What is “Titan V”?
It is the latest high-end “pro-sumer” card from nVidia with the next-generation “Volta” architecture, the next generation to the current “Pascal” architecture on the Series 10 cards. Based on the top-end 100 chipset (not lower 102 or 104) it boasts full speed FP64/FP16 performance as well as brand-new “tensor cores” (matrix multipliers) for scientific and deep-learning workloads. It also comes with on-chip HBM2 (high-bandwidth) memory unlike more traditional GDDRX stand-alone memory.
For this reason the price is also far higher than previous Titan X/XP cards but considering the features/performance are more akin to “Tesla” series it would still be worth it depending on workload.
While using the additional cores provided in FP64/FP16 workloads is automatic – save usual code optimisations – tensor cores support requires custom code and existing libraries and apps need to be updated to make use of them. It is unknown at this time if consumer cards based on “Volta” will also include them. As they support FP16 precision only, not workloads may be able to use them – but DL (deep learning) and AI (artificial intelligence) are generally fine using lower precision thus for such tasks it is ideal.
See these other articles on Titan (and competition) performance:
- AMD Radeon RX 6900 (RDNA2, Navi2) Review & Benchmarks – GPGPU Performance
- nVidia 3090, 3080 RTX: Ampere GPGPU performance in CUDA and OpenCL
- nVidia Titan RTX / 2080Ti: Turing GPGPU performance in CUDA and OpenCL
- AMD Radeon 5700XT: Navi GPGPU Performance in OpenCL
- nVidia Titan X : Pascal GPGPU performance in CUDA and OpenCL
- nVidia Titan V/X: FP16 and Tensor CUDA Performance
Hardware Specifications
We are comparing the top-of-the-range Titan V with previous generation Titans and competing architectures with a view to upgrading to a mid-range high performance design.
| GPGPU Specifications | nVidia Titan V |
nVidia Titan X (P) |
nVidia 980 GTX (M2) |
Comments | |
| Arch Chipset | Volta GV100 (7.0) | Pascal GP102 (6.1) | Maxwell 2 GM204 (5.2) | The V is the only one using the top-end 100 chip not 102 or 104 lower-end versions | |
| Cores (CU) / Threads (SP) | 80 / 5120 | 28 / 3584 | 16 / 2048 | The V boasts 80 CU units but these contain 64 FP32 units only not 128 like lower-end chips thus equivalent with 40. | |
| FP32 / FP64 / Tensor Cores | 5120 / 2560 / 640 | 3584 / 112 / no | 2048 / 64 / no | Titan V is the only one with tensor cores and also huge amount of FP64 cores that Titan X simply cannot match; it also has full speed FP16 support. | |
| Speed (Min-Turbo) | 1.2GHz (135-1.455) | 1.531GHz (139-1910) | 1.126GHz (135-1.215) | Slightly lower clocked than the X it will will make up for it with sheer CU units. | |
| Power (TDP) | 300W | 250W (125-300) | 180W (120-225) | TDP increases by 50W but it is not unexpected considering the additional units. | |
| ROP / TMU |
96 / 320 | 96 / 224 | 64 / 128 | Not a “gaming card” but while ROPs stay the same the number of TMUs has increased – likely required for compute tasks using textures. | |
| Global Memory | 12GB HBM2 850Mhz 3072-bit | 12GB GDDR5X 10Gbps 384-bit | 4GB GDDR5 7Gbps 256-bit | Memory size stays the same at 12GB but now uses on-chip HBM2 for much higher bandwidth | |
| Memory Bandwidth (GB/s) |
652 | 512 | 224 | In addition to the modest bandwidth increase, latencies are also meant to have decreased by a good amount. | |
| L2 Cache | 4.5MB | 3MB | 2MB | L2 cache has gone up by about 50% to feed all the cores. | |
| FP64/double ratio |
1/2 | 1/32 | 1/32 | For FP64 workloads the V has huge advantage as consumer and previous Titan X had far less FP64 units. | |
| FP16/half ratio |
2x | 1/64 | n/a | The V has an even bigger advantage here with over 128x more units for FP16 tasks like DL and AI. | |

nVidia Titan V (Volta)
Processing Performance
We are testing both CUDA native as well as OpenCL performance using the latest SDK / libraries / drivers.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest nVidia drivers 398.36, CUDA 9.2, OpenCL 1.2. Turbo / Boost was enabled on all configurations.
| Processing Benchmarks | nVidia Titan V CUDA/OpenCL |
nVidia Titan X CUDA/OpenCL |
nVidia GTX 980 CUDA/OpenCL |
Comments | |
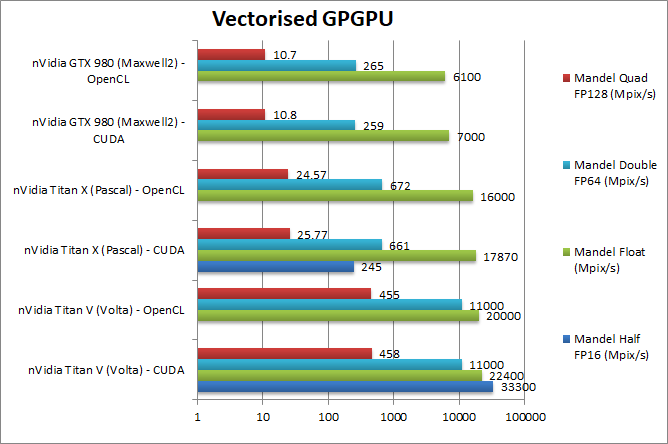 |
|||||
 |
Mandel FP32/Single (Mpix/s) | 22,400 [+25%] / 20,000 | 17,870 / 16,000 | 7,000 / 6,100 | Right off the bat, the V is just 25% faster than the X some optimisations may be required. |
|
Mandel FP16/Half (Mpix/s) | 33,300 [135x] / n/a | 245 / n/a | n/a | For FP16 workloads the V shows its power: it is an astonishing 135 *times* (times not %) faster than the X. |
|
Mandel FP64/Double (Mpix/s) | 11,000 [+16.7x] / 11,000 | 661 / 672 | 259 / 265 | For FP64 precision workloads the V shines again, it is 16 times faster than the X. |
|
Mandel FP128/Quad (Mpix/s) | 458 [+17.7x] / 455 | 25 / 24 | 10.8 / 10.7 | With emulated FP128 precision the V is again 17 times faster. |
| As expected FP64 and FP16 performance is much improved on Titan V, with FP64 over 16x times faster than the X; FP16 performance is over 50% faster than FP32 performance making it almost 2x faster than Titan X. For workloads that need it, the performance of Titan V is stellar. | |||||
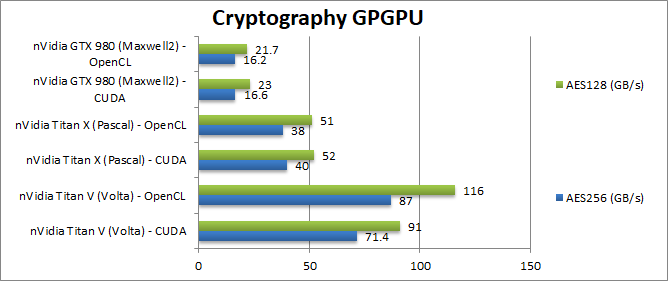 |
|||||
 |
Crypto AES-256 (GB/s) | 71 [+79%] / 87 | 40 / 38 | 16 / 16 | Titan V is almost 80% faster than the X here a significant improvement. |
|
Crypto AES-128 (GB/s) | 91 [+75%] / 116 | 52 / 51 | 23 / 21 | Not a lot changes here, with the V still 7% faster than the X. |
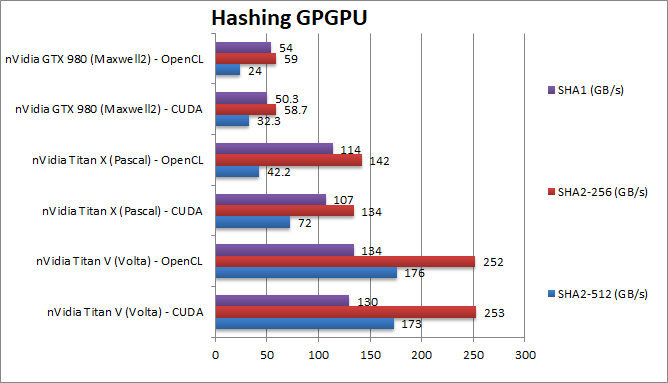 |
|||||
|
Crypto SHA2-256 (GB/s) | 253 [+89%] / 252 | 134 / 142 | 58 / 59 | In this integer workload, Titan V is almost 2x faster than the X. |
|
Crypto SHA1 (GB/s) | 130 [+21%] / 134 |
107 / 114 | 50 / 54 | SHA1 is mysteriously slower than SHA256 and here the V is just 21% faster. |
|
Crypto SHA2-512 (GB/s) | 173 [+2.4x] / 176 | 72 / 42 | 32 / 24 | With 64-bit integer workload, Titan V shines again – it is almost 2.5x (times) faster than the X! |
| Historically, nVidia cards have not been tuned for integer workloads, but Titan V is almost 2x faster in 32-bit hashing and almost 3x faster in 64-bit hashing than the older X. For algorithms that use integer computation this can be quite significant. | |||||
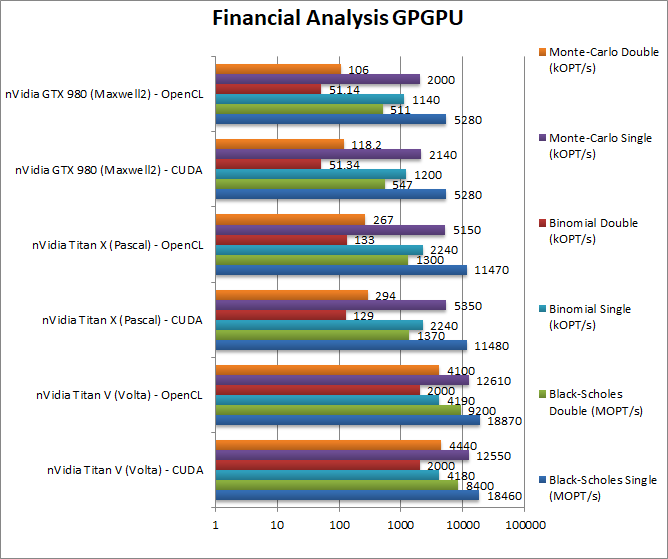 |
|||||
 |
Black-Scholes float/FP32 (MOPT/s) | 18,460 [+61%] / 18,870 |
11,480 / 11,470 | 5,280 / 5,280 | Titan V manages to be 60% faster in this FP32 financial workload. |
|
Black-Scholes double/FP64 (MOPT/s) | 8,400 [+6.1x] / 9,200 |
1,370 / 1,300 | 547 / 511 | Switching to FP64 code, the V is over 6x (times) faster than the X. |
|
Binomial float/FP32 (kOPT/s) | 4,180 [+81%] / 4,190 |
2,240 / 2,240 | 1,200 / 1,140 | Binomial uses thread shared data thus stresses the SMX’s memory system: but the V is 80% faster than the X. |
|
Binomial double/FP64 (kOPT/s) | 2,000 [+15.5x] / 2,000 |
129 / 133 | 51 / 51 | With FP64 code the V is much faster – 15x (times) faster! |
|
Monte-Carlo float/FP32 (kOPT/s) | 12,550 [+2.35x] / 12,610 |
5,350 / 5,150 | 2,140 / 2,000 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure – here the V is over 2x faster than the X and that is FP32 code! |
|
Monte-Carlo double/FP64 (kOPT/s) | 4,440 [+15.1x] / 4,100 |
294 / 267 | 118 / 106 | Switching to FP64 the V is again over 15x (times) faster! |
| For financial workloads, the Titan V is significantly faster, almost twice as fast as Titan X on FP32 but over 15x (times) faster on FP64 workloads. If time is money, then this can be money well-spent! | |||||
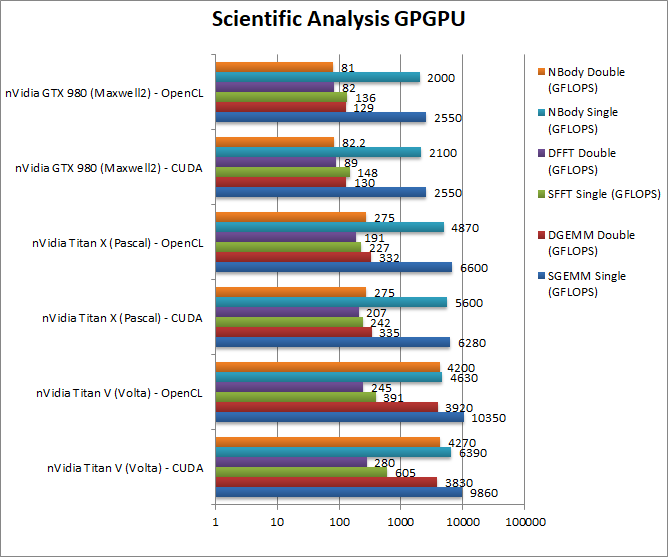 |
|||||
 |
SGEMM (GFLOPS) float/FP32 | 9,860 [+57%] / 10,350 |
6,280 / 6,600 | 2,550 / 2,550 | Without using the new “tensor cores”, Titan V is about 60% faster than the X. |
|
DGEMM (GFLOPS) double/FP64 | 3,830 [+11.4x] / 3,920 | 335 / 332 | 130 / 129 | With FP64 precision, the V crushes the X again it is 11x (times) faster. |
|
SFFT (GFLOPS) float/FP32 | 605 [+2.5x] / 391 | 242 / 227 | 148 / 136 | FFT allows the V to do even better – no doubt due to HBM2 memory. |
|
DFFT (GFLOPS) double/FP64 | 280 [+35%] / 245 | 207 / 191 | 89 / 82 | We may need some optimisations here, otherwise the V is just 35% faster. |
|
SNBODY (GFLOPS) float/FP32 | 6,390 [+15%] / 4,630 |
5,600 / 4,870 | 2,100 / 2,000 | N-Body simulation also needs some optimisations as the V is just 15% faster. |
|
DNBODY (GFLOPS) double/FP64 | 4,270 [+15.5x] / 4,200 |
275 / 275 | 82 / 81 | With FP64 precision, the V again crushes the X – it is 15x faster. |
| The scientific scores are a bit more mixed – GEMM will require code paths to take advantage of the new “tensor cores” and some optimisations may be required – otherwise FP64 code simply flies on Titan V. | |||||
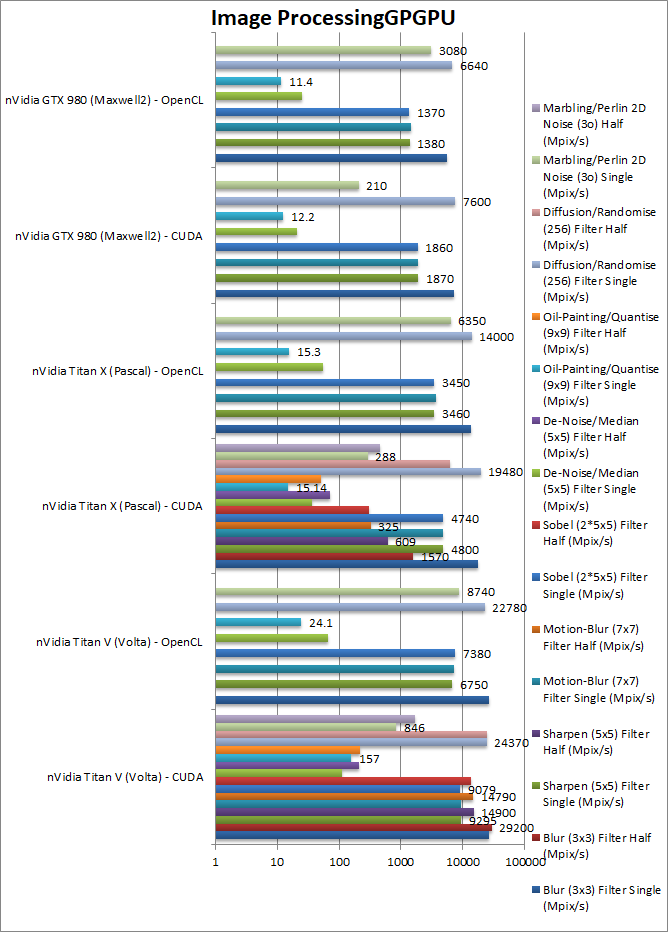 |
|||||
 |
Blur (3×3) Filter single/FP32 (MPix/s) | 26,790 [50%] / 26,660 |
17,860 / 13,680 | 7,310 / 5,530 | In this 3×3 convolution algorithm, Titan V is 50% faster than the X. Convolution is also used in neural nets (CNN) thus performance here counts. |
|
Blur (3×3) Filter half/FP16 (MPix/s) | 29,200 [+18.6x] |
1,570 | n/a | With FP16 precision, Titan V shines it is 18x (times faster than X) but 12% faster than FP32. |
|
Sharpen (5×5) Filter single/FP32 (MPix/s) | 9,295 [+94%] / 6,750 |
4,800 / 3,460 | 1,870 / 1,380 | Same algorithm but more shared data allows the V to be almost 2x faster than the X. |
|
Sharpen (5×5) Filter half/FP16 (MPix/s) | 14,900 [24.4x] |
609 | n/a | With FP16 Titan V is almost 25x (times) faster than X and also 60% faster than Fp32. |
|
Motion-Blur (7×7) Filter single/FP32 (MPix/s) | 9,428 [+2x] / 7,260 |
4,830 / 3,620 | 1,910 / 1,440 | Again same algorithm but even more data shared the V is 2x faster than the X. |
|
Motion-Blur (7×7) Filter half/FP16 (MPix/s) | 14,790 [+45x] | 325 | n/a | With FP16 the V is now45x (times) faster than the X showing the usefulness of FP16 support. |
|
Edge Detection (2*5×5) Sobel Filter single/FP32 (MPix/s) | 9,079 [1.92x] / 7,380 |
4,740 / 3450 | 1,860 / 1,370 | Still convolution but with 2 filters – Titan V is almost 2x faster again. |
|
Edge Detection (2*5×5) Sobel Filter half/FP16 (MPix/s) | 13,740 [+44x] |
309 | n/a | Just as we seen above, the V is an astonishing 44x (times) faster than the X, and also ~20% faster than FP32 code. |
|
Noise Removal (5×5) Median Filter single/FP32 (MPix/s) | 111 [+3x] / 66 |
36 / 55 | 20 / 25 | Different algorithm but here the V is even faster, 3x faster than the X! |
|
Noise Removal (5×5) Median Filter half/FP16 (MPix/s) | 206 [+2.89x] |
71 | n/a | With FP16 the V is “only” 3x faster than the X but also 2x faster than FP32 code-path again a big gain for FP16 processing |
|
Oil Painting Quantise Filter single/FP32 (MPix/s) | 157 [+10x] / 24 |
15 / 15 | 12 / 11 | Without major processing, this filter flies on the V – it is 10x faster than the X. |
|
Oil Painting Quantise Filter half/FP16 (MPix/s) | 215 [+4x] | 50 | FP16 precision is “just” 4x faster but it is also ~40% faster than FP32. | |
|
Diffusion Randomise (XorShift) Filter single/FP32 (MPix/s) | 24,370 / 22,780 [+25%] | 19,480 / 14,000 | 7,600 / 6,640 | This algorithm is 64-bit integer heavy and here Titan V is 25% faster than the X. |
|
Diffusion Randomise (XorShift) Filter half/FP16 (MPix/s) | 24,180 [+4x] | 6,090 | FP16 does not help a lot here, but still the V is 4x faster than the X. | |
|
Marbling Perlin Noise 2D Filter single/FP32 (MPix/s) | 846 [+3x] / 874 | 288 / 635 | 210 / 308 | One of the most complex and largest filters, Titan V does very well here, it is 3x faster than the X. |
|
Marbling Perlin Noise 2D Filter half/FP16 (MPix/s) | 1,712 [+3.7x] |
461 | n/a | Switching to FP16, the V is almost 4x (times) faster than the X and over 2x faster than FP32 code. |
| For image processing, Titan V brings big performance increases from 50% to 4x (times) faster than Titan X a big upgrade. If you are willing to drop to FP16 precision, then it is an extra 50% to 2x faster again – while naturally FP16 is not really usable on the X. With potential 8x times better performance Titan V powers through image processing tasks. | |||||
Memory Performance
We are testing both CUDA native as well as OpenCL performance using the latest SDK / libraries / drivers.
Results Interpretation: For bandwidth tests (MB/s, etc.) high values mean better performance, for latency tests (ns, etc.) low values mean better performance.
Environment: Windows 10 x64, latest nVidia drivers 398.36, CUDA 9.2, OpenCL 1.2. Turbo / Boost was enabled on all configurations.
HBM2 does seem to increase latencies slightly by about 10% but for sequential accesses Titan V does perform a lot better than the X with 20-40% lower latencies, likely due to the the new architecture. Thus code using coalesce memory accesses will perform faster but for code using random access pattern over large data sets
| Memory Benchmarks | nVidia Titan V CUDA/OpenCL |
nVidia Titan X CUDA/OpenCL |
nVidia GTX 980 CUDA/OpenCL |
Comments | |
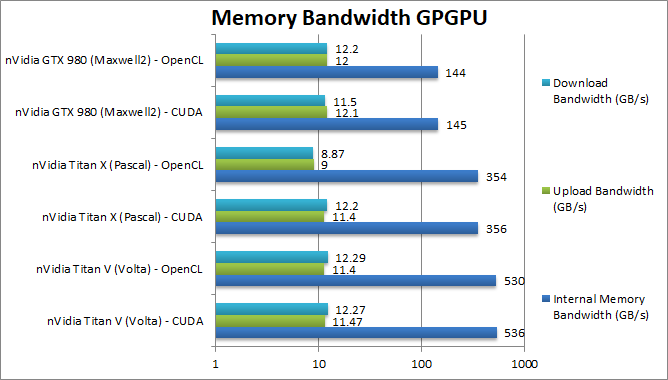 |
|||||
 |
Internal Memory Bandwidth (GB/s) | 536 [+51%] / 530 |
356 / 354 | 145 / 144 | HBM2 brings about 50% more raw bandwidth to feed all the extra compute cores, a significant upgrade. |
|
Upload Bandwidth (GB/s) | 11.47 / 11,4 |
11.4 / 9 | 12.1 / 12 | Still using PCIe3 x16 there is no change in upload bandwidth. Roll on PCIe4! |
|
Download Bandwidth (GB/s) | 12.3 / 12.3 |
12.2 / 8.9 | 11.5 / 12.2 | Again no significant difference but we were not expecting any. |
| Titan V’s HBM2 brings 50% more memory bandwidth but as it still uses the PCIe3 x16 connection there is no change to host upload/download bandwidth which may be a bit of a bottleneck trying to keep all those cores fed with data. Even more streaming load/save is required and code will need to be optimised to use all that processing power | |||||
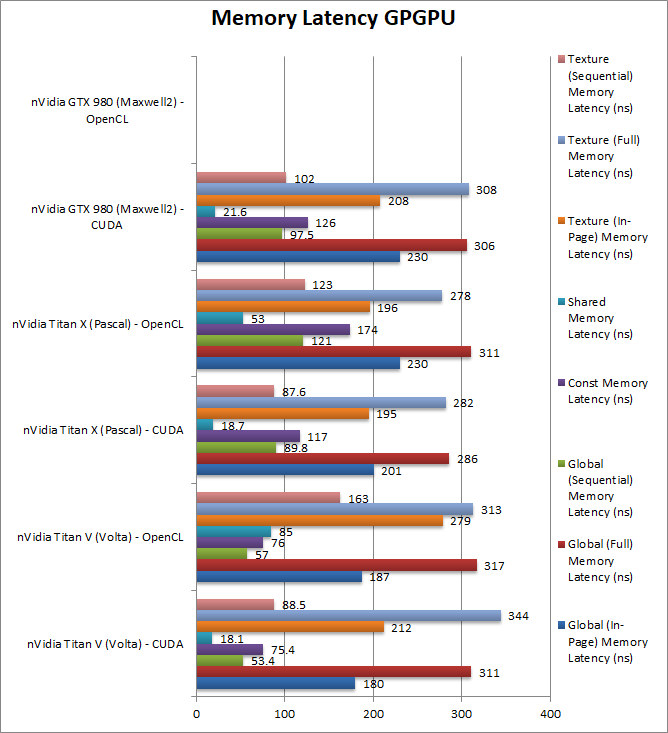 |
|||||
 |
Global (In-Page Random Access) Latency (ns) | 180 [-10%] / 187 |
201 / 230 | 230 | From the start we see global latency accesses reduced by 10%, not a lot but will help. |
|
Global (Full Range Random Access) Latency (ns) | 311 [+9%] / 317 |
286 / 311 | 306 | Full range random accesses do seem to be 9% slower which may be due to the architecture. |
|
Global (Sequential Access) Latency (ns) | 53 [-40%] / 57 | 89 / 121 | 97 | However, sequential accesses seem to have dropped a huge 40% likely due to better prefetchers on the Titan V. |
|
Constant Memory (In-Page Random Access) Latency (ns) | 75 [-36%] / 76 | 117 / 174 | 126 | Constant memory latencies also seem to have dropped by almost 40% a great result. |
|
Shared Memory (In-Page Random Access) Latency (ns) | 18 / 85 | 18 / 53 | 21 | No significant change in shared memory latencies. |
|
Texture (In-Page Random Access) Latency (ns) | 212 [+9%] / 279 | 195 / 196 | 208 | Texture access latencies seem to have increased by 9% |
|
Texture (Full Range Random Access) Latency (ns) | 344 [+22%] / 313 | 282 / 278 | 308 | As we’ve seen with global memory, we see increased latencies here by about 20%. |
|
Texture (Sequential Access) Latency (ns) | 88 / 163 | 87 /123 | 102 | With sequential access there is no appreciable delta in latencies. |
| HBM2 does seem to increase latencies slightly by about 10% but for sequential accesses Titan V does perform a lot better than the X with 20-40% lower latencies, likely due to the the new architecture. Thus code using coalesce memory accesses will perform faster but for code using random access pattern over large data sets | |||||
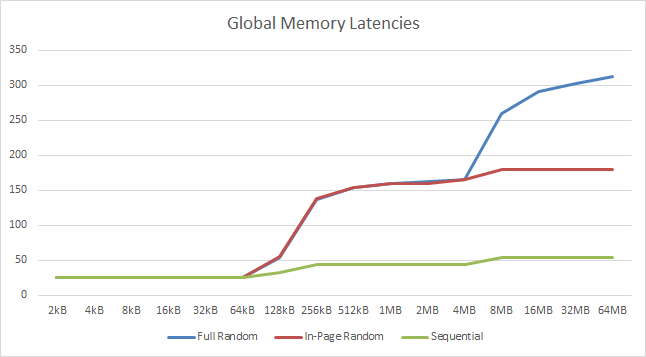 |
|||||
| We see L1 cache effects between 64-128kB tallying with an L1D of 96kB – 4x more than what we’ve seen on Titan X (at 16kB). The other inflexion is at 4MB – matching the 4.5MB L2 cache size – which is 50% more than what we saw on Titan X (at 3MB). | |||||
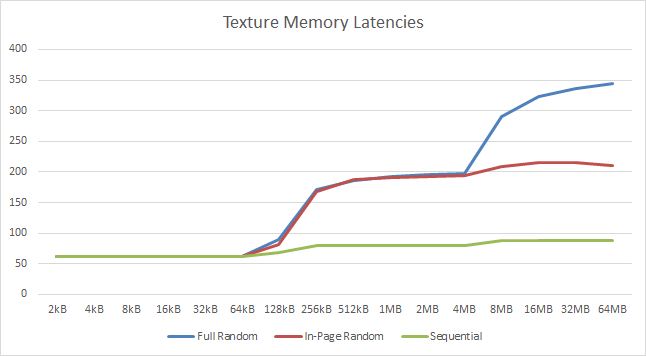 |
|||||
| As with global memory we see the same L1D (64kB) and L2 (4.5MB) cache affects with similar latencies. Both are significant upgrades over Titan X’ caches. | |||||
Titan V’s memory performance does not disappoint – HBM2 obviously brings large bandwidth increase – latency depends on access pattern, when prefetchers can engage they are much lowers but in random accesses out-of-page they are a big higher but nothing significant. We’re also limited by the PCIe3 bus for transfers which requires judicious overlap of memory transfers and compute to keep the cores busy.
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
“Volta” architecture does bring good improvements in FP32 performance which we hope to see soon in consumer (Series 11?) graphics cards – as well as lower-end Titan cards.
But here (on Titan V) we have the top-end chip with full-power FP64 and FP16 units more akin to Tesla which simply power through any and all algorithms you can throw at them. This is really the “Titan” you were looking for and upgrading from the previous Titan X (Pascal) is a huge upgrade admittedly for quite a bit more money.
If you have workloads that requires double/FP64 precision – Titan V is 15-16x times faster than Titan X – thus great value for money. If code can make do with FP16 precision then you can gain up to 2x extra performance again – as well as save storage for large data-sets – again Titan X cannot cut it here running at 1/64 rate.
We have not yet shown tensor core performance which is an additional reason for choosing such a card – if you have code that can make use of them you can gain an extra 16x (times) performance that really puts Titan V heads and shoulders over the Titan X.
All in all Titan V is a compelling upgrade if you need more power than Titan X and are (or thinking of) using multiple cards – there is simply no point. One Titan V can replace 4 or more Titan X cards on FP64 or FP16 workloads and that is before you make any optimisations. Obviously you are still “stuck” with 12GB memory and PCIe bus for transfers but with judicious optimisations this should not impact performance significantly.
nVidia Titan V (Volta)