What is “Vega2”?
It is the code-name of the updated “Vega” GPU arch(itecture), the last of the GCN (graphics core next) arch (version 5.1) shrinked to 7nm before being replaced by the forthcoming “Navi”. Originally for the professional/workstation high-end market, “Vega2″/”big Vega” designed for compute (scientific, machine learning, etc.) workloads was pressed into service to battle the latest 2000-series “Turing”/RTX competition.
As a result it contains many high-end features not normally found on consumer cards:
- 1/4 FP64 rate (instead of 1/16 or worse)
- 16GB HBM2 memory (instead of 8-12)
- 4096-bit HBM2 memory 1TB/s bandwidth (instead of 400-500)
- Int8/Int4 support for AI/ML workloads
- PCIe 4.0 capable but not enabled at this time
See these other articles on GPGPU performance:
- AMD Radeon 5700XT: Navi GPGPU performance in OpenCL
- nVidia Titan V : Volta GPGPU performance in CUDA & OpenCL
- nVidia Titan X: Pascal GPGPU performance in CUDA & OpenCL
Hardware Specifications
We are comparing the middle-range Radeon with previous generation cards and competing architectures with a view to upgrading to a mid-range high performance design.
| GPGPU Specifications | AMD Radeon VII (Vega2) | nVidia Titan V (Volta) | nVidia Titan X (Pascal) | AMD Vega 56 (Vega1) | Comments | |
| Arch Chipset | Vega 20 / GCN 5.1 | GV100 / 7.0 | GP102 / 6.1 | Vega 10 / GCN 5.0 | A minor revision of Vega1. | |
| Cores (CU) / Threads (SP) | 60 / 3840 | 80 / 5120 | 28 / 3584 | 56 / 3584 | More CUs than normal Vega but not 64. | |
| SIMD per CU / Width | 4 / 16 | n/a | n/a | 4 / 16 | Naturally same SIMD count and width | |
| Wave/Warp Size | 64 | 32 | 32 | 75 | Wave size has always been 2x nVidia. | |
| Speed (Min-Turbo) | 1.4 – 1.750 [+21%] | (135-1455) | 1.531 (139-1910) | 1.156 – 1.471 | Base clock is ~20% higher and turbo | |
| Power (TDP) | 300W [+42%] | 300W | 250W | 210W | TDP has gone up by 40%. | |
| ROP / TMU | 64 / 256 | 96 / 320 | 96 / 224 | 64 / | ROPs and TMUs unchanged | |
| Shared Memory |
32kB | 48 / 96 kB | 48 / 96kB | 32kB | No shared memory change. | |
| Constant Memory |
8GB | 64kB | 64kB | 4GB | No dedicated constant memory but large. | |
| Global Memory | 16GB HBM2 2Gbps 4096-bit | 12GB HBM2 2x850Mbps 3072-bit | 12GB GDDR5X 10Gbps 384-bit | 8GB HBM2 1.89Gbps 2048-bit | 2x as big and 2x as wide HBM a huge improvement. | |
| Memory Bandwidth (GB/s) |
1000 [+2.4x] | 652 | 512 | 410 | Still bandwidth is 9% higher. | |
| L1 Caches | 16kB x 60 | 96kB x 80 | 48kB x 28 | 16kB x 56 | L1 has not changed. | |
| L2 Cache | 4MB | 4.5MB | 3MB | 4MB | L2 has not changed. | |
| Maximum Work-group Size |
256 / 1024 | 1024 / 2048 | 1024 / 2048 | 256 / 1024 | Same work-group sizes. | |
| FP64/double ratio |
1/4x | 1/2x | 1/32x | 1/16x | Ratio is 4x better than Vega1. | |
| FP16/half ratio |
2x | 2x | 1/64x | 2x | Ratio is the same throughout. | |
Disclaimer
This is an independent article that has not been endorsed or sponsored by any entity (e.g AMD). All trademarks acknowledged and used for indentification only under fair use.
The article contains only public information available elsewhere on the Internet and not provided under NDA or embargoed. At publication time, the products have not been directly testied by SiSoftware and thus the accuracy of the benchmark scores cannot be verified; however, they appear consistent and do not appear to be false/fake.
Processing Performance
We are testing both OpenCL performance using the latest SDK / libraries / drivers from both AMD and competition.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and nVidia drivers. Turbo / Boost was enabled on all configurations.
| Processing Benchmarks | AMD Radeon VII (Vega2) | nVidia Titan V (Volta) | nVidia Titan X (Pascal) | AMD Vega 56 (Vega1) | Comments | |
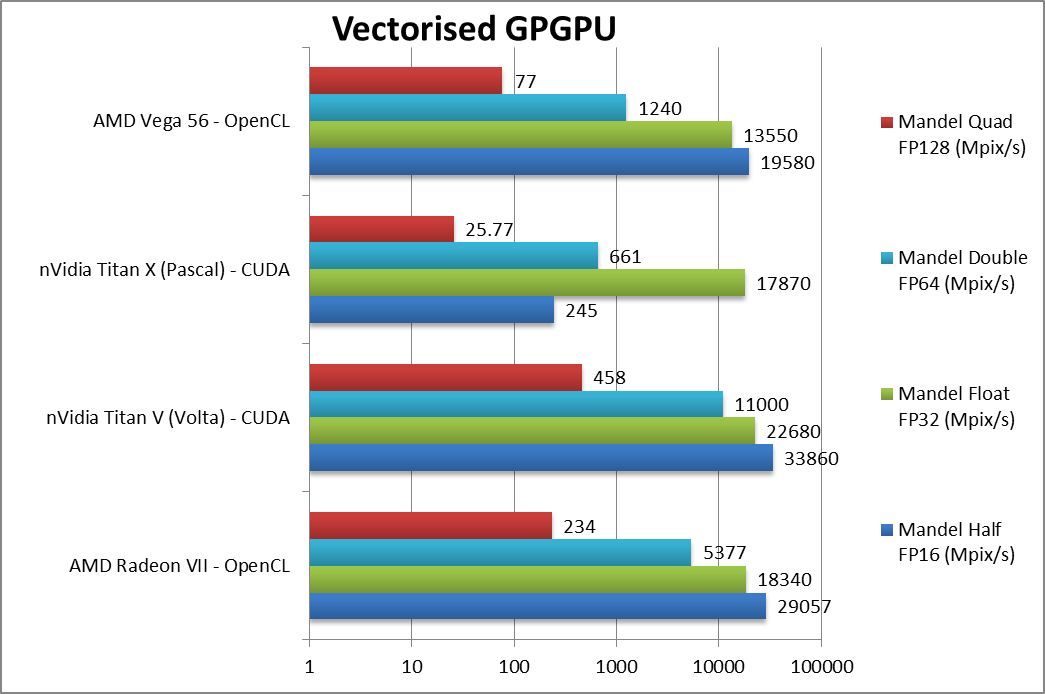 |
||||||
 |
Mandel FP16/Half (Mpix/s) | 29,057 [+48%] | 33,860 | 245 | 19,580 | Vega2 starts strong with a 48% lead over Vega1 and almost catching Volta. |
|
Mandel FP32/Single (Mpix/s) | 18,340 [+35%] | 22,680 | 17,870 | 13,550 | Good improvement here +35% over Vega1 again close to Volta. |
|
Mandel FP64/Double (Mpix/s) | 5,377 [+4.3x] | 11,000 | 661 | 1,240 | 1/4 FP64 rate makes it over four (4x) times faster than Vega1. |
|
Mandel FP128/Quad (Mpix/s) | 234 [+3x] | 458 | 25.77 | 77 | Similar to above, Vega2 is over three (3x) faster. |
| Vega2 looks about 35-50% faster than Vega1 in FP32/FP16 and 3-4x faster in FP64 due to its 1/4 FP64 rate. It won’t beat real workstation cards with 1/2 FP64 rate through thus that Titan has nothing to worry about. | ||||||
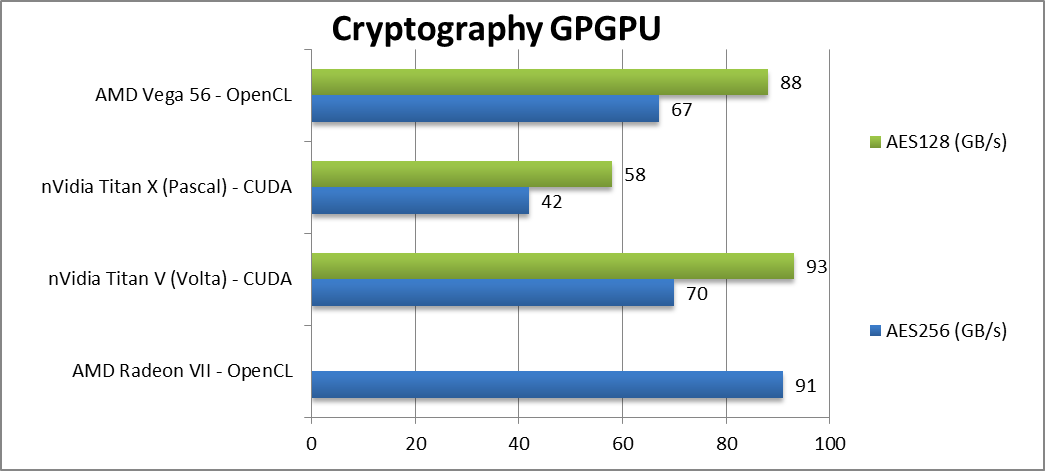 |
||||||
 |
Crypto AES-256 (GB/s) | 91 [+36%] | 70 | 42 | 67 | The fast HBM2 memory allows it to beat even Volta not just Vega1. |
|
Crypto AES-128 (GB/s) | 93 | 58 | 88 | – | |
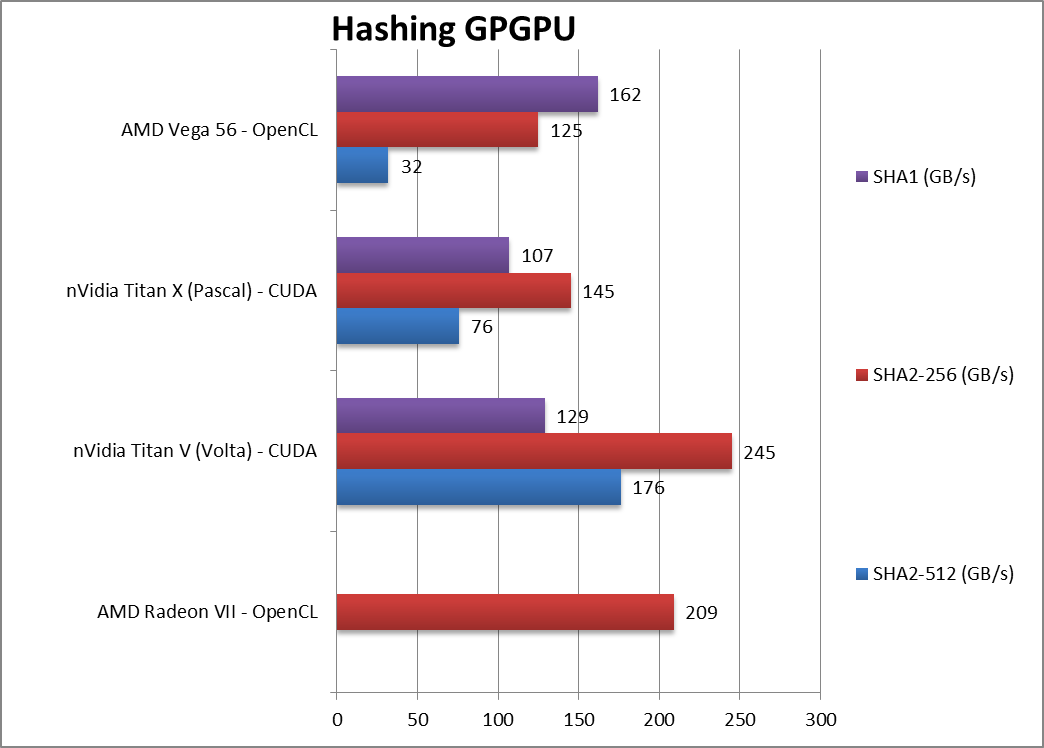 |
||||||
|
Crypto SHA2-256 (GB/s) | 209 [+67%] | 245 | 145 | 125 | Vega2 is a huge 70% faster in integer/crypto workloads. |
|
Crypto SHA1 (GB/s) | 129 | 107 | 162 | – | |
|
Crypto SHA2-512 (GB/s) | 176 | 76 | 32 | – | |
| Vega2 increases its lead in integer workloads even streaming ones no doubt due to its very fast HBM2 memory making it the crypto-king of the hill though its cost may be an issue. | ||||||
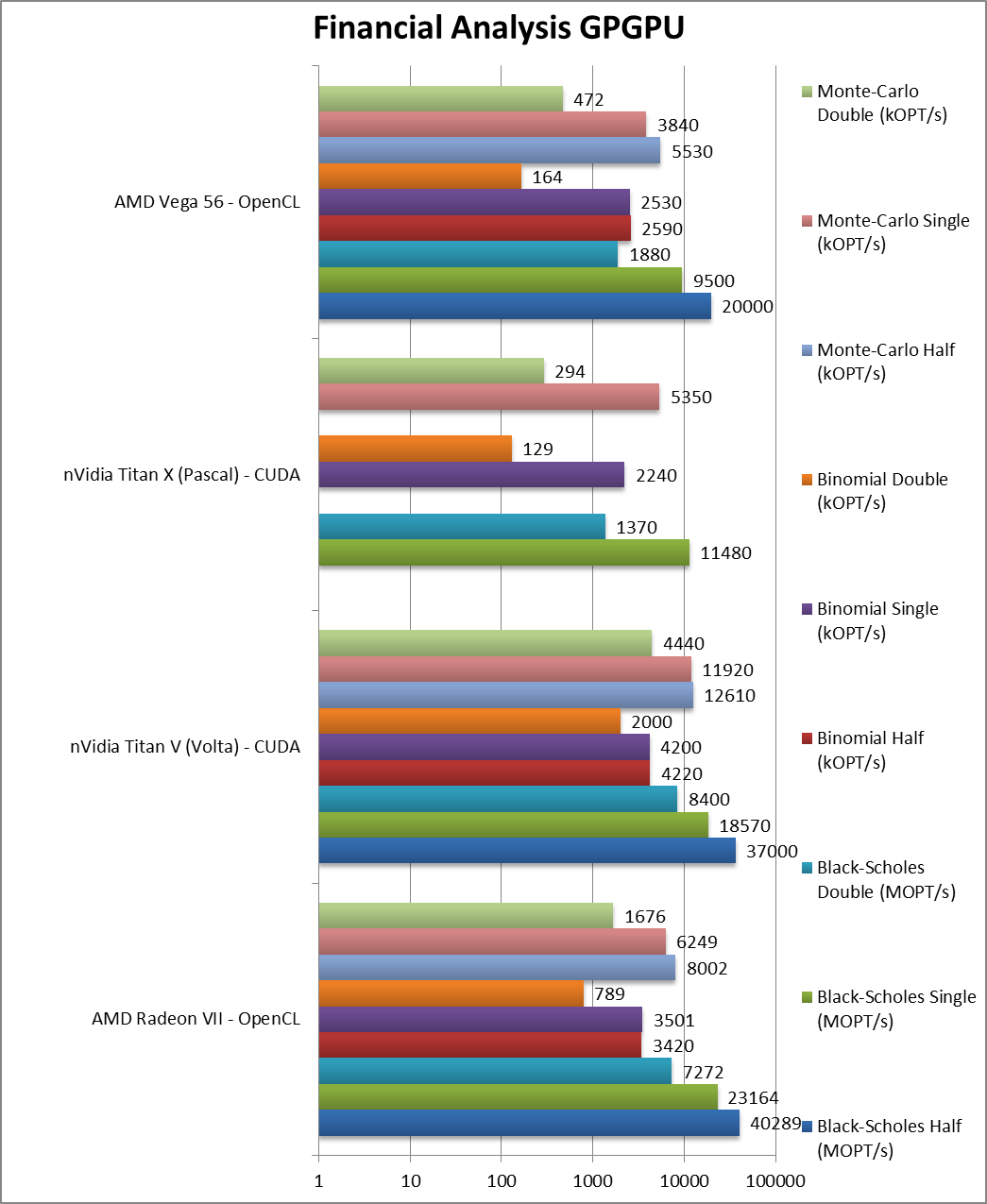 |
||||||
 |
Black-Scholes float/FP32 (MOPT/s) | 23,164 [+2.3x] | 18,570 | 11,480 | 9,500 | Vega2 is over 2x faster than Vega1 also beating Volta. |
|
Black-Scholes double/FP64 (MOPT/s) | 7,272 [+3.84x] | 8,400 | 1,370 | 1,880 | In FP64 its almost 4x faster just below Volta! |
|
Binomial float/FP32 (kOPT/s) | 3,501 [+38%] | 4,200 | 2,240 | 2,530 | Binomial uses thread shared data thus stresses the memory system Vega2 is still 40% faster. |
|
Binomial double/FP64 (kOPT/s) | 789 [+4.8x] | 2,000 | 129 | 164 | With FP64 we’re almost 5x faster than Vega1. |
|
Monte-Carlo float/FP32 (kOPT/s) | 6,249 [+62%] | 11,920 | 5,350 | 3,840 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure – here Vega2 is 60% faster. |
|
Monte-Carlo double/FP64 (kOPT/s) | 1,676 [+3.55x] | 4,440 | 294 | 472 | With FP64 we’re over 3.5x faster. |
| For financial FP32 workloads, Vega2 is 40-60% faster than Vega1 a decent improvement; naturally in FP64 it’s 4-5x times faster thus a significant upgrade for algorithms that require such precision. | ||||||
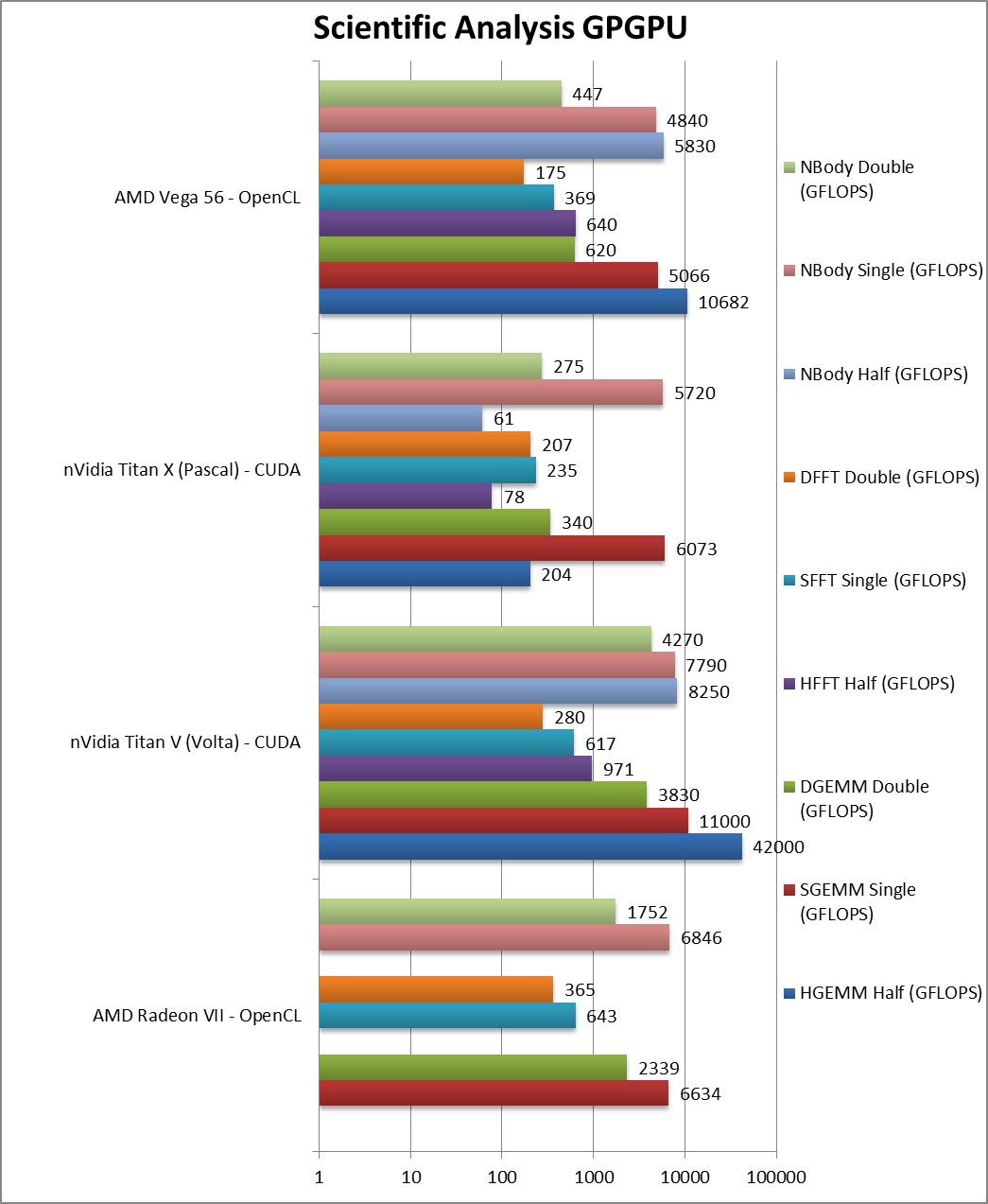 |
||||||
 |
SGEMM (GFLOPS) float/FP32 | 6,634 [+30%] | 11,000 | 6,073 | 5,066 | GEMM still brings a 30% improvement over Vega1. |
|
DGEMM (GFLOPS) double/FP64 | 2,339 [+3.77x] | 3,830 | 340 | 620 | But DGEMM is almost 4x faster. |
|
SFFT (GFLOPS) float/FP32 | 643 [+74%] | 617 | 235 | 369 | FFT loves HBM thus Vega2 is 75% faster. |
|
DFFT (GFLOPS) double/FP64 | 365 [+2.1x] | 280 | 207 | 175 | DFFT is tough but Vega2 is still twice as fast. |
|
SNBODY (GFLOPS) float/FP32 | 6,846 [+41%] | 7,790 | 5,720 | 4,840 | In N-Body physics Vega2 is 40% faster. |
|
DNBODY (GFLOPS) double/FP64 | 1,752 [+3.9x] | 4,270 | 275 | 447 | And in FP64 physics Vega2 is almost 4x faster. |
| The scientific scores show a similar improvement, with FP32 30-40% better but FP64 a whopping four (4x) faster than Vega1 and, in some algorithms, matching the hugely expensive Volta. | ||||||
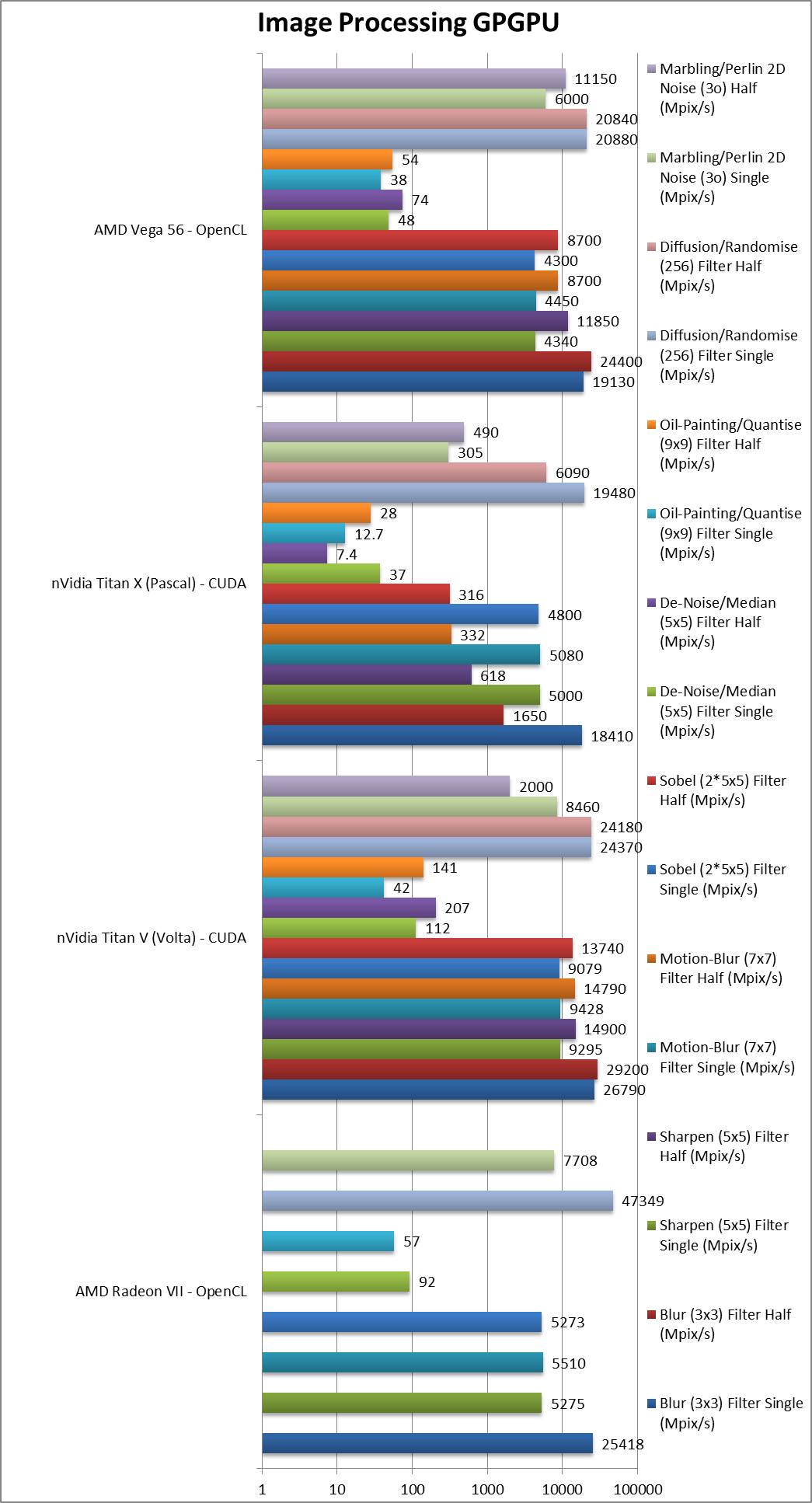 |
||||||
 |
Blur (3×3) Filter single/FP32 (MPix/s) | 25,418 [+32%] | 26,790 | 18,410 | 19,130 | In this 3×3 convolution algorithm, Vega2 is 32% faster than Vega1 |
|
Sharpen (5×5) Filter single/FP32 (MPix/s) | 5,275 [+21%] | 9,295 | 5,000 | 4,340 | Same algorithm but more shared data reduces the lead to 21%. |
|
Motion Blur (7×7) Filter single/FP32 (MPix/s) | 5,510 [+24%] | 9,428 | 5,080 | 4,450 | With even more data the gap remains constant. |
|
Edge Detection (2*5×5) Sobel Filter single/FP32 (MPix/s) | 5,273 [+23%] | 9,079 | 4,800 | 4,300 | Still convolution but with 2 filters – similar 23% faster. |
|
Noise Removal (5×5) Median Filter single/FP32 (MPix/s) | 92 [+91%] | 112 | 37 | 48 | Different algorithm makes Vega2 almost 2x faster than Vega1. |
|
Oil Painting Quantise Filter single/FP32 (MPix/s) | 57 [+50%] | 42 | 12.7 | 38 | Without major processing, this filter is 50% faster on Vega2. |
|
Diffusion Randomise (XorShift) Filter single/FP32 (MPix/s) | 47,349 [+2.3x] | 24,370 | 19,480 | 20,880 | This algorithm is 64-bit integer heavy and Vega2 flies 2x faster than Vega1. |
|
Marbling Perlin Noise 2D Filter single/FP32 (MPix/s) | 7,708 [+28%] | 8,460 | 305 | 6,000 | One of the most complex and largest filters, Vega2 is 28% faster. |
| For image processing using FP32 precision, Vega goes from 21% to 2x faster, overall a decent improvement if you are processing a large number of images. In many filters it beats the far more expensive Volta competition. | ||||||
Memory Performance
We are testing both OpenCL performance using the latest SDK / libraries / drivers from AMD and competition.
Results Interpretation: For bandwidth tests (MB/s, etc.) high values mean better performance, for latency tests (ns, etc.) low values mean better performance.
Environment: Windows 10 x64, latest AMD and nVidia. drivers. Turbo / Boost was enabled on all configurations.
| Memory Benchmarks | AMD Radeon VII (Vega2) | nVidia Titan V (Volta) | nVidia Titan X (Pascal) | AMD Vega 56 (Vega1) | Comments | |
 |
||||||
 |
Internal Memory Bandwidth (GB/s) | 627 [+88%] | 536 | 356 | 333 | Vega2’s wide HBM2 is almost 2x faster as expected. |
|
Upload Bandwidth (GB/s) | 12.37 [+2%] | 11.47 | 11.4 | 12.18 | Using PCIe 3.0 similar upload bandwidth. |
|
Download Bandwidth (GB/s) | 12.95 [+7%] | 12.27 | 12.2 | 12.08 | Again similar bandwidth. |
| Vega2 benefits greatly from its very wide HBM2 memory (4096-bit) which provides almost 2x real bandwidth as expected. But while PCIe 4.0 capable for now it has to make do with 3.0 and thus same upload/download bandwith. Here’s hoping for a BIOS update once new motherboards come out. | ||||||
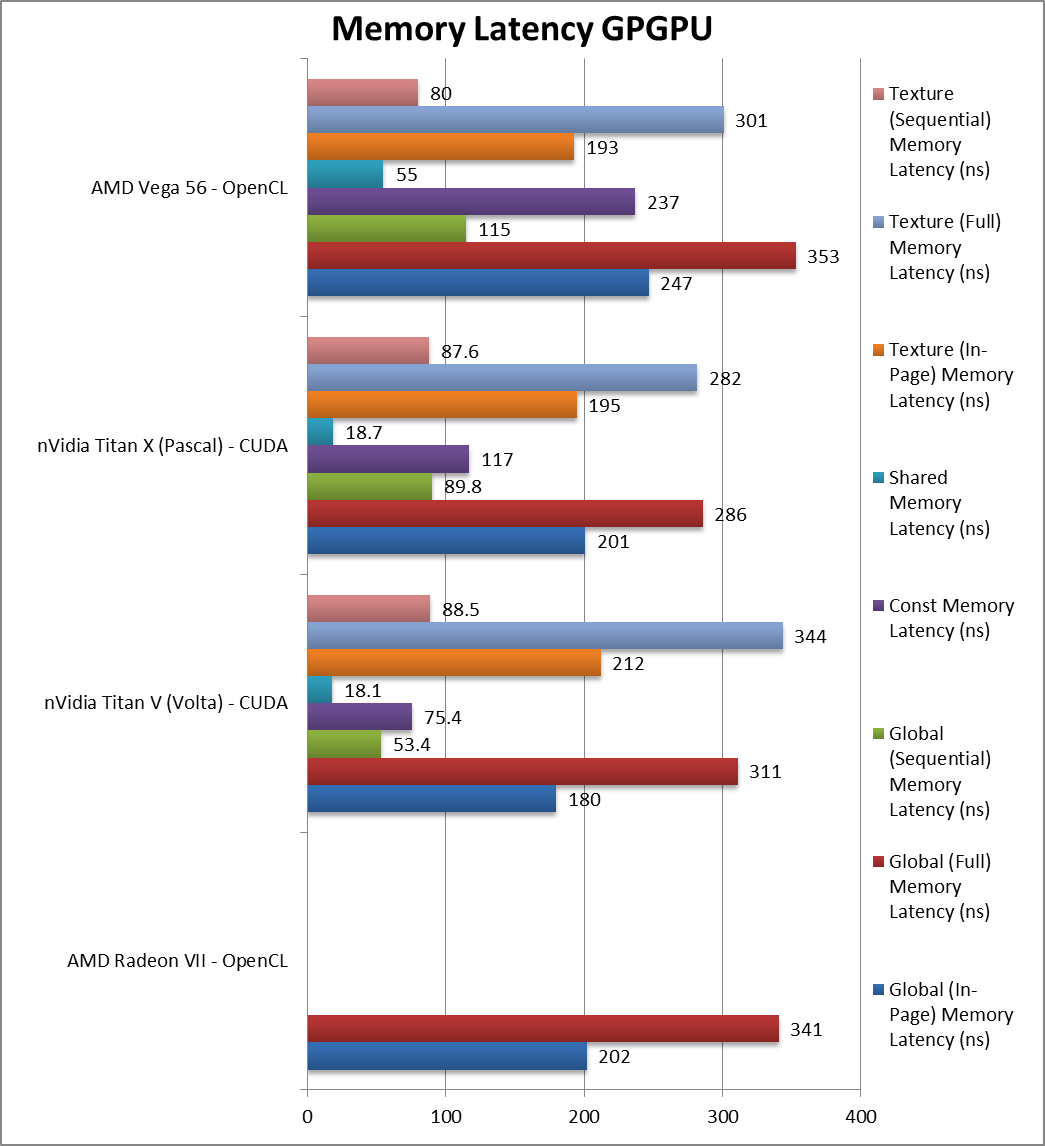 |
||||||
 |
Global (In-Page Random Access) Latency (ns) | 202 [-19%] | 180 | 201 | 247 | The higher clock allows Vega2 a 20% latency reduction. |
|
Global (Full Range Random Access) Latency (ns) | 341 [-4%] | 311 | 286 | 353 | Full range is only 4% faster. |
|
Global (Sequential Access) Latency (ns) | 53.4 | 89.8 | 115 | – | |
|
Constant Memory (In-Page Random Access) Latency (ns) | 75.4 | 117 | 237 | – | |
|
Shared Memory (In-Page Random Access) Latency (ns) | 18.1 | 18.7 | 55 | – | |
|
Texture (In-Page Random Access) Latency (ns) | 212 | 195 | 193 | – | |
|
Texture (Full Range Random Access) Latency (ns) | 344 | 282 | 301 | – | |
|
Texture (Sequential Access) Latency (ns) | 88.5 | 87.6 | 80 | – | |
| Not unexpected, GDDR6′ latencies are higher than HBM2 although not by as much as we were fearing. | ||||||
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
Vega2 (“BigVega”) is a big improvement over normal Vega1 and its workstation-class pedigree shows. For FP16/Fp32 workloads though the 30-40% performance improvement may not be worth it considering the much higher price: naturally FP64 performance is almost 4x due to 1/4 FP64 rate though not as good at professional cards with 1/2 rate or Titan competition with similar 1/2 rate.
While the GCN core (rev 5.1) has seen internal updates, there is nothing new that can be supported/optimised for in the compute land thus any code working well on Vega1 should work just as well on Vega2.
The 16GB HBM2 wide memory also helps big workloads with 2x higher bandwidth and also lower latency due to higher clock. For some workloads this alone makes it a definite buy when competition stops at 12GB.
Unfortunately the card has had a limited release at a relatively high price thus value/price ratio depends entirely on your workload – if FP64 with large datasets then it is very much worth it; if FP32/FP16 with datasets that fit in standard 8GB memory then the older Vega1 is much better value and you can even get 2 for the price of the Vega2.
For revolutionary change we need to wait for Navi and its brand new RDNA (Radeon DNA) arch(itecture)…
Disclaimer
This is an independent article that has not been endorsed or sponsored by any entity (e.g AMD). All trademarks acknowledged and used for indentification only under fair use.
The article contains only public information available elsewhere on the Internet and not provided under NDA or embargoed. At publication time, the products have not been directly testied by SiSoftware and thus the accuracy of the benchmark scores cannot be verified; however, they appear consistent and do not appear to be false/fake.