What is this “AlderLake-E”?
After considering whether the recently released AlderLake (ADL) would have been better with 10 big/P(erformance) Cores and AVX512 rather than hybrid – someone asked why not the other way round? Why not just use LITTLE/E(fficient) Atom cores and no big/P cores?
Note that Intel had such exact products in the “Phi” line of (GP-GPU) accelerators, i.e. many cores with the initial version of AVX512 and 4-threads per Atom core. Later products increased the number of cores (e.g. 7000 series) to 61C / 244T, that despite being used in many supercomputers, has been discontinued by Intel in 2018.
Thus while many-core (MIC) wide (aka SIMD/VLIW) do have their uses, they don’t always make sense for general purpose computing. But since ADL’s Atom cores are far more advanced (than old “Phi”) perhaps it has a chance to perform well.
- Intel says that 4x LITTLE/E Atom cluster = 1x big/P Core die size wise. We replace 8x Cores cores with 32 LITTLE/E Atom cores.
- We thus have 40 Core / 40 Threads ADL-E(fficient) (no SMT, no AVX512)
- Phi had up to 61C thus 40C is not a crazy amount. AMD ThreadRipper even has 32C big cores / 64.
- Intel has sold server CPUs with many Atom cores (16C) for quite some time now
- Intel claims “Gracemont” Atom core compute equivalent to old ” Skylake” (SKL) big Core
- We’ll call this i11 since must be better than 9 – it must go to 11 (yes it’s a This is Spinal Tap reference 😉
- Still Gen 12 but need to increase product number from 900 to… 911?
- Must replace boring K(F) with E (efficiency) we end up with the mythical “Intel Core i11-12911E“
- It may not sound as cool as the 12999X, but it is imagined for efficiency

Mythical ADL-E with 40 LITTLE/P Atom cores / 40 Threads and NO big Cores
What would be the advantages of this mythical “AlderLake-E”?
With many Atom cores rather than few big “Core” cores we have somewhat different advantages:
- No hybrid architecture required, thus no software changes, current software would just work.
- No need for Windows 11! With some luck even Windows 7 might work just fine.
- Many core designs lend themselves to server work (serving many clients) or converged virtualisation (hosting many server VMs each with a few dedicated cores). Not gaming, but still plenty of uses both home/office.
- AVX2/FMA is still fine even for vectorised heavy compute code (after all AMD Zen3 only has AVX2/FMA3).
- With VNNI/256 and SHA, VAES/256 a formidable crypto / AI (Artificial Intelligence / ML (Machine Learning) accelerator.
- 40 Atom cores of Skylake (SKL) Core power should have considerable raw compute power far beyond old Atom cores.
Hardware Specifications
We are comparing the mythical top-of-the-range Gen 12 Intel with competing architectures as well as competitors (AMD) with a view to upgrading to a top-of-the-range, high performance design.
| Specifications | Mythical Intel Core i11-12911E 40C/40T (ADL-E) Projected |
Intel Core i9-12900K 8C+8c/24T (ADL) | Intel Core i9-11900K 8C/16T (RKL) AVX512 |
AMD Ryzen 9 5950X 16C/32T (Zen3) | Comments | |
| Arch(itecture) | Gracemont / AlderLake-E | Golden Cove + Gracemont / AlderLake | Cypress Cove / RocketLake | Zen3 / Vermeer | Still very latest arch | |
| Cores (CU) / Threads (SP) | 40C / 40T | 8C+8c / 24T | 8C / 16T | 2M / 16C / 32T | More cores and threads than anybody | |
| Rated Speed (GHz) | 2.4 | 3.2 big / 2.4 LITTLE | 3.5 | 3.4 | Base as E-cores | |
| All/Single Turbo Speed (GHz) |
3.9 | 5.0 – 5.2 big / 3.7 – 3.9 LITTLE | 4.8 – 5.3 | 4.9 | Turbo as E-cores | |
| Rated/Turbo Power (W) |
150-300? | 125 – 250 | 125 – 228 | 105 – 135 | We increase TDP a little | |
| L1D / L1I Caches | 40x 32kB / 40x 64kB | 8x 48kB/32kB + 8x 64kB/32kB | 8x 48kB 12-way / 8x 32kB 8-way | 16x 32kB 8-way / 16x 32kB 8-way | Many L1D caches | |
| L2 Caches | 10x 2MB (20MB) |
8x 1.25MB + 2x 2MB (14MB) | 8x 512kB 16-way (4MB) | 16 512kB 16-way (8MB) | Huge L2 cache | |
| L3 Cache(s) | 30MB 16-way | 30MB 16-way | 16MB 16-way | 2x 16MB 16-way (32MB) | Keep L3 the same | |
| Microcode (Firmware) | 090672-0F [updated] | 090672-0F [updated] | 06A701-40 | 8F7100-1009 | Same microcode | |
| Special Instruction Sets |
VNNI/256, SHA, VAES/256 | VNNI/256, SHA, VAES/256 | AVX512, VNNI/512, SHA, IFMA52, VAES/512 | AVX2/FMA, SHA | Still modern ISA support | |
| SIMD Width / Units |
256-bit | 256-bit | 512-bit (1x FMA) | 256-bit | Same width | |
| Price / RRP (USD) |
$799? | $599 | $539 | $799 | Let’s match AMD 5950X | |
Disclaimer
This is an independent article that has not been endorsed nor sponsored by any entity (e.g. Intel). All trademarks acknowledged and used for identification only under fair use.
This article contains speculation with extrapolated results; there is NO such product! It also makes some assumptions and over-simplifications.
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!
Assumptions
- Scaling from 8c/8t to 40c/40t (5x) would be linear in the compute heavy SIMD algorithms tested
- The product would not be power limited though its power use may be higher with more cores
- The product would maintain similar base/turbo clocks despite having more cores
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets. Mythical “AlderLake” (ADL-E) does not support AVX512 just like normal ADL.
Note we only present those benchmarks that are compute heavy, vectorised and using AVX2/FMA3. Benchmarks that are memory latency or bandwidth sensitive are harder to extrapolate as the scaling is not linear, thus we would not expect all (benchmark) scores to just increase by the same ratio.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 11 x64, latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
| Native Benchmarks | Mythical Intel Core i11-12911E 40C/40T (ADL-E) Projected |
Intel Core i9-12900K 8C+8c/24T big+LITTLE (ADL) | Intel Core i9-11900K 8C/16T (RKL) AVX512 |
AMD Ryzen 9 5950X 16C/32T (Zen3) | Comments | |
 |
||||||
 |
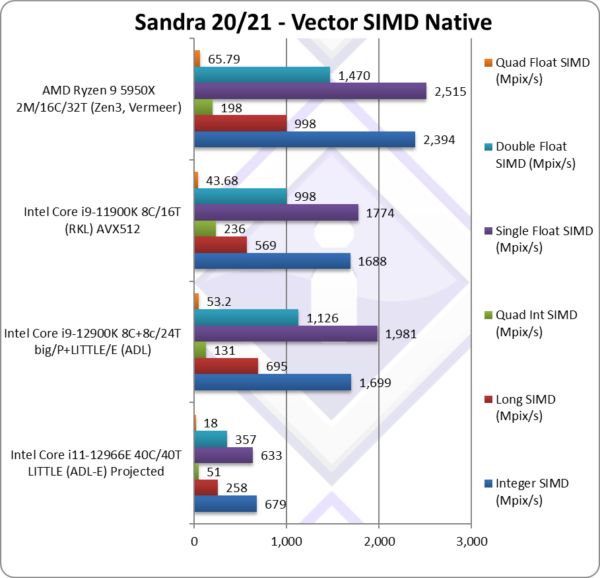
Native Integer (Int32) Multi-Media (Mpix/s) | 679** [-60%] | 1,699 | 1,688* | 2,394 | Atom cores no match for big Cores |
|
Native Long (Int64) Multi-Media (Mpix/s) | 258** [-63%] | 695 | 569* | 998 | With a 64-bit, ADL-E still 63% slower. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 51** [-61%] | 131 | 236*/*** | 198 | Using 64-bit int to emulate Int128 still slow |
|
Native Float/FP32 Multi-Media (Mpix/s) | 633** [-69%] | 1,981 | 1,774* | 2,515 | In this floating-point vectorised test ADL-E is 69% slower than ADL. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 357** [-69%] | 1,126 | 998* | 1,470 | Switching to FP64 nothing much changes. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 18** [-66%] | 53.2 | 43.68 | 65.79 | Using FP64 to mantissa extend FP128 we’re 66% slower. |
| With heavily vectorised SIMD workloads – even with AVX2/FMA3 – the Atom cores are no match for big Cores from either Intel or AMD. They may be Skylake equivalent with legacy/non-SIMD code but even 40 of them (40C / 40T) won’t cut it.
It seems probable that AVX2/FMA3 are executed by 128-bit SIMD units similar to old AMD Zen cores (thus 1/2 rate). With full rate AVX512 and Hyper-threading (the “Phi” accelerator Atom cores supported 4-threads each) the performance would be much higher – we saw Zen3 double SIMD performance – but at this time it is low. Some may be disappointed, but let’s remember they are still efficient, LITTLE, Atom cores not meant for top-end SIMD performance. Note:* using AVX512 instead of AVX2/FMA. Note:** extrapolated results based on ADL with 8 LITTLE/E Atom cores 8T (but big/P Cores disabled). Note:*** using AVX512-IFMA52 to emulate 128-bit integer (int128) operations. |
||||||
Note we only present those benchmarks that are compute heavy, vectorised and using AVX2/FMA3. Benchmarks that are memory latency or bandwidth sensitive are harder to extrapolate as the scaling is not linear, thus we would not expect all (benchmark) scores to just increase by the same ratio.
SiSoftware Official Ranker Scores
- 12th Gen Intel Core i9-12900K (8C + 8c / 24T)
- 12th Gen Intel Core i9-12900KF (8C + 8c / 24T)
- 12th Gen Intel Core i7-12700K (8C + 4c / 20T)
- 12th Gen Intel Core i5-12600K (6C + 4c / 16T)
Final Thoughts / Conclusions
Summary: Would be useful for some workloads
ADL has been designed for efficiency – not performance at any cost regardless of power usage (like RKL); however, changes to support the hybrid architecture and the loss of AVX512 are non-trivial. All in the name of efficiency.
With Intel claiming that the 4-LITTLE/E Atom cluster takes the same die space as 1 big/P Core, perhaps an efficient version (ADL-E) with 40 LITTLE/E Atom cores / 40T could be made. Just like the now defunct “Phi” accelerators, many-core/threads wide SIMD CPUs are not for everybody. But while the “Phi” Atom cores were very weak and optimised for SIMD/AVX512 – the far more powerful ADL “Gracemont” Atom cores are similar in power to old Skylake (SKL) big Core and support AVX2/FMA3, VNNI/256, SHA, VAES/256.
Extrapolating from 8c/8t to 40c/40t – thus 5x higher performance best case – is still not sufficient for heavy vectorised compute algorithms. While the Atom cores have improve considerably, even 40 of them cannot match 8 big Cores. They may match SKL in legacy/non-vectorised code but heavy compute is just not for them. Again, AVX512 and Hyperthreading would likely help here but, alas, they are not available.
With just 2 memory channels (even high speed DDR5), 40 cores would be starved for data. Algorithms that could fit their datasets in the 10x L2 caches (20MB total) or unified L3 cache (30MB) would perform well but anything latency or bandwidth sensitive would likely incur penalties.
As we mentioned, this is not your usual or “gaming” CPU – but an efficient, many core/thread version – without the cost of comparable server CPUs. It could still have a place in your home/office but handling different tasks to your usual PC. If the price were right, we’d take one.
Summary: Would be useful for some workloads
Further Articles
Please see our other articles on:
- CPU
- Cache & Memory
- GP-GPU
Disclaimer
This is an independent article that has not been endorsed nor sponsored by any entity (e.g. Intel). All trademarks acknowledged and used for identification only under fair use.
This article contains speculation with extrapolated results; there is NO such product! It also makes some assumptions and over-simplifications.
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!