What is “RocketLake”?
It is the desktop/workstation version of the true “next generation” Core (gen 10+) architecture – finally replacing the ageing “Skylake (SKL)” arch and its many derivatives that are still with us (“CometLake (CML)”, etc.). It is a combination of the “IceLake (ICL)” CPU cores launched about a year go and the “TigerLake (TGL)” Gen12 XE graphics cores launched recently.
With the new core we get a plethora of new features – some previously only available on HEDT platform (AVX512 and its many friends), improved L1/L2 caches, improved memory controller and PCIe 4.0 buses. Sadly Intel had to back-port the older ICL (not TGL) cores to 14nm – we shall have to wait for future (desktop) processors “AlderLake (ADL)” to see 10nm on the desktop…
- 14nm+++ improved process (not 10nm)
- Up to 8C/16T “Cypress Cove” cores aka 14nm+++ “Sunny Cove” from ICL – Claimed core IPC uplift of +19%
- AVX512 and all of its friends (1x FMA Unit)
- Increased L1D cache to 48kB (50% larger)
- Increased L2 cache to 512MB (2x as large)
- PCIe 4.0 (up to 32GB/s with x16 lanes) – 20 (16+4 or 8+8+4) lanes
- Thunderbolt 3 (and thus USB 3.2 2×2 support @ 20Gbps) integrated
- Hardware fixes/mitigations for vulnerabilities (“JCC”, “Meltdown”, “MDS”, various “Spectre” types)
The biggest change is support for AVX512-family instruction set, effectively doubling SIMD processing width (vs. AVX2/FMA) as well as adding a whole host of specialised instructions that even the HEDT platform (SKL/KBL-X) does not support yet:
- AVX512-VNNI (Vector Neural Network Instructions, dlBoost FP16/INT8) e.g. convolution
- AVX512-VBMI, VBMI2 (Vector Byte Manipulation Instructions) various use
- AVX512-BITALG (Bit Algorithms) various use
- AVX512-VAES (Vector AES) accelerating block-crypto
- AVX512-GFNI (Galois Field) – e.g. used in AES-GCM
- SHA HWA accelerating hashing (SHA1, SHA2-256 only)
While some software may not have been updated to AVX512 as it was reserved for HEDT/Servers, due to this mainstream launch you can pretty much guarantee that just about all vectorised algorithms (already ported to AVX2/FMA) will soon be ported over. VNNI, IFMA, etc. support can accelerate low-precision neural-networks that are likely to be used on mobile platforms.
The caches are finally getting updated and increased considering that the competition has deployed massively big caches in its latest products. L1D is 50% larger and L2 doubles (2x) but L3 has not been increased. We will measure latencies in a future article.
From a security point-of-view, RKL mitigates all (current/reported) vulnerabilities in hardware/firmware (Spectre 2, 3/a, 4; L1TF, MDS, etc.) except BCB (Spectre V1 that does not have a hardware solution) thus should not require slower mitigations that affect performance (especially I/O). RKL is also not affected by the JCC errata that needs mitigatation through software (compiler) changes on older processors.
The memory controller supports higher DDR4 speeds (up to 3200Mt/s) while the cache/TLB systems have been improved that should help both CPU and GPU performance (see corresponding article) as well as reduce power vs. older designs using LP-DDR3. Again we will measure bandwidth and latencies in a future article.
PCIe 4.0 finally arrives on Intel and should drive wide adoption for both discrete graphics (GP-GPUs including Intel’s) and NVMe SSDs with ~8GB/s transfer (x4 lanes) and to ~32GB/s (x16). Note that the DMI/OPI link between CPU and I/O Hub is also thus updated to PCIe 4.0 speeds improving CPU/Hub transfer.
On the desktop – while the Intel is launching new 500-series motherboards, RKL should be compatible with 400-series boards with a BIOS update. Just as with AMD, PCIe 4.0 may only be available on 500-series boards.
Finally the GPU cores have been updated to XE (Gen 12) cores, up to 96 on some SKUs that represent huge compute and graphics performance increases over the old (Gen 9.x) cores used by gen 10 APUs (see corresponding article).
CPU (Core) Performance Benchmarking
In this article we test CPU core performance; please see our other articles on:
- CPU
- Intel 12th Gen Core AlderLake (i9-12900K) Review & Benchmarks – big/LITTLE Performance
- Intel 11th Gen Core RocketLake AVX512 Performance Improvement vs AVX2/FMA3
- Intel 11th Gen Core RocketLake (i9-11900K) Review & Benchmarks – CPU AVX512 Performance
- Intel Core Gen 10 IceLake ULV (i7-1065G7) Review & Benchmarks – CPU AVX512 Performance
- Cache & Memory
- GPGPU
- Intel Iris Gen 12 Rocketlake (i7-11700K) Review & Benchmarks – GPGPU Performance
- Intel DG1 (Iris Xe Max Gen12) Review & Benchmarks – GPGPU Performance
- Intel Iris Plus G7 Gen 12 XE TigerLake ULV (i7-1165G7) Review & Benchmarks – GPGPU Performance
- Intel Iris Plus G7 Gen 11 IceLake ULV (i7-1065G7) Review & Benchmarks – GPGPU Performance
Hardware Specifications
We are comparing the top-of-the-range Intel with competing architectures as well as competiors (AMD) with a view to upgrading to a mid-range but high performance design.
| Specifications | Intel i7 11700K 8C/16T (RKL) | AMD Ryzen 7 5800X 8C/16T (Zen3) | Intel i9 9900K 8C/16T (CFL-R) | Intel i9 7900X 10C/20T (SKL-X) | Comments | |
| Arch(itecture) | Cypress Cove / RocketLake | Zen3 / Vermeer | CoffeeLake Refresh | Skylake-X | Not the very latest arch. | |
| Cores (CU) / Threads (SP) | 8C / 16T [=] | 2M / 8C / 16T | 8C / 16T | 10C / 16T | No change in cores count. | |
| Rated Speed (GHz) | 3.6 [=] | 3.8 | 3.6 | 3.3 | Same base clock. | |
| All/Single Turbo Speed (GHz) |
4.6 – 5.0 [=] | 4.5 – 4.8 | 4.7 – 5 | 4.0 – 4.3 | Same single-core turbo. | |
| Power TDP/Turbo (W) |
125 – 175 | 105 – 135 | 95 – 135 | 140 – 308 | TDP seems 25% over CFL. | |
| L1D / L1I Caches | 8x 48kB 12-way [+50%] / 8x 32kB 8-way | 8x 32kB 8-way / 8x 32kB 8-way | 8x 32kB 8-way / 8x 32kB 8-way | 10x 32kB 8-way / 10x 32kB 8-way | L1D is 50% larger. | |
| L2 Caches | 8x 512kB 16-way [2x] | 8x 512kB 16-way | 8x 256B 16-way | 10x 1MB 16-way | L2 has doubled. | |
| L3 Caches | 16MB 16-way [=] | 32MB 16-way | 16MB 16-way | 13.75MB 11-way | L3 is the same | |
| Microcode (Firmware) | 06A701-2C* (ver 44*) |
8F7100-21 (ver 33) | 069E0C-D6 (ver 214) | 065504-69 (ver 105) | Revisions just keep on coming. | |
| Special Instruction Sets |
AVX512, VNNI, SHA, VAES | AVX2/FMA, SHA | AVX2/FMA | AVX512 | More AVX512! | |
| SIMD Width / Units |
512-bit (1x FMA Unit) |
256-bit | 256-bit | 512-bit (2x FMA Units) |
Widest SIMD units, but single FMA. | |
| Price / RRP (USD) |
$399 [-17%] |
$449 | $479 | $999 |
Cheapest launch i7? | |
Disclaimer
This is an independent review (critical appraisal) that has not been endorsed nor sponsored by any entity (e.g. Intel, etc.). All trademarks acknowledged and used for identification only under fair use.
The review contains only public information and not provided under NDA nor embargoed. At publication time, the products have not been directly tested by SiSoftware but submitted to the public Benchmark Ranker; thus the accuracy of the benchmark scores cannot be verified, however, they appear consistent and pass current validation checks.
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets. “Rocketlake” (RKL) supports all modern instruction sets including AVX512, VNNI, SHA HWA, VAES and naturally the older AVX2/FMA, AES HWA.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
Note: The microcode (aka CPU firmware) used in the test as per above is version 2C (version 44); older or newer versions (e.g. 34, 39, etc.) seem to exhibit different performance. We will update the review when we obtain our sample and run our own tests.
| Native Benchmarks | Intel i7 11700K 8C/16T (RKL) | AMD Ryzen 7 5800X 8C/16T (Zen3, Vermeer) | Intel i9 9900K 8C/16T (CFL-R) | Intel i9 7900X 10C/20T (SKL-X) | Comments | |
 |
||||||
 |
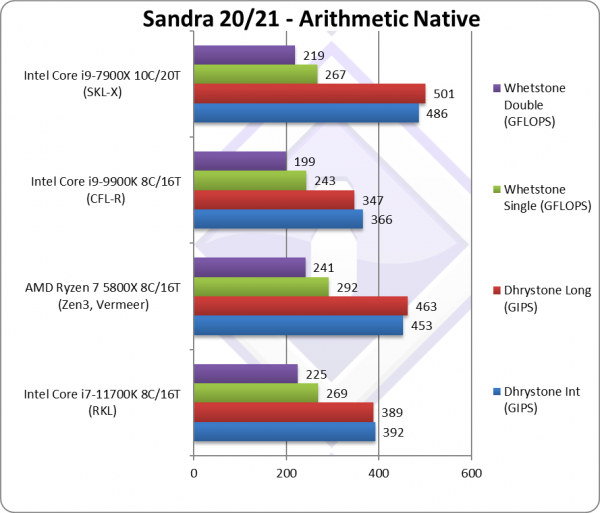
Native Dhrystone Integer (GIPS) | 392 [+7%] | 453 | 366 | 397 | RKL is just 7% faster than CFL. |
|
Native Dhrystone Long (GIPS) | 389 [+12%] | 463 | 347 | 392 | A 64-bit integer workload RKL is 12% faster. |
|
Native FP32 (Float) Whetstone (GFLOPS) | 269 [+11%] | 292 | 243 | 264 | With floating-point, RKL is again 11% faster. |
|
Native FP64 (Double) Whetstone (GFLOPS) | 225 [+13%] | 241 | 199 | 221 | With FP64 nothing much changes. |
| With legacy integer/floating-point workloads, RKL is just 7-13% faster than old CFL-R and while that is enough to beat old Ryzen, it is beaten by the latest Zen3 (5800X) in all tests. Intel claims about +19% IPC uplift so we’re almost there (17%).
For the same number of cores Zen3 is faster – which perhaps it is not a surprise as these are not TGL (“Willow Cove”) 10nm cores; we will likely have to wait until the next generation ADL (“Alder Lake”) cores to perhaps to beat AMD. Note that due to being “legacy” none of the benchmarks support AVX512; while we could update them, they are not vectorise-able in the “spirit they were written” – thus single-lane AVX512 cannot run faster than AVX2/SSEx. |
||||||
 |
||||||
 |
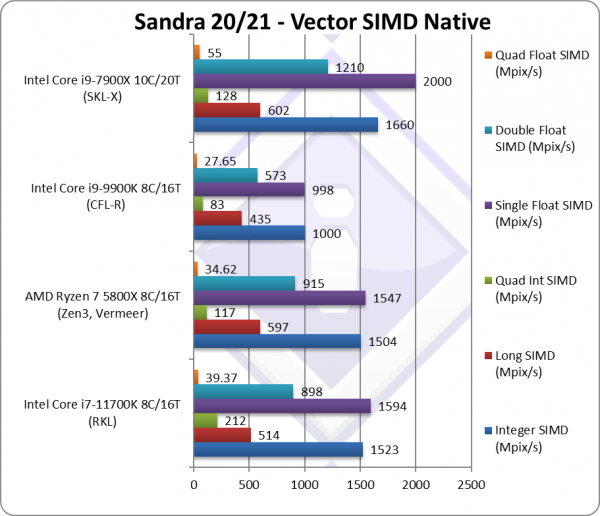
Native Integer (Int32) Multi-Media (Mpix/s) | 1,523* [+52%] | 1,504 | 1,000 | 1,590* | With AVX512 RKL is 52% faster than CFL. |
|
Native Long (Int64) Multi-Media (Mpix/s) | 514* [+18%] | 597 | 435 | 548* | With a 64-bit AVX512 integer workload RKL is just 18% faster. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 212* [+2.55x] | 117 | 83 | 125* | Using 64-bit int to emulate Int128 RKL is over 2x faster due to AVX512. |
|
Native Float/FP32 Multi-Media (Mpix/s) | 1,594* [+60%] | 1,547 | 998 | 1,930* | In this floating-point vectorised test RKL is 60% faster. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 898* [+57%] | 915 | 573 | 1,210* | Switching to FP64 SIMD AVX512 code, RKL is 57% faster. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 39.37* [+42%] | 34.62 | 27.65 | 50* | Using FP64 to mantissa extend FP128 RKL is still 42% faster. |
| With heavily vectorised SIMD workloads RKL can leverage its AVX512 support to dominate old CFL and is between 20-60% faster, despite the same no. of cores (8C/16T). It also generally matches the old HEDT SKL-X with its 10-cores (also using AVX512 but with 2x FMA units).
However, the latest Ryzen 5800X is tough competition with just AVX2/FMA3 running neck-and-neck with it with perhaps RKL marginally winning more tests (4 out of 6) by a whisker. Note:* using AVX512 instead of AVX2/FMA. |
||||||
 |
||||||
 |
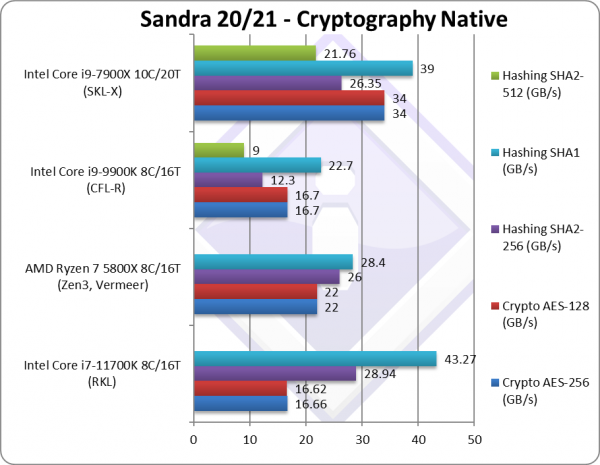
Crypto AES-256 (GB/s) | 16.66* [=] | 22 | 16.7 | 34 | Memory bandwidth rules here. |
|
Crypto AES-128 (GB/s) | 16.62* [=] | 22 | 16.7 | 34 | No change with AES128. |
|
Crypto SHA2-256 (GB/s) | 28.94*** [+2.35x] | 26** | 12.3 | 26*** | With AVX512, RKL is almost 2.4x faster. |
|
Crypto SHA1 (GB/s) | 42.27*** [+91%] | 22.7 | 39*** | Less compute intensive SHA1 RKL is 2x faster. | |
|
Crypto SHA2-512 (GB/s) | 9 | 21*** | SHA2-512 is not accelerated by SHA HWA. | ||
| The memory sub-system is crucial here, and RKL cannot beat CFL despite having VAES as AES HWA is accelerated already. Despite having SHA HWA, RKL using AVX512 is between 2-2.4x faster than CFL also beating Zen3 with its SHA HWA.
* using VAES (AVX512 VL) instead of AES HWA. [note we need much faster memory for VAES to beat AES HWA] ** using SHA HWA instead of multi-buffer AVX2. [note multi-buffer AVX2 is slower than SHA hardware-acceleration] *** using AVX512 B/W [note multi-buffer AVX512 is faster than using SHA hardware-acceleration] |
||||||
 |
||||||
 |
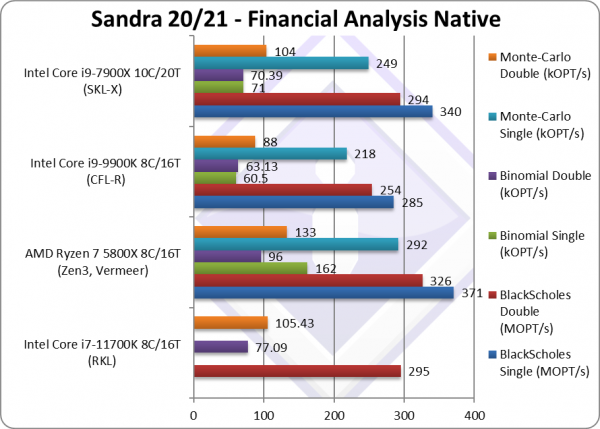
Black-Scholes float/FP32 (MOPT/s) | 285 | 340 | Black-scholes is unvectorised and compute heavy. | ||
|
Black-Scholes double/FP64 (MOPT/s) | 295 [+16%] | 326 | 254 | 289 | Using FP64 RKL is 16% faster. |
|
Binomial float/FP32 (kOPT/s) | 60.5 | 71 | Binomial uses thread shared data thus stresses the cache & memory system. | ||
|
Binomial double/FP64 (kOPT/s) | 77.09 [+22%] | 96 | 63.13 | 68 | With FP64 code RKL is 22% faster. |
|
Monte-Carlo float/FP32 (kOPT/s) | 218 | 249 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches. | ||
|
Monte-Carlo double/FP64 (kOPT/s) | 105 [+20%] | 133 | 88 | 104 | Switching to FP64 RKL is 20% faster. |
| With non-SIMD financial workloads, RKL improves by a more modest ~20% over CFL – not enough to beat Zen3 but not far off (about 20% slower). As before Intel’s CPUs rely heavily on SIMD instruction sets to win.
Still, it is more likely that the GP-GPU will be used for such workloads today. |
||||||
 |
||||||
 |
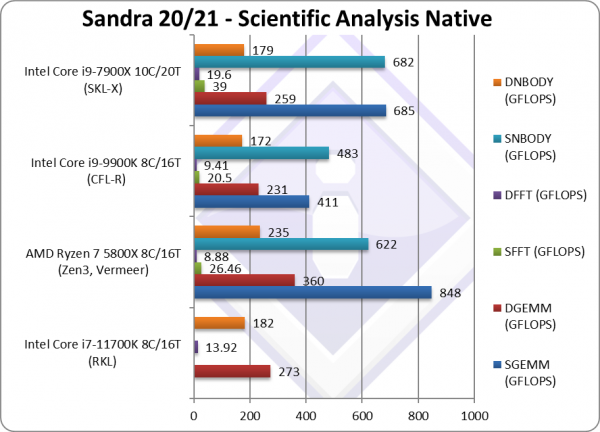
SGEMM (GFLOPS) float/FP32 | 411 | 685* | In this tough vectorised algorithm | ||
|
DGEMM (GFLOPS) double/FP64 | 273* [+18%] | 360 | 231 | 231* | With FP64 vectorised code, RKL is 18% faster. |
|
SFFT (GFLOPS) float/FP32 | 20.5 | 39* | FFT is also heavily vectorised but memory dependent . | ||
|
DFFT (GFLOPS) double/FP64 | 13.92* [+48%] | 8.88 | 9.41 | 19.6* | With FP64 code, RKL is 48% faster. |
|
SNBODY (GFLOPS) float/FP32 | 483 | 592* | N-Body simulation is vectorised but with more memory accesses. | ||
|
DNBODY (GFLOPS) double/FP64 | 182* [+6%] | 235 | 172 | 179* | With FP64 RKL is 6% faster. |
| With highly vectorised SIMD code (scientific workloads), RKL can show the power of AVX512 and is between 20-50% faster than CFL though seems bandwidth constrained in some tests – it really needs faster memory – just like Ryzen3. Thus while it manages to beat old SKL-X it cannot always win against Ryzen 3.
* using AVX512 instead of AVX2/FMA3 |
||||||
 |
||||||
 |
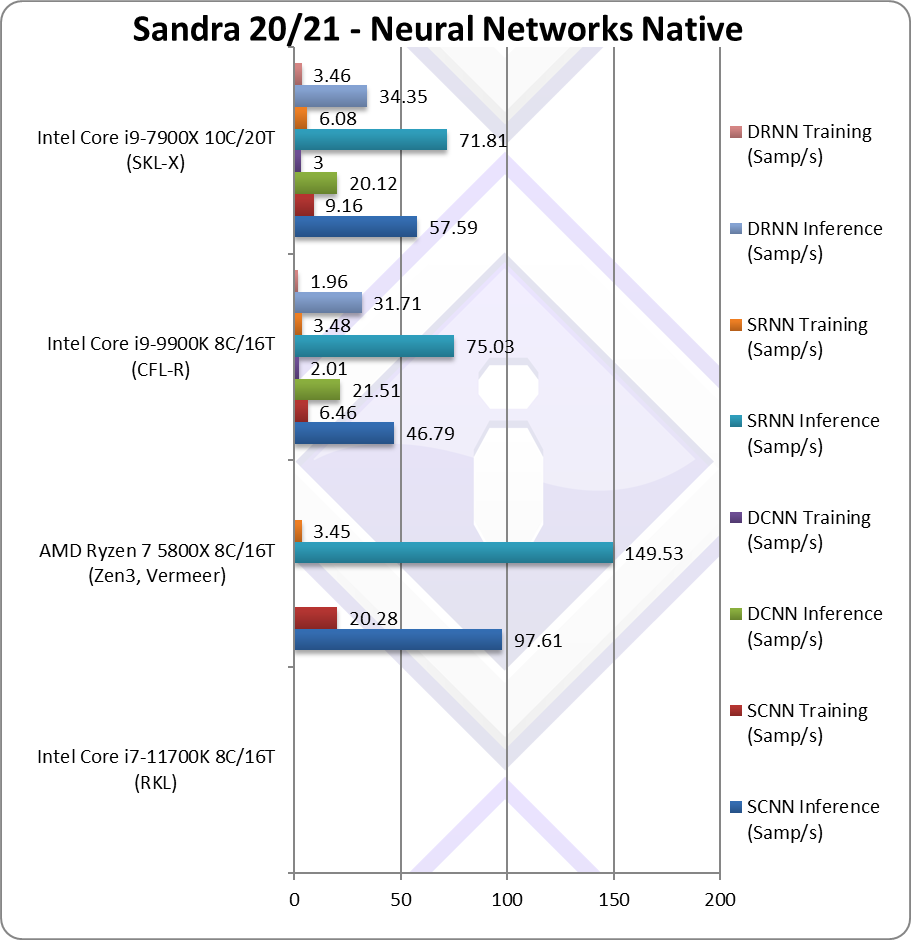
NeuralNet CNN Inference (Samples/s) | 97.61 | 46.79 | 54.19* | Waiting for results | |
|
NeuralNet CNN Training (Samples/s) | 20.28 | 6.46 | 9.16* | Waiting for results | |
|
NeuralNet RNN Inference (Samples/s) | 149 | 75.03 | 71.81* | Waiting for results | |
|
NeuralNet RNN Training (Samples/s) | 3.45 | 3.48 | 6.08* | Waiting for results | |
| * using AVX512 instead of AVX2/FMA (not using VNNI yet) | ||||||
 |
||||||
 |
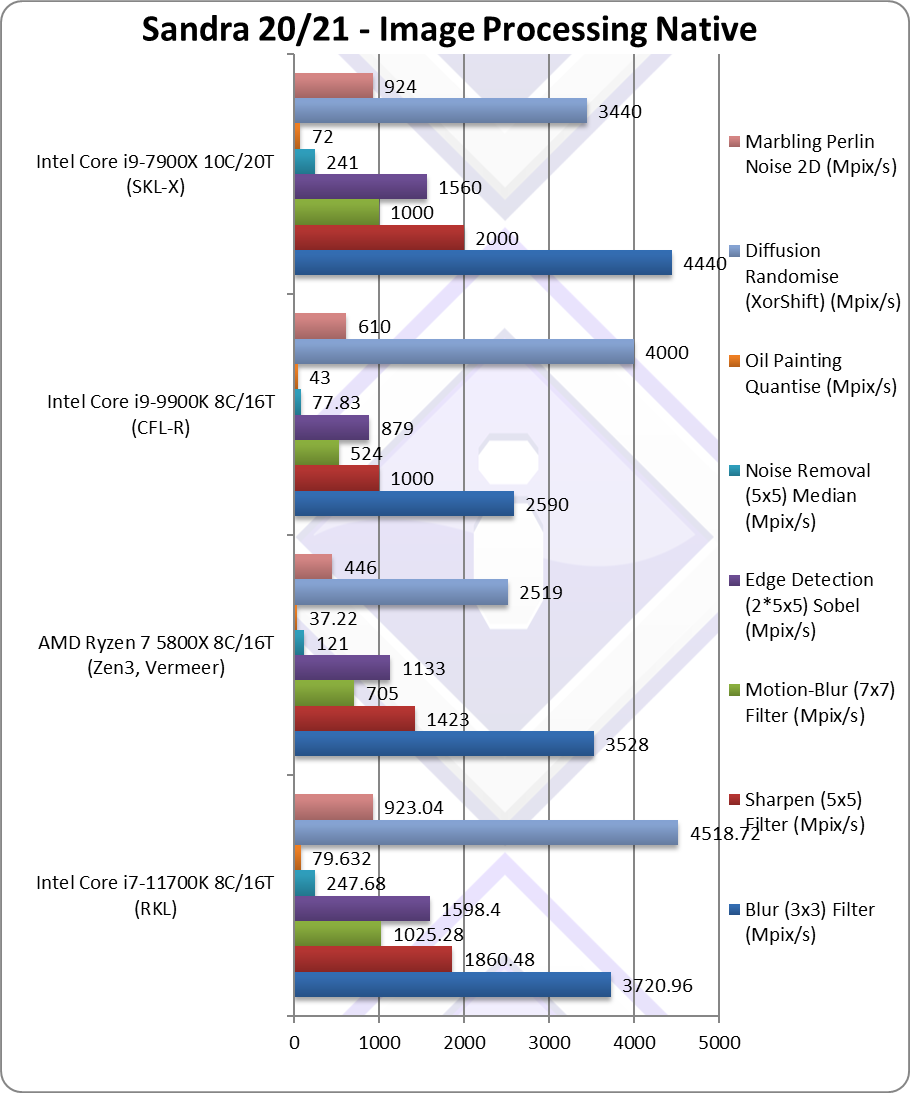
Blur (3×3) Filter (MPix/s) | 3,720* [+44%] | 3,528 | 2,590 | 4,440* | In this vectorised integer workload RKL is 44% faster. |
|
Sharpen (5×5) Filter (MPix/s) | 1,860* [+86%] | 1,423 | 1,000 | 2,000* | Same algorithm but more shared data RKL is now 86% faster. |
|
Motion-Blur (7×7) Filter (MPix/s) | 1,025* [+96%] | 705 | 524 | 1,000* | Again same algorithm but even more data shared 96% faster. |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 1,598* [+82%] | 1,133 | 879 | 1,560* | Different algorithm but still vectorised workload RKL 82% faster. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 247* [+3.1x] | 121 | 77.83 | 217* | Still vectorised code RKL is 3x faster. |
|
Oil Painting Quantise Filter (MPix/s) | 79.63* [+85%] | 37.22 | 43 | 68* | Similar improvement here of about 85%. |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 4,518* [+13%] | 2,519 | 4,000 | 3,440* | With integer workload, RKL is just 13% faster. |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 923* [+51%] | 446 | 610 | 777* | In this final test again with integer workload RKL is 51% faster. |
| Thanks to AVX512 (and friends) RKL returns to being 44-95% faster than CFL, a pretty significant improvement that allows it to beat Ryzen3 in all algorithms – though not by much in most cases. Intel’s salvation is SIMD and AVX512. Long term, most software will be updated to use AVX512.
* using AVX512 instead of AVX2/FMA |
||||||
 |
||||||
 |
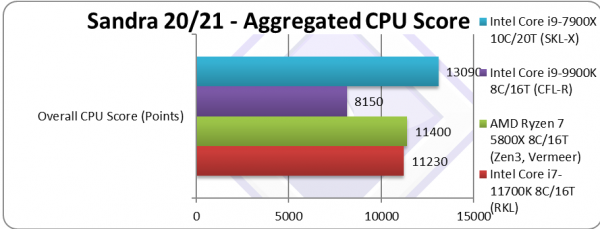
Aggregate Score (Points) | 11,230* [+38%] | 11,400 | 8,150 | 13,090* | Across all benchmarks, RKL is 38% faster. |
| RKL (8C/16T 1170K) is almost 40% faster than CFL across all the benchmarks – a great improvement where AVX512 massively (as almost all our benchmarks support AVX512). It also gets within 1% of its Ryzen3 rival (8C/16T 5800X) though it just misses out beating it. Not bad considering it’s still 14nm+++.
Note*: using AVX512 not AVX2/FMA3. |
||||||
 |
||||||
 |
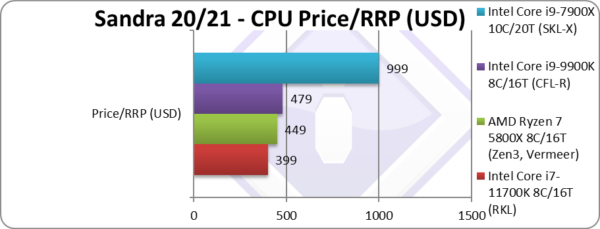
Price/RRP (USD) | $399 [-17%] |
$449 | $479 | $999 | Cheapest i7 at launch? |
 |
||||||
|
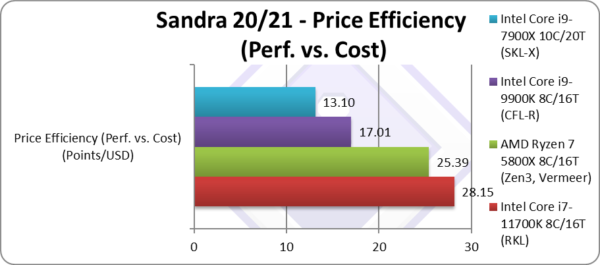
Price Efficiency (Perf. vs. Cost) (Points/USD) | 28.14 [+65%] |
25.38 | 17 | 13 | RKL is 65% more efficient! |
| Due to its performance and pretty low launch price – RKL is an impressive 65% more “bang-per-buck” than the old CFL-R which is quite impressive – especially if you have a 400-series board.
Zen3 despite great performance but higher cost is slightly less value – unless you have a somewhat recent AM4 board you can use, when again it makes sense to upgrade. However both Zen3 and RKL benefit from 500-series boards… |
||||||
 |
||||||
 |
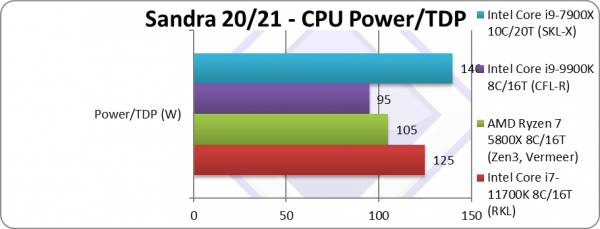
Power/TDP (W) | 125 – 175W [+25%] |
105 – 135W | 95 – 135W | 140 – 308W | TDP is 25% higher – but CFL TDP is optimistic. |
 |
||||||
|
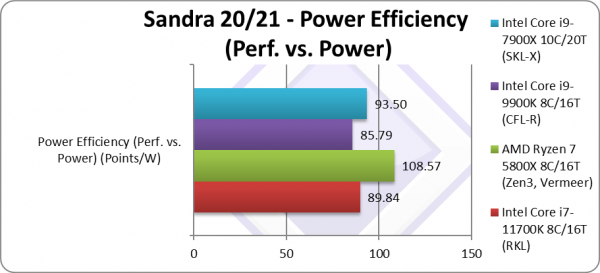
Power Efficiency (Perf. vs. Power) (W) | 89 [+5%] |
108 | 85.78 | 93.5 | Due to higher TDP, RKL is just 5% more efficient. |
| If we go by listed TDP which for CFL (9900K) is 95W then RKL (11700K) at 125W TDP does not fare well; despite the improved performance it ends up just 5% more power efficient which is not great.
TDP has always been somewhat optimistic – and despite the higher TDP considering we are still at 14nm perhaps, even 125W may not be enough to maintain top clocks especially running AVX512 SIMD code. |
||||||
Across SIMD tests, we see RKL with AVX512 about 40% faster than old CFL-R with the same number of cores (8C / 16T). Thus RKL also beats the older HEDT SKL-X with more cores (7900X 10C / 20T and 2x FMA units) and thus top-range CML (10900K 10C / 20T). But it cannot always win against Ryzen3 5800X (also 8C / 16T) with the winner changing across a variety of tests.
SiSoftware Official Ranker Scores
- 11th Gen Intel Core i9-11900K (8C / 16T, 5.3GHz)
- 11th Gen Intel Core i7-11700K (8C / 16T, 3.6GHz)
- 11th Gen Intel Core i7-11700 (8C / 16T, 2.5GHz)
- 11th Gen Intel Core i5-11600 (6C / 12T, 4.8GHz)
Final Thoughts / Conclusions
Summary: A long over-due upgrade (~40% SIMD/AVX512 improvement) : 8.5/10
Note2: The microcode (aka CPU firmware) used in the test as per above is version 2C (version 44); older or newer versions seem to exhibit different performance. We will update the review when we obtain our sample and run our own tests.
Note3: All benchmarks run are using the latest supported instruction sets – i.e. AVX512; Sandra does allow you to disable it and run AVX2/FMA3 or even AVX, SSE4, SSE2. Once we get our sample we will show the results using AVX2/FMA3.
We’ve really been waiting way too long for this – endless Skylake (SKL) derivatives (Gen 6, 7, 8, 9 and 10) then finally IceLake (ICL) and TigerLake (TGL) but for mobile (ULV) only. RocketLake (RKL) is not quite what we expected, as it’s not on 10nm and also using the older ICL cores (not TGL), but at least compatible with the 400-series (LGA 1200) platform. With AMD making steady improvements with Ryzen (series 2000, 3000 and now 5000), the top end i9 10900K CometLake (CML) could not really keep up: we really needed a new contender from Intel.
RocketLake (RKL) i7 (11700K) does not increase number of cores (still 8C / 16T), nor speeds (rated / turbo), but AVX512 + arch improvements (IPC, larger caches, TLBs, etc.) make it about 40% faster than CFL/CML and with optimisations (and higher speed memory) likely higher. TDP (Power) is higher at 125W and being still at 14nm RKL will need a lot more (155W+) to maintain top clocks.
Existing 400-series boards should also support RKL after a BIOS update, but likely no PCIe 4.0 (as we had with AMD Ryzen 3000/5000 and 400-series boards). Still best to get a 500-series board for best support which does add to the cost.
We have been waiting for PCIe 4.0, already supported by AMD 2 generations ago, and by now by modern GP-GPUs and NVMe SSDs; perhaps not quite needed, but with mass-market gaming consoles (Sony PS5, Microsoft XBox SS/XS) using NVMe/PCIe4 storage – it became a bit of an embarrassment for top-end PCs to lack it.
We also get native USB 3.2 2×2 at 20Gbps and Thunderbolt 3 (depending on the board) which can greatly help both external storage (especially NVMe or RAID arrays) and even network connection (through Thunderbolt) faster than the meagre 1Gbps (Gigabit) Ethernet… [note some boards include 2.5Gbps Ethernet, but sadly not all]
We have not touched on the Iris Gen12 XE graphics which is a *big* upgrade over the really old EV9.x graphics (see the corresponding review). However, while the TGL 96EU versions are pretty powerful – the gimped 32 EU versions will be limited: but at least i7, i9 versions are likely to be paired with a dedicated graphics card.
The keen pricing ($399) and good performance do make it a good choice for both upgraders (with 400-series boards) and those that want to “future-proof” by choosing a CPU with the latest technologies. With updated software and support, performance will only get better and hopefully the price reduce even further – making the i7 (11700K) great value for money.
Summary: Recommended : 8.5/10
The Future: AlderLake (ADL) Hybrid (big.LITTLE)
As we have seen in our TigerLake (TGL) benchmarks, TGL improves significantly over ICL (and thus RKL using the same cores at 14nm) – thus 10nm ADL “big Core” is likely to be much faster than RKL and at much lower power. So if it all goes to plan, ADL will be the Core we are all looking for…
However, ADL is a hybrid processor, consisting of “big Core” cores + “LITTLE Atom” cores – and these kind of hybrid architectures are a massive pain in the proverbial for (software) developers. There is a massive work being done underneath the hood in Sandra to support such hybrid architecture (detection/scheduler/benchmarks/UI) and it will live and die based on how good the Windows scheduler will manage cores. The future will certainly be interesting…
Further Articles
Please see our other articles on:
- CPU
- Intel 12th Gen Core AlderLake (i9-12900K) Review & Benchmarks – big/LITTLE Performance
- Intel 11th Gen Core RocketLake AVX512 Performance Improvement vs AVX2/FMA3
- Intel 11th Gen Core RocketLake (i9-11900K) Review & Benchmarks – CPU AVX512 Performance
- Intel Core Gen 10 IceLake ULV (i7-1065G7) Review & Benchmarks – CPU AVX512 Performance
- Cache & Memory
- GPGPU
- Intel Iris Gen 12 Rocketlake (i7-11700K) Review & Benchmarks – GPGPU Performance
- Intel DG1 (Iris Xe Max Gen12) Review & Benchmarks – GPGPU Performance
- Intel Iris Plus G7 Gen 12 XE TigerLake ULV (i7-1165G7) Review & Benchmarks – GPGPU Performance
- Intel Iris Plus G7 Gen 11 IceLake ULV (i7-1065G7) Review & Benchmarks – GPGPU Performance
Disclaimer
This is an independent review (critical appraisal) that has not been endorsed nor sponsored by any entity (e.g. Intel, etc.). All trademarks acknowledged and used for identification only under fair use.
The review contains only public information and not provided under NDA nor embargoed. At publication time, the products have not been directly tested by SiSoftware but submitted to the public Benchmark Ranker; thus the accuracy of the benchmark scores cannot be verified, however, they appear consistent and pass current validation checks.