What is AVX512?
AVX512 (Advanced Vector eXtensions) is the 512-bit SIMD instruction set that follows from previous 256-bit AVX2/FMA3/AVX instruction set. Originally introduced by Intel with its “Xeon Phi” GPGPU accelerators – albeit in a somewhat different form – it has finally made it to its desktop CPU lines with “RocketLake” (RKL) having previously been available in HEDT / server / workstation “Skylake-X” (SKL-X) and mobile “IceLake” (ICL).
While it was rumoured desktop/mobile “Skylake” arch was meant to also support AVX512 based on core changes (widening of ports to 512-bit, unit changes, etc.) – nevertheless no public way of engaging them has been found.
AVX512 consists of multiple extensions and not all CPUs (or GPGPUs) may implement them all:
- AVX512F – Foundation – most floating-point single/double instructions widened to 512-bit. [supported by SKL-X, ICL, RKL]
- AVX512-DQ – Double-Word & Quad-Word – most 32 and 64-bit integer instructions widened to 512-bit [supported by SKL-X, ICL, RKL]
- AVX512-BW – Byte & Word – most 8-bit and 16-bit integer instructions widened to 512-bit [supported by SKL-X, ICL, RKL]
- AVX512-VL – Vector Length eXtensions – most AVX512 instructions on previous 256-bit and 128-bit SIMD registers [supported by SKL-X, ICL, RKL]
- AVX512-CD – Conflict Detection – loop vectorisation through predication [future server ICL-SP]
- AVX512-ER – Exponential & Reciprocal – transcedental operations [future server ICL-SP]
- AVX512-VNNI (Vector Neural Network Instructions, dlBoost FP16/INT8) e.g. convolution [supported by ICL, RKL]
- AVX512-VBMI, VBMI2 (Vector Byte Manipulation Instructions) various use
- AVX512-VAES (Vector AES) accelerating block-crypto [supported by ICL, RKL]
- AVX512-GFNI (Galois Field) – e.g. used in AES-GCM [supported by ICL, RKL]
- more sets will be introduced in future versions
Unfortunately, simply doubling register width does not automagically increase performance by 2x (twice) as dependencies, memory load/store latencies and even data characteristics limit performance gains – some of which may require future arch or even tools to realise their true potential.
AVX512 usage does increase the power usage of the processor; this is why historically the turbo speed was limited in AVX512 mode just as previously was limited with AVX2/AVX mode. While SKL-X already consumed a relatively high amount of power on HEDT platform (which needed to be dissipated by the cooling system) – RKL is the first desktop processor to consume/dissipate such high amounts (up to 250W).
Some have postulated that AVX512 should just be disabled and RKL should just rely on older AVX2/FMA3; we shall see whether that would have been sufficient and just how much RKL benefits from AVX512 code.
Reviews
In this article we test AVX512 core performance; please see our other articles on:
- Intel 12th Gen Core AlderLake (i9-12900K) Review & Benchmarks – big/LITTLE Performance
- Intel 11th Gen Core RocketLake (i9-11900K) Review & Benchmarks – CPU AVX512 Performance
- Intel 11th Gen Core RocketLake (i7-11700K) Review & Benchmarks – CPU AVX512 Performance
- Intel 11th Gen Core RocketLake – Cache & Memory Performance (2x DDR4-3200)
- Intel Core Gen 11 TigerLake ULV (i7-1165G7) Review & Benchmarks – CPU AVX512 Performance
- Intel Core Gen 10 IceLake ULV (i7-1065G7) Review & Benchmarks – CPU AVX512 Performance
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!
Disclaimer
Note: We (SiSoftware) claim copyright over the scores (benchmark results) posted to the Ranker. Please see:
Privacy: Who owns the data (scores) posted to the Ranker?
Native SIMD Performance
We are testing native SIMD performance using various instruction sets: AVX512, AVX2/FMA3, AVX to determine the gains the new instruction sets bring.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest Intel drivers. Turbo / Dynamic Overclocking was enabled on both configurations.
| Native Benchmarks | Intel Core i9 11900K 8C/16T (RKL) – AVX512 | Intel Core i9 11900K 8C/16T (RKL) – AVX2/FMA3 | Intel Core i9 10900K 10C/20T (CML) – AVX2/FMA3 | Comments | |
 |
|||||
 |
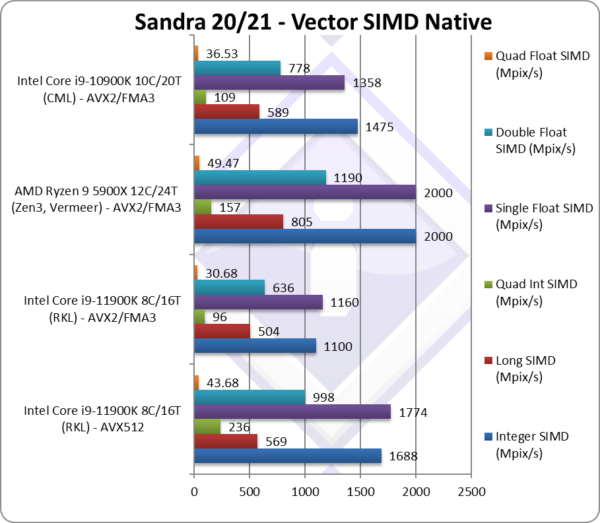
Native Integer (Int32) Multi-Media (Mpix/s) | 1,688 [+53%] | 1,100 | 1,475 | Integer workloads improve by over 50% and allow it to beat CML. |
|
Native Long (Int64) Multi-Media (Mpix/s) | 569 [+13%] | 504 | 589 | With a 64-bit integer, the improvement is just 13%. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 236* [+2.46x] | 96 | 109 | IFMA makes AVX512 almost 2.5x faster and faster than CML. |
|
Native Float/FP32 Multi-Media (Mpix/s) | 1,774 [+53%] | 1,160 | 1,358 | With floating-point we see a similar 53% improvement and again beating CML. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 998 [+57%] | 636 | 778 | Switching to FP64 we get an even better 57% improvement. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 43.68 [+42%] | 30.68 | 36.63 | Using FP64 to mantissa extend FP128 we see a 42% improvement. |
| If you were expecting 2x performance you may be disappointed: don’t be! AVX512 delivers a solid 40-50% improvement over AVX2/FMA3 which allows RKL beat CML with 2 more cores and be competitive against AMD competition.
Keeping in mind RKL at 14nm runs hot and very likely thermally limited and has a single AVX512-FMA unit. Future processors at 10nm will perform much better. In any case RKL is much more performant with AVX512. Note*: using AVX512-IFMA extension. |
|||||
 |
|||||
 |
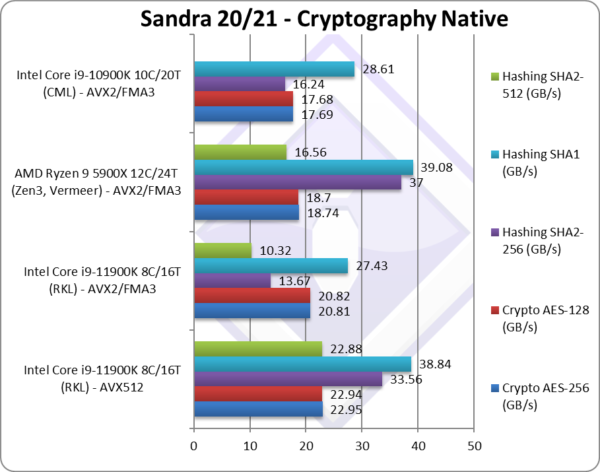
Crypto SHA2-256 (GB/s) | 33.56 [+2.46x] | 13.67 | 16.24 | Heavy compute shows the power of AVX512 – it’s almost 2.5x faster. |
|
Crypto SHA1 (GB/s) | 38.84 [+42%] | 27.43 | 28.61 | Less compute reduces the benefit to 42% – likely due to memory bandwidth limitation. |
|
Crypto SHA2-512 (GB/s) | 22.88 [+2.2x] | 10.32 | 64-bit integer workload is over 2x faster with AVX512. | |
| With heavy compute integer workload, we see AVX512 over 2x faster than old AVX – a significant result. It’s only when we hit memory bandwidth limitations (using same memory speed) the improvement reduces – we need higher speed memory.
Despite core improvements, it is clear RKL with less cores would not beat CML nor AMD competition without AVX512. |
|||||
 |
|||||
 |
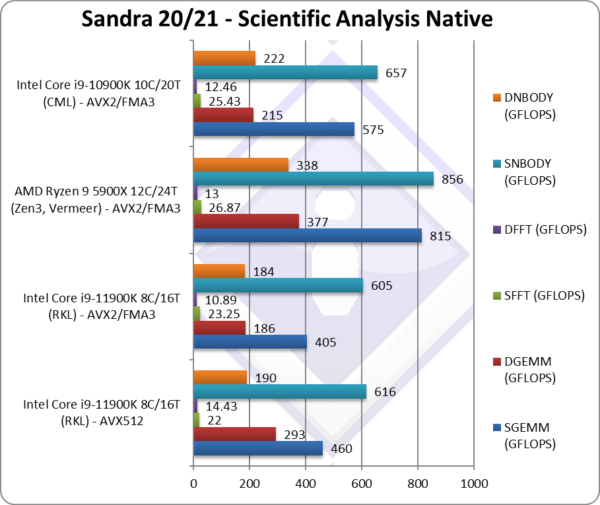
SGEMM (GFLOPS) float/FP32 | 460 [+14%] | 405 | 575 | FP32 GEMM sees only 14% improvement, need optimisation |
|
DGEMM (GFLOPS) double/FP64 | 293 [+58%] | 186 | 215 | Changing to FP64 we see a healthy 58% improvement. |
|
SFFT (GFLOPS) float/FP32 | 22 [-5%] | 23.25 | 25.43 | We see a regression here that needs optimisation. |
|
DFFT (GFLOPS) double/FP64 | 14.43 [+33%] | 10.89 | 12.46 | With FP64 we again see a good 33% improvement. |
|
SNBODY (GFLOPS) float/FP32 | 616 [+2%] | 605 | 657 | Again we only see a minor 2% improvement – further optimisation needed. |
|
DNBODY (GFLOPS) double/FP64 | 190 [+3%] | 184 | 222 | With FP64 we again see a minor improvement. |
| With complex SIMD code – not written in assembler, it seems there is *still* some work to be done just as we say many years back with SKL-X. Memory bound algorithms with many dependencies need careful optimisation to take advantage of AVX512. | |||||
 |
|||||
 |
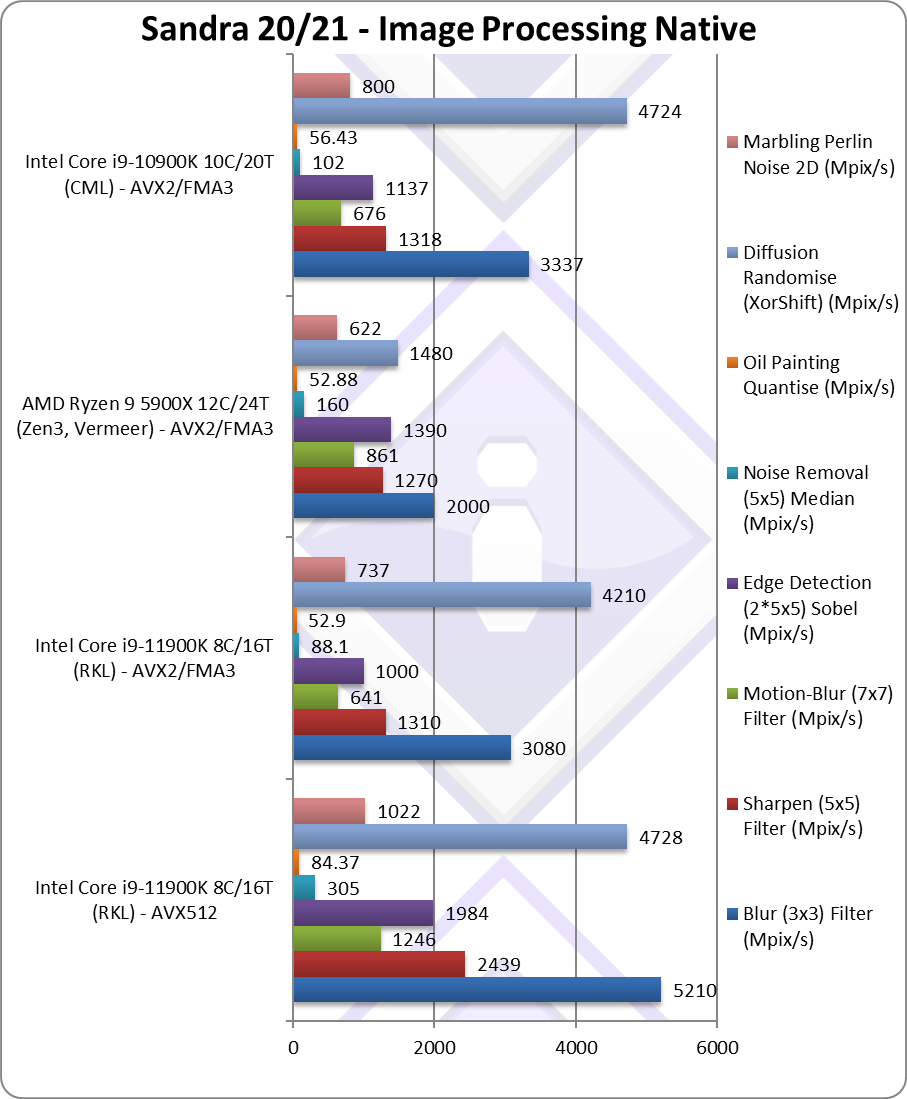
Blur (3×3) Filter (MPix/s) | 5,210 [+69%] | 3,080 | 3,337 | We start well here with AVX512 69% faster with float FP32 workload. |
|
Sharpen (5×5) Filter (MPix/s) | 2,439 [+86%] | 1,310 | 1,318 | Same algorithm but more shared data improves by 86%. |
|
Motion-Blur (7×7) Filter (MPix/s) | 1,246 [+94%] | 641 | 676 | Again same algorithm but even more data shared bring 2x improvement. |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 1,984 [+98%] | 1,000 | 1,137 | Using two buffers retains the 2x speed improvement. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 305 [+3.46x] | 88.1 | 102 | This algorithms loves AVX512, it’s almost 3.5x faster! |
|
Oil Painting Quantise Filter (MPix/s) | 84.37 [+59%] | 52.9 | 56.43 | Using the new scatter/gather in AVX512 brings 60% improvement. |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 4,728 [+12%] | 4,210 | 4,724 | A 64-bit integer workload only brings 12% improvement. |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 1,022 [+39%] | 737 | 800 | Again loads of gathers brings 40% performance. |
| Image processing just loves SIMD and here AVX512 again brings massive performance increases of 40% to 3.5x, with the new scatter/gather instructions proving especially useful – even when limited by memory latency.
There is no question that for image processing tasks, AVX512 is a winner. |
|||||
SiSoftware Official Ranker Scores
- 11th Gen Intel Core i9-11900K (8C / 16T, 5.3GHz)
- 11th Gen Intel Core i7-11700K (8C / 16T, 3.6GHz)
- 11th Gen Intel Core i7-11700 (8C / 16T, 2.5GHz)
- 11th Gen Intel Core i5-11600 (6C / 12T, 4.8GHz)
Final Thoughts / Conclusions
Summary: AVX512 is ~40% faster than AVX2/FMA3 on RocketLake!
Despite RKL on 14nm and being power limited (just like SKL-X before it due to its high power consumption) which is especially an issue in AVX512 mode – there is no question, across algorithms there is no question that RKL performs much better due to AVX512 and will benefit greatly from software updated to use it.
With AVX512 now available across platforms (server/workstation, mobile, desktop) there is no question that just about all modern software will *have to* be updated to use it – which generally is not a difficult task. Further optimisations taking advantage of specific extensions (e.g. IFMA, VNNI, etc.) will yield far higher improvements. Here, at SiSoftware, are very much looking to optimise our benchmarks further.
It is likely that future processors, e.g. “AlderLake” (ADL) on 10nm that will not be power limited, allowing them to sustain higher turbo speeds – will perform even better on AVX512 code. Thus there is no question that AVX512 is here to stay and get even more extensions.
Here is to the next processors!
Reviews
In this article we test AVX512 core performance; please see our other articles on:
- Intel 12th Gen Core AlderLake (i9-12900K) Review & Benchmarks – big/LITTLE Performance
- Intel 11th Gen Core RocketLake (i9-11900K) Review & Benchmarks – CPU AVX512 Performance
- Intel 11th Gen Core RocketLake (i7-11700K) Review & Benchmarks – CPU AVX512 Performance
- Intel 11th Gen Core RocketLake – Cache & Memory Performance (2x DDR4-3200)
- Intel Core Gen 11 TigerLake ULV (i7-1165G7) Review & Benchmarks – CPU AVX512 Performance
- Intel Core Gen 10 IceLake ULV (i7-1065G7) Review & Benchmarks – CPU AVX512 Performance
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!
Disclaimer
Note: We (SiSoftware) claim copyright over the scores (benchmark results) posted to the Ranker. Please see:
Privacy: Who owns the data (scores) posted to the Ranker?