What is “Titan X (Pascal)”?
It is the current high-end “pro-sumer” card from nVidia using the current generation “Pascal” architecture – equivalent to the Series 10 cards. It is based on the 2nd-from-the-top 102 chipset (not the top-end 100) thus it does not feature full speed FP64/FP16 performance that is generally reserved for the “Quadro/Tesla” professional range of cards. It does however come with more memory to fit more datasets and is engineered for 24/7 performance.
Pricing has increased a bit from previous generation X/XP but that is a general trend today from all manufacturers; we will see if the performance justifies this (price efficiency) and also whether the power increase is also worth it (price efficiency).
See these other articles on Titan (and competition) performance:
- AMD Radeon RX 6000 (RDNA2, Navi2) Review & Benchmarks – GPGPU Performance
- nVidia RTX 3090, 3080: Ampere GPGPU performance in CUDA and OpenCL
- nVidia Titan RTX / 2080Ti: Turing GPGPU performance in CUDA and OpenCL
- AMD Radeon 5700XT: Navi GPGPU Performance in OpenCL
- nVidia Titan V : Volta GPGPU performance in CUDA and OpenCL
Hardware Specifications
We are comparing the top-of-the-range Titan X with previous generation cards and competing architectures with a view to upgrading to a mid-range high performance design.
| GP-GPU Specifications | nVidia Titan X (P) | nVidia 980 GTX (M2) | AMD Vega 56 | AMD Fury 64 |
Comments | |
| Arch Chipset | Pascal GP102 (6.1) | Maxwell 2 GM204 (5.2) | Vega 10 | Fiji | The X uses the current Pascal architecture that is also powering the current Series 10 consumer cards | |
| Cores (CU) / Threads (SP) | 28 / 3584 | 16 / 2048 | 56 / 3584 | 64 / 4096 | We’ve got 28CU/SMX here down from 32 on GP100/Tesla but should still be sufficient to power through tasks. | |
| FP32 / FP64 / Tensor Cores | 3584 / 112 / no | 2048 / 64 / no | 3584 / 448 / no | 4096 / 512 / no | Only 112 FP64 units – a lot less than competition from AMD, this is a card geared for FP32 workloads. | |
| Speed (Min-Turbo) (GHz) |
1.531GHz (139-1910) | 1.126GHz (135-1.215) | 1.64GHz | 1GHz | Higher clocked that previous generation and comparative with competition. | |
| Power (TDP) | 250W (125-300) | 180W (120-225) | 200W | 150W | TDP has also increased to 250W but again that is inline with top-end cards that are pushing over 200W. | |
| ROP / TMU |
96 / 224 | 64 / 128 | 64 / 224 | 64 / 256 | As it may also be used as top-end graphics card, it has a good amount of ROPs (50% more than competition) and similar numbers of TMUs. | |
| Global Memory (GB) |
12GB GDDR5X 10Gbps 384-bit | 4GB GDDR5 7Gbps 256-bit | 8GB HBM2 2Gbps 2048-bit | 4GB HBM 1Gbps 4096-bit | Titan X comes with a huge 12GB of current GDDR5X memory while the competition has switched to HBM2 for top-end cards. | |
| Memory Bandwidth (GB/s) |
512 | 224 | 483 | 512 | Due to high speed GDDR5X, the X has plenty of memory bandwidth even higher than HBM2 competition. | |
| L2 Cache (MB) |
3MB | 2MB | 4MB | 2MB | L2 cache has increased by 50% over previous arch to keep all cores fed. | |
| FP64/double ratio |
1/32 | 1/32 | 1/8 | 1/8 | The X is not really meant for FP64 workloads as it uses the same ratio 1:32 as normal consumer cards. | |
| FP16/half ratio |
1/64 | n/a | 1/1 | 1/1 | With 1:64 ratio FP16 is not really usable on Titan X but can only really be used for compatibility testing. | |

nVidia Titan X (Pascal)
Processing Performance
We are testing both CUDA native as well as OpenCL performance using the latest SDK / libraries / drivers from both nVidia and competition.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest nVidia drivers 398.36, CUDA 9.2, OpenCL 1.2. Turbo / Boost was enabled on all configurations.
| Processing Benchmarks | nVidia Titan X CUDA/OpenCL | nVidia GTX 980 CUDA/OpenCL | AMD Vega 56 OpenCL | AMD Fury 64 OpenCL | Comments | |
 |
||||||
 |
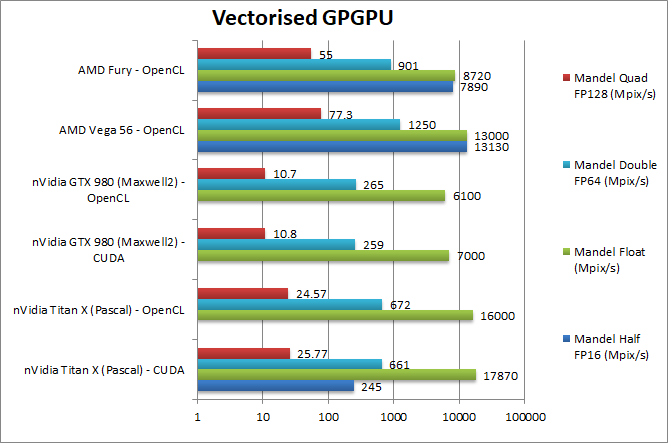
Mandel FP32/Single (Mpix/s) | 17,870 [37%] / 16,000 | 7,000 / 6,100 | 13,000 | 8,720 | Titan X makes a good start beating the Vega by almost 40%. |
|
Mandel FP16/Half (Mpix/s) | 245 [-98%] / n/a | n/a | 13,130 | 7,890 | FP16 is so slow that it is unusable – just for testing. |
|
Mandel FP64/Double (Mpix/s) | 661 [-47%] / 672 | 259 / 265 | 1,250 | 901 | FP64 is also quite slow though a lot faster than on the GTX 980. |
|
Mandel FP128/Quad (Mpix/s) | 25 [-67%] / 24 | 10.8 / 10.7 | 77.3 | 55 | Emulated FP128 precision depends entirely on FP64 performance and thus is… slow. |
| With FP32 “normal” workloads Titan X is quite fast, ~40% faster than Vega and about 2.5x faster than an older GTX 980 thus quite an improvement. But FP16 workloads should not apply – better off with FP32 – and FP64 is also about 1/2 the performance of a Vega – also slower than even a Fiji. As long as all workloads are FP32 there should be no problems. | ||||||
 |
||||||
 |
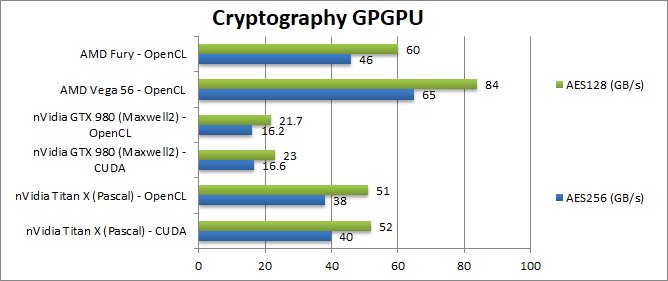
Crypto AES-256 (GB/s) | 40 [-38%] / 38 | 16 / 16 | 65 | 46 | Titan X is a lot faster than previous gen but still ~40% slower than a Vega |
|
Crypto AES-128 (GB/s) | 52 [-38%] / 51 | 23 / 21 | 84 | 60 | Nothing changes here , the X still about 40% slower than a Vega. |
 |
||||||
|
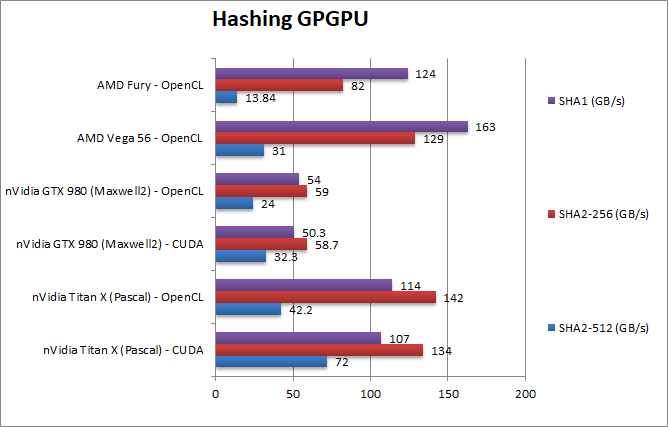
Crypto SHA2-256 (GB/s) | 134 [+4%] / 142 | 58 / 59 | 129 | 82 | In this integer workload, somehow Titan X manages to beat the Vega by 4%! |
|
Crypto SHA1 (GB/s) | 107 [-34%] / 114 | 50 / 54 | 163 | 124 | SHA1 is mysteriously slower thus the X is ~35% slower than a Vega. |
|
Crypto SHA2-512 (GB/s) | 72 [+2.3x] / 42 | 32 / 24 | 31 | 13.8 | With 64-bit integer workload, Titan X is a massive 2.3x times faster than a Vega. |
| Historically, nVidia cards have not been tuned for integer workloads, but Titan X still manages to beat a Vega – the “gold standard” for crypto-currency hashing – on both SHA256 and especially on 64-bit integer SHA2-512! Perhaps for the first time a nVidia card is competitive on integer workloads and even much faster on 64-bit integer workloads. | ||||||
 |
||||||
 |
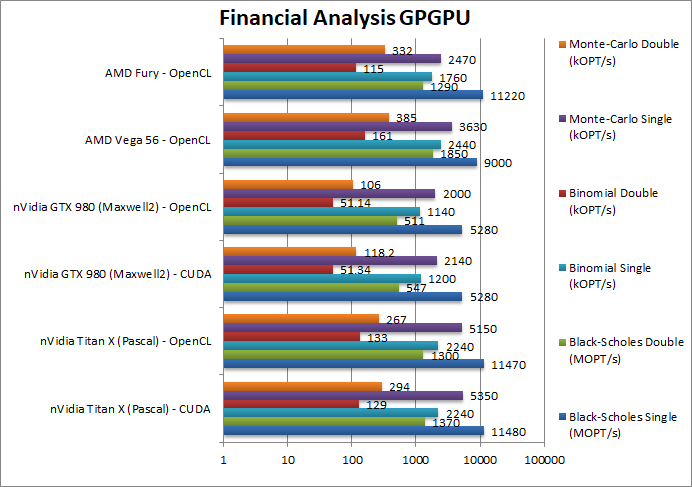
Black-Scholes float/FP32 (MOPT/s) | 11,480 [+28%] / 11,470 | 5,280 / 5,280 | 9,000 | 11,220 | In this FP32 financial workload Titan X is almost 30% faster than a Vega. |
|
Black-Scholes double/FP64 (MOPT/s) | 1,370 [-36%] / 1,300 | 547 / 511 | 1,850 | 1,290 | Switching to FP64 code, the X remains competitive and is about 35% slower. |
|
Binomial float/FP32 (kOPT/s) | 2,240 [-8%] / 2,240 | 1,200 / 1,140 | 2,440 | 1,760 | Binomial uses thread shared data thus stresses the SMX’s memory system and here Vega surprisingly does better by 8% |
|
Binomial double/FP64 (kOPT/s) | 129 [-20%] / 133 | 51 / 51 | 161 | 115 | With FP64 code the X is only 20% slower than a Vega. |
|
Monte-Carlo float/FP32 (kOPT/s) | 5,350 [+47%] / 5,150 | 2,140 / 2,000 | 3,630 | 2,470 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure – here Titan X is almost 50% faster! |
|
Monte-Carlo double/FP64 (kOPT/s) | 294 [-34%] / 267 | 118 / 106 | 385 | 332 | Switching to FP64 the X is again 34% slower than a Vega. |
| For financial FP32 workloads, the Titan X generally beats the Vega by a good amount or at least ties with it; with FP64 precision it is about 1/2 the speed which is to be expected. As long as you have FP32 workloads this should not be a problem. | ||||||
 |
||||||
 |
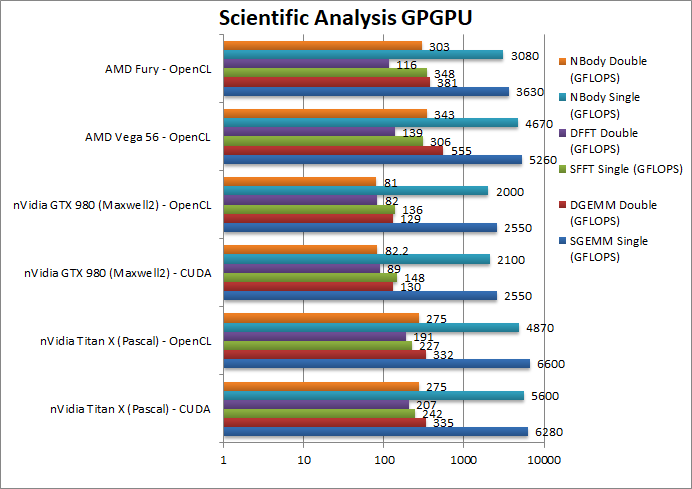
SGEMM (GFLOPS) float/FP32 | 6,280 [+19%] / 6,600 | 2,550 / 2,550 | 5,260 | 3,630 | Using 32-bit precision Titan X beats the Vega by 20%. |
|
DGEMM (GFLOPS) double/FP64 | 335 [-40%] / 332 | 130 / 129 | 555 | 381 | With FP64 precision, unsurprisingly the X is 40% slower. |
|
SFFT (GFLOPS) float/FP32 | 242 [-20%] / 227 | 148 / 136 | 306 | 348 | FFT does better with HBM memory and here Titan X is 20% slower than a Vega. |
|
DFFT (GFLOPS) double/FP64 | 207 / 191 | 89 / 82 | 139 | 116 | Surprisingly the X does very well here and manages to beat all cards by almost 50%! |
|
SNBODY (GFLOPS) float/FP32 | 5,600 [+20%] / 4,870 | 2,100 / 2,000 | 4,670 | 3,080 | Titan X does well in this algorithm, beating the Vega by 20%. |
|
DNBODY (GFLOPS) double/FP64 | 275 [-20%] / 275 | 82 / 81 | 343 | 303 | With FP64 precision, the X is again 20% slower. |
| The scientific scores are similar to the financial ones but the gain/loss is about 20% not 40% – in FP32 workloads Titan X is 20% faster while in FP64 it is about 20% slower than a Vega – a closer result than expected. | ||||||
 |
||||||
 |
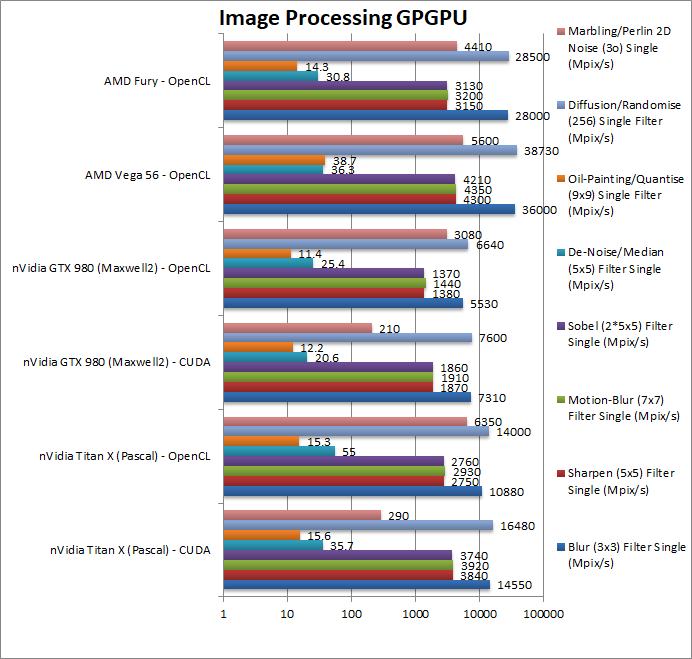
Blur (3×3) Filter single/FP32 (MPix/s) | 14,550 [-60%] / 10,880 | 7,310 / 5,530 | 36,000 | 28,000 | In this 3×3 convolution algorithm, somehow Titan X is over 50% slower than a Vega and even a Fury. |
|
Sharpen (5×5) Filter single/FP32 (MPix/s) | 3,840 [-11%] / 2,750 | 1,870 / 1,380 | 4,300 | 3,150 | Same algorithm but more shared data reduces the gap to 10% but still a loss. |
|
Motion Blur (7×7) Filter single/FP32 (MPix/s) | 3,920 [-10%] / 2,930 | 1,910 / 1,440 | 4,350 | 3,200 | With even more data the gap remains at 10%. |
|
Edge Detection (2*5×5) Sobel Filter single/FP32 (MPix/s) | 3,740 [-11%] / 2,760 | 1,860 / 1,370 | 4,210 | 3,130 | Still convolution but with 2 filters – Titan X is 10% slower again. |
|
Noise Removal (5×5) Median Filter single/FP32 (MPix/s) | 35.7 / 55 [+52%] | 20.6 / 25.4 | 36.3 | 30.8 | Different algorithm allows the X to finally beat the Vega by 50%. |
|
Oil Painting Quantise Filter single/FP32 (MPix/s) | 15.6 [-60%] / 15.3 | 12.2 / 11.4 | 38.7 | 14.3 | Without major processing, this filter does not like the X much it runs 1/2 slower than the Vega. |
|
Diffusion Randomise (XorShift) Filter single/FP32 (MPix/s) | 16,480 [-57%] / 14,000 | 7,600 / 6,640 | 38,730 | 28,500 | This algorithm is 64-bit integer heavy but again Titan X is 1/2 the speed of Vega. |
|
Marbling Perlin Noise 2D Filter single/FP32 (MPix/s) | 290 / 6,350 [+13%] | 210 / 3,080 | 5,600 | 4,410 | One of the most complex and largest filters, Titan X finally beats the Vega by over 10%. |
| For image processing using FP32 precision Titan X surprisingly does not do as well as expected – either in CUDA or OpenCL – with the Vega beating it by a good margin on most filters – a pretty surprising result. Perhaps more optimisations are needed on nVidia hardware. We obviously did not test FP16 performance at all as that would have been far slower. | ||||||
Memory Performance
We are testing both CUDA native as well as OpenCL performance using the latest SDK / libraries / drivers from nVidia and competition.
Results Interpretation: For bandwidth tests (MB/s, etc.) high values mean better performance, for latency tests (ns, etc.) low values mean better performance.
Environment: Windows 10 x64, latest nVidia drivers 398.36, CUDA 9.2, OpenCL 1.2. Turbo / Boost was enabled on all configurations.
| Memory Benchmarks | nVidia Titan X CUDA/OpenCL | nVidia GTX 980 CUDA/OpenCL | AMD Vega 56 OpenCL | AMD Fury 64 OpenCL | Comments | |
 |
||||||
 |
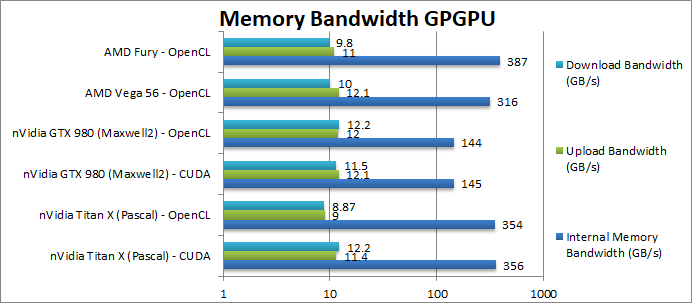
Internal Memory Bandwidth (GB/s) | 356 [+13%] / 354 | 145 / 144 | 316 | 387 | Titan X brings more bandwidth than a Vega (+13%) but the old Fury takes the crown. |
|
Upload Bandwidth (GB/s) | 11.4 / 9 | 12.1 / 12 | 12.1 | 11 | All cards use PCIe3 x16 and thus no appreciable delta. |
|
Download Bandwidth (GB/s) | 12.2 / 8.9 | 11.5 / 12.2 | 10 | 9.8 | Again no significant difference but we were not expecting any. |
| Titan X uses current GDDR5X but with high data rate allowing it to bring more bandwidth that some HBM2 designs – a pretty impressive feat. Naturally high-end cards using HBM2 should have even higher bandwidth. | ||||||
 |
||||||
 |
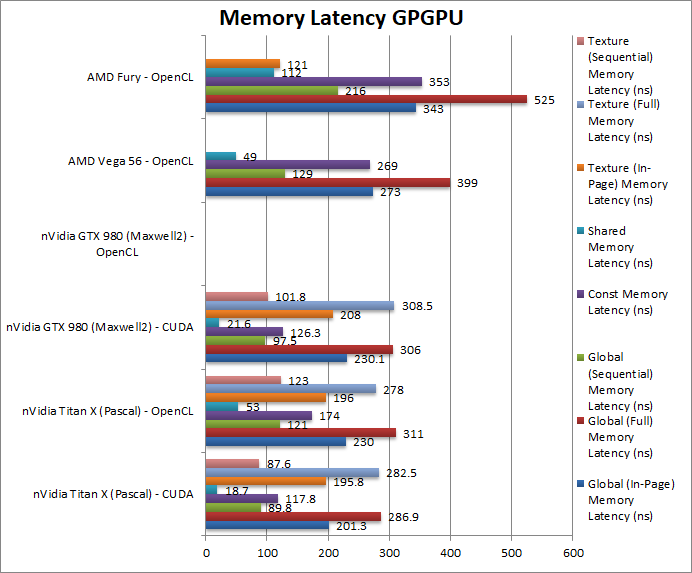
Global (In-Page Random Access) Latency (ns) | 201 / 230 | 230 | 273 | 343 | Compared to previous generation, Titan X has better latency due to higher data rate. |
|
Global (Full Range Random Access) Latency (ns) | 286 / 311 | 306 | 399 | 525 | Similarly, even full random accesses are faster, |
|
Global (Sequential Access) Latency (ns) | 89 / 121 | 97 | 129 | 216 | Sequential access has similarly low latencies but nothing special. |
|
Constant Memory (In-Page Random Access) Latency (ns) | 117 / 174 | 126 | 269 | 353 | Constant memory latencies have also dropped. |
|
Shared Memory (In-Page Random Access) Latency (ns) | 18 / 53 | 21 | 49 | 112 | Even shared memory latencies have dropped likely due to higher core clocks. |
|
Texture (In-Page Random Access) Latency (ns) | 195 / 196 | 208 | 121 | Texture access latencies have come down as well. | |
|
Texture (Full Range Random Access) Latency (ns) | 282 / 278 | 308 | And even full range latencies have decreased. | ||
|
Texture (Sequential Access) Latency (ns) | 87 /123 | 102 | With sequential access there is no appreciable delta in latencies. | ||
| We’re only comparing CUDA latencies here (as OpenCL is quite variable) – thus compared to the previous generation (GTX 980) all latencies are down, either due to higher memory data rate or core clock increases – but nothing spectacular. Still good progress and everything helps. | ||||||
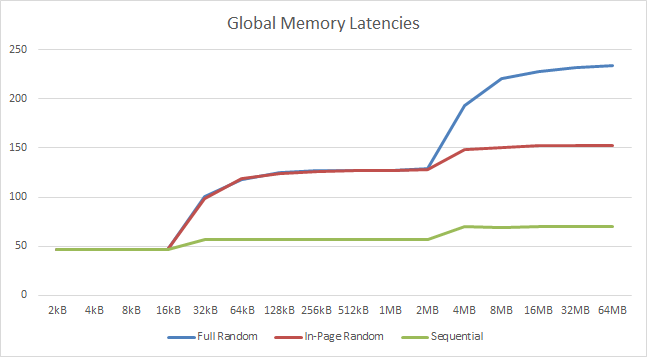 |
||||||
| We see L1 cache effects until 16kB (same as previous arch) and between 2-4MB tallying with the 3MB cache. While fast perhaps they could be a bit bigger. | ||||||
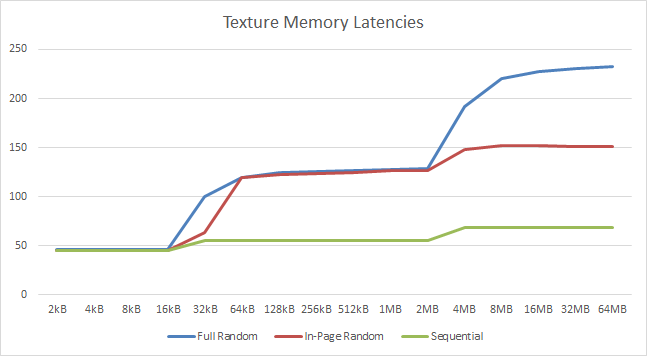 |
||||||
| As with global memory we see the same L1D and L2 cache affects with similar latencies. All in all good performance but we could do with bigger caches. | ||||||
Titan X’s memory performance is what you’d expect from higher clocked GDDR5X memory – it is competitive even with the latest HBM2 powered competition – both bandwidth and latency wise. There are no major surprises here and everything works nicely.
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
Executive Summary: Great update, big performance increase: Gold Star 9/10!
Titan X based on the current “Pascal” architecture performs very well in FP32 workloads – it is much faster than previous generation for a modest price increase and is competitive with the AMD’s Vega offers. But it is likely due to be replaced soon as next-generation “Volta” architecture is already out on the high-end (Titan V) and likely due to filter down the stack to both consumer (Series 11?) cards and “pro-sumer” cheaper Titan cards than the Titan V.
For FP64 workloads it is perhaps best to choose an older Quadro/Tesla card with more FP64 units as performance is naturally much lower. FP16 performance is also restricted and pretty much not usable – good for compatibility testing should you hope to upgrade to a full-speed FP16 card in the future. For both these workloads – the high-end Titan V is the card you probably want – but at a much higher price.
Still for the money, Titan X has its place and the most common FP32 workloads (financial, scientific, high precision image processing, etc.) that do not require FP64 nor FP16 optimisations perform very well and this card is all you need.
nVidia Titan X (Pascal)