What is “CofeeLake” CFL?
The 8th generation Intel Core architecture is code-named “CofeeLake” (CFL): unlike previous architectures, it is a minor stepping of the previous 7th generation “KabyLake” (KBL), itself a minor update of the 6th generation “SkyLake” (SKL). The server/workstation (SKL-X/KBL-X) CPU core saw new instruction set support (AVX512) as well as other improvements – these have not made the transition yet.
Possibly due limited competition (before AMD Ryzen launch), process issues (still at 14nm) and the disclosure of a whole host of hardware vulnerabilities (Spectre, Meltdown, etc.) which required microcode (firmware) updates – performance improvements have not been forthcoming. This is pretty much unprecedented – while some Core updates were only evolutionary we have not had complete stagnation before; in addition the built-in GPU core has also remained pretty much stagnant – we will investigate this in a subsequent article.
However, CFL does bring up a major change – and that is increased core counts both on desktop and mobile: on desktop we go from 4 to 6 cores (+50%) while on mobile (ULV) we go from 2 to 4 (+100%) within the same TDP envelope!
In this article we test CPU Cache and Memory performance; please see our other articles on:
- Intel Core i7 8700K CofeeLake Review & Benchmarks – CPU 6-core/12-thread Performance
- Intel UHD 630 (Core i7 8700K, i9 9900K) – GPGPU Performance
- Intel Core i7 9900K CofeeLake-R Review & Benchmarks – 8-core/16-thread CPU Performance
Hardware Specifications
We are comparing the top-of-the-range Gen 8 Core i7 (8700K) with previous generation (6700K) and competing architectures with a view to upgrading to a mid-range high performance design.
| CPU Specifications | Intel i7-8700K CofeeLake | AMD Ryzen2 2700X Pinnacle Ridge | Intel i9-7900X SkyLake-X | Intel i7-6700K SkyLake | Comments | |
| L1D / L1I Caches | 6x 32kB 8-way / 6x 32kB 8-way | 8x 32kB 8-way / 8x 64kB 8-way | 10x 32kB 8-way / 10x 32kB 8-way | 4x 32kB 8-way / 4x 32kB 8-way | No L1D/I changes, Ryzen’s L1I is twice as big. | |
| L2 Caches | 6x 256kB 4-way | 8x 512kB 8-way | 10x 1MB 16-way | 4x 256kB 4-way | No L2 changes, Ryzen’s L2 is twice as big again. | |
| L3 Caches | 12MB 16-way | 2x 8MB 16-way | 2x 8MB 16-way | 8MB 16-way | L3 has also increased with no of cores, still behind Ryzen’s dual 8MB L3 caches. | |
| TLB 4kB pages |
64 4-way / 64 8-way/ 1536 6-way | 64 full-way 1536 8-way | 64 4-way / 64 8-way / 1536 6-way | 64 4-way / 64 8-way / 1536 6-way | No TLB changes. | |
| TLB 2MB pages |
8 full-way / 1536 6-way | 64 full-way 1536 2-way | 8 full-way / 1536 6-way | 8 full-way / 1536 6-way | No TLB changes. | |
| Memory Controller Speed (MHz) | 1200-4400 | 1333-2667 | 1200-2700 | 1200-4000 | The uncore (memory controller) runs at faster clock due to higher rated clock but not a lot in it. | |
| Memory Data Speed (MHz) |
3200 | 2667 | 3200 | 2533 | CFL can easily run at 3200Mt/s while KBL/SKL were not as reliable. We could not get Ryzen past 2667 while it does support 2933. | |
| Memory Channels / Width |
2 / 128-bit | 2 / 128-bit | 2 / 128-bit | 2 / 128-bit | All have 128-bit total channel width. | |
| Memory Bandwidth (GB/s) |
50 | 42 | 100 | 40 | Bandwidth has naturally increased with memory clock speed but latencies are higher. | |
| Uncore / Memory Controller Firmware |
2.6.2 | 2.0.0.6 | We’re on firmware 2.6.x vs. 2.0.x on old SKL/KBL. | |||
| Memory Timing (clocks) |
16-16-16-36 6-52-25-12 2T | 16-17-17-35 7-60-20-10 2T | 16-18-18-36 5-54-21-10 2T | Timings are very much BIOS dependent and vary a lot. | ||
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (AVX2, AVX, etc.). CFL supports most modern instruction sets (AVX2, FMA3) but not the latest SKL/KBL-X AVX512 nor a few others like SHA HWA (Atom, Ryzen).
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64 (1807), latest drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
Spectre / Meltdown Windows Mitigations: all were enabled as per default (BTI enabled, RDCL/KVA enabled, PCID enabled).
| Native Benchmarks | Intel i7-8700K CofeeLake | AMD Ryzen2 2700X Pinnacle Ridge | Intel i9-7900X SkyLake-X | Intel i7-6700K SkyLake | Comments | |
 |
||||||
 |
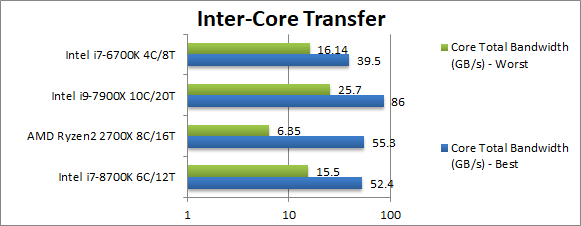
Total Inter-Core Bandwidth – Best (GB/s) | 52.5 [-5%] | 55.3 | 86 | 39.5 | Despite just 2 less cores, CFL has only 5% less bandwidth than Ryzen 2. |
|
Total Inter-Core Bandwidth – Worst (GB/s) | 15.5 [+144%] | 6.35 | 25.7 | 16.1 | In worst-case pairs on Ryzen2 must go across CCXes – unlike Intel’s CPUs – thus CFL can muster over 2x more bandwidth in this case. |
| CFL manages good bandwidth improvement over KBL/SKL – and due to unified design matching Ryzen2 in best case and beating it soundly in worst case. | ||||||
 |
||||||
|
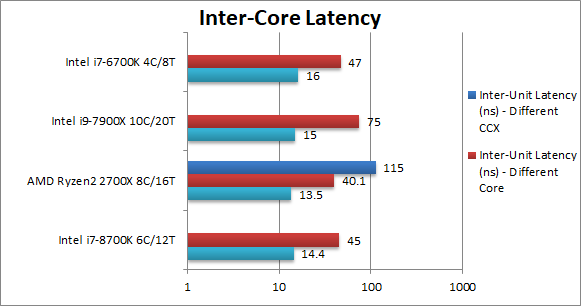
Inter-Unit Latency – Same Core (ns) | 14.4 [+7%] | 13.5 | 15 | 16 | Surprisingly, Ryzen2 manages lower thread latency when sharing core. |
|
Inter-Unit Latency – Same Compute Unit (ns) | 45 [+12%] | 40 | 75 | 47 | Within the same unit, Ryzen2 is again faster than CFL. |
|
Inter-Unit Latency – Different Compute Unit (ns) | – | 115 | – | – | Obviously going across CCXes is slow, about 3x slower which needs careful thread scheduling. |
| The multiple CCX design still presents some challenges to programmers requiring threads to be carefully scheduled – but we see Ryzen2 with lower latencies for both core and unit a surprising result as usually Intel’s caches are lower latency. | ||||||
 |
||||||
 |
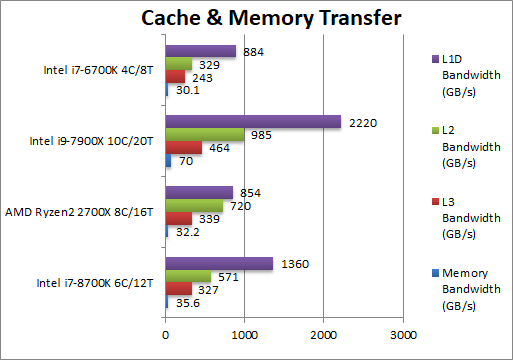
Aggregated L1D Bandwidth (GB/s) | 1630 [+59%] |
854 | 2220 | 884 | Intel’s wide data path L1 caches allow even old SKL to beat Ryzen2 with CFL enjoying 60% more bandwidth. |
|
Aggregated L2 Bandwidth (GB/s) | 571 [-21%] | 720 | 985 | 329 | But Ryzen2’s L2 caches are not only twice as big but also very wide – CFL has 20% less bandwidth. |
|
Aggregated L3 Bandwidth (GB/s) | 327 [-4%] | 339 | 464 | 243 | Ryzen’s 2 L3 caches also provide good bandwidth matching CFL’s unified L3 cache. |
|
Aggregated Memory (GB/s) | 35.6 [+11%] | 32.2 | 70 | 30.1 | Running at 3200Mt’s obviously CFL enjoys higher bandwidth than Ryzen2 at 2667Mt’s but somehow the latter has better efficiency. |
| Nothing much has changed in CFL vs. old SKL thus while L1 caches are wide and thus fast – the L2, L3 are not as impressive and the memory controller while competitive it does not seem as efficient as Ryzen2 but is more stable at high data rates allowing for higher bandwidth. | ||||||
 |
||||||
 |
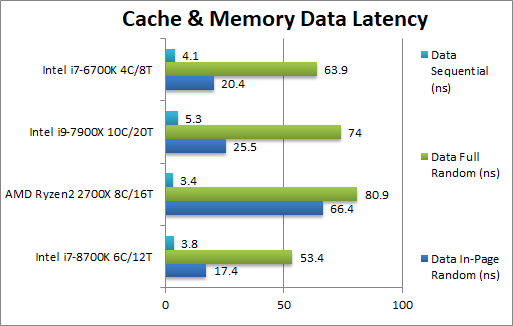
Data In-Page Random Latency (ns) | 17.4 (4-11-20) [-73%] | 63.4 (4-12-31) | 25.5 (4-13-30) | 20.4 (4-12-21) | While clock latencies have not changed w.s. old KBL/SKL, CFL enjoys lower latencies due to higher data rates. Ryzen2 has problems here. |
|
Data Full Random Latency (ns) | 53.4 (4-11-42) [-30%] | 76.2 (4-12-32) | 74 (4-13-62) | 63.9 (4-12-34) | Out-of-page clock latencies have increased but still overall lower. Ryzen2 has almost caught up here. |
|
Data Sequential Latency (ns) | 3.8 (4-11-12) [+15%] | 3.3 (4-6-7) | 5.3 (4-12-12) | 4.1 (4-12-13) | With sequential access, Ryzen2 is now faster as CFL’s clock latencies have not changed. |
| CFL is lucky here as even Ryzen2 still has high latencies in random accesses (either in-page or full range) but manages to be faster with sequential access. Intel will need to improve going forward as clock latencies while good have really not improved at all. | ||||||
 |
||||||
|
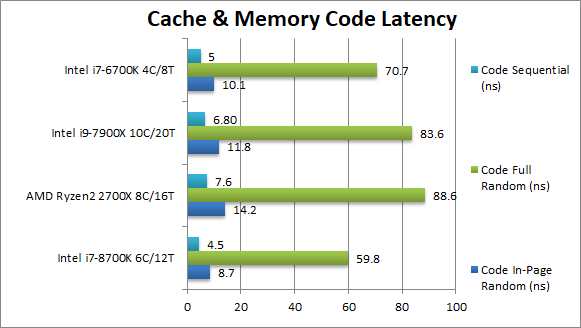
Code In-Page Random Latency (ns) | 8.7 (2-10-21) [-37%] | 13.8 (4-9-24) | 11.8 (4-14-25) | 10.1 (2-10-21) | Code clock latencies also have not changed and again and while Ryzen2 performs a lot better, CFL (even old SKL) manage to be ~35% faster. |
|
Code Full Random Latency (ns) | 59.8 (2-10-48) [-30%] | 85.7 (4-14-49) | 83.6 (4-15-74) | 70.7 (2-11-46) | Out-of-page clock latencies also have not changed and here CFL is 20% faster over Ryzen2. |
|
Code Sequential Latency (ns) | 4.5 (2-4-10) [-39%] | 7.4 (4-12-20) | 6.8 (4-7-11) | 5 (2-4-9) | Ryzen2 is competitive but again CFL manages to be almost 40% faster. |
| CFL dominates here and enjoys 30-40% less latency over Ryzen2 but the latter has improved a lot in time. | ||||||
| Memory Update Transactional (MTPS) | 54 [+980%] | 5 | 59 | 35 | Finally all top-end Intel CPUs have HLE enabled and working and thus enjoy huge performance increase. | |
| Memory Update Record Only (MTPS) | 38 [+730%] | 4.58 | 59 | 24.8 | Nothing much changes here. | |
CFL does not bring anything new vs. old KBL/SKL, both caches and memory controller are unchanged. The latter can now (officially) use higher clocked memory thus it does improve in terms of bandwidth/latencies and the uncore can also clock a bit higher but that is it.
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
CFL’s caches and memory (uncore) sub-systems are unchanged from SKL/KBL and thus provide no surprises, with rock-solid performance at 3200Mt/s with huge bandwidth (needed after all to feed 12 threads) but Ryzen2 has improved a lot over old AMD CPU designs.
With the continuous increase in cores/threads (8/12 in CFL-R) as with Ryzen1/2 but modest DDR4 speed increases (not to mention very high cost), the desktop platforms are likely to see diminishing returns due to core/thread data starvation while the extra cores just cannot be fed by the memory sub-systems. The L2 and L3 caches will need to be improved (widened, larger as with SKL-X) also the now defunct L4/eDRAM cache should re-emerge to mitigate these issues…