What is “Navi”?
It is the code-name of the new AMD GPU, the first of the brand-new RDNA (Radeon DNA) GPU arch(itecture) – replacing the “Vega” that was the last of the GCN (graphics core next) arch(itecture). It is a mid-range GPU optimised for gaming thus not expected to set records, but GPUs today are used for many other tasks (mining, encoding, algorithm/compute acceleration, etc.) as well.
RDNA arch brings big changes from the various GCN revisions we’ve seen previously, but its first iteration here does not bring any major new features at least in the compute domain. Hopefully the next versions will bring tensor units (TSX) or matrix multiplicators (MMA) and other accelerated instruction sets (e.g. ray-tracing (RTX) units) and so on.
See these other articles on GP-GPU performance:
- ExtremeTech
- SiSoftware
Hardware Specifications
We are comparing the middle-range Radeon with previous generation cards and competing architectures with a view to upgrading to a mid-range high performance design.
| GP-GPU Specifications | AMD Radeon 5700XT (Navi) | AMD Radeon VII (Vega2) | nVidia Titan X (Pascal) | AMD Radeon 56 (Vega1) | Comments | |
| Arch / Chipset | RDNA1 / Navi 10 | GCN5.1 / Vega 20 | Pascal / GP102 | GCN5.0 / Vega 10 | The first of the Navi chips. | |
| Cores (CU) / Threads (SP) | 40 / 2560 | 60 / 3840 | 28 / 3584 | 56 / 3584 | Less CUs than Vega1 and same (64x) SP per CU. | |
| SIMD per CU / Width | 2 / 32 [2x] | 4 / 16 | – | 4 / 16 | Navi increases the SIMD width but decreases counts. | |
| Wave/Warp Size | 32 [1/2x] | 64 | 32 | 64 | Wave size is reduced to match nVidia. | |
| Speed (Min-Turbo) (GHz) |
1.6-1.755 | 1.4-1.75 | 1.531-1.91 | 1.156-1.471 | 40% faster base and 20% turbo than Vega 1. | |
| Power (TDP) | 225W | 295W | 250W | 210W | Slightly higher TDP but nothing significant | |
| ROP / TMU | 64 / 160 | 64 / 240 | 96 / 224 | 64 / 224 | ROPs are the same but we see ~30% less TMUs. | |
| Shared Memory (kB) |
64kB [+2x] |
32kB | 48kB / 96kB per SM | 32kB | We have 2x more shared memory allowing bigger kernels. | |
| Constant Memory (GB) |
4GB | 8GB | 64kB dedicated | 4GB | No dedicated constant memory but large. | |
| Global Memory (GB) |
8GB GDDR6 14Gt/s 256-bit | 16GB HBM2 1Gt/s 4096-bit | 12GB GDDR5X 10Gt/s 384-bit | 8GB HBM2 900Gt/s 4096-bit | Sadly no HBM this time but the faster but not very wide. | |
| Memory Bandwidth (GB/s) |
448GB/s [+9%] | 1024GB/s | 512GB/s | 410GB/s | Still bandwidth is 9% higher. | |
| L1 Caches (kB) |
? x40 | 16kB x60 | 48kB x28 | 16kB x56 | L1 does not appear changed but unclear. | |
| L2 Cache (MB) |
4MB | 4MB | 3MB | 4MB | L2 has not changed. | |
| Maximum Work-group Size |
1024 / 1024 | 256 / 1024 | 1024 / 2048 per SM | 256 / 1024 | AMD has unlocked work-group sizes to 4x. | |
| FP64/double ratio |
1/16x | 1/4x | 1/32x | 1/16x | Ratio is same as consumer Vega1 rather than pro Vega2. | |
| FP16/half ratio |
2x | 2x | 1/64x | 2x | Ratio is the same throughout. | |
Disclaimer
This is an independent article that has not been endorsed nor sponsored by any entity (e.g. AMD). All trademarks acknowledged and used for identification only under fair use.
The article contains only public information (available elsewhere on the Internet) and not provided under NDA nor embargoed. At publication time, the products have not been directly tested by SiSoftware and thus the accuracy of the benchmark scores cannot be verified; however, they appear consistent and do not appear to be false/fake.
Processing Performance
We are testing both OpenCL performance using the latest SDK / libraries / drivers from both AMD and competition.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and nVidia drivers. Turbo / Boost was enabled on all configurations.
| Processing Benchmarks | AMD Radeon 5700XT (Navi) | AMD Radeon VII (Vega2) | nVidia Titan X (Pascal) | AMD Radeon 56 (Vega1) | Comments | |
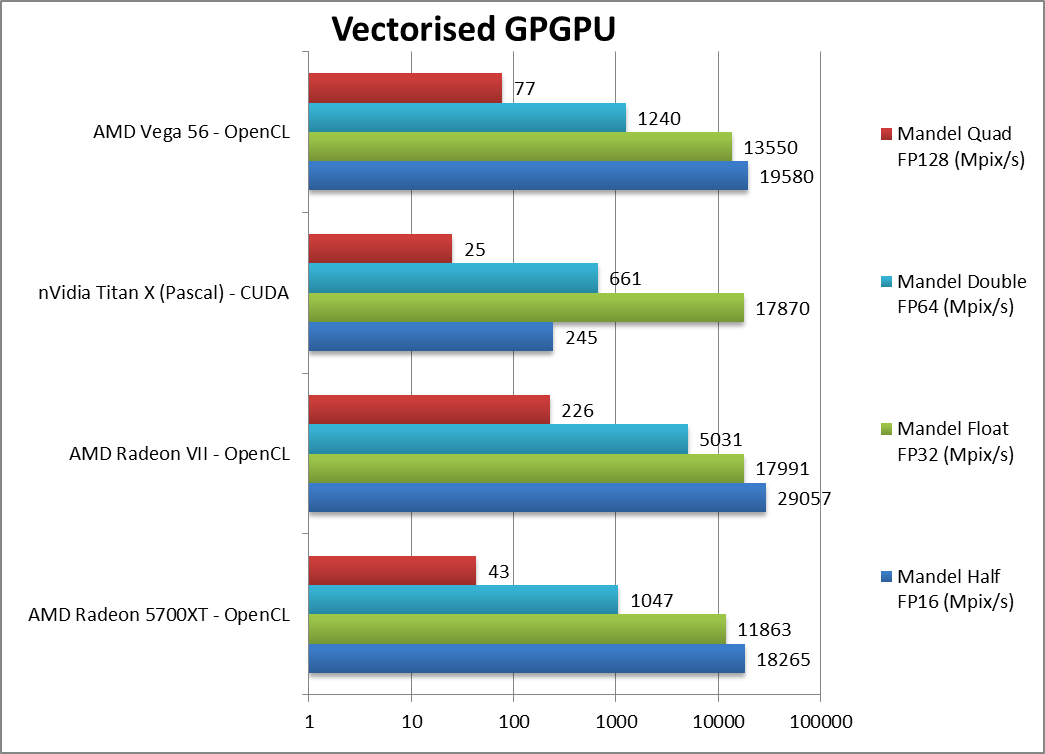 |
||||||
 |
Mandel FP16/Half (Mpix/s) | 18,265 [-7%] | 29,057 | 245 | 19,580 | Navi starts well but cannot beat Vega1. |
|
Mandel FP32/Single (Mpix/s) | 11,863 [-13%] | 17,991 | 17,870 | 13,550 | Standard FP32 increases the gap to 13%. |
|
Mandel FP64/Double (Mpix/s) | 1,047 [-16%] | 5,031 | 661 | 1,240 | FP64 does not change much, Navi is 16% slower. |
|
Mandel FP128/Quad (Mpix/s) | 43 [-45%] | 226 | 25 | 77 | Emulated FP128 is hard on FP64 units and here Navi is almost 1/2 Vega1. |
| Starting up, Navi does not seem to be able to beat Vega1 in heavy vectorised compute loads with FP16 most efficient (almost parity) while complex FP128 is 2x slower. | ||||||
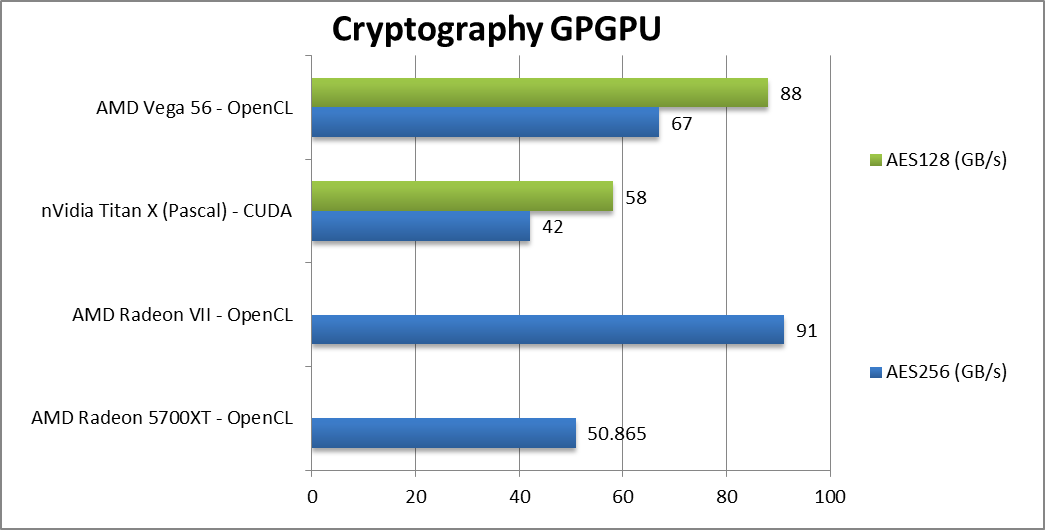 |
||||||
 |
Crypto AES-256 (GB/s) | 51 [-25%] | 91 | 42 | 67 | Despite more bandwidth Navi is 25% slower than Vega1. |
|
Crypto AES-128 (GB/s) | 58 | 88 | – | ||
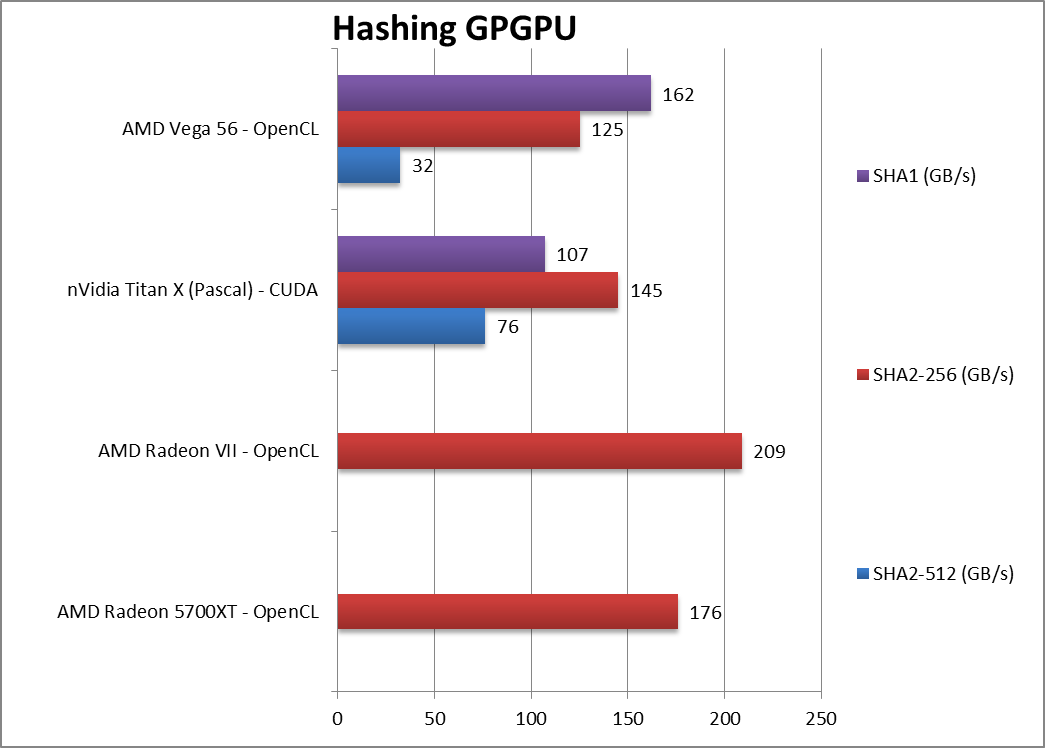 |
||||||
|
Crypto SHA2-256 (GB/s) | 176 [+40%] | 209 | 145 | 125 | Navi shows its power here beating Vega1 by a huge 40%! |
|
Crypto SHA1 (GB/s) | 107 | 162 | – | ||
|
Crypto SHA2-512 (GB/s) | 76 | 32 | – | ||
| Despite more bandwidth of GDDR6, streaming algorithms work better on on “old” HBM2 thus Navi cannot beat Vega. But in pure integer compute algorithms like hashing, it is much faster by a significant amount which bodes well for the future. | ||||||
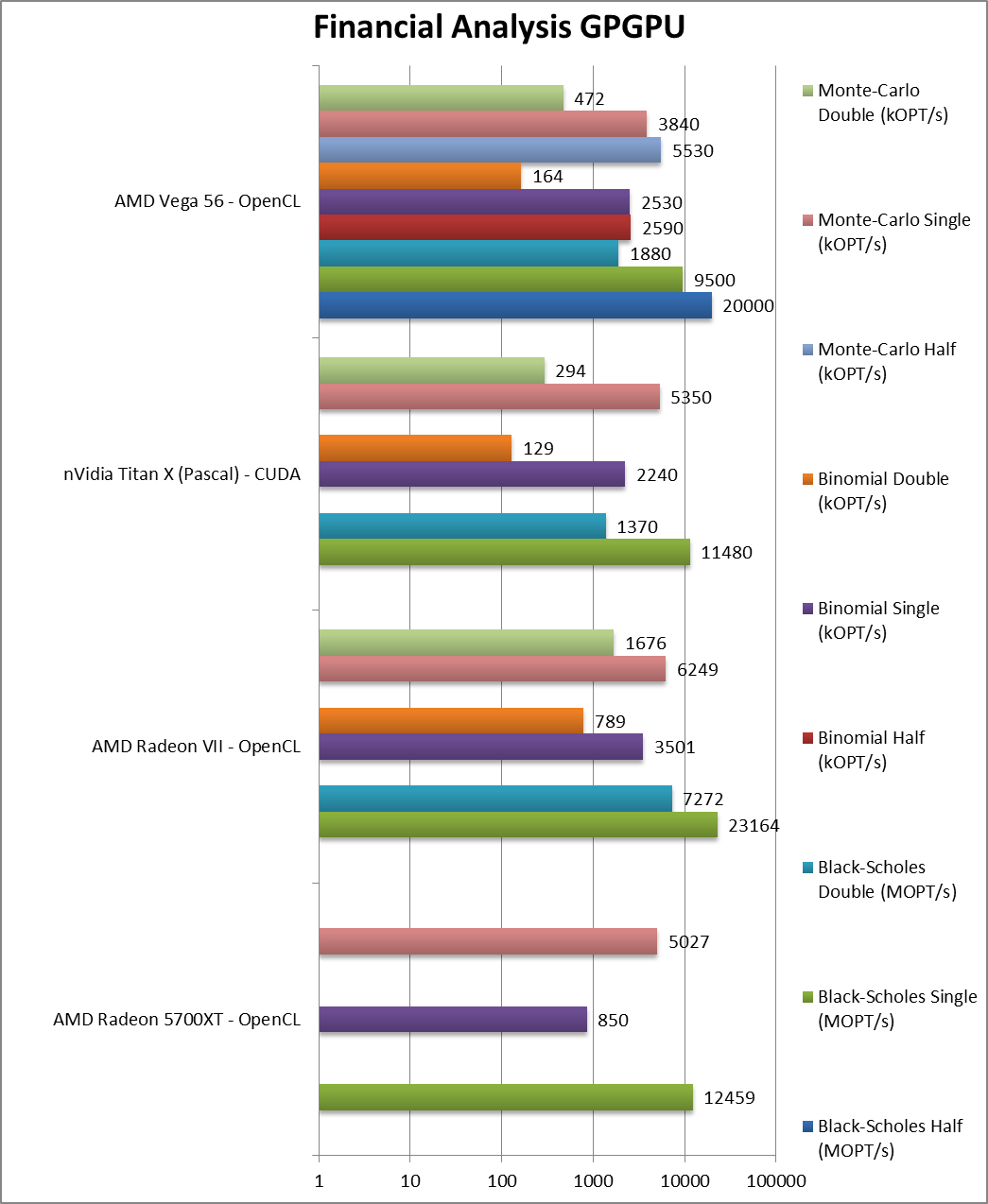 |
||||||
 |
Black-Scholes float/FP32 (MOPT/s) | 12,459 [+31%] | 23,164 | 11,480 | 9,500 | In this FP32 financial workload Navi is 30% faster than Vega1! |
|
Black-Scholes double/FP64 (MOPT/s) | 7,272 | 1,370 | 1,880 | – | |
|
Binomial float/FP32 (kOPT/s) | 850 [1/3x] | 3,501 | 2,240 | 2,530 | Binomial uses thread shared data thus stresses the memory system and here we have some optimisation to do. |
|
Binomial double/FP64 (kOPT/s) | 789 | 129 | 164 | – | |
|
Monte-Carlo float/FP32 (kOPT/s) | 5,027 [+30%] | 6,249 | 5,350 | 3,840 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure – here Navi is again 30% faster. |
|
Monte-Carlo double/FP64 (kOPT/s) | 1,676 | 294 | 472 | – | |
| For financial FP32 workloads, Navi is ~30% faster than Vega1 – a pretty good improvement – though it naturally cannot compete with Vega2 due to consumer multiplier (1/16x). Crypto-currencies fans will love the Navi. | ||||||
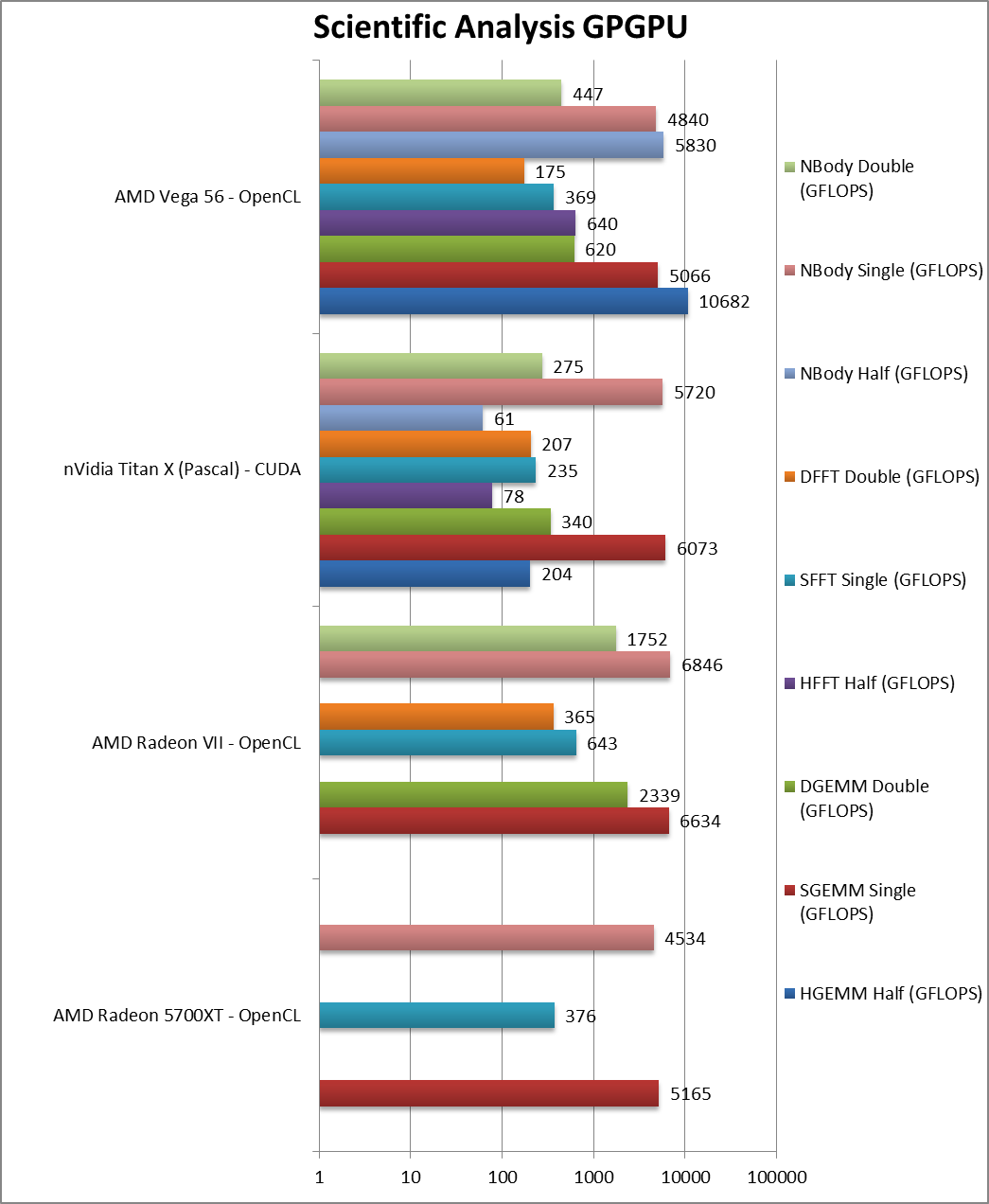 |
||||||
 |
SGEMM (GFLOPS) float/FP32 | 5,165 [+2%] | 6,634 | 6,073 | 5,066 | GEMM can only bring a measly 2% improvement over Vega1. |
|
DGEMM (GFLOPS) double/FP64 | 2,339 | 340 | 620 | – | |
|
SFFT (GFLOPS) float/FP32 | 376 [+2%] | 643 | 235 | 369 | FFT loves HBM but Navi is still 2% faster. |
|
DFFT (GFLOPS) double/FP64 | 365 | 207 | 175 | – | |
|
SNBODY (GFLOPS) float/FP32 | 4,534 [-6%] | 6,846 | 5,720 | 4,840 | Navi can’t manage as well in N-Body and ends up 6% slower. |
|
DNBODY (GFLOPS) double/FP64 | 1,752 | 275 | 447 | – | |
| The scientific scores don’t show the same improvement as the financial ones likely due to heavy use of shared memory with Navi just matching Vega1. Perhaps the larger shared memory can allow us to use larger workgroups. | ||||||
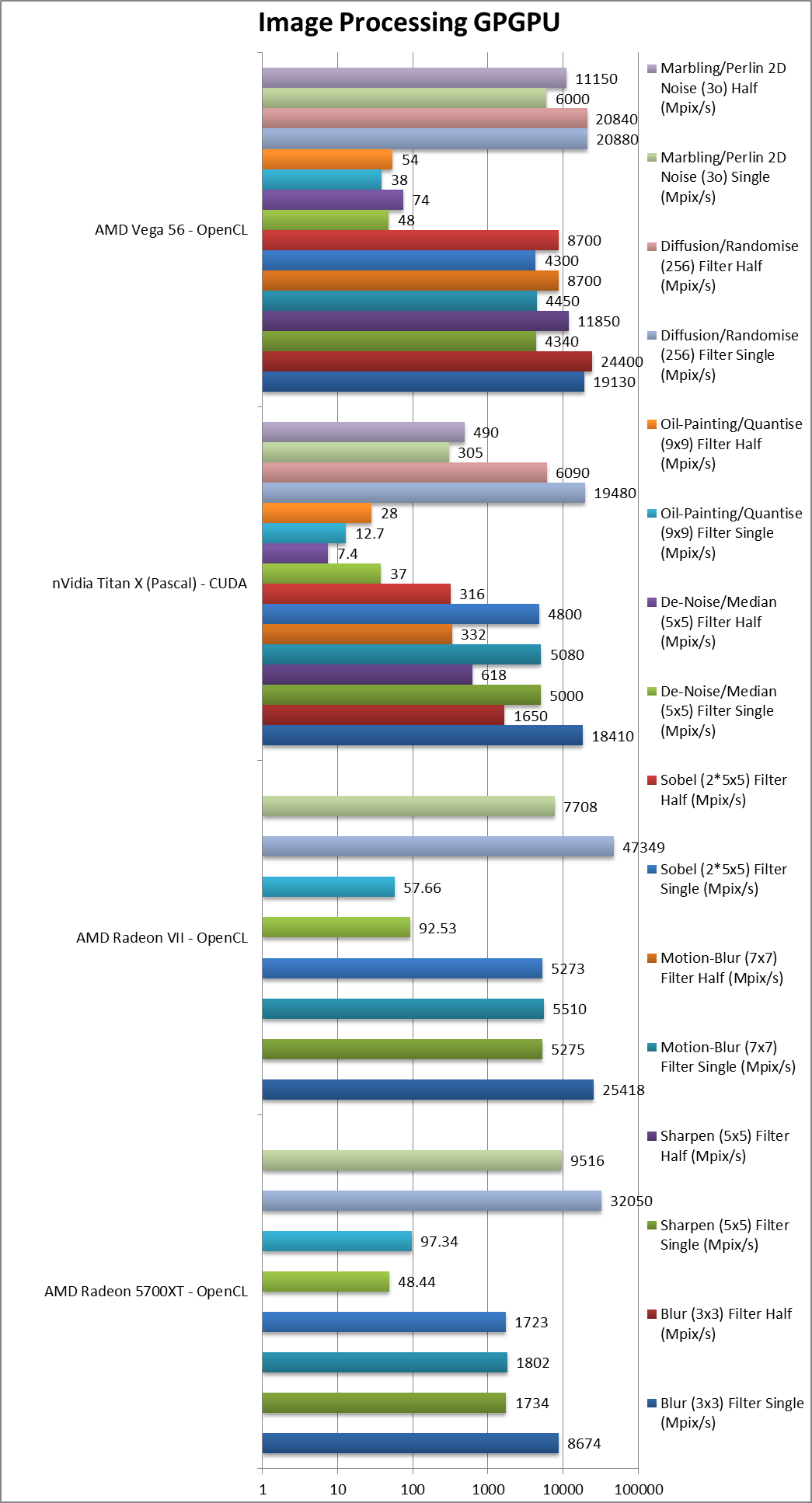 |
||||||
 |
Blur (3×3) Filter single/FP32 (MPix/s) | 8,674 [1/2.1x] | 25,418 | 18,410 | 19,130 | In this 3×3 convolution algorithm, Navi is 1/2x the speed of Vega1. |
|
Sharpen (5×5) Filter single/FP32 (MPix/s) | 1,734 [1/3x] | 5,275 | 5,000 | 4,340 | Same algorithm but more shared data makes Navi even slower. |
|
Motion Blur (7×7) Filter single/FP32 (MPix/s) | 1,802 [1/2.5x] | 5,510 | 5,080 | 4,450 | With even more data the gap remains at 1/2.5x. |
|
Edge Detection (2*5×5) Sobel Filter single/FP32 (MPix/s) | 1,723 [1/2.5x] | 5,273 | 4,800 | 4,300 | Still convolution but with 2 filters – same 1/2.5x performance. |
|
Noise Removal (5×5) Median Filter single/FP32 (MPix/s) | 48.44 [=] | 92.53 | 37 | 48 | Different algorithm allows Navi to tie with Vega1. |
|
Oil Painting Quantise Filter single/FP32 (MPix/s) | 97.34 [+2.5x] | 57.66 | 12.7 | 38 | Without major processing, this filter performs well on Navi. |
|
Diffusion Randomise (XorShift) Filter single/FP32 (MPix/s) | 32,050 [+1.5x] | 47,349 | 19,480 | 20,880 | This algorithm is 64-bit integer heavy and Navi is 50% faster than Vega1. |
|
Marbling Perlin Noise 2D Filter single/FP32 (MPix/s) | 9,516 [+1.6x] | 7,708 | 305 | 6,000 | One of the most complex and largest filters, Navi is again 50% faster. |
| For image processing using FP32 precision, Navi goes from 1/2.5x Vega1 performance (convolution) to 50% faster (complex algorithms with integer processing). It seems some optimisations are needed for the convolution algorithms. | ||||||
Memory Performance
We are testing both OpenCL performance using the latest SDK / libraries / drivers from AMD and competition.
Results Interpretation: For bandwidth tests (MB/s, etc.) high values mean better performance, for latency tests (ns, etc.) low values mean better performance.
Environment: Windows 10 x64, latest AMD and nVidia. drivers. Turbo / Boost was enabled on all configurations.
| Memory Benchmarks | AMD Radeon 5700X (Navi) | AMD Radeon VII (Vega2) | nVidia Titan X (Pascal) | AMD Radeon 56 (Vega1) | Comments | |
 |
||||||
 |
Internal Memory Bandwidth (GB/s) | 376 [+13%] | 627 | 356 | 333 | Navi’s GDDR6 manages 13% more bandwidth than Vega1. |
|
Upload Bandwidth (GB/s) | 21.56 [+77%] | 12.37 | 11.4 | 12.18 | PCIe 4.0 brings almost 80% more bandwidth |
|
Download Bandwidth (GB/s) | 22.28 [+84%] | 12.95 | 12.2 | 12.08 | Again almost 2x more bandwidth. |
| Navi’s PCIe 4.0 interface (on 500-series AMD motherboards) brings as expected almost 2x more upload/download bandwidth while its high-clocked GDDR6 manages just over 10% higher bandwidth over HBM2. | ||||||
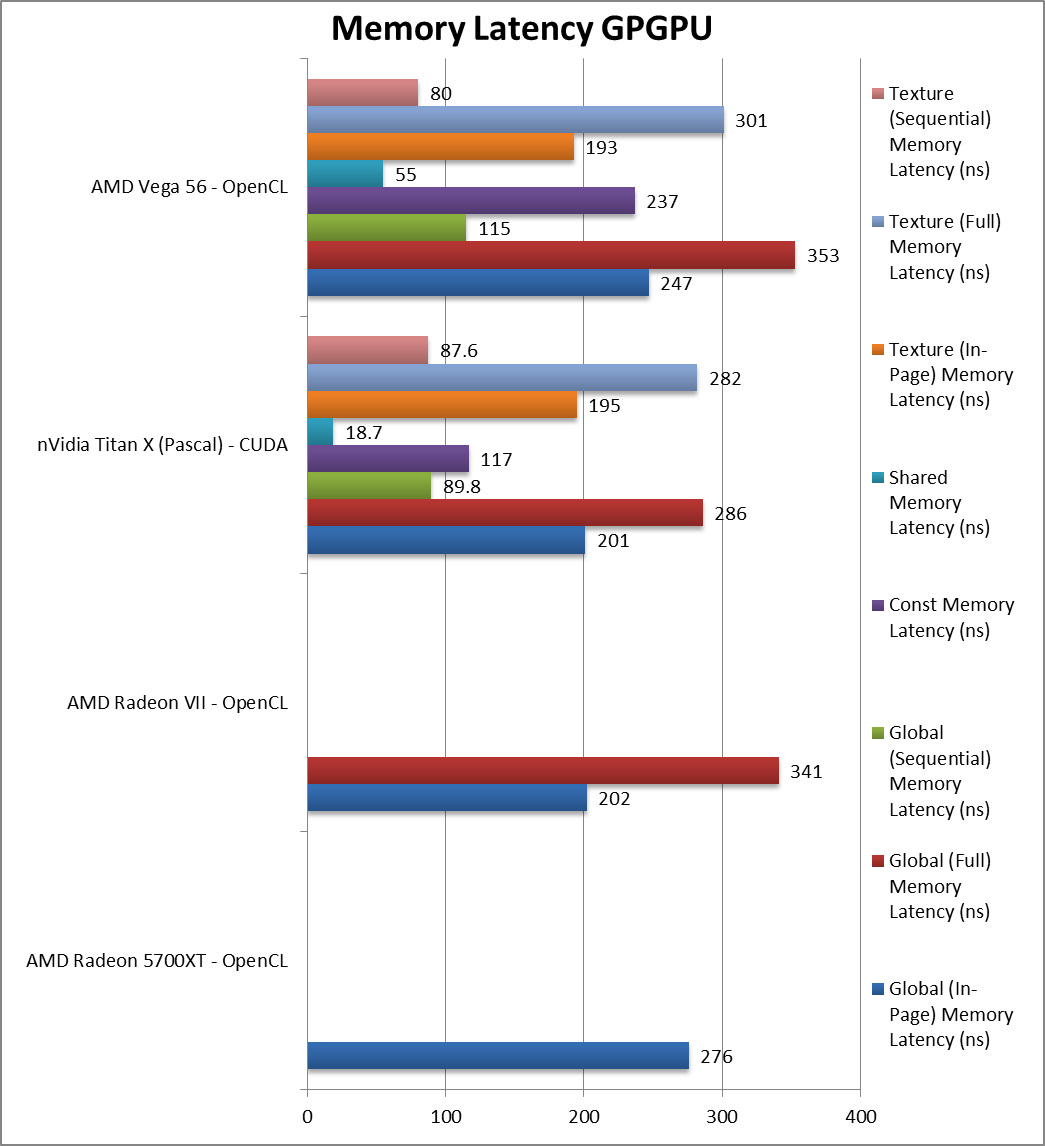 |
||||||
 |
Global (In-Page Random Access) Latency (ns) | 276 [+11%] | 202 | 201 | 247 | Navi’s GDDR6 brings slight latency increase (+10%) |
|
Global (Full Range Random Access) Latency (ns) | 341 | 286 | 353 | – | |
|
Global (Sequential Access) Latency (ns) | 89.8 | 115 | – | ||
|
Constant Memory (In-Page Random Access) Latency (ns) | 117 | 237 | – | ||
|
Shared Memory (In-Page Random Access) Latency (ns) | 18.7 | 55 | – | ||
|
Texture (In-Page Random Access) Latency (ns) | 195 | 193 | – | ||
|
Texture (Full Range Random Access) Latency (ns) | 282 | 301 | – | ||
|
Texture (Sequential Access) Latency (ns) | 87.6 | 80 | – | ||
| Not unexpected, GDDR6′ latencies are higher than HBM2 although not by as much as we were fearing. | ||||||
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
“Navi” is an interesting chip to be sure and perhaps more was expected of it; as always the drivers are the weak link and it is hard to determine which issues will be fixed driver-side and which will need to be optimised in compute kernels.
Thus performance-wise it oscillates between 1/2x and 50% Vega1 performance depending on algorithm, with compute-heavy algorithms (especially crypto-currencies) doing best and shared/local memory heavy algorithms doing worst. The 2x bigger shared memory (64kB vs 32) in conjunction with the larger work-group (1024 vs 256 by default) sizes do present future optimisation opportunities. AMD has also reduced the warp/wave size to match nVidia – a historic change.
Memory wise, the cost-cutting change from HBM2 to even high-speed GDDR6 does bring more bandwidth but naturally higher latencies – but PCIe 4.0 doubles upload/download bandwidths which will become much more important on higher capacity (16GB+) cards in the future.
Overall it is hard to recommend it for compute workloads unless the particular algorithm (crypto, financial) does well on Navi, otherwise the much older Vega1 56/64 offer better performance/cost ratio especially today. However, as drivers mature and implementations are optimised for it, Navi is likely to start to perform better.
We are looking forward to the next iterations of Navi, especially the rumored “big Navi” version optimised for compute… [See article AMD Radeon RX 6900XT (RDNA2, Navi2) Review & Benchmarks – GPGPU Performance]
Disclaimer
This is an independent article that has not been endorsed nor sponsored by any entity (e.g. AMD). All trademarks acknowledged and used for identification only under fair use.
The article contains only public information (available elsewhere on the Internet) and not provided under NDA nor embargoed. At publication time, the products have not been directly tested by SiSoftware and thus the accuracy of the benchmark scores cannot be verified; however, they appear consistent and do not appear to be false/fake.