What is “Titan RTX / 2080Ti”?
It is the latest high-end “pro-sumer” card from nVidia with the next-generation “Turing” architecture, the update to the current “Volta” architecture that has had a limited release in Titan/Quadro cards. It powers the new Series 20 top-end (with RTX) and Series 16 mainstream (without RTX) cards that replace the old Series 10 “Pascal” series.
As “Volta” is intended for AI/scientific/financial data-centers – it features high-end HBM2 memory; since “Turing” is meant for gaming, rendering, etc. has “normal” GDDR6 memory. Similarly “Turing” has the new RTX (Ray-Tracing) cores for high-fidelity visualisation and image generation – in addition to the Tensor (TSX) cores that “Volta” has introduced.
While “Volta” has 1/2 FP64 ratio cores (vs. FP32), “Turing” has the normal 1/32 FP64 ratio cores: for high-precision computation – you need “Volta”. However, as “Turing” maintains the 2x FP16 rate (vs. FP32) it can run low-precision AI (neural networks) at full speed. Old “Pascal” had 1/64x FP16 ratio making it pretty much unusable in most cases.
“Turing” does not have high-end on-package HBM2 memory but instead high-speed GDDR6 memory that has decent bandwidth but is not plentiful – with 1GB missing (11GB instead of 12GB).
With the soon-to-be unveiled “Ampere” (Series 30) architecture, we look whether you can have a “cheap” Titan V performance using a Turing 2080TI consumer card.
See these other articles on Titan performance:
- AMD Radeon RX 6900XT (RDNA2, Navi2X) Review & Benchmarks – GPGPU Performance
- AMD Radeon RX 6800 (RDNA2, Navi2L) Review & Benchmarks – GPGPU Performance
- nVidia 3090, 3080 RTX: Ampere GPGPU performance in CUDA and OpenCL
- nVidia Titan V : Volta GPGPU performance in CUDA and OpenCL
- nVidia Titan X : Pascal GPGPU performance in CUDA and OpenCL
- nVidia Titan V/X: FP16 and Tensor CUDA Performance
Hardware Specifications
We are comparing the top-of-the-range Titan V with previous generation Titans and competing architectures with a view to upgrading to a mid-range high performance design.
| GPGPU Specifications | nVidia Titan RTX / 2080TI (Turing) |
nVidia Titan V (Volta) |
nVidia Titan X (Pascal) |
Comments | |
| Arch Chipset | Turing GP102 (7.5) | Volta VP100 (7.0) | Pascal FP102 (6.1) | The V is the only one using the top-end 100 chip not 102 or 104 lower-end versions | |
| Cores (CU) / Threads (SP) | 68 / 4352 | 80 / 5120 | 28 / 3584 | Not as many cores as Volta but still decent. | |
| ROPs / TMUs | 88 / 272 | 96 / 320 |
96 / 224 | Cannot match Volta but more ROPs per CU for gaming. | |
| FP32 / FP64 / Tensor Cores | 4352 / 136 / 544 | 5120 / 2560 / 640 | 3584 / 112 / no | Maintains the Tensor cores important for AI tasks (neural networks, etc.) | |
| Speed (Min-Turbo) | 1.35GHz (136-1.635) | 1.2GHz (135-1.455) | 1.531 (135-1.910) | Clocks have improved over Volta likely due to lower number of SMs. | |
| Power (TDP) | 260W | 300W | 250W (125-300) | TDP is less due to lower CU number. | |
| Global Memory | 11GB GDDR6 14GHz 320-bit | 12GB HBM2 850Mhz 3072-bit | 11GB GDDR5X 10GHz 384-bit | As a pro-sumer card it has 1GB less than Volta and same as Pascal. | |
| Memory Bandwidth (GB/s) |
616 | 652 | 512 | Despite no HBM2, bandwidth almost matches due to high speed of GDDR6. | |
| L1 Cache | 2x (32kB + 64kB) | 2x 24kB / 96kB shared | L1/shared is still the same but ratios have changed. | ||
| L2 Cache | 5.5MB (6MB?) | 4.5MB (3MB?) | 3MB | L2 cache reported has increased by 25%. | |
| FP64/double ratio |
1/32x | 1/2x | 1/32x | Low ratio like all consumer cards, Volta dominates here | |
| FP16/half ratio |
2x | 2x | 1/32x | Same rate as Volta, 2x over FP32 | |

nVidia RTX 2080 TI (Turing)
Processing Performance
We are testing both CUDA native as well as OpenCL performance using the latest SDK / libraries / drivers.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest nVidia drivers 452, CUDA 11.3, OpenCL 1.2 (latest nVidia provides). Turbo / Boost was enabled on all configurations.
| Processing Benchmarks | nVidia Titan RTX / 2080TI (Turing) | nVidia Titan V (Volta) | nVidia Titan X (Pascal) | Comments | |
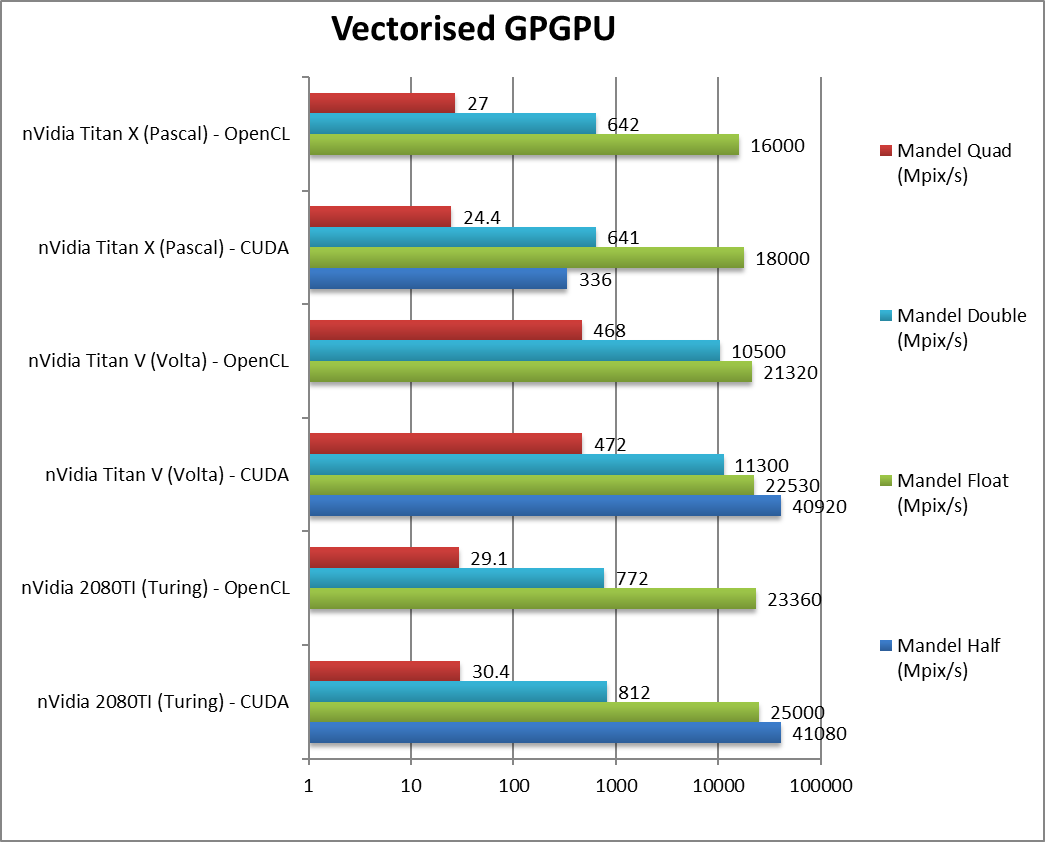 |
|||||
 |
Mandel FP16/Half (Mpix/s) | 41,080 / n/a [=] | 40,920 / n/a | 336 / n/a | Right off the bat, Turing matches Volta and is miles faster than old Pascal. |
|
Mandel FP32/Single (Mpix/s) | 25,000 / 23,360 [+11%] | 22,530 / 21320 | 18,000 / 16,000 | With standard FP32, Turing even manages to be 11% faster despite less CUs. |
|
Mandel FP64/Double (Mpix/s) | 812 / 772 [-93%] | 11,300 / 10,500 | 641 / 642 | For FP64 you don’t want Turing, you want Volta. At any cost. |
|
Mandel FP128/Quad (Mpix/s) | 30.4 / 29.1 [-94%] | 472 / 468 | 24.4 / 27 | With emulated FP128 precision Turing is again demolished. |
| Turing manages to improve over Volta in FP16/FP32 despite having less CUs – most likely due to faster clock and optimisations. However, if you do need FP64 precision then Volta reigns supreme – the 1/32 rate of Turing & Pascal just does not cut it. | |||||
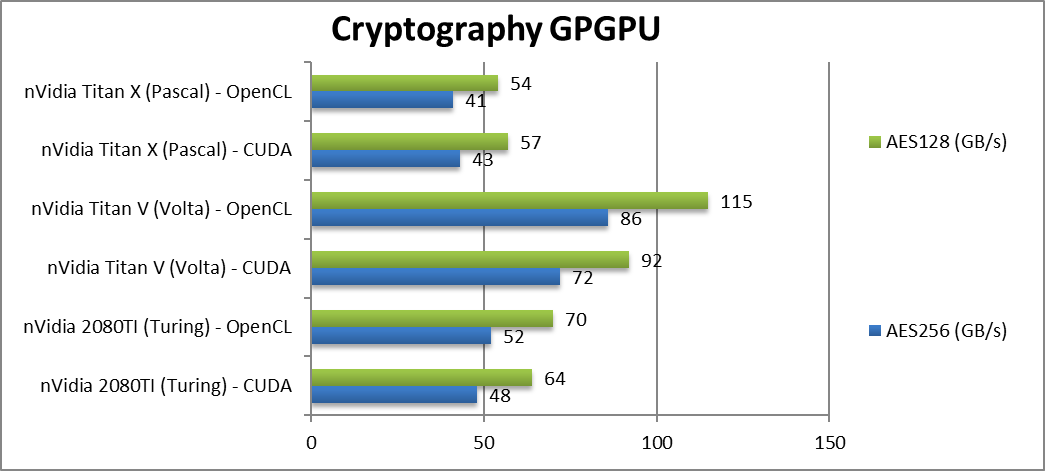 |
|||||
 |
Crypto AES-256 (GB/s) | 48 / 52 [-33%] | 72 / 86 | 42 / 41 | Streaming workloads love Volta’s HBM2 memory, Turing is 33% slower. |
|
Crypto AES-128 (GB/s) | 64 / 70 [-30%] | 92 / 115 | 57 / 54 | Not a lot changes here, Turing is 30% slower. |
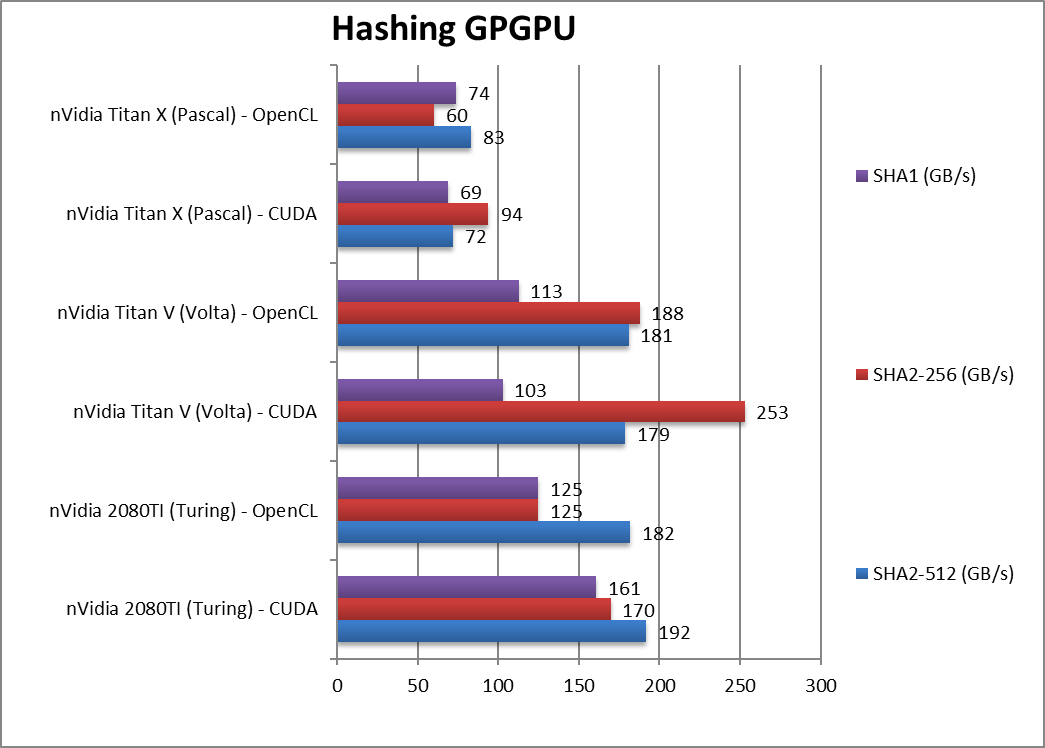 |
|||||
|
Crypto SHA2-512 (GB/s) | 192 / 182 [+7%] | 179 / 181 | 72 / 83 | With 64-bit integer workload, Turing manages a 7% win despite “slower” memory. |
|
Crypto SHA256 (GB/s) | 170 / 125 [-33%] | 253 / 188 | 95 / 60 | As with AES, hashing loves HBM2 so Turing is 33% slower than Volta. |
|
Crypto SHA1 (GB/s) | 161 / 125 [+56] | 103 / 113 | 69 / 74 | While Turing wins, it is likely a compiler optimisation. |
| It seems that Turing GDDR6 memory cannot keep up with Volta’s HBM2 – despite the similar bandwidths: streaming algorithms are around 30% slower on Turing. The only win is 64-bit integer workload that is 7% faster on Turing likely due to integer units optimisations. | |||||
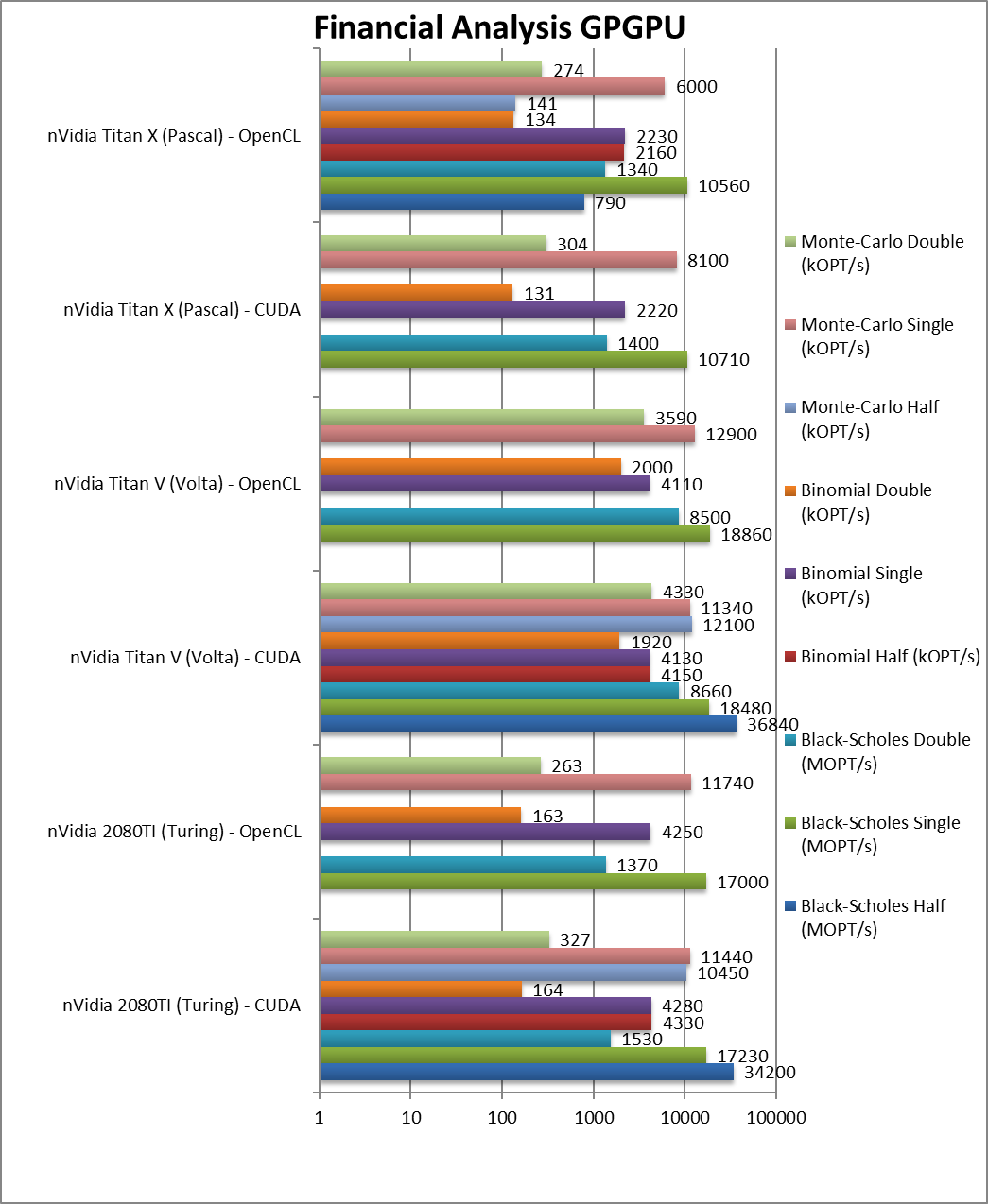 |
|||||
 |
Black-Scholes float/FP32 (MOPT/s) | 17,230 / 17,000 [-7%] | 18,480 / 18,860 | 10,710 / 10,560 | Turing is just 7% slower than Volta. |
|
Black-Scholes double/FP64 (MOPT/s) | 1,530 / 1,370 [-82%] | 8,660 / 8,500 | 1,400 / 1,340 | FP64 is almost 1/8x slower. |
|
Binomial float/FP32 (kOPT/s) | 4,280 / 4,250 [+4%] | 4,130 / 4,110 | 2,220 / 2,230 | Binomial uses thread shared data thus stresses the SMX’s memory system – Turing is 4% faster. |
|
Binomial double/FP64 (kOPT/s) | 164 / 163 [-91%] | 1,920 / 2,000 | 131 / 134 | With FP64 code Turing is 1/10x slower. |
|
Monte-Carlo float/FP32 (kOPT/s) | 11,440 / 11,740 [+1%] | 11,340 / 12,900 | 8,100 / 6,000 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure – Turing is just 1% faster. |
|
Monte-Carlo double/FP64 (kOPT/s) | 327 / 263 [-92%] | 4,330 / 3,590 | 304 / 274 | Switching to FP64 again Turing is 1/10x slower. |
| For financial workloads, as long as you only need FP32 (or FP16), Turing can match and slightly outperform Volta; considering the cost that is no mean feat. However, if you do need FP64 precision – as we saw before, there is no contest – Volta is 10x (ten times) faster. | |||||
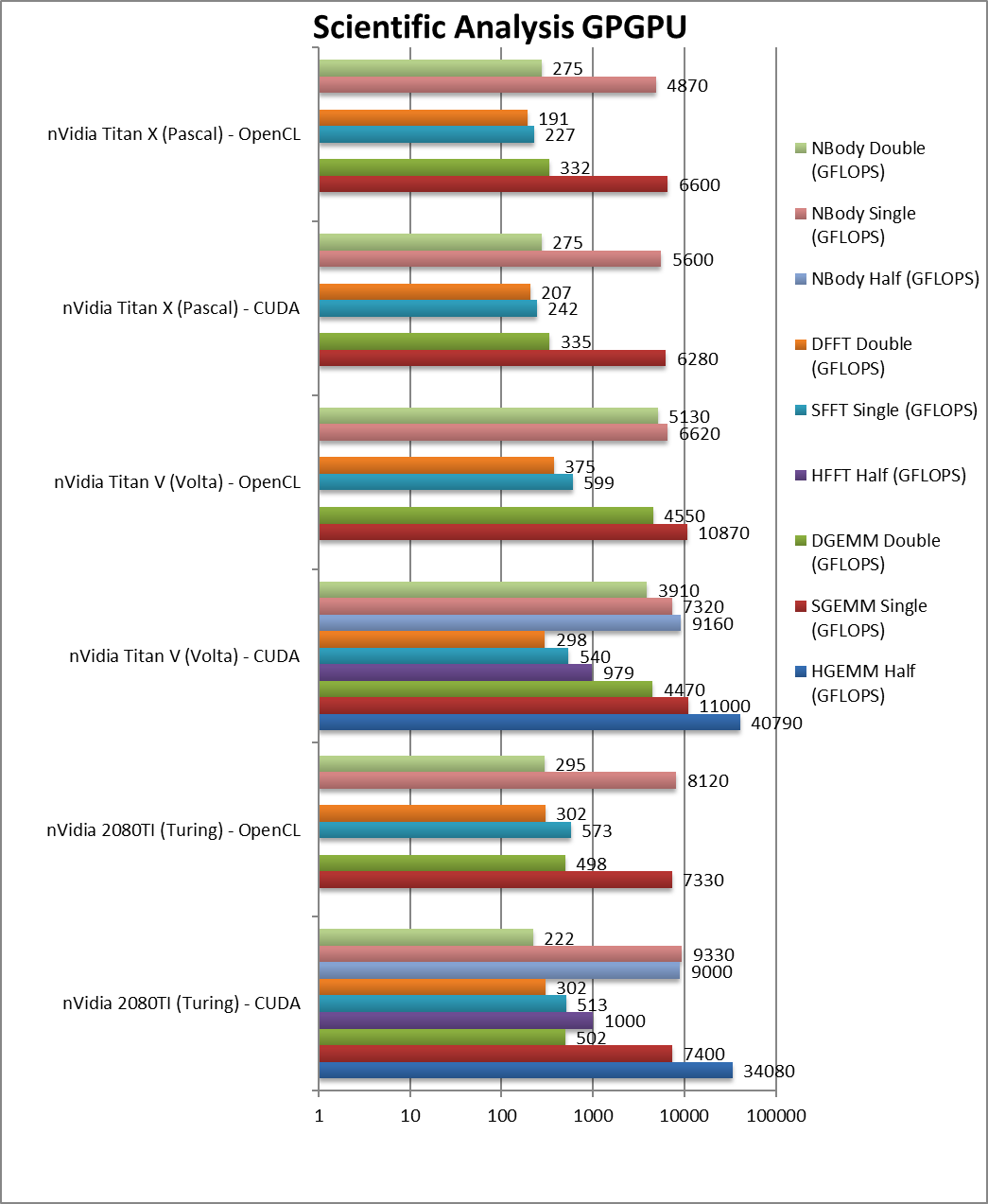 |
|||||
 |
HGEMM (GFLOPS) half/FP16 | 34,080 [-16%] | 40,790 | Using the new Tensor cores, Turing is just 16% slower. | |
|
SGEMM (GFLOPS) float/FP32 | 7,400 / 7,330 [-33%] | 11,000 / 10,870 | 6,280 / 6,600 | Perhaps surprisingly, Turing is 33% slower than Volta here. |
|
DGEMM (GFLOPS) double/FP64 | 502 / 498 [-89%] | 4,470 4,550 | 335 / 332 | With FP64 precision, Turing is 1/10x slower than Volta. |
|
HFFT (GFLOPS) half/FP16 | 1,000 [+2%] | 979 | FFT somehow allows Turing to match Volta in performance. | |
|
SFFT (GFLOPS) float/FP32 | 512 / 573 [-5%] | 540 / 599 | 242 / 227 | With FP32, Turing is just 5% slower. |
|
DFFT (GFLOPS) double/FP64 | 302 / 302 [+1%] | 298 / 375 | 207 / 191 | Completely memory bound, Turing matches Volta here. |
|
HNBODY (GFLOPS) half/FP16 | 9,000 [-2%] | 9,160 | N-Body simulation with FP16 is just 2% slower. | |
|
SNBODY (GFLOPS) float/FP32 | 9,330 / 8,120 [+27%] | 7,320 / 6,620 | 5,600 / 4,870 | N-Body simulation allows Turing to dominate. |
|
DNBODY (GFLOPS) double/FP64 | 222 / 295 [-94%] | 3,910 / 5,130 | 275 / 275 | With FP64 precision, Turing is again 1/10x slower than Volta. |
| The scientific scores are a bit more mixed – but again Turing can match or slightly exceed Volta with FP32/FP16 precision – as long as we’re not memory limited; there Volta is still around 30% faster. With FP64 it’s the same story, Turing is about 1/10x slower. | |||||
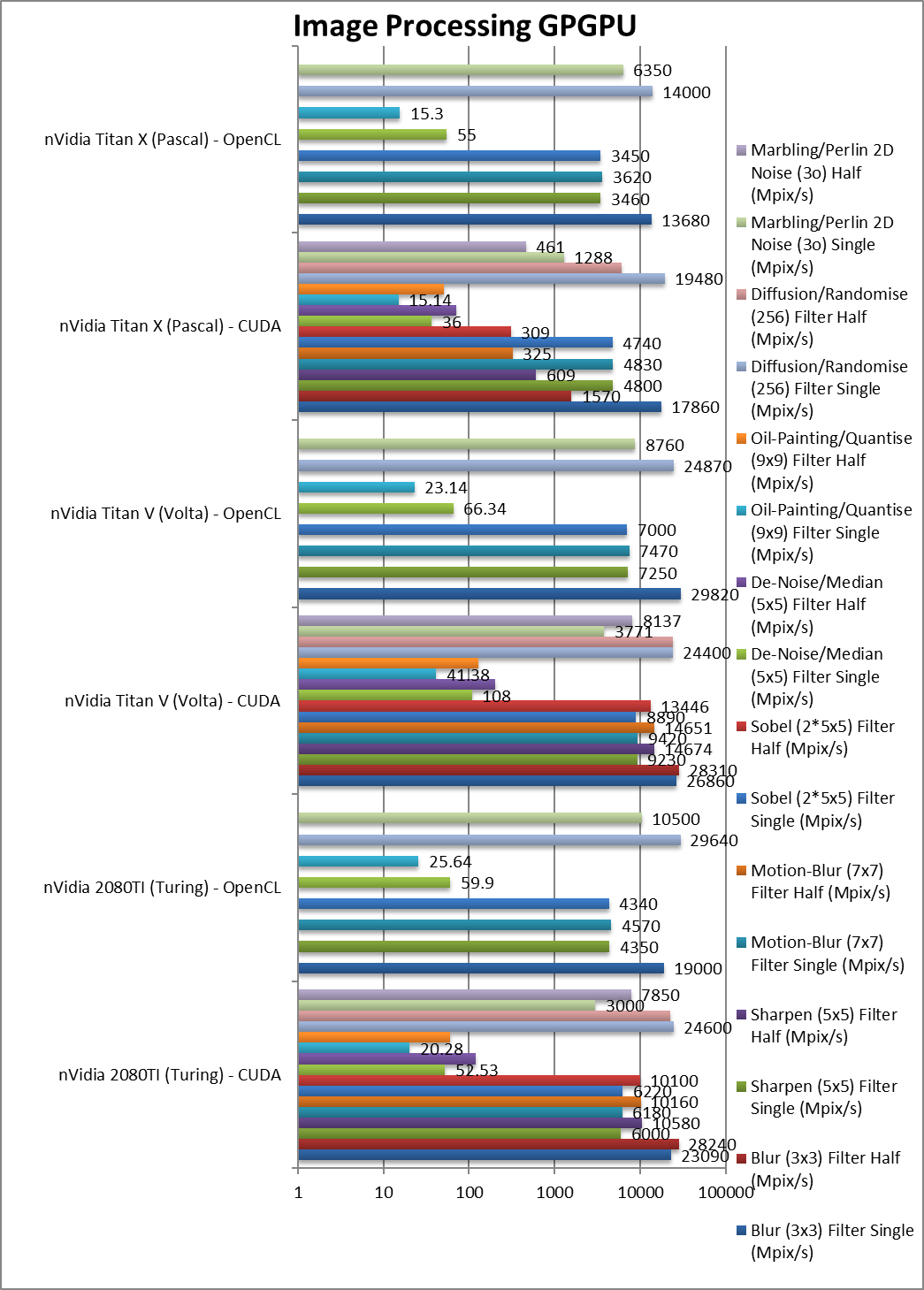 |
|||||
 |
Blur (3×3) Filter single/FP32 (MPix/s) | 23,090 / 19,000 [-14%] | 26,860 / 29,820 | 17,860 / 13,680 | In this 3×3 convolution algorithm, Turing is 14% slower. Convolution is also used in neural nets (CNN). |
|
Blur (3×3) Filter half/FP16 (MPix/s) | 28,240 [=] | 28,310 | 1,570 | With FP16 precision, Turing matches Volta in performance. |
|
Sharpen (5×5) Filter single/FP32 (MPix/s) | 6,000 / 4,350 [-35%] | 9,230 / 7,250 | 4,800 / 3,460 | Same algorithm but more shared data makes Turing 35% slower. |
|
Sharpen (5×5) Filter half/FP16 (MPix/s) | 10,580 [-38%] | 14,676 | 609 | With FP16 Volta is almost 40% faster over Turing. |
|
Motion-Blur (7×7) Filter single/FP32 (MPix/s) | 6,180 / 4,570 [-33%] | 9,420 / 7,470 | 4,830 / 3,620 | Again same algorithm but even more data shared Turing is 33% slower. |
|
Motion-Blur (7×7) Filter half/FP16 (MPix/s) | 10,160 [-31%] | 14,651 | 325 | With FP16 nothing much changes in this algorithm. |
|
Edge Detection (2*5×5) Sobel Filter single/FP32 (MPix/s) | 6,220 / 4,340 [-30%] | 8,890 / 7,000 | 4,740 / 3,450 | Still convolution but with 2 filters – Turing is 30% slower. |
|
Edge Detection (2*5×5) Sobel Filter half/FP16 (MPix/s) | 10,100 [-25%] | 13,446 | 309 | Just as we seen above, Turing is about 25% slower than Volta. |
|
Noise Removal (5×5) Median Filter single/FP32 (MPix/s) | 52.53 / 59.9 [-50%] | 108 / 66.34 | 36 / 55 | Different algorithm we see the biggest delta with Turing 50% slower. |
|
Noise Removal (5×5) Median Filter half/FP16 (MPix/s) | 121 [-40%] | 204 | 71 | With FP16 Turing reduces the loss to just 40%. |
|
Oil Painting Quantise Filter single/FP32 (MPix/s) | 20.28 / 25.64 [-50%] | 41.38 / 23.14 | 15.14 / 15.3 | Without major processing, this filter flies on Volta, again Turing is 50% slower. |
|
Oil Painting Quantise Filter half/FP16 (MPix/s) | 59.55 [-54%] | 129 | 50.75 | FP16 precision does not change things. |
|
Diffusion Randomise (XorShift) Filter single/FP32 (MPix/s) | 24,600 / 29,640 [+1%] | 24,400 / 24,870 | 19,480 / 14,000 | This algorithm is 64-bit integer heavy and here Turing is 1% faster. |
|
Diffusion Randomise (XorShift) Filter half/FP16 (MPix/s) | 22,400 [-8%] | 24,292 | 6,090 | FP16 does not help here as we’re at maximum performance. |
|
Marbling Perlin Noise 2D Filter single/FP32 (MPix/s) | 3,000 / 10,500 [-20%] | 3,771 / 8,760 | 1,288 / 6,530 | One of the most complex and largest filters, Turing is 20% slower than Volta. |
|
Marbling Perlin Noise 2D Filter half/FP16 (MPix/s) | 7,850 [-4%] | 8,137 | 461 | Switching to FP16, the V is almost 4x (times) faster than the X and over 2x faster than FP32 code. |
| For image processing, Turing is generally 20-35% slower than Volta somewhat in line with memory performance. If FP16 is sufficient, then we see Turing matching Volta in performance – something that old Pascal could never do. | |||||
Memory Performance
We are testing both CUDA native as well as OpenCL performance using the latest SDK / libraries / drivers.
Results Interpretation: For bandwidth tests (MB/s, etc.) high values mean better performance, for latency tests (ns, etc.) low values mean better performance.
Environment: Windows 10 x64, latest nVidia drivers 352, CUDA 11.3, OpenCL 1.2. Turbo / Boost was enabled on all configurations.
| Memory Benchmarks | nVidia Titan RTX / 2080TI (Turing) | nVidia Titan V (Volta) | nVidia Titan X (Pascal) | Comments | |
 |
|||||
 |
Internal Memory Bandwidth (GB/s) | 494 / 485 [-7%] | 534 / 530 | 356 / 354 | GDDR6 provides good bandwidth, only 7% less than HBM2. |
|
Upload Bandwidth (GB/s) | 11.3 / 10.4 [-1%] | 11.4 / 11.4 | 11.4 / 9 | Still using PCIe3 x16 there is no change in upload bandwidth. Roll on PCIe4! |
|
Download Bandwidth (GB/s) | 11.9 / 12.3 [-1%] | 12.1 / 12.3 | 12.2 / 8.9 | Again no significant difference but we were not expecting any. |
| Turing’s GDDR6 memory provides almost the same bandwidth as Volta’s expensive HBM2. All cards use PCIe3 x16 connections thus similar upload/download bandwidth. Hopefully the move to PCIe4/5 will improve transfers. | |||||
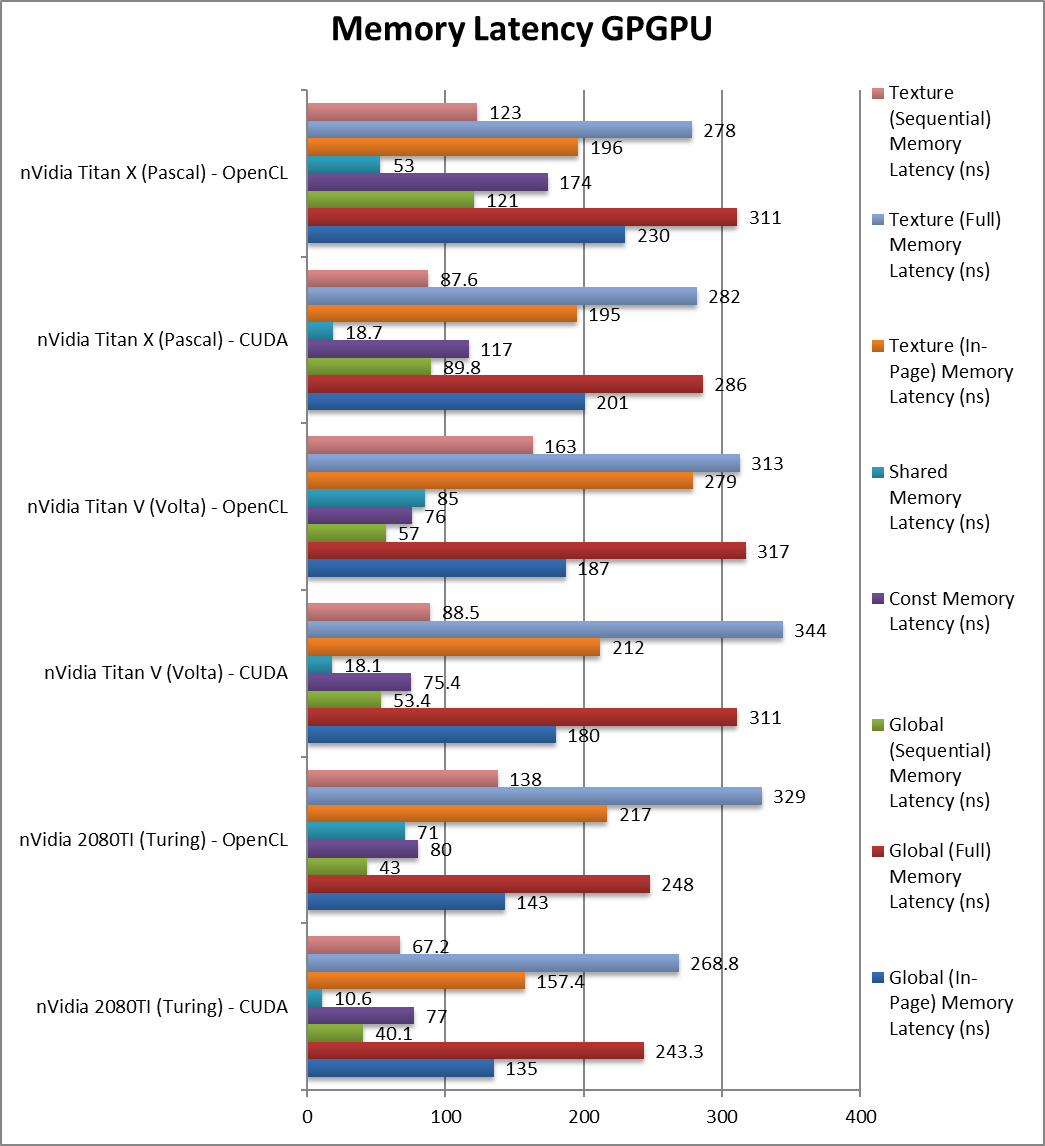 |
|||||
 |
Global (In-Page Random Access) Latency (ns) | 135 / 143 [-25%] | 180 / 187 | 201 / 230 | From the start we see global latency accesses reduced by 25%, not a lot but will help. |
|
Global (Full Range Random Access) Latency (ns) | 243 / 248 [-22%] | 311 / 317 | 286 / 311 | Full range random accesses are also 22% faster. |
|
Global (Sequential Access) Latency (ns) | 40 / 43 [-25%] | 53 / 57 | 89 / 121 | Sequential accesses have also dropped 25%. |
|
Constant Memory (In-Page Random Access) Latency (ns) | 77 / 80 [+2%] | 75 / 76 | 117 / 174 | Constant memory latencies seem about the same. |
|
Shared Memory (In-Page Random Access) Latency (ns) | 10.6 / 71 [-41%] | 18 / 85 | 18.7 / 53 | Shared memory latencies seem to be improved. |
|
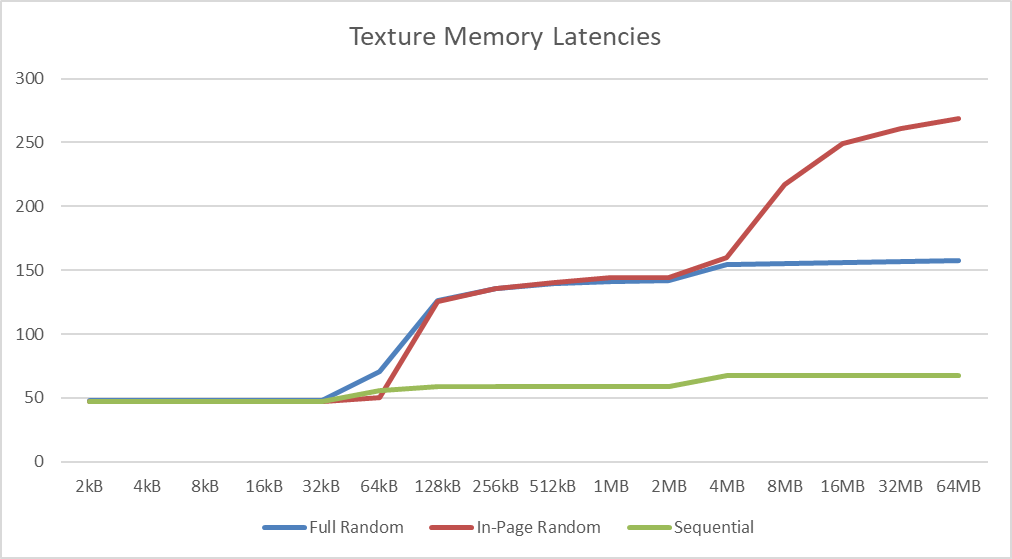
Texture (In-Page Random Access) Latency (ns) | 157 / 217 [-26%] | 212 / 279 | 195 / 196 | Texture access latencies have also reduced by 26%. |
|
Texture (Full Range Random Access) Latency (ns) | 268 / 329 [-22%] | 344 / 313 | 282 / 278 | As we’ve seen with global memory, we see reduced latencies by 22%. |
|
Texture (Sequential Access) Latency (ns) | 67 / 138 [-24%] | 88 / 163 | 87 / 123 | With sequential access we also see a 24% reduction. |
| The high data rate of Turing’s GDDR6 brings reduced latencies across the board over HBM2 although as we’ve seen in the compute benchmarks, this does not always translate in better performance. Still some algorithms, especially less optimised ones may still benefit at much lower cost. | |||||
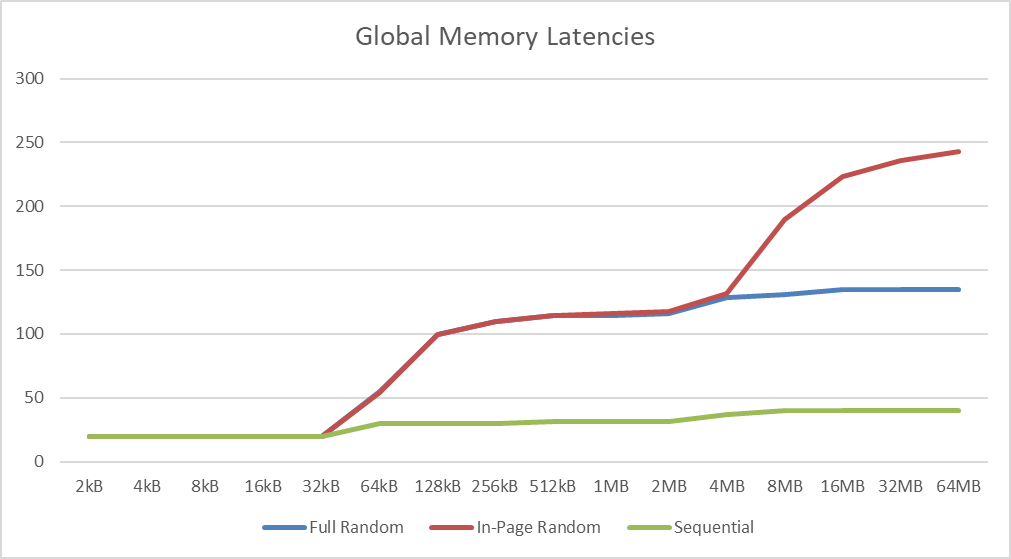 |
|||||
| We see L1 cache effects between 32-64kB tallying with an L1D of 32-48kB (depending on setting) with the other inflexion between 4-8MB matching the 6MB L2 cache. | |||||
 |
|||||
| As with global memory we see the same L1D (32kB) and L2 (6MB) cache affects with similar latencies. Both are significant upgrades over Titan X’ caches. | |||||
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
If you wanted to upgrade your old Pascal Titan X but could not afford the Volta’s Titan V – then you can now get a cheap RTX 2080Ti or Titan RTX and get similar if not slightly faster FP16/FP32 performance that blows the not-so-old Titan X out of the water! If you can make do with FP16 and use Tensor cores, we’re looking at 6-8x performance over FP32 using a single card.
Naturally, the FP64 performance is again “gimped” at 1/32x so if that’s what you require, Turing cannot help you there – you will have to get a Volta. But then again the Titan X was similarly “gimped” thus if that’s what you had you still get a decent performance upgrade.
The GDDR6 memory may have similar bandwidth on paper, but in streaming algorithms is about 33% slower than HBM2 so there Turing cannot match Volta, but considering the cost it is a good trade. You will also lose 1GB just like with Titan X but again, not a surprise. Global/Constant/Texture memory access latencies are lower due to the high data rate which should help algorithms that are memory access limited (if you cannot help hide them).
As we’re testing GPGPU performance here, we have not touched on the ray-tracing (RTX) units, but should you happen to play a game or two when you are “resting”, then the Titan RTX / 2080TI might just impress you even more. Here, not even Volta can match it!
All in all – Titan RTX is a compelling (relatively) cheap upgrade over the old Titan X if you don’t require FP64 precision.

nVidia Titan RTX (Turing)