What are “AlderLake”, “RaptorLake”?
It is the current (12th gen) Core architecture – soon to be replaced by “RaptorLake” (RPL 13th gen) – that replaced the short-lived “RocketLake” (RKL “real” 10th gen aka ICL) that finally replaced the many, many “Skylake” (SKL) derivative architectures (6th-10th “fake” gen). It is the 1st mainstream “hybrid” arch – i.e. combining big/P(erformant) “Core” cores with LITTLE/E(fficient) “Atom” cores in a single package. While in the ARM world such SoC designs are quite common, this is quite new for x86 – thus operating systems (Windows) and applications had to be updated.
RPL is rumoured to just double LITTLE/E Atom core counts (unchanged “Gracemont“) while including slightly updated big/P Core (“Raptor Cove” vs. “Golden Cove“) that are rumoured to clock faster (at least in Turbo). Here we wonder if this is a risky step for Intel considering what the competition (AMD) has in the pipeline.
We also wonder what the next arch (14th gen, “MeteorLake” MTL) might need to bring to match or even beat the competition…
Why re-test it now?
We have added additional “parallelism” (aka native scheduling bypassing Windows / Intel’s Thread Director) testing methods that allows specific big/P or LITTLE/E cores only testing (with multi-threading or not) or big-2-LITTLE cores testing – without the need of rebooting and disabling cores / SMT.
Scheduling Changes
- “All Threads (MT/MC)” (thus all cores + all threads – e.g. 6C+4c / 16T (2×6 + 4)
- “All Cores (MC aka big+LITTLE) Only” (both core types, no threads) – thus 6C+4c / 10T (6+4)
- “All Threads big/P Cores Only” (only “Core” cores + their threads) – thus 6C / 12T (2×6)
- “big/P Cores Only” (only “Core” cores) – thus 6C / 6T
- “LITTLE/E Cores Only” (only “Atom” cores) – thus 6c / 6t
- “Single Thread big/P Core Only” (thus single “Core” core) – thus 1T
- “Single Thread LITTLE/E Core Only” (thus single “Atom” core) – thus 1t
We have also added hybrid “compute contribution” that details the benchmark score apportioned to big/P & LITTLE/E clusters/cores and thus determine just now much contribution each core type makes to the overall score as well as the big-2-LITTLE compute power ratio. We can thus see how shared resources (current, power, thermal) are distributed for best overall performance.
Note that this is when all cores/threads are used together rather than tested separately – i.e. it is a completely different view to “parallelism” where different clusters / cores are tested individually and not together – when resources (current, power, thermal) are all available to the cluster/cores under test and (hopefully) not shared with unused/parked cluster/cores.
Benchmarking Changes
- Dynamic/Asymmetric workload allocator – based on each thread’s compute power
- Note some tests/algorithms are not well-suited for this (here P threads will finish and wait for E threads – thus effectively having only E threads). Different ways to test algorithm(s) will be needed.
- Dynamic/Asymmetric buffer sizes – based on each thread’s L1D caches
- Memory/Cache buffer testing using different block/buffer sizes for P/E threads
- Algorithms (e.g. GEMM) using different block sizes for P/E threads
- Best performance core/thread default selection – based on test type
- Some tests/algorithms run best just using cores only (SMT threads would just add overhead)
- Some tests/algorithms (streaming) run best just using big/P cores only (E cores just too slow and waste memory bandwidth)
- Some tests/algorithms sharing data run best on same type of cores only (either big/P or LITTLE/E) (sharing between different types of cores incurs higher latencies and lower bandwidth)
- Reporting the Performance Contribution & Ratio of each thread
- Thus the big/P and LITTLE/E cores contribution for each algorithm can be presented. In effect, this allows better optimisation of algorithms tested, e.g. detecting when either big/P or LITTLE/E cores are not efficiently used (e.g. overloaded)
As per above you can be forgiven that some developers may just restrict their software to use big/Performance threads only and just ignore the LITTLE/Efficient threads at all – at least when using compute heavy algorithms.
For this reason we recommend using the very latest version of Sandra and keep up with updated versions that likely fix bugs, improve performance and stability.
Cluster Performance Contribution (per Cluster type)
- Multi-Media Integer Native : 80% big/Cluster – 20% LITTLE/cluster
- Multi-Media Long-int Native : 83% big/Cluster – 17% LITTLE/cluster
- Multi-Media Quad-int Native : 85% big/Cluster – 15% LITTLE/cluster
- Multi-Media Single-float Native : 85% big/Cluster – 15% LITTLE/cluster
- Multi-Media Double-float Native : 85% big/Cluster – 15% LITTLE/cluster
- Multi-Media Quad-float Native : 86% big/Cluster – 14% LITTLE/cluster
Note: Here we sum the compute performance contribution for all cores in the type of cluster. If SMT is enabled, all threads will be summed.
Note2: This feature also works on Arm64 big.LITTLE / DynamicQ SoCs, it is not tied to x86 Intel hybrid systems.
Cluster Performance Ratio (per core type)
- Multi-Media Integer Native : 3x big/Core – 1x LITTLE/core
- Multi-Media Long-int Native : 3.1x big/Core – 1x LITTLE/core
- Multi-Media Quad-int Native : 3.2x big/Core – 1x LITTLE/core
- Multi-Media Single-float Native : 3.3x big/Core – 1x LITTLE/core
- Multi-Media Double-float Native : 3.3x big/Core – 1x LITTLE/core
- Multi-Media Quad-float Native : 3.4x big/Core – 1x LITTLE/core
Note: Here we divide the cluster performance contribution by the number of cores in each cluster – and then work out the big/LITTLE ratio. If SMT is enabled or not, we still only count the number of cores per cluster, not threads.
CPU (Core) Performance Benchmarking
In this article we test CPU core performance; please see our other articles on:
- CPU
- What Intel needs is SVE-like variable width AVX (AVX-V?) to solve hybrid
- Intel 12th Gen Core AlderLake Mobile (i7-12700H) Review & Benchmarks – big/LITTLE Performance
- big/Performance Core Performance Analysis – Intel 12th Gen Core AlderLake (i9-12900K)
- Intel 11th Gen Core RocketLake (i7-11700K) Review & Benchmarks – CPU AVX512 Performance
- Cache & Memory
- GP-GPU
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets. “AlderLake” (ADL) does not support AVX512 – but it does support 256-bit versions of some original AVX512 extensions.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 11 x64, latest Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
| Native Benchmarks | Intel Core i5-12600K 6C+4c/16T (All Cores+Threads) | Intel Core i5-12600K 6C/12T (Big Cores+Threads) | Intel Core i5-12600K 6C/6T (Big Cores Only) | Intel Core i5-12600K 4c/4t (Little Atom cores Only) | Comments | |
 |
||||||
 |
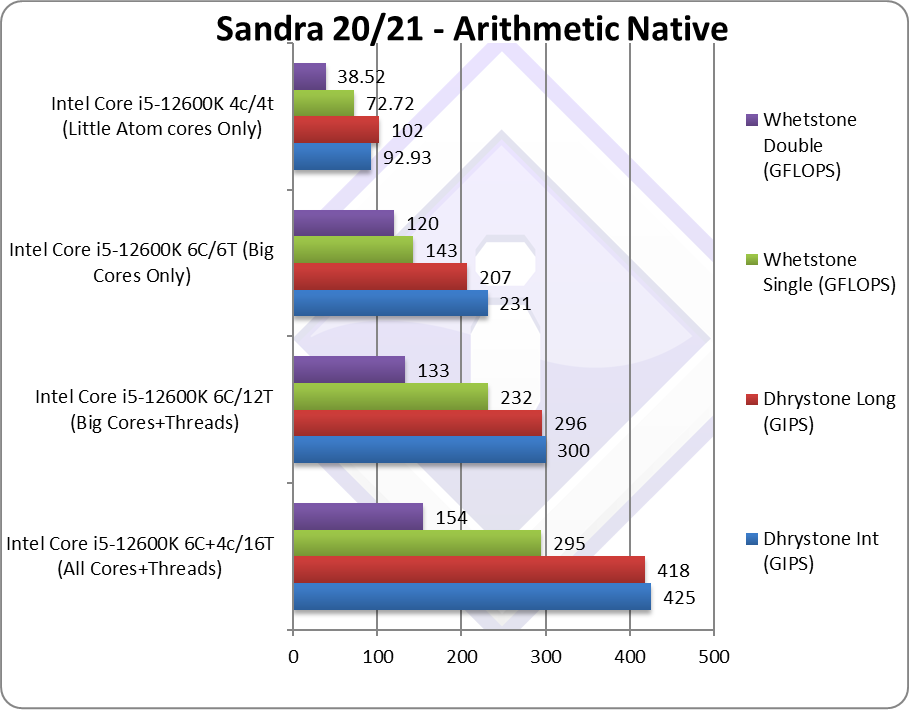
Native Dhrystone Integer (GIPS) | 425 [+42%] | 300 [2.15x] | 231 | 92.93 | LITTLE cores bring 42% improvement! |
|
Native Dhrystone Long (GIPS) | 418 [+41%] | 296 [1.93x] | 207 | 102 | A 64-bit integer workload changes nothing |
|
Native FP32 (Float) Whetstone (GFLOPS) | 295 [+27%] | 232 [2.12x] | 143 | 38.52 | With floating point, just 27% improvement. |
|
Native FP64 (Double) Whetstone (GFLOPS) | 154 [+16%] | 133 [2.3x] | 120 | 38.52 | With FP64 we’re down to 16%. |
| On legacy, non-SIMD tasks the LITTLE/E Atom cores make a decent contribution – 40% in integer workloads which is significant; the big/P cores are about 2x faster through.
On floating-point non-SIMD legacy compute workloads, we’re down to about 20% improvement only as the Atom FPU is just not as powerful w.r.t. to the Core FPU even on such non-SIMD code. Still, big/P cores is only about 2.3x faster. With 4 LITTLE/E cores the same area as 1 big/P Core, more LITTLE cores as with RPL is looking to be very beneficial. |
||||||
 |
||||||
 |
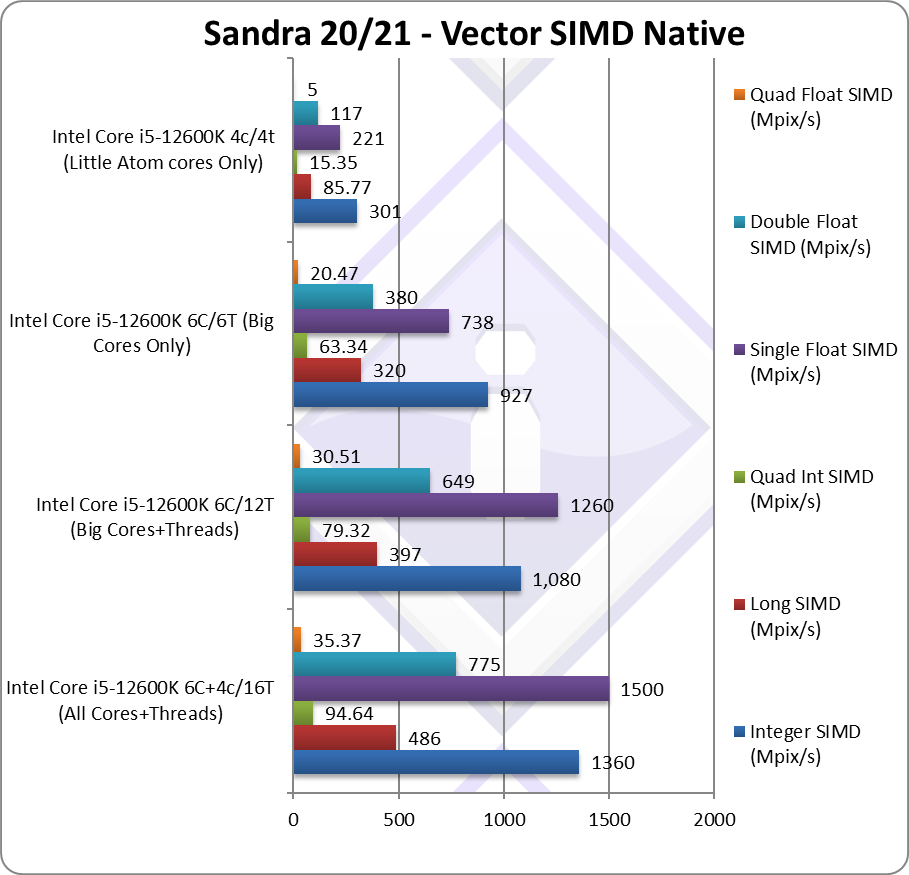
Native Integer (Int32) Multi-Media (Mpix/s) | 1,360 [+26%] | 1,080 [2.4x] | 927 | 301 | LITTLE cores only bring 26% improvement. |
|
Native Long (Int64) Multi-Media (Mpix/s) | 486 [+22%] | 397 [3.1x] | 320 | 85.77 | With a 64-bit, we’re down to 22% improvement. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 94.64 [+19%] | 79.32 [3.5x] | 63.34 | 15.35 | Using 64-bit int to emulate Int128 we’re 19% better |
|
Native Float/FP32 Multi-Media (Mpix/s) | 1,500 [+19%] | 1,260 [3.8x] | 738 | 221 | In this floating-point vectorised we’re still 19% better. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 775 [+19%] | 649 [3.7x] | 380 | 117 | Switching to FP64 nothing changes. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 35.37 [+16%] | 30.51 [4.1x] | 20.47 | 5 | Using FP64 to mantissa extend FP128 we’re just 16% faster. |
| With heavily vectorised SIMD workloads – the LITTLE/E Atom cores fall much further behind and bring just 16-26% better performance. Integer SIMD performance is still a big stronger (~23% better) while floating-point falls to about (~18% better).
As a result the big/P Core is generally 3x faster than LITTLE/E Atom, with one test just over 4.1x – and this is running AVX2/FMA code. As we saw RPL/ADL Cores running AVX512 code up to 30-40% faster (when the LITTLE/E cores are disabled completely) – it makes the big/P Cores over 5.x faster (AVX512) vs. LITTLE/E Atom (AVX2/FMA). With RPL doubling the LITTLE/E cores but not adding more big/P cores, we don’t expect it to improve significantly on this benchmark and likely lose to Zen4 with AVX512. But this is perhaps the worst-case-scenario. |
||||||
 |
||||||
 |
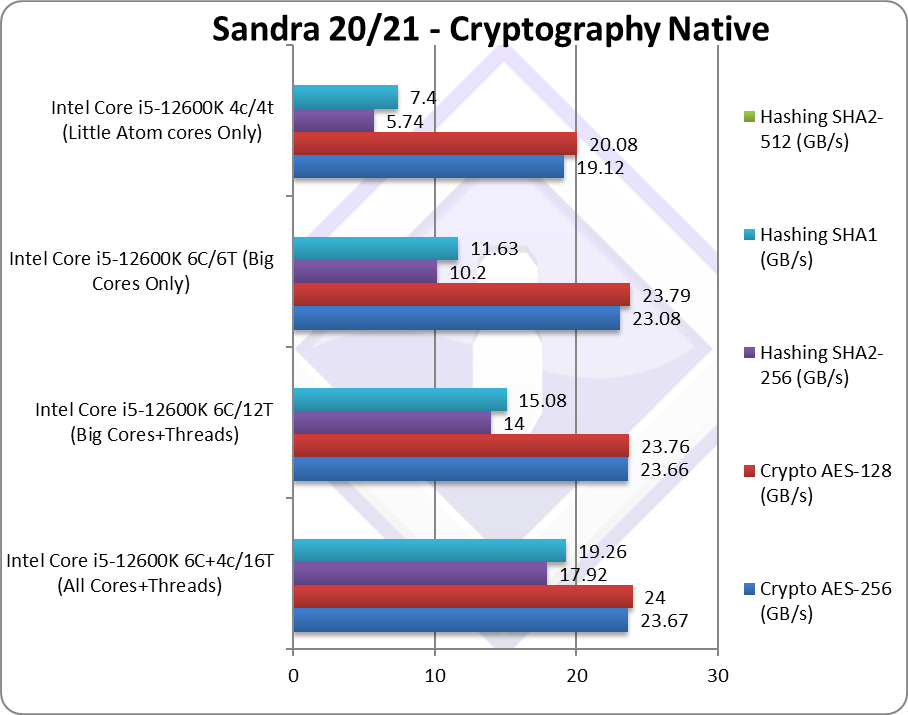
Crypto AES-256 (GB/s) | 23.67 [=] | 23.66 [0.82x] | 23.08 | 19.12 | LITTLE cores cannot help here |
|
Crypto AES-128 (GB/s) | 24 [+1%] | 23.76 [0.79x] | 23.79 | 20.08 | No change with AES128. |
|
Crypto SHA2-256 (GB/s) | 17.92 [+28%] | 14 [1.62x] | 10.2 | 5.76 | LITTLE cores do bring 28% improvement |
|
Crypto SHA1 (GB/s) | 19.26 [+28%] | 15.08 [1.35x] | 11.63 | 7.4 | Less compute intensive SHA1. |
| The memory sub-system is crucial here, and the crypto tests show that the LITTLE/E cores cannot help – but at least they don’t get in the way. Note that both big/P and LITTLE/E Atom cores have AES hardware acceleration (HWA).
Hashing tests are compute intensive – despite hardware acceleration (HWA) supported by both types of cores – and here the LITTLE/E Atom cores do help – bringing 28% performance improvement. Still, the big/P Cores are over 1.5x faster. Still, let’s recall that AVX512 multi-buffer has shown to be even faster than even SHA HWA (which operates on a single buffer) that we cannot use here. RPL with twice as many LITTLE/E Atom cores that are both AES and SHA hardware accelerated – is likely to improve by a decent amount over ADL, though in some cases the loss of AVX512 will still hurt. |
||||||
 |
||||||
 |
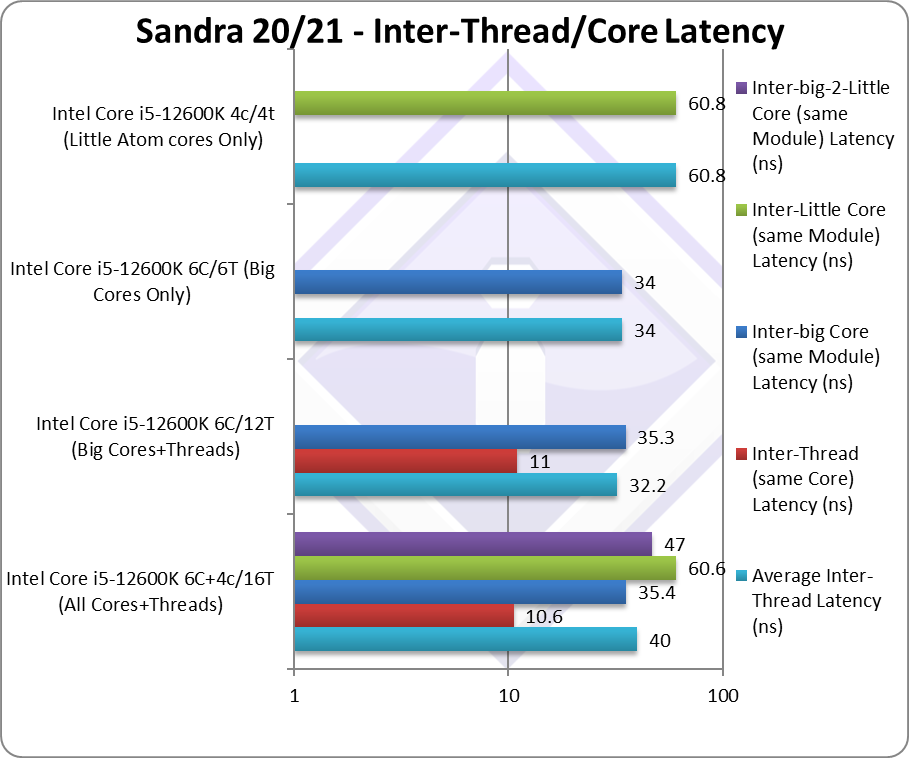
Average Inter-Thread Latency (ns) | 40 [+24%] | 32.2 | 34 | 60.8 | Latency is 24% worse due to LITTLE cores |
|
Inter-Thread Latency (Same Core) (ns) | 10.6 [=] | 11 | – | – | L1D helps massively here. |
|
Inter-big/P-Core Latency (ns) | 35.4 [=] | 35.3 | 34 | – | Without L1D we’re 3.5x slower. |
|
Inter-LITTLE/E Atom core Latency (ns) | 60.6 [=] | – | – | 60.8 | But LITTLE cores are 6x slower |
|
Inter-big/P-to-LITTLE/E core Latency (ns) | 47 | – | – | – | big to LITTLE is just 4.7x slower. |
| As big/P Cores share L1D, thread pairs have very low latency (~10ns) – while going off Core (big/P to big/P) is about 3.5x slower (~35ns).
Still, LITTLE/E to LITTLE/E Atom core – despite sharing cluster L2 cache – is much slower (~60ns) which is almost 2x slower than what we saw before. If anything big/P to LITTLE/E core transfer have lower latency (~45ns) than this which is unexpected. |
||||||
 |
||||||
|
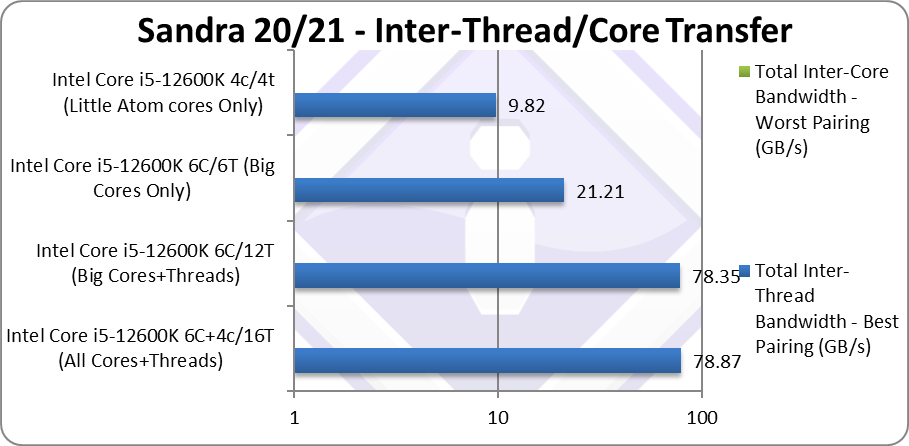
Total Inter-Thread Bandwidth – Best Pairing (GB/s) | 78.87 [=] | 78.35 [5.3x] | 21.21 | 9.82 | No improvement for LITTLE cores |
| As with inter-thread latency, while the big/P Cores share L1D (very useful for small data transfers) – the LITTLE/E Atom cores have to rely on the shared cluster L2 cache that has much lower bandwidth. In effect, bandwidth between big/P cores is over 5x greater – with even transfers between big/P to LITTLE/E cores faster(!)
However, due to the big unified L3 cache, the bandwidth does not “crater” when the pairing is not the best – as for example multiple CCX/Module AMD Ryzens. |
||||||
 |
||||||
 |
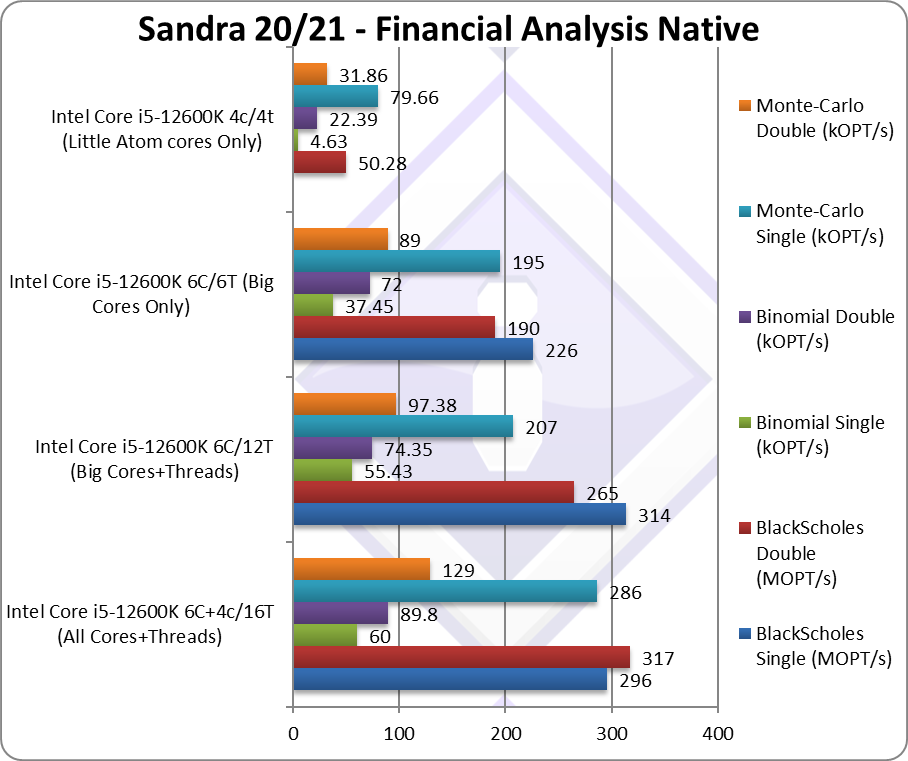
Black-Scholes float/FP32 (MOPT/s) | 296 [-6%] | 314 [3.78x] | 226 | 55.26 | Black-scholes is un-vectorised and compute heavy. |
|
Black-Scholes double/FP64 (MOPT/s) | 317 [+20%] | 265 [3.51x] | 190 | 50.28 | Using FP64 LITTLE brings 20% improvement. |
|
Binomial float/FP32 (kOPT/s) | 60 [+8%] | 55.43 [7.98x] | 37.45 | 4.63 | Binomial uses thread shared data thus stresses the cache & memory system. |
|
Binomial double/FP64 (kOPT/s) | 89.8 [+21%] | 74.34 [2.21x] | 72 | 22.39 | With FP64 code LITTLE brings 21% improvement. |
|
Monte-Carlo float/FP32 (kOPT/s) | 286 [+38%] | 207 [1.73x] | 195 | 79.66 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches. |
|
Monte-Carlo double/FP64 (kOPT/s) | 129 [+32%] | 97.32 [2.03x] | 89 | 31.86 | Switching to FP64 LITTLE/E brings 32% |
| With non-SIMD financial workloads, similar to what we’ve seen in legacy floating-point code (Whetstone), the LITTLE/E Atom cores bring about 20% improvement overall. Unfortunately, we cannot hope for the 40% we saw in integer workloads – but it is still a decent improvement.
RPL will thus improve decently over ADL with double the count of LITTLE/E Atom cores, though it may still be better to have got more big/P Cores. Perhaps such code is better offloaded to GP-GPUs these days, but still lots of financial software do not use GP-GPUs even today. |
||||||
 |
||||||
 |
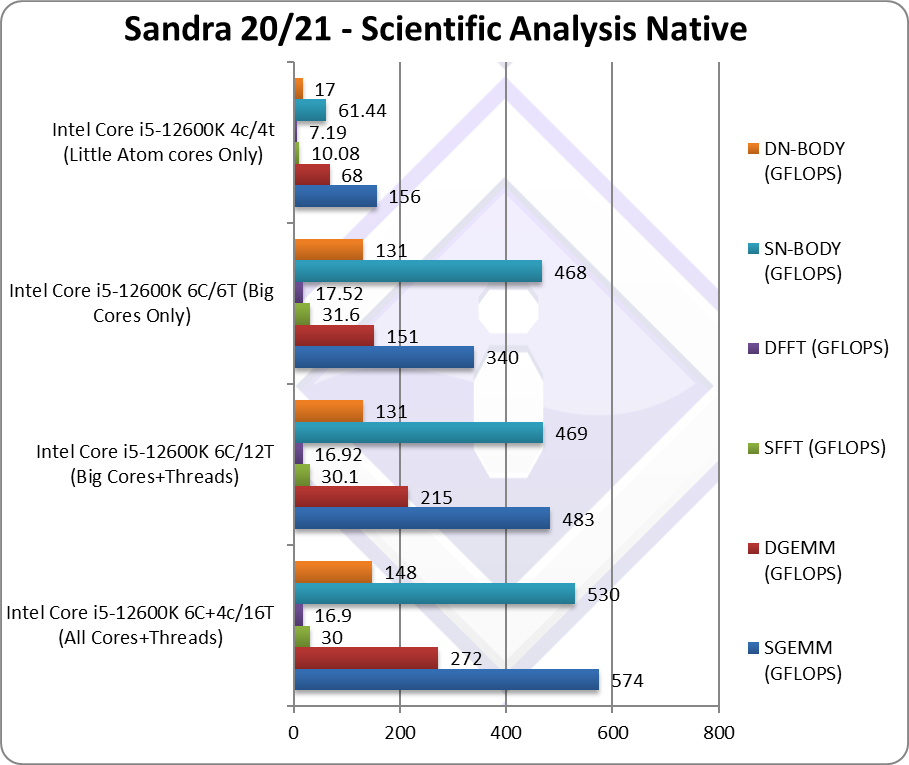
SGEMM (GFLOPS) float/FP32 | 574 [+19%] | 483 [2.06x] | 340 | 156 | In this tough vectorised algorithm we see 20% improvement. |
|
DGEMM (GFLOPS) double/FP64 | 272 [+27%] | 215 [2.1x] | 151 | 68 | With FP64 vectorised code, we’re 27% faster. |
|
SFFT (GFLOPS) float/FP32 | 30 [=] | 30.1 [2x] | 31.6 | 10.08 | FFT is also heavily vectorised but memory dependent. |
|
DFFT (GFLOPS) double/FP64 | 16.9 [=] | 16.92 [1.56x] | 17.52 | 7.19 | With FP64 code, nothing changes |
|
SN-BODY (GFLOPS) float/FP32 | 530 [+13%] | 469 [5.1x] | 468 | 61.44 | N-Body simulation is vectorised but with more memory accesses. |
|
DN-BODY (GFLOPS) double/FP64 | 148 [+13%] | 131 [5.13x] | 131 | 17 | With FP64 we’re still 13% better |
| With highly vectorised SIMD code (scientific workloads) but memory latency dependent – the LITTLE/E Atom cores perform better than on pure compute heavy SIMD code – with a modest 12% improvement overall. In fairness, in some algorithms (FFT) even SMT does not help – and here just using the big/P cores only would yield the best performance.
RPL is thus not likely to improve much over ADL with just more LITTLE/E Atom cores – except in some algorithms (e.g. GEMM). |
||||||
 |
||||||
 |
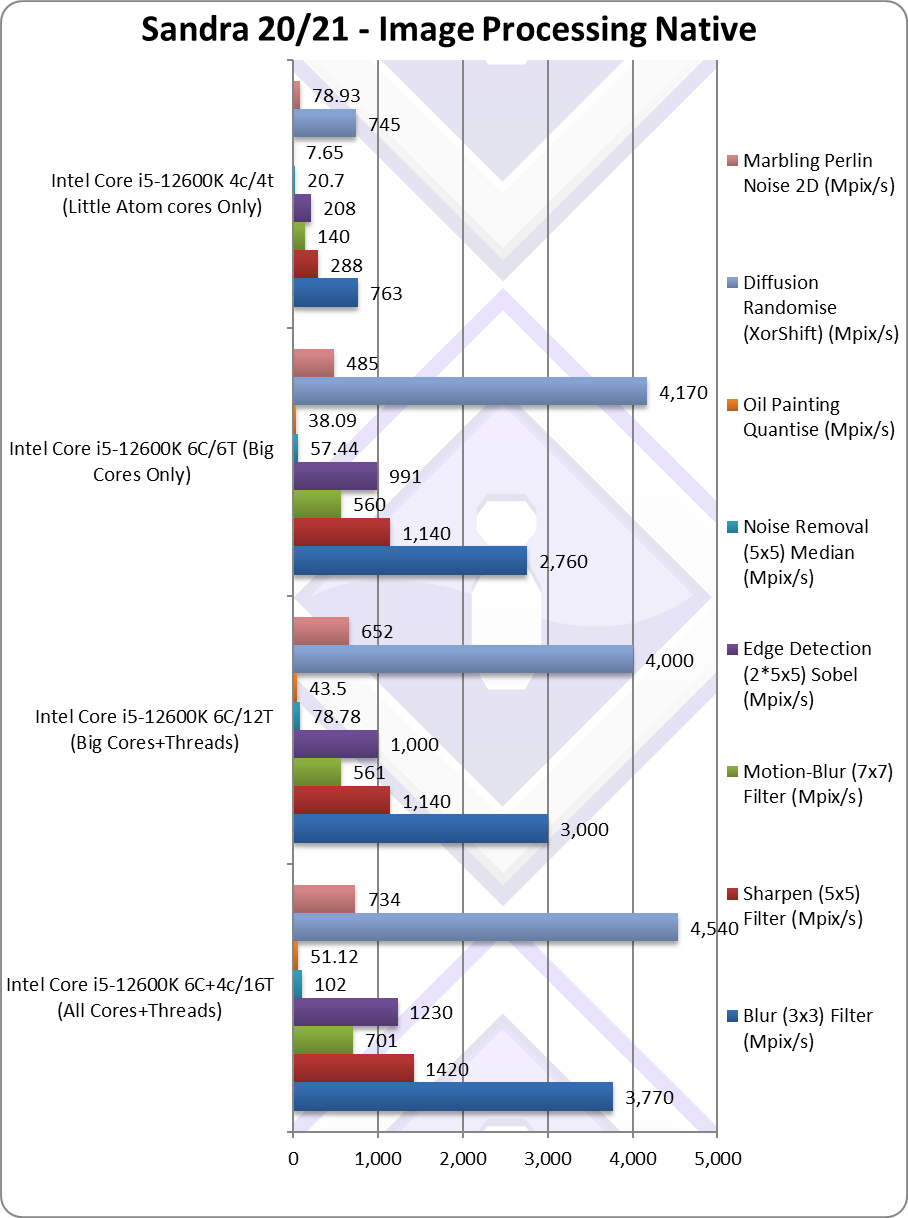
Blur (3×3) Filter (MPix/s) | 3,770 [+26%] | 3,000 [2.62x] | 2,760 | 763 | Vectorised integer workload LITTLE is 26% better. |
|
Sharpen (5×5) Filter (MPix/s) | 1,420 [+25%] | 1,140 [2.63x] | 1,140 | 288 | Same algorithm but more shared data we’re 25% better. |
|
Motion-Blur (7×7) Filter (MPix/s) | 701 [+25%] | 561 [2.67x] | 560 | 140 | Again same algorithm but even more data shared 25% better. |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 1,230 [+23%] | 1,000 [3.2x] | 991 | 208 | Different algorithm LITTLE brings 23% improvement. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 102 [+29%] | 78.78 [2.53x] | 57.44 | 20.7 | Still vectorised we see 29% improvement. |
|
Oil Painting Quantise Filter (MPix/s) | 51.12 [+18%] | 43.5 [3.8x] | 38.09 | 7.65 | LITTLE/E bring only 18% improvement |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 4,540 [+14%] | 4,000 [3.57x] | 4,170 | 745 | With integer workload, LITTLE is 14% faster. |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 734 [+13%] | 652 [5.5x] | 485 | 78.93 | In this final test LITTLE/E bring 13% improvement |
| This benchmarks *love* AVX512 even without, here, we still see the LITTLE/E Atom cores provide an overall 21% uplift which is not to be ignored. Overall, the big/P Cores are 3.3x faster than the LITTLE/E cores, though in some tests over 5x faster.
Unlike the heavy compute SIMD fractals – here it is likely RPL with double LITTLE/E Atom cores is still going to improve by a good about – though, again, perhaps not as much if we had AVX512 support. Going against AVX512-enabled competition (AMD) is going to be tough… |
||||||
SiSoftware Official Ranker Scores
- 12th Gen Intel Core i9-12900K (8C + 8c / 24T)
- 12th Gen Intel Core i9-12900KF (8C + 8c / 24T)
- 12th Gen Intel Core i7-12700K (8C + 4c / 20T)
- 12th Gen Intel Core i5-12600K (6C + 4c / 16T)
Final Thoughts / Conclusions
Summary: RaptorLake takes a big gamble with more LITTLE Atom cores
RaptorLake (RPL) will double LITTLE/E Atom cores vs. AlderLake (ADL) – but will not add additional big/P Cores: will this strategy win?
It is not really a surprise to find that the LITTLE/E Atom cores have good performance on “legacy” non-SIMD code where they are generally 1/2x the performance of the big/P Core; this means that with 4x of them (area wise) – you get 2x the performance per area – thus more LITTLE/E Atom cores will work out better in RPL.
With SIMD heavy compute workloads (AVX2/FMA) – things are more complicated, as the LITTLE/E Atom cores are only 1/3x-1/4x the performance of big/P Core – thus in general (considering the overhead of additional threads) – we would generally be better off with more big/P Cores (power notwithstanding).
An additional is that AVX512 has been disabled – just at the time when the competition (AMD) is bringing AVX512-enabled CPUs (Zen4 – Series 7000)! We’ve previously seen that RKL/ADL Cores perform 30-40% better with AVX512 code – thus making big/P Core over 5x faster than LITTLE/E Atom core. There is no question here that we’d prefer more big/P cores and not more LITTLE/E Atom cores.
We should also mention that the big/P Cores in RPL are updated (“Raptor Cove” vs. “Golden Cove“) and are rumoured to run much faster (Turbo clock) that should bring additional performance vs. the big/P Cores in ADL. Meanwhile the LITTLE/E Atom cores (“Gracemont“) have not been updated at all and seem to run at the frequency limit and thus unlikely be any faster.
It is likely that Intel is aware of this and there is nothing else they could do in the short-term (process-wise, power-wise, etc.) and adding more big/P Cores was actually worse. In non-SIMD (especially non-AVX512) workloads (Cinebench?) more Atom cores are likely to perform better and likely consume less power as well.
Thus we will have to wait for the next arch (“MeteorLake” MTL) to perhaps increase the big/P Core counts, perhaps enable AVX512 code to run by updating LITTLE/E Atom cores to support it (microcode emulation? variable-width AVX? forced scheduling to big/P Cores?) In any case, MTL may have to bring significant performance upgrades if it is to beat the AVX512-enabled competition (AMD)…
Long Summary:RPL is a risky gamble that just doubles the LITTLE/E Atom core counts while not increasing the big/P Cores counts at all. While this will improve non-SIMD code performance, it is likely to fail against AVX512 enabled competition. Still for some workloads, especially low-compute, RPL might be a decent improvement over ADL. Still, maybe it’s best to wait…
Summary: RaptorLake takes a big gamble with more LITTLE Atom cores
Further Articles
Please see our other articles on:
- CPU
- Cache & Memory
- GP-GPU
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!