What is “Raspberry Pi 3B(+)”?
It is the 3th generation of the Raspberry Pi series of single-board computers (SBC) that can be consider to have single-handedly restarted the enthusiast computer revolution of the 1980s. Selling millions of units per year, it is the best selling UK computer and used far and wide for many projects.
Unlike x86 world, where main-boards need discrete CPUs, graphics boards, memory modules, etc. to function – in the ARM world this is not common, with single-board containing not just the SoC (CPU, graphics) but also soldered memory, Ethernet, WiFi/Bluetooth that are not upgrade-able.
 The Pi has always used custom-made Broadcom SoCs based on the ARM architecture (BCM series) – with the Pi3B(+) now using AArch64 64-bit Cortex-A cores! Unfortunately, the memory is still 1GB that limits the running of large, unoptimised operating systems like Windows.
The Pi has always used custom-made Broadcom SoCs based on the ARM architecture (BCM series) – with the Pi3B(+) now using AArch64 64-bit Cortex-A cores! Unfortunately, the memory is still 1GB that limits the running of large, unoptimised operating systems like Windows.
What is “Windows Arm64”?
It is the 64-bit version of “desktop” Windows 10/11 for AArch64 ARM devices – analogous to the current x64 Windows 10/11 for Intel & AMD CPUs. While “desktop” Windows 8.x has been available for ARM (AArch32) as Windows RT – it did not allow running of non-Microsoft native Win32 applications (like Sandra) and also did not support emulation for current x86/x64 applications.
We should also recall that Windows Phone (though now dead) has always run on ARM devices and was first to unify the Windows desktop and Windows CE kernels – thus this is not a brand-new port. Windows was first ported to 64-bit with the long-dead Alpha64 (Windows NT 4) and then Itanium IA64 (Windows XP 64) which showed the versatility of the NT micro-kernel.
By contrast, Windows 10/11 Arm64 is able to run both native AArch64 applications (compiled for Arm64 like Sandra) as well as emulating x86/x64 and also ARM (AArch32) native applications through WOW (Windows on Windows emulation ). While it does come with native versions of in-box drivers for many peripherals/devices – it may not a driver for very new peripheral/device and the manufacturers are unlikely to provide support for Arm64. For some devices, standard in-box “class” drivers (e.g. NVMe controller/SSD, AHCI controller/SSD, USB controller, keyboard, mouse, etc.) do work but otherwise a driver is required.
How do I get Windows Arm64 on Raspberry Pi 3B(+)?
Thanks to a team of extremely talented developers (far more talented than us) and lots of work – firmware (BIOS/UEFI), drivers and even an installer automatically creates a bootable micro-SD or USB drive:
- You Can Now Run Windows 10 on the Raspberry Pi 3 @ Tom’s Hardware
- Windows on Raspberry Project @ WORP
- Download Windows 10/11 Arm64 ISO @ UUP Dump
What hardware do I need to run Windows Arm4 on Raspberry Pi 3B(+)?
In addition to the Pi itself, we recommend additional hardware as Windows is quite a demanding OS:
- Raspberry Pi 3B+ or Raspberry Pi 3B
- Faster CPU makes it more responsive
- Fast Storage I/O for Main Storage:
- High Performance USB stick – e.g. SanDisk Extreme USB series
- USB to SATA adapter + SATA SSD Drive 64GB+
- Fast Storage I/O for Page File:
- High Performance micro-SD card – e.g. SanDisk micro-SD Ultra series
- High performance cooling system/case
With 1GB memory, even latest (optimised) Windows 10/11 will need a page (swap) file. Unfortunately, the USB storage is not a suitable target – thus a micro SD card needs to be used in addition to host the page file. This is actually *a good thing* as you are distributing the I/O paging load to the other device – and due to the shared USB 2.0 controller, the primary storage I/O won’t be great whatever stick you use.
The Pi 3B+ comes “pre-overclocked” at 1.4GHz, thus despite the heatspreader, it runs quite hot. You will need to use good cooling, to avoid down-clock, either an all-metal passive cooling case or perhaps even an active-fan/heatsink combo. Do note that metal cases do attenuate the WiFi/Bluetooth signal from the internal antenna – however you are best using the Ethernet connectivity for best network performance.
The original Pi 3B can be overclocked higher than its 1.2GHz base (approx 1.35GHz), but again requires decent cooling and over-volting (within warranty range, more possible but not recommended). It is worth it but does not make a huge difference.
Raspberry Pi 3 SoC Details
- Broadcom BCM2837 SoC custom-made for the Pi Foundation
- ARMv8-A (Arm64) 64-bit core (vs. Pi 2 ARMv7 cores)
- 4x ARM Cortex A53 “little-cores” (vs. Cortex A7 “little-cores” in Pi 2)
- 1.4GHz on 3B+, 1.2 on original 3B
- 28nm++ process
- Unified 512kB L2 cache (vs. 256kB on Pi 2)
- Same micro-USB and HDMI ports
The (arguably) most important upgrade vs. Pi 2 is the AArch64 (ARMv8) capable cores, allowing the use of 64-bit operating systems for the first time. While limited to 1GB, thus well within the range of normal 32-bit operating systems, ARMv8 mode is a huge instruction set change (ISA) offering better performance vs. older ARMv7 mode.
The A53 core is perhaps the most widely used 64-bit core today, powering most low-cost/efficient mobile/tablet/gaming devices – thus perhaps the choice for the Pi – an inexpensive computer.
ARM Advanced Instructions Support
SIMD: As in the x86 world, ARM supports SIMD instructions called “NEON” operating on 128-bit width registers – equivalent to SSE2. However, there are 32 of them – while x64 SSE/AVX only provide 16 – until AVX512 which also provides 32. In most algorithms we can use them in batches of 4 – effectively making them 512-bit!
Unlike newer cores, the older A7X cores do not support SVE (“Scalable Vector eXtensions” – the successor of NEON), although current designs are still just 128-bit width although they do provide more flexibility especially when implementing complex algorithms.
Crypto: Similar to x86, ARM does provide hardware-accelerated (HWA) encryption/decryption (AES, SM3) as well as hashing (SHA1, SHA2, SHA3, SM4) – but the Broadcom SoC cores have these features disabled! Thus the Pi does not perform well as a crypto device.
Virtualisation: The ARM cores do have hardware virtualisation – but currently the UEFI firmware does not provide the required fuctionality to enable Hyper-V (which is not publicly available anyway). You will need VmWare ESXi ARM edition or KVM (e.g. Proxmox 7 PVE) and then perhaps try to run Windows 10/11 Arm64 on it!
Security Extensions: ARM cores since ARMv6 (!) have included TrustZone secure virtualisation. AMD’s own recent CPUs all contain an ARM core (Cortex A5?) supporting TrustZone handling the security functionality (e.g. PSP / firmware-emulated TPM). See our article
Crypto-processor (TPM) Benchmarking: Discrete vs. internal AMD, Intel, Microsoft HV.
Changes in Sandra to support ARM
As a relatively old piece of software (launched all the way back in 1997 (!)), Sandra contains a good amount of legacy but optimised code, with the benchmarks generally written in assembler (MASM, NASM and previously YASM) for x86/x64 using various SIMD instruction sets: SSE2, SSSE3, SSE4.1/4.2, AVX/FMA3, AVX2 and finally AVX512. All this had to be translated in more generic C/C++ code using templated instrinsics implementation for both x86/x64 and ARM/Arm64.
As a result, some of the historic benchmarks in Sandra have substantially changed – with the scores changing to some extent. This cannot be helped as it ensures benchmarking fairness between x86/x64 and ARM/Arm64 going forward.
For this reason we recommend using the very latest version of Sandra and keep up with updated versions that likely fix bugs, improve performance and stability.
CPU Performance Benchmarking
In this article we test CPU core performance; please see our other articles on:
- CPU
- Cache & Memory
- GP-GPU
Hardware Specifications
We are comparing the Raspberry Pi with Atom x64 processors of similar vintage – all running current Windows 10, latest drivers.
| Specifications | Raspberry Pi 4B (BCM2711) | Raspberry Pi 3B+ (BCM2837) | Intel Atom Z3740 |
Intel Atom x5-Z8350 | Comments | |
| Arch(itecture) | Cortex A72 (Arm64) 16nm | Cortex A53 (Arm64) 28nm | Atom “BayTrail” (x64) 22nm | Atom “CherryTrail” (x64) 14nm | Little vs. Atom | |
| Launch Date |
2019 | 2016 | 2013 | 2016 | Similar age | |
| Cores (CU) / Threads (SP) | 4C / 4T | 4C / 4T | 4C / 4T | 4C / 4T | Same number of threads | |
| Rated Speed (GHz) | 1.5 | 1.2 | 1.33 | 1.44 | Similar base clock | |
| All/Single Turbo Speed (GHz) |
2.0-2.2 | 1.4-1.6 | 1.87 | 1.92 | Much lower turbo for PIs | |
| Rated/Turbo Power (W) |
4-6 (whole SBC) |
3-5 (whole SBC) | 2-4 (SoC only) | 2-4 (SoC only) | Far less power for whole SBC | |
| L1D / L1I Caches | 4x 32kB 2-way | 4x 48kB 3-way | 4x 32kB 4-way | 4x 32kB 2-way | 4x 32kB 4-way | 4x 32kB 4-way | 4x 32kB 4-way | 4x 32kB 4-way | Similar L1 caches | |
| L2 Caches | 1MB 16-way | 512kB 16-way | 2x 1MB | 2x 1MB | Atom has 2-4x bigger L2 | |
| L3 Cache(s) | n/a | n/a | n/a | n/a | None have L3 | |
| Microcode (Firmware) | 1.37 | 1.37 | 030673-320 | 0406C4-411 | Updates keep on coming | |
| Special Instruction Sets |
v8-A, VFP4, TZ, Neon | v8-A, VFP4, TZ, Neon | AES, VT-x, SSE4.2 | AES, VT-x, SSE4.2 | No crypto on BCM – big loss | |
| SIMD Width / Units |
128-bit | 128-bit | 128-bit | 128-bit | Same width | |
| Price / RRP (USD) |
$55 (whole SBC) | $35 (whole SBC) | $25 (CPU only) | ~$21 (CPU only) | Pi price is for whole BMC! (including memory) | |
Disclaimer
This is an independent review (critical appraisal) that has not been endorsed nor sponsored by any entity (e.g. Pi, etc.). All trademarks acknowledged and used for identification only under fair use.
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets, on both x64 and Arm64 platforms.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64/Arm64, latest drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations where supported.
| Native Benchmarks | Raspberry Pi 3B+ (BCM2837) 1.2GHz 3W | Raspberry Pi 3B+ (BCM2837) 1.6GHz 5W | Intel Atom Z3740 1.87GHz 2W | Intel Atom x5-Z8350 1.92GHz 2W | Comments | |
 |
||||||
 |
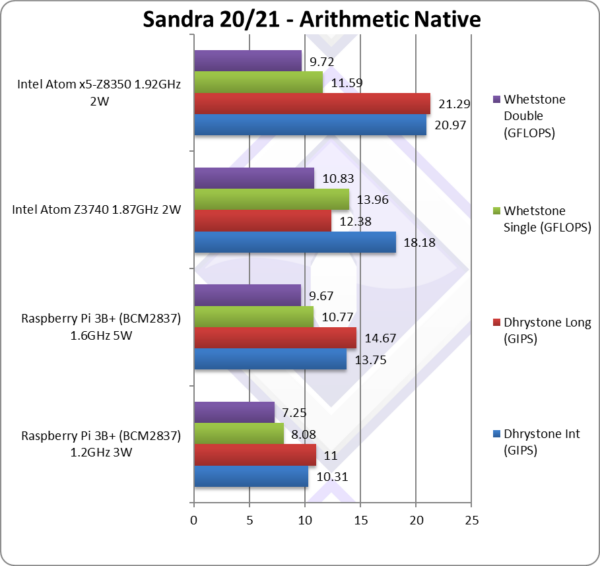
Native Dhrystone Integer (GIPS) | 10.31 | 13.74 [-25%] | 18.18 | 20.97 | Pi3 is 25% slower than old Atom. |
|
Native Dhrystone Long (GIPS) | 11 | 14.67 [+18%] | 12.38 | 21.29 | A 64-bit integer workload makes it 18% faster. |
|
Native FP32 (Float) Whetstone (GFLOPS) | 8.08 | 10.77 [-23%] | 13.96 | 11.59 | With floating-point, Pi3 is 23% slower. |
|
Native FP64 (Double) Whetstone (GFLOPS) | 7.25 | 9.67 [-11%] | 10.83 | 9.72 | With FP64 it is 11% slower. |
| Even in these standard C legacy tests, the Pi3 is a bit outclassed even against old BayTrail Atom; even heavily overclocked to 1.6GHz it does not help much. Windows is just not the OS for the Pi 3.
Note*: using SSE2-3 SIMD processing. |
||||||
 |
||||||
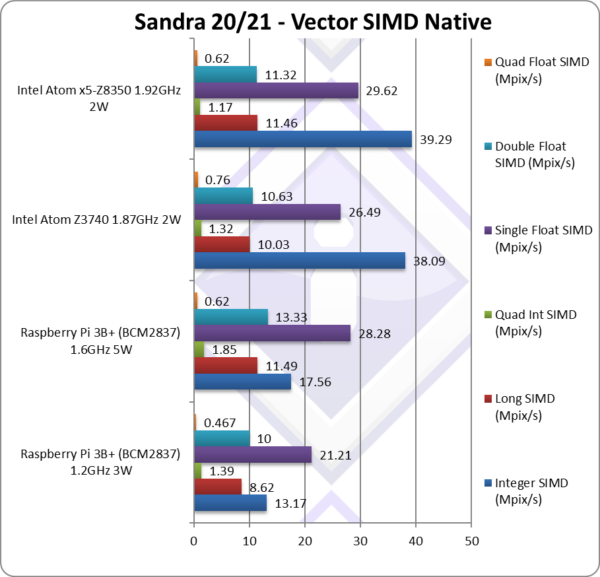
 |
Native Integer (Int32) Multi-Media (Mpix/s) | 13.17** | 17.56** [-1/2x] | 38.09* | 39.29* | Atom is 2x faster than Pi3 OC’d. |
|
Native Long (Int64) Multi-Media (Mpix/s) | 8.63** | 11.49** [+14%] | 10.02* | 11.46* | With a 64-bit, Pi3 OC is 14% faster. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 1.39** | 1.85** [+40%] | 1.32* | 1.17* | Using 64-bit int to emulate Int128 Pi3 is 40% faster. |
|
Native Float/FP32 Multi-Media (Mpix/s) | 21.21** | 28.28** [+6%] | 26.49* | 29.62* | In this FP vectorised test Pi3 is 6% faster. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 10** | 13.33** [+25%] | 10.63* | 11.32* | Switching to FP64 Pi3 is 25% slower. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 0.46** | 0.62** [-20%] | 0.76* | 0.62* | Using FP64 to mantissa extend FP128 Pi3 is 20% slower. |
| With heavily vectorised SIMD workloads – due to Neon’s extra registers (32) and flexibility with respect to even SSE2-SSE4, Pi3 does much better with decent improvement in most tests (except one). The A53 is pretty much the lowest compute power ARMv8 core but it can hold its own against Atom cores of similar vintage.
Note*: using SSE2/4 128-bit (or higher) SIMD processing. Note**: using NEON 128-bit (or higher) Advanced SIMD processing. |
||||||
 |
||||||
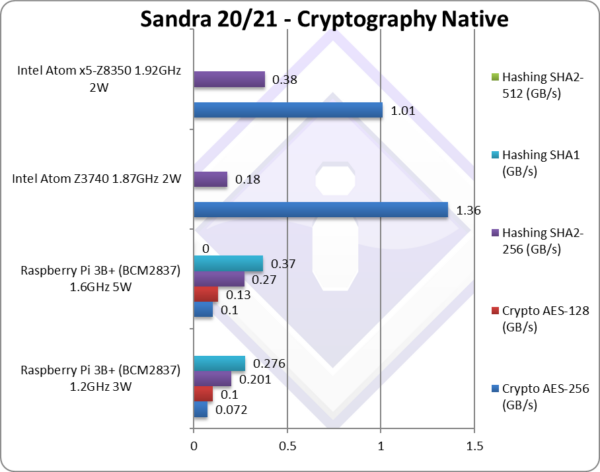
 |
Crypto AES-256 (GB/s) | 0.072 | 0.1 [1/10x] | 1.36* | 1.01* | No hardware acceleration, Pi is 1/10 of Atom. |
|
Crypto AES-128 (GB/s) | 0.1 | 0.13 | No change with AES128. | ||
|
Crypto SHA2-256 (GB/s) | 0.201 | 0.27 [+50%] | 0.18*** | 0.38*** | Pi3 bests old Atom but not SHA HWA Atom. |
|
Crypto SHA1 (GB/s) | 0.276 | 0.37 | Less compute intensive SHA1. | ||
|
Crypto SHA2-512 (GB/s) | SHA2-512 is not accelerated by SHA HWA. | ||||
| Allegedly for licensing/cost reasons, the BCM range as used in the Pi does not enable the AES nor SHA crypto hardware-acceleration (HWA) instructions – even though pretty much all other ARMv8 cores include it! This means we are forced to use software emulation which is about 10x (ten times) slower which is a big shame.
In the meantime, we are converting the multi-buffer SSE4 hashing code to NEON which should greatly improve performance by hashing 4x buffers simultaneously. This should match the Atom, although the relatively low memory bandwidth (LP-DDR4) may hinder performance to some extent. Note**: using multi-buffer SSE4 (4x) hashing. Note***: using SHA HWA (hardware acceleration). Note****: using multi-buffer Neon (4x) hashing. |
||||||
 |
||||||
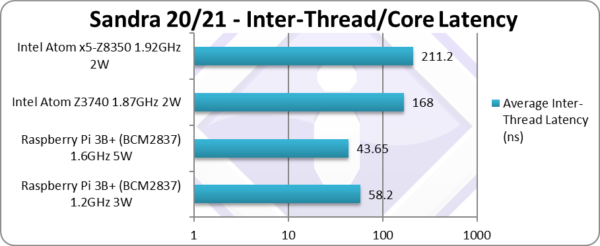
 |
Inter-Module (CCX) Latency (Same Package) (ns) | 58.2 | 43.65 [1/4x] | 168 | 211 | 1/4 of Atom latency! |
| Without SMT and single cluster, there is no difference between thread-pairings (no “best”/”worst” case) and and we have an unified L2. [Note Atom having separate L2 caches could be thought as different modules]
At base clock, Pi3 with unified L2 cache is 1/3 of Atom latency – while over-clocked latency falls to 1/4 (a fourth!) of Atom – meaning inter-core transfers are quick. With Atom having 2 separate L2 caches, some pairings need to synchronize at main memory thus far slower. |
||||||
 |
||||||
|
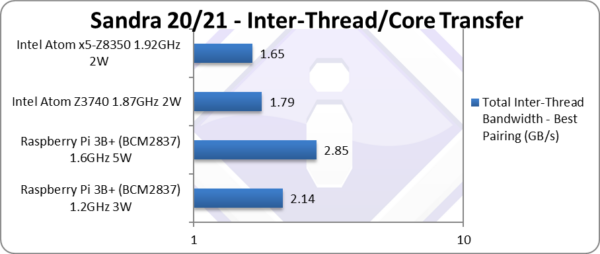
Total Inter-Thread Bandwidth – Best Pairing (GB/s) | 2.14** | 2.85** [+60%] | 1.79* | 1.65* | Pi3 manages 60% more bandwidth than Atom! |
| Without SMT and single cluster, there is no difference between thread-pairings (no “best”/”worst” case) and and we have an unified L2. [Note Atom having separate L2 caches could be thought as different modules]
With the unified L2 cache, even at stock clock the old Pi3 has higher inter-core bandwidth than Atom and over-clocked as much as 60% more! This is a great result – and shows why newer Atoms have unified L2 cache. Note:* using SSE 128-bit wide transfers. Note**: using NEON 128-bit wide transfers. |
||||||
 |
||||||
 |
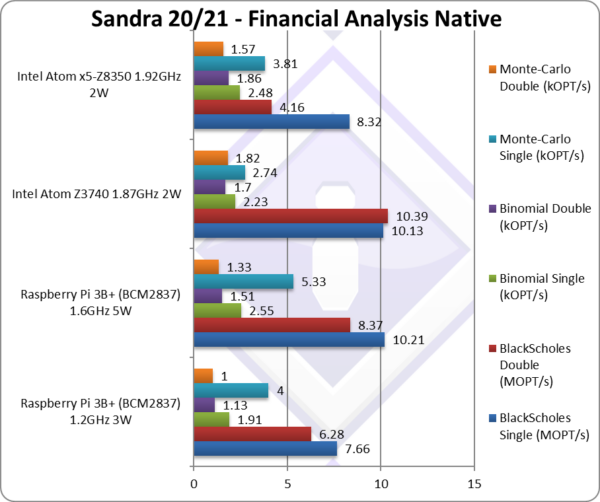
Black-Scholes float/FP32 (MOPT/s) | 7.66 | 10.21 [=] | 10.13 | 8.32 | Black-scholes is un-vectorised and compute heavy. |
|
Black-Scholes double/FP64 (MOPT/s) | 6.28 | 8.37 [-20%] | 10.39 | 4.16 | Using FP64 Pi3 is 20% slower. |
|
Binomial float/FP32 (kOPT/s) | 1.91 | 2.55 [+14%] | 2.23 | 2.48 | Binomial uses thread shared data thus stresses the cache & memory system. |
|
Binomial double/FP64 (kOPT/s) | 1.13 | 1.51 [-12%] | 1.7 | 1.86 | With FP64 Pi3is 12% slower. |
|
Monte-Carlo float/FP32 (kOPT/s) | 4 | 5.33 [2x] | 2.74 | 3.81 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches. |
|
Monte-Carlo double/FP64 (kOPT/s) | 1 | 1.33 [-27%] | 1.82 | 1.57 | Switching to FP64 Pi3 is 27% slower. |
| With non-SIMD financial workloads, similar to what we’ve seen in legacy floating-point code (Whetstone), Pi3 does pretty well in some algorithms – though those involving thread-sharing data (Binomial, Monte-Carlo) seem to take a larger hit.
In any case, such code is these days best offloaded to the GPU via one of the GP-GPU interfaces (OpenCL, Vulkan, DirectX Compute, etc.) – but the Pi4 does not have a “proper” video driver with compute acceleration we cannot really test its prowess. |
||||||
 |
||||||
 |
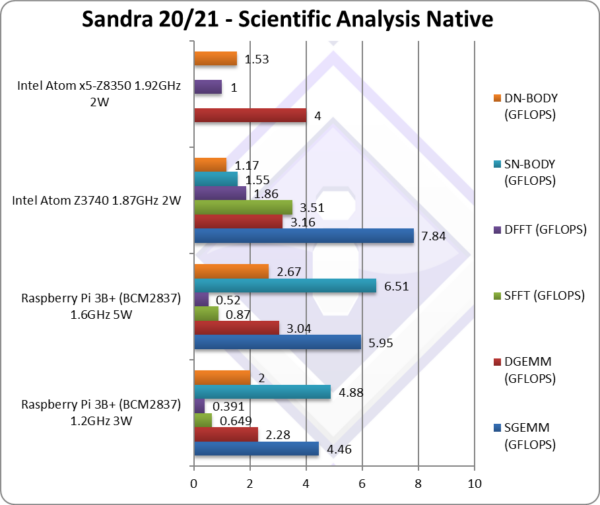
SGEMM (GFLOPS) float/FP32 | 4.46** | 5.95** [-25%] | 7.84* | In this tough vectorised algorithm Pi3 is 25% slower. | |
|
DGEMM (GFLOPS) double/FP64 | 2.28** | 3.04** [-4%] | 3.16* | 4* | With FP64 vectorised code, Pi3 is just 4% slower. |
|
SFFT (GFLOPS) float/FP32 | 0.649** | 0.87** [1/4x] | 3.51* | FFT is also heavily vectorised but memory dependent. | |
|
DFFT (GFLOPS) double/FP64 | 0.391** | 0.52** [1/4x] | 1.86* | 1* | With FP64 code, Pi4 is 1/4 the Atom performance. |
|
SN-BODY (GFLOPS) float/FP32 | 4.88** | 6.51** [4.2x] | 1.55* | N-Body simulation is vectorised but with more memory accesses. | |
|
DN-BODY (GFLOPS) double/FP64 | 2** | 2.67** [2.3x] | 1.17* | 1.53* | With FP64 Pi3 is finally 2.3x faster than Atom! |
| With highly vectorised SIMD code (scientific workloads), it is clear that a lot of work is needed to optimise code for ARM to get it to match x86/x64 in performance. In some algorithms (GEMM, N-BODY) it is doing well but in memory latency bound algorithms that also stress unified caches (L2 here) (FFT) – performance does suffer.
Note*: using SSE2-4 128-bit SIMD (or wider). Note**: using NEON 128-bit SIMD (or wider). |
||||||
 |
||||||
 |
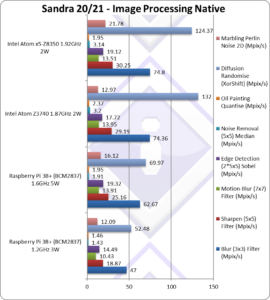
Blur (3×3) Filter (MPix/s) | 47** | 62.67** [-16%] | 74.36* | 74.8* | In this vectorised integer workload Pi3 is 16% slower. |
|
Sharpen (5×5) Filter (MPix/s) | 18.87** | 25.16** [-14%] | 29.19* | 30.25* | Same algorithm but more shared data Pi3 is 14% slower. |
|
Motion-Blur (7×7) Filter (MPix/s) | 10.43** | 13.91** [-1%] | 13.95* | 13.51* | Again same algorithm but even more data shared we’re tied. |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 14.49** | 19.32** [+9%] | 17.72* | 19.12* | Different algorithm but still vectorised workload Pi3 is 9% faster. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 1.43** | 1.91** [-41%] | 3.2* | 3.14* | Still vectorised code Pi3 is 41% slower. |
|
Oil Painting Quantise Filter (MPix/s) | 1.46** | 1.95** [-18%] | 2.37* | 1.95* | In this tough filter, Pi3 is 18% slower. |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 52.48** | 69.97** [1/2x] | 132 | 124 | With 64-bit integer workload, Pi3 is 1/2 slower than Atom. |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 12.09 | 16.12 [+24%] | 12.97 | 21.78 | In this final test (scatter/gather) Pi3 is 24% faster. |
| We know these benchmarks *love* SIMD, with AVX2/AVX512 always performing strongly – and Pi3 with Neon’s extra resources (registers) and versatility does well against Atom. In tests involving scatter/gather and thus memory latency bound – the Pi3 does less well and is 25-35% slower than the old Atom.
Again, these days such image-processing algorithms are offloaded to the GPU and unlikely to be run on the CPU – except for very complex non-linear filters – thus performance is acceptable. Note*: using SSE2-4 128-bit SIMD (or wider). Note**: using NEON 128-bit SIMD (or wider). |
||||||
 |
||||||
 |
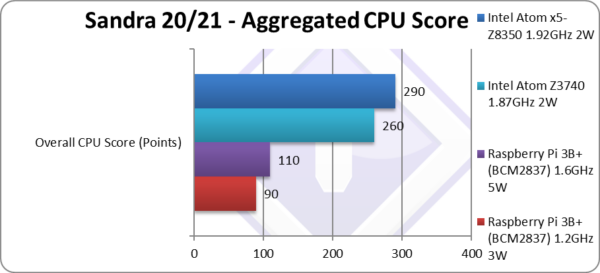
Aggregate Score (Points) | 90 | 110 [-58%] | 260 | 290 | Across all benchmarks, Pi4 is 58% slower than Atom. |
| Perhaps surprising despite good performance, Pi3 over-clocked to 1.6GHz still scores only 58% of the old Atom BayTrail, although there are early days; with optimisations we are confident the score will only improve – while Atom is pretty much fully optimised and unlikely to extract more performance. Additional SIMD/Neon code paths (e.g. hashing) to compensate for the lack of hardware acceleration will also increase the score significantly. | ||||||
 |
||||||
 |
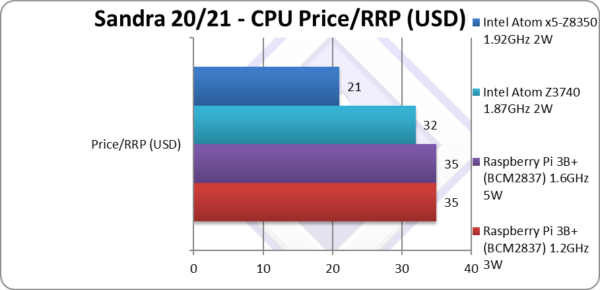
Price/RRP (USD) | $35 (whole SBC) | $35 (whole SBC) | $32 SoC only (~$100 total) | $21 SoC (~$90 total) | Pi3 cost is for the whole SBC (including memory!) while Atom is for SoC only. |
 |
||||||
|
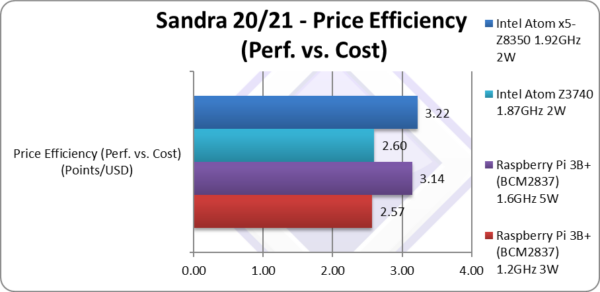
Price Efficiency (Perf. vs. Cost) (Points/USD) | 2.57 | 3.14 [+20%] | 2.6 | 3.22 | Pi3 OC is 20% better value. |
| Despite the relatively low total score, the old Pi3 is more price/performance efficient than old BayTrail Atom and when OC’d ties with the newer (but still old) CherryTrail Atom. Withe the Atom requiring a mainboard (with the SoC + heatsink built-in) and 1-2GB DDR2 SO-DIMM stick you can see how costs mount up. The Pi3 board is far smaller, and likely the cheapest mini computer you can get your hands on… except the Pi 4 that is! | ||||||
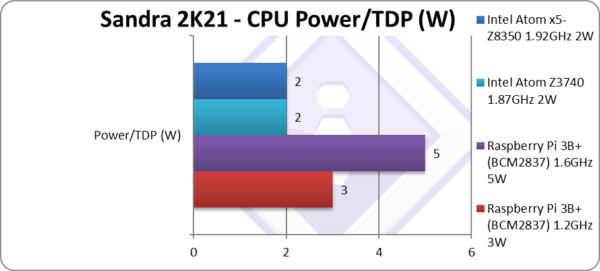 |
||||||
 |
Power/TDP (W) | 3W (whole SBC) | 5W (whole SBC) | 2W SoC, ~10W whole | 2W SoC, ~10W whole | Pi3 whole SBC is as much as Atom SoC! |
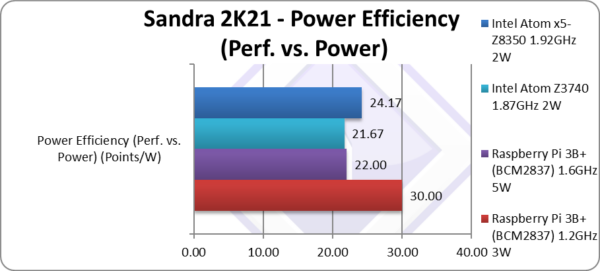 |
||||||
|
Power Efficiency (Perf. vs. Power) (W) | 30 | 22 [+1%] | 21.67 | 25.17 | The Pi3 is ties with Atom. |
| Despite the Pi3 SBC consuming only 3-5W, the Atom is not that far behind and puts a good showing. While over-clocking to 1.6GHz greatly improves performance, in terms of power it is not worth it – with efficiency dropping 50%. | ||||||
SiSoftware Official Ranker Scores
- Microsoft SQ2 (Microsoft Surface X)
- Raspberry Pi 4 Model B (Broadcom BCM2711)
- Raspberry Pi 3 Model B+ (Broadcom BCM2837)
- Apple Silicon on Parallels VM
Is x86 Dead?
We think: not yet! But the signs are not good…
The Pi 3B(+) is pretty old now – but surprisingly not yet obsolete! Its A53 cores – despite being the least powerful ARMv8 cores – can still be competitive against Atom cores of similar vintage, and thus still serve as the “little” cores in a big/LITTLE hybrid SoC.
It is the lack of more memory (1GB too little) and too slow I/O (no SATA, eMMC, etc.) that makes the Pi3 unable to run Windows decently. If Windows ARM32 (AArch32) were available, it would likely have performed better due to lower memory requirements; even Raspbian (Raspberry OS) / Linux / Android for Pi 3 were 32-bit until quite recently.
Considering there were lots of slow Windows 8.x Atom tablets with 1-2GB memory that headed to the e-waste dump, perhaps an ARM Windows with a similar SoC to Pi3 may not have done better. Windows simply needs far more memory, I/O and even compute to be usable. Meanwhile, in the Pi eco-system, something like a Pi3 is “over-powered” for a lot of the tasks!
Final Thoughts / Conclusions
Raspberry Pi3: Able to (just about) run Windows (and Sandra) natively!
The Raspberry Pi range has been a huge success, there is no question about that. But due to its ARM platform – it had always run a flavour of Linux (can also run FreeBSD, etc.). Windows, for all its issues – it is still the desktop leader and this does not seem to be changing any time soon. While there have been ARM versions of Windows going back decades (Windows CE, Windows Mobile), the kernel/Win32 API were unified with Windows Phone (now dead), and we had actual Windows tablets with Windows RT (also dead) – we finally have desktop 64-bit ARM64 Windows with feature parity with standard 64-bit x64 Windows.
Through emulation it was possible to run x86 code, but with just 1GB of memory and micro-SD for storage, the Pi 3B(+) can just about run Windows Arm64; its A53 “little” cores, however can tango with similar vintage Atom cores. In contrast, its successor the Pi 4B with 4-8GB can run Windows pretty well (and we test that in . article) and for a cheap price too.
All we can say at this time is that it is a pity that Windows ARM (aka RT) was not open to native apps as the Pi 3 could likely run it just as well as Atom 32-bit of that era for a much lower cost. With a bit more memory, aka 2GB, the Pi 3 could have been a formidable competitor to the Atom – and the rest, as they say, would have been history…
Raspberry Pi3: Able to (just about) run Windows (and Sandra) natively!
Further Articles
Please see our other articles on:
- CPU
- Cache & Memory
- GP-GPU
Disclaimer
This is an independent review (critical appraisal) that has not been endorsed nor sponsored by any entity (e.g. Pi, etc.). All trademarks acknowledged and used for identification only under fair use.
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!