What is “Ampere”?
It is the latest arch(itecture) (SM8.x) from nVidia launching with the new Series 30 mainstream cards (RTX 3090, 3080 and soon 3070, 3060) cards, a major update from the previous “Turing”/”Volta” (Series 20, SM 7.x). A “Titan” pro-sumer version will also launch soon while the data-center A100 version is already available.
Like previous mainstream versions, “Ampere” uses the standard compute ratios (1/32 FP64, 2x FP16) and (high-speed) GDDR6X memory (not HBM2+). It brings update 3rd gen(eration) tensor cores and 2nd gen ray-tracing (RTX) cores but not any new core types.
The updated tensor cores now support FP64 precision, BF16 (in addition to existing FP16) and also TF32 – an “optimised” FP32 precision format that can speed-up operations that require higher precision (than 16-bit). Thus for the first time, high precision algorithms can make use of the tensor cores, greatly expanding their use.
It supports PCIe4, thus doubling transfers bandwidth (PCIe4 x16 up to 32GB/s) on supported platforms (AMD only for now but soon Intel with RocketLake and later) which was needed considering size of video memory (up to 24GB). It also supports “RTX I/O” that can asynchronously transfer from storage direct to GPU; this will be used for Microsoft’s DirectStorage (and similar) and hopefully CUDA / OpenCL extensions.
For higher bandwidth, “Ampere” supports GDDR6X, an evolution of GDDR6 allowing for much higher data rates – up to 40% over previous generation. Size-wise the 3090 comes with 24GB video memory, over 2x increase over the previous 2080Ti!
Note: Due to the great increase in both compute and memory capacity, we (SiSoftware) have had to increase (Sandra’s GPGPU) benchmark limits to take advantage of the new capabilities. Please update to Sandra 20/20 R10 or later for best results. The optimisation work is on-going and likely further updates will be released in due course.
See these other articles on Titan (and competition) performance:
- AMD Radeon RX 6900 (RDNA2, Navi2) Review & Benchmarks – GPGPU Performance
- AMD Radeon RX 6800 (RDNA2, Navi2) Review & Benchmarks – GPGPU Performance
- nVidia Titan V : Volta GPGPU performance in CUDA and OpenCL
- nVidia Titan X : Pascal GPGPU performance in CUDA and OpenCL
- nVidia Titan V/X : FP16 and Tensor CUDA Performance
Hardware Specifications
We are comparing the top-of-the-range “Ampere” with previous generation cards and competing architectures with a view to upgrading to a mid-range high performance design.
| GPGPU Specifications | nVidia RTX 3090 FE (Ampere) | nVidia RTX 3080 FE (Ampere) | nVidia RTX 2080TI (Turing) | nVidia Titan V (Volta) | Comments | |
| Arch Chipset | Ampere GA102 (SM8.6) | Ampere GA102 (SM8.6) | Turing GP102 (SM7.5) | Volta VP100 (SM7.0) | The V is the only one using the top-end 100 chip | |
| Cores (CU) / Threads (SP) | 82 / 10,496 [+2.4x] | 68 / 8,704 [2x] | 68 / 4,352 | 80 / 5,120 | 2x more units per SP quite an increase. | |
| ROPs / TMUs | 112 / 328 | 96 / 272 | 88 / 272 | 96 / 320 | More units per SP. | |
| Tensor Cores (TC) |
328 | 272 [1/2x] | 544 | 640 | More powerful tensor cores despite less count. | |
| Speed (Min-Turbo) | 1.4GHz (135-1.78) | 1.44GHz (135-1.71) | 1.35GHz (136-1.635) | 1.2GHz (135-1.455) | Clocks have improved over Volta likely due to lower number of SMs. | |
| Power (TDP) (W) |
350W [+34%] | 320W [+23%] | 260W | 300W | TDP has greatly increased. | |
| Global Memory (GP) |
24GB GDDR6X 19GHz 384-bit | 10GB GDDR6X 19GHz 320-bit | 11GB GDDR6 14GHz 320-bit | 12GB HBM2 850Mhz 3072-bit | 2x more memory than even Volta. | |
| Memory Bandwidth (GB/s) |
936 [+52%] | 760 [+23%] | 616 | 652 | Despite no HBM2, 40% more bandwidth | |
| L1 Cache (kB) |
2x (64kB + 64kB) [+33%] | 2x (64kB + 64kB) [+33%] | 2x (32kB + 64kB) | 2x 24kB / 96kB shared | L1/shared is still the same but ratios have changed. | |
| L2 Cache (MB) |
6MB | 5MB | 5.5MB |
4.5MB | L2 cache reported has increased. | |
| FP64/double ratio | 1/32x | 1/32x | 1/32x | 1/2x | Low ratio like all consumer cards, Volta dominates here | |
| FP16/half ratio | 2x | 2x | 2x | 2x | Same rate as Volta, 2x over FP32 | |
| Price/RRP (USD) |
$1,500 [+25%, +$300] | $700 | $1,200 | $3,000 | Ampere gets a $300 bump, about %25% vs. Turing. | |

nVidia RTX 3090 (Ampere)
Processing Performance
We are testing both CUDA native as well as OpenCL performance using the latest SDK / libraries / drivers.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest nVidia drivers 452, CUDA 11.3, OpenCL 1.2 (latest nVidia provides). Turbo / Boost was enabled on all configurations.
| Processing Benchmarks | nVidia RTX 3090 FE (Ampere) | nVidia RTX 3080 FE (Ampere) | nVidia RTX 2080TI (Turing) | nVidia Titan V (Volta) | Comments | |
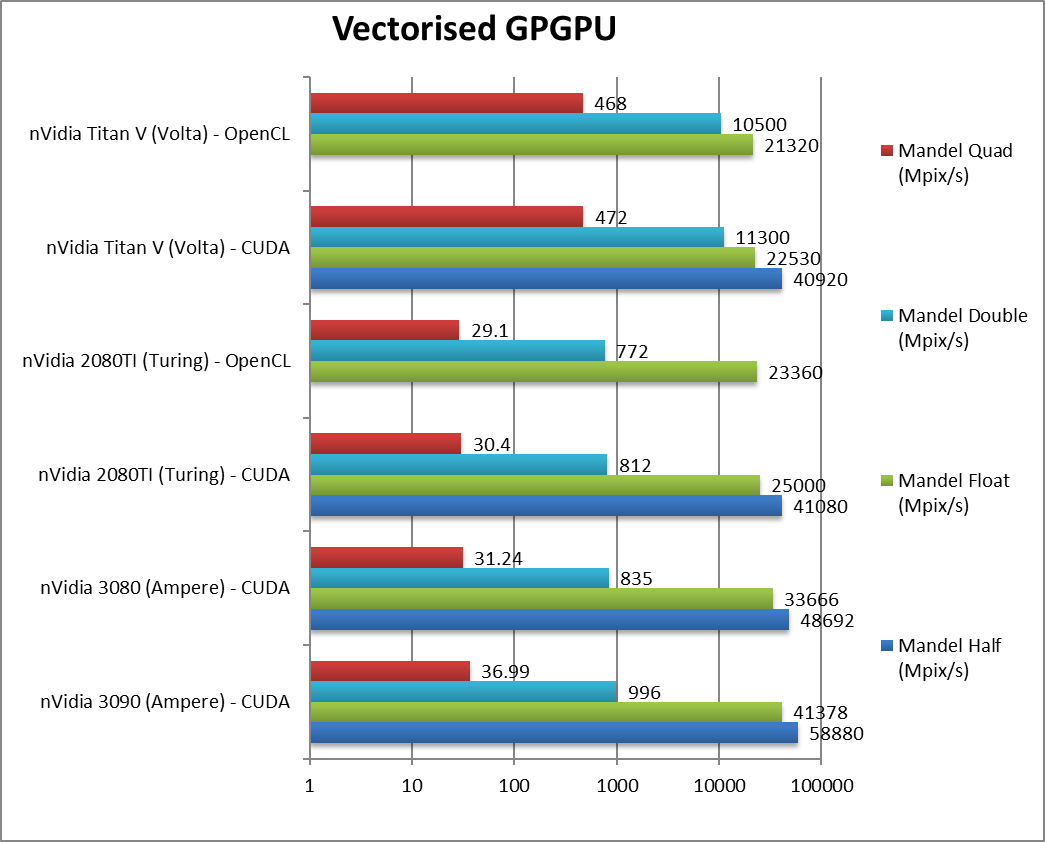 |
||||||
 |
Mandel FP16/Half (Mpix/s) | 58,880 [+43%] | 48,692 [+18%] | 41,080 / n/a | 40,920 / n/a | Right off the bat, Ampere is 43% faster. |
|
Mandel FP32/Single (Mpix/s) | 41,378 [+66%] | 33,666 [+34%] | 25,000 / 23,360 | 22,530 / 21,320 | With standard FP32, Ampere is 66% faster. |
|
Mandel FP64/Double (Mpix/s) | 996 [+23%] | 835 [+3%] | 812 / 772 | 11,300 / 10,500 | For FP64 you don’t want consumer Ampere. |
|
Mandel FP128/Quad (Mpix/s) | 37 | 31 [+2%] | 30.4 / 29.1 | 472 / 468 | With emulated FP128 precision Ampere is again demolished. |
| Ampere greatly improves over Turing/Volta using FP16/FP32 precision, between 40-70%! Naturally being consumer, FP64 performance is too low to be considered an option. | ||||||
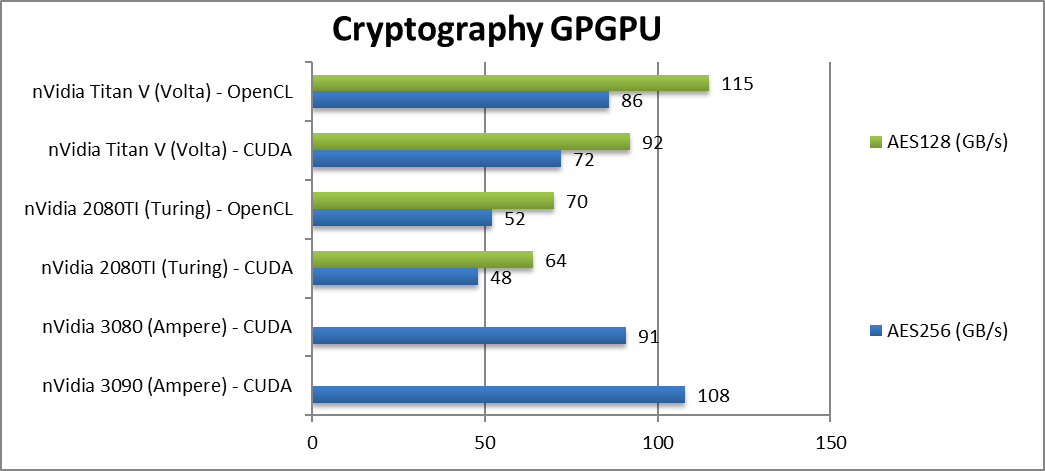 |
||||||
 |
Crypto AES-256 (GB/s) | 108 [+2.25x] | 91 [+89%] | 48 / 52 | 72 / 86 | Streaming workloads fly on Ampere despite no HBMx. |
|
Crypto AES-128 (GB/s) | 64 / 70 | 92 / 115 | Not a lot changes here. | ||
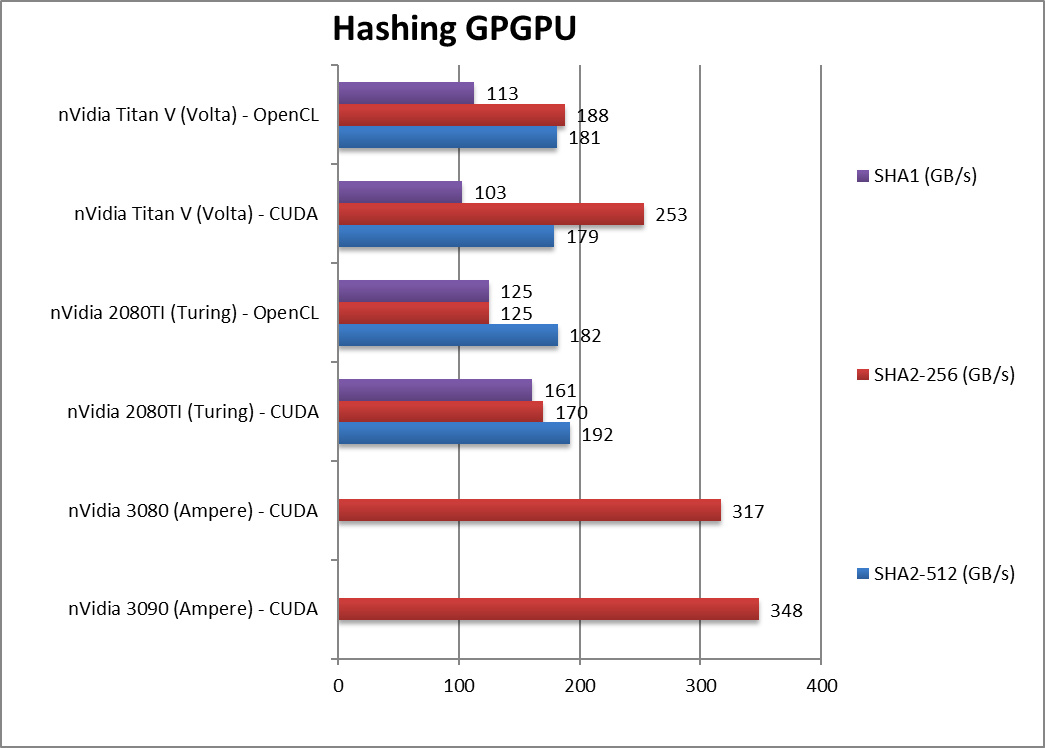 |
||||||
|
Crypto SHA2-512 (GB/s) | 192 / 182 | 179 / 181 | With 64-bit integer workload. | ||
|
Crypto SHA256 (GB/s) | 348 [+2.05x] | 317 [+86%] | 170 / 125 | 253 / 188 | Despite no HBM, again Ampere reigns. |
|
Crypto SHA1 (GB/s) | 161 / 125 | 103 / 113 | Nothing much changes here | ||
| While Turing’s GDDR6 memory could not keep up with Volta’s HBM2 – Ampere’s GDDR6X has no problems: it is over 2x faster than Turing in both streaming benchmarks (crypto or hashing). With the huge increase in size (24GB) – it is a significant upgrade. | ||||||
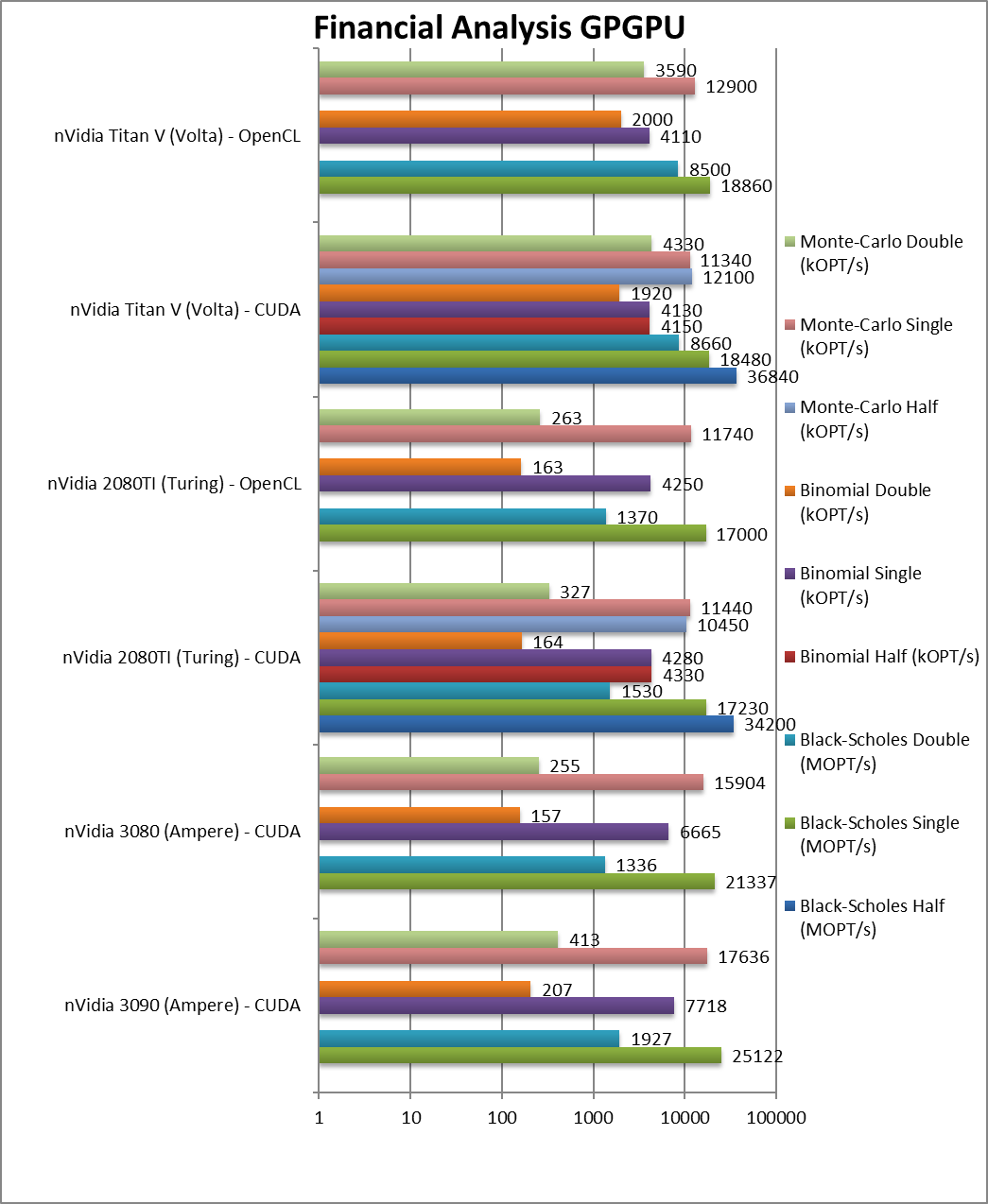 |
||||||
 |
Black-Scholes float/FP32 (MOPT/s) | 25,122 [+46%] | 21,337 [+24%] | 17,230 / 17,000 | 18,480 / 18,860 | Ampere starts 46% faster than Turing. |
|
Black-Scholes double/FP64 (MOPT/s) | 1,927 [+26%] | 1,336 [-13%] | 1,530 / 1,370 | 8,660 / 8,500 | FP64 is 26% faster but no point. |
|
Binomial float/FP32 (kOPT/s) | 7,718 [+80%] | 6,665 [+55%] | 4,280 / 4,250 | 4,130 / 4,110 | Binomial uses thread shared data thus stresses the SMX’s memory system. |
|
Binomial double/FP64 (kOPT/s) | 207 [+26%] | 157 [-5%] | 164 / 163 | 1,920 / 2,000 | With FP64 again no point. |
|
Monte-Carlo float/FP32 (kOPT/s) | 17,636 [+54%] | 15,904 [+39%] | 11,440 / 11,740 | 11,340 / 12,900 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure. |
|
Monte-Carlo double/FP64 (kOPT/s) | 413 [+26%] | 255 [-4%] | 327 / 263 | 4,330 / 3,590 | Switching to FP64 again little point. |
| For financial workloads, as long as you only need FP32 (or FP16), Ampere is again 40-80% faster than Turing. But anything using high-precision (FP64) need not apply. | ||||||
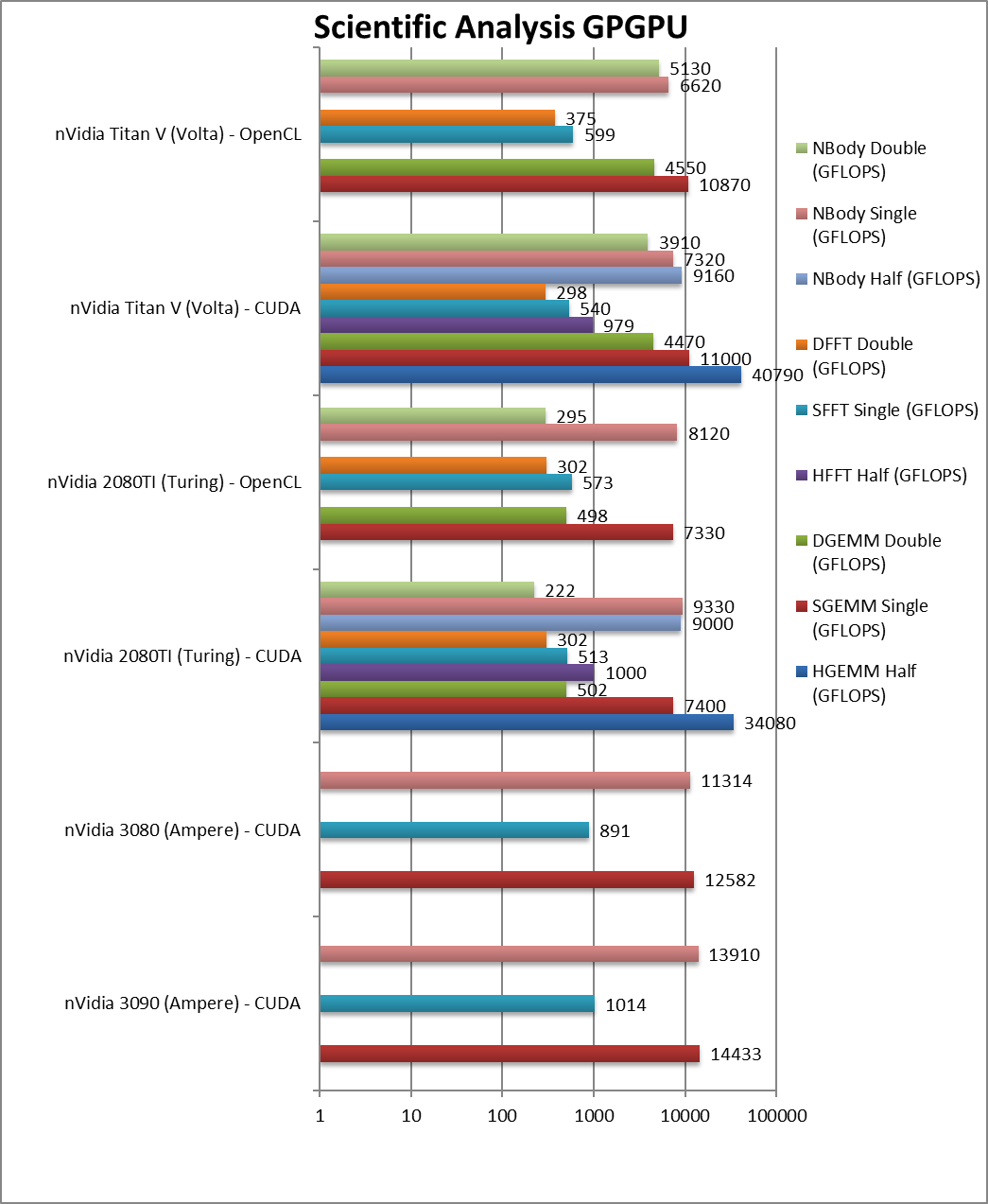 |
||||||
 |
HGEMM (GFLOPS) half/FP16 | 34,080* | 40,790* | Using tensor cores. | ||
|
SGEMM (GFLOPS) float/FP32 | 14,433 [+95%] | 12,582 [+70%] | 7,400 / 7,330 | 11,000 / 10,870 | Ampere is almost 2x faster than Turing. |
|
DGEMM (GFLOPS) double/FP64 | 502 / 498 | 4,470 4,550 | With FP64 precision. | ||
|
HFFT (GFLOPS) half/FP16 | 1,000 | 979 | FFT is memory-bound. | ||
|
SFFT (GFLOPS) float/FP32 | 1,014 [+98%] | 891 [+74%] | 512 / 573 | 540 / 599 | With FP32, Ampere is again 2x faster. |
|
DFFT (GFLOPS) double/FP64 | 302 / 302 | 298 / 375 | Completely memory bound. | ||
|
HNBODY (GFLOPS) half/FP16 | 9,000 | 9,160 | N-Body simulation with FP16. | ||
|
SNBODY (GFLOPS) float/FP32 | 13,910 [+49%] | 11,314 [+21%] | 9,330 / 8,120 | 7,320 / 6,620 | N-Body simulation allows Ampere to dominate. |
|
DNBODY (GFLOPS) double/FP64 | 222 / 295 | 3,910 / 5,130 | With FP64 precision. | ||
| With the new tensor cores Ampere enjoys a 2x lead over Turing; in other benchmarks we see the similar 50% improvement. Again, FP64 performance is too low to matter, tensor cores or not. | ||||||
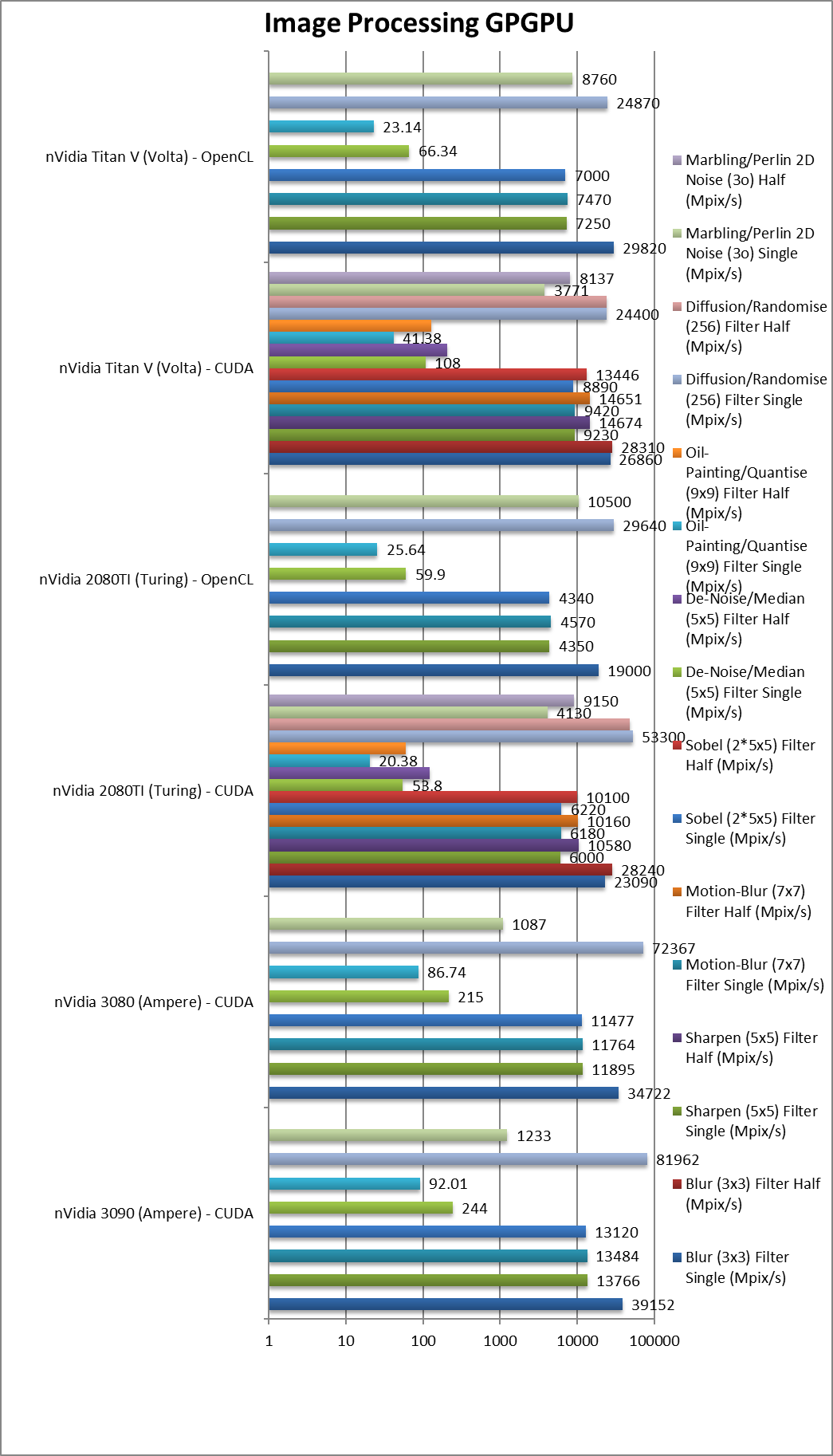 |
||||||
 |
Blur (3×3) Filter single/FP32 (MPix/s) | 39,152 [+70%] | 34,722 | 23,090 / 19,000 | 26,860 / 29,820 | In this 3×3 convolution algorithm, Ampere is 70% faster. |
|
Blur (3×3) Filter half/FP16 (MPix/s) | 28,240 | 28,310 | With FP16 precision. | ||
|
Sharpen (5×5) Filter single/FP32 (MPix/s) | 13,766[+2.29x] | 11,895 | 6,000 / 4,350 | 9,230 / 7,250 | More shared data: Ampere is over 2x faster! |
|
Sharpen (5×5) Filter half/FP16 (MPix/s) | 10,580 | 14,676 | With FP16. | ||
|
Motion-Blur (7×7) Filter single/FP32 (MPix/s) | 13,484 [+2.18x] | 11,764 | 6,180 / 4,570 | 9,420 / 7,470 | Even more data, Ampere still 2x faster. |
|
Motion-Blur (7×7) Filter half/FP16 (MPix/s) | 10,160 | 14,651 | With FP16 nothing much changes in this algorithm. | ||
|
Edge Detection (2*5×5) Sobel Filter single/FP32 (MPix/s) | 13,120 [+2.11x] | 11,477 | 6,220 / 4,340 | 8,890 / 7,000 | Still convolution but with 2 filters – Ampere still 2x faster. |
|
Edge Detection (2*5×5) Sobel Filter half/FP16 (MPix/s) | 10,100 | 13,446 | Just as we seen above. | ||
|
Noise Removal (5×5) Median Filter single/FP32 (MPix/s) | 244 [+4.5x] | 215 | 52.53 / 59.9 | 108 / 66.34 | In this very memory sensitive algorithm, Ampere is over 4x faster. |
|
Noise Removal (5×5) Median Filter half/FP16 (MPix/s) | 121 | 204 | With FP16. | ||
|
Oil Painting Quantise Filter single/FP32 (MPix/s) | 92 [+4.5x] | 86 | 20.28 / 25.64 | 41.38 / 23.14 | Memory helps Ampere be 4.5x faster. |
|
Oil Painting Quantise Filter half/FP16 (MPix/s) | 59.55 | 129 | FP16 precision does not change things. | ||
|
Diffusion Randomise (XorShift) Filter single/FP32 (MPix/s) | 81,962 [+54%] | 72,367 | 24,600 / 29,640 | 24,400 / 24,870 | This algorithm is 64-bit integer heavy: Ampere is 54% faster. |
|
Diffusion Randomise (XorShift) Filter half/FP16 (MPix/s) | 22,400 | 24,292 | FP16 does not help here as we’re at maximum performance. | ||
|
Marbling Perlin Noise 2D Filter single/FP32 (MPix/s) | 1,233 [-70%] | 1,087 | 3,000 / 10,500 | 3,771 / 8,760 | Complex and largest filters needs some optimisations. |
|
Marbling Perlin Noise 2D Filter half/FP16 (MPix/s) | 7,850 | 8,137 | Switching to FP16. | ||
| For image processing, Ampere is even faster than what we’ve seen in other tests – routinely 2x faster than Turing. SM improvements and memory perfomance seem to help a lot here. | ||||||
 |
||||||
 |
Internal Memory Bandwidth (GB/s) | 766 [+55%] | 624 [+26%] | 494 / 485 | 534 / 530 | GDDR6X gives 55% better performance. |
|
Upload Bandwidth (GB/s) | 24.4 [+2.16x] | 23.3 [+2x] | 11.3 / 10.4 | 11.4 / 11.4 | PCIe4 is 2x faster. |
|
Download Bandwidth (GB/s) | 24.5 [+2.05x] | 24.4 [+2x] | 11.9 / 12.3 | 12.1 / 12.3 | Again, PCIe4 is 2x faster. |
| GDDR6X brings over 50% more bandwidth and overtakes even Volta’s HBM2; PCIe4 increases upload/download bandwidth by 2x which should greatly help the large memory transfers. All in all a huge upgrade over Turing. | ||||||
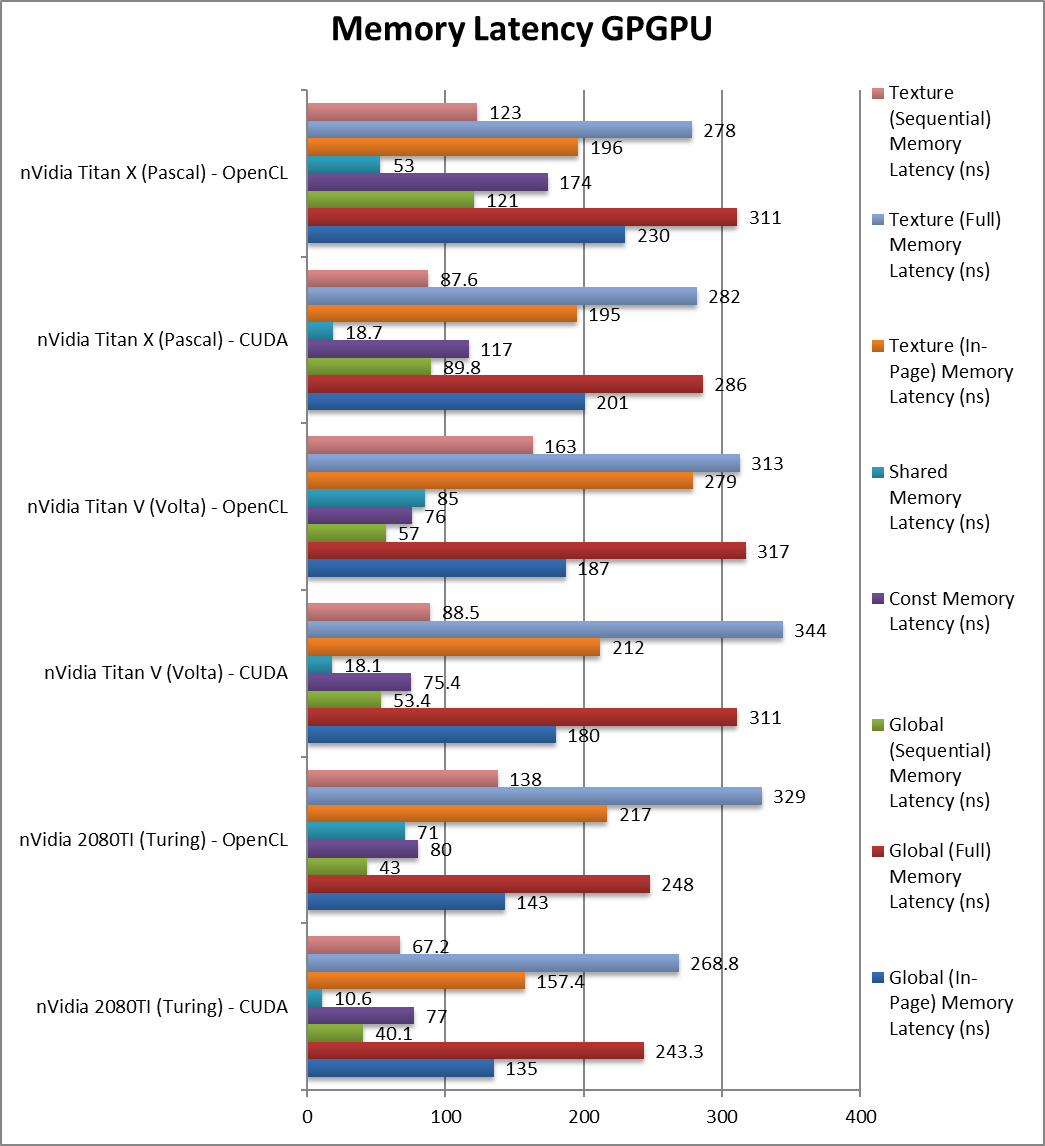 |
||||||
 |
Global (In-Page Random Access) Latency (ns) | 156 [+16%] | 151 | 135 / 143 | 180 / 187 | Despite the higher clock latencies seem to go up. |
|
Global (Full Range Random Access) Latency (ns) | 243 / 248 | 311 / 317 | Full range random accesses are also 22% faster. | ||
|
Global (Sequential Access) Latency (ns) | 40 / 43 | 53 / 57 | Sequential accesses have also dropped 25%. | ||
|
Constant Memory (In-Page Random Access) Latency (ns) | 77 / 80 | 75 / 76 | Constant memory latencies seem about the same. | ||
|
Shared Memory (In-Page Random Access) Latency (ns) | 10.6 / 71 | 18 / 85 | Shared memory latencies seem to be improved. | ||
|
Texture (In-Page Random Access) Latency (ns) | 157 / 217 | 212 / 279 | Texture access latencies have also reduced by 26%. | ||
|
Texture (Full Range Random Access) Latency (ns) | 268 / 329 | 344 / 313 | As we’ve seen with global memory, we see reduced latencies by 22%. | ||
|
Texture (Sequential Access) Latency (ns) | 67 / 138 | 88 / 163 | With sequential access we also see a 24% reduction. | ||
| For now, we see Ampere’s GDDR6X bring higher latencies despite the great increase of clock and bandwidth. Perhaps future versions will either increase clocks (while maintaining timings) or decrease timings as better memory becomes available. | ||||||
| Memory Benchmarks | nVidia 3090 RTX FE (Ampere) | nVidia 3080 RTX FE (Ampere) | nVidia 2080TI (Turing) | nVidia Titan V (Volta) | Comments | |
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
Executive Summary: Big, expensive but immensely powerful: 9/10 overall.
For compute loads on mainstream cards, “Ampere” brings big gains (50-100%) when using FP16/FP32 precision, a sizeable improvement. The new updated tensor cores also allow TF32/FP64 acceleration (for the first time) that greatly help many algorithms (e.g. convolution: neural networks/AI, image processing, etc.). The increase in memory size and performance also allows much bigger kernels and data sets to run.
Still as with all mainstream cards, FP64 performance is too reduced to be usable, for that you need either a full-Titan (not consumer) or a professional card. If the performance (especially with tensor cores supporting FP64 now) is similar to FP16/FP32, then the gains will be significant.
GDDR6X and PCIe4 bring sizeable bandwidth increases (50%-2x) and while latencies seem to have gone up a bit, they are manageable and don’t seem to have an effect on performance. As mentioned the top-end memory size (24GB) could be a game-changer if the dataset now fits.
Except physical size (it takes 3 slots) and power (TDP is now up to 350W (up from 280-300W) there aren’t really any downsides to the new “Ampere”. Most systems should have adequate power supplies however thus no worries there.
In summary, even upgrading from previous Turing arch(itecture) cards is worth-while as the performance gains are significant enough; but the old cards have maintained their value well and can offset the new cost – thus making the upgrade much cheaper. As algorithms get updated and data sets increase we should see even higher performance gains.
nVidia 3090 RTX (Ampere)