What is FP16 (“half”)?
FP16 (aka “half” floating-point) is the IEEE lower-precision floating-point representation that has recently begun to be supported by GPGPUs for compute (e.g. Intel EV9+ Skylake GPU, nVidia Pascal/Turing) and soon by CPUs (BFloat16). While originally meant for mobile devices in order to reduce memory and compute requirements – it also allows workstations/servers to handle deep neural-network workloads that have exploded in both size and compute power.
While not all algorithms can use such low precision and thus may require parts to use normal precision, nevertheless FP16 can still be used in many instances and thus needs to be implemented and benchmarked.
In addition we see the introduction of specialised compute engines that specifically support FP16 (and not higher precision like FP32/FP64) like “Tensor Engines”.
What are “Tensors”?
A tensor engine (hardware accelerator) is a specialised processing unit that accelerates matrix multiplication in hardware, in this case the latest nVidia GPGPU architectures (Pascal/Turing). While the former was targeted to workstations (Titan), the latter powers all consumer (series 2000) graphics cards – thus it has entered the mainstream. In addition, the speed restrictions (e.g. Maxwell FP16 processing speed was limited to 1/64 FP32 speed) have been lifted.
While it is used in other algorithms, it is intended to be used to accelerate neural networks (so called “AI”) that are now being used in mainstream local workloads like image/video processing (scaling, de-noising, etc.), games (anti-aliasing, de-noising when using with ray-tracing, bots/NPCs, procedural world-building, etc.).
In this article we are investigating both FP16/half performance vs. standard FP32 as well as the performance improvement when using tensors.
- nVidia Titan RTX / 2080Ti: Turing GPGPU performance in CUDA and OpenCL
- nVidia Titan V : Volta GPGPU performance in CUDA and OpenCL
- nVidia Titan X : Pascal GPGPU performance in CUDA and OpenCL
FP16/half Performance
We are testing GPGPU performance of the GPUs in CUDA as it supports both FP16/half operations and tensors; hopefully both OpenCL and DirectX will also be updated to support both FP16/half (compute) and tensors.
Results Interpretation: Higher values (MPix/s, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest nVidia drivers (Jan 2019). Turbo / Dynamic Overclocking was enabled on all configurations.
For image processing, Titan V brings big performance increases from 50% to 4x (times) faster than Titan X a big upgrade. If you are willing to drop to FP16 precision, then it is an extra 50% to 2x faster again – while naturally FP16 is not really usable on the X. With potential 8x times better performance Titan V powers through image processing tasks.
| Processing Benchmarks | nVidia Titan X FP32 |
nVidia Titan X FP16/half |
nVidia Titan V FP32 |
nVidia Titan V FP16/half |
Comments | |
 |
||||||
 |
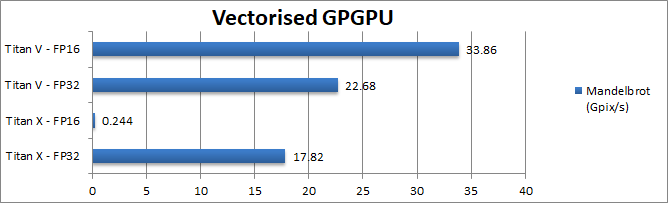
Mandel (Mpix/s) | 17.82 | 0.244 | 22.68 | 33.86 [+49%] | In a purely compute-heavy algorithm FP16 can bring 50% improvement. |
| When F16 precision is sufficient, compute heavy algorithms improve greatly on the unlocked Titan V; we see that on the previous Titan X FP16 is not worth using as its performance is way too low. | ||||||
 |
||||||
 |
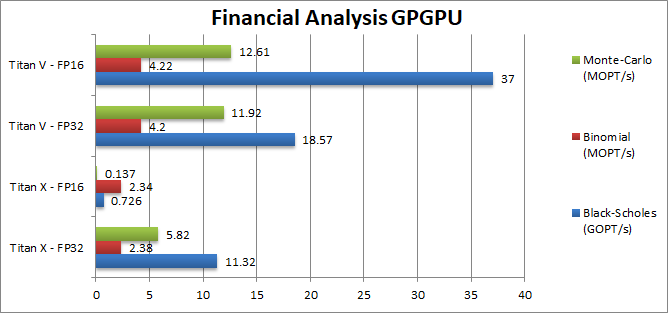
Black-Scholes (MOPT/s) | 11.32 | 0.726 | 18.57 | 37 [+99%] | B/S benefits greatly from FP16 both through decreased memory storage and low precision compute. |
|
Binomial (kOPT/s) | 2.38 | 2.34 | 4.2 | 4.22 [+1%] | Binomial requires higher precision for the results to make sense thus sees almost no benefit. |
|
Monte-Carlo (kOPT/s) | 5.82 | 0.137 | 11.92 | 12.61 [+6%] | M/C also uses thread shared data but read-only but still requires higher precision. |
| For financial workloads, FP16 is generally too low and most parts of the algorithm do need to be performed in FP32; we can still use FP16 as data storage but the heavy compute sees little benefit. When FP16 can be deployed as in B/S then we see far higher performance benefits. | ||||||
 |
||||||
 |
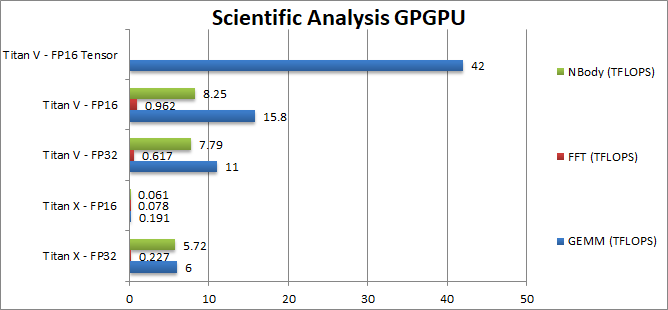
GEMM (GFLOPS) | 6 | 0.191 | 11 | 15.8 [+44%] /
42 Tensor [+4x] |
Here we see the power of the tensor cores – in FP16 Titan V is 4 times faster! Normal compute is still almost 50% faster a good result. |
|
FFT (GFLOPS) | 0.227 | 0.078 | 0.617 | 0.962 [+56%] | FFT also benefits from FP16 due to reduced memory pressure. |
|
NBODY (GFLOPS) | 5.72 | 0.061 | 7.79 | 8.25 [+6%] | N-Body simulation needs some parts in FP32 thus does not benefit as much. |
| The new Tensor cores show their power in FP16 GEMM – we see 4x (times) higher performance than in FP32 which can go a long way in making neural network processing much faster not to mention 1/2 memory size requirement of FP32. | ||||||
 |
||||||
 |
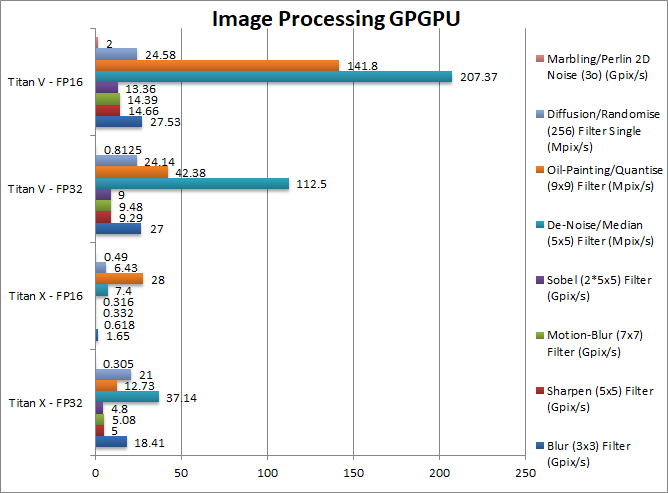
Blur (3×3) Filter (MPix/s) | 18.41 | 1.65 | 27 | 27.53 [+2%] |
Surprisingly 3×3 does not seem to benefit much from FP16 processing performance. |
|
Sharpen (5×5) Filter (MPix/s) | 5 | 0.618 | 9.29 | 14.66 [+58%] | Same algorithm but more shared brings over 50% performance improvement. |
|
Motion-Blur (7×7) (MPix/s) | 5.08 | 0.332 | 9.48 | 14.39 [52%] | Again same algorithm but even more data shared also brings around 50% better performance. |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 4.8 | 0.316 | 9 | 13.36 [+48%] | Still convolution but with 2 filters – similar 50% improvement. |
|
Noise Removal (5×5) Median Filter(MPix/s) | 37.14 | 7.4 | 112.5 | 207.37 [+84%] | Median filter benefits greatly from FP16 processing, it’s almost 2x faster. |
|
Oil Painting Quantise Filter (MPix/s) | 12.73 | 28 | 42.38 | 141.8 [+235%] | Without major processing, quantisation benefits even more from FP16, it’s over 3x faster. |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 21 | 6.43 | 24.14 | 24.58 [+2%] | This algorithm is 64-bit integer heavy thus shows almost no benefit. |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 0.305 | 0.49 | 0.8125 | 2 [+148%] | One of the most complex and largest filters, FP16 makes it over 2.5x faster. |
| FP16/half brings huge performance improvement in image processing as long as the results are acceptable – again some parts have to use higher precision (FP32) in order to prevent artifacts. Convolution can be implemented through matrix multiplication thus would benefit even more from Tensor core hardware acceleration. | ||||||
Final Thoughts / Conclusions
FP16/half support when unlocked can greatly benefit many algorithms – if the lower precision is acceptable: in general performance improves by about 50% – though in some cases it can reach 200%.
When using the new Tensor cores – performance improves hugely: in GEMM we see 4x performance improvement (vs. FP32). It thus makes great sense to modify algorithms (like convolution) to use matrix multiplication and thus the Tensor cores – which will greatly accelerate image processing and neural networks. With the new nVidia 2000 series – this kind of performance is available in the mainstream right now and is pretty amazing to see.
Expect to see similar hardware accelerator units from both GPGPUs and soon CPUs with AVX512-VNNI as well as FP16 processing support (BFloat16) that will allow multi-core wide-SIMD CPUs to be competitive.