What is “AlderLake”?
It is the “next-generation” (12th) Core architecture – replacing the short-lived “RocketLake” (RKL) that finally replaced the many, many “Skylake” (SKL) derivative architectures (6th-10th). It is the 1st mainstream “hybrid” arch – i.e. combining big/P(erformant) “Core” cores with LITTLE/E(fficient) “Atom” cores in a single package. While in the ARM world such SoC designs are quite common, this is quite new for x86 – thus operating systems (Windows) and applications may need to be updated.
Unlike the “limited edition” ULV-only 1st gen hybrid “LakeField” (LKF) arch (1C + 4c 6T and thus very low compute power) – ADL launches on desktop, mobile and ultra-mobile (ULV) platforms – all with different counts of big/P and LITTLE/E cores. For example (data as per AnandTech: Intel 12th Gen Core Alder Lake for Desktops: Top SKUs Only, Coming November 4th):
- Desktop (65-125W rated, up to 250W turbo)
- 8C (aka big/P) + 8c (aka LITTLE/E) / 24T total (12th Gen Core i9-12900K(F))
- 8C + 4c / 20T total (12th Gen Core i7-12700K(F))
- 6C + 4c / 16T total (12th Gen Core i5-12600K(F))
- 6C only / 12T total (12th Gen Core i5-12600)
- High-Performance Mobile (H) (45-55W rated, up to 157W turbo)
- 8C + 8c / 24T total
- Mobile (P) (20-28W rated, up to 64W turbo)
- 6C + 8c / 20T total
- Ultra-Mobile/ULV (U) (9-15W rated, up to 29W turbo)
- 2C + 8c / 12T total
For best performance and efficiency, this does require operating system scheduler changes – in order for threads to be assigned on the appropriate physical core/thread. For compute-heavy/low-latency this means a “big/P” core; for low compute/power-limited this means a “LITTLE/E” core.
In the Windows world, this means “Windows 11” for clients and “Windows Server vNext” (note not the recently released Server 2022 based on 21H2 Windows 10 kernel) for servers. The Windows power plans (e.g. “Balanced“, “High Performance“, etc.) contain additional settings (hidden), e.g. prefer (or require) scheduling on big/P or LITTLE/E cores and so on. But in general, the scheduler is supposed to automatically handle it all based on telemetry from the CPU.
Windows 11 also gets updated QoS (Quality of Service) API (aka functions) allowing app(lications) like Sandra to indicate which threads should use big/P cores and which LITTLE/E cores. Naturally, these means updated applications will be needed for best power efficiency.
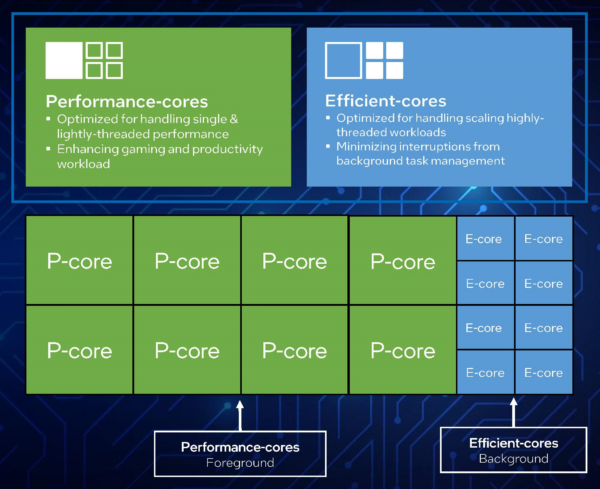
AlderLake Desktop 8C (big/P) + 8c (LITTLE/E)
General SoC Details
- 10nm++ improved process
- Unified 30MB L3 cache (almost 2x 16MB of RKL)
- PCIe 5.0 (up to 64GB/s with x16 lanes) – up to x16 lanes PCIe5 + x4 lanes PCIe4
- NVMe SSDs may thus be limited to PCIe4 or bifurcate main x16 lanes with GPU to PCIe5 x8 + x8
- PCH up to x12 lanes PCIe4 + x16 lanes PCIe3
- CPU to PCH DMI 4 x8 link (aka PCIe4 x8)
- DDR5/LP-DDR5 memory controller support (e.g. 4x 32-bit channels) – up to 4800Mt/s (official)
- New XMP 3.0 (eXtreme Memory Profile(s)) specification for overclocking with 3 profiles and 2 user-writable profiles (!)
- Thunderbolt 4 (and thus USB 4)
big/P(erformance) “Core” core
- Up to 8C/16T “Golden Cove” cores 7nm – improved from “Willow Cove” in TGL – claimed +19% IPC uplift
- Disabled AVX512! in order to match Atom cores (on consumer)
- (Server versions support AVX512 and new extensions like AMX and FP16 data-format)
- SMT support still included, 2 threads/core – thus 16 total
- 6-wide decode (from 4-way until now) + many other front-end upgrades
- L1I remains at 32kB but iTLB increased 2x (256 vs. 128)
- L1D remains at 48kB but dTLB increased 50% (96 vs. 64)
- L2 increased to 1.25MB per core (over 2x TGL of 512kB) – server versions 2MB
- See big/Performance Core Performance Analysis – Intel 12th Gen Core AlderLake (i9-12900K) article for more information
LITTLE/E(fficient) “Atom” core
- Up to 8c/8T “Gracemont” cores 7nm – improved from “Tremont” – claimed “Skylake” (SKL) Core performance (!)
- No SMT support, only 1 thread/core – thus 8 total (in 2 modules of 4 threads)
- AVX2 support – first for Atom core, but no AVX512!
- (Recall that “Phi” GP-GPU accelerator w/AVX512 was based on Atom core)
- L1I at 64kB (2x increase) same latency
- L1D still at 32kB
- L2 2MB shared by 4 cores, aka 512kB/core [not 1MB/core as expected]
- See LITTLE/Efficient Atom core Performance Analysis – Intel 12th Gen Core AlderLake (i9-12900K) article for more information
The big news – beside the hybrid arch – is that AVX512 supported by desktop/mobile “Ice Lake” (ICL), “Tiger Lake” (TGL) and “Rocket Lake” (RKL) – is no longer enabled on “Alder Lake” big/P cores in order to match the Atom LITTLE/E cores. Future HEDT/server versions with presumably only big/P cores should support it just like Ice Lake-X (ICL-X).
Note: It seems that AVX512 can be enabled on big/P Cores (at least for now) on some mainboards that provide such a setting; naturally LITTLE/E Atom cores need to be disabled. We plan to test this ASAP.
In order to somewhat compensate – there are now AVX2 versions of AVX512 extensions:
- VNNI/256 – (Vector Neural Network Instructions, dlBoost FP16/INT8) e.g. convolution
- VAES/256 – (Vector AES) accelerating block-crypto
- SHA HWA accelerating hashing (SHA1, SHA2-256 only)
While for Atom cores AVX2 support is a huge upgrade – that will make new Atom designs very much performant (not just power efficient), losing AVX512 for Core is a big loss – especially for compute-heavy software that have been updated in order to take advantage of the new instruction set. While server versions still support AVX512 (including new extensions), it is debatable how much developers will bother now unless targeting that specific niche market (heavy compute on servers).
We saw in the “RocketLake” review (Intel 11th Gen Core RocketLake AVX512 Performance Improvement vs AVX2/FMA3) that AVX512 makes RKL almost 40% faster vs. AVX2/FMA3 – and despite its high power consumption – it made RKL competitive. Without it – RKL with 2 less cores than “Comet Lake” (CML) would have not sufficiently improved to be worth it.
At SiSoftware – with Sandra – we naturally adopted and supported AVX512 from the start (with SKL-X) and added support for various new extensions as they were added in subsequent cores – this is even more disappointing; while it is not a problem to add AVX2 versions (e.g. VAES, VNNI) the performance cannot be expected to match the AVX512 original versions.
Let’s note that originally AVX512 launched with the Atom-core powered “Phi” GP-GPU accelerators – thus it would not have been impossible for Intel to add support to the new Atom core – and perhaps we shall see that in future arch… when an additional compute performance uplift will be required (i.e. deal with AMD competition).
The move to DDR5 (and LP-DDR5X) is significant, providing finer granularity (32-bit channels not 64) – allowing single DIMM multi-channel operation as well as much higher bandwidth (although latencies will naturally increase). With an even larger number of cores (up to 16 now) – dual channel DDR4 is just insufficient to feed all these cores. But at launch, it may be cripplingly expensive.
Changes in Sandra to support Hybrid
Like Windows (and other operating systems), we have had to make extensive changes to both detection, thread scheduling and benchmarks to support hybrid/big-LITTLE. Thankfully, this means we are not dependent on Windows support – you can confidently test AlderLake on older operating systems (e.g. Windows 10 or earlier – or Server 2022/2019/2016 or earlier) – although it is probably best to run the very latest operating systems for best overall (outside benchmarking) computing experience.
- Detection Changes
- Detect big/P and LITTLE/E cores
- Detect correct number of cores (and type), modules and threads per core -> topology
- Detect correct cache sizes (L1D, L1I, L2) depending on core
- Detect multipliers depending on core
- Scheduling Changes
- “All Threads (MT/MC)” (thus all cores + all threads – e.g. 24T
- “All Cores (MC aka big+LITTLE) Only” (both core types, no threads) – thus 16T
- “All Threads big/P Cores Only” (only “Core” cores + their threads) – thus 16T
- “big/P Cores Only” (only “Core” cores) – thus 8T
- “LITTLE/E Cores Only” (only “Atom” cores) – thus 8T
- “Single Thread big/P Core Only” (thus single “Core” core) – thus 1T
- “Single Thread LITTLE/E Core Only” (thus single “Atom” core) – thus 1T
- “All Threads (MT/MC)” (thus all cores + all threads – e.g. 24T
- Benchmarking Changes
- Dynamic/Asymmetric workload allocator – based on each thread’s compute power
- Note some tests/algorithms are not well-suited for this (here P threads will finish and wait for E threads – thus effectively having only E threads). Different ways to test algorithm(s) will be needed.
- Dynamic/Asymmetric buffer sizes – based on each thread’s L1D caches
- Memory/Cache buffer testing using different block/buffer sizes for P/E threads
- Algorithms (e.g. GEMM) using different block sizes for P/E threads
- Best performance core/thread default selection – based on test type
- Some tests/algorithms run best just using cores only (SMT threads would just add overhead)
- Some tests/algorithms (streaming) run best just using big/P cores only (E cores just too slow and waste memory bandwidth)
- Some tests/algorithms sharing data run best on same type of cores only (either big/P or LITTLE/E) (sharing between different types of cores incurs higher latencies and lower bandwidth)
- Reporting the Compute Power Contribution of each thread
- Thus the big/P and LITTLE/E cores contribution for each algorithm can be presented. In effect, this allows better optimisation of algorithms tested, e.g. detecting when either big/P or LITTLE/E cores are not efficiently used (e.g. overloaded)
- Dynamic/Asymmetric workload allocator – based on each thread’s compute power
As per above you can be forgiven that some developers may just restrict their software to use big/Performance threads only and just ignore the LITTLE/Efficient threads at all – at least when using compute heavy algorithms.
For this reason we recommend using the very latest version of Sandra and keep up with updated versions that likely fix bugs, improve performance and stability.
CPU (Core) Performance Benchmarking
In this article we test CPU core performance; please see our other articles on:
- CPU
- Cache & Memory
- GP-GPU
Hardware Specifications
We are comparing the mythical top-of-the-range Gen 12 Intel with competing architectures as well as competitors (AMD) with a view to upgrading to a top-of-the-range, high performance design.
| Specifications | Intel Core i9 12900K 8C+8c/24T (ADL) | Intel Core i9 11900K 8C/16T (RKL) | AMD Ryzen 9 5900X 12C/24T (Zen3) | Intel Core i9 10900K 10C/20T (CML) | Comments | |
| Arch(itecture) | Golden Cove + Gracemont / AlderLake | Cypress Cove / RocketLake | Zen3 / Vermeer | Comet Lake | The very latest arch | |
| Cores (CU) / Threads (SP) | 8C+8c / 24T | 8C / 16T | 2M / 12C / 24T | 10C / 20T | 8 more LITTLE cores | |
| Rated Speed (GHz) | 3.2 big / 2.4 LITTLE | 3.5 | 3.7 | 3.7 | Base clock is a bit higher | |
| All/Single Turbo Speed (GHz) |
5.0 – 5.2 big / 3.7 – 3.9 LITTLE | 4.8 – 5.3 | 4.5 – 4.8 | 4.9 – 5.2 | Turbo is a bit lower | |
| Rated/Turbo Power (W) |
125 – 250 | 125 – 228 | 105 – 135 | 125 – 155 | TDP is the same on paper. | |
| L1D / L1I Caches | 8x 48kB/32kB + 8x 64kB/32kB |
8x 48kB 12-way / 8x 32kB 8-way | 12x 32kB 8-way / 12x 32kB 8-way | 10x 32kB 8-way / 10x 32kB 8-way | L1D is 50% larger. | |
| L2 Caches | 8x 1.25MB + 2x 2MB (14MB) |
8x 512kB 16-way (4MB) | 12x 512kB 16-way (6MB) | 10x 256kB 16-way (2.5MB) | L2 has almost doubled | |
| L3 Cache(s) | 30MB 16-way | 16MB 16-way | 2x 32MB 16-way (64MB) | 13.75MB 11-way | L3 is almost 2x larger | |
| Microcode (Firmware) | 090672-0F [updated] | 06A701-40 | 8F7100-1009 | 06A505-C8 | Revisions just keep on coming. | |
| Special Instruction Sets |
VNNI/256, SHA, VAES/256 | AVX512, VNNI/512, SHA, VAES/512 | AVX2/FMA, SHA | AVX2/FMA | Losing AVX512 | |
| SIMD Width / Units |
256-bit | 512-bit (1x FMA) |
256-bit | 256-bit | Less wide SIMD units | |
| Price / RRP (USD) |
$599 | $539 | $549 | $499 | Price is a little higher. | |
Disclaimer
This is an independent review (critical appraisal) that has not been endorsed nor sponsored by any entity (e.g. Intel, etc.). All trademarks acknowledged and used for identification only under fair use.
The review contains only public information and not provided under NDA nor embargoed. At publication time, the products have not been directly tested by SiSoftware but submitted to the public Benchmark Ranker; thus the accuracy of the benchmark scores cannot be verified, however, they appear consistent and pass current validation checks.
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets. “AlderLake” (ADL) does not support AVX512 – but it does support 256-bit versions of some original AVX512 extensions.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 11 x64, latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
| Native Benchmarks | Intel Core i9 12900K 8C+8c/24T big+LITTLE (ADL) | Intel Core i9 11900K 8C/16T (RKL) | AMD Ryzen 9 5900X 12C/24T (Zen3) | Intel Core i9 10900K 10C/20T (CML) | Comments | |
 |
||||||
 |
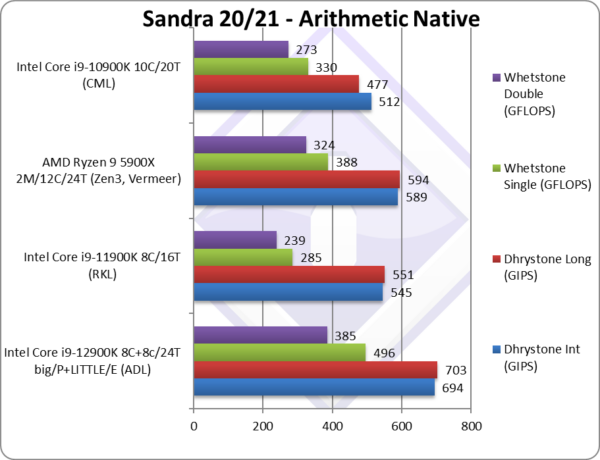
Native Dhrystone Integer (GIPS) | 694 [+27%] | 545 | 589 | 512 | ADL is 27% faster than RKL. |
|
Native Dhrystone Long (GIPS) | 703 [+28%] | 55 | 594 | 477 | A 64-bit integer workload ADL is 27% faster. |
|
Native FP32 (Float) Whetstone (GFLOPS) | 496 [+74%] | 285 | 388 | 330 | With floating-point, ADL is 74% slower |
|
Native FP64 (Double) Whetstone (GFLOPS) | 384 [+61%] | 239 | 324 | 273 | With FP64 nothing much changes. |
| While the initial scores were rather poor, both Sandra and ADL firmware/BIOS/OS (Windows 11) updates have done the trick. With legacy integer code ADL is 27% faster than RKL while floating-point is a whopping 60-75% faster!
The LITTLE/E Atom cores seem to make a decent difference with such non-SIMD legacy code which is the kind used by software in general – thus here ADL will perform very well. Even Zen3 despite having 12C “big” cores cannot match ADL with 16C Zen3 (5950) needed to beat it. Note that due to being “legacy” none of the benchmarks support AVX512; while we could update them, they are not vectorise-able in the “spirit they were written” – thus single-lane AVX512 cannot run faster than AVX2/SSEx. |
||||||
 |
||||||
 |
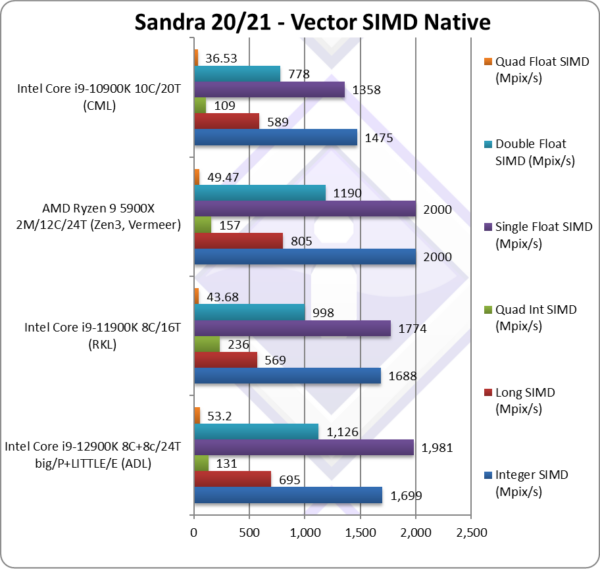
Native Integer (Int32) Multi-Media (Mpix/s) | 1,699 [+1%] | 1,688* | 2,000 | 1,475 | ADL manages to tie RKL here despite no AVX512. |
|
Native Long (Int64) Multi-Media (Mpix/s) | 695 [+22%] | 569* | 805 | 589 | With a 64-bit, ADL is 22% faster. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 131 [-44%] | 236*/** | 157 | 109 | Using 64-bit int to emulate Int128 ADL is 1/2 the speed. |
|
Native Float/FP32 Multi-Media (Mpix/s) | 1,981 [+12%] | 1,774* | 2,000 | 1,358 | In this floating-point vectorised test ADL is 12% faster. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 1,126 [+13%] | 998* | 1,190 | 778 | Switching to FP64 ADL is 13% faster than RKL. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 53.2 [+22%] | 43.68* | 49.47 | 36.53 | Using FP64 to mantissa extend FP128 ADL is 22% faster. |
| With heavily vectorised SIMD workloads – even without AVX512 support – ADL is now 10-20% faster than RKL which is encouraging considering how much AVX512 helps RKL in these benchmarks. The LITTLE/E Atom cores do help a little here but cannot match the power of big/P Cores.
This makes ADL competitive with Zen3 with same number of threads but 50% more big/P cores (12C/24T vs. 8bC+8LC/24T) which is encouraging but then again AMD is due to bring a new arch out (Zen3+, Zen4) with likely better performance. The lack of AVX512 unfortunately shows here – with ADL likely to perform a lot better should AVX512 been enabled. Note:* using AVX512 instead of AVX2/FMA. Note:** using AVX512-IFMA52 to emulate 128-bit integer operations (int128). |
||||||
 |
||||||
 |
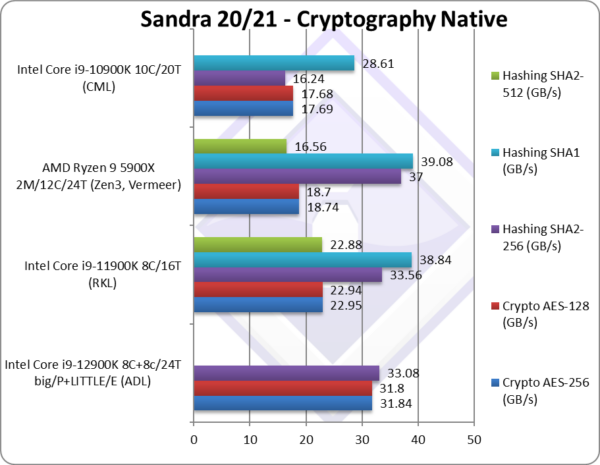
Crypto AES-256 (GB/s) | 31.84 [+39%] | 22.95* | 18.74 | 17.69 | DDR5 memory bandwidth rules here. |
|
Crypto AES-128 (GB/s) | 31.8 [+39%] | 22.94* | 18.7 | 17.68 | No change with AES128. |
|
Crypto SHA2-256 (GB/s) | 33.08** [-1%] | 33.56*** | 37** | 16.24 | ADL is just 1% slower than RKL. |
|
Crypto SHA1 (GB/s) | 38.84*** | 39** | 28.61 | Less compute intensive SHA1. | |
|
Crypto SHA2-512 (GB/s) | 22.88*** | 16.56 | SHA2-512 is not accelerated by SHA HWA. | ||
| The memory sub-system is crucial here, and these (streaming) tests show that using SMT threads is just not worth it; similarly using the LITTLE/E Atom cores is also perhaps also not worth it – with the memory bandwidth best used by the big/E Cores only. In effect out of 24T of ADL just 8T (one per big/P Core) is sufficient – but high-speed DDR5 memory may change that in the future.
DDR5 bandwidth rules here – with ADL 40% faster in AES crypto, something neither RKL nor Zen3 can match with DDR4 @ 3200Mt/s. With compute hashing, SHA HWA does help – but cannot beat multi-buffer AVX512 in RKL; thus ADL just matches it despite DDR5 and multiple cores/threads. Zen3 can win here with its additional big cores. Again, the loss of AVX512 is felt here. Note:* using VAES (AVX512-VL or AVX2-VL) instead of AES HWA. Note:** using SHA HWA instead of multi-buffer AVX2. [note multi-buffer AVX2 is slower than SHA hardware-acceleration] Note:*** using AVX512 B/W [note multi-buffer AVX512 is faster than using SHA hardware-acceleration] |
||||||
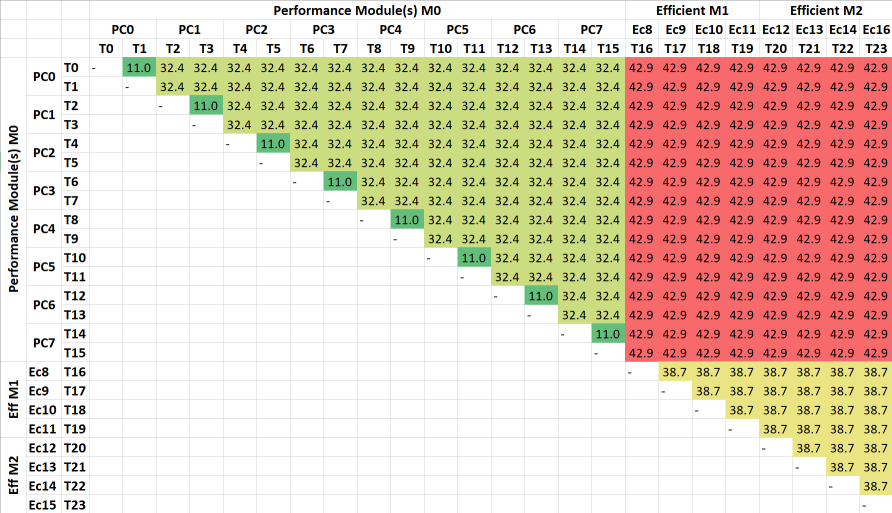 AlderLake Inter-Thread/Core (big & LITTLE) Latency HeatMap (ns) |
||||||
 |
Average Inter-Thread Latency (ns) | 38.5 [+35%] | 28.5 | 45.1 | 28.1 | ADL’s average is higher due to the LITTLE cores. |
|
Inter-Thread Latency (Same Core) (ns) | 11 [-17%] | 13.2 | 10 | 12.9 | ADL is 17% faster than RKL and close to Zen3. |
|
Inter-Core Latency (Same Module, Same Type) (ns) | 32.4 big [+11%] / 38.7 LITTLE | 29.1 | 21.1 | 29.1 | Again ADL is 11% slower than RKL here. |
|
Inter-big-2-LITTLE-Core Latency (Same Module, Different Type) (ns) | 42.9 [+32%] | – | – | – | Between different core types latency is 32% higher. |
|
Inter-Module (CCX) Latency (Same Package) (ns) | – | – | 68.1 [+3x] | – | Only Zen3 has different CCX/modules. |
| ADL’s inter-thread (same big/P Core aka L1D/L2 shared) and inter-big-Core (same Module aka L3 shared) are similar to RKL’s but not lower. However, ADL’s inter-thread (same LITTLE/E Atom core) don’t share a L1D but just L2 which is much slower.
Latency between different core types (aka big-2-LITTLE) are 32% higher than inter-Core but not as high as Zen3’s inter-Module (aka inter-CCX) as it is handled by the shared L3 cache. Thus, sharing data between different core types does not take such a big hit and is doable. |
||||||
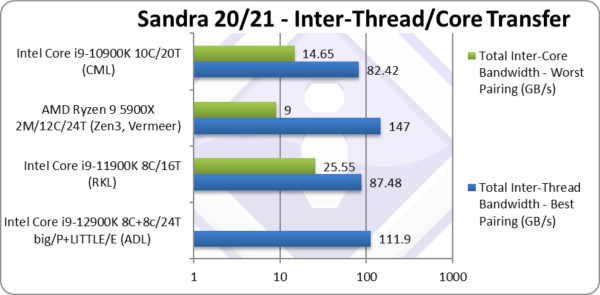 |
||||||
|
Total Inter-Thread Bandwidth – Best Pairing (GB/s) | 111.9 [+28%] | 87.48* | 147 | 82.42 | ADL’s bandwidth is ~30% higher than RKL. |
| As with inter-thread latency, while ADL’s threads on big/P Cores share L1D (which comes useful for small data transfers), ADL’s threads on LITTLE/E Atom cores only have the shared L2 cache which has lower bandwidth.
Thus while ADL’s 8 LITTLE/E Atom cores do help ADL have 30% more bandwidth than RKL, naturally they cannot help it beat AMD’s Zen3 which 12 “big” cores. Due to the shared L3 caches, none of the Intel designs “crater” when the pairing is worst (aka across Module/CCX) with bandwidth falling to 1/3 (a third) while Zen3’s bandwidth falls to 1/16 (a sixteenth)! Again, sharing data between different core types is not as problematic as between modules in Zen3 where threads sharing data have to be carefully affinitized. Note:* using AVX512 512-bit wide transfers. |
||||||
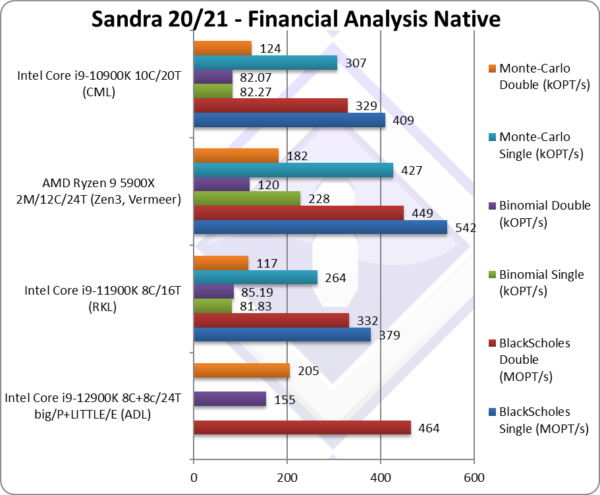 |
||||||
 |
Black-Scholes float/FP32 (MOPT/s) | – | 542 | 409 | Black-scholes is un-vectorised and compute heavy. | |
|
Black-Scholes double/FP64 (MOPT/s) | 464 [+40%] | 332 | 449 | 329 | Using FP64 ADL is 40% faster. |
|
Binomial float/FP32 (kOPT/s) | – | 228 | 82.27 | Binomial uses thread shared data thus stresses the cache & memory system. | |
|
Binomial double/FP64 (kOPT/s) | 155 [+82%] | 85.19 | 120 | 82.07 | With FP64 code ADL is 82% faster. |
|
Monte-Carlo float/FP32 (kOPT/s) | – | 427 | 307 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches. | |
|
Monte-Carlo double/FP64 (kOPT/s) | 205 [+75%] | 117 | 182 | 124 | Switching to FP64 ADL is 75% faster. |
| With non-SIMD financial workloads, similar to what we’ve seen in legacy floating-point code (Whetstone), ADL with its extra 8 LITTLE/E Atom cores does much better – it is 40-80% faster than RKL (!) – and more importantly just beats its Zen3 opposition with its 12 “big” cores.
Perhaps such code is better offloaded to GP-GPUs these days, but still lots of financial software do not use GP-GPUs even today. Thus with such code ADL performs very well, much better than RKL with its AVX512 unused. |
||||||
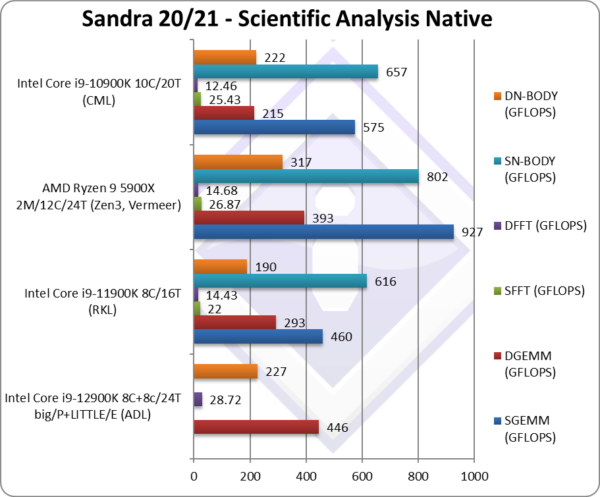 |
||||||
 |
SGEMM (GFLOPS) float/FP32 | – | 815 | 575 | In this tough vectorised algorithm ADL does well. | |
|
DGEMM (GFLOPS) double/FP64 | 446 [+52%] | 210* | 377 | 215 | With FP64 vectorised code, ADL is 52% faster. |
|
SFFT (GFLOPS) float/FP32 | – | 26.87 | 25.43 | FFT is also heavily vectorised but memory dependent. | |
|
DFFT (GFLOPS) double/FP64 | 28.72 [+2x] | 14.43* | 13 | 12.43 | With FP64 code, ADL is 2x faster. |
|
SN-BODY (GFLOPS) float/FP32 | – | 856 | 657 | N-Body simulation is vectorised but with more memory accesses. | |
|
DN-BODY (GFLOPS) double/FP64 | 227 [+19%] | 190* | 338 | 222 | With FP64 ADL is +19% faster. |
| With highly vectorised SIMD code (scientific workloads), after the various updates ADL starts to perform very well despite the loss of AVX512. Judicious L1D cache-size and workload-size optimisations can perhaps push performance even higher.
* using AVX512 instead of AVX2/FMA3 |
||||||
 |
||||||
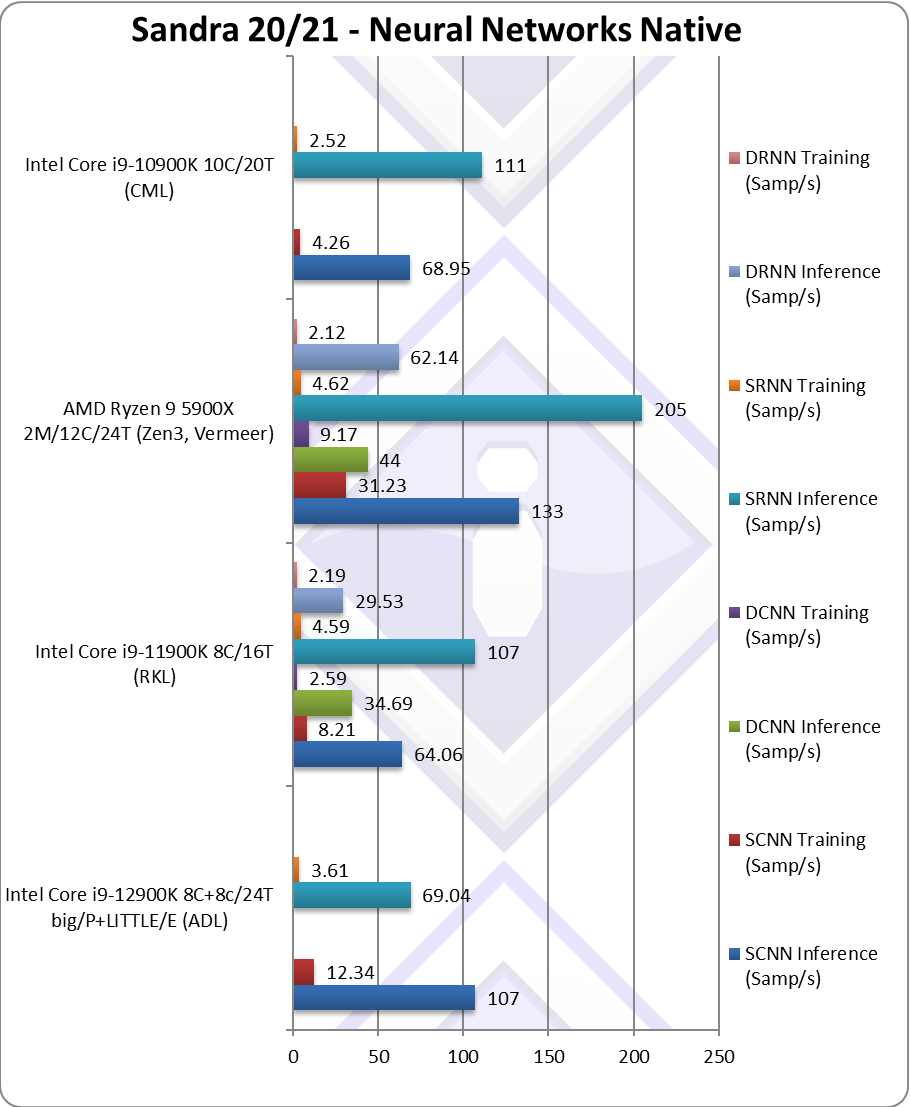
 |
NeuralNet CNN Inference (Samples/s) | 107 [+67%] | 60.08* | 133 | 68.95 | Despite AVX512, ADL is 67% slower. |
|
NeuralNet CNN Training (Samples/s) | 12.34 [+50%] | 8.21* | 31.23 | 4.26 | ADL is 50% faster but nowhere near Zen3. |
|
NeuralNet RNN Inference (Samples/s) | 69.04 [-35%] | 102* | 205 | 111 | ADL ends up 35% slower than RKL. |
|
NeuralNet RNN Training (Samples/s) | 3.61 [-21%] | 4.59* | 4.62 | 2.52 | ADL is still 20% slower than RKL here. |
| Despite good gains in other benchmarks, ADL does not do well here despite being 50% faster than RKL in some tests (despite loss of AVX512) – and ending up 20-30% slower than RKL in others. In the end, Zen3 still reigns supreme, with none of Intel’s CPUs able to match it in any of the tests.
* using AVX512 instead of AVX2/FMA (not using VNNI yet) |
||||||
 |
||||||
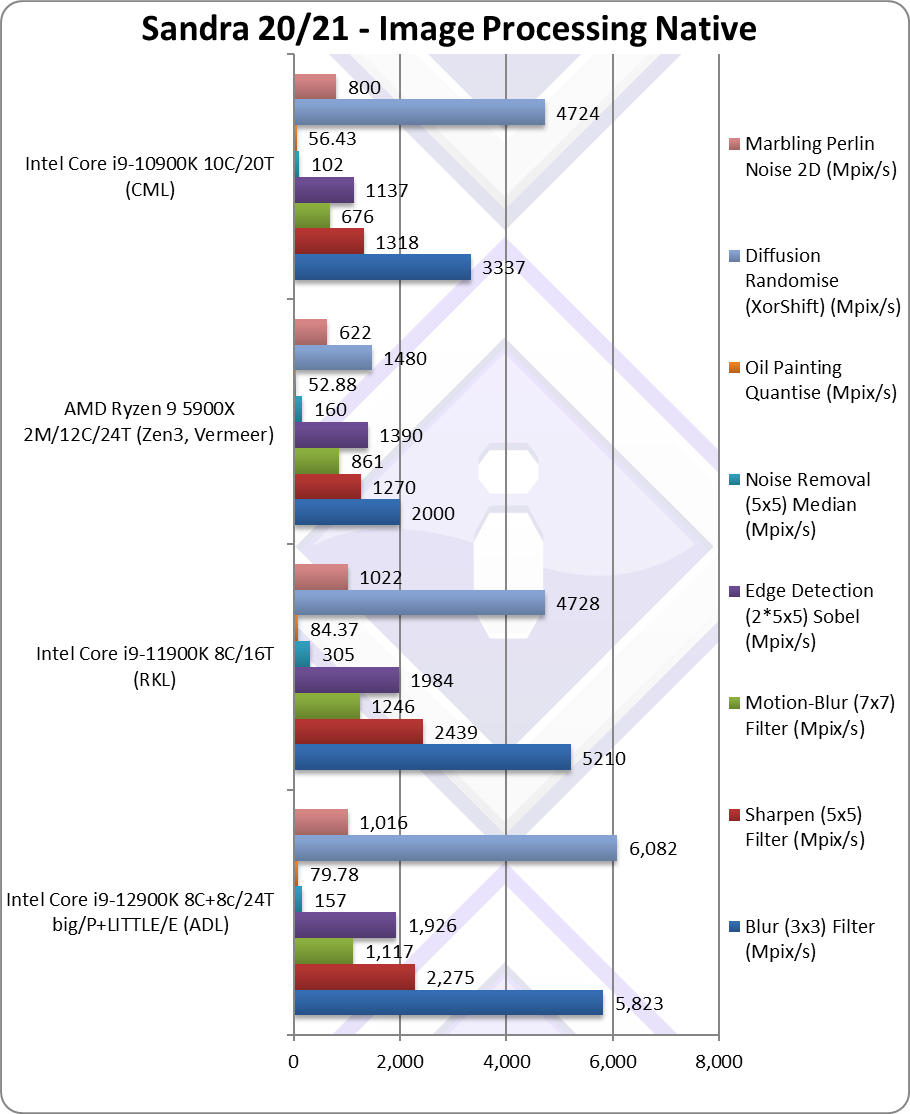
 |
Blur (3×3) Filter (MPix/s) | 5,823 [+12%] | 5,210* | 2,000 | 3,337 | In this vectorised integer workload ADL is 12% faster. |
|
Sharpen (5×5) Filter (MPix/s) | 2,275 [-7%] | 2,439* | 1,270 | 1,318 | Same algorithm but more shared data ADL is 7% slower. |
|
Motion-Blur (7×7) Filter (MPix/s) | 1,117 [-10%] | 1,246* | 861 | 676 | Again same algorithm but even more data shared 10% slower. |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 1,926 [-3%] | 1,984* | 1,390 | 1,137 | Different algorithm but still vectorised workload ADL is 3% slower. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 157 [-1/2x] | 305* | 160 | 102 | Still vectorised code ADL is 1/2 of RKL. |
|
Oil Painting Quantise Filter (MPix/s) | 79.78 [-5%] | 84.37* | 52.88 | 56.43 | ADL is 5% slower here. |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 6,082 [+29%] | 4,728* | 1,480 | 4,724 | With integer workload, ADL is 29% faster. |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 1,016 [-1%] | 1,022* | 622 | 800 | In this final test again with integer workload ADL ties RKL. |
| This benchmarks *love* AVX512 but here, after updates, ADL is within +/-10% of RKL which is a pretty good result, considering that AVX512 makes RKL about 2x faster here. Again, more importantly ADL does beat its Zen3 competition with 50% more “big” cores.
Again, the loss of AVX512 while mitigated – is still greatly felt here – with ADL w/AVX512 would have likely beat all other CPUs into dust. We guess we’ll have to wait for the future arch to see this. * using AVX512 instead of AVX2/FMA |
||||||
 |
||||||
 |
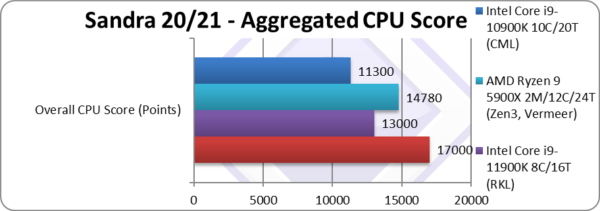
Aggregate Score (Points) | 17,000 [+31%] | 13,000* | 14,780 | 11,300 | Across all benchmarks, ADL is 30% faster than RKL. |
| Perhaps surprising despite early tests, updates to benchmarks (Sandra) and ADL platform (firmware/BIOS) have managed to improve ADL performance – so much so that it ends up 30% faster than RKL despite the loss of AVX512.
This is also about 13% faster than Zen3 competition (5900X with 12C/24T) which is a pretty impressive result for ADL. Then again, AMD will release updates soon (Zen3+, Zen4) which are likely to perform much better. Note*: using AVX512 not AVX2/FMA3. |
||||||
 |
||||||
 |
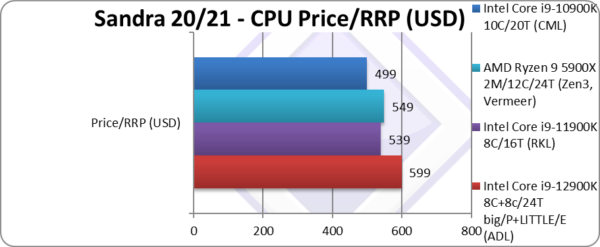
Price/RRP (USD) | $599 [+11%] | $539 | $549 | $499 | Price has gone up a bit by 11%. |
 |
||||||
|
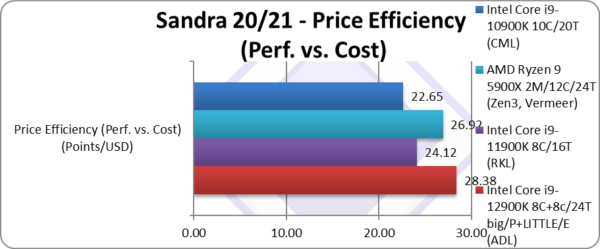
Price Efficiency (Perf. vs. Cost) (Points/USD) | 28.38 [+18%] | 24.11 | 26.92 | 22.64 | Despite the price increase, ADL is almost 20% more price efficient. |
| With its somewhat significant performance increase (+30% over RKL), ADL ends up almost 20% more performance/price (“bang-per-buck”) more efficient despite the price increase (RRP). Naturally, this *does not include* the platform cost (mainboard, expensive DDR5 memory, etc.) that is likely to make ADL much more expensive at launch than existing RKL/CML or competitor AMD designs.
Thus while ADL ends up more price efficient than AMD’s Zen3, B550/X570 mainboards do cost a lot less and even high speed DDR4 memory (3600Mt/s and higher) is also much cheaper than DDR5 at launch – thus overall, a complete Zen3 platform (e.g. 5900X + X570 + DDR4) would cost a whole lot less than an ADL platform (12900K + Z690 + DDR5) at launch. Future AMD Zen4 platform (with new FP5 socket) and DDR5 with similarly be very expensive at launch – thus it all depends on how much you are willing to spend on the “latest and greatest”. |
||||||
 |
||||||
 |
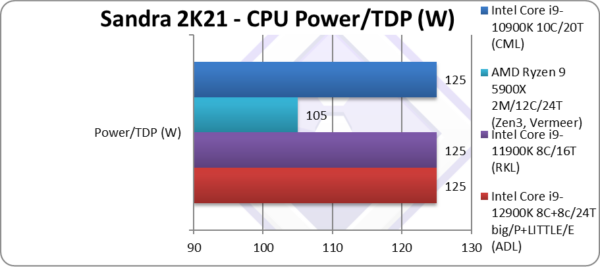
Power/TDP (W) | 125 – 250W | 125 – 250W | 105 – 155W | 125 – 155W | TDP is the same – at least on paper |
 |
||||||
|
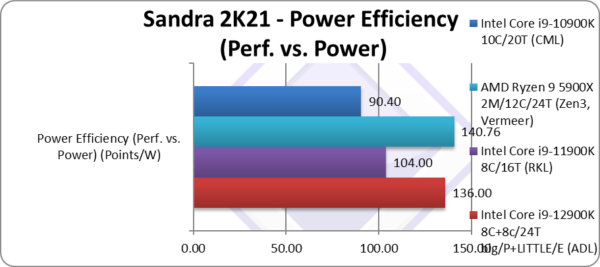
Power Efficiency (Perf. vs. Power) (W) | 136 [+31%] | 104 | 140 | 90.4 | Based on TDP, ADL is 31% more efficient. |
| If we go by listed TDP which matches RKL (and older CML), ADL is 30% more efficient – same as performance increase. But reports show that despite actual power drawn being much higher (~250W) this is still likely to be less than RKL which is really pushing things both power and thermal with AVX512 (as much as ~300W).
Zen3 remains more efficient by a (cat’s) whisker – but in real-life still using less power (~155W) than either Intel designs. However, when using just the LITTLE/E Atom cores, ADL is likely to consume far less power in low compute tasks (e.g. I/O) thus may well end up much more power efficient than any AMD design. |
||||||
SiSoftware Official Ranker Scores
- 12th Gen Intel Core i9-12900K (8C + 8c / 24T)
- 12th Gen Intel Core i9-12900KF (8C + 8c / 24T)
- 12th Gen Intel Core i7-12700K (8C + 4c / 20T)
- 12th Gen Intel Core i5-12600K (6C + 4c / 16T)
Final Thoughts / Conclusions
Summary: Forward-looking but expensive upgrade: 8/10
ADL has been designed for efficiency – not performance at any cost regardless of power usage (like RKL); it is perhaps too much to expect it to beat RKL in everything. But overall it is encouraging.
With updated Sandra benchmarks (dynamic workload allocator), firmware/BIOS/OS (Windows 11) ADL is performing a lot better than what we’ve initially seen. It is likely its performance will improve in the future as both its firmware/BIOS and OS/applications are optimised further.
- In heavy-compute SIMD tests – that use AVX512 for RKL – ADL is overall slightly faster (+10-15%). Considering that AVX512 makes RKL about 40% faster vs. AVX2/FMA3 (though in some tests much faster) – this means ADL is about 45% faster in AVX2 than RKL using AVX2 – or perhaps RKL was just not that fast with AVX2 code.
- In non-SIMD tests, we see ADL 25-40% faster than RKL that, more impressively, allows it to be competitive with Zen3 (5900X). Thus for normal non-SIMD code, ADL will perform much better. RKL was not able to match Zen3 in this way.
- Streaming (bandwidth bound) tests benefit greatly from DDR5 bandwidth but still perhaps only the big/P Cores should be used with the LITTLE/E Atom cores just wasting bandwidth. This may change as even faster DDR5 memory becomes available.
- Different core type (aka between big/P and LITTLE/E cores) transfer latencies are higher than same-core (aka between P-cores) threads sharing memory should stay on the same type of cores.
While we have not tested power here, ADL is likely to be very power efficient while running low-compute tasks (e.g. mainly I/O) with the scheduler only using LITTLE/E Atom cores and parking the high-power big/P cores. But when starting a heavy compute task – you suddenly have the full power of the big/P cores – with the LITTLE/E cores dealing with background threads (again I/O) – so that the big/P cores are not interrupted needlessly. For computers that spend most of their time (90%+) not performing heavy compute tasks – this should save a huge amount of energy.
This does not only applies in mobile/ULV market – ADL should also be a nice server (VM-host) CPU: with compute intensive VM threads using the big/P cores while less intensive, I/O and other background tasks relegated to LITTLE/E cores. For the desktop market, this is perhaps less important though less electricity usage is always a bonus in these challenging times…
- ADL brings PCIe 5.0 with even faster transfers (e.g. for NVMe and future GP-GPUs) – for once upstaging AMD as well as mass-market gaming consoles (take that Microsoft/Sony), Thunderbolt 4 and thus USB 4 that should finally solve the USB 3.x mess we’re currently in. But you will need brand-new expensive GP-GPUs and devices to take advantage of these speeds.
- ADL also brings DDR5 (and LP-DDR5X on mobile) support which is very much needed to feed all these cores (up to 16) and not keep them waiting for data. We already see this in the streaming (crypto) benchmarks where DDR4 systems are well beaten. However, at launch DDR5 is likely to be very expensive and in limited supply thus a very expensive upgrade.
As with RKL, the i7 version (Core i7 12700K – 8C+4c / 20T) will be better priced and thus most likely better value; it still includes 8 big/P cores for performance – with the loss of 4 LITTLE/E Atom cores of little importance.
Long Summary: ADL is a revolutionary design that adds support for many new technologies (hybrid, DDR5, PCIe5, TB4, ThreadDirector, etc.) but the platform will be expensive at launch and requires a full upgrade (DDR5 memory, dedicated PCIe5 GP-GPU, TB4 devices, Windows 11 upgrade, upgraded apps/games/etc.). For mobile devices (laptops/tablets) it is likely to be a better upgrade.
Summary: Forward-looking but expensive upgrade: 8/10
Further Articles
Please see our other articles on:
- CPU
- Cache & Memory
- GP-GPU
Disclaimer
This is an independent review (critical appraisal) that has not been endorsed nor sponsored by any entity (e.g. Intel, etc.). All trademarks acknowledged and used for identification only under fair use.
The review contains only public information and not provided under NDA nor embargoed. At publication time, the products have not been directly tested by SiSoftware but submitted to the public Benchmark Ranker; thus the accuracy of the benchmark scores cannot be verified, however, they appear consistent and pass current validation checks.
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!