What is this “AlderLake-X”?
ADL has now been launched – with AVX512 disabled: but, for the moment, it is possible to enable AVX512 on some boards; at least until the next microcode update. Some users have managed to benchmark ADL with AVX512 enabled (only big/P Cores enabled, LITTLE/E Atom cores disabled) and shown nice improvement over RKL (that does have AVX512). Even better, ADL supports some new AVX512 extensions that are due to feature in the future “Sapphire Rapids” server processors! This gave us a crazy idea…
Having spent many years developing AVX512 code (that is now superfluous) and dealing with extensive changes to support Hybrid, we thought it may be fun to “reimagine” a top-end ADL as “ADL-X” with the LITTLE/E Atom cores replaced by corresponding big/P Cores and AVX512 enabled. Would such “beast” be possible?
- Intel says that 4x LITTLE/E Atom cluster = 1x big/P Core die size wise. We replace 8x Atom cores with 2 big/P Cores.
- We thus have 10 Core / 20 Threads ADL-X with AVX512 enabled!
- CometLake desktop (CML) had 10C/20T thus we have a precedent. AMD Ryzen 5950X even has 16C/32T!
- We’ll call this i11 since must be better than 9 – it must go to 11 (yes it’s a This is Spinal Tap reference 😉
- Still Gen 12 but need to increase product number from 900 to… 999?
- Must replace boring K(F) with X (the coolest letter) we end up with the mythical “Intel Core i11-12999X“
- Who says we cannot do marketing?
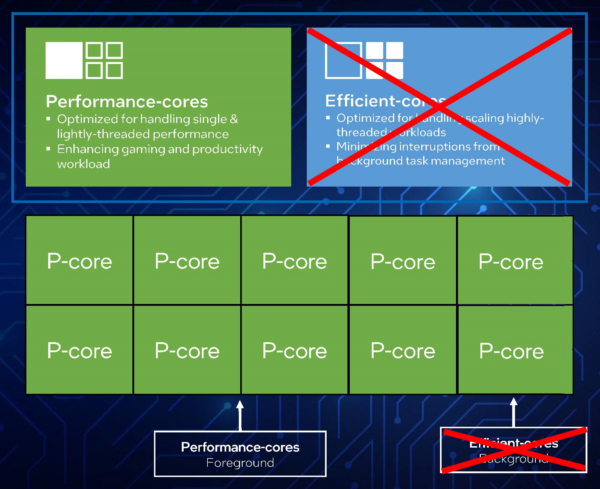
Mythical ADL-X with 10 big/P-Cores / 20 Threads and No Pesky LITTLE/E-Atom cores!
What would be the advantages of this mythical “AlderLake-X”?
Right off the bat we can see quite a few advantages:
- No hybrid architecture required, thus no software changes, current software would just work.
- No need for Windows 11! With some luck even Windows 7 might work just fine.
- AVX512 + new friends in addition to what RKL / ICL-SP (Server IceLake-X) support:
- FP16 – aka “half floating-point” thus possible 2x performance in algorithms where precision can be lowered without adverse effects. Note it also halves the required memory space/bandwidth (16-bit vs. 32-bit)
- Would allow us to test/develop without emulation or perhaps renting (forget buying) a “Sapphire Rapids” server.
- Note it is a complete implementation of current single/double AVX512 instruction set, not just a few conversion/dot instructions like say BF16! You know, Intel, there is more than just “AI” dot-product out there.
- Note that unlike SKL-X and ICL-SP, there is just 1x AVX512/FMA unit, not 2x
- 10 big Cores back at top end rather than 8C with RKL/ADL when AMD competition has 16C!
Hardware Specifications
We are comparing the mythical top-of-the-range Gen 12 Intel with competing architectures as well as competitors (AMD) with a view to upgrading to a top-of-the-range, high performance design.
| Specifications | Mythical Intel Core i11 12999X 10C/20T (ADL-X) AVX512 Projected |
Intel Core i9 12900K 8C+8c/24T (ADL) | Intel Core i9 11900K 8C/16T (RKL) AVX512 |
AMD Ryzen 9 5950X 16C/32T (Zen3) | Comments | |
| Arch(itecture) | Golden Cove / AlderLake-X | Golden Cove + Gracemont / AlderLake | Cypress Cove / RocketLake | Zen3 / Vermeer | The very latest arch | |
| Cores (CU) / Threads (SP) | 10C / 20T | 8C+8c / 24T | 8C / 16T | 2M / 16C / 32T | Less threads, more big Cores. | |
| Rated Speed (GHz) | 3.2 | 3.2 big / 2.4 LITTLE | 3.5 | 3.4 | Assume same base clock | |
| All/Single Turbo Speed (GHz) |
5.0 – 5.2 | 5.0 – 5.2 big / 3.7 – 3.9 LITTLE | 4.8 – 5.3 | 4.9 | Assume same turbo clock | |
| Rated/Turbo Power (W) |
150-300? | 125 – 250 | 125 – 228 | 105 – 135 | We increase TDP a little | |
| L1D / L1I Caches | 10x 48kB / 10x 32kB | 8x 48kB/32kB + 8x 64kB/32kB | 8x 48kB 12-way / 8x 32kB 8-way | 16x 32kB 8-way / 16x 32kB 8-way | L1D is comparable | |
| L2 Caches | 10x 1.25MB (12.5MB) |
8x 1.25MB + 2x 2MB (14MB) | 8x 512kB 16-way (4MB) | 16 512kB 16-way (8MB) | L2 ends up smaller | |
| L3 Cache(s) | 30MB 16-way | 30MB 16-way | 16MB 16-way | 2x 32MB 16-way (64MB) | Keep L3 the same | |
| Microcode (Firmware) | 090672-0F [updated] | 090672-0F [updated] | 06A701-40 | 8F7100-1009 | Same microcode | |
| Special Instruction Sets |
AVX512, VNNI/512, SHA, IFMA52, VAES/512, FP16 | VNNI/256, SHA, VAES/256 | AVX512, VNNI/512, SHA, IFMA52, VAES/512 | AVX2/FMA, SHA | We have AVX512! And FP16. | |
| SIMD Width / Units |
512-bit (1x FMA) | 2x 256-bit | 512-bit (1x FMA) | 2x 256-bit | 2x wider | |
| Price / RRP (USD) |
$799? | $599 | $539 | $799 | Let’s match AMD 5950X | |
Disclaimer
This is an independent article that has not been endorsed nor sponsored by any entity (e.g. Intel). All trademarks acknowledged and used for identification only under fair use.
This article contains speculation with extrapolated results; there is NO such product! It also makes some assumptions and over-simplifications.
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!
Assumptions
- Scaling from 8C/16T to 10C/20T (10/8x) would be linear in the compute heavy SIMD algorithms tested
- The product would not be power limited though its power use may be higher with more big/P Cores
- The product would maintain similar base/turbo clocks despite having more big/P Cores
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets. Mythical “AlderLake” (ADL-X) does support AVX512 just like normal ADL (with LITTLE/E cores disabled).
Note we only present those benchmarks that are compute heavy, vectorised and using AVX512. Benchmarks that are memory latency or bandwidth sensitive are harder to extrapolate as the scaling is not linear, thus we would not expect all (benchmark) scores to just increase by the same ratio.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 11 x64, latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
| Native Benchmarks | Mythical Intel Core i11-12999X 10C/20T (ADL-X) AVX512 Projected |
Intel Core i9-12900K 8C+8c/24T big+LITTLE (ADL) | Intel Core i9-11900K 8C/16T (RKL) AVX512 |
AMD Ryzen 9 5950X 16C/32T (Zen3) | Comments | |
 |
||||||
 |
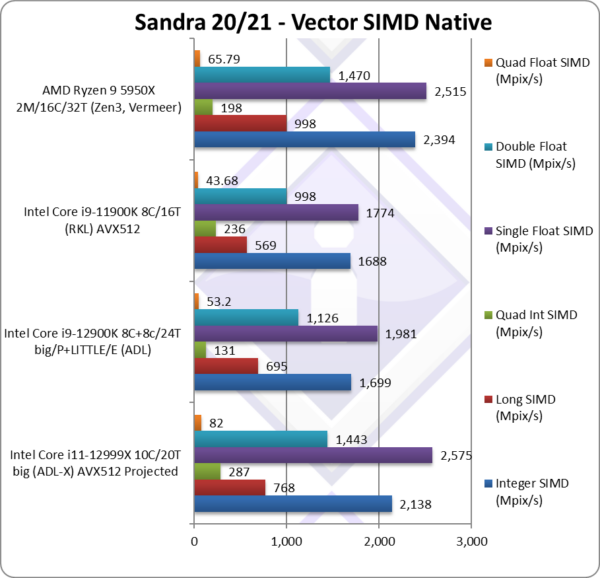
Native Integer (Int32) Multi-Media (Mpix/s) | 2,138*/** [+26%] | 1,699 | 1,688* | 2,394 | ADL-X is 26% faster than ADL still Zen3 wins. |
|
Native Long (Int64) Multi-Media (Mpix/s) | 768*/** [+10%] | 695 | 569* | 998 | With a 64-bit, ADL-X is just 10% faster. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 287*/**/*** [+2.2x] | 131 | 236*/*** | 198 | Using 64-bit int to emulate Int128 ADL-X is over 2x faster! |
|
Native Float/FP32 Multi-Media (Mpix/s) | 2,575*/** [+30%] | 1,981 | 1,774* | 2,515 | In this floating-point vectorised test ADL-X is 30% faster than ADL. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 1,443*/** [+28%] | 1,126 | 998* | 1,470 | Switching to FP64 nothing much changes. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 82*/** [+54%] | 53.2 | 43.68 | 65.79 | Using FP64 to mantissa extend FP128 ADL-X is 54% faster. |
| With heavily vectorised SIMD workloads – with the power of AVX512 our mythical 10C/20T ADL-X trades blows with the 16C/32T Zen3 – with 3 wins each! In general it is about +25-30% faster than real ADL with more cores/threads (8C+8c / 24T).
Where we can deploy specific AVX512 extensions like IFMA52 that don’t exist in AVX2, the improvement is over 2x (twice). FP16 can also bring almost 2x performance improvement over single-precision (32-bit) floating-point! Despite AMD’s Zen3 having far more big cores than Intel can currently muster, it shows that perhaps such a mythical ADL-X with 10 big/P Cores might match it and even beat it in algorithms using AVX512. And no need for the whole hybrid / Windows 11 extensive code changes. Note:* using AVX512 instead of AVX2/FMA. Note:** extrapolated results based on ADL with 8 big/P Cores 16T and AVX512 enabled (but LITTLE/E Atom cores disabled). Note:*** using AVX512-IFMA52 to emulate 128-bit integer (int128) operations. |
||||||
Note we only present those benchmarks that are compute heavy, vectorised and using AVX512. Benchmarks that are memory latency or bandwidth sensitive are harder to extrapolate as the scaling is not linear, thus we would not expect all (benchmark) scores to just increase by the same ratio.
SiSoftware Official Ranker Scores
- 12th Gen Intel Core i9-12900K (8C + 8c / 24T)
- 12th Gen Intel Core i9-12900KF (8C + 8c / 24T)
- 12th Gen Intel Core i7-12700K (8C + 4c / 20T)
- 12th Gen Intel Core i5-12600K (6C + 4c / 16T)
Final Thoughts / Conclusions
Summary: At least we can dream, can’t we?
ADL has been designed for efficiency – not performance at any cost regardless of power usage (like RKL); however, changes to support the hybrid architecture and the loss of AVX512 are non-trivial. And power seems to be increasing still…
With Intel claiming that the 4-LITTLE/E Atom cluster takes the same die space as 1 big/P Core, perhaps a top-end processor (ADL-X) with 10 big/P Cores / 20T could be made. With AVX512 supported by such big/P Cores (but disabled in current ADL) there would be no issues to have it enabled. It even supports brand-new extensions (e.g. FP16, etc.) that can greatly improve performance (~2x) in algorithms where precision can be lowered without adverse effects.
We saw ADL with AVX512 enabled and LITTLE/E Atom cores disabled improve decently over RKL (that has AVX512). Just how well might an ADL-X perform?
Extrapolating from 8C/16T+AVX512 to 10C/20T+AVX512 shows that such a “beast” would perform very well, about 30% faster than real ADL with 8C+8c / 24T despite less threads – and more importantly trade blows with top-end AMD Ryzen 5950X competition despite its 16C/32T!
Summary: At least we can dream, can’t we?
Further Articles
Please see our other articles on:
- CPU
- Cache & Memory
- GP-GPU
Disclaimer
This is an independent article that has not been endorsed nor sponsored by any entity (e.g. Intel). All trademarks acknowledged and used for identification only under fair use.
This article contains speculation with extrapolated results; there is NO such product! It also makes some assumptions and over-simplifications.
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!