What is “DG1” / “Iris Xe”?
It is the gen(eration) 12 graphics introduced with the “TigerLake” (TGL) mobile APUs and will also feature on “RocketLake” (RKL) desktop APUs – but will also be launched as discrete GPU for laptops and even desktops as an add-in card. In effect, Intel is re-entering the discrete graphics market – if we discount “Phi” / “Larabee” GP-GPUs – would be the ancient 740 Graphics accelerator of 1998!
While integrated Intel graphics have stagnated for a long time (e.g. EV7 / “Skylake”) – since “IceLake” Intel has made great strides, first with Gen11 and then with Gen12 / Xe that have (finally) brought big changes:
- 10nm++ process (lower voltage, higher performance benefits)
- Gen12 (Xe-LP) graphics 80 EU (96 EU as here Xe Max)
- LP-DDR4X generally used now up to 4266Mt/s, 128-bit (~66GB/s bandwidth)
- New Image Processing Unit (IPU6) up to 4K90 resolution
- New 2x Media Encoders HEVC 4K60-10b 4:4:4 & 8K30-10b 4:2:0
- PCIe 4.0 (up to 8GB/s with x4 lanes)
While discrete desktop DG1 (and laptop Iris Xe Max Gen12) GPU unit is the same as the integrated part – being discrete it does behave a bit differently:
- It can be clocked higher (1.65GHz) as it has its own 15W (laptop)/25W (desktop) power budget
- Dedicated LP-DDR4X memory and thus bandwidth but no zero-copy data transfers
- Data upload/download through PCIe4 x4 (PCIe3 with current systems)
- Possible fanless due to low-power (25-30W TDP), single-slot
In terms of support, everything is the same, sadly no FP64 which competing low-end discrete graphics do support. FP16 rate is 2x FP32 though and more likely to be used. Int32, Int16 performance has reportedly doubled with Int8 now supported and DP4A accelerated.
GP-GPU DG1 (Iris Xe Max Gen12) Performance Benchmarking
In this article we test GPGPU core performance; please see our other articles on:
- CPU
- Intel Core Gen 11 RocketLake (i7-11700K) Review & Benchmarks – AVX512 Performance
- Intel Core Gen11 TigerLake ULV (i7-1165G7) Review & Benchmarks – CPU AVX512 Performance
- Benchmarks of JCC Erratum Mitigation – Intel CPUs
- Intel Core Gen10 IceLake ULV (i7-1065G7) Review & Benchmarks – CPU AVX512 Performance
- AVX512 Improvement for Icelake Mobile (i7-1065G7 ULV)
- GPGPU
Hardware Specifications
We are comparing the middle-range Intel integrated GP-GPUs with previous generation, as well as competing architectures with a view to upgrading to a brand-new, high performance, design.
| GP-GPU |
Intel DG1 (Discrete, Iris Xe Max, 96C) | Intel Iris Xe-LP (Internal, 1165G7, 96C) | Intel Iris Plus LP (Internal, 1065G7, 64C) | nVidia GeForce GT 1030 (Discrete, GP108, 3C) |
Comments | |
| Arch / Chipset | EV12 / DG1 | EV12 / G7 (built-in “TigerLake”) | EV11 / G7 (built-in “IceLake”) | GP108-300 “Pascal” | Same GPU as TGL | |
| Cores (CU) / Threads (SP) | 96 / 768 | 96 / 768 | 64 / 512 | 3 / 384 | Same no. of CU / SP | |
| Tensors (TSX) / Matrix Units (MMA) |
none | none | none | none on Pascal | Sadly no TSX/MMA units | |
| SIMD per CU / Width | 8 | 8 | 8 | 128 | Same SIMD width | |
| Wave/Warp Size | 32 | 32 | 32 | 32 | Wave size matches nVidia | |
| Speed (Base/Turbo) (GHz) |
1.65GHz [+38%] |
1.2GHz | 1.1GHz | 1.227-1.468GHz | Turbo is 38% faster. | |
| Power (TDP) | 25-30W (Dedicated) | 15-25W (Shared) | 15-25W (Shared) | 30W (Dedicated) | Similar power envelope. | |
| ROP / TMU | 24 / 48 | 24 / 48 | 16 / 32 | 8 / 24 | Same no. ROP / TMUs | |
| Shared Memory (kB) |
64kB |
64kB | 64kB | 32kB | Same shared memory but 2x nVidia. | |
| Constant Memory (GB) |
1.6GB | 3.2GB | 2.7GB | 64kB | No dedicated constant memory but large. | |
| Global Memory Size (GB) | 4GB (Dedicated) |
(Shared) ~50% system memory | (Shared) ~50% system memory | 2GB (Dedicated) | Somewhat small memory. | |
| Global Memory Type | LP-DDR4X 128-bit 4267Mt/s [+14%] |
(Shared) LP-DDR4X 128-bit 4267Mt/s | (Shared) LP-DDR4X 128-bit 3733Mt/s | GDDR5 64-bit 6000Mt/s | Memory rate is 14% faster. | |
| Memory Bandwidth (GB/s) |
66GB/s [=] | (Shared) 66GB/s | (Shared) 58GB/s | 48GB/s | Same bandwidth but dedicated. | |
| L1 Caches | 64kB x 6 | 64kB x 6 | 16kB x 8 | 16kB x3 | Same L1 | |
| L3 Cache | 3.8MB | 3.8MB | 3MB | 512kB | Same L3 | |
| Maximum Work-group Size |
256×256 | 256×256 | 256×256 | 1024×1024 | nVidia supports bigger workgroups | |
| FP64/double ratio |
No! | No! | No! | Yes, 1/64x | No FP64 support | |
| FP16/half ratio |
2x | 2x | 2x | 2x | Same 2x ratio | |
| OpenCL Suppport |
3.0 | 3.0 | 2.1 | 1.2 | Intel is up to 3.0 while nVidia still on 1.2! | |
| Price/RRP (USD) |
Unknown, possibly $70 | $426 (whole APU) | $426 (whole APU) | $80 (at launch, more now due to pandemic) | We will need to see OEM card price | |
Disclaimer
This is an independent article that has not been endorsed or sponsored by any entity (e.g. Intel). All trademarks acknowledged and used for identification only under fair use. Errors and omissions excepted (E&OE).
The article contains only public information (available elsewhere on the Internet) and not provided under NDA nor embargoed. At publication time, the products have not been directly tested by SiSoftware and thus the accuracy of the benchmark scores cannot be verified; however, they appear consistent and do not appear to be false/fake.
Processing Performance
We are testing both OpenCL performance using the latest SDK / libraries / drivers from both Intel and competition.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest Intel and nVidia drivers. Turbo / Boost was enabled on all configurations.
| Processing Benchmarks | Intel DG1 (Discrete, Iris Xe Max, 96C) | Intel Iris Xe-LP (Internal, 1165G7, 96C) | Intel Iris Plus LP (Internal, 1065G7, 64C) | nVidia GeForce GT 1030 (Discrete, GP108, 3C) | Comments | |
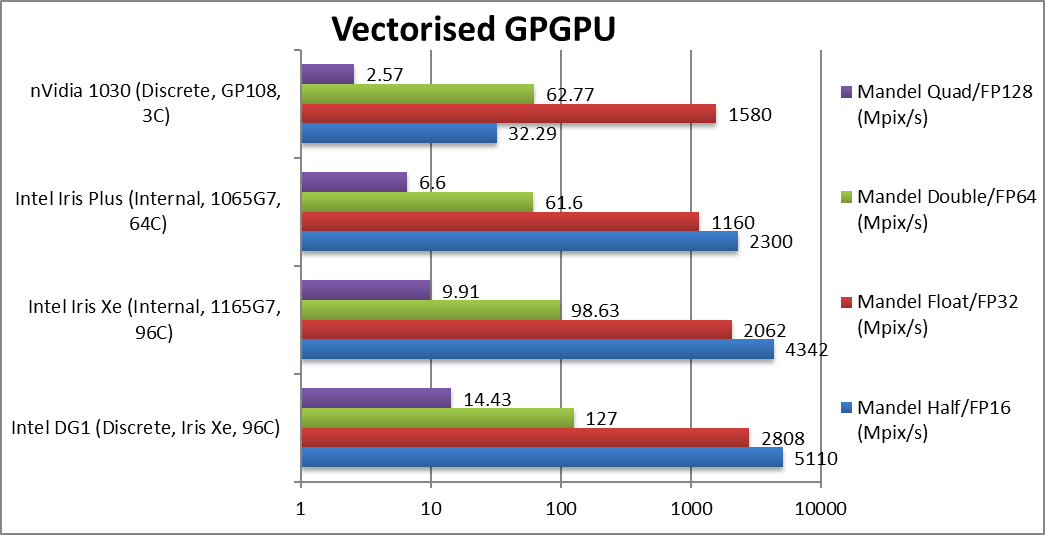 |
||||||
 |
Mandel FP16/Half (Mpix/s) | 5,110 [+18%] | 4,342 | 2,300 | 32.29** | DG1 is 18% faster and demolishes nVidia. |
|
Mandel FP32/Single (Mpix/s) | 2,808 [+36%] | 2,062 | 1,160 | 1,580 | Standard FP32 is 36% faster on DG1. |
|
Mandel FP64/Double (Mpix/s) | 127* [+29%] | 98.63 | 61.6 | 62.77 | Even without FP64, DG1 rules. |
|
Mandel FP128/Quad (Mpix/s) | 14.43* [+46%] | 9.91 | 6.6 | 2.57 | Emulated FP128 is 46% faster. |
| Starting off, DG1 is 18-46% faster than integrated Xe and even without FP64 it easily beats the 1030 pretty much into dust (2x faster). It shows just how much Intel GPUs have improved, the 1030 is still very much popular choice. Interesting that DG1 emulating FP64 through FP32 (1/22x FP32 rate) is way faster than native FP64 1030 (1/32x FP32 rate)!
Note*: Emulated FP64 through FP32 as no dedicated support. Note**: Using CUDA not OpenCL as no dedicated FP16 support in driver. |
||||||
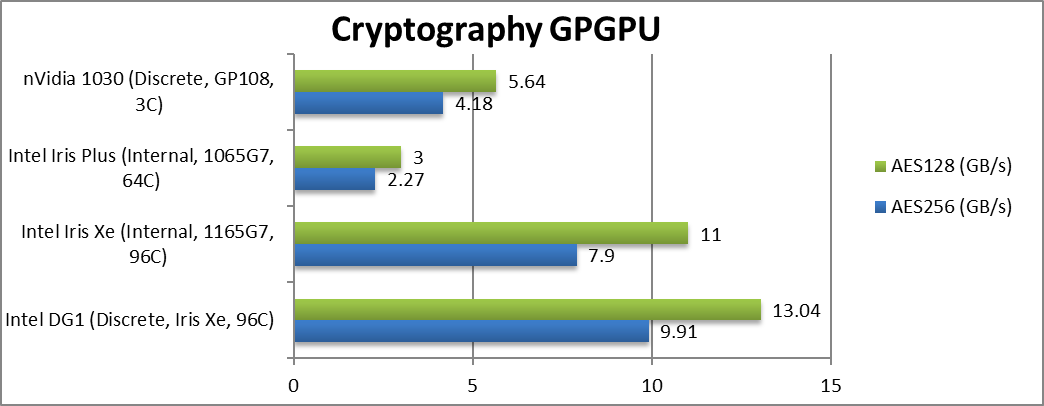 |
||||||
 |
Crypto AES-256 (GB/s) | 9.91 [+25%] | 7.9 | 2.27 | 4.18 | Streaming DG1 is 25% faster than Xe. |
|
Crypto AES-128 (GB/s) | 13.04 [+19%] | 11 | 3 | 5.64 | DG1 gets even faster here. |
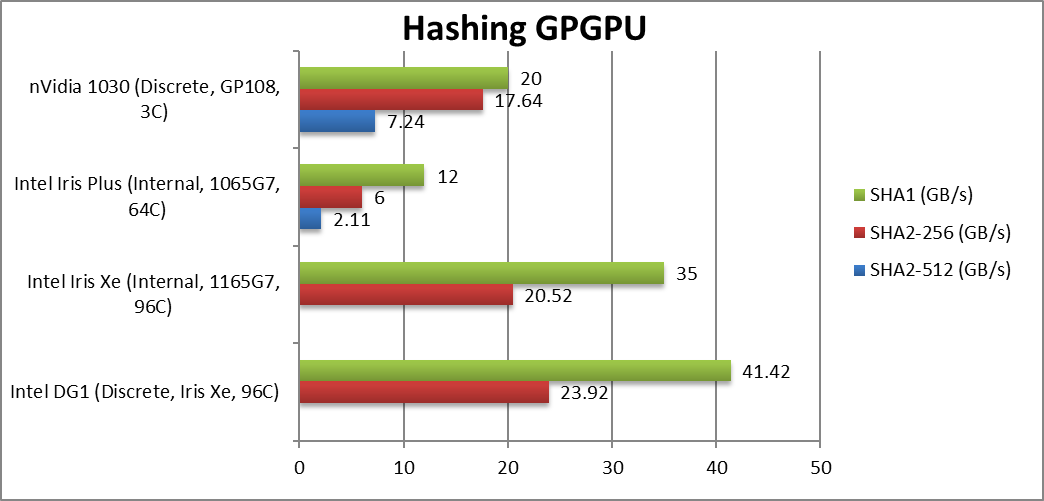 |
||||||
|
Crypto SHA2-256 (GB/s) | 23.92 [+17%] | 20.52 | 6 | 17.64 | DG1 is 17% faster in this integer compute test. |
|
Crypto SHA1 (GB/s) | 41.42 [+18%] | 35 | 12 | 20 | With 128-bit DG1 is even faster. |
|
Crypto SHA2-512 (GB/s) | 2.11 | 7.24 | 64-bit integer workload is also great. | ||
| With faster, dedicated memory – DG1 is 17-25% faster in memory streaming algorithms like crypto while faster clock helps in heavy compute (integer) tasks. Again, DG1 has no problem beating the 1030, generally being 2x faster across crypto tests. While the crypto currency frenzy has died out, DG1 is a pretty good low-power “crypto-cracker” GP-GPU. | ||||||
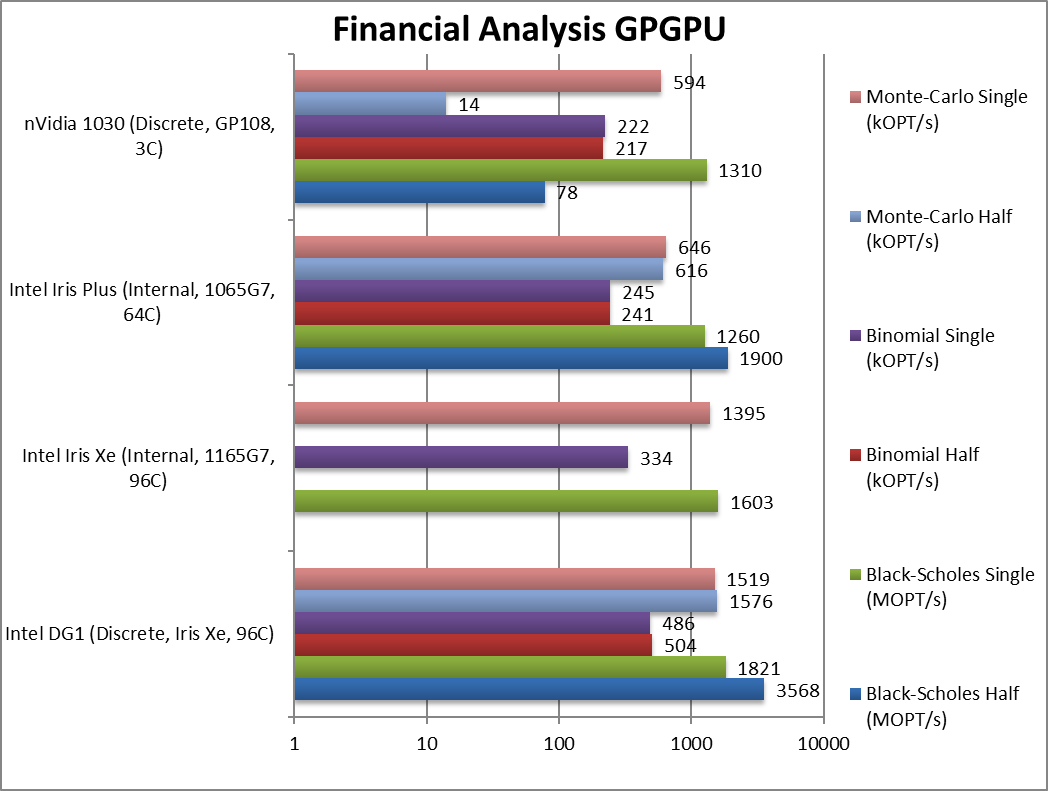 |
||||||
 |
Black-Scholes float/FP16 (MOPT/s) | 3,568 | 1,900 | 78* | FP16 is a massive 95% faster. | |
|
Black-Scholes float/FP32 (MOPT/s) | 1,821 [+14%] | 1,603 | 1,260 | 1,310 | DG1 starts with 14% improvement. |
|
Binomial half/FP16 (kOPT/s) | 504 | 241 | 217* | Just 3% improvement for FP16. | |
|
Binomial float/FP32 (kOPT/s) | 486 [+46%] | 334 | 245 | 222 | Binomial uses thread shared data thus stresses the memory system. |
|
Monte-Carlo half/FP16 (kOPT/s) | 1,576 | 616 | 14* | No improvement for FP16. | |
|
Monte-Carlo float/FP32 (kOPT/s) | 1,519 [+9%] | 1,395 | 646 | 594 | Monte-Carlo also uses thread shared data but read-only. |
| For financial workloads, DG1 is 9-46% faster than Xe-LP – still a good result; FP16 cannot always improve as plenty of data (e.g. accumulators, some precision functions) needs to remain FP32 but some algorithms improve by 2x. Unfortunately lack of FP64 support may prevent some precision algorithms to run at all – and here the 1030 though slow may have its uses.
Note*: Using CUDA not OpenCL as no dedicated FP16 support in driver. |
||||||
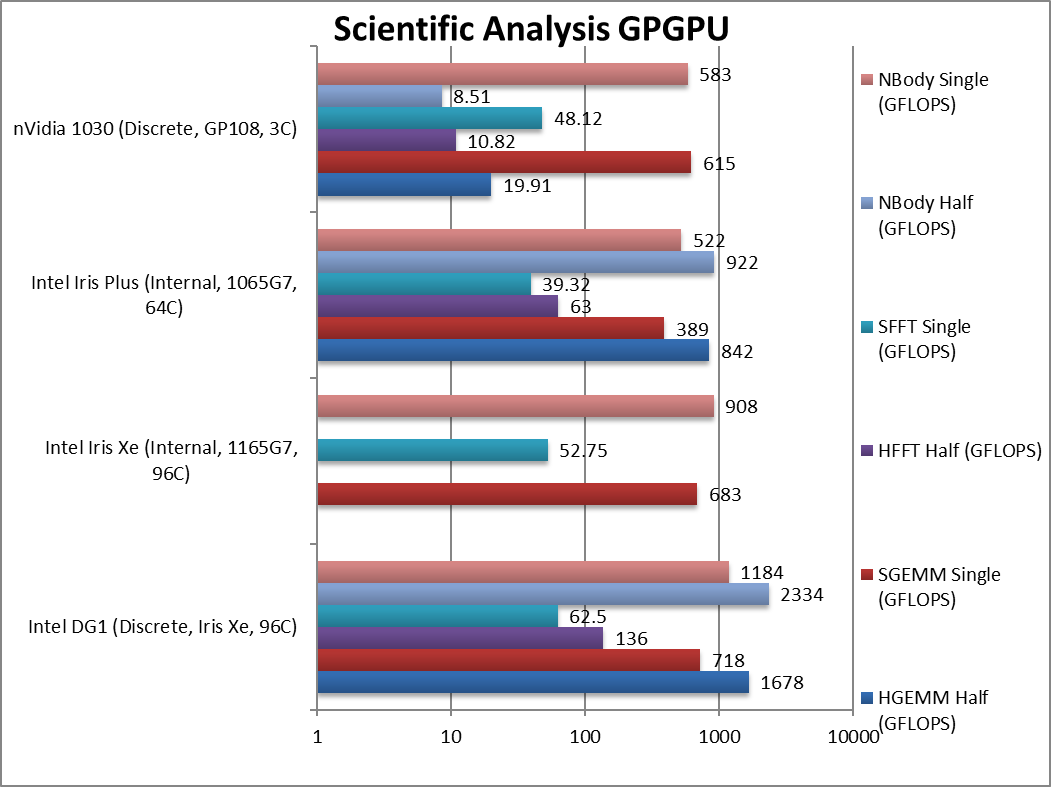 |
||||||
 |
HGEMM (GFLOPS) float/FP16 | 1,678 | 842 | 19.91* | FP16 is over 2.33x faster than FP32! | |
|
SGEMM (GFLOPS) float/FP32 | 718 [+5%] | 683 | 389 | 615 | Matrix multiplication is common, DG1 is 5% faster. |
|
HFFT (GFLOPS) float/FP16 | 136 | 63 | 10.82* | FP16 is again over 2x faster. | |
|
SFFT (GFLOPS) float/FP32 | 62.5 [+18%] | 52.75 | 39.32 | 48.12 | FFT is also used everywhere, DG1 is 18% faster. |
|
HNBODY (GFLOPS) float/FP16 | 2,334 | 922 | 8.51* | All Intel GPUs do well here. | |
|
SNBODY (GFLOPS) float/FP32 | 1,184 [+30%] | 908 | 522 | 583 | N-Body improves by a decent 30%. |
| With common scientific algorithms used everywhere (GEMM, FFT, etc.) DG1 only improves by 5-30% but switching to FP16 generally doubles performance (2x) or more. Naturally at this low-level we don’t have tensors. Unfortunately due to FP64 native support some precision scientific kernels will not run – unless through FP32 emulation (as we do with fractals).
Note*: Using CUDA not OpenCL as no dedicated FP16 support in driver. |
||||||
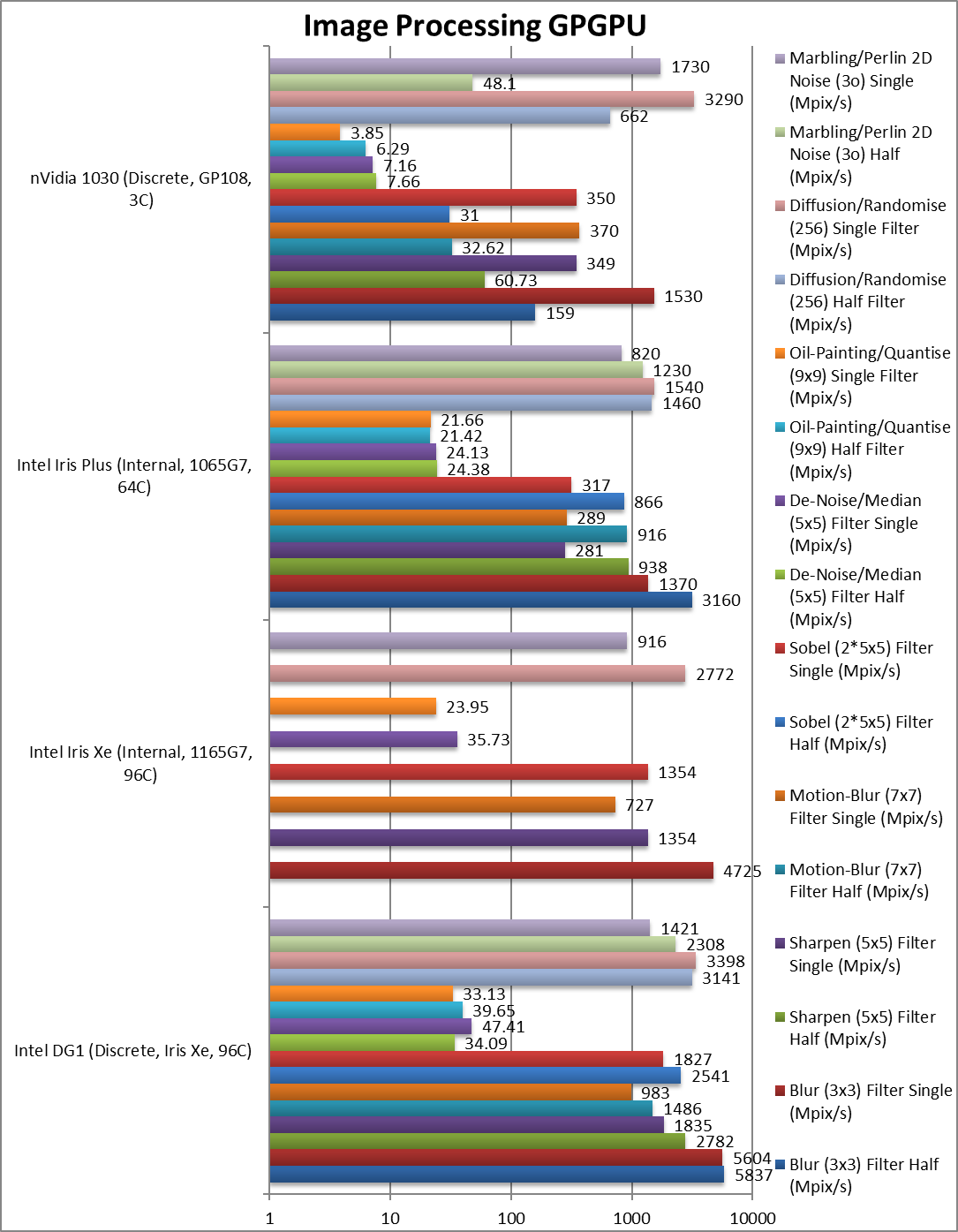 |
||||||
 |
Blur (3×3) Filter single/FP16 (MPix/s) | 5,837 | 3,160 | 159* | FP16 is just 4% faster over FP32 | |
|
Blur (3×3) Filter single/FP32 (MPix/s) | 5,604 [+19%] | 4,725 | 1,370 | 1,530 | In this 3×3 convolution algorithm, DG1 is 19% faster |
|
Sharpen (5×5) Filter single/FP16 (MPix/s) | 2,782 | 938 | 60.73* | FP16 improves by 51%. | |
|
Sharpen (5×5) Filter single/FP32 (MPix/s) | 1,835 [+36%] | 1,354 | 281 | 349 | Same algorithm but more shared data, DG1 is up 36% |
|
Motion Blur (7×7) Filter single/FP16 (MPix/s) | 1,486 | 916 | 32.62* | Again FP16 is up 51%. | |
|
Motion Blur (7×7) Filter single/FP32 (MPix/s) | 983 [+35%] | 727 | 289 | 370 | With even more data DG1 is still 35% faster |
|
Edge Detection (2*5×5) Sobel Filter single/FP16 (MPix/s) | 2,541 | 866 | 31* | FP16 brings 39% improvement | |
|
Edge Detection (2*5×5) Sobel Filter single/FP32 (MPix/s) | 1,827 [+35%] | 1,354 | 317 | 350 | Still convolution but with 2 filters – still 35% faster |
|
Noise Removal (5×5) Median Filter single/FP16 (MPix/s) | 34.09 | 24.38 | 7.66* | Somehow we end up slower using FP16 | |
|
Noise Removal (5×5) Median Filter single/FP32 (MPix/s) | 47.41 [+33%] | 35.73 | 24.13 | 7.16 | Different algorithm DG1 still 33% faster. |
|
Oil Painting Quantise Filter single/FP16 (MPix/s) | 39.65 | 21.42 | 6.29* | FP16 is just 17% faster. | |
|
Oil Painting Quantise Filter single/FP32 (MPix/s) | 33.13 [+38%] | 23.95 | 21.66 | 3.85 | Without major processing, DG1 is 38% faster. |
|
Diffusion Randomise (XorShift) Filter single/FP16 (MPix/s) | 3,141 | 1,460 | 662* | Again, we see FP16 slower than FP32. | |
|
Diffusion Randomise (XorShift) Filter single/FP32 (MPix/s) | 3,398 [+23%] | 2,772 | 1,540 | 3,290 | This algorithm is 64-bit integer heavy DG1 is 23% faster. |
|
Marbling Perlin Noise 2D Filter single/FP16 (MPix/s) | 2,308 | 1,230 | 48.1* | FP16 sees a massive 62% improvement. | |
|
Marbling Perlin Noise 2D Filter single/FP32 (MPix/s) | 1,421 [+55%] | 916 | 820 | 1,730 | One of the most complex and largest filters, DG1 is again 55% faster. |
| For image processing tasks, DG1 improves anywhere between 19-62% over normal Xe-LP that is already very much faster than 1030. Switching to FP16 we usually see a 50% improvement (not 2x) that demolishes the crippled FP16 (CUDA) performance of 1030. Fortunately you don’t need FP64 for image processing tasks.
Note*: Using CUDA not OpenCL as no dedicated FP16 support in driver. |
||||||
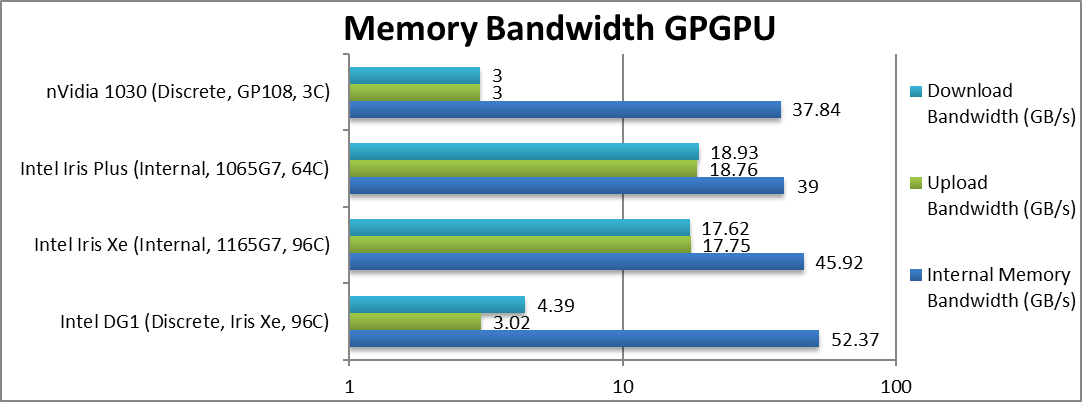 |
||||||
 |
Internal Memory Bandwidth (GB/s) | 52.37 [+14%] | 45.92 | 39 | 37.84 | DG1 has 14% more bandwidth than Xe. |
|
Upload Bandwidth (GB/s) | 3.02* [-80%] | 17.75 | 18.76 | 3* | Uploads are 1/5 of Xe. |
|
Download Bandwidth (GB/s) | 4.39* [-75%] | 17.62 | 18.93 | 3* | Download bandwidth are 1/4 of Xe |
| Thanks to the faster, dedicated LP-DDR4X memory, DG1 has a 14% bandwidth gain over the integrated Xe. However, due to the PCIe3 x4 connection upload/download is slow – thus needs to be overlapped with compute to prevent bottlenecks. But it also supports PCIe4 for the future.
Note*: PCIe3 x4 connection – not integrated. (DG1 supports PCIe4 but not used here) |
||||||
| Overall Benchmarks | Intel DG1 (Discrete, Iris Xe, 96C) | Intel Iris Xe (Internal, 1165G7, 96C) | Intel Iris Plus (Internal, 1065G7, 64C) | nVidia GeForce GT 1030 (Discrete, GP108, 3C) | Comments | |
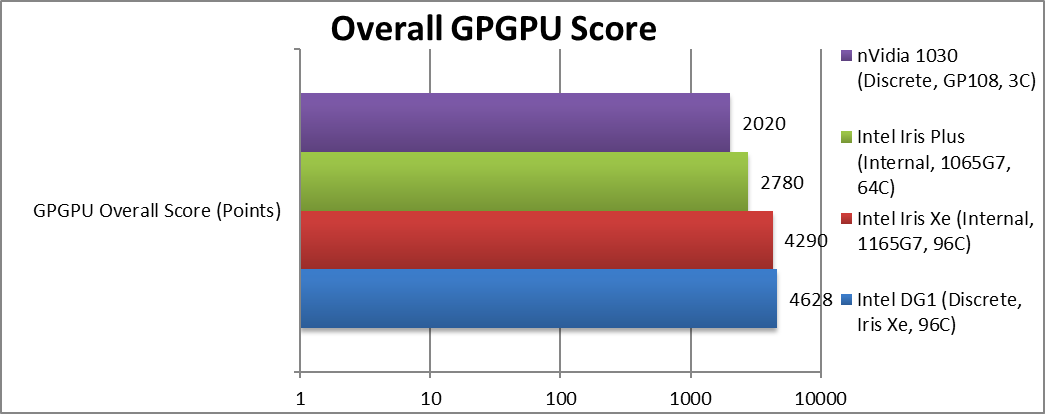 |
||||||
 |
Overall GP-GPU Score | 4,628 [+7%] |
4,290 | 2,780 | 2,020* | DG1 is 7% faster overall. |
| Despite the dedicated resources (memory and power) – being discrete – DG1 is only about 7% faster than the integrated version in TGL. It’s early days and likely lots of optimisations still outstanding to best take advantage of the available resources. It is much faster (2.3x) than nVidia’s 1030. | ||||||
 |
||||||
 |
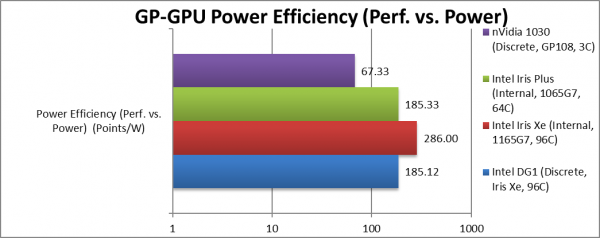
Power Efficiency (Performance vs. Power) | 185 |
286* | 185* | 67.33 | 2.6x “bang for buck” than competition. |
| Since the integrated prices include “the whole laptop” – we can only compare the DG1 with the 1030 directly: here DG1 gives you over 2.5x more “bang-for-buck” than the 1030 – which in these times is extremely important. Let’s hope the price is as rumoured.
Note*: integrated version includes whole laptop price thus not directly comparable with dedicated version price. |
||||||
 |
||||||
 |
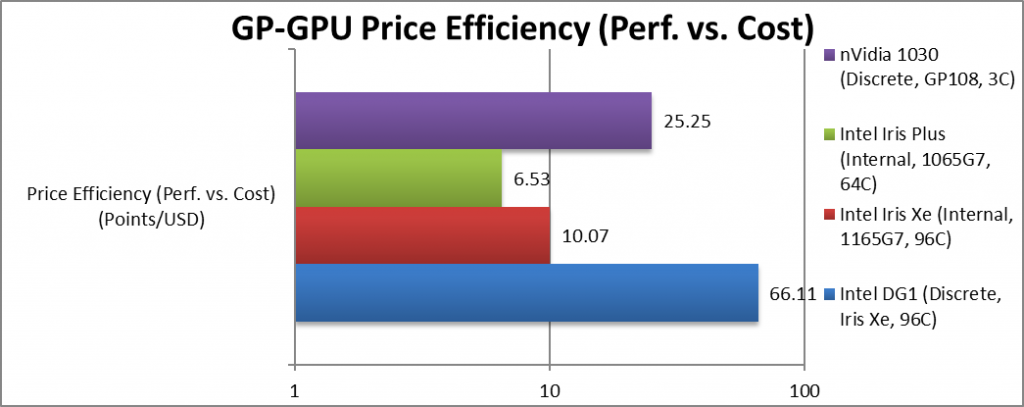
Price Efficiency (Performance vs. Cost) | 66.11 [+2.6x] |
10.07* | 6.53* | 25.25 | 2.6x “bang for buck” than competition. |
| Since the integrated prices include “the whole laptop” – we can only compare the DG1 with the 1030 directly: here DG1 gives you over 2.5x more “bang-for-buck” than the 1030 – which in these times is extremely important. Let’s hope the price is as rumoured.
Note*: integrated version includes whole laptop price thus not directly comparable with dedicated version price. |
||||||
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
Executive Summary: Intel DG1 Xe is a great low-end dedicated GPU. Good Performance, 8/10!
Intel seems to have started to take graphics (GP-GPUs today) seriously: DG1 packs some serious power at the low-end just as we’ve seen when testing “TigerLake” (TGL). Overall, it is 8% faster than integrated Xe-LP of TGL but sometimes as much as 50% in some tests and likely to get faster with future drivers.
Like all low-end dedicated GPUs (even the 1030) the PCIe3 x4 connection makes data uploads/downloads slow – thus judicious use of overlapping compute and transfers is needed to prevent bottlenecks. But DG1 supports PCIe4 – thus future Intel systems (“RocketLake”) that bring PCIe4 support will double transfers which should alleviate the problem.
Lack of native FP64 support is disappointing but likely not useful on low-end GP-GPUs like these; at 1/32x rate on 1030 it is very slow. FP16 rate at 2x is almost 2x faster than FP32 and light-years over the crippled 1/64x rate on 1030. We do hope that future (higher-end) versions will have native FP64 support though that would come in handy for financial workloads and precision modelling.
For HTPC, media/NAS servers (including virtualised), DG1 will make a good choice – e.g. instead of the GT 1030, Quadro NVS – as the Intel drivers are just as reliable as nVidia across operating systems. We’re not taking AAA games here, we’re talking normal desktop/server graphics and media transcoding.
The decoding/encoding/transcoding (QuickSync) supports all the modern features (HEVC/H265, AV1, etc.) and is widely supported – making it ideal upgrade for older systems (e.g. SKL/KBL/WHL/CML) using EV9x or even older graphics. Due to low-power (25W, TDP-down to 15W), DG1 would also make an ideal fanless/quiet card, hopefully low-profile single-slot for those ITX HTPC media clients or servers.
The rumoured price (OEM) is also extremely competitive – especially considering the competition where prices if anything have gone up. This makes DG1 over 2.5x more “price efficient” than say the 1030 we compared it against – a bargain.
Competition, even at low-end, is always welcome and should you find DG1 is not for you – it will at least force competitors (e.g. AMD, nVidia) to release updated dedicated low-end GPUs for those that need them. At the moment the choices (like the 1030) are relatively expensive for what you are getting and DG1 will certainly improve choices.
Please see our other articles on:
- Intel Iris Plus G7 Gen11 IceLake ULV (i7-1065G7) Review & Benchmarks – GPGPU Performance
- Intel Core Gen10 IceLake ULV (i7-1065G7) Review & Benchmarks – CPU AVX512 Performance
Disclaimer
This is an independent article that has not been endorsed or sponsored by any entity (e.g. Intel). All trademarks acknowledged and used for identification only under fair use. Errors and omissions excepted (E&OE).
The article contains only public information (available elsewhere on the Internet) and not provided under NDA nor embargoed. At publication time, the products have not been directly tested by SiSoftware and thus the accuracy of the benchmark scores cannot be verified; however, they appear consistent and do not appear to be false/fake.