Who is “Zhaoxin”?
It is a joint venture of VIA Technologies that now effectively owns Centaur Technologies. Centaur/IDT used to make the “WinChip” – one of the few x86 compatible designs. After VIA aquisition, Centaur/VIA then produced the C3, C7 and finally Nano. After Zhaoxin formation, the designs continued with minor modifications of the “Nano” core with the ZX family of CPUs – however Zhaoxin now has brought out new designs:
- ZX-C “Zhangiang” (2016): 4-8C 2GHz 28nm ~45W
- KX-5000 “Wudaokou” (2017): 4-8C 2GHz 28nm ~45W
- KX-6000 “Lujiazui” (2019): 4-8C 3GHz 16nm ~70W
- KX-7000 due to launch this year (2021)
What is “ZHAOXIN KaiXian”?
It is 5th generation CPU/SoC released by Zhaoxin/Centaur released in 2019 that includes modern new features and functionality common in competitive designs e.g. AMD/Intel. Designed for the internal Chinese market, it reduces dependencies on foreign designs and also includes custom local features, e.g. Chinese National Standard cryptographic functions (SM3/hash, SM4/block ciphers, etc.). Its relatively simplicity and cost are also advantages against much more expensive imported western CPUs from AMD/Intel.
The latest KX-6000 arch is made on a relatively modern process and includes many modern features:
- 5th Gen micro-arch (derived of VIA/Centaur Nano) 16nm FinFET
- AVX and SSE 4.2/4.1, SSSE3, SSE2 instruction sets
- AES, SHA + SM3/SM4 HWA (hardware acceleration)
- 8C/8T “little” core design (no SMT) up to 3GHz (no turbo)
- 32kB L1D/L1I 8-way set caches (similar to competition)
- 8MB L2 16-way set cache (similar to L3 cache in competition)
- PCIe 3.0
- 2x channel DDR4 memory controller up to 2667MHzm 64MB total memory
- Virtualization support (VT-d)
- TDP / Power ~70W
- Price inc. motherboard ~$500 (internal China price)
Unfortunately for Zhaoxin, while 8-cores (even little ones) was quite something in 2016, with Intel keeping all desktop-class CPUs at 4C/8T (with Skylake and friends) – the recent AMD/Intel “war” has seen the number of CPU cores more than double – with Intel at 10C/20T and AMD at an incredible 16C/32T! Intel Atom “Denverton” (DVT) even goes as high as 16-cores (C3858 12C, C3958 16C) thus more cores will be needed in the future to stay competitive.
At 16nm the TDP for those 8 “little” cores is a somewhat large 70W that will need to reduce significantly if number of cores doubles or clock speed increases. Current designs have no dynamic over-clocking functionality (Turbo) which means they cannot increase speed over rated (3GHz top) that while decent – will also need to increase significantly for it to remain competitive.
AES & SHA hardware-acceleration makes it a good fit for a network appliance (though TDP is somewhat large) and the large number of cores allows a greater number of (network card) queues to be used (RSS). Virtualization support means it could serve as high-number of VM/low-compute/utilisation host similar to Intel’s Atom “Denverton” family.
On the instruction front, while we do have AVX (i.e. 4th Gen Core “Haswell”-class), we are missing further AVX2, FMA3 updates that have become pretty widely used since then. The next core (KX-7000) is meant to support even AVX512 which is not impossible considering Intel’s own modified Atom cores of “Phi” (Larabee) accelerators have done so. However, lets remember Intel has canned the project so it has not exactly been successful. However, Zhaoxin has different priorities and a 32-core/AVX512 KX-7000 may be a winner.
CPU (Core) Performance Benchmarking
In this article we test CPU core performance; please see our other articles on:
- CPU
Hardware Specifications
We are comparing the KaiXian with somewhat older competing architectures with a view of whether it has caught up in performance.
| CPU Specifications | ZHAOXIN KaiXian KX-U6780A (8C/8T) | Intel Core i5-7500 (KBL) 4C/4T | AMD Ryzen 3 PRO 1300 (Zen) 4C/4T | Intel Atom C3758 (DVT) 8C/8T | Comments | |
| Cores (CU) / Threads (SP) | 8C / 8T | 4C/4T | 4C/4T | 8C/8T | More cores for your money | |
| Speed Rated/Turbo (GHz) |
2.7GHz | 3.4-3.8GHz | 3.5-3.7GHz | 2.2GHz | No turbo, clock could be higher | |
| Power TDP/Turbo (W) |
70W | 65W | 65W | 25W | TDP somewhat high. | |
| L1D / L1I Caches | 8x 32kB / 8x 32kB | 4x 32kB / 4x 32kB | 4x 32kB / 4x 64kB | 8x 32kB / 8x 24kB | L1 caches are competitive | |
| L2 Caches | 8MB 16-way | 4x 256kB | 4x 512kB | 16MB 16-way | L2 is good size but could be larger. | |
| L3 Caches | n/a | 6MB | 8MB | n/a | No L3 like Atom | |
| Microcode (Firmware) | MU069E09-B4 | MU8F0101-38 | No indication of microcode | |||
| Special Instruction Sets |
AVX?, SSE4/3/2 | AVX2/FMA, SHA | AVX2/FMA | SSE4/3/2 | Meant to support AVX | |
| SIMD Width / Units |
128-bit | 256-bit | 256-bit | 128-bit | Widest SIMD units ever | |
Disclaimer
This is an independent article that has not been endorsed or sponsored by any entity (e.g. Zhaoxin/Centaur). All trademarks acknowledged and used for identification only under fair use.
The article contains only public information (available elsewhere on the Internet) and not provided under NDA nor embargoed. At publication time, the products have not been directly tested by SiSoftware and thus the accuracy of the benchmark scores cannot be verified; however, they appear consistent and do not appear to be false/fake.
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets. While the KaiXian does not support the very latest instruction sets (e.g. AVX512, VAES, AVX2/FMA) it does support older instruction sets (AVX, SSE4, SSSE3, SSE2).
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
| Native Benchmarks | ZHAOXIN KaiXian KX-U6780A (8C/8T) | Intel Core i5-7500 (KBL) 4C/4T | AMD Ryzen 3 PRO 1300 (Zen) 4C/4T | Intel Atom C3758 (DVT) 8C/8T | Comments | |
 |
||||||
 |
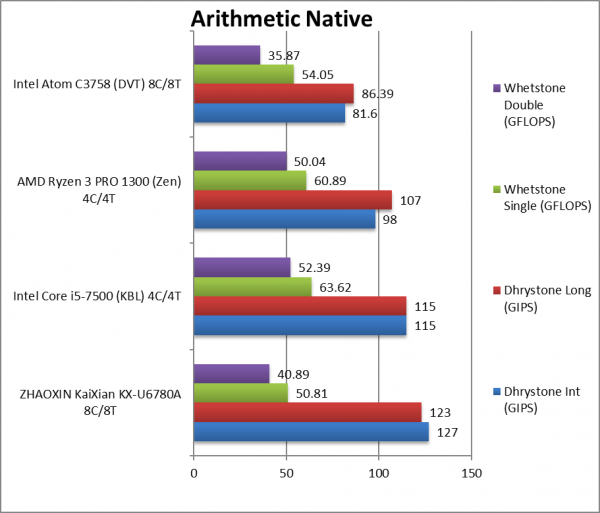
Native Dhrystone Integer (GIPS) | 127 [+56%] |
115 | 98 | 81.6 | With 8C, the KX manages to come on top. |
|
Native Dhrystone Long (GIPS) | 123 [42%] |
115 | 107 | 86.39 | With a 64-bit integer workload KX wins again. |
|
Native FP32 (Float) Whetstone (GFLOPS) | 50.81 [-6%] | 63.62 | 60.89 | 54.05 | With floating-point, the older KBL still wins. |
|
Native FP64 (Double) Whetstone (GFLOPS) | 40.89 [+14%] | 52.39 | 50.04 | 35.87 | With FP64 nothing much changes, KBL still on top. |
| With 8-cores, the KX does manage to come on top against competing 4-core designs but not by much. 2 KX cores are a bit faster than an Intel/AMD cores – but at least it outclases Atom DVT with same no of cores.
With floating point, the Intel/AMD SIMD units show their power and even 2x KX cores cannot beat one of their cores. Again, Atom is much, much slower. |
||||||
 |
||||||
 |
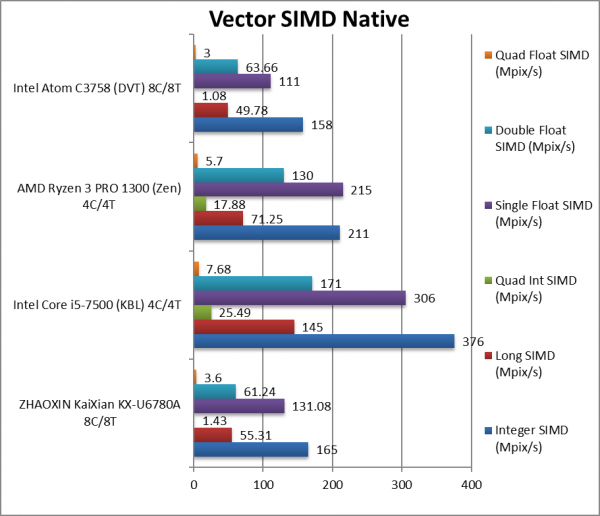
Native Integer (Int32) Multi-Media (Mpix/s) | 165 [+4%] | 376* | 211* | 158 | Without AVX2, KX is about 1/2x KBL. |
|
Native Long (Int64) Multi-Media (Mpix/s) | 55.31 [+11%] | 145* | 71.25* | 49.78 | Again without AVX2, 64-bit workload is 1/3x KBL. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 1.43 [+32%] | 25.49* | 17.88* | 1.08 | Using long integers Int128 KX is much slower. |
|
Native Float/FP32 Multi-Media (Mpix/s) | 131 [+18%] | 306** | 215** | 111 | In floating-point, KX is still 1/3x rate. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 61.24 [-4%] | 171** | 130** | 63.66 | Switching to FP64 KX is still 1/3x rate. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 3.6 [+20%] | 7.68** | 5.7** | 3 | Using FP64 to mantissa extend FP128 RKL is still 42% faster. |
| Without AVX2, integer SIMD workloads on KX are 1/2-1/3x slower than KBL/Ryzen – despite having 2x as many cores. It needs to rely on quite old SSE4/SSSE3 like Atom – which again just manages to beat.
With floating-point, we do have AVX – though missing FMA3 that does not have a huge impact, but even there KX is about 1/3x slower than KBL again despite having 2x no of cores. Against Atom the situation is similar – beating it in all but 1 test. Note*: using AVX2. Note**: using AVX/FMA3. |
||||||
 |
||||||
 |
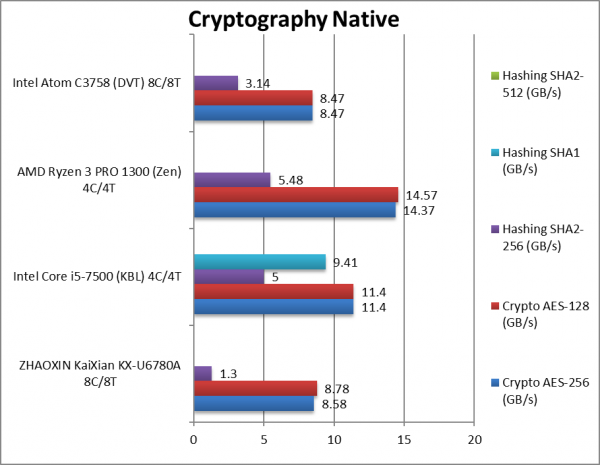
Crypto AES-256 (GB/s) | 8.58 [+1%] | 11.4 | 14.34 | 8.47 | Memory bandwidth rules KX could do better. |
|
Crypto AES-128 (GB/s) | 8.78 [+4%] | 11.4 | 14.57 | 8.49 | No change with AES128. |
|
Crypto SHA2-256 (GB/s) | 1.3 [-59%] | 5* | 5.48** | 3.14 | KX does pretty badly here beaten by Atom. |
|
Crypto SHA1 (GB/s) | 9.41 | Less compute intensive SHA1. | |||
|
Crypto SHA2-512 (GB/s) | SHA2-512 is not accelerated by SHA HWA. | ||||
| Centaur/VIA brought the 1st x86 AES/SHA hardware accelerators (HWA) with PadLock which made the SoC “killer” network appliances (VPN gateways, etc.). However, these days – competitors have standardised on AES/SHA HWA with AVX2 in addition for multi-buffer hashing. [While Sandra supported PadLock until early 20/20, we have now removed support]
Memory bandwidth is crucial here, and KX seems a bit starved here, with KBL/Ryzen quite a bit faster. Against Atom is competitive in crypto but surprisingly not in hashing – despite its acceleration. |
||||||
 |
||||||
 |
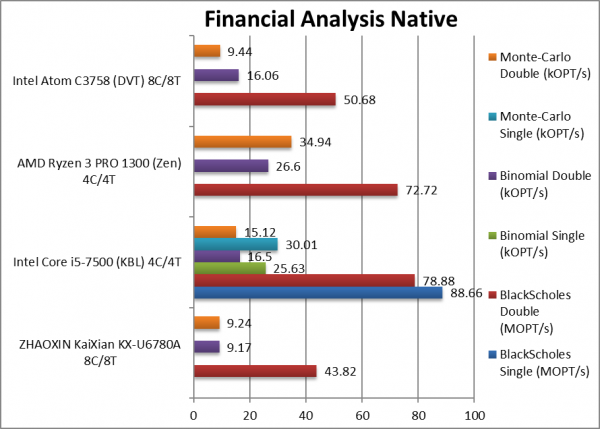
Black-Scholes float/FP32 (MOPT/s) | 88.66 | Black-scholes is unvectorised and compute heavy. | |||
|
Black-Scholes double/FP64 (MOPT/s) | 43.82 [-14%] | 78.88 | 72.72 | 50.68 | Using FP64 KX is slower than Atom. |
|
Binomial float/FP32 (kOPT/s) | 25.63 | Binomial uses thread shared data thus stresses the cache & memory system. | |||
|
Binomial double/FP64 (kOPT/s) | 9.17 [-43%] | 16.5 | 26.6 | 16.06 | With FP64 code KX is 1/2 slower. |
|
Monte-Carlo float/FP32 (kOPT/s) | 30.01 | Monte-Carlo also uses thread shared data but read-only. | |||
|
Monte-Carlo double/FP64 (kOPT/s) | 9.24 [-2%] | 15.12 | 34.94 | 9.44 | Switching to FP64 KX ties with Atom. |
| With non-SIMD financial workloads, KX seems to do a lot worse than expected, sometimes 1/2 slower than even Atom, sometimes matching it. Naturally, both Intel/AMD big cores have no problem blowing them both away (despite 1/2x less cores). For compute tasks – neither Atom nor KX should be on your list. | ||||||
 |
||||||
 |
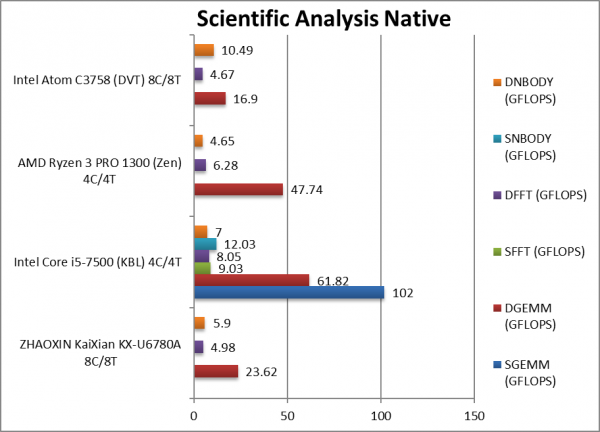
SGEMM (GFLOPS) float/FP32 | 102 | In this tough vectorised algorithm | |||
|
DGEMM (GFLOPS) double/FP64 | 23.62 [+40%] | 61.82 | 47.74 | 16.9 | With FP64 vectorised code, KX is 40% faster. |
|
SFFT (GFLOPS) float/FP32 | 9.03 | FFT is also heavily vectorised but memory dependent. | |||
|
DFFT (GFLOPS) double/FP64 | 4.98 [+7%] | 8.05 | 6.28 | 4.67 | With FP64 code, KX is 7% faster. |
|
SNBODY (GFLOPS) float/FP32 | 12.03 | N-Body simulation is vectorised but with more memory accesses. | |||
|
DNBODY (GFLOPS) double/FP64 | 5.9 [1/2x] | 7 | 4.65 | 10.49 | With FP64 KX is 1/2 slower. |
| With highly vectorised SIMD code (scientific workloads), KX does manage to do better, showing that overall its SIMD units are more powerful than Intel’s Atom. Again both AMD/Intel big cores have no problem dispatching both – again compute workloads are not for Atom nor the KX. | ||||||
 |
||||||
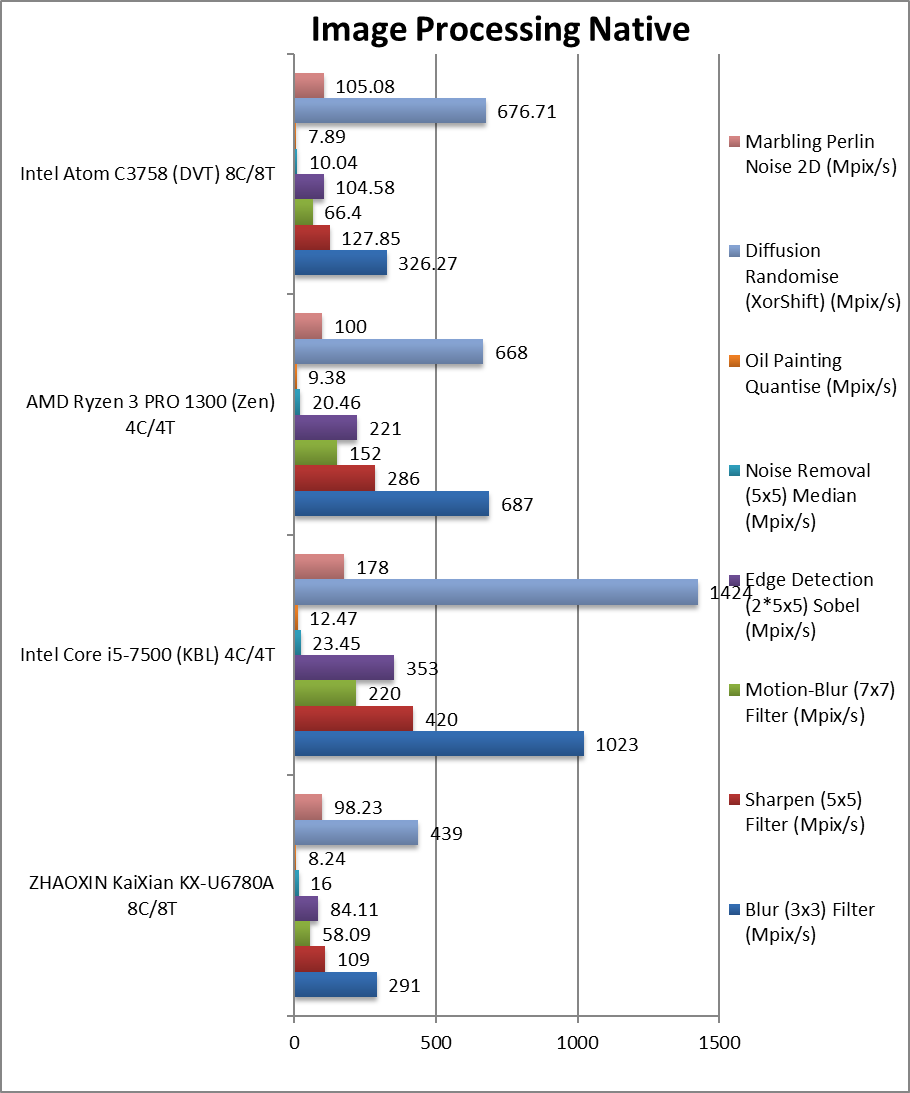
 |
Blur (3×3) Filter (MPix/s) | 291 [-11%] | 1,023* | 687* | 326 | In this vectorised integer workload KX is 11% slower. |
|
Sharpen (5×5) Filter (MPix/s) | 109 [-15%] | 420* | 286* | 127 | Same algorithm but more shared data KX is 15% slower. |
|
Motion-Blur (7×7) Filter (MPix/s) | 58.09 [-13%] | 220* | 152* | 66.4 | Again same algorithm but even more data shared, KX is 13% slower. |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 84.11 [-20%] | 353* | 221* | 104 | Different algorithm but still vectorised workload KX is 20% slower. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 16 [+59%] | 23.45 | 20.46 | 10.04 | Still vectorised code KX is 60% faster. |
|
Oil Painting Quantise Filter (MPix/s) | 8.24 [+4%] | 12.47 | 9.38 | 7.89 | Here KX is just 4% faster. |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 439 [-35%] | 1,424 | 668 | 676 | With integer workload, KX is 35% slower. |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 98.23 [-7%] | 178 | 100 | 105 | In this final test again with integer workload KX is 7% slower. |
| Without AVX2 and despite having AVX, sometimes the KX manages to be consistently behind the Atom in these algorithms. Again, the gap between big core AMD/Intel and Atom/KX is very large, showing yet again that neither are good for computing workloads.
Note*: using AVX2. |
||||||
 |
||||||
 |
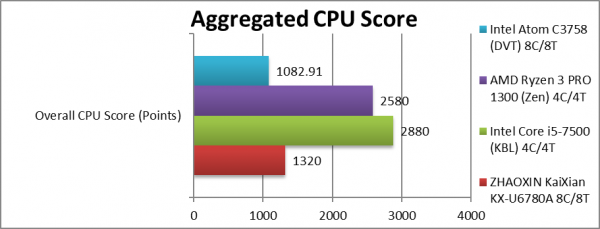
Aggregate Score (Points) | 1,320 [+22%] | 2,880* | 2,580* | 1,082 | Across all benchmarks, KX is 22% faster! |
| All that matters is that for the same number of cores, KX beats Intel’s Atom DVT by over 20%! Sure, both it and Atom are demolished by the big AMD/Intel cores (which are at least 2x faster despite having half the cores!) – but that matters not.
Note*: using AVX2. |
||||||
 |
||||||
 |
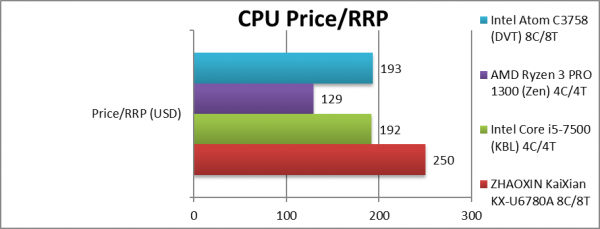
Price/RRP (USD) | ~$250 SoC only | $192 | $129 | $193 | Hopefully price will come down. |
 |
||||||
|
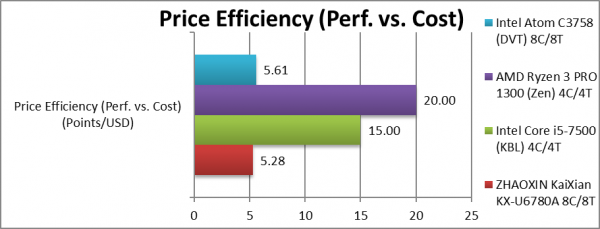
Price Efficiency (Perf. vs. Cost) (Points/USD) | 5.28 [-6%] | 15 | 20 | 5.61 | KX 6% less cost effective. |
| As it is sold only in China including the mainboard, it is difficult to determine the exact SoC price; due to the relatively low-volume, the cost is perhaps not as cheap as expected – but is competitive with Atom. While both KX & Atom may appear un-competitive, let’s remember they are SoCs and include lots of functionality of the PCH.
Let’s consider the point of this CPU/SoC is independence from western designs, thus being a bit less performance/cost efficient matters not. |
||||||
 |
||||||
 |
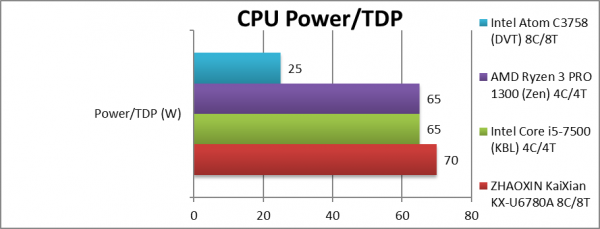
Power/TDP (W) | 70W [+2.5x] | 65W | 65W | 25W | KX TDP is 2.5x Atom, huge difference. |
 |
||||||
|
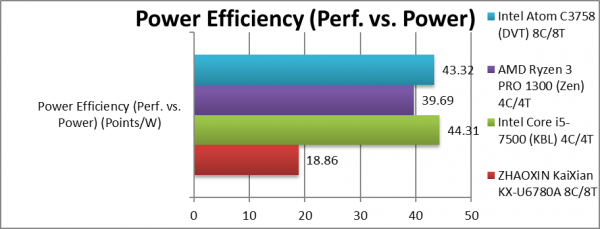
Power Efficiency (Perf. vs. Power) (W) | 18.86 [1/2x] | 44.31 | 39.69 | 43.32 | KX much less efficient than Atom. |
| Despite its better performance, its quite high TDP (same as big cores from AMD/Intel) makes the KX very power inefficient; perhaps in China where electricity is cheap that does not matter, but in the west that is a problem.
Interesting to see that Atom despite its low performance, its low TDP makes it just as if not more competitive than big cores in performance/power. Zhaoxin/Centaur need to reduce TDP by a significant amount to match Atom. |
||||||
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
Summary: An interesting SoC, hoping for better: 7/10
Centaur/VIA will always have a special place for us (SiSoftware) as we have been working with them for almost 20 years (!) Despite their size they added their own mark on the x86 world (e.g. crypto acceleration with PadLock, etc.) and it is great to see Zhaoxin continuing the proud tradition. Here’s to the next 20 years!
The soon to be replaced KX-6000 series is an interesting SoC that – at launch (2017) – was likely the only real 8-core CPU you could get at non-ridiculous prices (e.g. Intel’s HEDT platform). But now desktop CPUs from AMD/Intel with 10-16C 20-32T are available and even Atom “Denverton” DVT goes up to 16C – thus many more cores are needed.
In testing the KX cores perform reasonably well, and can beat Atom DVT with the same number of cores; considering in how many network appliances (firewalls, routers, gateways, etc.), storage (NAS, low-cost SAN) and low-cost servers Atom is used – there is a market there for the KX if the price is right. No, it cannot beat modern AMD/Intel cores (even many years older) – and systems may still be more cost effective.
About the only issue is the somewhat high TDP (70W) which does not compare well with Atom DVT (25W) – especially as the latter includes 2.5/10Gbe LAN that are known to use significant power. Thus it may not be possible to build passive network/storage devices without fan cooling (e.g. for homes/offices) while for rack usage the higher power usage results in higher costs.
If Zhaoxin/Centaur can improve SIMD performance in the future KX and add more cores (16? 24? 32?) it can pretty much finish Intel’s Atom which would be a big achievement in itself. Here’s to the new low-cost king!
In summary – recommended!
Please see our other articles on:
- Intel Iris Plus G7 Gen 12 XE TigerLake ULV (i7-1165G7) Review & Benchmarks – GPGPU Performance
- AVX512-IFMA(52) Improvement for IceLake and TigerLake
- Intel Core Gen 10 IceLake ULV (i7-1065G7) Review & Benchmarks – Cache & Memory Performance
Disclaimer
This is an independent article that has not been endorsed or sponsored by any entity (e.g. Zhaoxin/Centaur). All trademarks acknowledged and used for identification only under fair use.
The article contains only public information (available elsewhere on the Internet) and not provided under NDA nor embargoed. At publication time, the products have not been directly tested by SiSoftware and thus the accuracy of the benchmark scores cannot be verified; however, they appear consistent and do not appear to be false/fake.