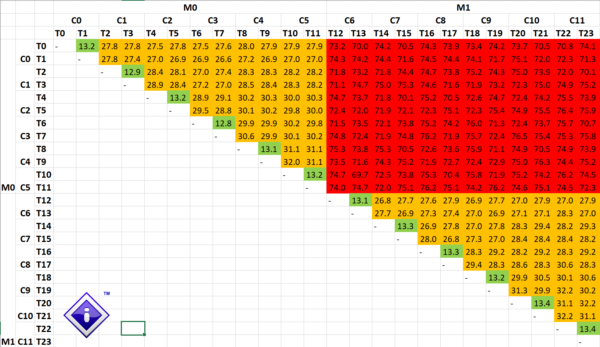
Inter-Thread Latencies for AMD Ryzen 9 5900X
We can clearly work out the topology of the processor – even without knowing its details:
- ~13.3ns between a few units (must be sharing the same core) [e.g. To-T1]
- ~27.7ns (2x higher) between many units (must be sharing the same module) [e.g T0-T2 to T11]
- ~73ns (5.4x higher) between just as many units (must be on different modules) [e.g. T0-T12 to T23]
Sandra can then compute the average latency for all thread pairs and also for each combination type:
By selecting the best (aka lowest latencies thread-pairs) and worst (aka highest latencies) we can measure the bandwidth when transferring different block sizes and different chain lengths:
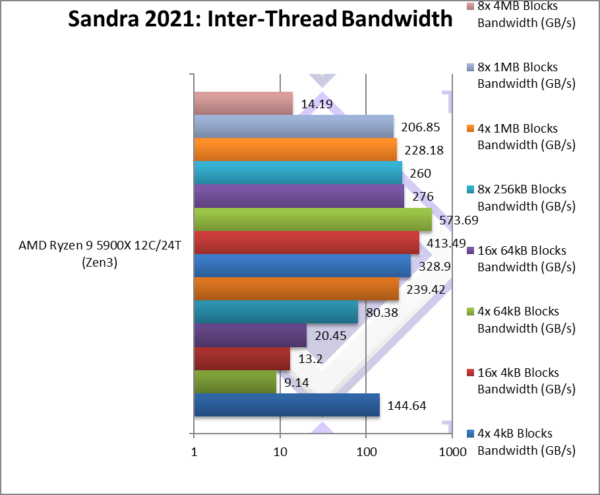
Again, even without knowing processor topology we can draw some basic conclusions:
- Larger block sizes are more efficient to transfer – up to a point at 256kB (likely L2 cache size)
- Longer chain lengths are more efficient to transfer- again up to a point
- Efficiency drops massively for very large blocks – at 8MB x 6 pairs = 48MB (likely larger than L3)
- Size of L3 matters a lot – all but largest transfer can be buffered – saving system memory access.
We can just how much the bandwidth varies from the best pairing (~144GB/s) to worst (9.14GB/s) – i.e. 1/15x lower – a catastrophic drop in performance which would hugely impact performance.
Wrap Up
We hope you enjoyed this in-(more)-depth overview of one of Sandra’s main benchmarks. Be sure to check out our very latest version SiSoftware Sandra 2K21.