What is “AlderLake”?
It is the “next-generation” (12th) Core architecture – replacing the short-lived “RocketLake” (RKL) that finally replaced the many, many “Skylake” (SKL) derivative architectures (6th-10th). It is the 1st mainstream “hybrid” arch – i.e. combining big/P(erformant) “Core” cores with LITTLE/E(fficient) “Atom” cores in a single package. While in the ARM world such SoC designs are quite common, this is quite new for x86 – thus operating systems (Windows) and applications may need to be updated.
For more details, please see our Intel 12th Gen Core AlderLake (i9-12900K) Review & Benchmarks – big/LITTLE Performance review. In this article we deal exclusively with the big/P “Core” cores.
big/P(erformance) “Core” core
- Up to 8C/16T “Golden Cove” cores 7nm – improved from “Willow Cove” in TGL – claimed +19% IPC uplift
- Disabled AVX512! in order to match Atom cores (on consumer)
- (Server versions support AVX512 and new extensions like AMX and FP16 data-format)
- SMT support still included, 2 threads/core – thus 16 total
- 6-wide decode (from 4-way until now) + many other front-end upgrades
- L1I remains at 32kB but iTLB increased 2x (256 vs. 128)
- L1D remains at 48kB but dTLB increased 50% (96 vs. 64)
- L2 increased to 1.25MB per core (over 2x TGL of 512kB) – server versions 2MB
The big news – beside the hybrid arch – is that AVX512 supported by desktop/mobile “Ice Lake” (ICL), “Tiger Lake” (TGL) and “Rocket Lake” (RKL) – is no longer enabled on “Alder Lake” big/P cores in order to match the Atom LITTLE/E cores. Future HEDT/server versions with presumably only big/P cores should support it just like Ice Lake-X (ICL-X).
Note: It seems that AVX512 can be enabled on big/P Cores (at least for now) on some mainboards that provide such a setting; naturally LITTLE/E Atom cores need to be disabled. We plan to test this ASAP.
In order to somewhat compensate – there are now AVX2 versions of AVX512 extensions:
- VNNI/256 – (Vector Neural Network Instructions, dlBoost FP16/INT8) e.g. convolution
- VAES/256 – (Vector AES) accelerating block-crypto
- SHA HWA accelerating hashing (SHA1, SHA2-256 only)
We saw in the “RocketLake” review (Intel 11th Gen Core RocketLake AVX512 Performance Improvement vs AVX2/FMA3) that AVX512 makes RKL almost 40% faster vs. AVX2/FMA3 – and despite its high power consumption – it made RKL competitive. Without it – RKL with 2 less cores than “Comet Lake” (CML) would have not sufficiently improved to be worth it.
At SiSoftware – with Sandra – we naturally adopted and supported AVX512 from the start (before SKL-X) and added support for various new extensions as they were added in subsequent cores (VAES, IFMA52, VNNI, BF16, etc.) – this is even more disappointing; while it is not a problem to add AVX2 versions (e.g. VAES, VNNI) the performance cannot be expected to match the AVX512 original versions.
Let’s note that originally AVX512 launched with the Atom-core powered “Phi” GP-GPU accelerators (“Knights Landing” KNI) – thus it would not have been impossible for Intel to add support to the new Atom core – and perhaps we shall see that in future arch… when an additional compute performance uplift will be required (i.e. deal with AMD competition).
Only big/P Cores, LITTLE/E Atom disabled
Changes in Sandra to support Hybrid
Like Windows (and other operating systems), we have had to make extensive changes to both detection, thread scheduling and benchmarks to support hybrid/big-LITTLE. Thankfully, this means we are not dependent on Windows support – you can confidently test AlderLake on older operating systems (e.g. Windows 10 or earlier – or Server 2022/2019/2016 or earlier) – although it is probably best to run the very latest operating systems for best overall (outside benchmarking) computing experience.
- Detection Changes
- Detect big/P and LITTLE/E cores
- Detect correct number of cores (and type), modules and threads per core -> topology
- Detect correct cache sizes (L1D, L1I, L2) depending on core
- Detect multipliers depending on core
- Scheduling Changes
- “All Threads (MT/MC)” (thus all cores + all threads – e.g. 24T
- “All Cores (MC aka big+LITTLE) Only” (both core types, no threads) – thus 16T
- “All Threads big/P Cores Only” (only “Core” cores + their threads) – thus 16T
- “big/P Cores Only” (only “Core” cores) – thus 8T
- “LITTLE/E Cores Only” (only “Atom” cores) – thus 8T
- “Single Thread big/P Core Only” (thus single “Core” core) – thus 1T
- “Single Thread LITTLE/E Core Only” (thus single “Atom” core) – thus 1T
- “All Threads (MT/MC)” (thus all cores + all threads – e.g. 24T
- Benchmarking Changes
- Dynamic/Asymmetric workload allocator – based on each thread’s compute power
- Note some tests/algorithms are not well-suited for this (here P threads will finish and wait for E threads – thus effectively having only E threads). Different ways to test algorithm(s) will be needed.
- Dynamic/Asymmetric buffer sizes – based on each thread’s L1D caches
- Memory/Cache buffer testing using different block/buffer sizes for P/E threads
- Algorithms (e.g. GEMM) using different block sizes for P/E threads
- Best performance core/thread default selection – based on test type
- Some tests/algorithms run best just using cores only (SMT threads would just add overhead)
- Some tests/algorithms (streaming) run best just using big/P cores only (E cores just too slow and waste memory bandwidth)
- Some tests/algorithms sharing data run best on same type of cores only (either big/P or LITTLE/E) (sharing between different types of cores incurs higher latencies and lower bandwidth)
- Reporting the Compute Power Contribution of each thread
- Thus the big/P and LITTLE/E cores contribution for each algorithm can be presented. In effect, this allows better optimisation of algorithms tested, e.g. detecting when either big/P or LITTLE/E cores are not efficiently used (e.g. overloaded)
- Dynamic/Asymmetric workload allocator – based on each thread’s compute power
As per above you can be forgiven that some developers may just restrict their software to use big/Performance threads only and just ignore the LITTLE/Efficient threads at all – at least when using compute heavy algorithms.
For this reason we recommend using the very latest version of Sandra and keep up with updated versions that likely fix bugs, improve performance and stability.
CPU (big Core) Performance Benchmarking
In this article we test CPU big Core performance; please see our other articles on:
- CPU
- Intel 12th Gen Core AlderLake Mobile (i7-12700H) Review & Benchmarks – big/LITTLE Performance
- Intel 12th Gen Core AlderLake (i9-12900K) Review & Benchmarks – big/LITTLE Performance
- Intel 11th Gen Core RocketLake AVX512 Performance Improvement vs AVX2/FMA3
- Intel 11th Gen Core RocketLake (i7-11700K) Review & Benchmarks – CPU AVX512 Performance
- Cache & Memory
- GP-GPU
Hardware Specifications
We are comparing the mythical top-of-the-range Gen 12 Intel with competing architectures as well as competitors (AMD) with a view to upgrading to a top-of-the-range, high performance design.
| Specifications | Intel Core i9 12900K 8C+8c/24T (ADL) big+LITTLE |
Intel Core i9 12900K 8C/16T (ADL) big ONLY – no AVX512 |
Intel Core i9 11900K 8C/16T (RKL) – no AVX512 |
AMD Ryzen 9 5900X 12C/24T (Zen3) | Comments | |
| Arch(itecture) | Golden Cove + Gracemont / AlderLake | Golden Cove / AlderLake | Cypress Cove / RocketLake | Zen3 / Vermeer | The very latest arch | |
| Cores (CU) / Threads (SP) | 8C+8c / 24T | 8C / 16T | 8C / 16T | 2M / 12C / 24T | 8 more LITTLE cores | |
| Rated Speed (GHz) | 3.2 big / 2.4 LITTLE | 3.2 big | 3.5 | 3.7 | Base clock is a bit higher | |
| All/Single Turbo Speed (GHz) |
5.0 – 5.2 big / 3.7 – 3.9 LITTLE | 5.0 – 5.2 big | 4.8 – 5.3 | 4.5 – 4.8 | Turbo is a bit lower | |
| Rated/Turbo Power (W) |
125 – 250 | 125 – 250 | 125 – 228 | 105 – 135 | TDP is the same on paper. | |
| L1D / L1I Caches | 8x 48kB/32kB + 8x 64kB/32kB |
8x 48kB/32kB | 8x 48kB 12-way / 8x 32kB 8-way | 12x 32kB 8-way / 12x 32kB 8-way | L1D is 50% larger. | |
| L2 Caches | 8x 1.25MB + 2x 2MB (14MB) |
8x 1.25MB (10MB) | 8x 512kB 16-way (4MB) | 12x 512kB 16-way (6MB) | L2 has almost doubled | |
| L3 Cache(s) | 30MB 16-way | 20MB 16-way | 16MB 16-way | 2x 32MB 16-way (64MB) | L3 is almost 2x larger | |
| Microcode (Firmware) | 090672-0F [updated] | 090672-0F [updated] | 06A701-40 | 8F7100-1009 | Revisions just keep on coming. | |
| Special Instruction Sets |
VNNI/256, SHA, VAES/256 (AVX512 disabled) | VNNI/256, SHA, VAES/256 (AVX512 disabled) | SHA, VAES/256 (AVX512 disabled) |
AVX2/FMA, SHA | Losing AVX512 | |
| SIMD Width / Units |
256-bit | 256-bit (AVX512 disabled) | 256-bit (AVX512 disabled) | 256-bit | Same width SIMD units | |
| Price / RRP (USD) |
$599 | $599 | $539 | $549 | Price is a little higher. | |
Disclaimer
This is an independent review (critical appraisal) that has not been endorsed nor sponsored by any entity (e.g. Intel, etc.). All trademarks acknowledged and used for identification only under fair use.
The review contains only public information and not provided under NDA nor embargoed. At publication time, the products have not been directly tested by SiSoftware but submitted to the public Benchmark Ranker; thus the accuracy of the benchmark scores cannot be verified, however, they appear consistent and pass current validation checks.
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets. “AlderLake” (ADL) does not support AVX512 – but it does support 256-bit versions of some original AVX512 extensions.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 11 x64, latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations.
| Native Benchmarks | Intel Core i9 12900K 8C+8c/24T (ADL) big+LITTLE | Intel Core i9 12900K 8C/16T (ADL) big ONLY | Intel Core i9 11900K 8C/16T (RKL) – no AVX512 | AMD Ryzen 9 5900X 12C/24T (Zen3) | Comments | |
 |
||||||
 |
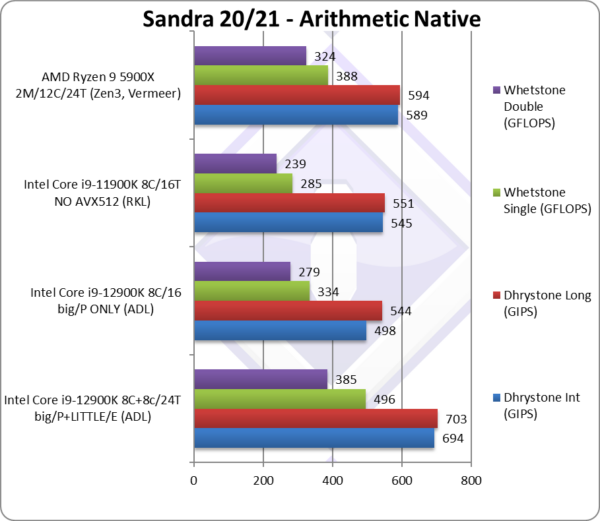
Native Dhrystone Integer (GIPS) | 694 | 498 [72%] | 545 | 589 | ADL’s big Cores provide 72% of overall performance. |
|
Native Dhrystone Long (GIPS) | 703 | 544 [77%] | 551 | 594 | A 64-bit integer workload increases ratio to 77%. |
|
Native FP32 (Float) Whetstone (GFLOPS) | 496 | 334 [67%] | 285 | 388 | With floating-point, ADL’s big Cores provide only 67%. |
|
Native FP64 (Double) Whetstone (GFLOPS) | 385 | 279 [72%] | 239 | 324 | With FP64 the ratio is back to 72%. |
| To start, in legacy integer/floating-point code, we see the big/P Cores in ADL provide about 70% of overall performance; thus the LITTLE/E Atom cores contribute about 30%. This is just enough to beat both RKL and Zen3 competition.
Without them, and thus just with the big/P Cores, ADL would be about 16% faster than RKL – which is just a bit less than what Intel claims (19% uplift). So while the big/P Cores have been improved, the difference is perhaps not as high as expected considering all the changes (2 generations’ updates, process shrink, etc.) Note that due to being “legacy” none of the benchmarks support AVX512; while we could update them, they are not vectorise-able in the “spirit they were written” – thus single-lane AVX512 cannot run faster than AVX2/SSEx. |
||||||
 |
||||||
 |
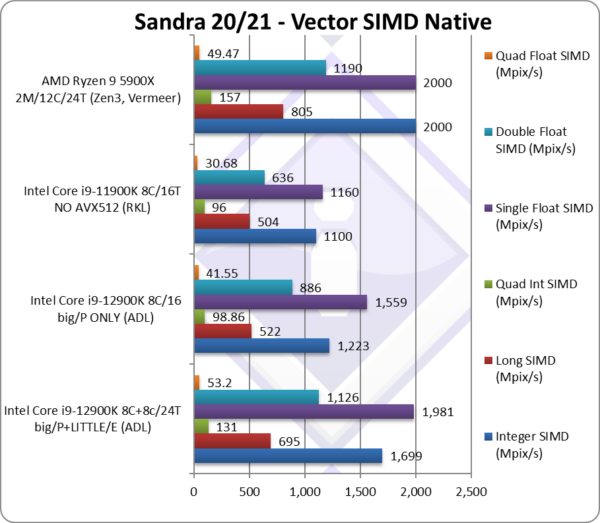
Native Integer (Int32) Multi-Media (Mpix/s) | 1,699 | 1,223 [72%] | 1,100 | 2,000 | big Cores provide 72% of performance. |
|
Native Long (Int64) Multi-Media (Mpix/s) | 695 | 522 [75%] | 504 | 805 | With a 64-bit, the ratio goes to 75%. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 131 | 98.86 [75%] | 96 | 157 | Using 64-bit int to emulate Int128 nothing changes. |
|
Native Float/FP32 Multi-Media (Mpix/s) | 1,981 | 1,559 [79%] | 1,160 | 2,000 | In this floating-point vectorised test big Cores provide 79%. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 1,126 | 866 [79%] | 636 | 1,190 | Switching to FP64 nothing much changes. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 53.2 | 41.55 [78%] | 30.68 | 49.47 | Using FP64 to mantissa extend FP128 ratio falls to 78%. |
| With heavily vectorised SIMD workloads – even without AVX512 support – ADL’s big/P Cores provide about 80% of overall performance (vs. 70% with legacy integer/floating-point code as we’ve seen before); thus the LITTLE/E Atom cores provide only about 20% of performance.
This does make sense, as while the LITTLE/E Atom cores now support AVX2/FMA3, they cannot really match the SIMD units of the big/P Cores, thus despite the count being the same (8C vs. 8c) their contribution falls to just 20%. Still, 20% is not to be ignored and it does help ADL get much closer to its Zen3 competition which naturally cannot beat. Against RKL – not using AVX512 – the ADL’s big/P cores are about 35% faster (same number of Cores/threads) which is a pretty big improvement (2 generations’ worth). Naturally, RKL does have AVX512 that when used makes it about 40% faster (as we’ve seen in our article) – thus ADL would have still ended up slower than RKL with/AVX512 that is a big loss. |
||||||
 |
||||||
 |
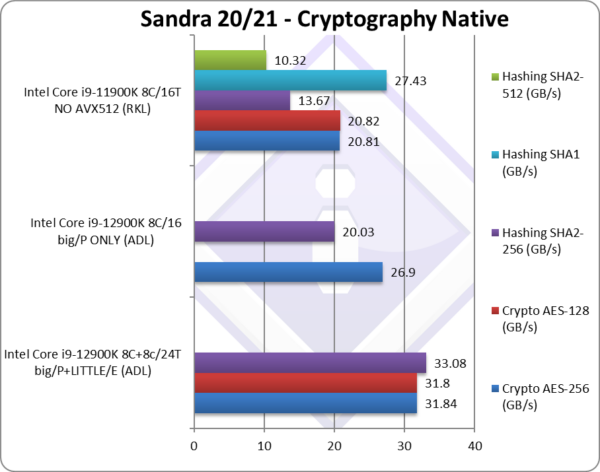
Crypto AES-256 (GB/s) | 31.84* | 26.9* [85%] | 20.81* | 18.74 | DDR5 memory rules here whatever core type. |
|
Crypto AES-128 (GB/s) | 31.8* | 20.82* | 18.7 | No change with AES128. | |
|
Crypto SHA2-256 (GB/s) | 33.08** | 20.03** [61%] | 13.67** | 37** | With compute, big Cores provide just 60%. |
|
Crypto SHA1 (GB/s) | 27.43** | 39.08** | Less compute intensive SHA1. | ||
|
Crypto SHA2-512 (GB/s) | 10.32 | 16.56 | SHA2-512 is not accelerated by SHA HWA. | ||
| The memory sub-system is crucial here, and these (streaming) tests show that using SMT threads is just not worth it. As both big/P Cores and LITTLE/E Atom cores support VAES/AVX and AES HWA (hardware acceleration) – their raw compute power does not matter as much, so the big/P Cores provide about 85% of overall performance, the highest ratio yet.
With compute hashing, SHA HWA (hardware acceleration) again helps both core types and here the big/P Cores (without AVX512) contribute just over 60% of overall performance. Here, the LITTLE/E Atom cores help best – showing that Atom cores are decent cryptographic processors thanks to both AES and SHA hardware acceleration. We have seen in RKL testing that AVX512 hashing is faster than even SHA HWA due to multi-buffer processing, so here ADL would have performed even better with AVX512. * using VAES (AVX512-VL or AVX2-VL) instead of AES HWA. ** using SHA HWA instead of multi-buffer AVX2. [note multi-buffer AVX2 is slower than SHA hardware-acceleration] |
||||||
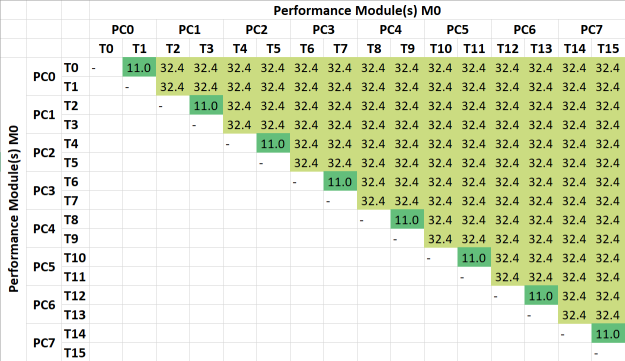 AlderLake Inter-Thread/CoreLatency Heatmap (ns) |
||||||
 |
Average Inter-Thread Latency (ns) | 38.5 | 29 [75%] | 28.5 | 45.1 | With just big/P Cores average latency is lower. |
|
Inter-Thread Latency (Same Core) (ns) | 11 | 11 | 13.2 | 10 | Naturally no changes. |
|
Inter-Core Latency (Same Module, Same Type) (ns) | 32.4 | 32.4 | 29.1 | 21.1 | Again no changes. |
|
Inter-big-2-LITTLE-Core Latency (Same Module, Different Type) (ns) | 42.9 | – | – | – | Between different core types latency is 32% higher. |
|
Inter-Module (CCX) Latency (Same Package) (ns) | – | – | – | 68.1 | Only Zen3 has different CCX/modules. |
| With the LITTLE/E Atom cores disabled, the higher (compared to the inter-thread of big/P Cores) latencies based on inter-LITTLE/E-cores and inter-big/P-to-LITTLE/E-cores no longer exist, thus the average decreases to 75% (thus 25% lower).
All values pretty much match RKL thus we do not have any regressions. In effect it becomes a “standard” non-hybrid CPU with simple two-tier latencies between threads rather than the complex hybrid 4-tier latencies in the default configuration. |
||||||
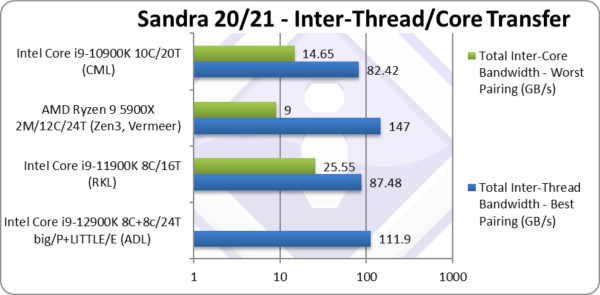 |
||||||
|
Total Inter-Thread Bandwidth – Best Pairing (GB/s) | 111.9 | 87.48 | 147 | ADL’s bandwidth is ~30% higher than RKL. | |
|
Total Inter-Core Bandwidth – Worst Pairing (GB/s) | – | 25.55 | 9 | Waiting for data. | |
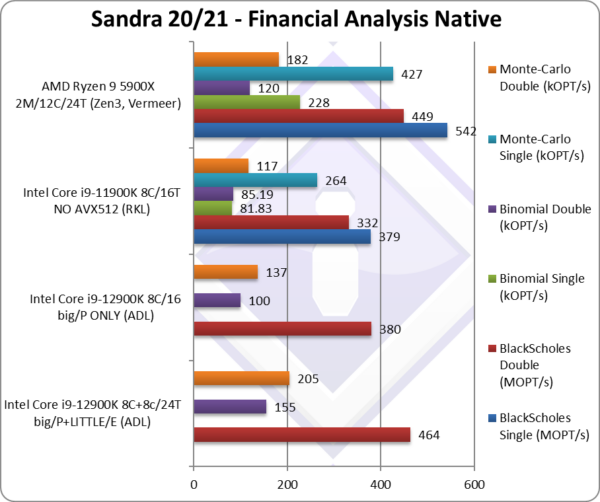 |
||||||
 |
Black-Scholes float/FP32 (MOPT/s) | 379 | 542 | Black-Scholes is un-vectorised and compute heavy. | ||
|
Black-Scholes double/FP64 (MOPT/s) | 464 | 380 [82%] | 332 | 449 | Using FP64 big/P Cores provide 82%. |
|
Binomial float/FP32 (kOPT/s) | 81.83 | 228 | Binomial uses thread shared data thus stresses the cache & memory system. | ||
|
Binomial double/FP64 (kOPT/s) | 155 | 100 [65%] | 85.19 | 120 | With FP64 code big/P Cores provide 65% |
|
Monte-Carlo float/FP32 (kOPT/s) | 264 | 427 | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches. | ||
|
Monte-Carlo double/FP64 (kOPT/s) | 205 | 137 [67%] | 117 | 182 | Switching to FP64 big/P Cores provide 67%. |
| With non-SIMD financial workloads, similar to what we’ve seen in legacy floating-point code (Whetstone), ADL’s big/P Cores provide between 65-80% of overall performance dependent on the algorithm. Again, the LITTLE/E Atom cores provide just enough uplift to beat both RKL and more importantly the Zen3 competition.
Perhaps such code is better offloaded to GP-GPUs these days, but still lots of financial software do not use GP-GPUs even today. Thus with such code ADL performs very well, much better than RKL with its AVX512 unused. |
||||||
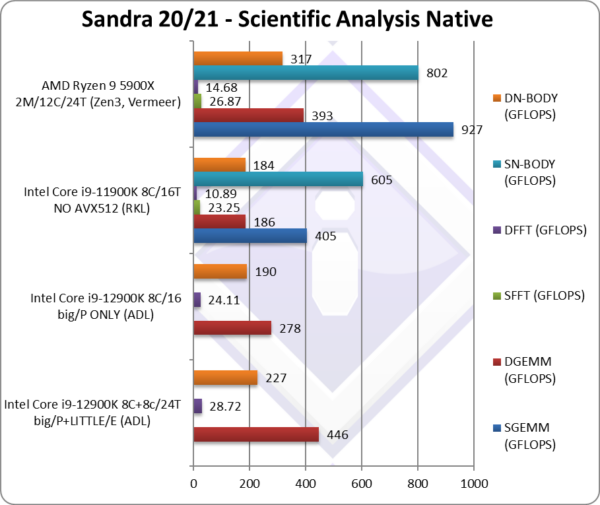 |
||||||
 |
SGEMM (GFLOPS) float/FP32 | 405 | 927 | In this tough vectorised algorithm ADL does well. | ||
|
DGEMM (GFLOPS) double/FP64 | 446 | 278 [62%] | 186 | 393 | With FP64 vectorised code, big/P Cores provide 62%. |
|
SFFT (GFLOPS) float/FP32 | 23.25 | 26.87 | FFT is also heavily vectorised but memory dependent. | ||
|
DFFT (GFLOPS) double/FP64 | 28.72 | 24.11 [84%] | 10.89 | 14.68 | With FP64 code, big/P Cores provide 84%. |
|
SN-BODY (GFLOPS) float/FP32 | 605 | 802 | N-Body simulation is vectorised but with more memory accesses. | ||
|
DN-BODY (GFLOPS) double/FP64 | 227 | 190 [84%] | 184 | 317 | With FP64 the big/P Cores provide 84%. |
| With highly vectorised SIMD code (scientific workloads), as we’ve seen in SIMD Vectorised processing, ADL’s big/P Cores provide about 84% of overall performance; thus the LITTLE/E Atom cores can only provide about 15%.
With RKL not using AVX512, ADL’s big/P Cores with the help of DDR5 are also very much faster which does show that SIMD unit performance has increased vs. RKL. Naturally, we’ve seen that AVX512 provides 40% uplift on RKL which is tough to match. While it may be somewhat disappointing to see just 15% uplift from the LITTLE/E Atom cores, that is still a decent improvement and with further optimisations perhaps can be increased. |
||||||
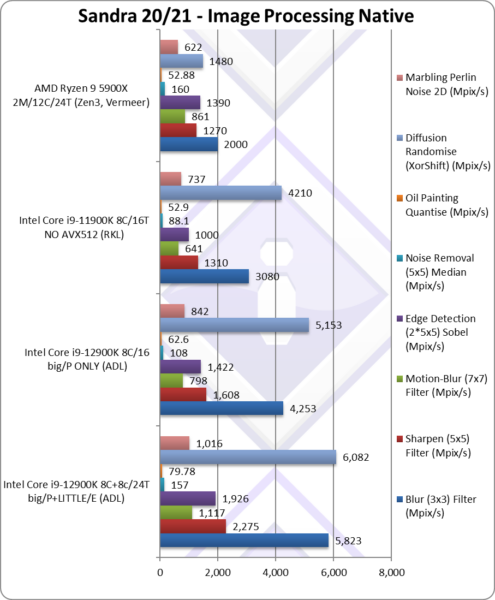 |
||||||
 |
Blur (3×3) Filter (MPix/s) | 5,823 | 4,253 [73%] | 3,080 | 2,000 | In this vectorised integer workload big/P Cores provide 73%. |
|
Sharpen (5×5) Filter (MPix/s) | 2,275 | 1,608 [71%] | 1,310 | 1,270 | Same algorithm but more shared data ratio is 71%. |
|
Motion-Blur (7×7) Filter (MPix/s) | 1,117 | 798 [71%] | 641 | 861 | Again same algorithm but even more data shared 71% ratio. |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 1,926 | 1,422 [74%] | 1,000 | 1,390 | Different algorithm but still vectorised big/P cores provide 74%. |
|
Noise Removal (5×5) Median Filter (MPix/s) | 157 | 108 [69%] | 88.1 | 160 | Still vectorised code ratio falls to 69%. |
|
Oil Painting Quantise Filter (MPix/s) | 79.78 | 62.6 [78%] | 52.9 | 52.88 | The big/P Cores contribute 78% here. |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 6,082 | 5,153 [85%] | 4,210 | 1,480 | With integer workload, the ratio is 85%! |
|
Marbling Perlin Noise 2D Filter (MPix/s) | 1,016 | 842 [83%] | 737 | 622 | In this final test again with integer workload ratio is unchanged. |
| These SIMD benchmarks are not as compute heavy as the Scientific ones and here the big/P Cores provide about 70-75% of the overall performance; naturally, this means the LITTLE/E Atom cores provide about 25-30%.
What is clear is that the big/P ADL Cores have greatly improved vs. RKL’s Cores (without AVX512) and they are about 35% faster, a significant improvement (2 generations’ worth, process shrink, etc.). Naturally RKL has AVX512 which absolutely *loves* these benchmarks. It is also clear that the LITTLE/E Atom cores do provide generous uplift which is again enough to beat the Zen3 competition. The scores are always better across all tests with the LITTLE/E Atom cores enabled. |
||||||
SiSoftware Official Ranker Scores
- 12th Gen Intel Core i9-12900K (8C + 8c / 24T)
- 12th Gen Intel Core i9-12900KF (8C + 8c / 24T)
- 12th Gen Intel Core i7-12700K (8C + 4c / 20T)
- 12th Gen Intel Core i5-12600K (6C + 4c / 16T)
Final Thoughts / Conclusions
Summary: Forward-looking but expensive upgrade (desktop)
ADL’s big/P Cores have improved decently over RKL – perhaps not a surprise as it is 2-generations over ICL/RKL and TGL had already shown decent improvements. The loss of AVX512 is painful in heavy compute SIMD algorithms and is missed.
Across most tests, the big/P Cores in ADL account for ~70-85% of overall performance (8C/16T) thus the LITTLE/E Atom cores provide about 20-30% (8c/8T). Perhaps overclockers may see better results with the LITTLE/E cores disabled or power/thermally constrained systems may see better Turbo performance – but at stock across *all benchmarks* show better performance with the LITTLE/E Atom cores *enabled*.
- In heavy-compute SIMD tests – without AVX512 on RKL thus using AVX2/FMA3 only – ADL’s big Cores are 10-30% faster than RKL’s. This is a decent improvement, but not enough to beat RKL with/AVX512 nor AMD’s Zen3 (with 12C/24T).
- In non-SIMD tests, we see ADL’s big Cores 10-15% faster than RKL – thus here the LITTLE Atom cores provide more uplift. Without them, ADL is not able to pull significantly away from RKL and match competition.
- Streaming (bandwidth bound) tests benefit greatly from DDR5 bandwidth: just the big Cores provide 85% of ADL’s performance (8T) and are 30-45% faster than RKL with DDR4 (3200). But this requires expensive DDR5 memory.
Perhaps not unexpectedly, the LITTLE Atom cores do provide decent uplift (especially with non-SIMD/legacy code) that makes up for losing AVX512. Without them, ADL is not significantly faster than RKL. By handling background tasks, the LITTLE Atom cores can prevent the big Cores for being interrupted (literally) from their heavy compute work and thus perform better. With thousands (~2,000) of threads and hundreds (~200) of processes in Windows just looking at the desktop – this is no joke.
However, with the reduced/no LITTLE Atom core versions priced better – they likely represent better value, at least on the Desktop platform. On the mobile and perhaps SOHO server where power efficiency is at a premium, the LITTLE Atom cores should become more useful.
Long Summary: ADL is a revolutionary design that adds support for many new technologies (hybrid, DDR5, PCIe5, TB4, ThreadDirector, etc.) but the platform will be expensive at launch and requires a full upgrade (DDR5 memory, dedicated PCIe5 GP-GPU, TB4 devices, Windows 11 upgrade, upgraded apps/games/etc.). For mobile devices (laptops/tablets) it is likely to be a better upgrade.
Summary: Forward-looking but expensive upgrade (desktop)
Further Articles
Please see our other articles on:
- CPU
- Cache & Memory
- GP-GPU
Disclaimer
This is an independent review (critical appraisal) that has not been endorsed nor sponsored by any entity (e.g. Intel, etc.). All trademarks acknowledged and used for identification only under fair use.
The review contains only public information and not provided under NDA nor embargoed. At publication time, the products have not been directly tested by SiSoftware but submitted to the public Benchmark Ranker; thus the accuracy of the benchmark scores cannot be verified, however, they appear consistent and pass current validation checks.
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!