What is “ZEN2”?
AMD’s Zen2 (“Matisse”) is the “true” 2nd generation ZEN core on 7nm process shrink while the previous ZEN+ (“Pinnacle Ridge”) core was just an optimisation of the original ZEN (“Summit Ridge”) core. While socket compatible it introduces many design improvements over both previous cores. An APU version (with integrated “Navi” graphics) is scheduled to be launched later.
While new chipsets (AMD 500 series) will also be introduced and required to support some new features (PCIe 4.0), with an BIOS/firmware update older boards may support them thus allowing upgrades to existing systems adding more cores and thus performance. [Note: older boards will not be enabled for PCIe 4.0 after all]
The list of changes vs. previous ZEN/ZEN+ is extensive thus performance delta is likely to be very different also:
- Built around “chiplets” of up to 2 CCX (“core complexes”) each of 4C/8T and 8MB L3 cache (7nm)
- Central I/O hub with memory controller(s) and PCIe 4.0 bridges connected through IF (“Infinity Fabric”) (12nm)
- Up to 2 chiplets on desktop platform thus up to 2x2x4C (16C/32T 3950X) (same amount as old ThreadRipper 1950X/2950X)
- 2x larger L3 cache per CCX thus up to 2x2x16MB (64MB) L3 cache (3900X+)
- 20 PCIe 4.0 lanes (2x higher transfer rate over PCIe 3.0)
- 2x DDR4 memory controllers up to 3200Mt/s official (4266Mt/s max)

What’s new in the Zen2 core?
Micro-architecturally there are more changes that should improve performance:
- 256-bit (single-op) SIMD units 2x FMA (fixing a major deficiency in ZEN/ZEN+ cores)
- TLB (2nd level) increased (should help out-of-page access latencies that are somewhat high on ZEN/ZEN+)
- Memory latencies claim to be reduced through higher-speed memory (note all requests go through IF to Central I/O hub with memory controllers)
- Load/Store 32bytes/cycle (2x ZEN/ZEN+) to keep up with the 256-bit SIMD units (L1D bandwidth should be 2x)
- L3 cache is 2x ZEN/ZEN+ (so 16MB) but higher latency (cache is exclusive)
- Infinity Fabric is 512-bit (2x ZEN/ZEN+) and can run 1x or 1/2x vs. DRAM clock (when higher than 3733Mt/s)
- AMD processors have thankfully not been affected by most of the vulnerabilities bar two (BTI/”Spectre”, SSB/”Spectre v4″) that have now been addressed in hardware.
- HWM-P (hardware performance state management) transitions latencies reduced (ACPI/CPPCv2)
In this article we test CPU core performance; please see our other articles on:
- AMD Ryzen 7 5800X (Zen3) Review & Benchmarks – CPU 8-core/16-thread Performance
- AMD Ryzen 9 3900X (Zen2) Review & Benchmarks – Cache and Memory Performance
- AMD Ryzen 7 3700X (Zen2) Review & Benchmarks – CPU 8-core/16-thread Performance
- AMD Ryzen Threadripper 3970X, 3960X Review & Benchmarks – CPU Performance
Hardware Specifications
We are comparing the top-of-the-range Ryzen2 (3900X, 3700X) with previous generation Ryzen+ (2700X) and competing architectures with a view to upgrading to a mid-range high performance design.
| CPU Specifications | AMD Ryzen 9 3900X (Matisse) |
AMD Ryzen 7 3700X (Matisse) | AMD Ryzen 7 2700X (Pinnacle Ridge) | Intel i9 9900K (Coffeelake-R) | Intel i9 7900X (Skylake-X) | Comments | |
| Cores (CU) / Threads (SP) | 12C / 24T | 8C / 16T | 8C / 16T | 8C / 16T | 10C / 20T | Matching core-count with CFL (3800X) but 3900X has 50% more cores – more than SKL-X. | |
| Topology | 2 chiplets, each 2 CCX, each 3 cores (1 disabled) (12C) | 1 chiplet, 2 CCX, each 4 cores (8C) | 2 CCX, each 4 cores (8C) | Monolithic die | Monolithic die | AMD uses discrete dies/chiplets unlike Intel | |
| Speed (Min / Max / Turbo) | 3.8 / 4.6GHz | 3.6 / 4.4GHz | 3.7 / 4.2GHz | 3.6 / 5GHz | 3.3 / 4.3GHz | Base clock and turbo are competitive with 3800X having higher base while 3900X higher turbo. | |
| Power (TDP / Turbo) | 105 / 135W | 65 / 90W | 105 / 135W | 95 / 135W | 140 / 308W | TDP remains the same but 3900X may exceed that having more cores. | |
| L1D / L1I Caches | 12x 32kB 8-way / 12x 32kB 8-way | 8x 32kB 8-way / 8x 32kB 8-way | 8x 32kB 8-way / 8x 64kB 4-way | 8x 32kB 8-way / 8x 32kB 8-way | 10x 32kB 8-way / 10x 32kB 8-way | ZEN2 matches L1I with CFL/SKL-X (1/2x ZEN+ but 8-way), L1D is unchanged (also matches Intel) | |
| L2 Caches | 12x 512kB (6MB) 8-way | 8x 512kB (4MB) 8-way | 8x 512kB (4MB) 8-way | 8x 256kB (2MB) 16-way | 10x 1MB (10MB) 16-way | No changes to L2, still 2x CFL. Only SKL-X has its massive 1MB L2 per core which 3900X almost matches! | |
| L3 Caches | 2x2x 16MB (64MB) 16-way | 2x 16MB (32MB) 16-way | 2x 8MB (16MB) 16-way | 16MB 16-way | 13.75MB 11-way | L3 is 2x ZEN/ZEN+ and thus 2x CFL (3800X) with 3900X having a massive 64MB unheard of on the desktop platform! SKL-X can’t match it either. | |
| Mitigations for Vulnerabilities | BTI/”Spectre”, SSB/”Spectre v4″ hardware | BTI/”Spectre”, SSB/”Spectre v4″ hardware | BTI/”Spectre”, SSB/”Spectre v4″ software/firmware | RDCL/”Meltdown”, L1TF hardware, BTI/”Spectre”, MDS/”Zombieload”, software/firmware | RDCL/”Meltdown” , L1TF, BTI/”Spectre”, MDS/”Zombieload”, all software/firmware | Ryzen2 addresses the remaining 2 vulnerabilities while Intel was forced to add MDS to its long list… | |
| Microcode | MU-8F7100-11 | MU-8F7100-11 | MU-8F0802-04 | MU-069E0C-9E | MU-065504-49 | The latest microcodes included in the respective BIOS/Windows have been loaded. | |
| SIMD Units | 256-bit AVX/FMA3/AVX2 | 256-bit AVX/FMA3/AVX2 | 128bit AVX/FMA3/AVX2 | 256-bit AVX/FMA3/AVX2 | 512-bit AVX512 | ZEN2 finally matches Intel/CFL but SKL-X’s secret weapon is AVX512 with even consumer CPUs able to do 2x 512-bit FMA ops. | |
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (AVX2, FMA3, AVX, etc.). Ryzen2 supports all modern instruction sets including AVX2, FMA3 and even more like SHA HWA but not AVX-512.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations. All mitigations for vulnerabilities (Meltdown, Spectre, L1TF, MDS, etc.) were enabled as per Windows default where applicable.
| Native Benchmarks | AMD Ryzen 9 3900X (Matisse) |
AMD Ryzen 7 2700X (Pinnacle Ridge) |
Intel i9 9900K (Coffeelake-R) |
Intel i9 7900X (Skylake-X) |
Comments | |
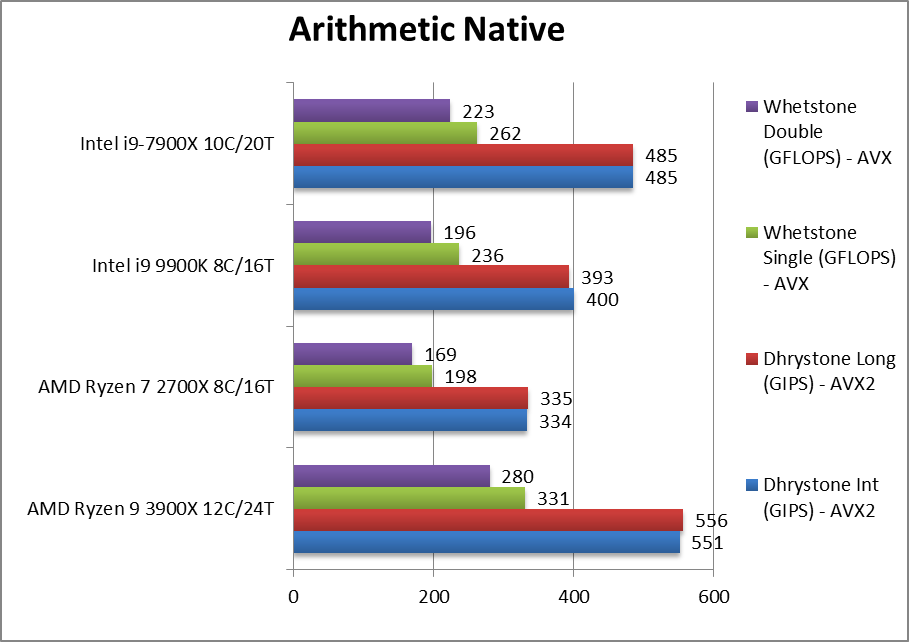 |
||||||
 |
Native Dhrystone Integer (GIPS) | 551 [+38%] | 334 | 400 | 485 | Right off Ryzen2 demolishes all CPUs, it is 40% faster than CFL-R! |
|
Native Dhrystone Long (GIPS) | 556 [+41%] | 335 | 393 | 485 | With a 64-bit integer workload nothing much changes. |
|
Native FP32 (Float) Whetstone (GFLOPS) | 331 [+40%] | 198 | 236 | 262 | Floating-point performance does not change delta either – still 40% faster! |
|
Native FP64 (Double) Whetstone (GFLOPS) | 280 [+43%] | 169 | 196 | 223 | With FP64 nothing much changes again. |
| Ryzen2 starts with an astonishing display, with 3900X demolishing both 9900X and 7900X winning all tests by a large margin 38-43%! It does have 50% more cores (12 vs. 8) but it is not easy to realise gains just by increasing core counts. Intel will need to add far more cores in future CPUs in order to compete! | ||||||
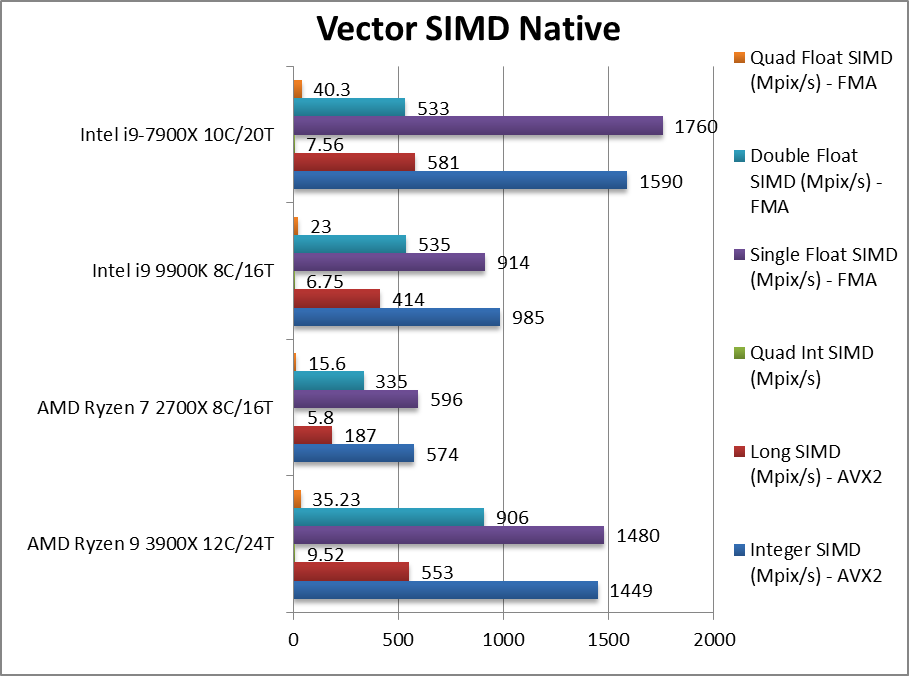 |
||||||
 |
Native Integer (Int32) Multi-Media (Mpix/s) | 1449 [+47%] | 574 | 985 | 1590 | Ryzen2 starts off by blowing CFL-R away by 47% and almost matching SKL-X with AVX512! |
|
Native Long (Int64) Multi-Media (Mpix/s) | 553 [+34%] | 187 | 414 | 581 | With a 64-bit AVX2 integer vectorised workload, Ryzen2 is still 34% faster! |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 9.52 [+41%] | 5.8 | 6.75 | 7.56 | This is a tough test using Long integers to emulate Int128 without SIMD; here Ryzen2 is again 41% faster! |
|
Native Float/FP32 Multi-Media (Mpix/s) | 1480 [+62%] | 596 | 914 | 1760 | In this floating-point AVX/FMA vectorised test, Ryzen2 is now over 60% faster than CFL-R and not far off SKL-X! |
|
Native Double/FP64 Multi-Media (Mpix/s) | 906 [+69%] | 335 | 535 | 533 | Switching to FP64 SIMD code, Ryzen2 is now 70% faster even beating SKL-X!!! |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 35.23 [+53%] | 15.6 | 23 | 40.3 | In this heavy algorithm using FP64 to mantissa extend FP128, Ryzen2 is still 53% faster! |
| With its brand-new 256-bit SIMD units, Ryzen2 finally goes toe-to-toe with Intel, soundly beating CFL-R in all benchmarks (+34-69%) sometimes by more than just core count increase (+50%). Only SKL-X with AVX512 manages to be faster (but also with its extra 2 cores). Intel had better release AVX512 for desktop soon but even that will not be enough without increasing core counts to match AMD. | ||||||
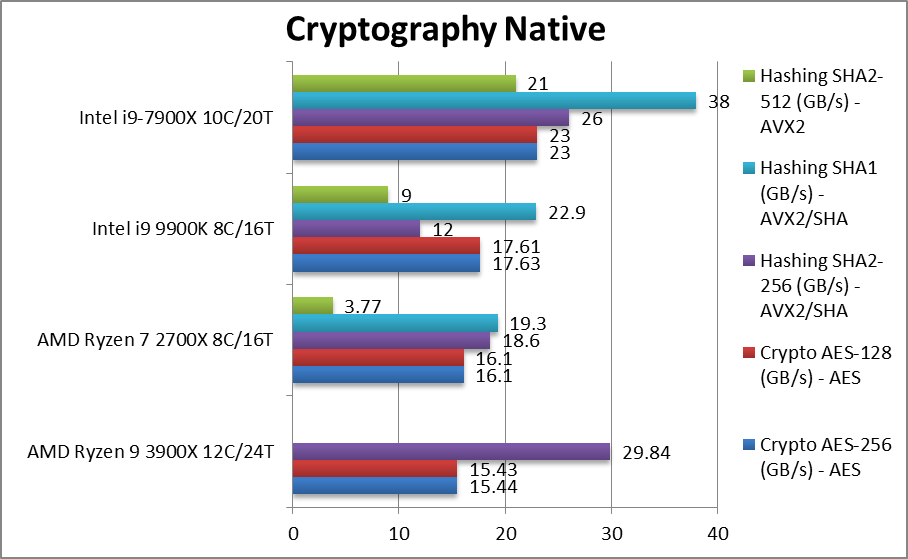 |
||||||
 |
Crypto AES-256 (GB/s) | 15.44 [-12%] | 16.1 | 17.63 | 23 | With AES/HWA support all CPUs are memory bandwidth bound – thus Ryzen2 scores less than Ryzen+ and CFL-R. |
|
Crypto AES-128 (GB/s) | 15.44 [-12%] | 16.1 | 17.61 | 23 | What we saw with AES-256 just repeats with AES-128; Ryzen2 is again slower by 12%. |
|
Crypto SHA2-256 (GB/s) | 29.84 [+2.5x] | 18.6 | 12 | 26 | With SHA/HWA Ryzen2 similarly powers through hashing tests leaving Intel in the dust – 2.5x faster than CFL-R and beating SKL-X with AVX512! |
|
Crypto SHA1 (GB/s) | 19.3 | 22.9 | 38 | – | |
|
Crypto SHA2-512 (GB/s) | 3.77 | 9 | 21 | – | |
| Ryzen2 with AES/SHA HWA is memory bound thus needs faster memory than 3200Mt/s in order to feed all the cores; otherwise due to increased contention for the same bandwidth it may end up slower than Ryzen+ and Intel designs. Here you see the need for HEDT platforms and thus ThreadRipper but at much increased cost. | ||||||
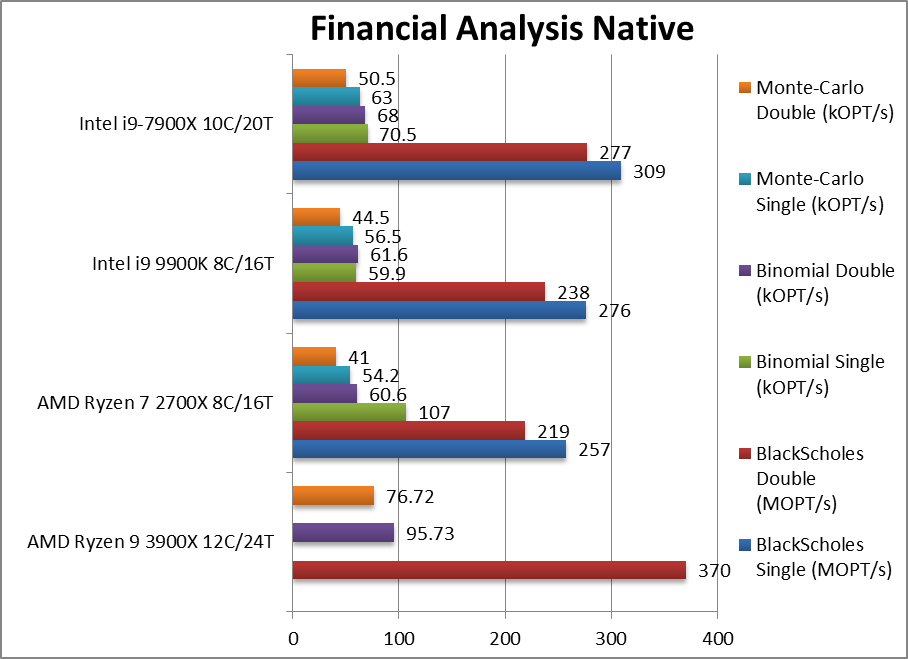 |
||||||
 |
Black-Scholes float/FP32 (MOPT/s) | 257 | 276 | 309 | – | |
|
Black-Scholes double/FP64 (MOPT/s) | 379 [+55%] | 219 | 238 | 277 | Switching to FP64 code, nothing much changes, Ryzen2 55% faster than CFL-R. |
|
Binomial float/FP32 (kOPT/s) | 107 | 59.9 | 70.5 | Binomial uses thread shared data thus stresses the cache & memory system; | |
|
Binomial double/FP64 (kOPT/s) | 95.73 [+55%] | 60.6 | 61.6 | 68 | With FP64 code Ryzen2 is still 55% faster! |
|
Monte-Carlo float/FP32 (kOPT/s) | 54.2 | 56.5 | 63 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches; | |
|
Monte-Carlo double/FP64 (kOPT/s) | 76.72 [+72%] | 41 | 44.5 | 50.5 | Switching to FP64 nothing much changes, Ryzen2 is 70% faster than CFL-R and still beating SKL-X. |
| Ryzen always did well on non-SIMD floating-point algorithms and here it does not disappoint: Ryzen2 is over 50% faster than CFL-R (+55-72%) and soundly beats SKL-X too! As before for financial algorithms there is only one choice and that is Ryzen, be it Ryzen1, Ryzen+ or Ryzen2! | ||||||
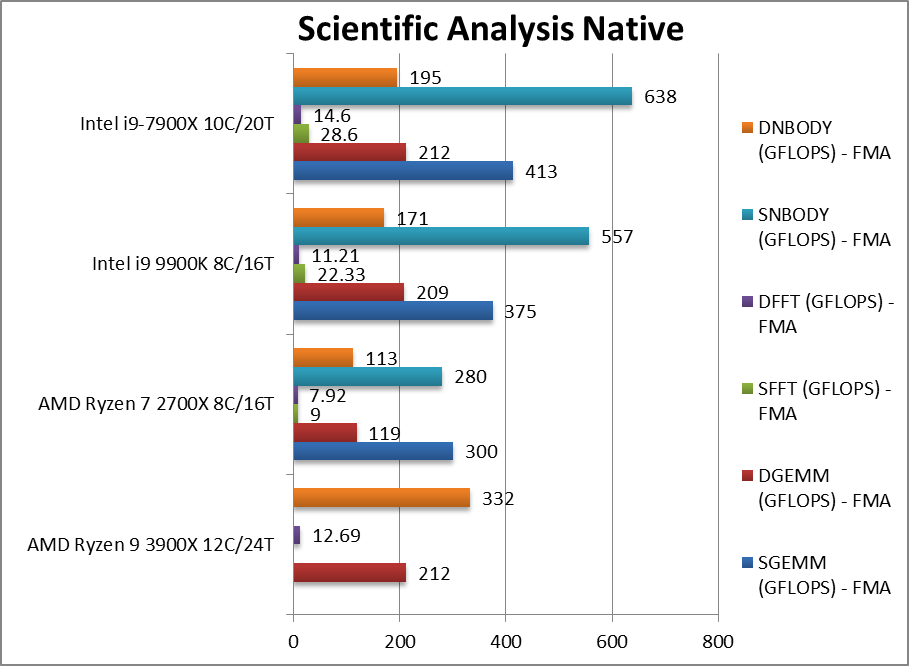 |
||||||
 |
SGEMM (GFLOPS) float/FP32 | 300 | 375 | 413 | In this tough vectorised algorithm Ryzen2. | |
|
DGEMM (GFLOPS) double/FP64 | 212 [+1%] | 119 | 209 | 212 | With FP64 vectorised code, Ryzen2 matches CFL-R and SKL-X. |
|
SFFT (GFLOPS) float/FP32 | 9 | 22.33 | 28.6 | FFT is also heavily vectorised but stresses the memory sub-system more; | |
|
DFFT (GFLOPS) double/FP64 | 12.69 [+13%] | 7.92 | 11.21 | 14.6 | With FP64 code, Ryzen2 is 13% faster than CFL-R. |
|
SNBODY (GFLOPS) float/FP32 | 280 | 557 | 638 | N-Body simulation is vectorised but fewer memory accesses; | |
|
DNBODY (GFLOPS) double/FP64 | 332 [+94%] | 113 | 171 | 195 | With FP64 precision Ryzen2 is almost 2x faster than CFL-R. |
| With highly vectorised SIMD code Ryzen2 remains competitive but finds some algorithms tougher than others. The new 256-bit SIMD units help but it seems the cores are starved of bandwidth (especially due to SMT) and some workloads may perform better with SMT off. | ||||||
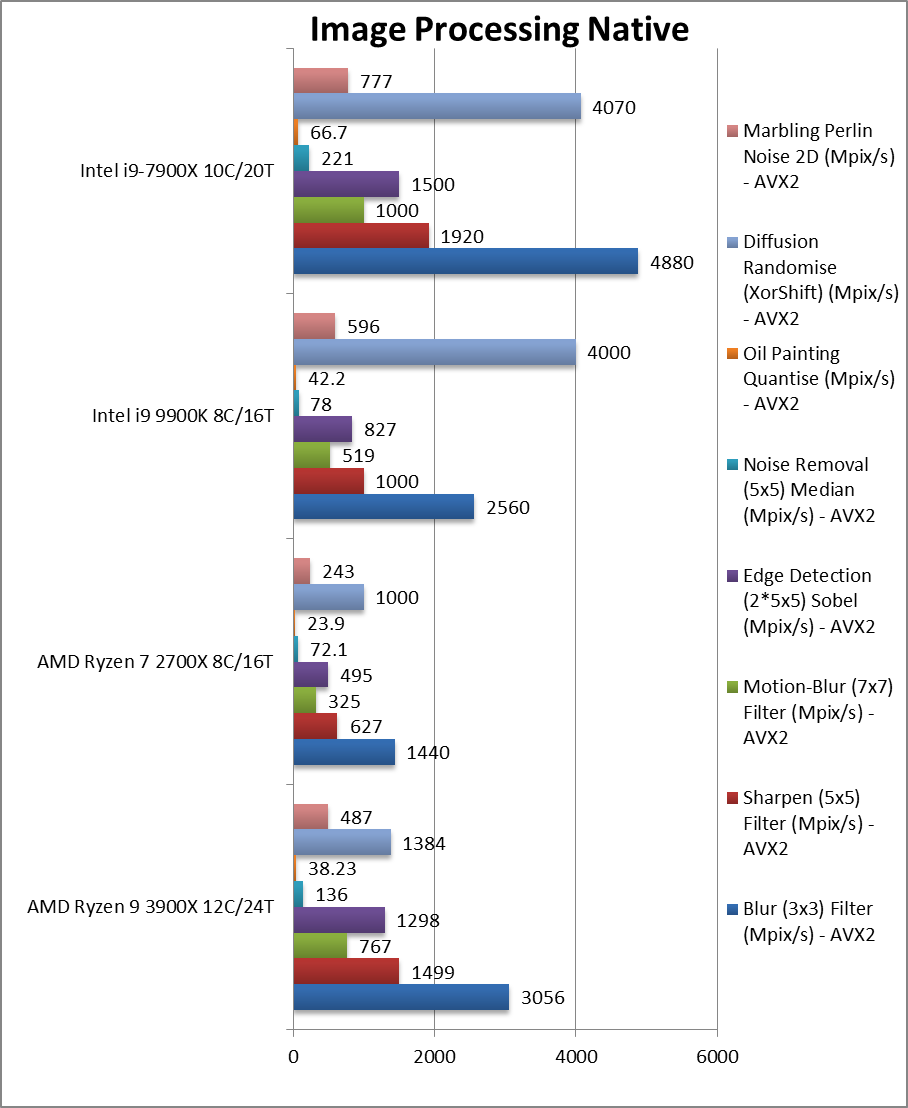 |
||||||
 |
Blur (3×3) Filter (MPix/s) | 3056 [+20%] | 1440 | 2560 | 4880 | In this vectorised integer workload Ryzen2 is 20% faster than CFL-R. |
|
Sharpen (5×5) Filter (MPix/s) | 1499 [+50%] | 627 | 1000 | 1920 | Same algorithm but more shared data makes Ryzen2 50% faster! |
|
Motion-Blur (7×7) Filter (MPix/s) | 767 [+48%] | 325 | 519 | 1000 | Again same algorithm but even more data shared still 50% faster |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 1298 [+57%] | 495 | 827 | 1500 | Different algorithm but still vectorised workload Ryzen2 is almost 60% faster. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 136 [+74%] | 72.1 | 78 | 221 | Still vectorised code now Ryzen2 is 70% faster. |
|
Oil Painting Quantise Filter (MPix/s) | 38.23 [-9%] | 23.9 | 42.2 | 66.7 | This test has always been tough for Ryzen but Ryzen2 is competitive. |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 1384 [-65%] | 1000 | 4000 | 4070 | With integer workload, Intel CPUs seem to do much better. |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 487 [-18%] | 243 | 596 | 777 | In this final test again with integer workload Ryzen2 is 20% slower. |
| Thanks to AVX512 SKL-X does win all tests but Ryzen2 beats CFL-R between 20-74% with a few test mixing integer & floating-point SIMD instructions seemingly heavily favouring Intel but nothing to worry about. Overall for image processing Ryzen2 should be your 1st choice. | ||||||
 |
||||||
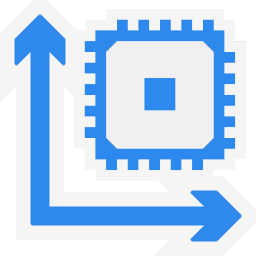 |
Aggregate Score (Points) | 10,250 [+29%] | 5,850 | 7,930 | 11,810 | Across all benchmarks, Ryzen2 is ~30% faster than CFL-R! |
| Aggregating all the various scores, the result was never in doubt: Ryzen2 (3900X) is almost 2x faster than Ryzen+ (2700X) and 30% faster than CFL-R, almost catching up HEDT SKL-X. | ||||||
Ryzen2 (unlike Ryzen1/+) has no trouble with SIMD code due to its widened SIMD units (256-bit) and thus soundly beats the opposition into dust (CFL-R 9900K flagship) sometimes more than just core count increase alone (+50% i.e. 12 cores vs. 8). Sometimes it even beats the AVX512 opposition (SKL-X 7900K) with more cores (10 cores vs. 12).
The only “problematic” algorithms are the memory bound ones where the cores/threads (due to SMT we have 24!) are starved for data and due to contention we see performance lower than less-core devices. While larger caches help (thus the massive 4x 16MB L3 caches) higher clocked memory should be used to match the additional core requirements.
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
Executive Summary: Ryzen2 is phenomenal and a huge upgrade over Ryzen1/+ that (most) AM4 users can enjoy and Intel has no answer to. 10/10.
Just as original Ryzen forced Intel to increase (double really) core counts to match (from 4 to 6 then 8), Ryzen2 will force Intel to come up with even more (and better) cores in order to compete. 3900X with its 12-cores soundly beats CFL-R 9900K (8-cores) in just about all benchmarks and in some tests goes toe-to-toe with HEDT SKL-X AVX512-enabled (10-cores) except in memory-bound algorithms where the 4 DDR4 memory channels with 2x more bandwidth count. For that you need ThreadRipper!
Ryzen1/+ was already competitive with Intel on integer and floating-point (non-SIMD) workloads but would fare badly on SIMD (AVX/FMA3/AVX2) workloads due to its 128-bit units; Ryzen2 “fixes” this issue, with its 256-bit units matching Intel. Only SKL-X with its 512-bit units (AVX512) is faster and Intel will have to finally include AVX512 for consumer CPUs in order to compete (IceLake?).
For compute-bound workloads, the forthcoming 3950X with its 16-cores/32-threads brings unprecedented performance to the consumer/desktop segment pretty much unheard of just a few years ago when 4-core/8-threads (e.g. 7700K) were all you could hope for – unless paying a lot more for HEDT where 8/10-core CPUs were far far more expensive. Naturally we shall see how the reduced memory bandwidth affects its performance with likely very fast DDR4 memory (4300Mt/s+) required for best performance.
Let’s also remember than Ryzen2 adds hardware mitigation to its remaining 2 vulnerabilities while Intel has been forced to add MDS/”Zombieload” even to its very latest CFL-R that now loses its trump card: hardware RDCL/”Meltdown” fix not to forget the recommendation to disable SMT/Hyperthreading that would mean a sizeable performance drop.
What is astonishing is that TDP has remained similar and with a BIOS/firmware upgrade, owners of older 300-series boards can now upgrade to these CPUs – and likely not even change the cooler unit! Naturally for PCIe4.0 a 500-series board is recommended and 400-series boards do support more features in Ryzen2/+ but let’s remember than on Intel you can only go back/forward 1 generation even though there is pretty much no core difference from Skylake (Gen 6) to Coffeelake-R (Gen 9)!
From top-end (3950X), high-end (3800X) to low-end/APU (3200G) Ryzen2 is such a compelling choice it is hard to recommend anything else… at least at this time…