What is “RocketLake”?
It is the desktop/workstation version of the true “next generation” Core (gen 10+) architecture – finally replacing the ageing “Skylake (SKL)” arch and its many derivatives that are still with us (“CometLake (CML)”, etc.). It is a combination of the “IceLake (ICL)” CPU cores launched about a year go and the “TigerLake (TGL)” Gen12 XE graphics cores launched recently.
With the new core we get a plethora of new features – some previously only available on HEDT platform (AVX512 and its many friends), improved L1/L2 caches, improved memory controller and PCIe 4.0 buses. Sadly Intel had to back-port the older ICL (not TGL) cores to 14nm – we shall have to wait for future (desktop) processors “AlderLake (ADL)” to see 10nm on the desktop…
- 14nm+++ improved process (not 10nm)
- Up to 8C/16T “Cypress Cove” cores aka 14nm+++ “Sunny Cove” from ICL
- Increased L1D cache to 48kB (50% larger)
- Increased L2 cache to 512MB (2x as large)
- Hardware fixes/mitigations for vulnerabilities (“JCC”, “Meltdown”, “MDS”, various “Spectre” types)
- TVB (Thermal Velocity Boost) for Core i9 only
- ABT (Adaptive Boost Technology) for Core i9-K(F) only
In this article we test Cache & Memory performance; please see our other articles on:
- Intel 12th Gen Core AlderLake (i9-12900K) Review & Benchmarks – big/LITTLE Performance
- Intel 11th Gen Core RocketLake AVX512 Performance Improvement vs. AVX2/FMA3
- Intel 11th Gen Core RocketLake (i7-11700K) Review & Benchmarks – CPU AVX512 Performance
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!
Hardware Specifications
We are comparing the top-of-the-range Intel with competing architectures as well as competiors (AMD) with a view to upgrading to a mid-range but high performance design.
| Specifications | Intel Core i9 11900K 8C/16T (RKL) | AMD Ryzen 9 5900X 12C/24T (Zen3) | Intel Core i9 10900K 10C/20T (CML) | Intel Core i9 7900X 10C/20T (SKL-X) | Comments | |
| Arch(itecture) | Cypress Cove / RocketLake | Zen3 / Vermeer | Comet Lake | Skylake-X | Not the very latest arch. | |
| Power TDP/Turbo (W) |
125 – 250 | 105 – 135 | 125 – 155 | 140 – 308 | TDP is the same on paper. | |
| L1D / L1I Caches | 8x 48kB 12-way [+50%] / 8x 32kB 8-way | 12x 32kB 8-way / 12x 32kB 8-way | 10x 32kB 8-way / 10x 32kB 8-way | 10x 32kB 8-way / 10x 32kB 8-way | L1D is 50% larger. | |
| L2 Caches | 8x 512kB 16-way [2x] | 12x 512kB 16-way | 10x 256B 16-way | 10x 1MB 16-way | L2 has doubled. | |
| L3 Caches | 16MB 16-way [=] | 2x 32MB 16-way | 20MB 16-way | 13.75MB 11-way | L3 is the same | |
| L1 Data TLBs |
4kB : 64 4-Way (256kB) / 2MB : 32 4-Way (64MB) / 1GB : 8 255-Way (8GB) | 4kB : 64 Full-Way (256kB) \ 2MB : 64 Full-Way (128MB) \ 1GB : 64 Full-Way (64GB) | 4kB : 64 4-Way (256kB) \ 1GB : 4 4-Way (4GB) | 4kB : 64 4-Way (256kB) \ 1GB : 4 4-Way (4GB) | Huge-page L1 data TLB has increased. | |
| L1 Instruction TLBs |
4kB : 24 Full-Way (96kB) / 2MB : 24 Full-Way (48MB) / 1GB : 16 Full-Way (16GB) | 4kB : 64 Full-Way (256kB) \ 2MB : 64 Full-Way (128MB) \ 1GB : 64 Full-Way (64GB) | 4kB : 64 8-Way (256kB) \ 2MB : 8 Full-Way (16MB) | 4kB : 64 8-Way (256kB) \ 2MB : 8 Full-Way (16MB) | We have fully-associative L1 instruction TLB now. | |
| L2 TLBs |
4kB : 2,048 8-Way (8MB) / 2MB : 1,024 8-Way (2GB) / 1GB : 1,024 8-Way (1TB) | 4kB : 2,048 8-Way (8MB) \ 2MB : 2,048 4-Way (4GB) \ 1GB : 64 Full-Way (64GB) | 4kB : 1,536 6-Way (6MB) \ 2MB : 1,536 6-Way (3GB) | 4kB : 1,536 6-Way (6MB) \ 2MB : 1,536 6-Way (3GB) | L2 TLBs have been bumped up to 2,048. | |
| Memory Controller Speed (MHz) | 3,600 [=] | 1,600 | 3,600 | 2,700 | Same controller clock. | |
| Memory Speed (MHz) Max |
3,200 [=] | 3,200 | 3,200 | 3,200 | Data rate is the same. | |
| Memory Channels / Width |
128-bit | 128-bit | 128-bit | 256-bit | Only SKL-X has 4 channels. | |
| Memory Timing (clocks) |
16-18-18-36 6-54-24-12 2T | 16-18-18-36 8-75-24-12 1T | 16-17-17-35 7-60-20-10 2T | 16-18-18-36 6-54-19-4 2T | Timings are similar but not the same | |
| Price / RRP (USD) |
$539 [+8%] |
$549 | $499 | $999 |
A little bit more expensive. | |
Disclaimer
Note: We (SiSoftware) claim copyright over the scores (benchmark results) posted to the Ranker. Please see:
Privacy: Who owns the data (scores) posted to the Ranker?
Native Performance
We are testing cache and memory performance using the highest performing instruction sets (AVX512, AVX2/FMA3, AVX, etc.).
Results Interpretation: Higher rate values (GOPS, MB/s, etc.) mean better performance. Lower latencies (ns, ms, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
| Native Benchmarks | Intel Core i9 11900K 8C/16T (RKL) | AMD Ryzen 9 5900X 12C/24T (Zen3) | Intel Core i9 10900K 10C/20T (CML) | Intel i9 7900X 10C/20T (SKL-X, Skylake-X) | Comments | |
 |
||||||
 |
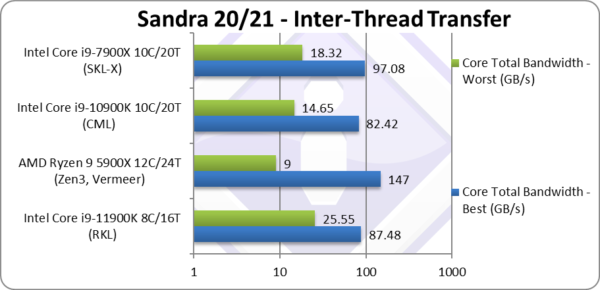
Total Inter-Thread Bandwidth – Best Affinity (GB/s) | 87.48* [+6%] | 147 | 82.42 | 97.08* | With just 8 cores, RKL still beats CML by 8%. |
|
Total Inter-Thread Bandwidth – Worst Affinity (GB/s) | 25.55* [+74%] | 9 | 14.46 | 18.32* | RKL beats all CPUs here and 74% better than CML. |
| We can see that inter-thread transfers are far more efficient – with just 8 cores it beats both CML and ties with SKL-X (also with AVX512 but 10 cores). Bandwidth between different cores (worst affinity – i.e. not on the same physical core) is much faster than all processors – especially compared to AMD’s Zen3 which craters as threads are between different CCXes.
Note*: using AVX512. |
||||||
 |
||||||
|
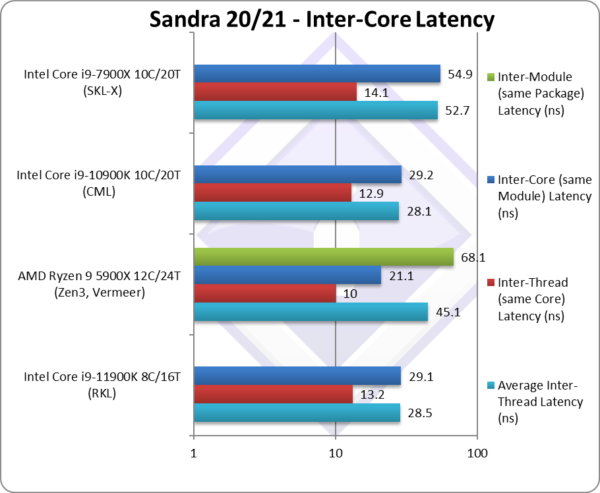
Average Inter-Thread Latency(ns) | 28.5 [+1%] | 45.1 | 28.1 | 52.7 | RKL just manages to tie with CML overall. |
|
Inter-Thread Latency (Same Core) (ns) | 13.2 [+2%] | 10 | 12.9 | 14.1 | Same core latencies seem to be the same. |
|
Inter-Thread Latency (Same Module) (ns) | 29.1 [-1%] | 21.1 | 29.2 | 54.9 | Different core latencies also seems to match. |
|
Inter-Thread Latency (Same Package) (ns) | – | 68.1 | – | – | Only Zen3 has different CCX/modules. |
| RKL just ties with the older CML at all levels which is somewhat surprising considering all the other core changes. Zen3 has lower latencies except inter-module/CCX that bring the overall latency up. | ||||||
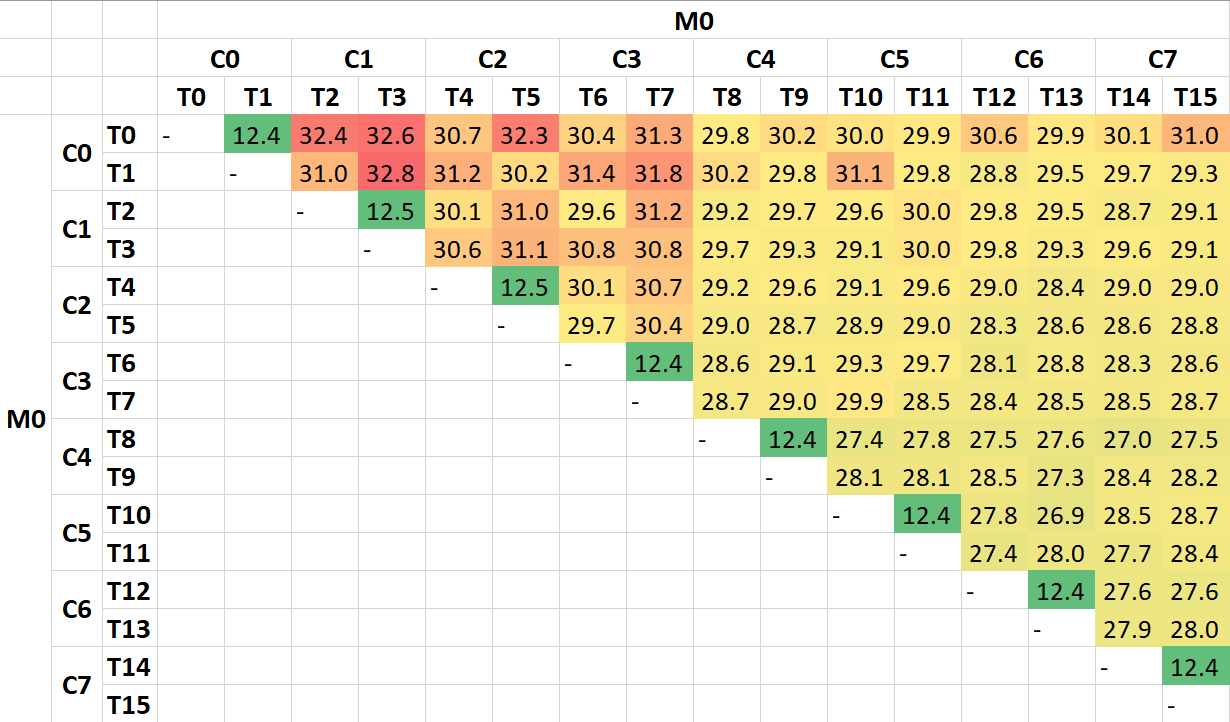 Intel RocketLake Inter-Thread/Core Latency HeatMap (ns) |
||||||
| The inter-thread latencies heat-map confirms what we saw above – with some variation on low-thread numbers but overall clear demarcation between same-core and different-core latencies. Naturally RKL has a single module/unified L3 cache thus relatively low penalty (3x higher latency) for going off-core. | ||||||
 |
||||||
 |
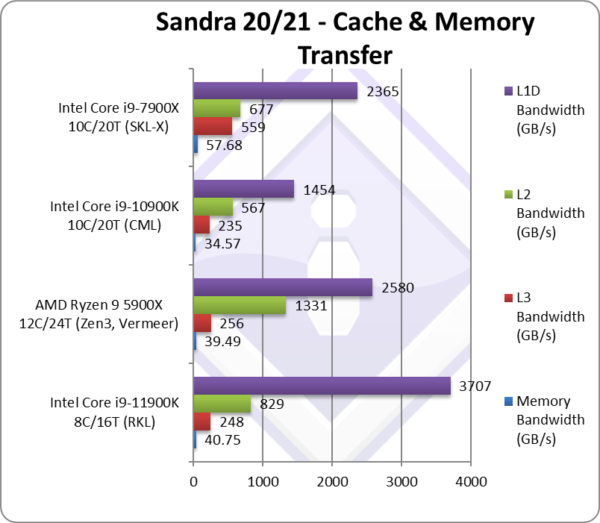
Aggregated L1D Bandwidth (GB/s) | 3,707* [+2.55x] | 2,580 | 1,454 | 2,365* | With just 8 cores, L1D bandwidth is over 2.5x higher! |
|
Aggregated L2 Bandwidth (GB/s) | 829* [+46%] | 1,331 | 567 | 677* | Again, just 8 cores but L2 bandwidth 50% higher. |
|
Aggregated L3 Bandwidth (GB/s) | 248* [+6%] | 256 | 235 | 559* | Unified L3 bandwidth is just 6% higher. |
|
Aggregated Memory (GB/s) | 40.75* [+18%] | 39.49 | 34.57 | 57.68* | Memory bandwidth is 28% higher. |
| Starting with L1D – we see massive bandwidth improvement – just over 2.5x vs. CML and much higher than even SKL-X; this would explain the gains we saw above in Inter-Thread bandwidth (best thread affinity). This will help massively with AVX512 code that handles more data at a time (512-bits vs. 256-bits). Let’s also recall L1D is now 50% bigger (48kB)!
L2 bandwidth is also decently improved (almost 50% higher) – while being 2x larger (512kB) though not as large as SKL-X (1MB). This will also help AVX512 code that requires more data to keep the SIMD units fed. L3 does not appear to have changed in this iteration, same size and pretty much the same bandwidth also. The memory controller performs well with AVX512/512-bit transfers and managed to squeeze 18% more bandwidth using the same data rate memory (3200Mt/s) that is welcome. Just like Ryzen, RKL will benefit from faster memory to keep the SIMD units fed. Note*: using AVX512. |
||||||
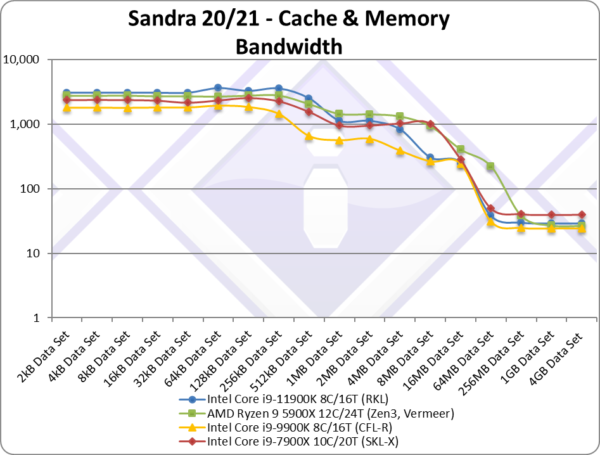 |
||||||
| The bandwidth graph does not present any surprises compared to the summary; RKL rules at small block sizes due to huge L1D cache bandwidth; L2 bandwidth is also impressive but not enough of – Zen3 and SKL-X have more of – while RKL and CML drop to L3.
Once we get to main memory, RKL is able to squeeze a little more bandwidth – except the 4-channel SKL-X that is in a different league. |
||||||
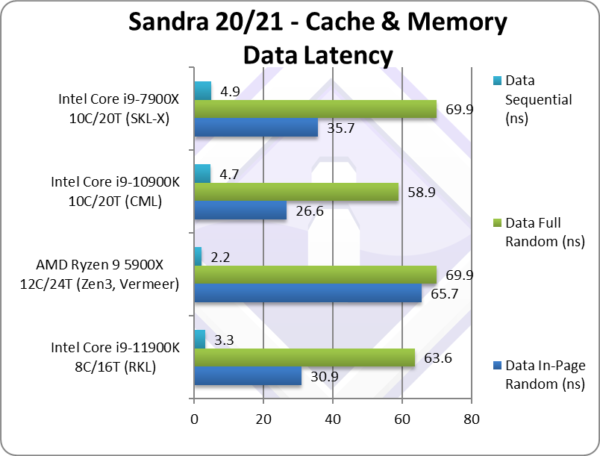 |
||||||
 |
Data In-Page Random Latency (ns) [L1D-L2-L3 clocks] | 30.9 [5-13-36] [+1,+1,+7][+16%] | 65.7 [4-12-44] | 26.6 [4-12-29] | 35.7 [4-14-49] | In-page we see latencies increase overall likely due to L1D 5 clk vs. 4 clk of CML/SKL-X but also L3 latency is higher (36 clk vs 29). |
|
Data Full Random Latency (ns) [L1D-L2-L3 clocks] | 63.6 [5-13-48][+1,+1,+6][+8%] | 69.9 [4-12-49] | 58.9 [4-12-54] | 69.9 [4-14-75] | Out-of-page latencies are a bit better but again L1D and L3 are higher. |
|
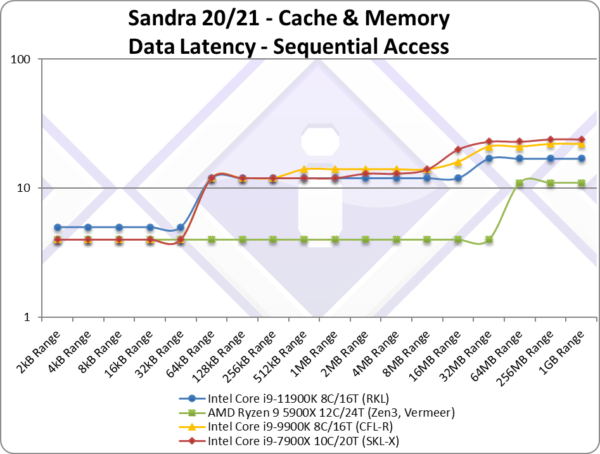
Data Sequential Latency (ns) [L1D-L2-L3 clocks] | 3.3 [5-12-12][+1,0,-4][-30%] | 2.2 [4-4-4] | 4.7 [4-12-16] | 4.9 [4-12-16] | We see a decent 30% latency reduction over CML but no matching Zen3. |
| Starting with L1D – we see a +1 clock increase (5 vs. 4) over the historic latencies of CML/CFL/etc. and also Zen3. This is mitigated in real-life by the 50% increase and higher bandwidth (+2.5x) but latency sensitive code might suffer.
L2 also sees a +1 clock increase (13 vs. 12) over CML/CFL/etc. and Zen3 but again it is 2x larger. Only SKL-X with its 1MB L2 is even slower. Again, this is mitigated by the size doubling and 50% higher bandwidth. L3 surprisingly fares the worst, with +6-7 clock latency increase (36 vs. 29) for the same size and bandwidth (as CML) which is surprising. Older microcode (before version 3X) performed even worse. |
||||||
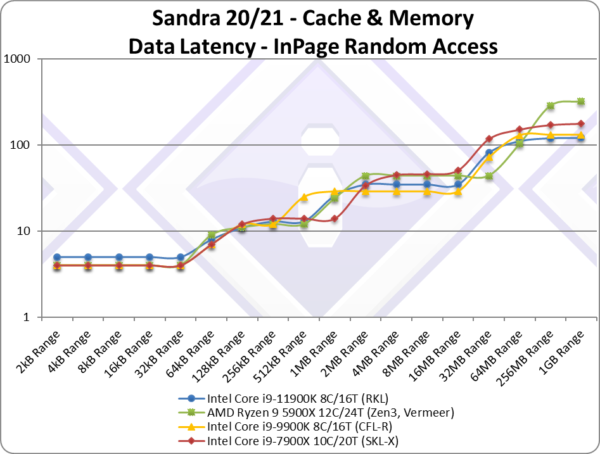 |
||||||
| Looking at the data access latencies’ graph for RKL we see the higher L1D latencies (5 clk) but the larger caches (L1D and L2) help reduce overall latencies for larger block sizes. For even larger blocks we see the higher L3 latency (~36 clk) which is disappointing but still decent performance compared with the older SKL-X and Zen3. | ||||||
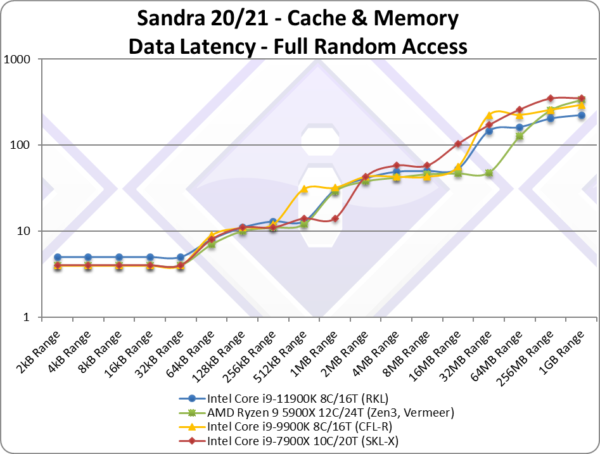 |
||||||
| Full-random access does not look much different, again we see higher L1D latency (unlike other CPUs) and L3 latencies. But memory latencies (blocks larger than L3 cache) – including TLB misses penalties – are lowest in the test. | ||||||
 |
||||||
| Again we see L1D higher latency but overall better performance as block sizes increase. Zen3 is in a world of its own! | ||||||
 |
||||||
|
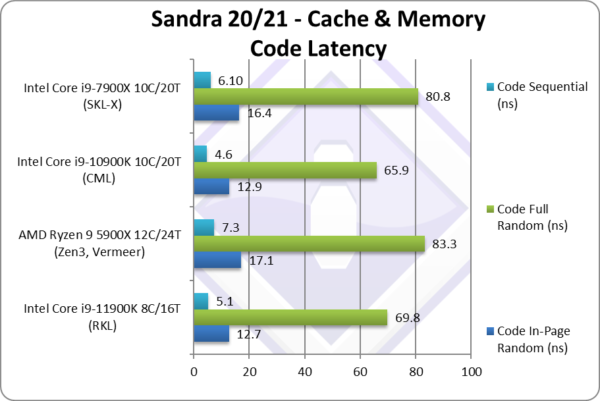
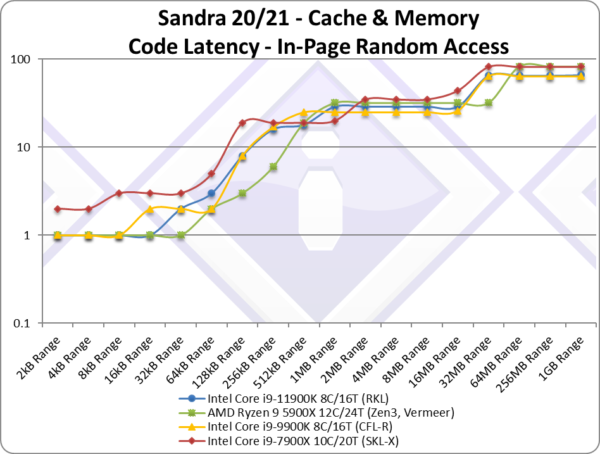
Code In-Page Random Latency (ns) [L1I-L2-L3 clocks] | 12.7 [2-18-27] [0,+2,0][-2%] | 17.1 [1-21-33] | 12.9 [2-16-27] | 16.4 [2-19-35] | Code latencies fare better matching CML. |
|
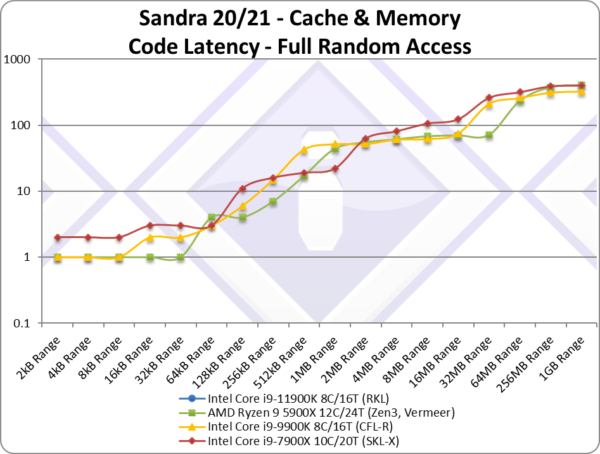
Code Full Random Latency (ns) [L1I-L2-L3 clocks] | 69.8 [2-18-69][0,+2,-2][+2%] | 83.3 [1-21-72] | 65.9 [2-16-67] | 80.8 [2-21-122] | Out-of-page latencies is also unchanged. |
|
Code Sequential Latency (ns) [L1I-L2-L3 clocks] | 5.1 [2-10-12][0,+1,+1][+11%] | 7.3 [1-18-21] | 4.6 [2-9-13] | 6.1 [2-9-19] | Sequential latencies end up 11% higher. |
| Unlike data, code latencies (any pattern) are competitive with CML/CFL with minor clock variations that don’t show significant changes. L1I appears unchanged and while L2 and L3 do show higher clocks, it is not as pronounced as with data. | ||||||
 |
||||||
| Unlike data, code latencies (any pattern) are competitive with CML/CFL with minor clock variations that don’t show significant changes. L1I appears unchanged and while L2 and L3 do show higher clocks, it is not as pronounced as with data. | ||||||
 |
||||||
| The full-random-access latencies graph does not show any surprises, with RKL closely tracking CML/CFL across block sizes, with only main memory accesses (including TLB miss penalties) lower. | ||||||
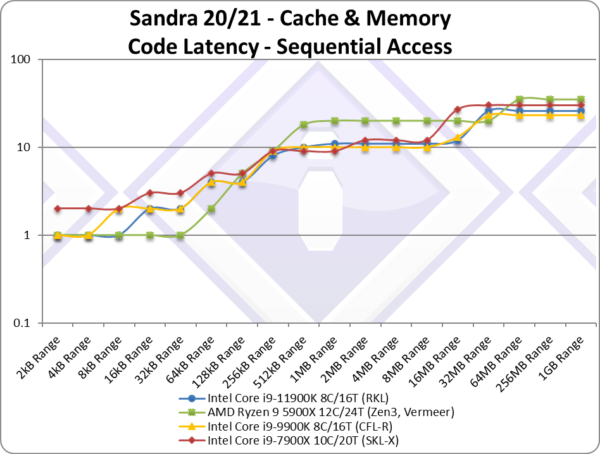 |
||||||
| The sequential access pattern graph does not present any surprises either, RKL tracks CML/CFL pretty closely until we get to main memory where latencies are somewhat higher but nothing significant. | ||||||
SiSoftware Official Ranker Scores
- 11th Gen Intel Core i9-11900K (8C / 16T, 5.3GHz)
- 11th Gen Intel Core i7-11700K (8C / 16T, 3.6GHz)
- 11th Gen Intel Core i7-11700 (8C / 16T, 2.5GHz)
- 11th Gen Intel Core i5-11600 (6C / 12T, 4.8GHz)
Final Thoughts / Conclusions
Summary: A good upgrade (big bandwidth improvement) : 7/10
Note2: The microcode (aka CPU firmware) used in the test as per above is version 3C (version 60); older or newer versions seem to exhibit different performance. We will update the review when we obtain our sample and run our own tests.
Note3: All benchmarks run are using the latest supported instruction sets – i.e. AVX512; Sandra does allow you to disable it and run AVX2/FMA3 or even AVX, SSE4, SSE2. Once we get our sample we will show the results using AVX2/FMA3.
Unlike CPU performance, RKL cache & memory performance is more of a mixed bag; this explains some of the results we saw in CPU testing. As with everything, there are good news and bad news:
- Good news: L1D is 50% larger with massively more bandwidth (over +2.5x); L2 is 2x larger with +50% more bandwidth. L3 seems unchanged in this iteration.
- More good news: Main memory accesses both in-page and out-of-page (thus TLB miss penalties) are much lower.
- Bad news: L1D latency is +1 clock higher, L2 is +1 clock higher and L3 +6-7 clocks.
Thus algorithms that rely on bandwidth (masking latencies) and use AVX512 benefit from larger and higher bandwidth but higher latency caches. We also see this in inter-thread transfers, be they same core unit (thus L1D/L2) or not.
Algorithms that are latency sensitive and not using SIMD or perhaps older SSE2/AVX are likely going to perform worse. They will have to be updated to AVX512 and use buffering techniques to hide latency effects to perform better.
It is likely Intel had no choice but to increase the sizes of L1D and L2 to ensure the AVX512 units are not starved of data – and the small L1D/L2 and even L3 of CML/CFL/SKL were insufficient. We see with TGL that L2 is increasing even further to exceed even old SKL-X 1M cache. Unfortunately – this has meant latency increases which can be mitigated through algorithm optimisations.
The Future: AlderLake (ADL) Hybrid (big.LITTLE)
As we have seen in our TigerLake (TGL) benchmarks, TGL improves significantly over ICL (and thus RKL using the same cores at 14nm) – thus 10nm ADL “big Core” is likely to be much faster than RKL and at much lower power. So if it all goes to plan, ADL will be the Core we are all looking for…
However, ADL is a hybrid processor, consisting of “big Core” cores + “LITTLE Atom” cores – and these kind of hybrid architectures are a massive pain in the proverbial for (software) developers. There is a massive work being done underneath the hood in Sandra to support such hybrid architecture (detection/scheduler/benchmarks/UI) and it will live and die based on how good the Windows scheduler will manage cores. The future will certainly be interesting…
Summary: Good: 7/10
In this article we tested CPU Cache & Memory performance; please see our other articles on:
- Intel 12th Gen Core AlderLake (i9-12900K) Review & Benchmarks – big/LITTLE Performance
- Intel 11th Gen Core RocketLake AVX512 Performance Improvement vs AVX2/FMA3
- Intel 11th Gen Core RocketLake (i7-11700K) Review & Benchmarks – CPU AVX512 Performance
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!
Disclaimer
Note: We (SiSoftware) claim copyright over the scores (benchmark results) posted to the Ranker. Please see:
Privacy: Who owns the data (scores) posted to the Ranker?