What is “Cascade Lake (CSL-X)”?
It is one of the 10th generation Core X-Series arch (CSL-X) from Intel – the latest revision of the “Skylake-X” (SKL-X) arch; it succeeds the older 9900 and 7900 X-Series for HEDT platform. Again, as on the desktop/mobile – it is not the “real” 10th generation Core-X arch – but unlike those platforms – it does actually bring a few more features thus it may be thought as “gen 9.5”:
- Up to 18C/36T (matching older 7/9-X series)
- Increased Turbo ratios (e.g. 3.0/4.6GHz for 10980X vs. 2.6/4.2 for 7980X)
- 4-channel DDR4-2933 (up from 2667) and 256GB (up from 128)
- AVX512-VNNI, aka “Deep Learning Boost” (DLB) for AI/ML neural networks
- Hardware fixes/mitigations for vulnerabilities (“Meltdown”, “MDS”, various “Spectre” types)
- Reduced cost – by 50% ($999 for 10980X vs. $1999 for 7980X)
Unfortunately there are no core-count increases here as the CPUs are still power limited especially with AVX512 loads, but we do have some base and turbo ratio increases that should come in useful. We also get a good increase in (official) memory data-speed support and double memory size support (256GB!) for those big servers.
New instruction sets are always appreciated, though “VNNI” is just an acceleration for twin 8/16-bit integer multiply/accumulate for faster summation for low-precision quantised (thus integer not floating-point) neural networks. Thus it is not something most algorithms can benefit from: if all you’re going to be using your CPU is AI/ML then great – otherwise it may not be much use.
Dropping the price by a *huge* 50% instantly doubles performance/cost ratio making the CSL-X far more competitive against the new Ryzen 3 / ThreadRipper 3 that have brought big performance gains. Alternatively, it also allows almost doubling the no. of cores/cost – which is a nice upgrade for lower-end users but will not help top-end (12C+) users.
Why review it now?
Until “IceLake” (ICL-X) makes its public debut, “Cascade Lake” is the latest X-Series CPU from Intel you can buy today; despite being just a revision of “Skylake-X” due to its reduced price they may still prove worthy competitors not just in cost but also performance.
As they contain hardware fixes/mitigations for vulnerabilities discovered since original “Skylake-X” has launched (especially “Meltdown” but also various “Spectre” variants), the operating system & applications do not need to deploy slower mitigations that can affect performance (especially I/O, virtualisation) on the older designs. For some algorithms, this may be enough to warrant an upgrade alone!
In this article we test CPU core performance; please see our other articles on:
Other articles using Sandra around the Internet:
Hardware Specifications
We are comparing the top-of-the-range Intel ULV with competing architectures (gen 8, 7, 6) as well as competiors (AMD) with a view to upgrading to a mid-range but high performance design.
| CPU Specifications | Intel Core i9-10980X (CSL-X) |
Intel Core i9-9900K (CFL-R) |
Intel Core i9-7900X (SKL-X) |
AMD Ryzen 9 3950X (Zen2) |
Comments | |
| Cores (CU) / Threads (SP) | 18C / 36T | 8C / 16T | 10C / 20T | 16C / 32T | CSL-X has the most cores thus a big advantage. | |
| Speed (Min / Max / Turbo) | 3.0 – 4.6GHz | 3.6 – 5.0GHz | 3.3-4.3GHz | 3.8-4.6GHz | CSL-X improves Turbo clock over SKL-X | |
| Power (TDP) | 165 – 250W | 95 – 135W | 140 – 250W | 105 – 135W | TDP has increased over SKL-X | |
| L1D / L1I Caches | 18x 32kB / 18x 32kB | 8x 32kB / 8x 32kB | 10x 32kB / 10x 32kB | 16x 32kB / 16x 32kB | No L1 change | |
| L2 Caches | 18x 1MB (18MB) | 8x 256kB (2MB) | 10x 1MB (10MB) | 16x 512kB (8MB) | No L2 change and good size vs. Ryzen3 | |
| L3 Caches | 24.75MB | 16MB | 13.75MB | 4x 16MB (64MB) | L3/Core stays the same – too little vs. Ryzen3 | |
| Microcode (Firmware) | MU065507-29 | MU069E0C-9E | MU065504-49 | MU8F7100-11 | Just a stepping change of the same core | |
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (AVX2, AVX, etc.). “CometLake” (CML) supports all modern instruction sets including AVX2, FMA3 but not AVX512 (like “IceLake”) or SHA HWA (like Atom, Ryzen).
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
| Native Benchmarks | Intel Core i9-10980X (18C/36T) | Intel Core i9-9900K (8C/16T) | Intel Core i9-7900X (10C/20T) | AMD Ryzen 9 3950X (16C/32T) | Comments | |
 |
||||||
 |
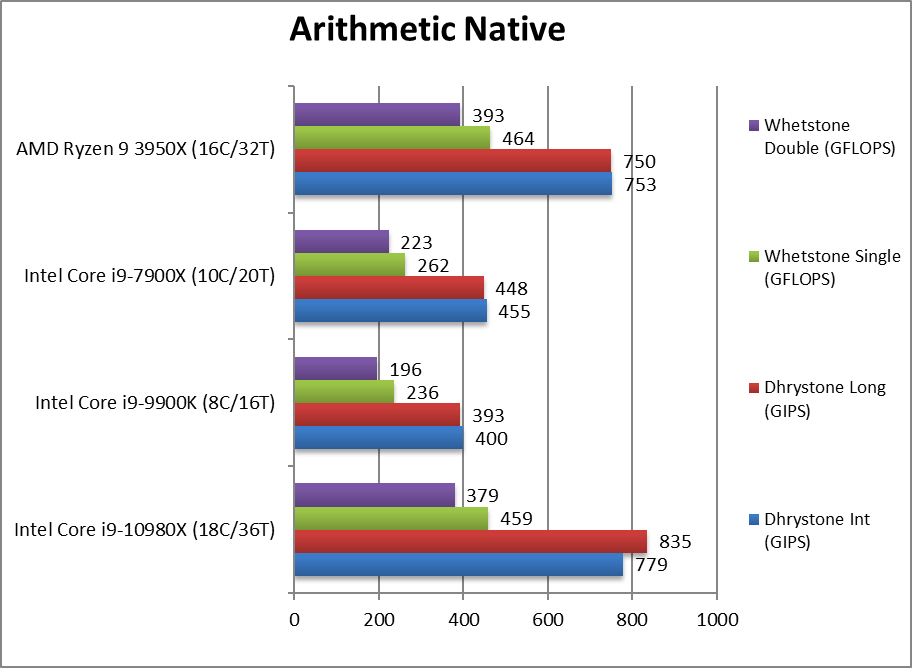
Native Dhrystone Integer (GIPS) | 779 [+3%] | 400 | 455 | 753 | CSL-X is just 3% faster than Ryzen3. |
|
Native Dhrystone Long (GIPS) | 835 [+11%] | 393 | 448 | 750 | With a 64-bit integer workload – the gain is 11%. |
|
Native FP32 (Float) Whetstone (GFLOPS) | 459 [-1%] | 236 | 262 | 464 | With floating-point workload we have a tie. |
|
Native FP64 (Double) Whetstone (GFLOPS) | 379 [-4%] | 196 | 223 | 393 | With FP64 it is 4% slower than R3. |
| Despite its extra 2 cores (18 vs. 16 Ryzen 3), CSL-X pretty much ties with Ryzen3 across both legacy workloads (integer and floating-point). The performance increase vs. the older SKL-X is pretty much inline with the no cores (18 vs. 10) thus no discernible core improvement. | ||||||
 |
||||||
 |
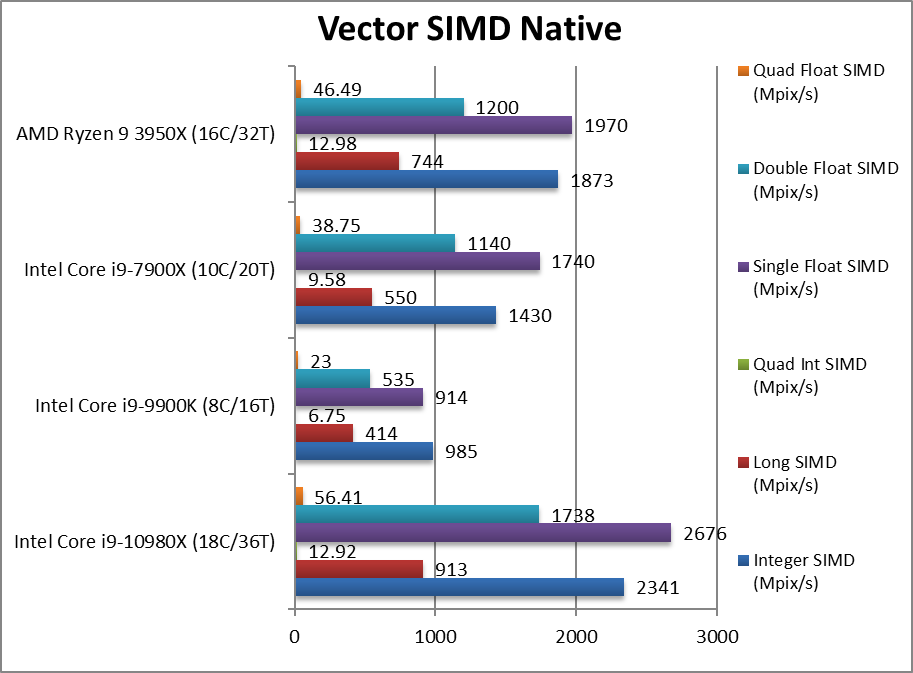
Native Integer (Int32) Multi-Media (Mpix/s) | 2,341 [+25%] | 985 | 1,430 | 1,873 | In this vectorised integer test, AVX512 allows CSL-X a 25% win. |
|
Native Long (Int64) Multi-Media (Mpix/s) | 913 [+23%] | 414 | 550 | 744 | With a 64-bit AVX2 integer workload the gain is 23%. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 12.92 [=] | 6.75 | 9.58 | 12.98 | This is a tough test using Long integers to emulate Int128 without SIMD it’s a tie. |
|
Native Float/FP32 Multi-Media (Mpix/s) | 2,676 [+36%] | 914 | 1,740 | 1,970 | In this floating-point vectorised test, CSL-X is 36% faster. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 1,738 [+45%] | 535 | 1,140 | 1,200 | Switching to FP64 SIMD code, the gain is 45%. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 56.4 [+21%] | 23 | 38.7 | 46.5 | In this heavy algorithm using FP64 to mantissa extend FP128 CSL-X is 21% faster. |
| Thanks to AVX512 support, CSL-X still manages to beat the new Ryzen3 (with its double-width SIMD units) by ~25% on vectorised integer and ~40% on floating-point workloads. With older AVX2/FMA we have a tie despite the extra 2 cores. Again, no appreciable delta vs. the old SKL-X thus without VNNI support there is nothing to see here. | ||||||
 |
||||||
 |
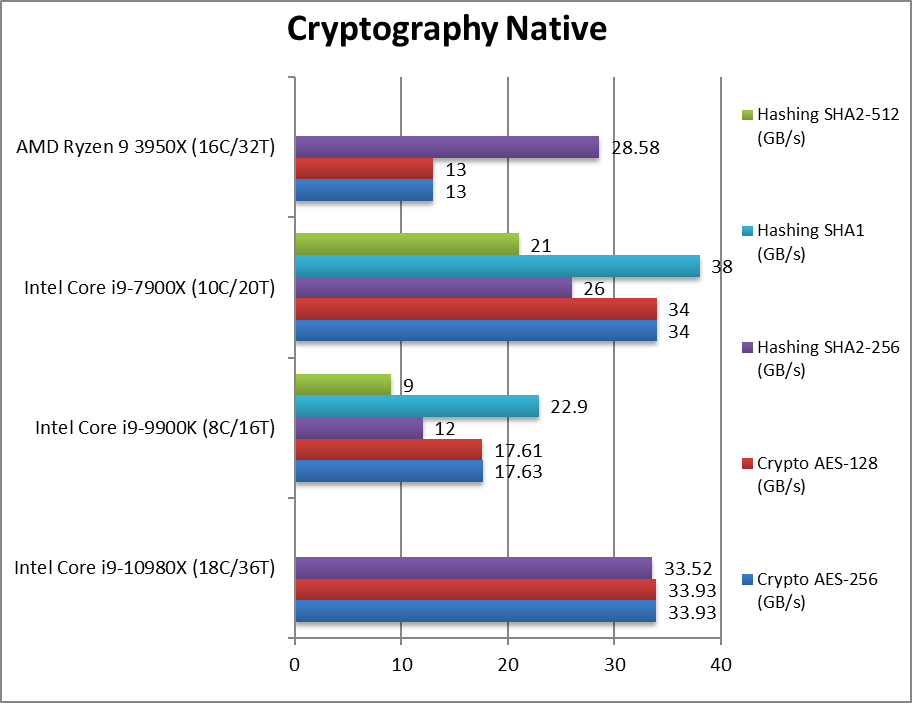
Crypto AES-256 (GB/s) | 33.9 [2.6x] | 17.6 | 34 | 13 | With AES/HWA support CSL-X wins due to 4-channels. |
|
Crypto AES-128 (GB/s) | 33.9 [2.6x] | 17.6 | 34 | 13 | No change with AES128. |
|
Crypto SHA2-256 (GB/s) | 33.5 [+17%] | 12 | 26 | 28.6 | Without SHA/HWA CSL-X still wins. |
|
Crypto SHA1 (GB/s) | 22.9 | 38 | Less compute intensive SHA1 . | ||
|
Crypto SHA2-512 (GB/s) | 9 | 21 | SHA2-512 is not accelerated by SHA/HWA. | ||
| The memory sub-system is crucial here, and with 4-channel DDR4 CSL-X easily wins against Ryzen3 even lacking SHA/HWA support. But again, nothing special vs. old SKL-X at 3200Mt/s that ties with it despite less cores. But if you were to use only “official/non-XMP” clocks then CSL-X would win. | ||||||
 |
||||||
 |
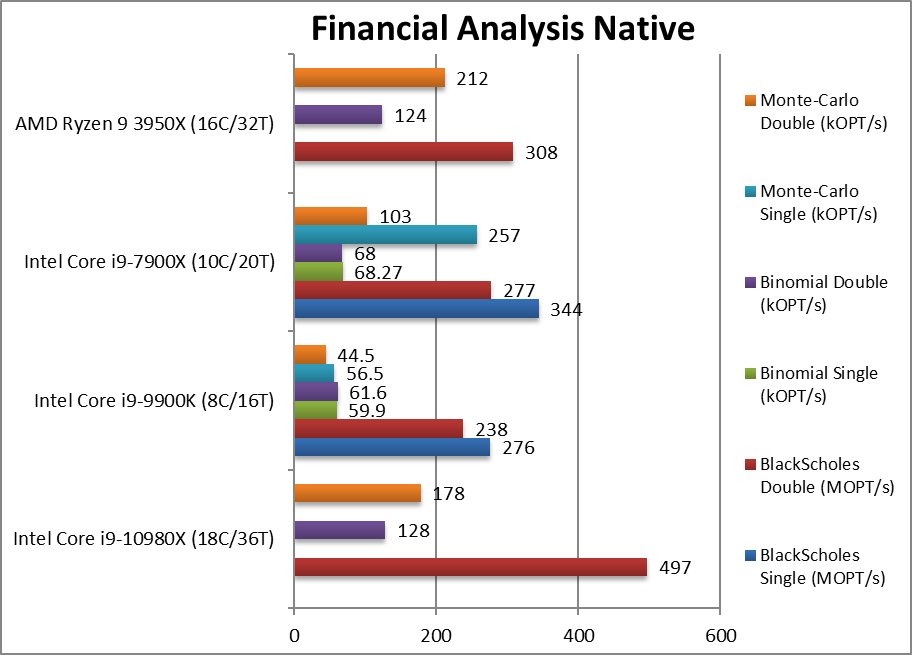
Black-Scholes float/FP32 (MOPT/s) | 276 | 344 | With non vectorised workload. | ||
|
Black-Scholes double/FP64 (MOPT/s) | 497 [+61%] | 238 | 277 | 308 | Using FP64 CSL-X is 60% faster than Ryzen3. |
|
Binomial float/FP32 (kOPT/s) | 59.9 | 68.3 | Binomial uses thread shared data thus stresses the cache & memory system. | ||
|
Binomial double/FP64 (kOPT/s) | 128 [+3%] | 61.6 | 68 | 124 | With FP64 code CSL-X is just 3% faster. |
|
Monte-Carlo float/FP32 (kOPT/s) | 56.5 | 257 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches. | ||
|
Monte-Carlo double/FP64 (kOPT/s) | 178 [-16%] | 44.5 | 103 | 212 | Switching to FP64 CSL-X is 16% slower. |
| With non-SIMD financial workloads, CSL-X does not always win outright over Ryzen3, sometimes it ties, sometimes it is slower and sometimes faster. It is a big improvement over SKL-X only due to having more cores at the same price. | ||||||
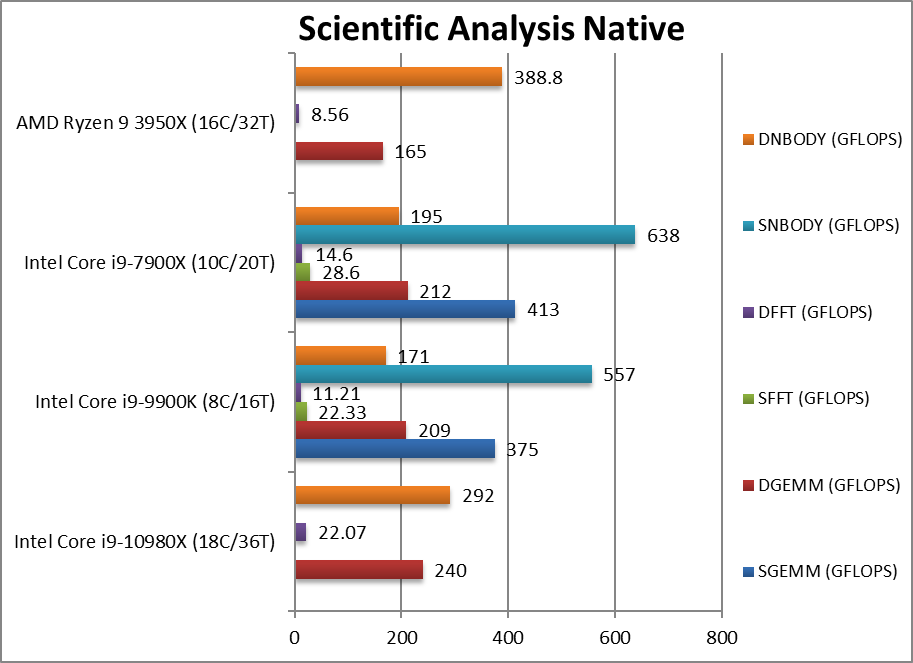 |
||||||
 |
SGEMM (GFLOPS) float/FP32 | 375 | 413 | In this tough vectorised AVX2/FMA algorithm. | ||
|
DGEMM (GFLOPS) double/FP64 | 240 [+45%] | 209 | 212 | 165 | With FP64 vectorised code, CSL-X is 45% faster. |
|
SFFT (GFLOPS) float/FP32 | 22.3 | 28.6 | FFT is also heavily vectorised but stresses the memory sub-system more. | ||
|
DFFT (GFLOPS) double/FP64 | 22.07 [+2.6x] | 11.21 | 14.6 | 8.56 | With FP64 code, CSL-X is over 2x faster. |
|
SNBODY (GFLOPS) float/FP32 | 557 | 638 | N-Body simulation is vectorised but with more memory accesses. | ||
|
DNBODY (GFLOPS) double/FP64 | 292 [-25%] | 171 | 195 | 388 | With FP64 code CSL-X is 25% slower. |
| With highly vectorised SIMD code (scientific workloads) using AVX512 – CSL-X easily wins again (up to 50% faster) over Ryzen3 but again nothing special over older SKL-X save its more cores. You will need AVX512 optimised algorithms though to realise these gains, otherwise it is again pretty much a tie vs. Ryzen3. | ||||||
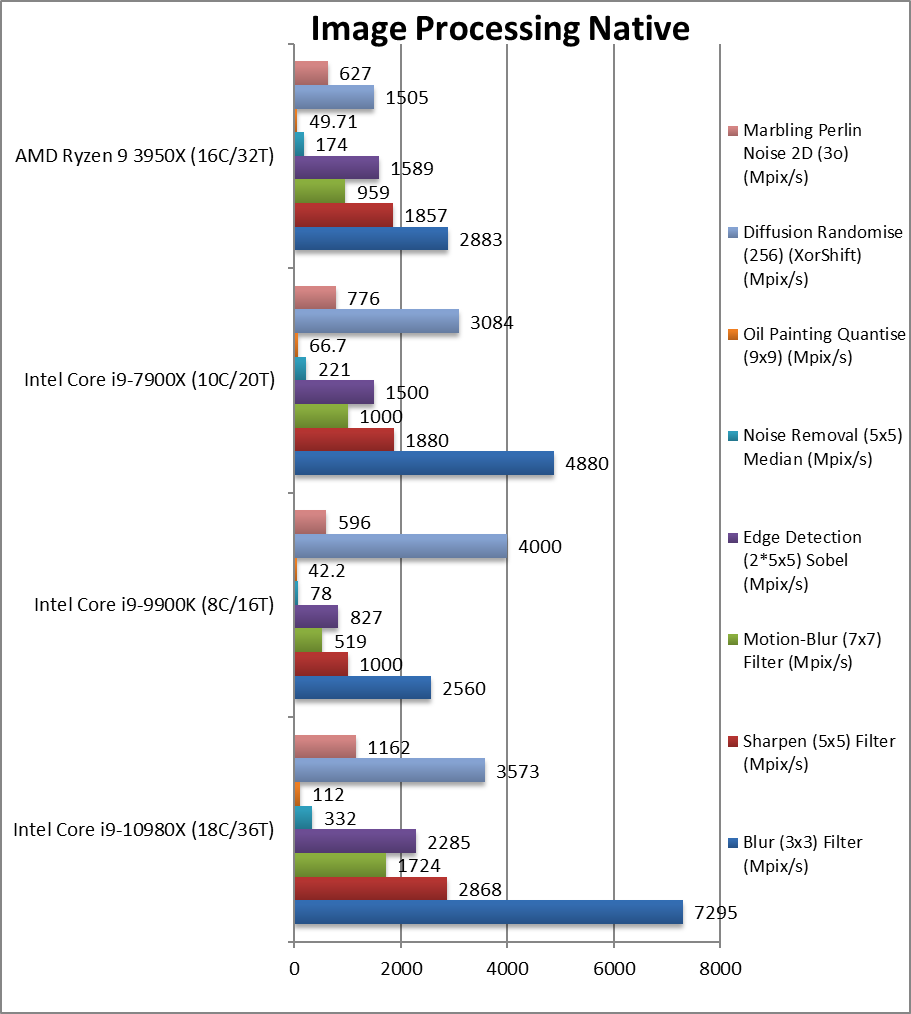 |
||||||
 |
Blur (3×3) Filter (MPix/s) | 7,295 [+2.53x] | 2,560 | 4,880 | 2,883 | In this vectorised integer workload CSL-X is 2.5x faster. |
|
Sharpen (5×5) Filter (MPix/s) | 2,868 [+54%] | 1,000 | 1,880 | 1,857 | Same algorithm but more shared data still 54%. |
|
Motion-Blur (7×7) Filter (MPix/s) | 1,724 [+80%] | 519 | 1,000 | 959 | Same algorithm but even more data shared 80% faster. |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 2,285 [+44%] | 827 | 1,500 | 1,589 | Different algorithm but still vectorised workload 44% faster. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 332 [+91%] | 78 | 221 | 174 | Still vectorised code again almost 2x faster. |
|
Oil Painting Quantise Filter (MPix/s) | 112 [+2.25x] | 42.2 | 66.7 | 49.7 | Even better improvement here of 2.25x |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 3,573 [2.37x] | 4,000 | 3,084 | 1,505 | With integer workload 2.5x faster. |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 1,162 [+85%] | 596 | 776 | 627 | In this final test again with integer workload CSL-X is 85% faster. |
Thanks to AVX512 CSL-X manages to easily beat Ryzen3 in heavily vectorised algorithms (up to 50% faster) and also in memory-bandwidth heavy algorithms (due to its 4-channels memory sub-system). But, despite having 2 extra cores, on older AVX2/FMA we pretty much have a tie – not something we are used to see from Intel.
Also, the improvement over older SKL-X is exactly in-line with the increase in cores (18 vs. 10 here) – thus there are no appreciable core improvements to boost performance. Without specific VNNI-accelerated algorithms, there is no point for SKL-X users to upgrade: you do get more cores for a lot less money but your hardware is also worth a lot less.
It shows how much Ryzen3 has improved (especially due to 256-bit width AVX2/FMA units) and ThreadRipper with 4-channels and even more cores (up to 32!) and threads (up to 64!) should nullify Intel’s AVX512 benefit.
SiSoftware Official Ranker Scores
- Intel Core i9-10980XE 18-core/36-threads
- Intel Core i9-10940X 14-core/28-threads
- Intel Core i9-10920X 12-core/24-threads
- Intel Core i9-10900X 10-core/20-threads
Final Thoughts / Conclusions
For many, it may be disappointing that we do not have the brand-new “IceLake-X” (ICL-X) now rather than a 3-rd revision “Skylake-X” – and indeed “Cascade Lake-X” (CSL-X) does struggle against newer (and older) competition to make its mark. Without core-count increases and with minor clock increases while still very limited by power at the high end it just does not bring enough improvement. The only exception are workloads (low-precision quantised neural networks) that can use AVX512-VNNI.
Indeed, its “ace card” is the 1/2 price reduction vs. old 7/9-X series and that just about makes it competitive; thankfully existing X299 mainboards can use it through a BIOS/ME update – although boards are still expensive.
But the competition (AMD Ryzen 3, ThreadRipper 3) has much higher performance these days while older CPUs (Ryzen 2 / ThreadRipper 2) have also been greatly reduced in price. They also can use older boards, although to use new features (PCIe 4.0, better power management) new boards are required.
All in all, Intel has done all it can – fix vulnerabilities, greatly reduce the price – to keep the X-Series competitive with current designs – and that it has pretty much achieved. The next X-Series arch better deliver otherwise it will be dead and buried.
In a word: Recommended due to 1/2 price drop
Please see our other articles on: