What is “Navi2”?
It is the code-name of the new AMD GPU, the 2nd generation RDNA (Radeon DNA) GPU arch(itecture) that itself replaced “Vega” / last of the GCN arch(itecture). Unlike the original Navi that was a mid-range GPU – this is the very much expected “big Navi” top-end GPU designed to battle nVidia’s finest 3000-series GPUs.
Navi/RDNA arch brought big changes from Vega/GCN and Navi2 has been enhanced and optimised from Navi1 adding more features:
- Ray-Tracing (RT) Cores – similar to nVidia’s Turing/Ampere cards
- Infinity Cache – 128MB
- Smart-Access Memory – PCIe BAR re-sizeing
- 6800 has Navi21 XL mid-range chip with 2/3 CUs enabled (60 out of 80)
Unlike Vega1/2 GPUs that perhaps were very much compute focused – Navi1/2 seem to be more gaming focused with the few compute features already introduced: reduced workgroup size matching nVidia (32), increased work-group sizes (1024). It is likely that AMD will launch HBM2 professional cards and hopefully Navi versions with tensor units (TSX) or matrix multiplicators (tuMMA).
See these other articles on GP-GPU performance:
- ExtremeTech
- SiSoftware
Hardware Specifications
We are comparing the mid-range Radeon with previous generation cards and competing architectures with a view to upgrading to a mid-range high performance design. We have included the top-end previous generation cards that may be cheaper to obtain today.
| GP-GPU Specifications | AMD Radeon RX 6800 (Navi2L) | AMD Radeon 5700XT (Navi1) | nVidia 3070 (Ampere) | nVidia 2080TI (Turing) | Comments | |
| Arch / Chipset | RDNA2 / Navi 21 XL | RDNA1 / Navi 10 | Ampere / GA104 / SM8.6 | Turing / GT102 / SM7.5 | The 2nd of the Navi cores | |
| Cores (CU) / Threads (SP) | 60 / 3840 [+50%] |
40 / 2,560 | 46 / 5,888 | 68 / 4,352 | The XL version has 50% more cores. | |
| Wave/Warp Size | 32 | 32 | 32 | 32 | Wave size now matches nVidia. | |
| Speed (Min-Turbo) (GHz) |
1.7 (1.815) |
1.6 (1.755) | 1.5 (.725) | 1.35 (1.635) | 40% faster base and 20% turbo than Vega1. | |
| Power (TDP) | 250W [+11%] | 225W | 220W | 260W | Power has only increased by 33% | |
| ROP / TMU | 96 / 240 [+50%] |
64 / 160 | 96 / 184 | 88 / 272 | ROPs are the same but we see ~30% less TMUs. | |
| Ray-Tracing (RT) |
60 | none | 82 | 68 | Navi2 brings 60 RT cores like nVidia. | |
| Shared Memory (kB) |
64kB | 64kB | 48kB / 96kB per SM | 48kB / 96kB per SM | No change in shared memory. | |
| Constant Memory (GB) |
8GB [+2x] | 4GB | 64kB dedicated | 64kB dedicated | No dedicated constant memory but large. | |
| Global Memory (GB) |
16GB GDDR6 16Gbps 256-bit | 8GB GDDR6 14Gbps 256-bit | 8GB GDDR6 14Gbps 256-bit | 11GB GDDR6 14Gbps 320-bit | No HBM at this level. | |
| Memory Bandwidth (GB/s) |
512GB/s [+14%] | 448GB/s | 448GB/s | 616GB/s | Still bandwidth is 9% higher. | |
| L1 Caches (kB) |
32kB / WG + 128kB/Array | 64kB/Array | 46x 128kB/SM | 68x 96kB/SM | L1 has been doubled (2x) | |
| L2 Cache (MB) |
4MB | 4MB | 4MB | 5.5MB | L2 has not changed. | |
| Maximum Work-group Size |
1024 / 1024 | 1024 / 1024 | 1024 / 2048 per SM | 1024 / 2048 per SM | AMD has unlocked work-group sizes to 4x. | |
| FP64/double ratio |
1/16x | 1/16x | 1/32x | 1/32x | Ratio is 2x nVidia. | |
| FP16/half ratio |
2x | 2x | 2x | 2x | Ratios are the same throughput. | |
| Price/RRP (USD) |
579 [+29%] | 450 | 499 | 1,000 | Price is 30% higher than Navi1. | |

AMD Radeon 6900 XT
Disclaimer
This is an independent article that has not been endorsed nor sponsored by any entity (e.g. AMD). All trademarks acknowledged and used for identification only under fair use.
The article contains only public information (available elsewhere on the Internet) and not provided under NDA nor embargoed. At publication time, the products have not been directly tested by SiSoftware and thus the accuracy of the benchmark scores cannot be verified; however, they appear consistent and do not appear to be false/fake.
Processing Performance
We are testing both OpenCL performance using the latest SDK / libraries / drivers from both AMD and competition.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and nVidia drivers. Turbo / Boost was enabled on all configurations.
| Processing Benchmarks | AMD Radeon RX 6800 (Navi2L) | AMD Radeon 5700XT (Navi1) | nVidia 3070 (Ampere) | nVidia 2080TI (Turing) | Comments | |
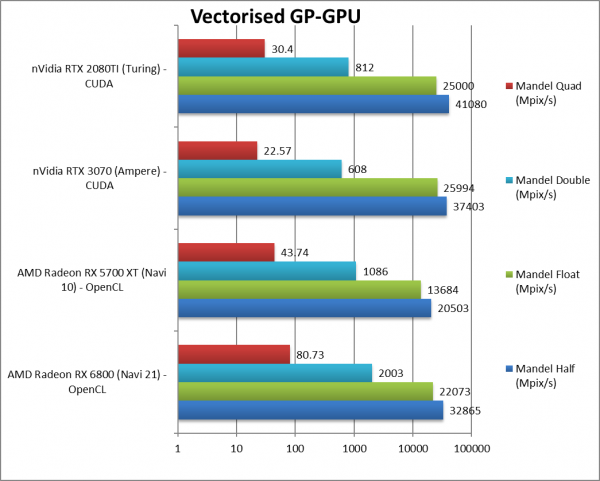 |
||||||
 |
Mandel FP16/Half (Mpix/s) | 32,865 [+60%] | 20,503 | 37,403 | 41,080 | Navi2L is still 60% faster than top Navi1. |
|
Mandel FP32/Single (Mpix/s) | 22,073 [+61%] | 13,684 | 25,994 | 25,000 | Standard FP32 is again 60% faster. |
|
Mandel FP64/Double (Mpix/s) | 2003 [+84%] |
1,086 | 608 | 812 | FP64 is 84% than Navi1. |
|
Mandel FP128/Quad (Mpix/s) | 80.73 [+85%] |
43.74 | 22.57 | 30.4 | Emulated FP128 is hard on FP64 units but we see similar improvement. |
| Navi2L with 50% more CU/SP and faster clock is 60-85% faster than old Navi1 – making it pretty much obsolete. Unlike its big brother (6900XT) it can match its nVidia competition in FP16/FP32 but it is almost 4x faster in FP64: if your workload needs high precision then Navi2 is the way to go. | ||||||
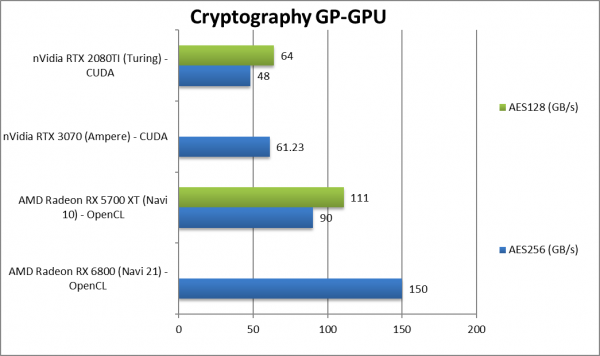 |
||||||
 |
Crypto AES-256 (GB/s) | 150 [+67%] | 90 | 61 | 48 | Navi2L is 67% faster than Navi1 |
|
Crypto AES-128 (GB/s) | 111 | 64 | – | ||
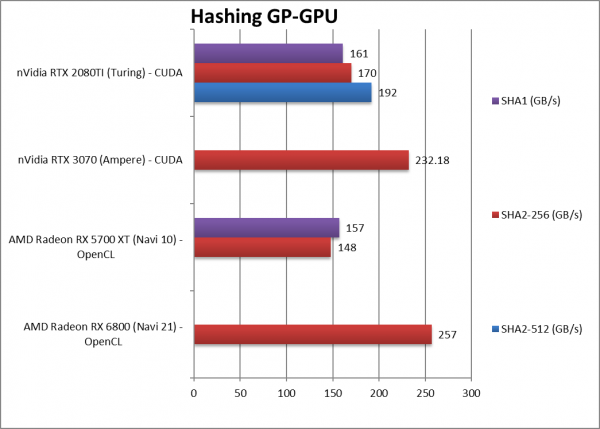 |
||||||
|
Crypto SHA2-256 (GB/s) | 257 [+74%] | 148 | 232 | 192 | Navi2L is 74% faster than Navi1. |
|
Crypto SHA1 (GB/s) | 157 | 170 | – | ||
|
Crypto SHA2-512 (GB/s) | 161 | – | |||
| Despite a modest bandwidth increase, Navi2L is between 67-74% faster than Navi1 – making it obsolete. We can see why 6900XT is memory constrained having the same bandwidth as this 6800.
It also has no problem keeping up with its nVidia competition (300) which it beats by a decent amount. |
||||||
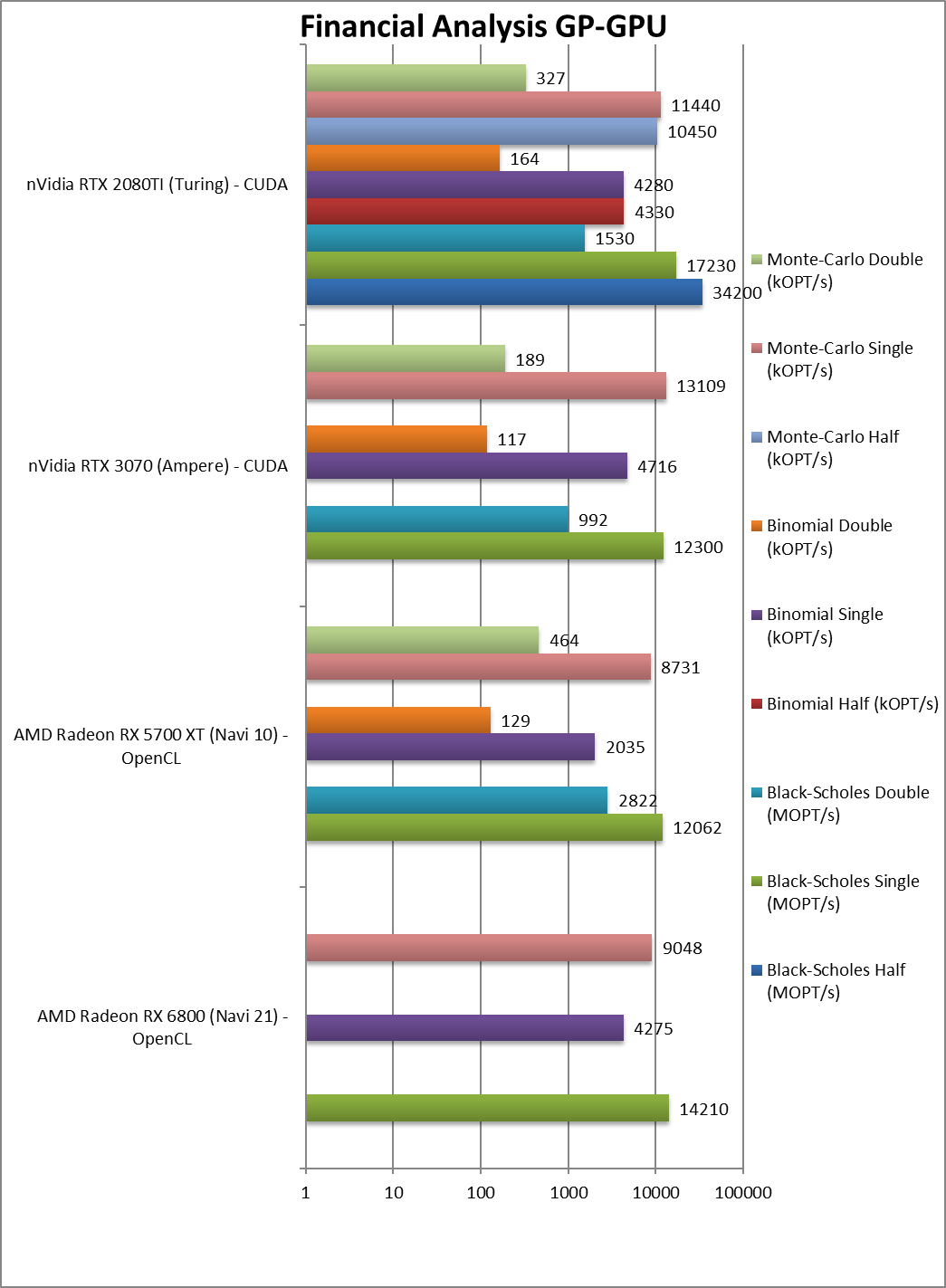 |
||||||
 |
Black-Scholes float/FP32 (MOPT/s) | 14,210 [+18%] | 12,062 | 12,300 | 17,230 | In this FP32 financial workload Navi2L is 18% faster. |
|
Black-Scholes double/FP64 (MOPT/s) | 2,822 | 992 | 1,530 | – | |
|
Binomial float/FP32 (kOPT/s) | 4,275 [+2.1x] | 2,035 | 4,716 | 4,280 | Binomial uses thread shared data – Navi2L over 2x faster. |
|
Binomial double/FP64 (kOPT/s) | 129 | 117 | 164 | – | |
|
Monte-Carlo float/FP32 (kOPT/s) | 9,048 [+4%] | 8,731 | 13,109 | 11,440 | Monte-Carlo uses read-only thread shared data reducing modify pressure: Navi2L is 4% faster. |
|
Monte-Carlo double/FP64 (kOPT/s) | 464 | 248 | 327 | – | |
| For financial FP32 workloads, Navi2L is between 18%-2x faster than Navi1, a more modest improvement. Still it can keep up with its nVidia competition which is something its bigger brother is not quite able to do. | ||||||
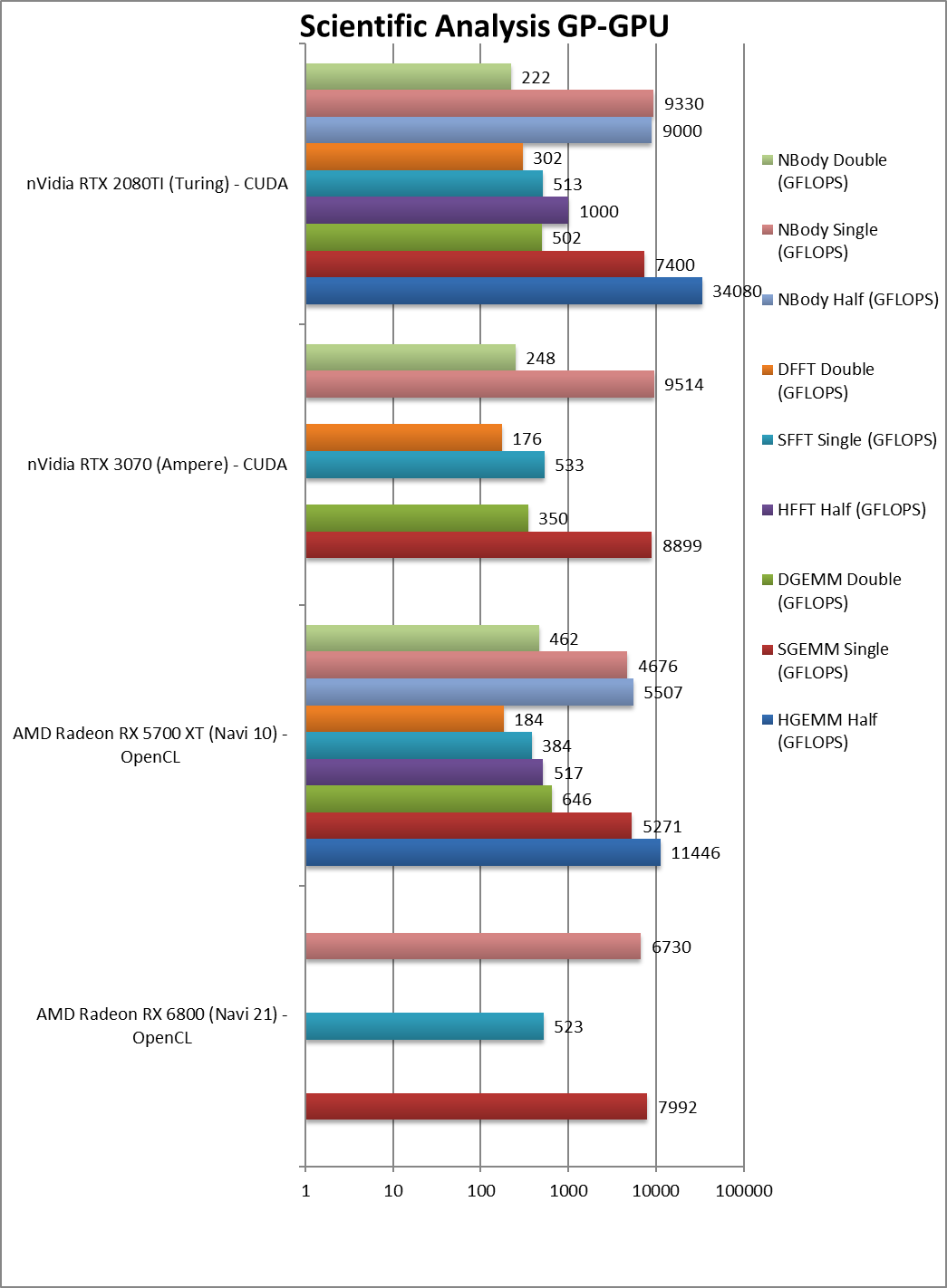 |
||||||
 |
SGEMM (GFLOPS) float/FP32 | 7,992 [+52%] | 5,271 | 8,889 | 7,400 | GEMM brings 52% improvement over Navi1. |
|
DGEMM (GFLOPS) double/FP64 | 646 | 350 | 502 | – | |
|
SFFT (GFLOPS) float/FP32 | 523 [+36%] | 384 | 533 | 513 | FFT also improved by a decent 36% on Navi2. |
|
DFFT (GFLOPS) double/FP64 | 184 | 176 | 302 | – | |
|
SNBODY (GFLOPS) float/FP32 | 6,730 [+44%] | 4,676 | 9,514 | 9,330 | Navi2 improves by 44% over Navi1 in N-Body. |
|
DNBODY (GFLOPS) double/FP64 | 462 | 248 | 222 | – | |
| The scientific FP16/32 algorithms scale better, with Navi2L 36-52% faster than Navi1; again this is sufficient to keep up with nVidia competition. Thankfully due to the high FP32/64 ratio on nVidia consumer cards – Navi2L is a great choice for high-precision (FP64) workloads. | ||||||
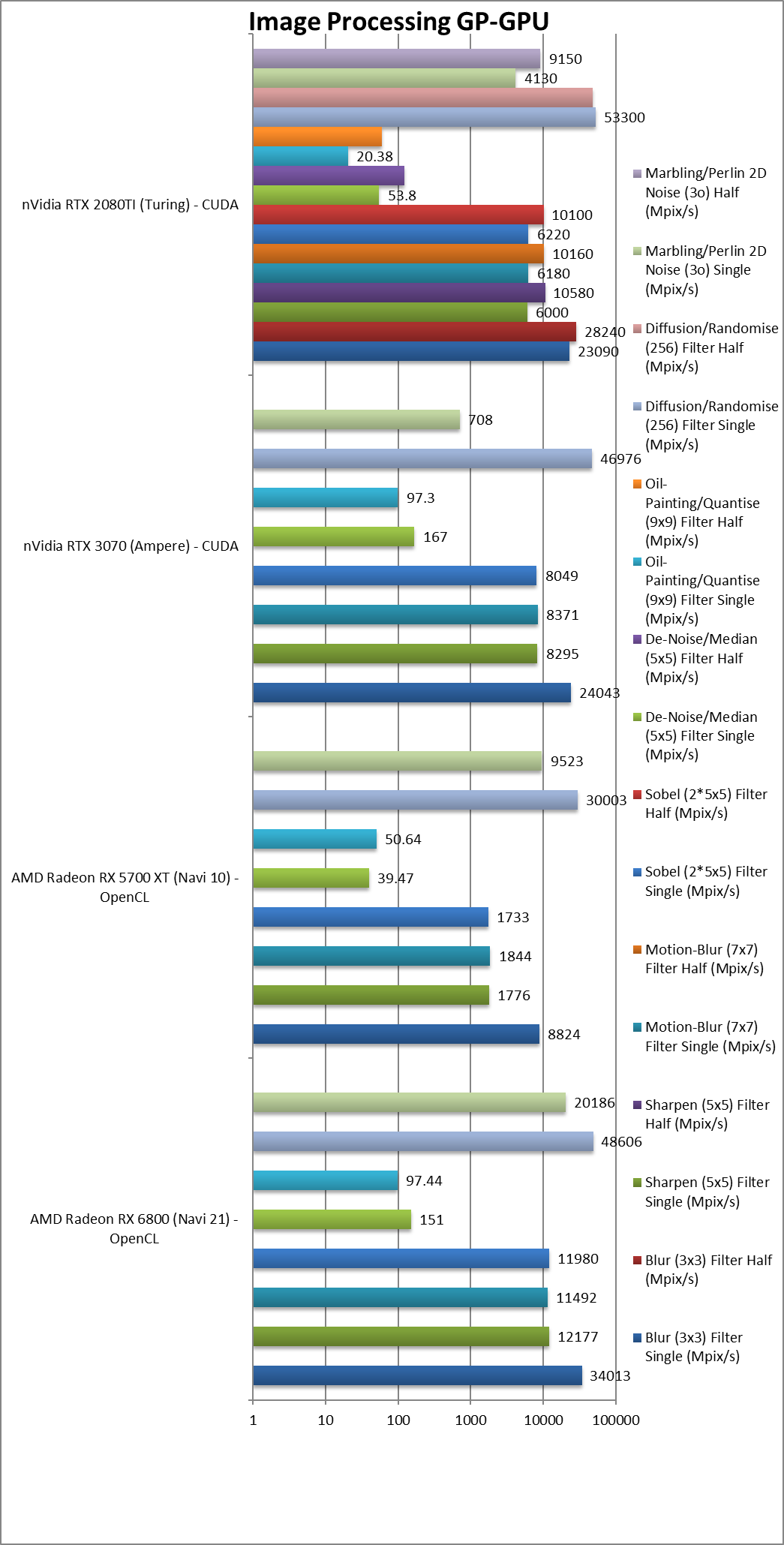 |
||||||
 |
Blur (3×3) Filter single/FP32 (MPix/s) | 34,013 [+3.85x] | 8,824 | 24,043 | 23,090 | In this 3×3 convolution algorithm, Navi2L is almost 4x faster! |
|
Sharpen (5×5) Filter single/FP32 (MPix/s) | 12,177 [+6.86x] | 1,776 | 8,295 | 6,000 | Same algorithm but more shared data makes Navi2L almost 7x faster!! |
|
Motion Blur (7×7) Filter single/FP32 (MPix/s) | 11,492 [+6.23x] | 1,844 | 8,371 | 6,180 | With even more data the gap remains at almost 6x. |
|
Edge Detection (2*5×5) Sobel Filter single/FP32 (MPix/s) | 11,980 [+6.9x] | 1,733 | 8,049 | 6,220 | Still convolution but with 2 filters – similarly almost 7x faster!! |
|
Noise Removal (5×5) Median Filter single/FP32 (MPix/s) | 151 [+3.83x] | 39,47 | 167 | 53.8 | Different algorithm makes Navi2 “only” 4x faster. |
|
Oil Painting Quantise Filter single/FP32 (MPix/s) | 97.44 [+2x] | 50.64 | 97.3 | 20.38 | Without major processing, this filter performs well on Navi2L. |
|
Diffusion Randomise (XorShift) Filter single/FP32 (MPix/s) | 48,606 [62%] | 30,003 | 46,976 | 53,300 | This algorithm is 64-bit integer heavy and Navi2 is 62% faster. |
|
Marbling Perlin Noise 2D Filter single/FP32 (MPix/s) | 20,186 [+2.12x] | 9,523 | 708 | 4,130 | One of the most complex and largest filters, Navi2 is over 2x faster |
| For image processing using FP32 precision, the improvement is just incredible: Navi2L is 2-7x faster than Navi1! Be it hardware, driver – what we saw in the 6900XL review was no fluke: Navi2 GPUs simply fly dominating even top-end nVidia competition. | ||||||
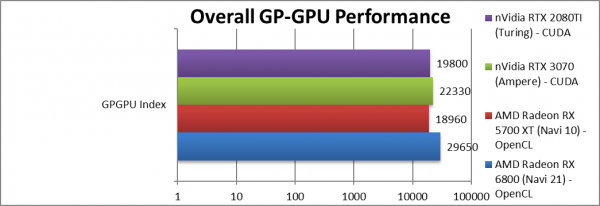 |
||||||
|
Overall GP-GPU Performance (Points) | 29,650 [+56%] | 18,960 | 22,330 | 19,800 | Overall (including memory) Navi2L is 56% faster than Navi1. |
| Across all benchmarks – including memory bandwidth/latency – Navi2L is almost 60% faster than Navi1 – a huge improvement for a mid-range chip. Considering we saw 6900XT just 80% faster makes 6800 a bargain. | ||||||
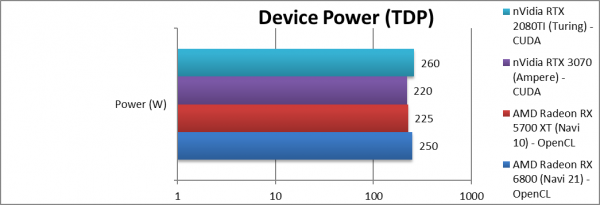 |
||||||
 |
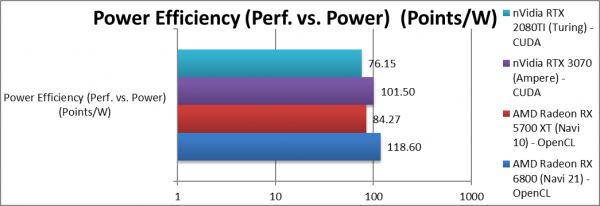
Power/TDP (W) | 250 [+11%] | 225 | 220 | 260 | Power has increased by just 11%. |
 |
||||||
|
Performance/Power (Power Efficiency) (Points/W) | 119 [+41%] | 84 | 101 | 76 | Navi2L power efficiency is 41% better than Navi1. |
| With only 11% in TDP/Power, the ~60% performance increase over Navi1 makes Navi2L 41% more efficient, beating everything else. Here competition cannot match it. | ||||||
 |
||||||
 |
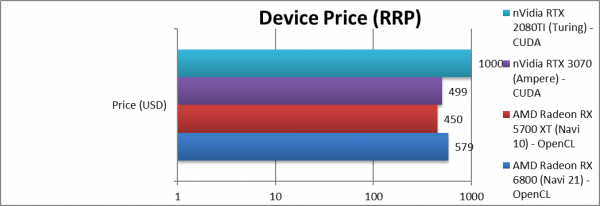
Price/RRP (USD) | $579 [+29%] | $450 | $499 | $1,000 | Price has doubled vs. Navi1. |
 |
||||||
|
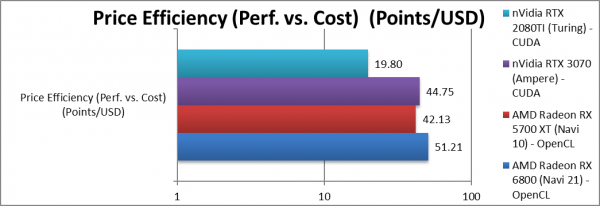
Performance/Power (Power Efficiency) (Points/W) | 51.2 [+22%] | 42.13 | 44.7 | 19.8 | Navi2 price efficiency is 22% lower than Navi1. |
| While Navi2L is about 60% faster than Navi1 across all algorithms, price increase of 30% is half that – thus Navi2L gets you much more for your money. And let’s not forget a better buy than its competition. | ||||||
Memory Performance
We are testing both OpenCL performance using the latest SDK / libraries / drivers from AMD and competition.
Results Interpretation: For bandwidth tests (MB/s, etc.) high values mean better performance, for latency tests (ns, etc.) low values mean better performance.
Environment: Windows 10 x64, latest AMD and nVidia. drivers. Turbo / Boost was enabled on all configurations.
| Memory Benchmarks | AMD Radeon RX 6800 (Navi2L) | AMD Radeon 5700XT (Navi1) | nVidia 3070 (Ampere) | nVidia 2080TI (Turing) | Comments | |
 |
||||||
 |
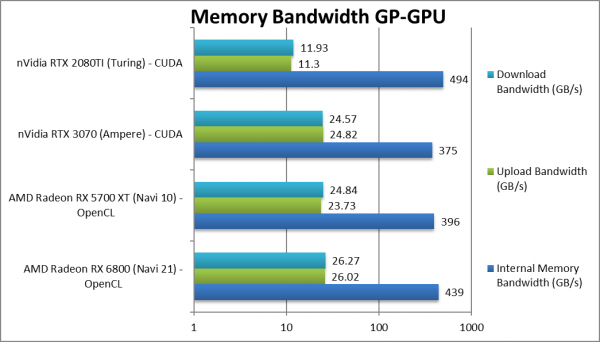
Internal Memory Bandwidth (GB/s) | 439 [+11%] | 396 | 375 | 494 | Navi2L gets a 11% bandwidth bump. |
|
Upload Bandwidth (GB/s) | 26.02 [+6%] | 23.73 | 24.82 | 11.3 | All modern cards have PCIe4 bus now. |
|
Download Bandwidth (GB/s) | 26.27 [+4%] | 24.84 | 24.57 | 11.93 | Again just 4% change. |
| Navi2’s 14% on-paper bandwidth upgrade translates to 11% in real life which at this level is OK; but certainly not for the higher end 6900XT as we saw in the other article.
Navi1 already has a PCIe4 interface (on 500-series AMD and soon 500-series Intel) thus minor improvement in upload/download bandwidth that only shines compared to much older PCIe3 cards (e.g. nVidia’s Turing). |
||||||
|
||||||
 |
Global (In-Page Random Access) Latency (ns) | 155 [-36%] | 241 | 141 | 135 | Due to the higher speed latency is 36% lower. |
|
Global (Full Range Random Access) Latency (ns) | 847 | 243 | – | ||
|
Global (Sequential Access) Latency (ns) | 40 | – | |||
|
Constant Memory (In-Page Random Access) Latency (ns) | 77 | – | |||
|
Shared Memory (In-Page Random Access) Latency (ns) | 10.6 | – | |||
|
Texture (In-Page Random Access) Latency (ns) | 157 | – | |||
|
Texture (Full Range Random Access) Latency (ns) | 268 | – | |||
|
Texture (Sequential Access) Latency (ns) | 67 | – | |||
| Not unexpected, GDDR6′ latencies are higher than HBM2 although not by as much as we were fearing. | ||||||
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
Summary: Much, much faster than old Navi1 and stellar FP64 performance: 9.5/10
Ever since the release of Navi1 (“little-Navi”) and its revolutionary new architecture AMD fans everywhere have eagerly awaited the release of “big-Navi” that can bring the fight to nVidia. A year or so later – we have Navi2: pretty much twice Navi1 + ray-tracing – tensors/tiles. It is everything that was expected but in some ways perhaps we expected more?
With 50% more CU/SP and faster speed, the little brother of “big-Navi” Navi2L chip in 6800 does not disappoint: in compute FP16/32 tasks it is at least 60% faster and in many cases much, much faster. Unlike its bigger brother – it has no problem keeping up with nVidia’s latest competition (Ampere 3070).
Compute FP64 performance is much better thanks to lower FP32/64 ratio (1/16x vs. nVidia 1/32x) that allows it to really put the boot into nVidia – and if that’s the kind of algorithms you run – Navi2 is your choice.
Memory-wise, it seems the meager bandwidth improvement over Navi1is OK for Navi2L which seems to have sufficient resources; it does not seem OK for Navi2XL as we saw in the 6900XT review. Having 2x more memory (16GB) allows much bigger kernels to run – and again shows that 6900XT should have had more.
The price (USD 579) is a bit higher than the old 5700XT but perhaps a sign of the times. Power/TDP is just 11% higher (250W) which shows how much Navi2 has improved efficiency over Navi1.
In summary – Navi2L in mid-range performs much better (compute wise) for the money and also against its competition (3070). We hear that it does even better in games! If you have Navi1, it is time to upgrade. AMD has done good!
To see how its “big-brother” Navi2X performs, please see our AMD Radeon RX 6900XT (RDNA2, Navi2X) Review & Benchmarks – GPGPU Performance article.
AMD Radeon 6900 XT
Disclaimer
This is an independent article that has not been endorsed nor sponsored by any entity (e.g. AMD). All trademarks acknowledged and used for identification only under fair use.
The article contains only public information (available elsewhere on the Internet) and not provided under NDA nor embargoed. At publication time, the products have not been directly tested by SiSoftware and thus the accuracy of the benchmark scores cannot be verified; however, they appear consistent and do not appear to be false/fake.