What is “RocketLake”?
It is the desktop/workstation version of the true “next generation” Core (gen 10+) architecture – finally replacing the ageing “Skylake (SKL)” arch and its many derivatives that are still with us (“CometLake (CML)”, etc.). It is a combination of the “IceLake (ICL)” CPU cores launched about a year go and the “TigerLake (TGL)” Gen12 XE graphics cores launched recently.
With the new core we get a plethora of new features – some previously only available on HEDT platform (AVX512 and its many friends), improved L1/L2 caches, improved memory controller and PCIe 4.0 buses. Sadly Intel had to back-port the older ICL (not TGL) cores to 14nm – we shall have to wait for future (desktop) processors “AlderLake (ADL)” to see 10nm on the desktop…
- 14nm+++ improved process (not 10nm)
- Up to 8C/16T “Cypress Cove” cores aka 14nm+++ “Sunny Cove” from ICL – Claimed core IPC uplift of +19%
- AVX512 and all of its friends (1x FMA Unit)
- Increased L1D cache to 48kB (50% larger)
- Increased L2 cache to 512MB (2x as large)
- PCIe 4.0 (up to 32GB/s with x16 lanes) – 20 (16+4 or 8+8+4) lanes
- Thunderbolt 3 (and thus USB 3.2 2×2 support @ 20Gbps) integrated
- Hardware fixes/mitigations for vulnerabilities (“JCC”, “Meltdown”, “MDS”, various “Spectre” types)
- TVB (Thermal Velocity Boost) for Core i9 only
- ABT (Adaptive Boost Technology) for Core i9-K(F) only
The biggest change is support for AVX512-family instruction set, effectively doubling SIMD processing width (vs. AVX2/FMA) as well as adding a whole host of specialised instructions that even the HEDT platform (SKL/KBL-X) does not support yet:
- AVX512-VNNI (Vector Neural Network Instructions, dlBoost FP16/INT8) e.g. convolution
- AVX512-VBMI, VBMI2 (Vector Byte Manipulation Instructions) various use
- AVX512-BITALG (Bit Algorithms) various use
- AVX512-VAES (Vector AES) accelerating block-crypto
- AVX512-GFNI (Galois Field) – e.g. used in AES-GCM
- SHA HWA accelerating hashing (SHA1, SHA2-256 only)
While some software may not have been updated to AVX512 as it was reserved for HEDT/Servers, due to this mainstream launch you can pretty much guarantee that just about all vectorised algorithms (already ported to AVX2/FMA) will soon be ported over. VNNI, IFMA, etc. support can accelerate low-precision neural-networks that are likely to be used on mobile platforms.
The caches are finally getting updated and increased considering that the competition has deployed massively big caches in its latest products. L1D is 50% larger and L2 doubles (2x) but L3 has not been increased. We will measure latencies in a future article.
From a security point-of-view, RKL mitigates all (current/reported) vulnerabilities in hardware/firmware (Spectre 2, 3/a, 4; L1TF, MDS, etc.) except BCB (Spectre V1 that does not have a hardware solution) thus should not require slower mitigations that affect performance (especially I/O). RKL is also not affected by the JCC errata that needs mitigatation through software (compiler) changes on older processors.
The memory controller supports higher DDR4 speeds (up to 3200Mt/s) while the cache/TLB systems have been improved that should help both CPU and GPU performance (see corresponding article) as well as reduce power vs. older designs using LP-DDR3. Again we will measure bandwidth and latencies in a future article.
PCIe 4.0 finally arrives on Intel and should drive wide adoption for both discrete graphics (GP-GPUs including Intel’s) and NVMe SSDs with ~8GB/s transfer (x4 lanes) and to ~32GB/s (x16). Note that the DMI/OPI link between CPU and I/O Hub is also thus updated to PCIe 4.0 speeds improving CPU/Hub transfer.
On the desktop – while the Intel is launching new 500-series motherboards, RKL should be compatible with 400-series boards with a BIOS update. Just as with AMD, PCIe 4.0 may only be available on 500-series boards.
As the i9 has the same number of cores/threads as the i7, it has two technologies enabled to boost its clocks:
- TVB – when temperature is below Tvb (~70C), Turbo clock is boosted by 100MHz throughout
- ABT – when power is available, overall Turbo matches 2C setting
CPU (Core) Performance Benchmarking
In this article we test CPU core performance; please see our other articles on:
- CPU
- Intel 12th Gen Core AlderLake (i9-12900K) Review & Benchmarks – big/LITTLE Performance
- Intel 11th Gen Core RocketLake AVX512 Performance Improvement vs AVX2/FMA3
- Intel 11th Gen Core RocketLake (i7-11700K) Review & Benchmarks – CPU AVX512 Performance
- Intel Core Gen 10 IceLake ULV (i7-1065G7) Review & Benchmarks – CPU AVX512 Performance
- Cache & Memory
- GPGPU
- Intel Iris Gen 12 Rocketlake (i7-11700K) Review & Benchmarks – GPGPU Performance
- Intel DG1 (Iris Xe Max Gen12) Review & Benchmarks – GPGPU Performance
- Intel Iris Plus G7 Gen 12 XE TigerLake ULV (i7-1165G7) Review & Benchmarks – GPGPU Performance
- Intel Iris Plus G7 Gen 11 IceLake ULV (i7-1065G7) Review & Benchmarks – GPGPU Performance
Hardware Specifications
We are comparing the top-of-the-range Intel with competing architectures as well as competiors (AMD) with a view to upgrading to a mid-range but high performance design.
| Specifications | Intel Core i9 11900K 8C/16T (RKL) | AMD Ryzen 9 5900X 12C/24T (Zen3) | Intel Core i9 10900K 10C/20T (CML) | Intel Core i9 7900X 10C/20T (SKL-X) | Comments | |
| Arch(itecture) | Cypress Cove / RocketLake | Zen3 / Vermeer | Comet Lake | Skylake-X | Not the very latest arch. | |
| Cores (CU) / Threads (SP) | 8C / 16T [-20%] | 2M / 12C / 24T | 10C / 20T | 10C / 16T | Two less cores. | |
| Rated Speed (GHz) | 3.5 [-6%] | 3.7 | 3.7 | 3.3 | Base clock is lower | |
| All/Single Turbo Speed (GHz) |
4.8 – 5.3 [+2%] | 4.5 – 4.8 | 4.9 – 5.2 | 4.0 – 4.3 | Turbo is 2% higher. | |
| Power TDP/Turbo (W) |
125 – 250 | 105 – 135 | 125 – 155 | 140 – 308 | TDP is the same on paper. | |
| L1D / L1I Caches | 8x 48kB 12-way [+50%] / 8x 32kB 8-way | 12x 32kB 8-way / 12x 32kB 8-way | 10x 32kB 8-way / 10x 32kB 8-way | 10x 32kB 8-way / 10x 32kB 8-way | L1D is 50% larger. | |
| L2 Caches | 8x 512kB 16-way [2x] | 12x 512kB 16-way | 10x 256B 16-way | 10x 1MB 16-way | L2 has doubled. | |
| L3 Caches | 16MB 16-way [=] | 2x 32MB 16-way | 20MB 16-way | 13.75MB 11-way | L3 is the same | |
| Microcode (Firmware) | 06A701-3C* (ver 60*) |
8F7100-1009 | 06A505-C8 (ver 214) | 065504-69 (ver 105) | Revisions just keep on coming. | |
| Special Instruction Sets |
AVX512, VNNI, SHA, VAES | AVX2/FMA, SHA | AVX2/FMA | AVX512 | More AVX512! | |
| SIMD Width / Units |
512-bit (1x FMA Unit) |
256-bit | 256-bit | 512-bit (2x FMA Units) |
Widest SIMD units, but single FMA. | |
| Price / RRP (USD) |
$539 [+8%] |
$549 | $499 | $999 |
A little bit more expensive. | |
Disclaimer
This is an independent review (critical appraisal) that has not been endorsed nor sponsored by any entity (e.g. Intel, etc.). All trademarks acknowledged and used for identification only under fair use.
Note: We (SiSoftware) claim copyright over the scores (benchmark results) posted to the Ranker. Please see:
Privacy: Who owns the data (scores) posted to the Ranker?
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets. “Rocketlake” (RKL) supports all modern instruction sets including AVX512, VNNI, SHA HWA, VAES and naturally the older AVX2/FMA, AES HWA.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
| Native Benchmarks | Intel Core i9 11900K 8C/16T (RKL) | AMD Ryzen 9 5900X 12C/24T (Zen3) | Intel Core i9 10900K 10C/20T (CML) | Intel i9 7900X 10C/20T (SKL-X) | Comments | |
 |
||||||
 |
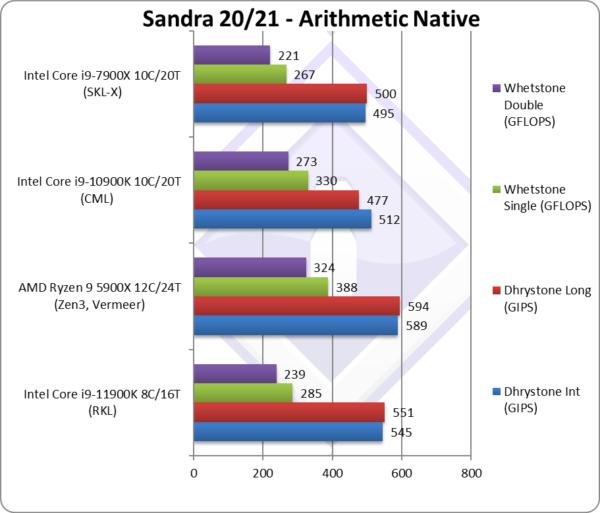
Native Dhrystone Integer (GIPS) | 545 [+6%] | 589 | 512 | 397 | RKL is 6% faster than CML. |
|
Native Dhrystone Long (GIPS) | 551 [+16%] | 594 | 477 | 392 | A 64-bit integer workload RKL is 16% faster. |
|
Native FP32 (Float) Whetstone (GFLOPS) | 285 [-14%] | 388 | 330 | 264 | With floating-point, RKL is 14% slower |
|
Native FP64 (Double) Whetstone (GFLOPS) | 239 [-12%] | 324 | 273 | 221 | With FP64 nothing much changes. |
| With legacy integer RKL manages to beat CML (6-16% faster) even with its 2 extra cores – an impressive; with floating-point it is about 13% slower which is acceptable.
Zen3 with 50% more cores naturally wins all tests – but the integer tests are not that much higher; floating-point tests do show the power of Zen3’s FPU cores – though “only” ~35% faster than RKL. If RKL had 10C then Zen3 might have had real competition. Note that due to being “legacy” none of the benchmarks support AVX512; while we could update them, they are not vectorise-able in the “spirit they were written” – thus single-lane AVX512 cannot run faster than AVX2/SSEx. |
||||||
 |
||||||
 |
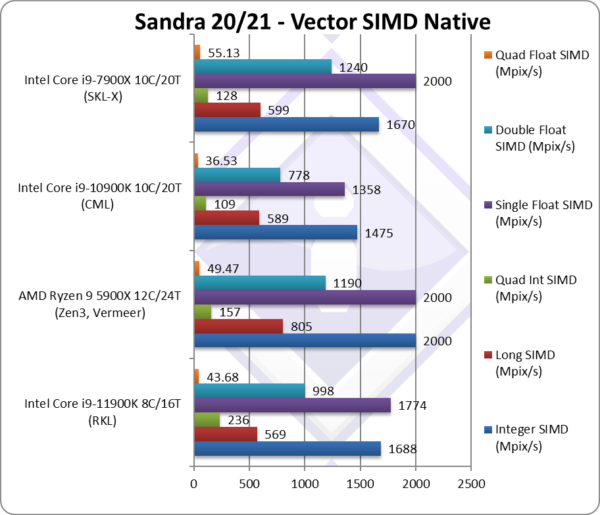
Native Integer (Int32) Multi-Media (Mpix/s) | 1,688* [+14%] | 2,000 | 1,475 | 1,590* | With AVX512 RKL is 14% faster. |
|
Native Long (Int64) Multi-Media (Mpix/s) | 569* [-3%] | 805 | 589 | 548* | With a 64-bit AVX512 integer RKL is slower. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 236* [+2.1x] | 157 | 109 | 125* | Using 64-bit int to emulate Int128 RKL is over 2x faster due to AVX512. |
|
Native Float/FP32 Multi-Media (Mpix/s) | 1,774* [+31%] | 2,000 | 1,358 | 1,930* | In this floating-point vectorised test RKL is 31% faster. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 998* [+28%] | 1,190 | 778 | 1,210* | Switching to FP64 SIMD AVX512 code, RKL is 28% faster. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 43.68 [+20%] | 49.47 | 36.53 | 50* | Using FP64 to mantissa extend FP128 RKL is still 20% faster. |
| With heavily vectorised SIMD workloads RKL can leverage its AVX512 support to dominate CML despite its 2 extra (10C) cores and also matches the old SKL-X with its 2 extra cores (also using AVX512 but with 2x FMA units).
However, Zen3 with 50% more cores (12C) is tough to beat and not even AVX512 manages to lift RKL that high – overall. We can see that if it had one more AVX512-FMA unit (like SKL-X), RKL might have been able to do it – but with a single unit it was a big ask. Note:* using AVX512 instead of AVX2/FMA. |
||||||
 |
||||||
 |
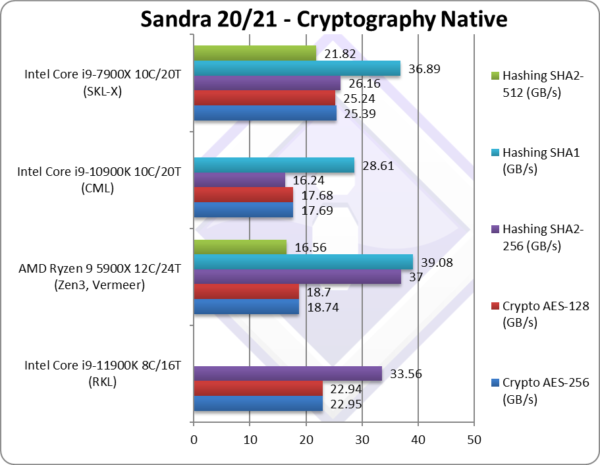
Crypto AES-256 (GB/s) | 22.95 [+30%] | 18.74 | 17.69 | 34 | Memory bandwidth rules here. |
|
Crypto AES-128 (GB/s) | 22.94 [+30%] | 18.7 | 17.68 | 34 | No change with AES128. |
|
Crypto SHA2-256 (GB/s) | 33.56*** [+2x] | 37 | 16.24 | 26*** | With AVX512, RKL is 2x faster. |
|
Crypto SHA1 (GB/s) | 38.84*** [+36%] | 39 | 28.61 | 39*** | Less compute intensive SHA1. |
|
Crypto SHA2-512 (GB/s) | 22.88*** | 16.56 | 21*** | SHA2-512 is not accelerated by SHA HWA. | |
| The memory sub-system is crucial here, and RKL using much faster memory manages to beat its competition. Despite having SHA HWA, RKL using AVX512 is 2x faster than CML but cannot beat Zen3 SHA HWA. With its 12C, Zen3 needs even faster memory to feed all the cores in streaming tests.
* using VAES (AVX512 VL) instead of AES HWA. [note we need much faster memory for VAES to beat AES HWA] ** using SHA HWA instead of multi-buffer AVX2. [note multi-buffer AVX2 is slower than SHA hardware-acceleration] *** using AVX512 B/W [note multi-buffer AVX512 is faster than using SHA hardware-acceleration] |
||||||
 |
||||||
 |
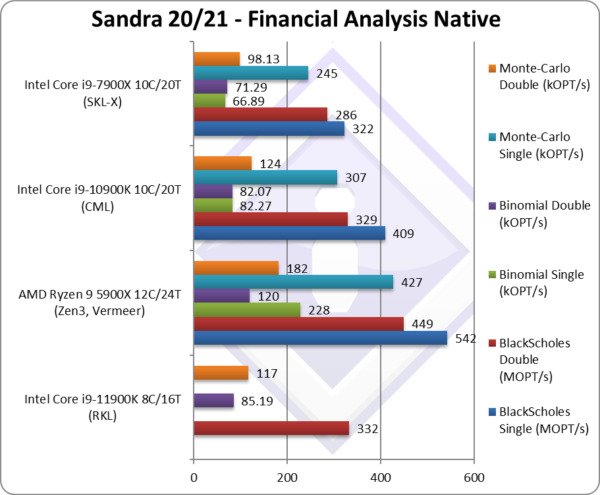
Black-Scholes float/FP32 (MOPT/s) | 379 [-7%] | 542 | 409 | 340 | Black-scholes is unvectorised and compute heavy. |
|
Black-Scholes double/FP64 (MOPT/s) | 332 [+1%] | 449 | 329 | 289 | Using FP64 RKL is 1% faster. |
|
Binomial float/FP32 (kOPT/s) | 81.83 [-1%] | 228 | 82.27 | 71 | Binomial uses thread shared data thus stresses the cache & memory system. |
|
Binomial double/FP64 (kOPT/s) | 85.19 [+4%] | 120 | 82.07 | 68 | With FP64 code RKL is 4% faster. |
|
Monte-Carlo float/FP32 (kOPT/s) | 264 [-14%] | 427 | 307 | 249 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches. |
|
Monte-Carlo double/FP64 (kOPT/s) | 117 [-6%] | 182 | 124 | 104 | Switching to FP64 RKL is 20% faster. |
| With non-SIMD financial workloads, RKL with just 8C is at a big disadvantage – but is still competitive against CML (4-6%) though naturally it cannot beat Zen3 with 12C. As before Intel’s CPUs rely heavily on SIMD instruction sets to win.
Still, it is more likely that the GP-GPU will be used for such workloads today. |
||||||
 |
||||||
 |
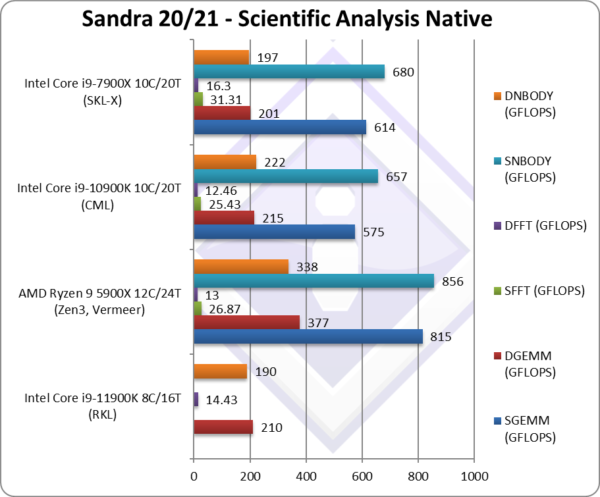
SGEMM (GFLOPS) float/FP32 | 460* [-20%] | 815 | 575 | 685* | In this tough vectorised algorithm |
|
DGEMM (GFLOPS) double/FP64 | 210* [-2%] | 377 | 215 | 231* | With FP64 vectorised code, RKL is 2% slower. |
|
SFFT (GFLOPS) float/FP32 | 22* [-13%] | 26.87 | 25.43 | 39* | FFT is also heavily vectorised but memory dependent . |
|
DFFT (GFLOPS) double/FP64 | 14.43* [+16%] | 13 | 12.43 | 19.6* | With FP64 code, RKL is 16% faster. |
|
SNBODY (GFLOPS) float/FP32 | 616* [-6%] | 856 | 657 | 592* | N-Body simulation is vectorised but with more memory accesses. |
|
DNBODY (GFLOPS) double/FP64 | 190* [-14%] | 338 | 222 | 179* | With FP64 RKL is 14% slower. |
| With highly vectorised SIMD code (scientific workloads), RKL can show the power of AVX512 units – though here we seem to have some regressions as it cannot beat CML with its extra cores and cannot beat Zen3 either.
* using AVX512 instead of AVX2/FMA3 |
||||||
 |
||||||
 |
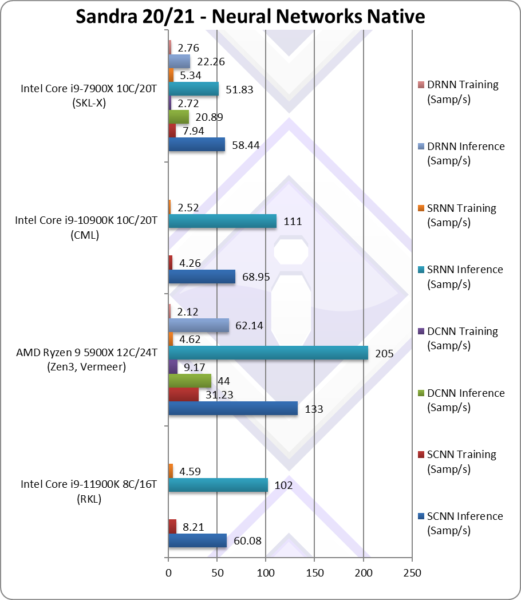
NeuralNet CNN Inference (Samples/s) | 60.08* [-13%] | 133 | 68.95 | 54.19* | Despite AVX512, RKL is 13% slower. |
|
NeuralNet CNN Training (Samples/s) | 8.21* [+2x] | 31.23 | 4.26 | 9.16* | RKL is 2x faster but nowhere near Zen3. |
|
NeuralNet RNN Inference (Samples/s) | 102* [-8%] | 205 | 111 | 71.81* | Despite AVX512, RKL is 8% slower. |
|
NeuralNet RNN Training (Samples/s) | 4.59* [+2x] | 4.62 | 2.52 | 6.08* | RKL is again 2x faster matching Zen3. |
| Despite using AVX512, RKL just manages to match CML with its 2 extra cores but cannot match Zen3 at all. We need some further optimisations for the AVX512 code-path to make it worthwhile on RKL.
* using AVX512 instead of AVX2/FMA (not using VNNI yet) |
||||||
 |
||||||
 |
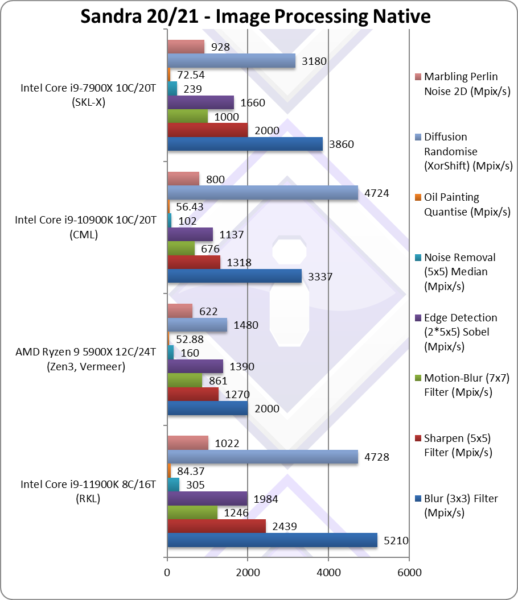
Blur (3×3) Filter (MPix/s) | 5,210* [+56%] | 2,000 | 3,337 | 4,440* | In this vectorised integer workload RKL is 56% faster. |
|
Sharpen (5×5) Filter (MPix/s) | 2,439* [+85%] | 1,270 | 1,318 | 2,000* | Same algorithm but more shared data RKL is now 85% faster. |
|
Motion-Blur (7×7) Filter (MPix/s) | 1,246* [+84%] | 861 | 676 | 1,000* | Again same algorithm but even more data shared 84% faster. |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 1,984* [74%] | 1,390 | 1,137 | 1,560* | Different algorithm but still vectorised workload RKL 74% faster. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 305* [+3x] | 160 | 102 | 217* | Still vectorised code RKL is 3x faster. |
|
Oil Painting Quantise Filter (MPix/s) | 84.37* [+50%] | 52.88 | 56.43 | 68* | Similar improvement here of about 50%. |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 4,728* [=] | 1,480 | 4,724 | 3,440* | With integer workload, RKL matches CML. |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 1,022* [+28%] | 622 | 800 | 777* | In this final test again with integer workload RKL is 28% faster. |
| Thanks to AVX512 (and friends) RKL really flies through this benchmark with massive gains that are up to 85% over CML despite its 2 more cores. It also blows both SKL-X and even Zen3 with 50% more cores.
Intel’s salvation is SIMD and AVX512. Long term, most software will be updated to use AVX512 which will favour RKL. * using AVX512 instead of AVX2/FMA |
||||||
 |
||||||
 |
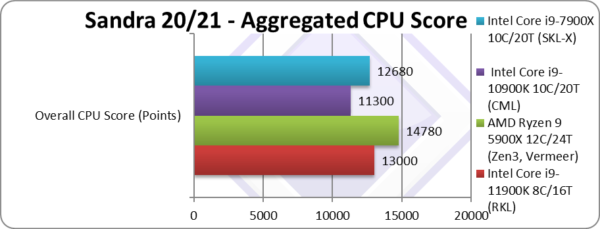
Aggregate Score (Points) | 13,000* [+15%] | 14,780 | 11,300 | 13,090* | Across all benchmarks, RKL is 15% faster. |
| RKL i9 (8C/16T 11900K) is 15% faster overall than CML i9 (10C/20T 10900K) which is a decent result though nowhere near to what we saw when testing RKL i7 (that is 40% faster than CFL i9 but with the same number of cores).
Naturally, with 12C Zen3 (5900X) is the fastest but not by as much as you may expect – it is just 15% faster still. Note*: using AVX512 not AVX2/FMA3. |
||||||
 |
||||||
 |
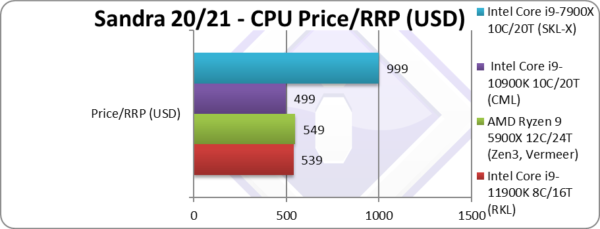
Price/RRP (USD) | $539 [+8%] | $549 | $499 | $999 | Price has gone up a bit by 8%. |
 |
||||||
|
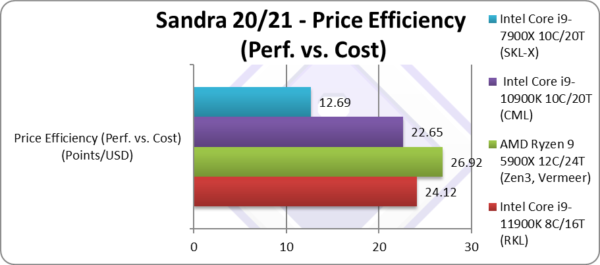
Price Efficiency (Perf. vs. Cost) (Points/USD) | 24.11 [+7%] | 26.92 | 22.64 | 12.69 | RKL is 7% more efficient. |
| Despite its modest performance increase, due to the slight price increase – the overall value is just 7% better over CML and its 10C, which is why we can be a bit disappointed. The increase is so slight that it all depends on the actual market prices, if the CML (i9 10900K) is discounted then it will be worth buying.
Zen3 is only a bit more expensive and packs 50% more cores which makes it a clear winner. But lack of availability and price gouging by sellers means the difference can be eroded especially should Intel decide to discount RKL in the run-up to ADL. |
||||||
 |
||||||
 |
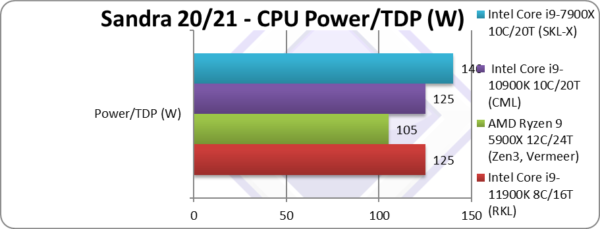
Power/TDP (W) | 125 – 250W [=] | 105 – 155W | 125 – 155W | 140 – 308W | TDP is the same – at least on paper |
 |
||||||
|
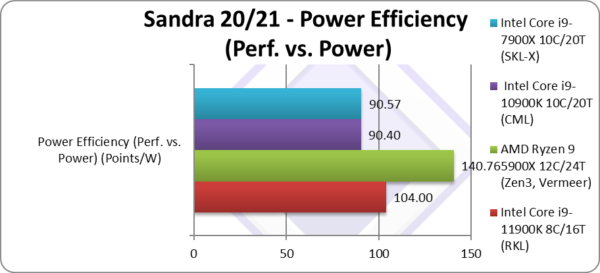
Power Efficiency (Perf. vs. Power) (W) | 104 [+15%] | 140 | 90.4 | 90.57 | Based on TDP, RKL is 15% more efficient. |
| If we go by listed TDP which matches CML – then naturally RKL is 15% more efficient, same as performance increase. But reports show that the actual power drawn is much higher thus if efficiency is what you want then old CML is the way to go.
Zen3 though is 40% more efficient which pretty much blows everything out of the water even at listed TDP. It is clear that Intel has a long way to go to match AMD in power efficiency. |
||||||
Across SIMD tests, we see RKL i9 (11900K) with AVX512 about 15% faster than CML i9 (10900K) which more cores (10C vs 8C) and also manages to beat SKL-X with the same number of cores and AVX512! You can see just how much RKL has improved over SKL at the same node (14nm) over no less than 5 generations.
However, at the top end AMD’s Zen3 how fields up to 2x more cores (e.g. 5950X with 16C) in a desktop socket at lower TDP (105W) which makes it pretty much unbeatable.
SiSoftware Official Ranker Scores
- 11th Gen Intel Core i9-11900K (8C / 16T, 5.3GHz)
- 11th Gen Intel Core i7-11700K (8C / 16T, 3.6GHz)
- 11th Gen Intel Core i7-11700 (8C / 16T, 2.5GHz)
- 11th Gen Intel Core i5-11600 (6C / 12T, 4.8GHz)
Final Thoughts / Conclusions
Summary: A good upgrade (~15% SIMD/AVX512 improvement) : 7/10
Note2: The microcode (aka CPU firmware) used in the test as per above is version 3C (version 60); older or newer versions seem to exhibit different performance. We will update the review when we obtain our sample and run our own tests.
Note3: All benchmarks run are using the latest supported instruction sets – i.e. AVX512; Sandra does allow you to disable it and run AVX2/FMA3 or even AVX, SSE4, SSE2. Once we get our sample we will show the results using AVX2/FMA3.
We’ve really been waiting way too long for this – endless Skylake (SKL) derivatives (Gen 6, 7, 8, 9 and 10) then finally IceLake (ICL) and TigerLake (TGL) but for mobile (ULV) only. RocketLake (RKL) is not quite what we expected, as it’s not on 10nm and also using the older ICL cores (not TGL), but at least compatible with the 400-series (LGA 1200) platform. With AMD making steady improvements with Ryzen (series 2000, 3000 and now 5000), the top end i9 10900K CometLake (CML) could not really keep up: we really needed a new contender from Intel.
RocketLake (RKL) i9 (11900K) reduces the number of cores (8C vs. 10C of 10900K) and also price-wise goes against competition with far more cores (12C of Ryzen 9 5900X). While AVX512 + arch improvements (IPC, larger caches, TLBs, etc.) make it about 40% faster than CFL/CML – the core discrepancy is an issue, unlike say RKL i7-11700K that goes against competition with the same core count.
Thus, overall it can only beat 10C CML by 15% and is just 12% slower than Zen3 which is competitive. With the latest microcode, it also manages to be about 15% faster than RKL i7-11700K but naturally at higher cost. It also requires a much better cooling solution especially for AVX512 compute workloads like the ones Sandra runs.
We have been waiting for PCIe 4.0, already supported by AMD 2 generations ago, and by now by modern GP-GPUs and NVMe SSDs; perhaps not quite needed, but with mass-market gaming consoles (Sony PS5, Microsoft XBox SS/XS) using NVMe/PCIe4 storage – it became a bit of an embarrassment for top-end PCs to lack it.
We also get native USB 3.2 2×2 at 20Gbps and Thunderbolt 3 (depending on the board) which can greatly help both external storage (especially NVMe or RAID arrays) and even network connection (through Thunderbolt) faster than the meagre 1Gbps (Gigabit) Ethernet… [note some boards include 2.5Gbps Ethernet, but sadly not all]
We’re not mentioning the integrated graphics here (XE-LP) as unless you are using it as a (pure) compute workstation/server – you really need to pair it with top-end GP-GPU.
While the i7-11700K is keenly priced ($399), the i9 is slightly more expensive for not a lot more performance which makes it less value. Unless you really want top-performance at any cost – the i7 is the one to go for. Especially as it has the same number of cores and features (except TVB and ABT that are speed related). This generation – the i9 is not quite what it used to be.
Summary: Good: 7/10
The Future: AlderLake (ADL) Hybrid (big.LITTLE)
As we have seen in our TigerLake (TGL) benchmarks, TGL improves significantly over ICL (and thus RKL using the same cores at 14nm) – thus 10nm ADL “big Core” is likely to be much faster than RKL and at much lower power. So if it all goes to plan, ADL will be the Core we are all looking for…
However, ADL is a hybrid processor, consisting of “big Core” cores + “LITTLE Atom” cores – and these kind of hybrid architectures are a massive pain in the proverbial for (software) developers. There is a massive work being done underneath the hood in Sandra to support such hybrid architecture (detection/scheduler/benchmarks/UI) and it will live and die based on how good the Windows scheduler will manage cores. The future will certainly be interesting…
Further Articles
Please see our other articles on:
- CPU
- Intel 12th Gen Core AlderLake (i9-12900K) Review & Benchmarks – big/LITTLE Performance
- Intel 11th Gen Core RocketLake AVX512 Performance Improvement vs AVX2/FMA3
- Intel 11th Gen Core RocketLake (i7-11700K) Review & Benchmarks – CPU AVX512 Performance
- Intel Core Gen 10 IceLake ULV (i7-1065G7) Review & Benchmarks – CPU AVX512 Performance
- Cache & Memory
- GPGPU
- Intel Iris Gen 12 Rocketlake (i7-11700K) Review & Benchmarks – GPGPU Performance
- Intel DG1 (Iris Xe Max Gen12) Review & Benchmarks – GPGPU Performance
- Intel Iris Plus G7 Gen 12 XE TigerLake ULV (i7-1165G7) Review & Benchmarks – GPGPU Performance
- Intel Iris Plus G7 Gen 11 IceLake ULV (i7-1065G7) Review & Benchmarks – GPGPU Performance
Disclaimer
This is an independent review (critical appraisal) that has not been endorsed nor sponsored by any entity (e.g. Intel, etc.). All trademarks acknowledged and used for identification only under fair use.
Note: We (SiSoftware) claim copyright over the scores (benchmark results) posted to the Ranker. Please see:
Privacy: Who owns the data (scores) posted to the Ranker?
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!