What is “CometLake”?
It is one of the 10th generation Core arch (CML) from Intel – the latest revision of the venerable (6th gen!) “Skylake” (SKL) arch; it succeeds the “WhiskyLake”/”CofeeLake” 8/9-gen current architectures for mobile (ULV U/Y) devices. The “real” 10th generation Core arch is “IceLake” (ICL) that does bring many changes but has not made its mainstream debut yet.
As a result there ar no major updates vs. previous “Skylake” designs, save increase in core count top end versions and hardware vulnerability mitigations which can still make a big difference:
- Up to 6C/12T (from 4C/8T “WhiskyLake”/”CoffeeLake” or 2C/4T Skylake/KabyLake)
- Increase Turbo ratios
- 2-channel LP-DDR4 support and DDR4-2667 (up from 2400)
- WiFi6 (802.11ax) AX201 integrated (from WiFi5 (802.11ac) 9560)
- Thunderbolt 3 integrated
- Hardware fixes/mitigations for vulnerabilities (“Meltdown”, “MDS”, various “Spectre” types)
The 3x (three times) increase in core count (6C/12T vs. “Skylake”/”Kabylake” 4C/8T) in the same 15-28W power envelope is pretty significant considering that Core ULV designs since 1st gen have always had 2C/4T; unfortunately it is limited to top-end thus even i7-10510U still has 4C/8T.
LP-DDR4 support is important as many thin & light laptops (e.g. Dell XPS, Lenovo Carbon X1, etc.) have been “stuck” with slow LP-DDR3 memory instead of high-bandwidth DDR4 memory in order to save power. Note the Y-variants (4.5-6W) will not support this.
WiFi is now integrated in the PCH and has been updated to WiFi6/AX (2×2 streams, up to 2400Mbps with 160MHz-wide channel) from WiFi5/AX (1733Mbps); this also means no simple WiFi-card upgrade in the future as with older laptops (except those with “whitelists” like HP, Lenovo, etc.)
Why review it now?
Until “IceLake” makes its public debut, “CometLake” latest ULV APUs from Intel you can buy today; despite being just a revision of “Skylake” due to increased core counts/Turbo ratios they may still prove worthy competitors not just in cost but also performance.
As they contain hardware fixes/mitigations for vulnerabilities discovered since original “Skylake” has launched (especially “Meltdown” but also various “Spectre” variants), the operating system & applications do not need to deploy slower mitigations that can affect performance (especially I/O) on the older designs. For some algorithms, this may be worth an upgrade alone!
In this article we test CPU core performance; please see our other articles on:
To compare against the other Gen10 CPU, please see our other articles:
- Intel Core Gen11 TigerLake ULV (i7-1165G7) Review & Benchmarks – CPU AVX512 Performance
- AVX512-IFMA(52) Improvement for IceLake and TigerLake
- Intel Core Gen10 IceLake ULV (i7-1065G7) Review & Benchmarks – CPU AVX512 Performance
- Intel Core Gen10 CometLake (i9-10900K) Review & Benchmarks – CPU Performance
Hardware Specifications
We are comparing the top-of-the-range Intel ULV with competing architectures (gen 8, 7, 6) as well as competiors (AMD) with a view to upgrading to a mid-range but high performance design.
| CPU Specifications | AMD Ryzen2 2500U Bristol Ridge | Intel i7 7500U (Kabylake ULV) | Intel i7 8550U (Coffeelake ULV) | Intel Core i7 10510U (CometLake ULV) | Comments | |
| Cores (CU) / Threads (SP) | 4C / 8T | 2C / 4T | 4C / 8T | 4C / 8T | No change in cores count. | |
| Speed (Min / Max / Turbo) | 1.6-2.0-3.6GHz | 0.4-2.7-3.5GHz | 0.4-1.8-4.0GHz (1.8 @ 15W, 2GHz @ 25W) |
0.4-1.8-4.9GHz (1.8GHz @ 15W, 2.3GHz @ 25W) |
CML has +22% faster turbo. | |
| Power (TDP) | 15-35W | 15-25W | 15-35W | 15-35W | Same power envelope. | |
| L1D / L1I Caches | 4x 32kB 8-way / 4x 64kB 4-way | 2x 32kB 8-way / 2x 32kB 8-way | 4x 32kB 8-way / 4x 32kB 8-way | 4x 32kB 8-way / 4x 32kB 8-way | No L1 changes | |
| L2 Caches | 4x 512kB 8-way | 2x 256kB 16-way | 4x 256kB 16-way | 4x 256kB 16-way | No L2 changes | |
| L3 Caches | 4MB 16-way | 4MB 16-way | 8MB 16-way | 8MB 16-way | And no L3 changes | |
| Microcode (Firmware) | MU8F1100-0B | MU068E09-8E | MU068E09-AE | MU068E0C-BE | Revisions just keep on coming. | |
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (AVX2, AVX, etc.). “CometLake” (CML) supports all modern instruction sets including AVX2, FMA3 but not AVX512 (like “IceLake”) or SHA HWA (like Atom, Ryzen).
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
| Native Benchmarks | AMD Ryzen2 2500U Bristol Ridge |
Intel i7 7500U (Kabylake ULV) |
Intel i7 8550U (Coffeelake ULV) |
Intel Core i7 10510U (CometLake ULV) |
Comments | |
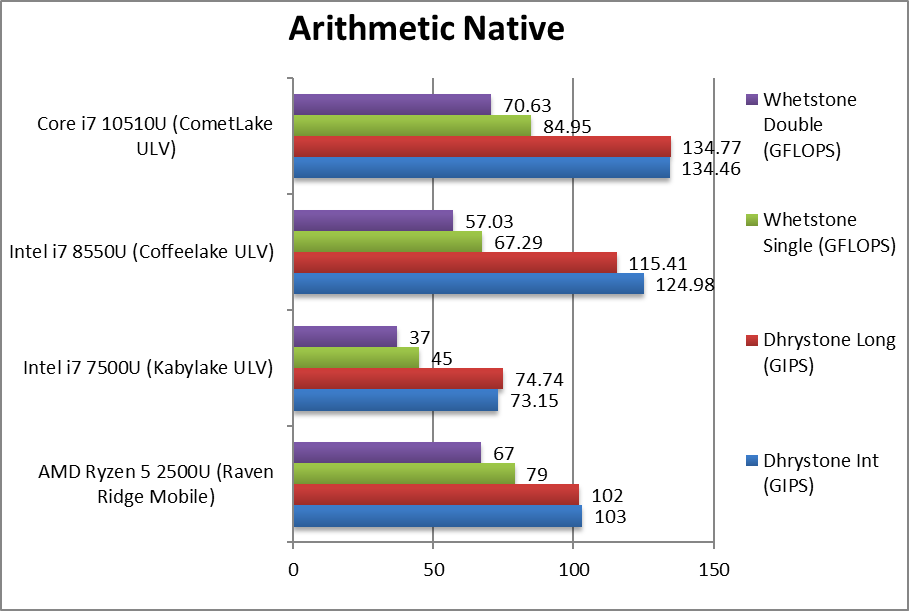 |
||||||
 |
Native Dhrystone Integer (GIPS) | 103 | 73.15 | 125 | 134 [+8%] | CML starts off 7% faster than CFL a good start. |
|
Native Dhrystone Long (GIPS) | 102 | 74.74 | 115 | 135 [+17%] | With a 64-bit integer workload – increases to 17%. |
|
Native FP32 (Float) Whetstone (GFLOPS) | 79 | 45 | 67.29 | 84.95 [+26%] | With floating-point workload CML is 26% faster! |
|
Native FP64 (Double) Whetstone (GFLOPS) | 67 | 37 | 57 | 70.63 [+24%] | With FP64 we see a similar 24% improvement. |
| With integer (legacy) workloads, CML-U brings a modest improvement of about 10% over CFL-U, cementing its top position. But with floating-points (also legacy) workloads we see a larger 25% increase which allows it to beat the competition (Ryzen Mobile) that was beating older designs (CFL-U, WHL-U, KBL-U, etc.) | ||||||
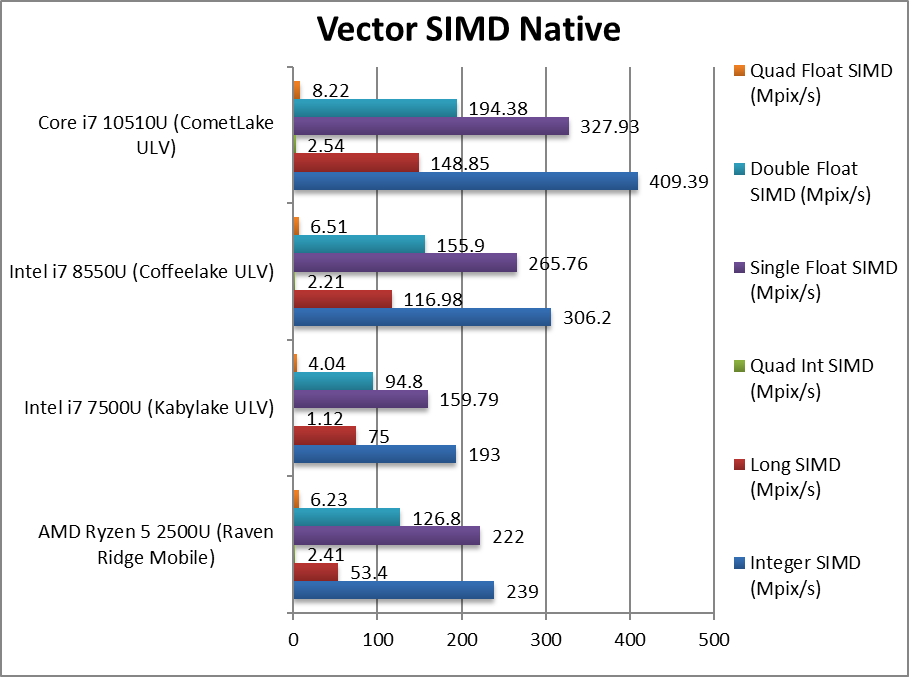 |
||||||
 |
Native Integer (Int32) Multi-Media (Mpix/s) | 239 | 193 | 306 | 409 [+34%] | In this vectorised AVX2 integer test CML-U is 34% faster than CFL-U. |
|
Native Long (Int64) Multi-Media (Mpix/s) | 53.4 | 75 | 117 | 149 [+27%] | With a 64-bit AVX2 integer workload the difference drops to 27%. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 2.41 | 1.12 | 2.21 | 2.54 [+15%] | This is a tough test using Long integers to emulate Int128 without SIMD; here CML-U is still 15% faster. |
|
Native Float/FP32 Multi-Media (Mpix/s) | 222 | 160 | 266 | 328 [+23%] | In this floating-point AVX/FMA vectorised test, CML-U is 23% faster. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 127 | 94.8 | 155.9 | 194.4 [+25%] | Switching to FP64 SIMD code, nothing much changes still 20% slower. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 6.23 | 4.04 | 6.51 | 8.22 [+26%] | In this heavy algorithm using FP64 to mantissa extend FP128 with AVX2 – we see 26% improvement. |
| With heavily vectorised SIMD workloads CML-U is 25% faster than previous CFL-U that may be sufficient to see future competition from Gen3 Ryzen Mobile with improved (256-bit) SIMD units, something that CFL/WHL-U may not beat. IcyLake (ICL) with AVX512 should improve over this despite lower clocks. | ||||||
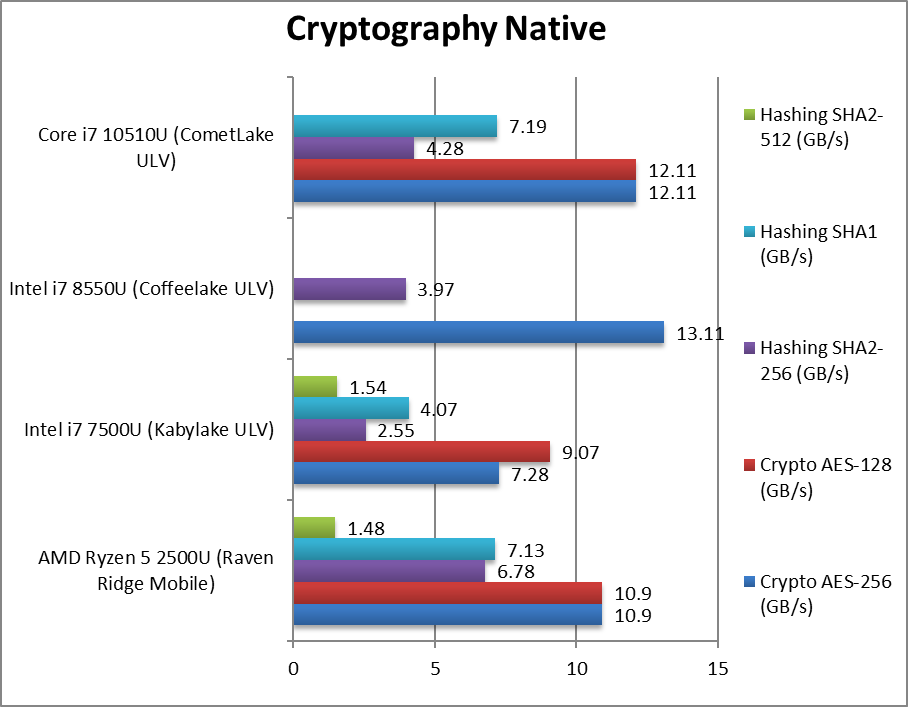 |
||||||
 |
Crypto AES-256 (GB/s) | 10.9 | 7.28 | 13.11 | 12.11 [-8%] | With AES/HWA support all CPUs are memory bandwidth bound. |
|
Crypto AES-128 (GB/s) | 10.9 | 9.07 | 13.11 | 12.11 [-8%] | No change with AES128. |
|
Crypto SHA2-256 (GB/s) | 6.78 | 2.55 | 3.97 | 4.28 [+8%] | Without SHA/HWA Ryzen Mobile beats even CML-U. |
|
Crypto SHA1 (GB/s) | 7.13 | 4.07 | 7.19 | Less compute intensive SHA1 allows CML-U to catch up. | |
|
Crypto SHA2-512 (GB/s) | 1.48 | 1.54 | SHA2-512 is not accelerated by SHA/HWA CML-U does better. | ||
| The memory sub-system is crucial here, and CML-U can improve over older designs when using faster memory (which we were not able to use here). Without SHA/HWA supported by Ryzen Mobile, it cannot beat it and improves marginally over older CFL-U. | ||||||
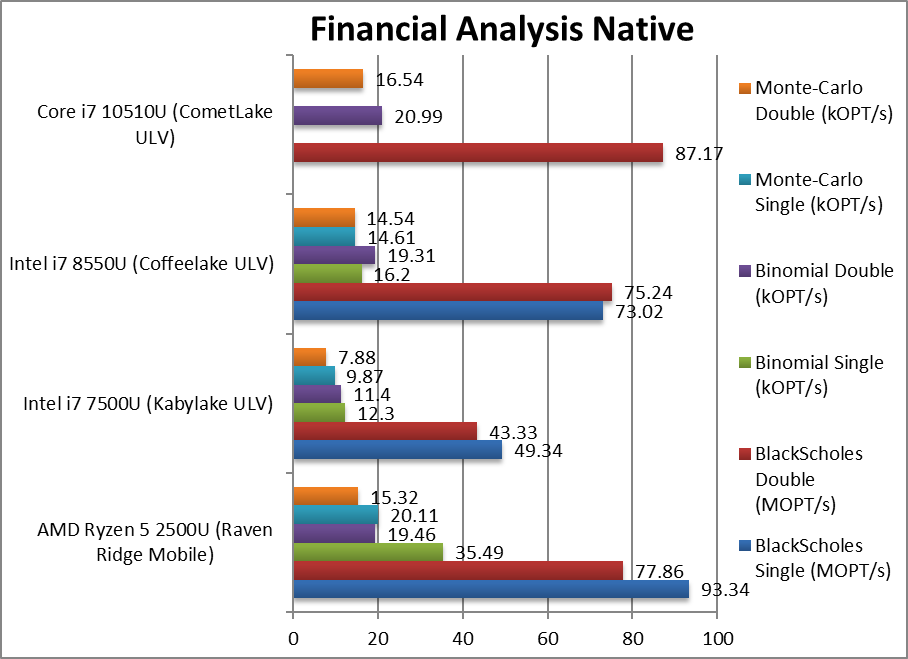 |
||||||
 |
Black-Scholes float/FP32 (MOPT/s) | 93.34 | 49.34 | 73.02 | With non vectorised CML-U needs to cath up. | |
|
Black-Scholes double/FP64 (MOPT/s) | 77.86 | 43.33 | 75.24 | 87.17 [+16%] | Using FP64 CML-U is 16% faster finally beating Ryzen Mobile. |
|
Binomial float/FP32 (kOPT/s) | 35.49 | 12.3 | 16.2 | Binomial uses thread shared data thus stresses the cache & memory system. | |
|
Binomial double/FP64 (kOPT/s) | 19.46 | 11.4 | 19.31 | 20.99 [+9%] | With FP64 code CML-U is 9% faster than CFL-U. |
|
Monte-Carlo float/FP32 (kOPT/s) | 20.11 | 9.87 | 14.61 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches. | |
|
Monte-Carlo double/FP64 (kOPT/s) | 15.32 | 7.88 | 14.54 | 16.54 [+14%] | Switching to FP64 nothing much changes, CML-U is 14% faster. |
| With non-SIMD financial workloads, CML-U modestly improves (10-15%) over the older CFL-U but this does allow it to beat the competition (Ryzen Mobile) which dominated older CFL-U designs. This may just be enough to match future Gen3 Ryzen Mobile and thus be competitive all-round. | ||||||
 |
||||||
 |
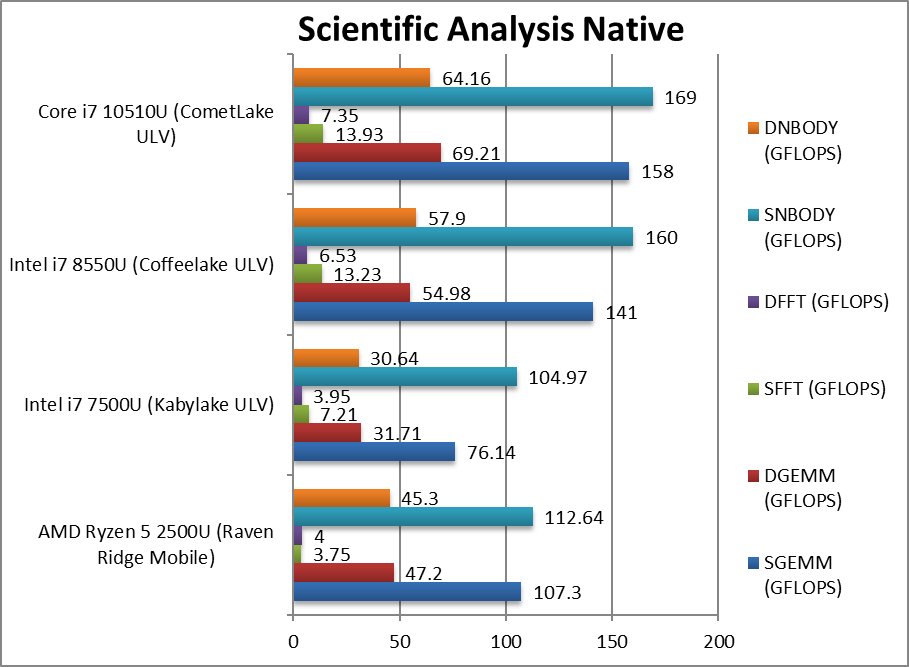
SGEMM (GFLOPS) float/FP32 | 107 | 76.14 | 141 | 158 [+12%] | In this tough vectorised AVX2/FMA algorithm CML-U is 12% faster. |
|
DGEMM (GFLOPS) double/FP64 | 47.2 | 31.71 | 55 | 69.2 [+26%] | With FP64 vectorised code, CML-U is 26% faster than CFL-U. |
|
SFFT (GFLOPS) float/FP32 | 3.75 | 7.21 | 13.23 | 13.93 [+5%] | FFT is also heavily vectorised (x4 AVX2/FMA) but stresses the memory sub-system more. |
|
DFFT (GFLOPS) double/FP64 | 4 | 3.95 | 6.53 | 7.35 [+13%] | With FP64 code, CML-U is 13% faster. |
|
SNBODY (GFLOPS) float/FP32 | 112.6 | 105 | 160 | 169 [+6%] | N-Body simulation is vectorised but with more memory accesses. |
|
DNBODY (GFLOPS) double/FP64 | 45.3 | 30.64 | 57.9 | 64.16 [+11%] | With FP64 code nothing much changes. |
| With highly vectorised SIMD code (scientific workloads) CML-U is again 15-25% faster than CFL-U which should be enough to match future Gen3 Ryzen Mobile with 256-bit SIMD units. Again we need ICL with AVX512 to bring dominance to these workloads or more cores. | ||||||
 |
||||||
 |
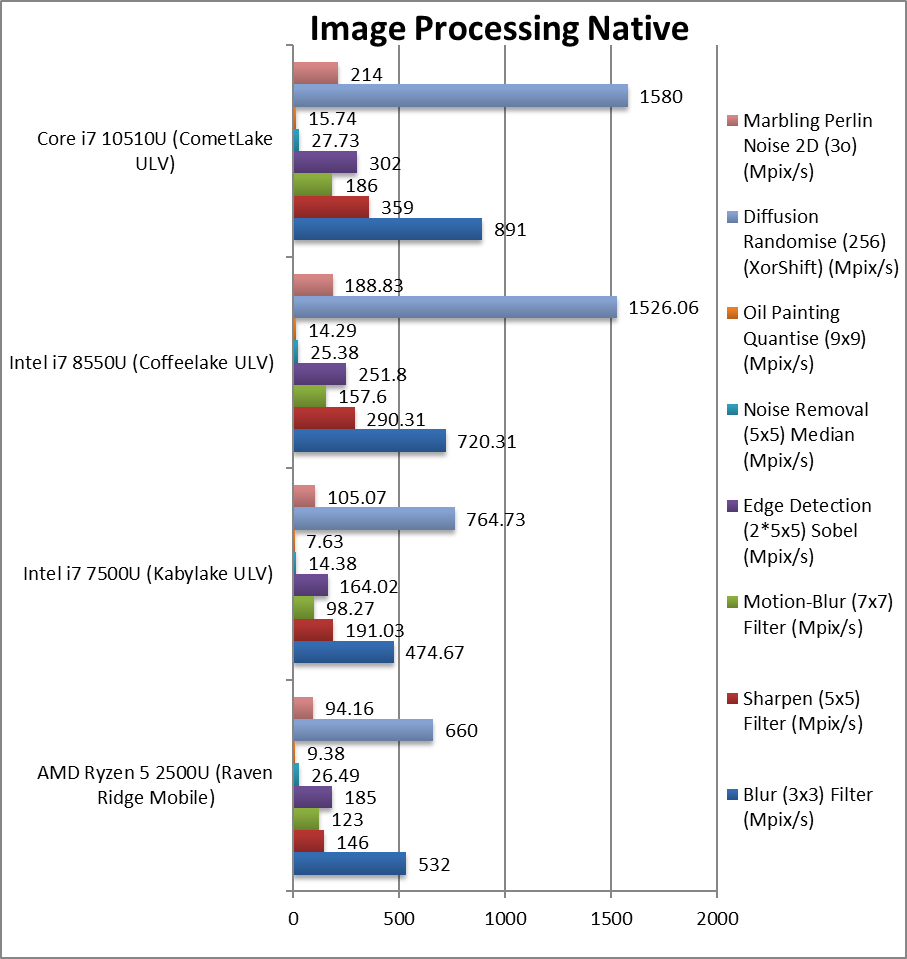
Blur (3×3) Filter (MPix/s) | 532 | 474 | 720 | 891 [+24%] | In this vectorised integer AVX2 workload CML-U is 24% faster. |
|
Sharpen (5×5) Filter (MPix/s) | 146 | 191 | 290 | 359 [+24%] | Same algorithm but more shared data still 24%. |
|
Motion-Blur (7×7) Filter (MPix/s) | 123 | 98.3 | 157 | 186 [+18%] | Again same algorithm but even more data shared reduces improvement to 18%. |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 185 | 164 | 251 | 302 [+20%] | Different algorithm but still AVX2 vectorised workload still 20% faster. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 26.49 | 14.38 | 25.38 | 27.73 [+9%] | Still AVX2 vectorised code but here just 9% faster. |
|
Oil Painting Quantise Filter (MPix/s) | 9.38 | 7.63 | 14.29 | 15.74 [+10%] | Similar improvement here of about 10%. |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 660 | 764 | 1525 | 1580 [+4%] | With integer AVX2 workload, only 4% improvement. |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 94,16 | 105.1 | 188.8 | 214 [+13%] | In this final test again with integer AVX2 workload CML-U is 13% faster. |
Without any new instruction sets (AVX512, SHA/HWA, etc.) support, CML-U was never going to be a revolution in performance and has to rely on clock and very minor improvements/fixes (especially for vulnerabilities) only. Versions with more cores (6C/12T) would certainly help if they can stay within the power limits (TDP/turbo).
Intel themselves did not claim a big performance improvement – still CML-U is 10-25% faster than CFL-U across workloads – at same TDP. At the same cost/power, it is a welcome improvement and it does allow it to beat current competition (Ryzen Mobile) which was nipping at its heels; it may also be enough to match future Gen3 Ryzen Mobile designs.
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
For some it may be disappointing we do not have brand-new improved “IceLake” (ICL-U) now rather than a 3-rd revision “Skylake” – but “CometLake” (CML-U) does seem to improve even over the previous revisions (8/9th gen “WhiskyLake”/”CofeeLake” WHL/CFL-U) while due to 2x core count completly outperforming the original (6/7th gen “Skylake”/”KabyLake”) in the same power envelope. Perhaps it also shows how much Intel has had to improve at short notice due to Ryzen Mobile APUs (e.g. 2500U) that finally brought competition to the mobile space.
While owners of 8/9-th gen won’t be upgrading – it is very rare to recommend changing from one generation to another anyway – owners of older hardware can look forward to over 2x performance increase in most workloads for the same power draw, not to mention the additional features (integrated WiFi6, Thunderbolt, etc.).
On the other hand, the competition (AMD Ryzen Mobile) also good performance and older 8/9th gen also offer competitive performance – thus it will all depend on price. With Gen3 Ryzen Mobile on the horizon (with 256-bit SIMD units) “CometLake” may just manage to match it on performance. It may also be worth waiting for “IceLake” to make its debut to see what performance improvements it brings and at what cost – which may also push “CometLake” prices down.
All in all Intel has managed to “squeeze” all it can from the old Skylake arch that while not revolutionary, still has enough to be competitive with current designs – and with future 50% increase core count (6C/12T from 4C/8T) might even beat them not just in cost but also in performance.
In a word: Qualified Recommendation!
Please see our other articles on: