What is “Sapphire Rapids”?
It is the “next-generation” Xeon (big Core-X) architecture, replacing the “Ice Lake X” / “Cascade Lake X” arch on HEDT platform. It consists only of big/P(erformant) gen 12 “Alder Lake X” cores (without any LITTLE/E(fficient) “Atom” cores) thus it is not a hybrid design. While mainly targeting servers – it also meant to “revive” the workstation / HEDT platform which has not seen any upgrades for quite some time.
- 220 – 350W rated, up to 450W+ turbo
- 12C – 56C / 24T – 112T big/P(erformant) Cores-X (aka ADL-X)
- 30MB – 105MB L3 unified cache (LLC)
As it contains only big/P cores, it does not require OS scheduler changes for hybrid support like current ADL “Alder Lake” – thus can happily use the older “Windows 10” (Pro / Workstation) or “Windows Server 2016/2019/2022” (also based on Windows 10 kernel). A hybrid design would have required either “Windows 11” or the “Windows Server vNext” (only in preview likely 2025 launch!) – that would have been massive embarrassment for Microsoft & Intel.
This also means it can include AVX512 & friends support, including brand-new features like AMX, FP16 (16-bit half floating-point) support that are pretty important in the HEDT space. Losing AVX512 support here would be pretty catastrophic for Intel and no amount of LITTLE/(E)fficient Atom cores could make up for that.
General SoC Details
- 10nm+++ (Intel 7+) improved process
- Unified 105MB L3 cache
- PCIe 5.0 (up to 64GB/s with x16 lanes)
- NVMe SSDs (PCIe 5.0) will not need lane bifurcation with GP-GPU as on desktop AlderLake
- DDR5 memory controller support (8x 32-bit channels) – up to 4800Mt/s (official, higher with XMP)
- XMP 3.0 (eXtreme Memory Profile(s)) specification for overclocking with 3 profiles and 2 user-writable profiles (!)
- Thunderbolt 4 (and thus USB 4)
big/P(erformance) “Core” core
- Up to 56C/112T “Golden Cove” X cores [like “Alder Lake” desktop]
- Enabled AVX512 & friends + new extensions
- AMX “tensors” (Tile Matrix FMA) support (e.g. matrix multiply, convolution, etc.)
- FP16 (16-bit half floating-point format) for 2x performance over FP32, also reduces memory size/bandwidth
- 2x 512-bit FMA units, 1024-bit total [likely not all SKUs though]
- SMT support included, 2x threads/core
- L1I at 32kB [same]
- L1D at 48kB per core [+50% CLK, same as ICL]
- L2 increased to 2MB per core [2x CLK, +50% ICL]
- Combined L2 cache can end up larger than LLC/L3! (e.g. 56x 2MB L2 > 105MB L3)
While some are not keen on AVX512 due to relatively large power required to use (and thus lower clocks) as well as the large number of extensions (F, BW, CD, DQ, ER, IFMA, PF, VL, BF16, FP16, VAES, VNNI, etc.) – the performance gain cannot be underestimated (2x if not higher). Most modern processors no longer need to “clock-down” (AVX512 negative offset) and can run at full speed – power/thermal limits notwithstanding.
Like previous versions, we have 2x 512-bit FMA units, effectively 1024-bit FMA compute power (e.g. matrix multiply, convolution, etc.) though the new AMX “tensor” instructions target the same usage and can provide even more uplift. However, “legacy AVX512” apps (!) and other algorithms will still benefit from such power. [Note we are still working on AMX support]
In addition to BF16, the FP16 support – can double performance (or at least reduce memory size/bandwidth requirements) in algorithms where the loss of precision is acceptable (e.g. image processing, neural networks, etc.) and also makes CPU <> GPGPU data exchange easier – with data no longer needed to be converted to/from FP32 for CPU use.
CPU (Core) Performance Benchmarking
In this article we test CPU core performance; please see our other articles on:
- CPU
- Intel 13th Gen Core RaptorLake (i9-13900) Preview & Benchmarks – Hybrid Performance
- Intel 12th Gen Core AlderLake Mobile (i7-12700H) Review & Benchmarks – big/LITTLE Performance
- big/Performance Core Performance Analysis – Intel 12th Gen Core AlderLake (i9-12900K)
- Intel 11th Gen Core RocketLake (i7-11700K) Review & Benchmarks – CPU AVX512 Performance
- Cache & Memory
Hardware Specifications
We are comparing the Intel with competing HEDT architectures as well as competitors (AMD) with a view to upgrading to a top-of-the-range HEDT workstation.
| Specifications | Intel Xeon W9-3495X (ADL-X ES) | AMD Threadripper 3990X (Zen2) |
Intel Xeon W-3275 (CLK) | AMD Ryzen 9 5950X (Zen3) | Comments | |
| Arch(itecture) | Golden Cove X / Sapphire Rapids | Zen 2 / Castle Peak | Cascade Lake | Zen 3 | The very latest arch | |
| Cores (CU) / Threads (SP) | 56C / 112T | 64C / 128T | 28C / 56T | 16C / 32T | ~3x more cores | |
| Rated Speed (GHz) | 1.9 | 2.9 | 2.5 | 3.4 | Lower base clock | |
| All/Single Turbo Speed (GHz) |
3.7 | 4.3 | 4.4 | 4.9 | Lower turbo clock | |
| Rated/Turbo Power (W) |
350-500? | 280-350 | 205-250 | 105-135 | TDP is almost 2x higher | |
| L1D / L1I Caches | 56x 48kB / 32kB |
64x 64kB / 64kB | 28x 32kB / 32kB | 16x 64kB / 64kB | 50% larger L1D | |
| L2 Caches | 56x 2MB [112MB] |
64x 512kB [32MB] | 28x 1MB [28MB] | 16x 512kB [8MB] | 2x larger L2 |
|
| L3 Cache(s) | 105MB | 16x 16MB [256MB] | 38.5MB | 2x 32MB [64MB] | L3 smaller than combined L2? |
|
| Microcode (Firmware) | 0806F3-8D000500 | 830F10-39 | 050657-500012C | A20F10-1016 | Revisions just keep on coming. | |
| Special Instruction Sets | AVX512, AMX, FP16 | AVX2, FMA3 | AVX512 | AVX2, FMA3 | Brand-new AMX, FP16 | |
| SIMD Width / Units |
2x 512-bit [1024-bit] |
2x 128-bit [256-bit] | 2x 512-bit [1024-bit] |
2x 256-bit [512-bit] | 1024-bit power | |
| Price / RRP (USD) |
? | $3,450 | $4,500 | $500 | Priced higher? | |
Disclaimer
This is an independent review (critical appraisal) that has not been endorsed nor sponsored by any entity (e.g. Intel, etc.). All trademarks acknowledged and used for identification only under fair use.
The review contains only public information and not provided under NDA nor embargoed. At publication time, the products have not been directly tested by SiSoftware but submitted to the public Benchmark Ranker; thus the accuracy of the benchmark scores cannot be verified, however, they appear consistent and pass current validation checks.
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!
SiSoftware Official Ranker Scores

Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets. “Sapphire Rapids” supports AVX512 as well as brand-new extensions.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows Server 2019 x64, latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
| Native Benchmarks | Intel Xeon W9-3495X (ADL-X ES) | AMD Threadripper 3990X | Intel Core i9-10980XE (CLK) | AMD Ryzen 9 5950X (Zen3) | Comments | |
 |
||||||
 |
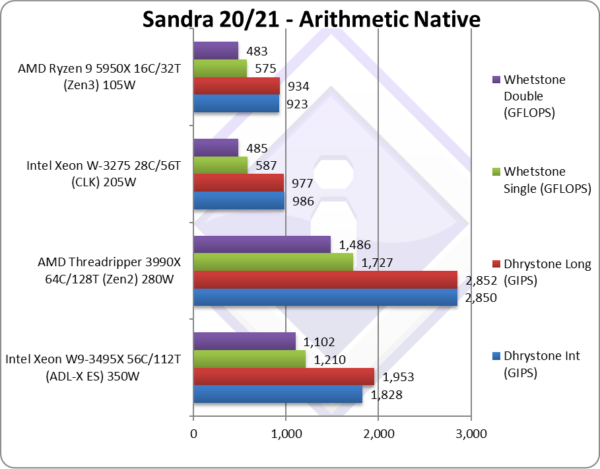
Native Dhrystone Integer (GIPS) | 1,828 [-36%] | 2,850 | 986 | 923 | SR cannot beat TR with just 56 cores. |
|
Native Dhrystone Long (GIPS) | 1,953 [-32%] | 2,852 | 977 | 934 | A 64-bit integer workload does not change things |
|
Native FP32 (Float) Whetstone (GFLOPS) | 1,210 [-30%] | 1,727 | 587 | 575 | With floating-point, SR is just 30% slower. |
|
Native FP64 (Double) Whetstone (GFLOPS) | 1,102 [-26%] | 1,486 | 485 | 483 | With FP64 nothing much changes |
| With non-SIMD legacy code, we see good performance uplift in both integer (old’ Dhrystone) and floating-point (old’ Whetstone) vs. old CLK (albeit with just 18 cores!) – but SR cannot beat AMD’s TR with its 64 cores. For such code, LITTLE Atom cores would perform well here (per Watt) which SR does not have.
However, HEDT users are not likely to run such kind of software – thus perhaps this is not make-or-break for SR. What it shows is that Intel does need more cores and at higher clocks, something that AMD manages to do. |
||||||
 |
||||||
 |
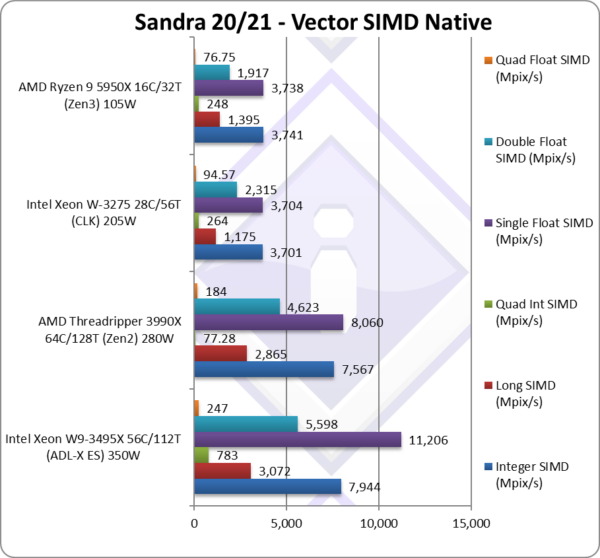
Native Integer (Int32) Multi-Media (Mpix/s) | 7,944* [+5%] |
7,567 | 3,701* | 3,741 | SP finally beats TR by 5%! |
|
Native Long (Int64) Multi-Media (Mpix/s) | 3,072* [+7%] |
2,865 | 1,175* | 1,395 | With a 64-bit, SP is 7% faster than TR |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 783** [+10x] |
77.3 | 264** | 248 | Using 64-bit int to emulate Int128 SP is 10x faster! |
|
Native Float/FP32 Multi-Media (Mpix/s) | 11,206* [+39%] |
8,060 | 3,704* | 3,738 | Float 2x FMA units make SP 40% faster! |
|
Native Double/FP64 Multi-Media (Mpix/s) | 5,598* [+21%] |
4,623 | 2,315* | 1,917 | Switching to FP64 SP is 21% faster |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 247* [+34%] |
184 | 94.57* | 76.75 | Using FP64 to emulate 128-bit we’re 34% faster! |
| With heavily vectorised SIMD workloads – that HEDT users are likely to use – SP finally beats AMD’s TR: a modest 5-7% AVX512 integer but due to the dual (2x) AVX512 FMA units 20-40% in AVX512 floating-point! The 128-bit integer test is 10x faster due to the AVX512-IFMA52 (aka integer FMA 52-bit) instructions.
If you were doubting the power of AVX512 for modern SIMD workloads – just look at the scores. (No Cinebench required!) You’d need many more cores to match that kind of performance – without it SR would again be 30-40% slower than AMD’s TR as we’ve seen in the legacy benchmarks. SKUs with just one (1x) FMA unit enabled would see their floating-point scores just 5-7% faster than TR in line with integer scores… Let’s remember that current AMD TR (3000 series) is based on Zen2 not Zen3 (5000 series) which almost doubles SIMD performance and this may well beat SR back into its place. An AVX512-supporting TR (7000 series) may well have killer performance. Note:* using AVX512. Note:** using AVX512-IFMA52 to emulate 128-bit integer operations (int128). |
||||||
Final Thoughts / Conclusions
Summary: More cores, extensions, tech, will it be enough? 8/10
Intel is finally reviving the HEDT platform – bringing current gen 12 “Alder Lake X” cores big/P(erformant) that have AVX512 enabled (including new features like AMX “tensors”, FP16, etc.) in a non-hybrid design that can run on Windows 10 (Pro / Workstation) / Windows Server 2016/2019/2022! No need for Windows 11!
It also brings all the new features that desktop/mobile users already have: DDR5 for much higher bandwidth (8x 32-bit channels up to 4,800Mt/s official – much higher with XMP 3.0); PCIe 5.0 for future GP-GPUs, high performance Optane/NVMe SSDs, network cards, etc; Thunderbolt 4/USB 4.0 for high-speed external devices, etc.
Intel really had no answer to AMD’s ThreadRipper, with HEDT CLK (gen 10) stopping at just 28C/56T while TR (Zen2, Series 3000) carried on all the way up to 64C / 128T with bigger L2 and huge L3 caches (128MB). While the old i9 Core-X was much cheaper, the Xeon W much higher pricing also means AMD’s TR is cheaper and brings more cores.
- In legacy ALU/FPU tests, SP is 25-35% slower than TR – likely due to less cores running slower
- In heavy vectorised/SIMD AVX512 integer tests, SR just 5-7% faster than TR.
- In heavy vectorised/SIMD AVX512 floating-point tests that can use the dual (2x) AVX512 units, SR is 20-40% faster than TR despite less cores.
- AMX and FP16 are likely to provide further uplift once software take advantage of them.
- We are waiting for additional benchmark results to have a better understanding.
As before, Intel leans heavily on AVX512 to win against TR (Zen2 based series 3000) – and this works for now, though a Zen3 based TR (series 5000) may prove much harder to beat. An AVX512-enabled Zen4 based TR (series 7000) may well be SR’s killer…
The rated TDP/power may also be a concern with 350W base and perhaps as high as 500W turbo that requires serious cooling. TR at 280W and 350W turbo is quite a bit less – and if future TR stays the same – SR’s power efficiency won’t look great. With electricity costs spiking and heatwaves this is not a good time for high power usage.
If you need the extra bandwidth DDR5 brings or the new technologies (PCIe 5, USB 4.0, etc.) SR is a great update if you want to stay with Intel (e.g. for AVX512) and cannot wait for AMD’s future TR. But things are due to change in the coming months and remains to be seen if Intel has done enough…
Summary: More cores, extensions, tech, will it be enough? 8/10
Further Articles
Please see our other articles on:
- CPU
- Intel 13th Gen Core RaptorLake (i9-13900) Preview & Benchmarks – Hybrid Performance
- Intel 12th Gen Core AlderLake Mobile (i7-12700H) Review & Benchmarks – big/LITTLE Performance
- big/Performance Core Performance Analysis – Intel 12th Gen Core AlderLake (i9-12900K)
- Intel 11th Gen Core RocketLake (i7-11700K) Review & Benchmarks – CPU AVX512 Performance
- Cache & Memory
Disclaimer
This is an independent review (critical appraisal) that has not been endorsed nor sponsored by any entity (e.g. Intel, etc.). All trademarks acknowledged and used for identification only under fair use.
The review contains only public information and not provided under NDA nor embargoed. At publication time, the products have not been directly tested by SiSoftware but submitted to the public Benchmark Ranker; thus the accuracy of the benchmark scores cannot be verified, however, they appear consistent and pass current validation checks.
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!