What is “CofeeLake-R” CFL-R?
It is the “refresh” (updated) version of the 8th generation Intel Core architecture (CFL) – itself a minor stepping of the previous 7th generation “KabyLake” (KBL), itself a minor update of the 6th generation “SkyLake” (SKL). While ordinarily this would not be much of an event – this time we do have more significant changes:
- Patched vulnerabilities in hardware: this can help restore I/O workload performance degradation due to OS mitigations
- Kernel Page Table Isolation (KPTI) aka “Meltdown” – Patched in hardware
- L1TF/Foreshadow – Patched in hardware
- (IBPB/IBRS) “Spectre 2” – OS mitigation needed
- Speculative Store Bypass disabling (SSBD) “Spectre 4” – OS mitigation needed
- Increased core counts yet again: CFL-R top-end now has 8 cores, not 6.
Intel CPUs bore the brunt of the vulnerabilities disclosed at the start of 2018 with “Meltdown” operating system mitigations (KVA) likely having the biggest performance impact in I/O workloads. While modern features (e.g. PCID (process context id) acceleration) could help reduce performance impact somewhat on recent architectures (4th gen and newer) the impact can still be significant. The CFL-R hardware fixes (thus not needing KVA) may thus prove very important.
On the desktop we also see increased cores (again!) now up to 8 (thus 16 threads with HyperThreading) – double what KBL and SKL brought and matching AMD.
We also see increased clocks, mainly Turbo, but this still allows 1 or 2 cores to boost clocks higher than CFL could and thus help workloads not massively threaded. This can improve responsiveness as single tasks can be run at top speed when there is little thread utilization.
While rated TDP has not changed, in practice we are likely to see increased “real” power consumption especially due to higher clocks – with Turbo pushing power consumption even higher – close to SKL/KBL-X.
In this article we test CPU Core performance; please see our other articles on:
- Intel Core i7 9900K CofeeLake-R Review & Benchmarks – Memory Performance
- Intel UHD 630 (Core i7 8700K, i9 9900K) – GPGPU Performance
- Intel Core i7 8700K CofeeLake Review & Benchmarks – Memory Performance
Hardware Specifications
We are comparing the top-of-the-range Gen 8 Core i9 (9900K) with previous generation (8700K) and competing architectures with a view to upgrading to a mid-range high performance design.
| CPU Specifications | Intel i9-9900K CofeeLake-R |
Intel i7-8700K CofeeLake |
AMD Ryzen2 2700X Pinnacle Ridge |
Intel i9-7900X SkyLake-X |
Comments | |
| Cores (CU) / Threads (SP) | 8C / 16T | 6C / 12T | 8C / 16T | 10C / 20T | We have 33% more cores matching Ryzen and close to mainstream SKL-X! | |
| Speed (Min / Max / Turbo) | 0.8-3.6-5GHz
(8x-36x-50x) |
0.8-3.7-4.7GHz (8x-37x-47x) | 2.2-3.7-4.2GHz (22x-37x-42x) | 1.2-3.3-4.3 (12x-33x-43x) | Single/Dual core Turbo has now reached 5GHz same as 8086K special edition. | |
| Power (TDP) | 95W (135) | 95W (131) | 105W (135) | 140W (308) | TDP is the same but overall power consumption likely far higher. | |
| L1D / L1I Caches | 8x 32kB 8-way / 8x 32kB 8-way | 6x 32kB 8-way / 6x 32kB 8-way | 8x 32kB 8-way / 8x 64kB 8-way | 10x 32kB 8-way / 10x 32kB 8-way | No change in L1 caches. Just more of them. | |
| L2 Caches | 8x 256kB 8-way | 6x 256kB 8-way | 8x 512kB 8-way | 10x 1MB 8-way | No change in L2 caches. Just more of them. | |
| L3 Caches | 16MB 16-way | 12MB 16-way | 2x 8MB 16-way | 13.75MB 11-way | L3 has also increased by 33% in line with cores matching Ryzen. | |
| Microcode/Firmware | MU069E0C-9E | MU069E0A-96 | MU8F0802-04 | MU065504-49 | We have a new stepping and slightly newer microcode. | |
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (AVX2, AVX, etc.). CFL supports most modern instruction sets (AVX2, FMA3) but not the latest SKL/KBL-X AVX512 nor a few others like SHA HWA (Atom, Ryzen).
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64 (1809), latest drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
Spectre / Meltdown Windows Mitigations: all were enabled as per default (BTI enabled, RDCL/KVA enabled, PCID enabled).
| Native Benchmarks | Intel i9-9900K CofeeLake-R | Intel i7-8700K CofeeLake | AMD Ryzen2 2700X Pinnacle Ridge | Intel i9-7900X SkyLake-X | Comments | |
 |
||||||
 |
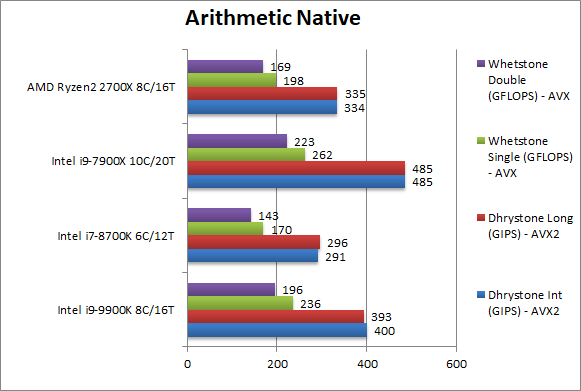
Native Dhrystone Integer (GIPS) | 400 [+20%] | 291 | 334 | 485 | In the old Dhrystone integer workload, CFL-R finally beats Ryzen by 20%. |
|
Native Dhrystone Long (GIPS) | 393 [+17%] | 296 | 335 | 485 | With a 64-bit integer workload – nothing much changes. |
|
Native FP32 (Float) Whetstone (GFLOPS) | 236 [+19%] | 170 | 198 | 262 | Switching to floating-point, CFL-R still beats Ryzen by 20% in old Whetstone. |
|
Native FP64 (Double) Whetstone (GFLOPS) | 196 [+16%] | 143 | 169 | 223 | With FP64 nothing much changes. |
| From integer workloads in Dhrystone to floating-point workloads in Whetstone, CFL-R handily beats Ryzen by about 20% and is also 33-39% faster than old CFL. It’s “king of the hill”. | ||||||
 |
||||||
 |
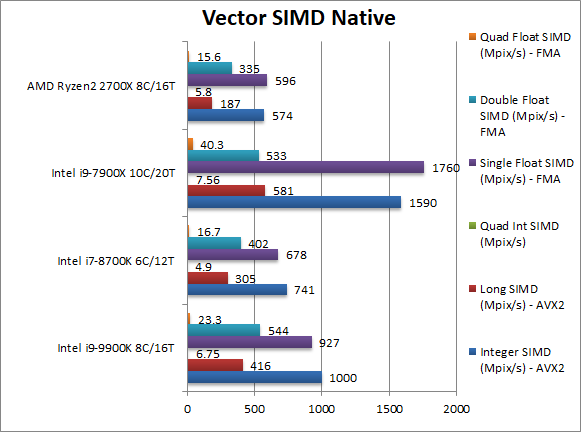
Native Integer (Int32) Multi-Media (Mpix/s) | 1000 [+74%] | 741 | 574 | 1590 (AVX512) | In this vectorised AVX2 integer test CFL-R is almost 2x faster than Ryzen |
|
Native Long (Int64) Multi-Media (Mpix/s) | 416 [+122%] | 305 | 187 | 581 (AVX512) | With a 64-bit AVX2 integer vectorised workload, CFL-R is now over 2.2x faster than Ryzen. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 6.75 [+16%] | 4.9 | 5.8 | 7.6 | This is a tough test using Long integers to emulate Int128 without SIMD: still CFL-R is fastest. |
|
Native Float/FP32 Multi-Media (Mpix/s) | 927 [+56%] | 678 | 596 | 1760 (AVX512) | In this floating-point AVX/FMA vectorised test, CFL-R is 56% faster than Ryzen. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 544 [+62%] | 402 | 335 | 533 (AVX512) | Switching to FP64 SIMD code, CFL-R increases its lead to 612. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 23.3 [+49%] | 16.7 | 15.6 | 40.3 (AVX512) | In this heavy algorithm using FP64 to mantissa extend FP128 but not vectorised – CFL-R is 50% faster. |
| In vectorised SIMD code we know Intel’s SIMD units (that can execute 256-bit instructions in one go) are much more powerful than AMD’s and it shows: Ryzen is soundly beaten by a big 50-100% margin. Naturally it cannot beat its “big brother” SKL-X with AVX512 – which is likely why Intel has not enabled them. | ||||||
 |
||||||
 |
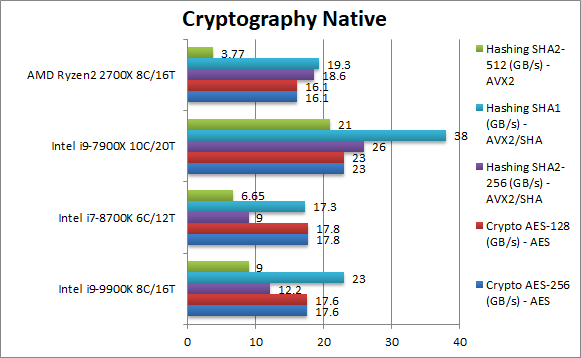
Crypto AES-256 (GB/s) | 17.6 [+9%] | 17.8 | 16.1 | 23 | With AES HWA support all CPUs are memory bandwidth bound; core contention (8 vs 6) means CFL-R scores slightly worse than CFL. |
|
Crypto AES-128 (GB/s) | 17.6 [+9%] | 17.8 | 16.1 | 23 | What we saw with AES-256 just repeats with AES-128. |
|
Crypto SHA2-256 (GB/s) | 12.2 [-34%] | 9 | 18.6 | 26 (AVX512) | With SHA HWA Ryzen2 powers through but CFL-R is only 34% slower. |
|
Crypto SHA1 (GB/s) | 23 [+19%] | 17.3 | 19.3 | 38 (AVX512) | Ryzen also accelerates the soon-to-be-defunct SHA1 but the algorithm is less compute heavy allowing CFL-R to beat it. |
|
Crypto SHA2-512 (GB/s) | 9 [+139%] | 6.65 | 3.77 | 21 (AVX512) | SHA2-512 is not accelerated by SHA HWA, allowing CFL-R to use its SIMD units and be 139% faster. |
| AES HWA is memory bound and here and CFL-R also enjoys the 3200Mt/s memory – but now feeding 8C / 16T which all contend for the bandwidth. Thus CFL-R does score slighly less than CFL and obviously gets left in the dust by SKL-X with 4 memory channels. Ryzen2 SHA HWA does manage a lonely win but anything SIMD accelerated belongs to Intel. | ||||||
 |
||||||
 |
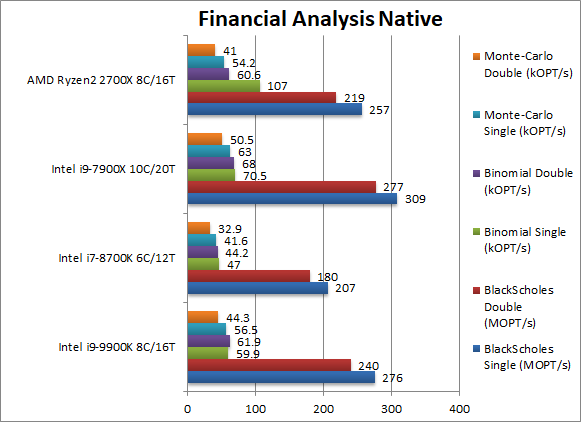
Black-Scholes float/FP32 (MOPT/s) | 276 [+7%] | 207 | 257 | 309 | In this non-vectorised test CFL-R is just a bit faster than Ryzen2. |
|
Black-Scholes double/FP64 (MOPT/s) | 240 [+10%] | 180 | 219 | 277 | Switching to FP64 code, nothing much changes, CFL-R is 10% faster |
|
Binomial float/FP32 (kOPT/s) | 59.9 [-44%] | 47 | 107 | 70.5 | Binomial uses thread shared data thus stresses the cache & memory system; CFL-R strangely loses by 44%. |
|
Binomial double/FP64 (kOPT/s) | 61.9 [+2%] | 44.2 | 60.6 | 68 | With FP64 code Ryzen2’s lead diminishes, CFL is pretty much tied with it. |
|
Monte-Carlo float/FP32 (kOPT/s) | 56.5 [+4%] | 41.6 | 54.2 | 63 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches; CFL-R is just 4% faster. |
|
Monte-Carlo double/FP64 (kOPT/s) | 44.3 [+8%] | 32.9 | 41 | 50.5 | Switching to FP64 CFL-R increases its lead to 8%. |
| Without SIMD support, CFL-R relies on its thread count increase (thus matching Ryzen2) to beat Ryzen2 by a small amount and lose in one test. But in a test that AMD used to always win (with Ryzen 1/2) Intel now has the lead. | ||||||
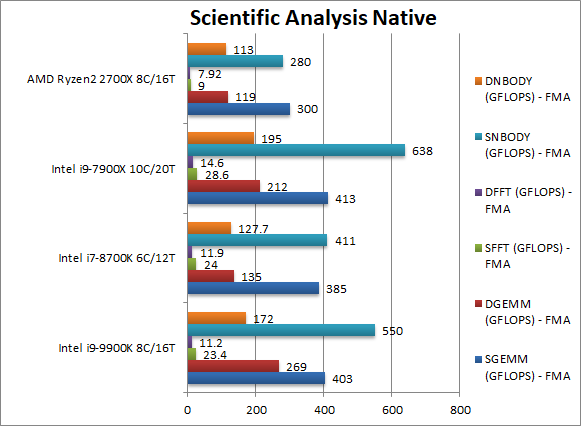 |
||||||
 |
SGEMM (GFLOPS) float/FP32 | 403 [+34%] | 385 | 300 | 413 (AVX512) | In this tough vectorised AVX2/FMA algorithm CFL-R is 35% faster than Ryzen2 |
|
DGEMM (GFLOPS) double/FP64 | 269 [+126%] | 135 | 119 | 212 (AVX512) | With FP64 vectorised code, CFL-R is over 2x faster. |
|
SFFT (GFLOPS) float/FP32 | 23.4 [+160%] | 24 | 9 | 28.6 (AVX512) | FFT is also heavily vectorised (x4 AVX/FMA) but stresses the memory sub-system more CFL-R is over 2x faster. |
|
DFFT (GFLOPS) double/FP64 | 11.2 [+41%] | 11.9 | 7.92 | 14.6 (AVX512) | With FP64 code, CFL-R’s lead reduces to 41%. |
|
SNBODY (GFLOPS) float/FP32 | 550 [+96%] | 411 | 280 | 638 (AVX512) | N-Body simulation is vectorised but many memory accesses to shared data but CFL-R is 2x faster than Ryzen2. |
|
DNBODY (GFLOPS) double/FP64 | 172 [+52%] | 127 | 113 | 195 (AVX512) | With FP64 code CFL’s lead reduces to 50% over Ryzen 2. |
| With highly vectorised SIMD code CFL-R performs very well – dominating Ryzen2: in some tests it is over 2x faster! Then again CFL did not have any issues here either, Intel is just extending their lead… | ||||||
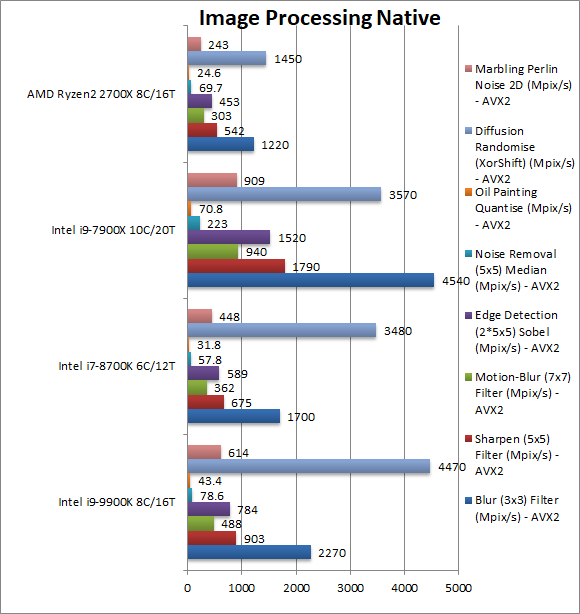 |
||||||
 |
Blur (3×3) Filter (MPix/s) | 2270 [+86%] | 1700 | 1220 | 4540 (AVX512) | In this vectorised integer AVX2 workload CFL-R is amost 2x faster than Ryzen2. |
|
Sharpen (5×5) Filter (MPix/s) | 903 [+67%] | 675 | 542 | 1790 (AVX512) | Same algorithm but more shared data reduces the lead to 67% still significant. |
|
Motion-Blur (7×7) Filter (MPix/s) | 488 [+61%] | 362 | 303 | 940 (AVX512) | Again same algorithm but even more data shared reduces the lead to 61%. |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 784 [+73%] | 589 | 453 | 1520 (AVX512) | Different algorithm but still AVX2 vectorised workload means CFL-R is 73% faster than Ryzen 2. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 78.6 [+13%] | 57.8 | 69.7 | 223 (AVX512) | Still AVX2 vectorised code but CFL-R stumbles a bit here – but it’s still 13% faster. |
|
Oil Painting Quantise Filter (MPix/s) | 43.4 [+76%] | 31.8 | 24.6 | 70.8 (AVX512) | CFL-R recovers its dominance over Ryzen2. |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 4470 [+208%] | 3480 | 1450 | 3570 (AVX512) | CFL-R (like all Intel CPUs) does very well here – it’s a huge 3x faster. |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 614 [+153%] | 448 | 243 | 909 (AVX512) | In this final test, CFL-R is over 2x faster than Ryzen 2. |
Adding 2 more cores brings additional performance gains (not to mention the higher Turbo clock) over CFL which showed big gains over the old SKL/KBL again within the same (rated) TDP. Intel never had any problem with SIMD code (AVX/AVX2/FMA3) beating Ryzen2 by a large margin (now over 2x faster) but now also wins pretty much all tests.
It is consistently 33-40% faster than CFL (8700K) in line with core/speed increases which bodes well for compute-heavy code; streaming performance can be lower due to increase core contention for bandwidth and here faster (though more expensive) memory would help.
No – it cannot beat its “older big brother” SKL-X with AVX512 – not to mention increased core/thread count as well as memory channels, but in some tests it is competitive.
Software VM (.Net/Java) Performance
We are testing arithmetic and vectorised performance of software virtual machines (SVM), i.e. Java and .Net. With operating systems – like Windows 10 – favouring SVM applications over “legacy” native, the performance of .Net CLR (and Java JVM) has become far more important.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64 (1809), latest drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
Spectre / Meltdown Windows Mitigations: all were enabled as per default (BTI enabled, RDCL/KVA enabled, PCID enabled).
| VM Benchmarks | Intel i9-9900K CofeeLake-R | Intel i7-8700K CofeeLake | AMD Ryzen2 2700X Pinnacle Ridge | Intel i9-7900X SkyLake-X | Comments | |
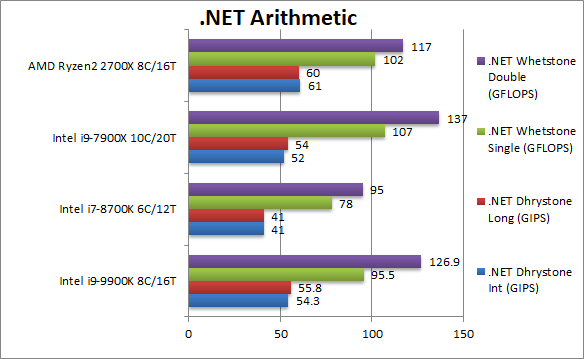 |
||||||
 |
.Net Dhrystone Integer (GIPS) | 54.3 [-11%] | 41 | 61 | 52 | .Net CLR integer performance starts off well but CFL-R is 10% slower. |
|
.Net Dhrystone Long (GIPS) | 55.8 [-7%] | 41 | 60 | 54 | With 64-bit integers the gap lowers to 7%. |
|
.Net Whetstone float/FP32 (GFLOPS) | 95.5 [-6%] | 78 | 102 | 107 | Floating-Point CLR performance does not change much, CFL-R is still 6% slower than Ryzen2 despite big gain over old CFL/KBL/SKL. |
|
.Net Whetstone double/FP64 (GFLOPS) | 126 [+8%] | 95 | 117 | 137 | FP64 performance allows CFL-R to win in the end. |
| Ryzen 2 performs exceedingly well in .Net workloads – but CFL-R can hold its own and overall it is not significantly slower (under 10%) and even wins 1 test out of 4. | ||||||
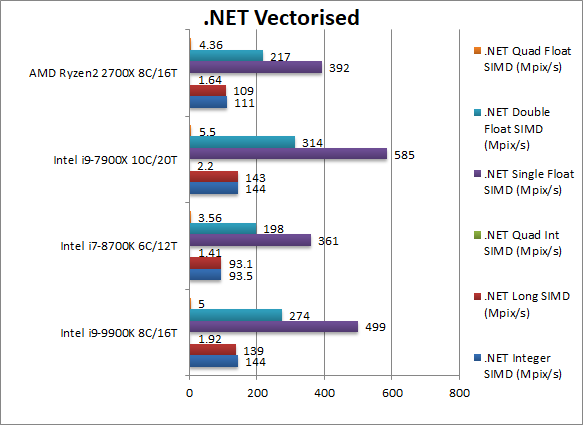 |
||||||
 |
.Net Integer Vectorised/Multi-Media (MPix/s) | 144 [+30%] | 93.5 | 111 | 144 | Unlike CFL, here CFL-R is 30% faster than Ryzen2. |
|
.Net Long Vectorised/Multi-Media (MPix/s) | 139 [+28%] | 93.1 | 109 | 143 | With 64-bit integer workload nothing much changes. |
|
.Net Float/FP32 Vectorised/Multi-Media (MPix/s) | 499 [+27%] | 361 | 392 | 585 | Here we make use of RyuJit’s support for SIMD vectors thus running AVX/FMA code and CFL-R is 27% faster than Ryzen2. |
|
.Net Double/FP64 Vectorised/Multi-Media (MPix/s) | 274 [+26%] | 198 | 217 | 314 | Switching to FP64 SIMD vector code – still running AVX/FMA – CFL-R is still faster. |
| We see a big improvement in CFL-R even against old CFL: this allows it to soundly beat Ryzen 2 (which used to win this test) by about 30%, a significant margin. It is possible the hardware fixes (“Meltdown”) are having an effect here. | ||||||
 |
||||||
 |
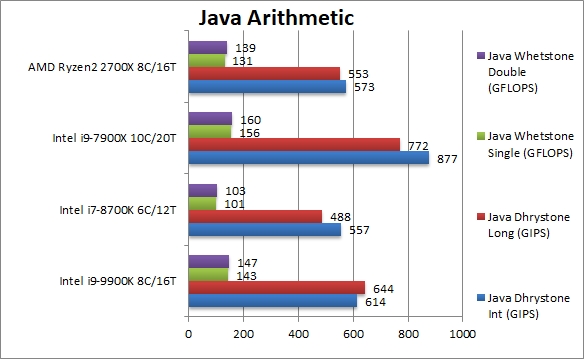
Java Dhrystone Integer (GIPS) | 614 [+7%] | 557 | 573 | 877 | Java JVM performance starts well with a 7% lead over Ryzen2. |
|
Java Dhrystone Long (GIPS) | 644 [+16%] | 488 | 553 | 772 | With 64-bit integers, CFL-R doubles its lead to 16%. |
|
Java Whetstone float/FP32 (GFLOPS) | 143 [+9%] | 101 | 131 | 156 | Floating-point JVM performance is similar – 9% faster. |
|
Java Whetstone double/FP64 (GFLOPS) | 147 [+6%] | 103 | 139 | 160 | With 64-bit precision the lead drops to 6%. |
| While CFL-R improves by a good amount over CFL (which itself improved greatly over KBL/SKL) and now beats Ryzen2 by a good margin 7-16%. | ||||||
 |
||||||
 |
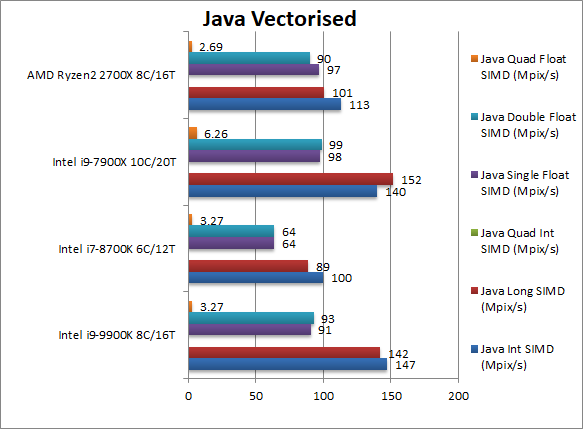
Java Integer Vectorised/Multi-Media (MPix/s) | 147 [+30%] | 100 | 113 | 140 | Without SIMD acceleration we still see CFL-R 30% than Ryzen2 in this integer workload. |
|
Java Long Vectorised/Multi-Media (MPix/s) | 142 [+41%] | 89 | 101 | 152 | Changing to 64-bit integer increases the lead to 41%. |
|
Java Float/FP32 Vectorised/Multi-Media (MPix/s) | 91 [-6%] | 64 | 97 | 98 | With floating-point non-SIMD accelerated Ryzen2 is faster. |
|
Java Double/FP64 Vectorised/Multi-Media (MPix/s) | 93 [+3%] | 64 | 90 | 99 | With 64-bit floatint-point precision CFL-R is back on top by just 3%. |
| With compute heavy vectorised code but not SIMD accelerated, CFL-R is still faster or at least ties with Ryzen2. | ||||||
CFL-R now beats or at least matches Ryzen2 in VM tests the latter used to easily win. It may not have the lead native SIMD vectorised code allows it – but has no trouble keeping up – unlike its older SKL/KBL “brothers”.
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
While Intel had finally increased core counts with CFL (after many years) in light of new competition from AMD with Ryzen/2 – it still relied on fewer but more powerful (at least in SIMD) cores to compete. CFL-R finally brings core (8 vs 8) and thread (16 vs 16) parity with the competition to ensure domination.
And with few exceptions – that’s what it has achieved – 9900K is the fastest desktop CPU at this time (November 2018) and if you can afford it you can upgrade on the same, old, 200-series mainboards (though naturally 300-series is recommended). The performance improvement (33-40% over 8700K) is pretty significant to upgrade – again if you can afford it – considering it is a “mere refresh”.
The “Meltdown” fixes in hardware are also likely to bring big improvement in I/O workloads – or to be precise – restore the performance loss of OS mitigations (KVA) that have been deployed this year (2018). Still, in very rough terms, now you don’t have to decide between “speed” and “security” – though perhaps KVA should be used by default just in case any CPU (not just Intel) leaks information between user/kernel spaces by a yet undiscovered side-channel vulnerability.
But despite the “i9” moniker – don’t think you’re getting a workstation-class CPU on the cheap: SKL-X not only (still) has more cores/threads and 2x memory channels but also supports AVX512 beating it soundly. It will also be refreshed soon – sporting the same “Meltdown” in-hardware fixes. But again considering the costs (almost 2x) CFL-R is likely the performance/price winner on most workloads.
For now, on the desktop, the 9900K is “king of the hill”!