What is “ZEN3” (Ryzen 5000)?
AMD’s Zen3 (“Vermeer”) is the 3rd generation ZEN core – aka the new 5000-series of CPUs from AMD, that introduces further refinements of the ZEN(2) core and layout. An APU version (with integrated “NaviX” graphics) is also scheduled to be launched later (as normal) but this time likely to keep the 5000-series moniker. The CPU/APUs remain socket AM4 compatible on desktop – thus allowing in-place upgrade (subject to BIOS upgrade as always) – but series 500-chipsets are recommended to enable all features (e.g. PCIe4, etc.). [Note this is the last CPU that will fit AM4 socket; future CPUs supporting DDR5 need a new socket]
Unlike ZEN2, the main changes are to the core/cache layout but they could still prove significant considering the cache/memory latencies issues that have impacted ZEN designs:
- (AMD) Claims +19% IPC (instructions per clock) overall improvement vs. ZEN2
- Higher base and turbo clocks +5% [for 5850X vs. 3850X]
- Still built around “chiplets” CCX (“core complexes”) but now of 8C/16T and 32MB L3 cache (still 7nm)
- Same central I/O hub with memory controller(s) and PCIe 4.0 bridges connected through IF (“Infinity Fabric”) (12nm)
- Up to 2 chiplets on desktop platform thus up to 2x 8C (16C/32T 5950X)
- L3 is the same 64MB on 5950X but 2x 32MB not 4x 16MB (not fully unified though unlike 8-core and less versions)
- 20 PCIe 4.0 lanes
- 2x DDR4 memory controllers up to 3200Mt/s official (4266Mt/s max) [future AM5 socket for DDR5 support]

2 chiplets, 1 I/O hub
To upgrade from Zen2 (Ryzen 3000) or not?
Micro-architecturally there are more changes that should improve performance and security:
- VAES 256-bit (vs. AES HWA 128-bit) [note that VAES/AVX512 is 512-bit]
- Control Flow Integrity eXtensions (CFX) & Shadow Stacks (SSX)
- Multi-Key Memory Encryption, e.g. individually encrypted VM memory
- Inter-core latencies reduced through shared L3 (8C and less); no more trips to memory to share data
- Ryzen processors have thankfully not been affected by most of the vulnerabilities bar two (BTI/”Spectre”, SSB/”Spectre v4″) that have now been addressed in hardware.
You also need to watch out for the compatibility issues especially for older boards:
- X570, B550 boards need AGESA 1.0.8.0 for Zen3 support
- AGESA 1.1.0.0 Patch C or later recommended
- X570 recommended for 5850X due to better VRMs
- A520 not a good choice for the power hungry 5850X
- X470, B450 boards need at least AGESA 1.0.1.0 to boot Zen3 and won’t receive full support for some time
- X470 recommended for 5850X due to better VRMs
- No PCIe4 support (as with Zen2)
- X370, B350, A320 boards are not likely to be updated for Zen3 and not a good choice for top-end Zen3
In this article we test CPU core performance; please see our other articles on:
- Zen3
- Zen2
Hardware Specifications
We are comparing the top-of-the-range Ryzen 9 5000-series (Zen3 16-core) with previous generation Ryzen 9 3000-series (Zen2 16-core) and competing architectures with a view to upgrading to a similar top-of-the-range design.
| CPU Specifications | AMD Ryzen 9 5950X 16C/32T (Vermeer) |
AMD Ryzen 9 3950X 16C/32T (Matisse) | Intel i9 10900K 10C/20T (CML) 14nm | Intel i9 10940X 14C/28T (CSL-X) | Comments | ||
| Cores (CU) / Threads (SP) | 16C / 32T | 16C / 32T | 10C / 20T | 14C / 28T | Core counts remain the same. | ||
| Topology | 2 chiplet, 2 CCX, each 8 core (16C) + I/O hub | 2 chiplet, 4 CCX, each 4 cores (16C) + I/O hub | Monolithic die | Monolithic die | Large CCX with 8 cores not 4 | ||
| Speed (Min / Max / Turbo) (GHz) |
3.4 / 4.9GHz [+4%] | 3.5 / 4.7GHz | 3.7 / 5.3GHz | 3.3 / 4.6GHz | Turbo only 5% higher. | ||
| Power (TDP / Turbo) (W) |
105W / 142W (PL2) | 105W / 142W (PL2) | 125W / 250W (PL2) | 165W / 308W (PL2) | Same TDP | ||
| L1D / L1I Caches (kB) |
16x 32kB 8-way / 16x 32kB 8-way | 16x 32kB 8-way / 16x 32kB 8-way | 10x 32kB 8-way / 10x 32kB 8-way | 14x 32kB 8-way / 14x 32kB 8-way | No changes to L1 | ||
| L2 Caches (MB) |
16x 512kB (8MB) 8-way inclusive | 16x 512kB (8MB) 8-way inclusive | 10x 256kB (2.5MB) 16-way | 14x 1MB (14MB) 16-way | No changes to L2 | ||
| L3 Caches (MB) |
2x 32MB (64MB) 16-way exclusive | 4x 16MB (64MB) 16-way exclusive | 20MB 16-way | 19.25MB 11-way | 2 L3 slices not 4. | ||
| Mitigations for Vulnerabilities | BTI/”Spectre”, SSB/”Spectre v4″ hardware | BTI/”Spectre”, SSB/”Spectre v4″ hardware | RDCL/”Meltdown”, L1TF hardware, BTI/”Spectre”, MDS/”Zombieload”, software/firmware | RDCL/”Meltdown” , L1TF, BTI/”Spectre”, MDS/”Zombieload”, all software/firmware | No new fixes required… yet! | ||
| Microcode (MU) |
MU-xxx | MU-8F7100-11 | MU-069E0C-9E | MU-065507-01 | The latest microcodes have been loaded. | ||
| SIMD Units | 256-bit AVX/FMA3/AVX2 | 256-bit AVX/FMA3/AVX2 | 256-bit AVX/FMA3/AVX2 | 512-bit AVX512 | Same SIMD widths | ||
| Price/RRP (USD) | $800 [+7%] | $750 | $490 | $780 | Modest price increase +7% but most expensive now. | ||
Disclaimer
This is an independent article that has not been endorsed nor sponsored by any entity (e.g. AMD). All trademarks acknowledged and used for identification only under fair use. Errors and omissions excepted (E&OE).
The article contains only public information (available elsewhere on the Internet) and not provided under NDA nor embargoed. At publication time, not all products have been directly tested by SiSoftware, thus the accuracy of the benchmark scores cannot be verified; however, they appear consistent and do not appear to be false/fake.
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (AVX2, FMA3, AVX, etc.). Zen3 supports all modern instruction sets including AVX2, FMA3 and even more like SHA HWA but not AVX-512.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations. All mitigations for vulnerabilities (Meltdown, Spectre, L1TF, MDS, etc.) were enabled as per Windows default where applicable.
| Native Benchmarks | AMD Ryzen 9 5950X 16C/32T (Vermeer) | AMD Ryzen 9 3950X 16C/32T (Matisse) | Intel i9 10900K 10C/20T (CML) | Intel i9 10940X 14C/28T (CSL-X) | Comments | |
 |
||||||
 |
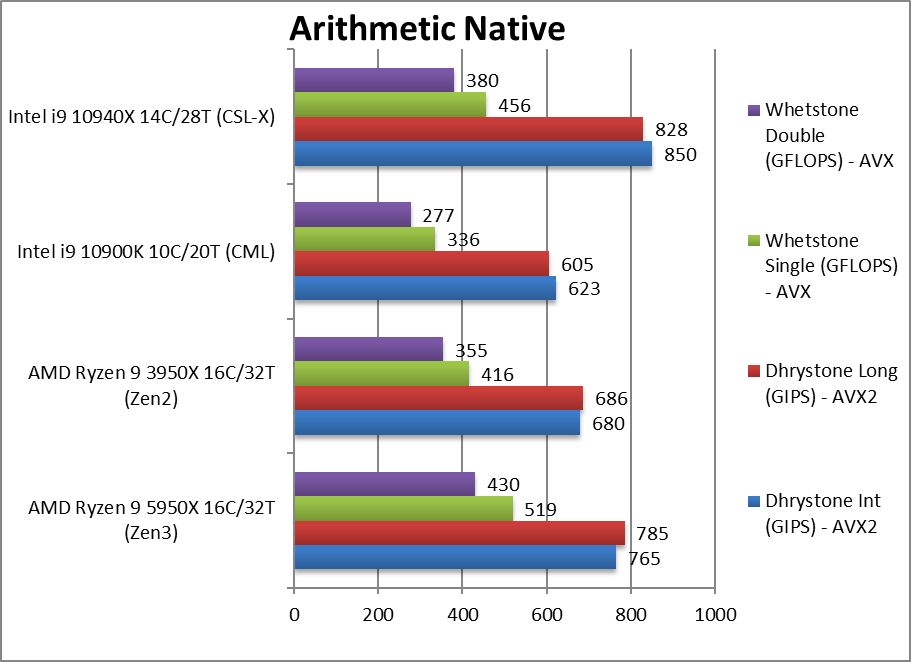
Native Dhrystone Integer (GIPS) | 765 [+13%] | 680 | 623 | 850 | Zen3 starts strongly with 13% faster than Zen2 in this legacy integer benchmark. |
|
Native Dhrystone Long (GIPS) | 785 [+14%] | 686 | 605 | 828 | With a 64-bit integer workload still 14% improvement. |
|
Native FP32 (Float) Whetstone (GFLOPS) | 519 [+25%] | 416 | 336 | 456 | Floating-point performance is even better, 25% better than Zen2! |
|
Native FP64 (Double) Whetstone (GFLOPS) | 430 [+21%] | 355 | 277 | 380 | With FP64 nothing much changes again. |
| Zen3 improves by a decent 13-25 over Zen2 in legacy integer/floating-point benchmarks, a good improvement. This means it may (still) not beat all the other CPUs but with cooling and higher Turbo it should have no problems. | ||||||
 |
||||||
 |
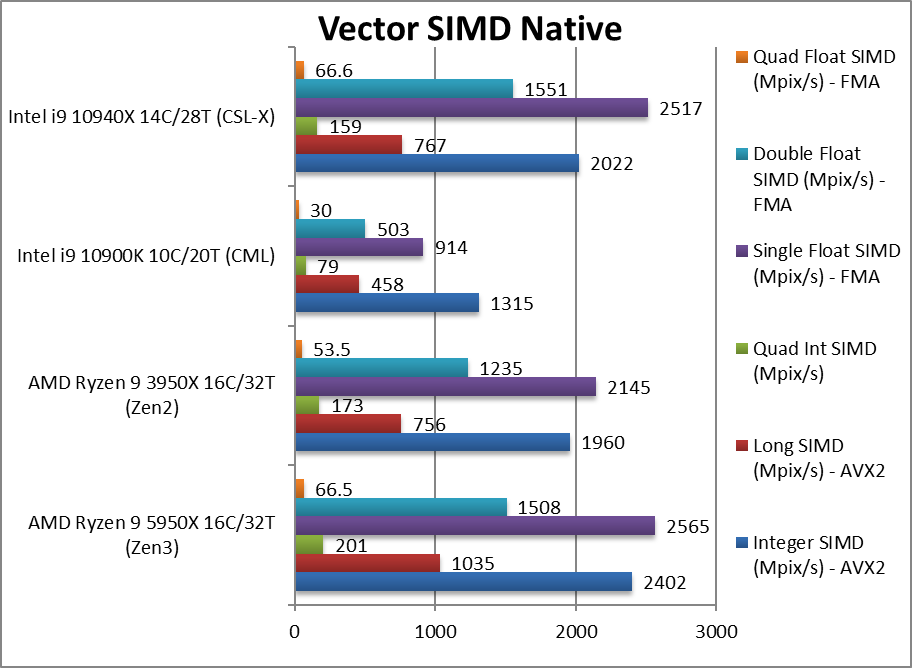
Native Integer (Int32) Multi-Media (Mpix/s) | 2,402 [+23%] | 1,960 | 1,315 | 2,022* | Zen3 is 23% over Zen2 despite same width SIMD units. |
|
Native Long (Int64) Multi-Media (Mpix/s) | 1,035 [+37%] | 756 | 458 | 767* | With a 64-bit AVX2 integer vectorised workload, Zen3 is 37% faster. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 201 [+16%] | 173 | 79 | 159* | This is a tough test using Long integers to emulate Int128 (now vectorised), Zen3 is still 16% faster. |
|
Native Float/FP32 Multi-Media (Mpix/s) | 2,565 [+20%] | 2,145 | 914 | 2,517* | In this floating-point AVX/FMA vectorised test, Zen3 is again 20% faster than Zen2. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 1,508 [+22%] | 1,235 | 503 | 1,551* | Switching to FP64 SIMD code, Zen3 is 22% faster. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 66.5 [+24%] | 53.5 | 30 | 66.6* | In this heavy algorithm using FP64 to mantissa extend FP128, Zen3 still manages to be 24% faster. |
| While Zen2 with its new 256-bit wide SIMD units was almost 2x faster (+100%) than Zen1/+, Zen 3 still manages to improve anywhere between 16-37%, similar to what we’ve seen in legacy benchmarks. While SIMD workloads were Intel’s strenghts, Zen3 manages to beat even AVX512 14-core CSL-X with its 2x 512-bit wide SIMD units! It seems that there’s nothing stopping Zen3!
Note*: using AVX512 instead of AVX2/FMA3. Note**: test has been rewritten in Sandra 20/20 R9: now vectorised and AVX512-IFMA enabled – see AVX512-IFMA(52) Improvement for IceLake and TigerLake article. |
||||||
 |
||||||
 |
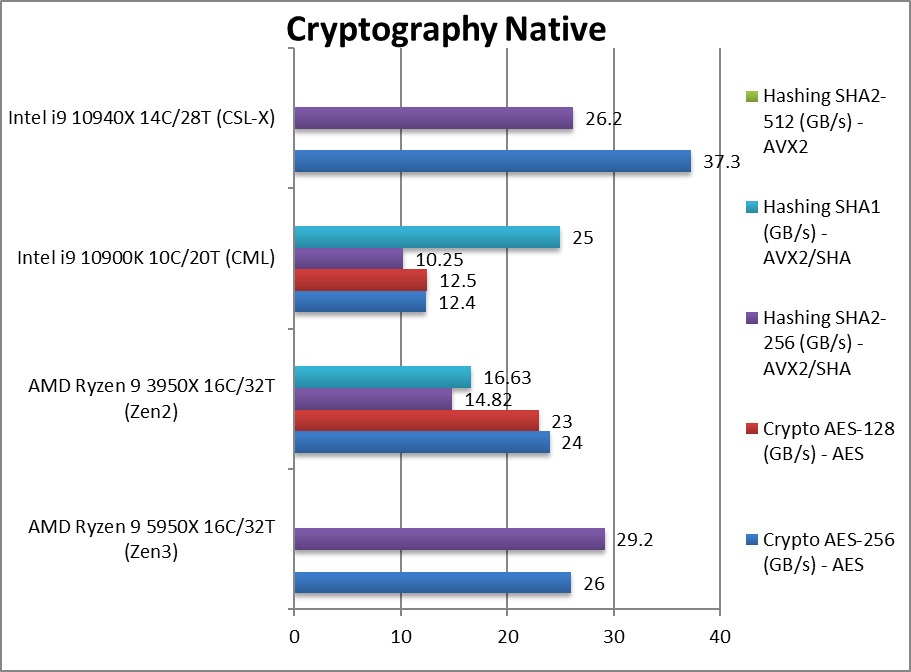
Crypto AES-256 (GB/s) | 26*** [+8%] | 24 | 12.4 | 37.3*** | With AES/HWA support all CPUs are memory bandwidth bound but Zen3 manages a 8% improvement. |
|
Crypto AES-128 (GB/s) | 26*** [+13%] | 23 | 12.5 | 37.4*** | What we saw with AES-256 just repeats with AES-128. |
|
Crypto SHA2-256 (GB/s) | 29.2** [+97%] | 14.82** | 10.25 | 26.2* | With SHA/HWA Zen3 similarly powers through hashing tests leaving Intel in the dust. |
|
Crypto SHA1 (GB/s) | ** | 16.63** | 25 | * | The less compute-intensive SHA1 does not change things due to acceleration. |
|
Crypto SHA2-512 (GB/s) | ** | ** | * | – | |
| While streaming tests (crypto/hashing) are memory bound, Zen3 still manages a decent 8-13% improvement over Zen2. With SHA HWA it even beats Intel’s CSL-X with AVX512. However, it is clear that we need either more memory channels or much faster memory to make use of all those 16-cores.
Note***: using VAES 256-bit (AVX2) or 512-bit (AVX512) Note**: using SHA HWA not SIMD (e.g. AVX512, AVX2, AVX, etc.) Note*: using AVX512 not AVX2. |
||||||
 |
||||||
 |
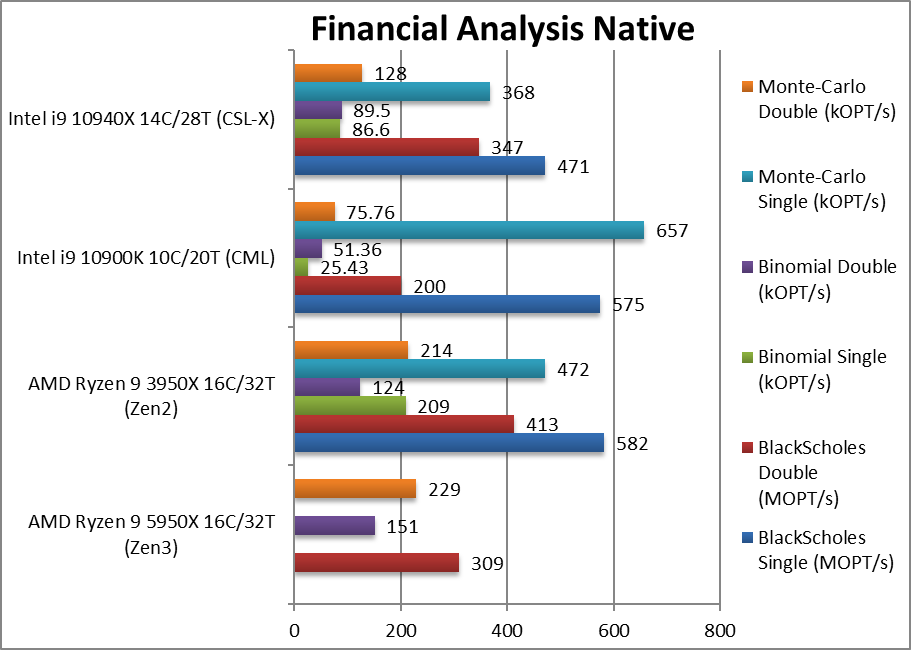
Black-Scholes float/FP32 (MOPT/s) | 582 | 575 | 471 | The stadard financial algorithm. | |
|
Black-Scholes double/FP64 (MOPT/s) | 309 [-25%] | 413 | 200 | 347 | Switching to FP64 code, we seem to have an outlier here. |
|
Binomial float/FP32 (kOPT/s) | 209 | 25.43 | 86.6 | Binomial uses thread shared data thus stresses the cache & memory system; | |
|
Binomial double/FP64 (kOPT/s) | 151 [+22%] | 124 | 51.36 | 89.5 | With FP64 code Zen3 is now 22% faster. |
|
Monte-Carlo float/FP32 (kOPT/s) | 472 | 657 | 368 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches; | |
|
Monte-Carlo double/FP64 (kOPT/s) | 229 [+7%] | 214 | 75.76 | 128 | Zen3 is a modest 7% faster here. |
| Ryzen always did well on non-SIMD floating-point algorithms and here it further cements its dominance: we do have a few outlier scores which may indicate scaling issues that need to be addressed either by our software or Windows (scheduler). In any case, even the outliers show that Intel’s CML core cannot compete with modern AMD Zen cores. | ||||||
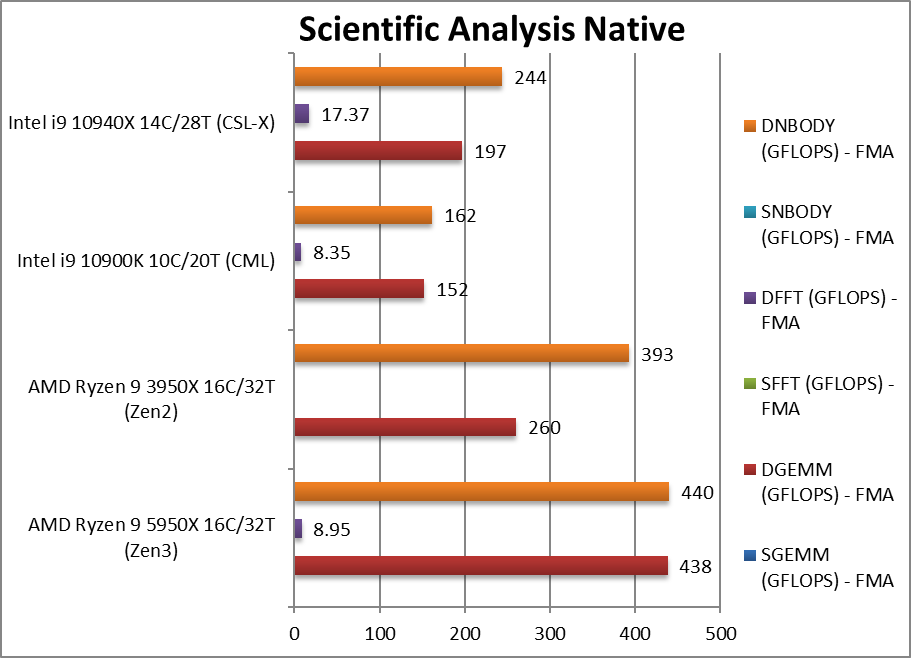 |
||||||
 |
SGEMM (GFLOPS) float/FP32 | In this tough vectorised algorithm that is widely used (e.g. AI/ML). | ||||
|
DGEMM (GFLOPS) double/FP64 | 438 [+68%] | 260 | 152 | 197* | With FP64 vectorised code, Zen3 is still 68% faster. |
|
SFFT (GFLOPS) float/FP32 | FFT is also heavily vectorised but stresses the memory sub-system more. | ||||
|
DFFT (GFLOPS) double/FP64 | 8.95 | 8.35 | With FP64 code, Zen3 still memory access bound. | ||
|
SNBODY (GFLOPS) float/FP32 | N-Body simulation is vectorised but fewer memory accesses. | ||||
|
DNBODY (GFLOPS) double/FP64 | 440 [+12%] | 393 | 162 | 244* | With FP64 precision ZEN2 is only 12% faster. |
| With highly vectorised SIMD code Zen3 still improves by a decent amount, although memory-access latency sensitive algorithms (not streaming) like FFT/N-Body are still problematic. GEMM is widely used in convolution (e.g. neural-networks AI/ML, image processing) and here Zen3 is much faster.
Note*: using AVX512 not AVX2/FMA3. |
||||||
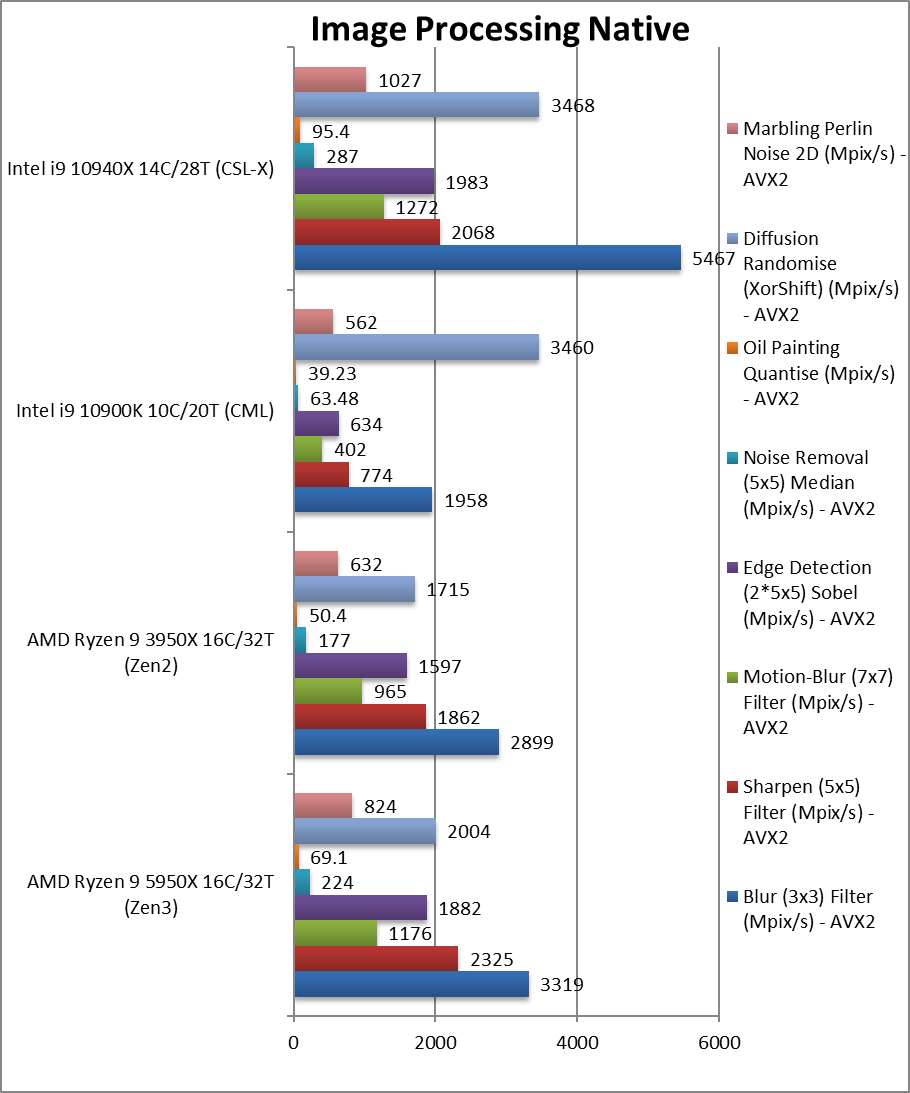 |
||||||
 |
Blur (3×3) Filter (MPix/s) | 3,319 [+14%] | 2,899 | 1,958 | 5,467* | In this vectorised integer workload Zen3 starts 14% faster than Zen2. |
|
Sharpen (5×5) Filter (MPix/s) | 2,325 [+25%] | 1,862 | 774 | 2,068* | Same algorithm but more shared data makes Zen3 25% faster. |
|
Motion-Blur (7×7) Filter (MPix/s) | 1,176 [+22%] | 965 | 402 | 1,272* | Again same algorithm but even more data shared still 22% faster |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 1,882 [+18%] | 1,597 | 634 | 1,983* | Different algorithm but still vectorised workload Zen3 is 18% faster. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 224 [+27%] | 177 | 63.48 | 287* | Still vectorised code but Zen3 is “only” 27% faster. |
|
Oil Painting Quantise Filter (MPix/s) | 69.1 [+37%] | 50.4 | 39.23 | 95.4* | This test has always been tough for Ryzen but Zen3 still manages 37% improvement! |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 2,004 [+17%] | 1,715 | 3,460 | 3,468* | With integer workload, Intel CPUs seem to do much better but Zen3 is still 17% faster than Zen2. |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 824 [+30%] | 632 | 562 | 1,027* | In this final test again with integer workload Zen3 is 30% faster. |
| While Zen2 brought almost 2x improvement due to its 256-bit wide SIMD units, Zen3 still manages anywhere between 14-37% improvement; here AVX512 coupled with 4-memory channels does show its power and Zen3 is unable to beat Intel’s CSL-X in most tasks. It really need more memory bandwidth.
Note*: using AVX512 not AVX2/FMA3. |
||||||
 |
||||||
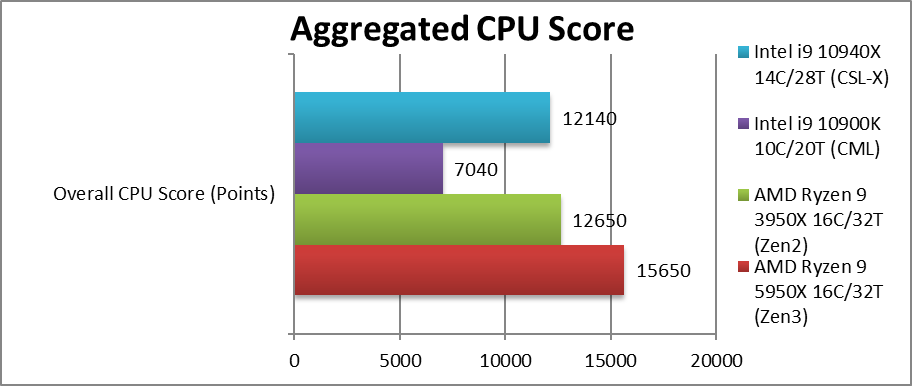
 |
Aggregate Score (Points) | 15,650 [+24%] | 12,650 | 7,040 | 12,140* | Across all benchmarks, Zen3 (16C) is 24% faster than Zen2! |
| Zen3 (16C) is 24% faster than previous Zen2 (16C) and now comfortably beats CSL-X even with AVX512. This is pretty much the highest compute performance you can get on a desktop today without getting into work-station/HEDT range and far more money (e.g. ThreadRipper).
Note*: using AVX512 not AVX2/FMA3. |
||||||
 |
||||||
 |
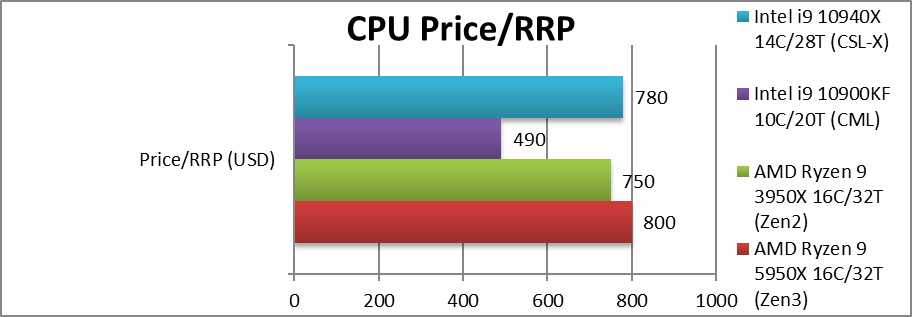
Price/RRP (USD) | $800 [+7%] |
$750 [likely to be higher now] | $490 | $780 | Unlike other Zen3 CPUs, 5950X had a modest 7% price increas only. |
 |
||||||
|
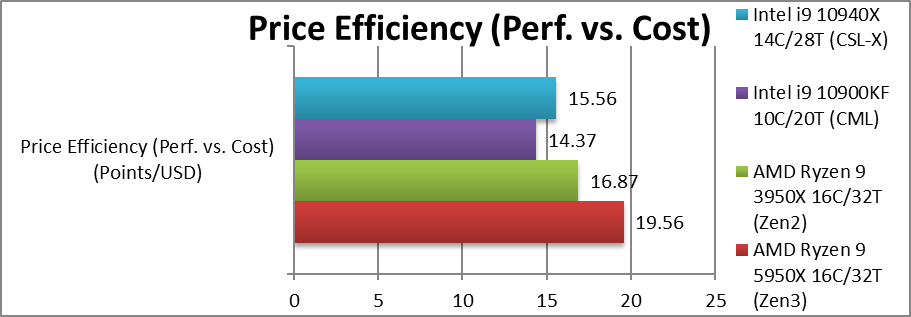
Price Efficiency (Perf. vs. Cost) (Points/USD) | 19.56 [+16%] |
16.86 | 14.36 | 15.56 | Zen3 is 16% more price efficient than Zen2 and much better than Intel. |
| Unlike other Zen3 CPUs (e.g. 5600X), the 5850X has had a modest (+$50) price increase which allows it to be 16% more performance/cost efficient (than Zen2, 3850X) which is great news all round. Due to the pandemic and high demand the cost of old 3000-series is much higher now than RRP (e.g. +50$) which makes the new 5000-series even more attractive.
While Intel seems very price inefficient based on RRP, the CPU cost is generally less than RRP today and likely to be reduced further soon. |
||||||
 |
||||||
 |
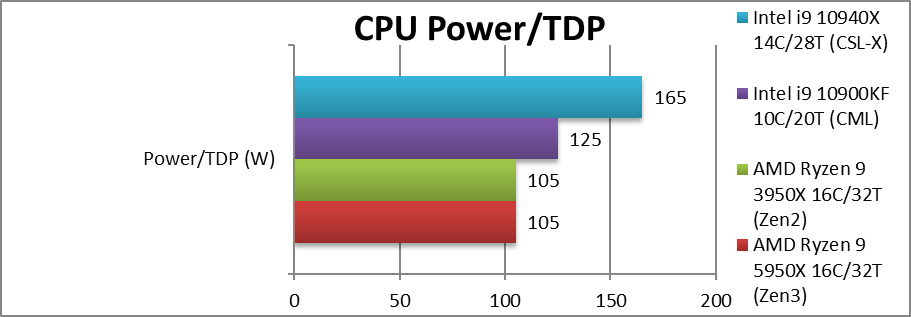
Power/TDP (W) | 105 [=] (142 PL2 turbo) |
105 (142 PL2 turbo) | 125 (250 PL2 turbo) | 165 (308 PL2 turbo) | Zen3 keeps the same TDP as Zen2. |
 |
||||||
|
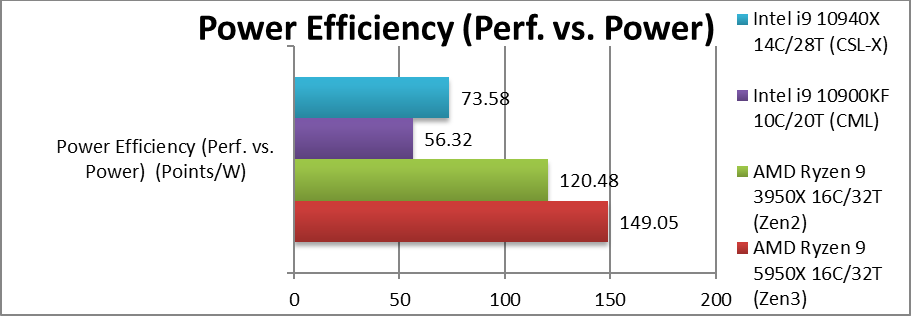
Power Efficiency (Perf. vs. Power) (W) | 149.05 [+24%] |
120.48 | 56.32 | 73.58 | Due to the same TDP, Zen3 is 24% more power efficient. |
| With the same TDP and improved performance, Zen3 (5950X) is far more power efficient than all competition: as much as 3x more power efficient than CML (10900KF)! This shows just how much performance has been packed into the AM4 socket. | ||||||
SiSoftware Official Ranker Scores
- AMD Ryzen 9 5950X 16-Core/32-Threads
- AMD Ryzen 7 5800X 8-Core/16-Threads
- AMD Ryzen 5 5600X 6-Core/12-Threads
Final Thoughts / Conclusions
Executive Summary: Zen3 (5850X, 16C) is ~24% faster than Zen2 (3850X, 16C) across all kinds of algorithms but only 7% more expensive. Fastest desktop compute deserves 10/10!
Unlike the 8-core and less Zen3 designs with unified L3 cache, the 12/16C Zen3 (e.g. 59XX range) still has separate L3 caches but now one for 8-cores not 4. Thus we thought it will improve a bit over Zen2 (16C) but not buy much. But it still manages to be a whopping 24% faster across all benchmarks.
This is the pinnacle of compute performance on the desktop – all still on the old AM4 socket (with a BIOS update) – without spending serious money on work-station/HEDT kit. Not that the 5950X (like the 3950X before it) is “cheap” but considering what HEDT platform costs (e.g. ThreadRipper, Intel’s 2011 socket, etc.) it is good value. The 5950X is so powerful that even AVX512 Intel high-end CPUs cannot beat it – and even old ThreadRippers (e.g. 1950X, 2990X) are beaten in compute tasks.
About the only issue is that it is still stuck with 2-channel DDR4 memory that even at high speeds (e.g. expensive 4266Mt/s) cannot feed 16-cores / 32-threads in streaming algorithms despite the absolutely massive 64MB L3 cache. Intel’s HEDT platform with 4-channel DDR4 + AVX512 is able to beat it in those kinds of algorithms.
DDR5 cannot come soon enough – but that will require a new platform (AM5 socket). Such high-end CPU should also be ideally paired with a good mainboard (e.g. X570) with PCIe4 as here it is likely to make a difference – again feeding all those cores.
If you have the money and the need for top-end compute performance and somehow cannot afford HEDT platform then this is the best you can get by a long shot. Best in class.
Please see our other articles on Zen3 performance:
- Zen3
- AMD Ryzen 7 5800X (Zen3) Review & Benchmarks – Cache and Memory Performance
- AMD Ryzen 7 5800X (Zen3) – CPU 8-core/16-thread Performance
- AMD Ryzen 5 5600X (Zen3) – CPU 6-core/12-thread Performance
- Zen2
Disclaimer
This is an independent article that has not been endorsed nor sponsored by any entity (e.g. AMD). All trademarks acknowledged and used for identification only under fair use. Errors and omissions excepted (E&OE).
The article contains only public information (available elsewhere on the Internet) and not provided under NDA nor embargoed. At publication time, not all products have been directly tested by SiSoftware, thus the accuracy of the benchmark scores cannot be verified; however, they appear consistent and do not appear to be false/fake.